恒速機上的MapReduce在線排序算法下界研究
2019-10-08 07:45:24姜曉燕帥天平
軟件 2019年1期
姜曉燕 帥天平

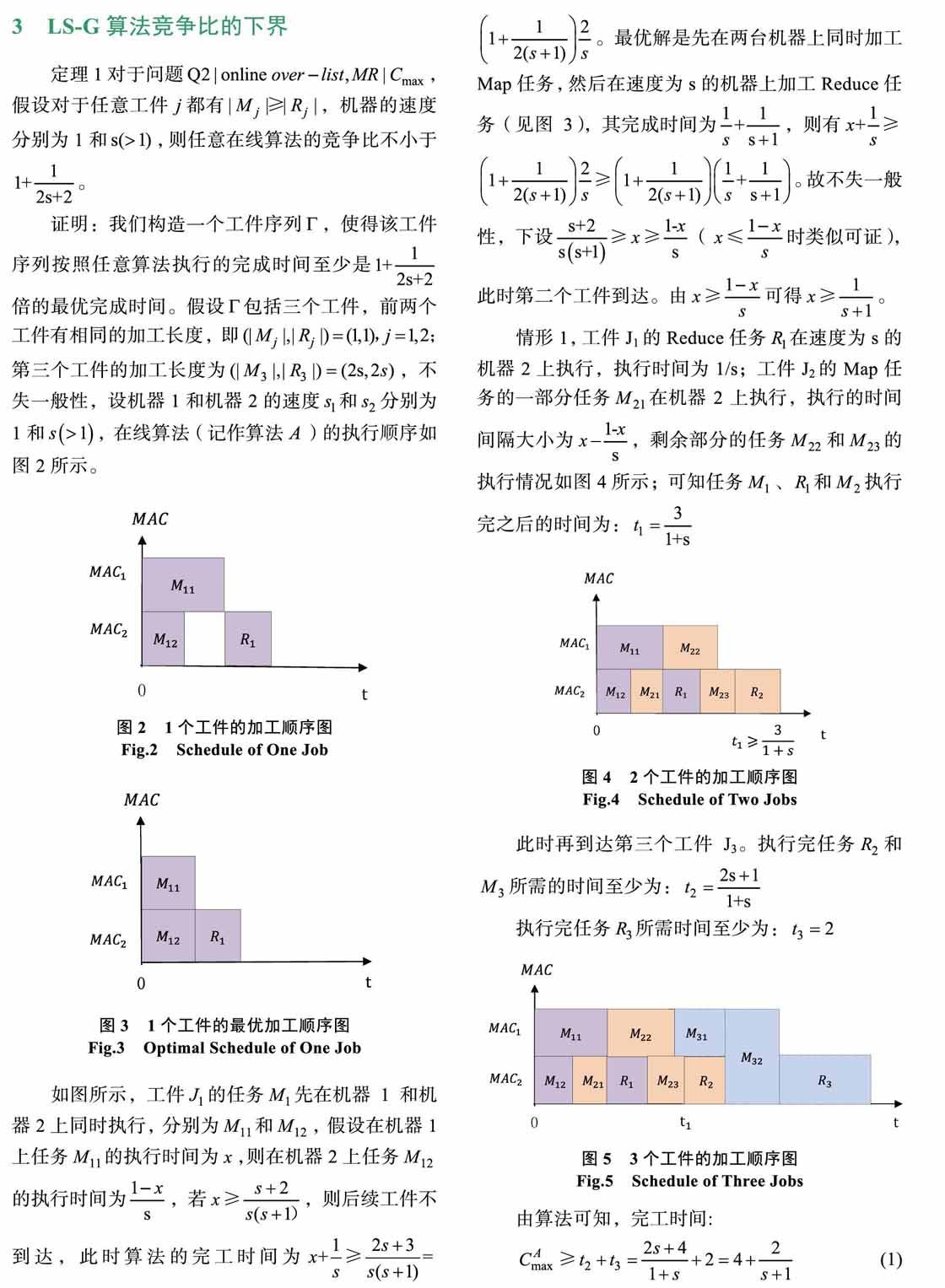
摘? 要: 本文研究源自于MapReduce模型系統的一類排序問題。給定兩臺恒速機和一批按列表到達的工件,每個工件包含兩類任務:Map 任務和Reduce任務。假設Map任務和Reduce任務都是不可中斷的,Map任務可以并行處理,即可以任意分割成若干小的任務并在兩臺機器上同時處理,而Reduce任務只可以在單臺機器上處理。一旦工件到達,必須為其指派機器和開工時間,目標是使得這批工件的最后完工時間最小。對|Mj|≥|Rj|的情形, 我們證明了任意在線算法的競爭比不小于.
