基于通信協議的數據解析研究與實現
2019-10-08 06:27:21閆超
軟件 2019年6期

摘 ?要: 網絡傳輸廣泛應用在IT領域的各個領域,為保證數據通信網中通信雙方能有效、可靠通信而規定的一系列約定。在實際應用中會接觸到對于通信協議的解析的需求,解析的方法更是根據實際情況種類繁多。本文主要依據衛星地面數據的解析問題,對實際應用中可能遇到的實時傳輸、誤碼、循環重傳等不同的數據情況進行了分析和處理。針對去重復、容錯等要求對不同解析方法的應對進行了分析、比較和實驗;針對數據解析時效性的要求,對數據進行分配并調度到線程池中進行處理,從而達到時效性的目的。
關鍵詞: 通信協議;預處理;包處理
中圖分類號: TP311.52 ? ?文獻標識碼: A ? ?DOI:10.3969/j.issn.1003-6970.2019.06.037
本文著錄格式:閆超. 基于通信協議的數據解析研究與實現[J]. 軟件,2019,40(6):160163
【Abstract】: Network transport is widely used in various domain of IT, network both sides data communication effective and reliable guaranteed by series of agreements. In real application, it needs to parse communication protocol and there are various parsing methods base on actual situations. This article is mainly based on analysis of satellite and ground data, it analyzed and processed different data situation may occur in reality, like real-time transmission, error, retransmission cycle and etc. According to requirements of de-duplication, fault tolerance and etc, it analyzed, compared and experimented different parsing methods. According to data parsing timeliness requirements, it distributed data and scheduled to a thread pool for processing.
【Key words】: Communication protocol; Preprocessing; Packet processing
0 ?引言
數據的通信協議[1]亦稱數據通信控制協議。是為保證數據通信網絡中通信雙方能有效、可靠通信而規定的一系列協議。這些協議包括數據的格式、順序、速率、數據傳輸的確認或拒收、差錯檢測、重傳控制和詢問等操作。最廣泛的通信協議為TCP[2]/IP[3]協議和UDP協議,本文討論的衛星的通信[4]協議就是在此協議的基礎上進行裁剪、修改和擴充得到的。
數據解析是指根據已知的數據通信協議,按照協議去掉冗余信息并進行計算獲得用戶需要的數據信息,在很多處理系統中通常為第一個或者前面環節用于數據的接收的初步處理,大量的操作與運算都在后臺服務器端進行。
1 ?功能與建模
1.1 ?功能
根據幀數據格式和幀同步頭獲取幀數據,去掉幀的冗余信息獲得包數據,再從包數據[5]解出所需要的數據信息并通過參數解算、格式轉化等操作獲得需要的接口數據。
由于衛星重復下傳數據造成了重復數據,需要進行去重處理。因為地面接收和星上下傳時間不同步,所以無法判斷數據重復的起始位置,所以只能通過解析數據獲得包時間,根據包時間是否重復判斷數據的重復性并去重復。
1.2 ?數據建模
