基于Scrapy和Hadoop平臺的房屋價格數據爬取和存儲系統
2019-10-09 05:48:58丁志毅
電子技術與軟件工程 2019年17期
文/丁志毅
隨著大數據、云計算、人工智能等新興計算機技術的急速發展,所產生的數據呈爆炸性增長,如何實現存儲和計算能力的分布式處理,擺脫目前傳統的計算技術和信息系統的處理方式,是目前數據分析領域亟待解決的問題。Hadoop 是使用 Java 語言開發的分布式計算存儲系統,是一個由Apache基金會支持的開源項目,提供可靠的,可擴展的分布式系統基礎架構,能夠跨計算機集群分布式存儲海量數據,允許使用簡單的編程模型分布式處理數據。用戶可以像操作本地文件系統一樣透明的訪問HDFS,常應用于海量數據的場景。
1 爬蟲系統的設計與實現
1.1 爬蟲基本原理
網絡爬蟲的主要作用是依據一定的爬行策略自動的從網上下載網頁鏡像到本地,并能夠抓取所有其能夠訪問到的網頁以獲取海量信息,解析其中的數據進行分析挖掘等。其基本工作原理如下:首先初始化一個URL作為爬行的開始位置,如果該 URL沒有被抓取過,解析其DNS信息,嘗試與這些 URL鏈接所在的服務器建立連接,自動提取頁面上的信息保存至本地,同時提取新的 URL,根據一定的遍歷算法將其去重過濾后加入待爬取隊列,重復以上步驟遍歷所有的網頁數據,直到待爬取的隊列中沒有可用的 URL,滿足停止的條件時結束爬取。
1.2 爬取模塊
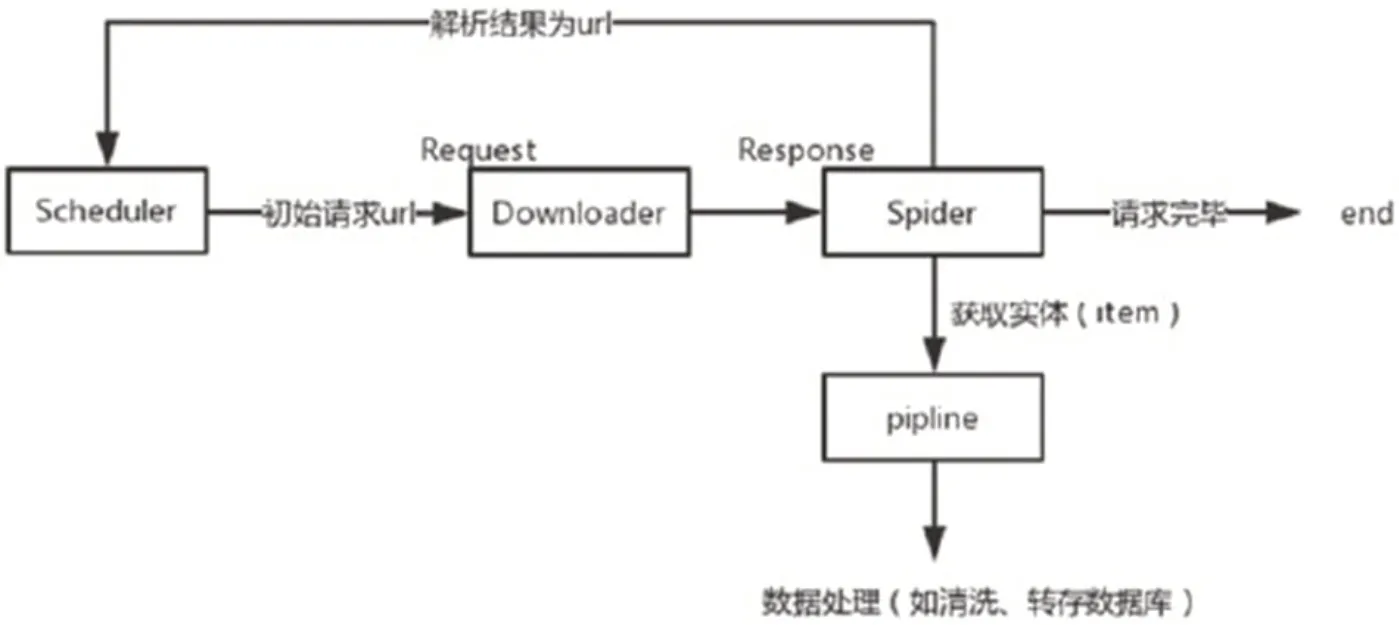
圖1:Scrapy爬蟲的流程
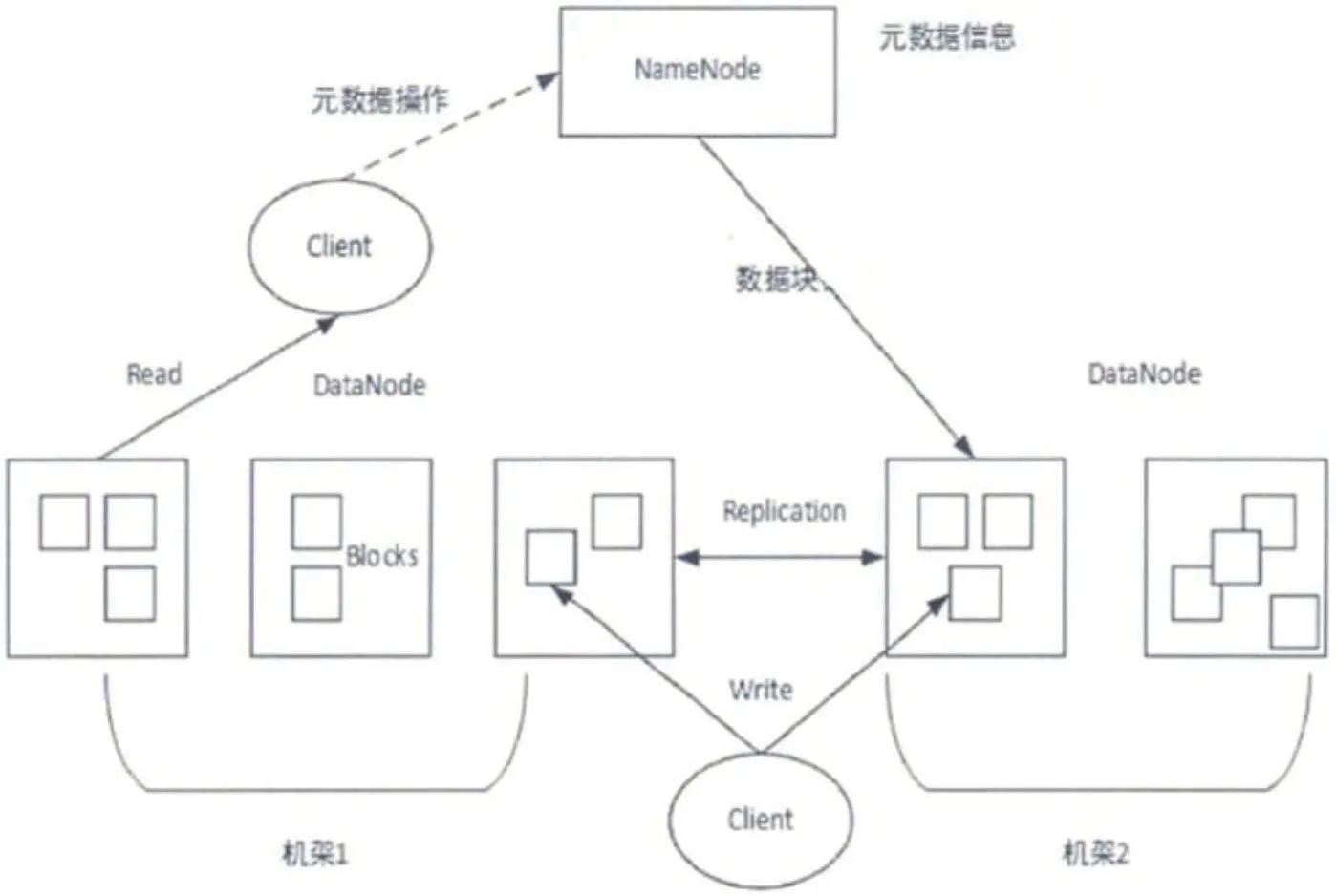
圖2:HDFS系統結構