關鍵詞: MapReduce;在線排序;LS-G算法;競爭比
中圖分類號: O223? ? 文獻標識碼: A? ? DOI:10.3969/j.issn.1003-6970.2019.01.002
0引言
目前,隨著全球信息產業在不斷融合發展,網絡資源與數據規模也在不斷增長,尤其是在科學研究(天文學、生物學、高能物理等)、計算機仿真、互聯網應用、電子商務等領域,數據量呈現快速增長的趨勢,并由此產生了許多機遇[1]。
傳統的數據分析技術已經越來越不適應當前密集型海量數據處理的需求。而近幾年興起的云計算(Cloud Computing),其實本質上是一種新的提供資源按需租用的服務模式,是一種新型的互聯網數據中心(Internet Data Center,IDC)業務。
為了解決當今處理海量數據的問題,Google 實驗室提出了云計算中的MapReduce[2]模型解決了這個問題,盡管MapReduce的分布式模型技術在模式上很簡單,但還存在許多問題,比如需要數據分析人員自行設計編寫Map與Reduce函數的具體細節,所以傳統的算法需要重新設計,才能更好地實現代碼向數據遷移這一目標,由此傳統算法的Map Reduce排序成為一個研究熱點,而在本文中我們主要研究MapReduce排序算法的完工時間問題。
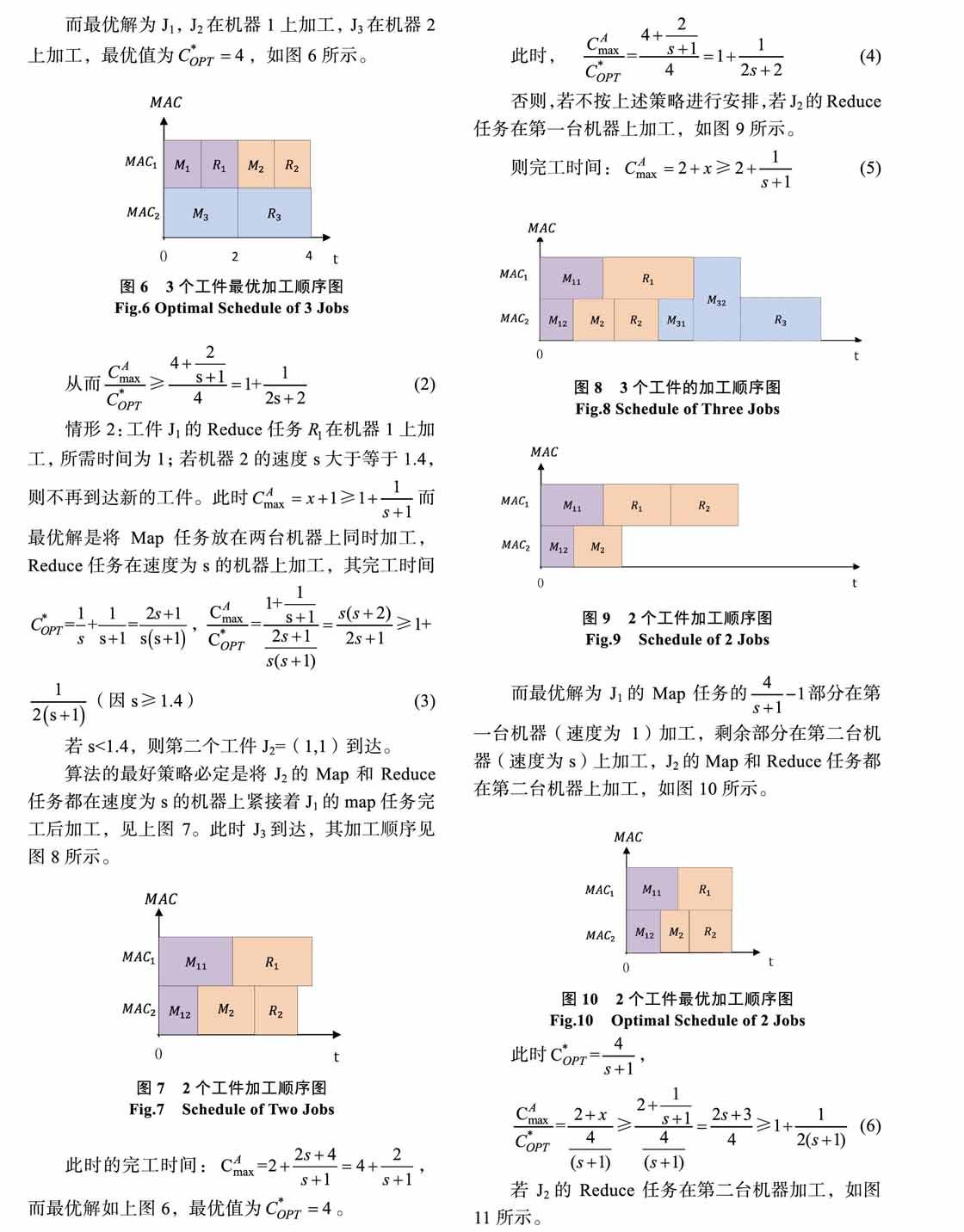
MapReduce系統在執行任務的過程時,首先加工到達工件的Map任務,產生中間鍵值對,然后再加工相對應的Reduce任務[7]。其實MapReduce講的就是“分而治之”的程序處理理念,把一個復雜的任務劃分為若干個簡單的任務分別來做。其執行流程圖[7]如下:
