基于FPGA的MMU IP軟核設計及實現*
2019-10-09 05:23:06劉紅偉梁超廣朱慧惠
通信技術 2019年9期
劉紅偉,梁超廣,朱慧惠,潘 靈,邵 龍,林 勤
(1.中國西南電子技術研究所,四川 成都 610036;2.航空工業西飛研究院,陜西 西安 710000)
0 引 言
隨著FPGA技術的發展,Xilinx公司最新的UltraScale+系列的ZCU102開發板不同于zynq-7000系列,采用的是64位的處理器armv8+大規模可編程邏輯器件(Field-Programmable Gate Array,FPGA)的 SoC模式[1]。與 armv7不同,64位的armv8擁有其獨特的內存管理機制[2]。
在armv8+FPGA的SoC模式中,ZCU102中的armv8可以很好地運行Linux嵌入式系統,實現豐富的對外接口(如串口、千兆網口、USB、EMMC以及I2C等);FPGA可以實現并行邏輯算法的加速或高速串行總線協議之間的邏輯轉換(如Rapid IO和PCIE之間的數據協議轉換),實現操作系統和并行邏輯器件之間的軟硬件結合。為了能夠訪問Linux嵌入式操作系統中寫入內存的數據,FPGA端需要一個內存管理單元(MMU)來配合Linux操作系統完成虛擬地址到物理地址的轉換,直接通過物理地址訪問處理器外掛內存的數據。本文針對這一需求設計了一個基于FPGA執行的包含TLB機制的支持虛擬地址到物理地址的轉換的內存管理單元(MMU)IP軟核,同時可以滿足訪問處理器外掛內存。
1 ZCU102平臺簡介
1.1 ZCU102開發板處理器和FPGA之間的數據通道簡介
Zynq UltraScale+系列的ZCU102開發板是ARM和FPGA兩種架構芯片結合的異構SoC,包括多處理引擎、顯示、高速外設(如PCIE、USB以及SATA等)、低速I/O功能(如CAN、UART、SPI以及NAND等)和FPGA,如圖1所示。處理引擎包括基于4核ARMCortexA53系列的處理器APU、大規模可編程邏輯陣列以及管理單元等。其中,處理器系統和FPGA之間通過AXI總線接口(ACP、M_AXI以及S_AXI等)多種互聯選擇,實現該異構SoC的整體應用的靈活性,滿足用戶許多不同的應用需求。

圖1 ZCU102平臺
AXI表示的是高級可擴展接口(Advanced eXtensible Interface,AXI),當前的版本是AXI4,是ARMAMBA?3.0開放標準的一部分。第三方廠家生產的許多芯片和IP包都是基于這個標準的。Xilinx把AXI4定義為FPGA架構內使用的優化的互聯技術[3-4]。其中,ACP是加速一致性端口(Accelerator Coherency Port,ACP),總線寬度為64位,FPGA部分作為主接口;M_AXI和S_AXI是通用AXI接口,總線寬度32位;處理器系統和FPGA都有主或從接口。
1.2 FPGA上實現MMU過程流程
ZCU102的處理器armv8運行Linux操作系統中物理地址到虛擬地址的轉換是采用頁表映射的機制實現的。Linux內核部分生成數據分配的虛擬地址通過頁表映射實現。FPGA部分可以通過訪問數據線上的物理地址讀取虛擬地址對應在內存中的數據。在開發板上,FPGA需要一個內存管理單元(MMU)完成操作系統中數據的虛擬地址到內存中物理地址的轉換,之后FPGA端通過訪問內存物理地址讀取生成的數據,從而實現FPGA端和處理器端外掛內存的地址共享,實現數據從處理器端到FPGA端的傳輸。ZCU102開發板上處理器和FPGA之間的MMU功能實現過程的功能流程,如圖2所示。處理器系統中armv8上運行Linux操作系統產生數據,之后將數據的頭虛擬地址和L1頁表地址通過M_AXI發到FPGA的S_AXI,之后傳到FPGA的MMU(內存管理單元),解析出L2、L3、L4頁表的物理地址。通過ACP讀取下一級頁表的地址,最后在FPGA的MMU中組合出數據虛擬地址對應的物理地址,訪問內存,將數據讀到FPGA,完成數據的傳輸過程。

圖2 FPGA上實現MMU處理過程的功能劃分
2 FPGA上的內存管理單元(MMU)的設計
FPGA上MMUIP軟核的設計主要由2部分組成,如圖1所示,一部分是虛擬地址到物理地址轉換的邏輯,另一部分是TLB的邏輯。
2.1 Armv8的內存管理體系
運行在armv8的Linux采用分頁式內存管理機制。內存空間分為用戶(User)空間和內核(Kernel)空間[5]。當使用用戶空間的地址進行翻譯時,使用的是TTBR0_EL0寄存器的值作為查找表的基地址;當使用內核空間的地址進行翻譯時,則使用TTBR1_EL1寄存器的值作為查找表的基地址,如圖3所示。
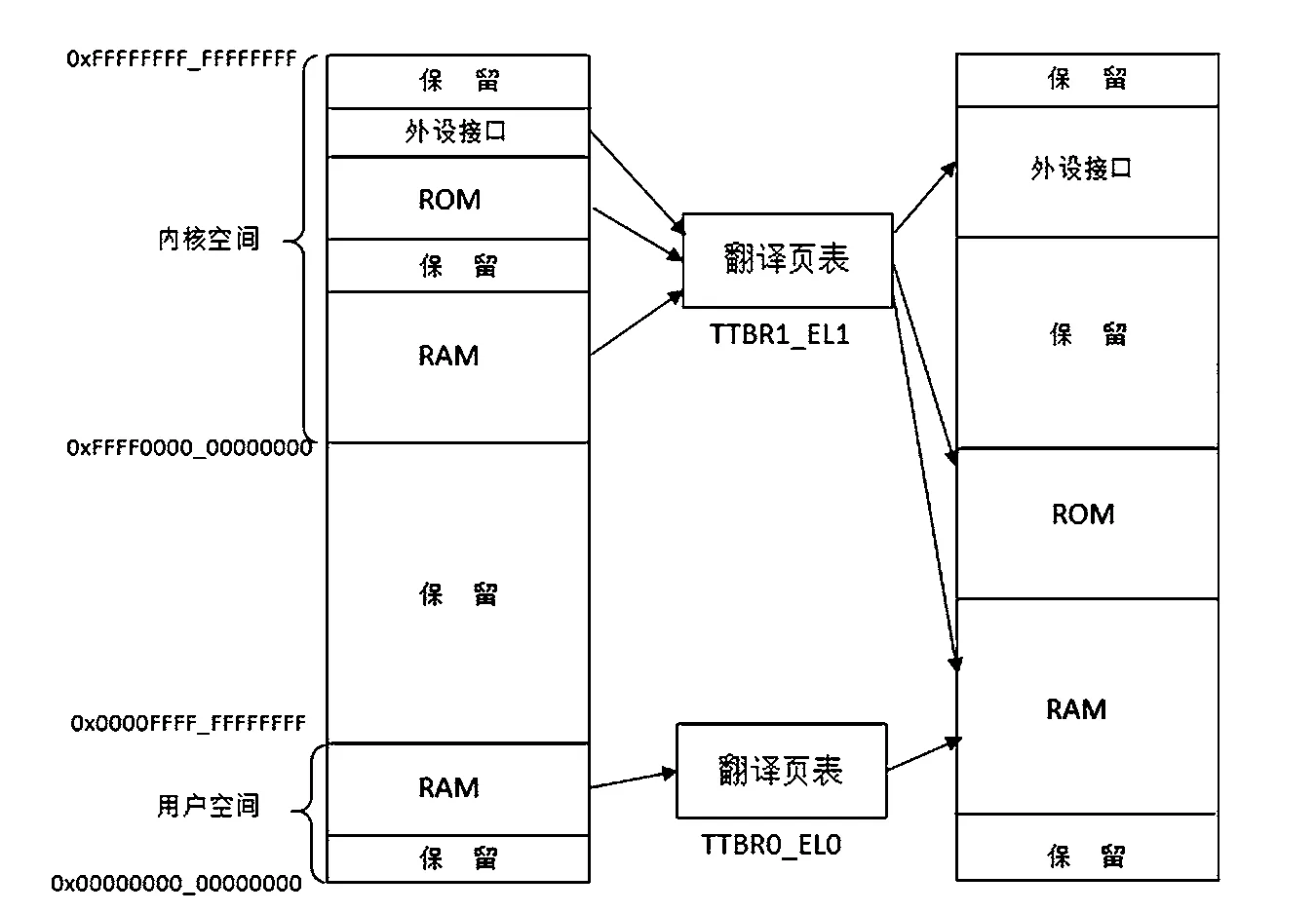
圖3 armv8內存映射機制
Armv8在執行Linux內核時支持多種內存轉換粒度及其對應的虛擬地址位寬,如表1所示。

表1 不同內存轉換粒度對應的虛擬地址位寬
2.2 MMU的原理及工作流程
本文的MMUIP核的設計依據運行在4kB的內存轉換粒度和39bit的虛擬地址位寬內核的Linux來完成。整個MMU的工作原理流程如圖4所示。
結合圖2和圖4的原理,設計MMUIP核VHDL邏輯工作流程如圖5所示。
具體步驟如下:
(1)Linux端通過MAXI發送虛擬地址以及TTBR0_EL0或TTBR1_EL1寄存器的值;
(2)進入MMU工作的VHDL邏輯,TTBR0_EL0 或 TTBR1_EL1[47:12]與 虛 擬 地 址 [38:30]以 及“000”進行第一次拼接,獲得L2頁表地址并將其通過MMUIP端MAXI發送到PS的ACPSAXI接口上;

圖4 MMU的工作原理流程
(3)將ACPSAXI接口獲得的L2頁表地址解析后得到PUD的值,同時MMUIP端MAXI接口將會獲取到 PUD[47:12]的值、虛擬地址 [29:21]以及“000”進行第二次拼接,獲得L3頁表地址并發送給PS;
(4)將ACPSAXI接口獲得的L3頁表地址解析后得到PMD的值,同時MMUIP端MAXI接口將會獲取到 PMD[47:12]的值、虛擬地址 [20:12]以及“000”進行第三次拼接,獲得L4頁表地址并發送給PS;
(5)將ACPSAXI接口獲得的L4頁表地址解析后得到PTE的值,并將PTE的值保存到TLB緩存中,同時MMUIP端MAXI接口將會獲取到PTE[47:12]的值與虛擬地址[11:0]進行第四次拼接,獲得物理地址并發送給PS;
(6)將ACPSAXI接口獲得的物理地址解析后得到對應的數據,同時MMUIP端MAXI接口將會獲取對應的數據進行保存;
(7)將虛擬地址進行間隔16bit的疊加,并判斷數據是否獲取完成。如果未完成且虛擬地址超出4kB的內存細粒度,則進入TLB緩存機制獲取PTE的值;如果未完成但虛擬地址超出4kB的內存細粒度,則返回到步驟(2)。
2.3 MMU的VHDL邏輯及狀態機的設計
按照2.2節的MMU工作原理,使用Vivado設計和封裝IP核時,虛擬地址到物理地址的轉換VHDL邏輯和MMU狀態機的設計,分別如圖6、圖7所示。
該狀態機采用單進程設計,共有11個狀態。狀態機從Read addr狀態進入,讀取到虛擬地址后進入Read tlb狀態判斷是否觸發TLB緩沖器。如果觸發,則進入Read Data cmd狀態讀取讀數據指令,進而進入Read Data狀態讀數據后返回Read addr狀態等待虛擬地址;如果沒有觸發,TLB緩存器則進入Read pud cmd狀態讀取讀PUD值指令,進而進入Read pud狀態讀取PUD值。如果PUD值的后兩位為全零,則表示未讀取到有效的PUD值,進入PAGE FAULT狀態,進而返回Read addr狀態等待虛擬地址;如果讀到有效的PUD值,則依次進入Read pmd cmd狀態和Read pmd狀態讀取PMD值。如果PMD值的后兩位為全零,則表示未讀取到有效的PMD值,則進入PAGEFAULT狀態,進而返回Read addr狀態等待虛擬地址;如果讀到有效的PMD值,則依次進入Read pte cmd狀態和Read pte狀態讀取PTE值。如果PTE值的后兩位為全零,則表示未讀取到有效的PTE值,進入PAGEFAULT狀態,進而返回Read addr狀態等待虛擬地址;如果讀到有效的PTE值,則依次進入Read data cmd狀態和Read data狀態讀取讀數據,隨后返回Read addr狀態等待虛擬地址。

圖5 MMUIP軟核VHDL邏輯工作流程
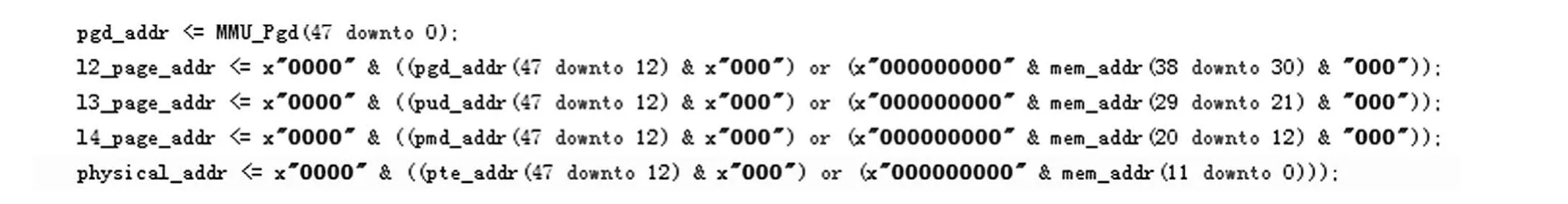
圖6 虛擬地址到物理地址的轉換VHDL邏輯
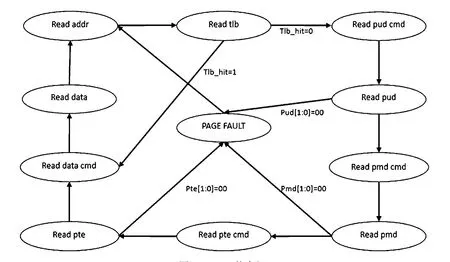
圖7 MMU狀態機
3 仿真及驗證
3.1 仿真及驗證平臺
本文設計的是一個可以運行在ZCU102平臺的MMUIP核。為了能夠使該IP核可以正常工作,需要在ZCU102平臺上運行64位的Linux系統,以及利用Vivado設計相應的工程進行測試。
本次測試的環境:Xilinx公司ZCU102 REVISION1.1開發板,Vivado 2018.3開發軟件,64位Linux操作系統。
本次測試的基本流程:在Linux操作系統中創建一個函數,函數內容包括申請一段64位數據類型的用戶空間內存,生成一段數據寫入該段用戶空間內存,并將該段用戶內存空間的起始地址和TTBR0_EL0寄存器的值發送給MMU。
利用Vivado 2018.3軟件創建Vivado工程,該Vivado工程包括MMU IP軟核和ZCU102的PS的IP核。綜合后添加ILA核調試工具生成bit文件和ltx文件,通過仿真器加載到開發板中即可調用Linux系統中設計的函數進行測試。
3.2 ILA調試工具仿真結果
64位的Linux內核在ZCU102開發板中初始化結束后調用函數,完成虛擬地址和TTBR0_EL0寄存器的值發送后,通過ILA調試工具可以得到如圖8所示輸出波形。

圖8 ILA調試的仿真波形
通過調試平臺得到的波形可以看出,MMU能夠很好地讀取到Linux內核分配的內存地址以及其相對應的數據。其中,虛擬地址的首地址為0x0038ca83a0,TTBR0_EL0寄存器的值為0x87aaab000,第一次與虛擬地址的[38:30]位拼接后查表得到的PUD的值為0x87a022003,第二次與虛擬地址的[29:21]位拼接后查表得到的PMD的值為0x87a816003,第三次與虛擬地址的[20:12]位拼接后查表得到的PTE的值為0x87bc9ff53,最終與虛擬地址的[11:0]位拼接得到的物理地址為0x87bc9f3a0,對應的值為0x1fff以及下一位的值0x1ffe。虛擬地址加16bit后為0x0038ca83b0,可以觸發TLB緩存,直接可得其對應的物理地址為0x87bc9f3b0,對應的值為0x1ffd以及下一位的值0x1ffc,可以滿足設計時的需求。
4 結 語
針對armv8的內存管理機制,結合FPGA對應用數據獲取的高效率和大吞吐量的需求,本文設計了一個可以適用于Xilinx公司的ZCU102開發板的包含了TLB緩存的MMU IP軟核。實驗表明:該MMU IP軟核可以從處理器端外掛的DDR存儲顆粒內穩定高效地獲取大吞吐量的數據,可以廣泛應用于FPGA和處理器端之間數據通信的應用場景。