Scrapy是一款開源的網絡爬蟲框架,是使用python 語言開發并封裝的一個強大的自動數據采集框架,目的為了爬取網站內容,提取結構性數據。無需再從零開始去設計爬蟲框架,而是可以簡單、高效的搭建python 的 Scrapy 框架,通過 Scrapy 框架提供的功能進行定向的數據爬取工作。在 Scrapy 項目中,可以方便地自定義爬蟲的爬取規則,即可快速獲得所需要的網頁數據,同時一些固定的前置后續處理可由一些穩定的開源庫幫助解決,并可根據需要將關鍵數據保存為特定的數據格式。Scrapy 爬蟲的流程如圖1所示。
Scrapy 強大的功能得益于他的構架,他總共有 8 個部分組成:
1.2.1 Scrapy Engine 組件
爬蟲框架的引擎組件,是整個框架的“大腦“,負責所有組件的數據流動。
1.2.2 Scheduler 組件
調度器組件,負責接收并創建請求隊列。
1.2.3 Downloader 組件
下載器組件,負責下載網頁數據。
1.2.4 spiders 組件
爬蟲模塊,其功能在于從特定的網頁結構數據中獲取指定信息,在 Scrapy 中被定義為實體(Item)。
1.2.5 Pipeline 組件
負責對數據進行清理、驗證以及持久化(轉存數據庫)的處理。
1.2.6 Downloader middlewares
其在引擎和下載器組件之間,功能是負責引擎發出的請求,以協調下載組件工作。
1.2.7 spider middlewares
負責處理爬蟲數據的輸入和輸出,主要是為了提高爬蟲質量,可以同時使用不同功能的下載中間件。
2 HDFS存儲模塊
HDFS 采用典型的主從式(master-slave)設計,在該設計中主要包含兩種節點:主節點(NameNode)和數據節點(DataNode)。主節點負責管理整個文件系統的命名空間;另外一種 DataNode是從節點,為數據提供真實的存儲、管理服務。DataNode 最基本的存儲單位是 Block,文件大于 Block 時會被劃分為多個 Block 存儲在不同的數據節點,其元數據存儲在NameNode中,全局調度數據塊的讀寫操作,主要用于定位block與DadaNode之間的對應關系。用戶如果操作 HDFS 文件時,需要先訪問 NameNode 節點,讀取元數據(metaData)信息,得到存儲位置后再訪問 DateNode 。其架構如圖2所示。
經Scrapy采集到的數據需要持久化到hdfs中,python語言來訪問Hadoop HDFS時,需要引入pyhdfs庫,通過pyhdfs提供的API接口實現對hdfs的操作。HdfsClient這個類可以連接HDFS的NameNode,用來讀、些、查詢HDFS上的文件。代碼示例:
Client=pyhdfs.HdfsClient(hosts="192.168.1.108,9000",user_name="hadoop")
從本地上傳文件至集群
client.copy_from_local("D:/test.csv","/user/hadoop/test.csv")
打開一個遠程節點上的文件,返回一個HttpResponse對象
HttpResponse response = client.open("/user/hadoop/test.csv")
3 結語
在房地產市場領域,浩瀚的網絡資源已經呈現出大數據的特點,傳統的信息處理技術已經無法適應需求。針對無法進行有效數據分析的現狀,本文研究利用Scrapy網絡爬蟲框架和HDFS 分布式文件系統進行數據的采集和存儲。HDFS 能為不斷增長的數據提供高度的容錯、高吞吐量和分布式儲存服務。通過提升大數據分析技術在房地產行業中的應用水平,充分利用 Hadoop 平臺的優勢,轉變數據存儲方式和計算模式,加強數據的分析和挖掘,提高政府及有關部門對房地產市場分析的廣度和深度,更好的為政府決策、行業管理提供決策依據是下一步的主要研究工作。