本文參照數據傳輸的基本數據格式,設計了幀數據和包數據的格式。
幀數據格式:1F2F3F4F為幀頭,幀長度固定為1024B;
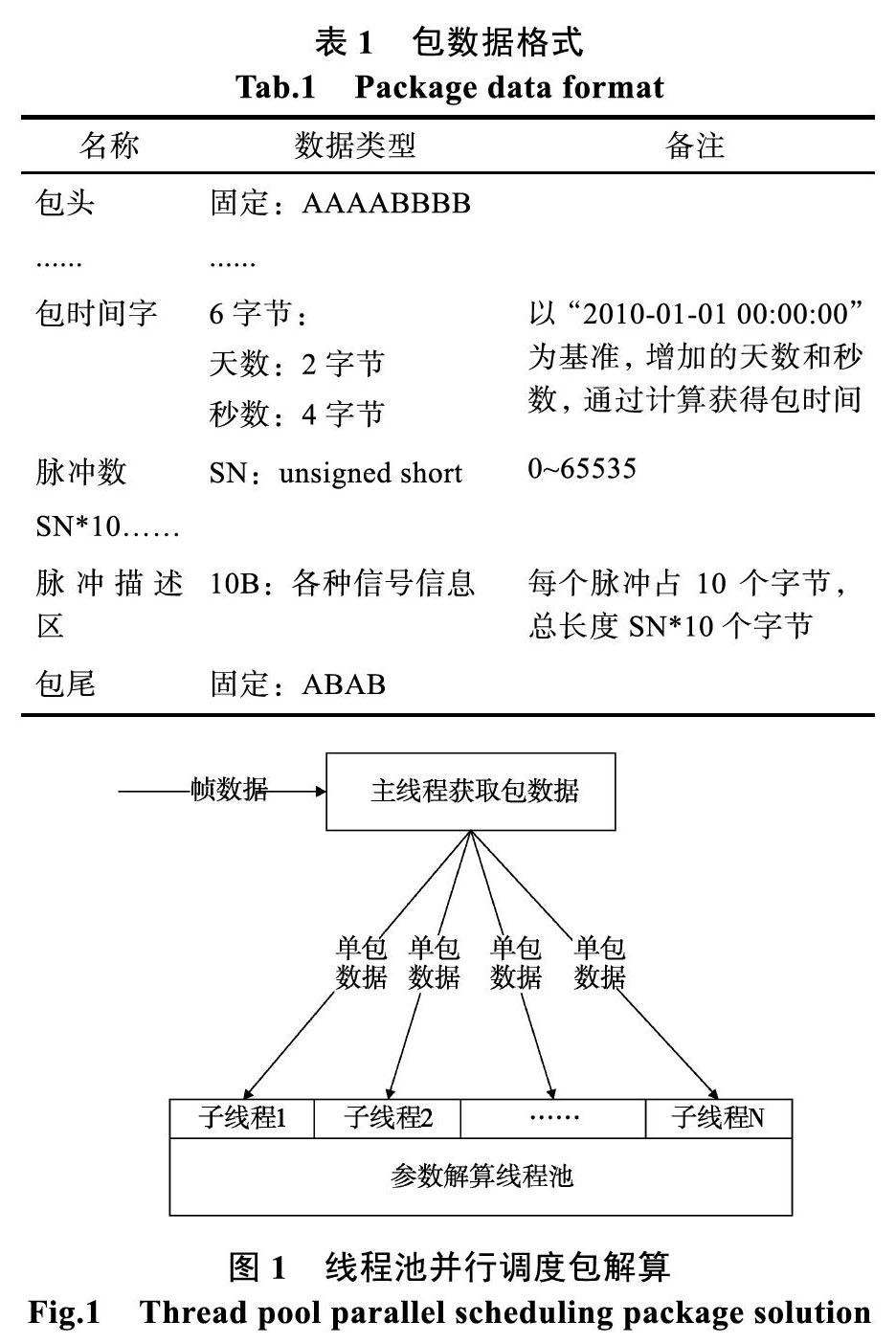
包數據格式:AAAABBBB為包頭,長度由所加載的脈沖數聯合確定,具體如下表所示。
2 ?數據解析算法設計與實現
2.1 ?解析算法介紹
數據解析過程按照固定步進和回溯對數據進行解析。一般的數據幀和數據包都有一定的規律,數據幀往往都是固定長度固定節拍,數據包的長度根據信息源、采樣率和采樣時間有所不同,但是根據包信息一般可計算出包的具體長度,所以根據固定節拍查找速度較快,但是對于糾錯能力比較弱,當固定步進無法找到合適匹配頭時,需要重新從搜索位置逐字節尋找。當獲得一包數據后,由于包內數據的運算量可能很高,需要創建線程池,將每包數據作為獨立的數據片段分配到不同的線程中進行處理。
2.2 ?數據解析
逐字節遞增進行幀和包同步頭的匹配,當匹配到合適的幀和包同步頭后進行有效性驗證,對于正確的數據進行后續處理;
固定步長查找方法是由于我們在組幀的時候也是按照固定節拍進行組幀,反過來一般的數據幀和數據包都有一定的規律,數據幀往往都是固定長度固定節拍,數據包的長度根據信息源、采樣率和采樣時間有所不同,但是根據包信息一般可計算出包的具體長度,所以根據固定節拍查找速度較快;
混合查找就是以固定步長為引導,當固定步長無法查找到有效的同步頭,在回溯到當前的查找位置用逐字節進行遍歷查找。
第一種方法是適應性最強,但是帶來的代價就是效率[6-7]也是最低的,對于數據完整性差、錯誤較多情況適用,適用于數據傳輸信號不穩定、單幀/包的數據長度不固定或者無法計算的情況。
第二種方式對于接收、數傳信道正確、穩定的數據,或者經過初步預處理的數據,效率最高,同時適應性也是最差的。本次模擬[8]的數據樣本有非常完整的數據,省掉了搜索匹配的地址位移和同步頭匹配的操作,可以較大提高執行效率。
第三種方法是結合前兩種方法,對數傳中會出現誤碼,數據完整性相對較好的情況,既需要步進查找,而且在出現誤碼時進行回溯查找。
2.3 ?數據去重復
因為地面接收站在接收衛星下傳數據時,衛星采用循環播放下傳方式,地面站接收時間較長,接收幾個周期的衛星下傳,所以會造成數據重復的現象,由于數據時間根據計劃可以獲得,根據時間制定哈希表去重復。
遍歷搜索方法是大家應用的比較多的方法,利用類似于STL中list的存儲,對新獲得的包時間與已存儲的數據的包時間進行比較去重復。
哈希表去重復是在數據有一定的連貫性,例如時間數據,以整秒進行遞增,可以建立有限的空間的哈希表,初始化為0,對于獲得的數據標記為1,對于已經標記過為1的數據判為重復數據,不再進行后續處理。如果幀計數為連續并且計數的最大值和最小值的差相對較小,也可根據幀計數制訂哈希表去重復。
第一種方法是使用第三方庫中現有方法或者依靠循環遍歷使用不同查找的方法,每次遍歷都不能直接找到重復數據,如果數據不重復則需要從前到后比對一遍,遍歷和比對造成時間消耗較大,可比較的數據元素的個數越多消耗越大。
第二種方法使用的創建哈希對照表的方法,通過計算時間差來獲得相對步進,從而支持了隨機訪問,存儲空間消耗相同,但是在時間性能上有較大提高,對于數據的時間跨度越大越明顯。哈希表的創建有局限性,對于連續的跨度在可接受范圍內的數據可以創建,如果創建哈希表代價過大需要根據實際情況進行分析。
2.4 ?數據并行處理
在解析數據時,幀和包數據的解析可以并行[9-10]處理,同時也可以在數據包內部進行并行。
(1)數據幀和數據包分兩個線程進行處理。
(2)數據幀和數據包分兩個線程進行處理,同時在數據包解析后,由于包與包之間在數據解析過程中不存在關聯關系,將每包數據視為獨立的數據片段。考慮到尋找下一包的時間消耗遠小于對一包數據的運算,可以使用一個線程進行解析獲得每包的數據片段,把獲得的數據包放入包處理的線程池中進行后續處理,包搜索線程同時搜尋下一包。
第一種方法是創建幀和包處理的的雙線程/進程通過文件/內存方式進行交互處理,同時處理幀和包數據。
第二種方法使用在幀和包并行處理的同時,由于單包的數據運算量較大,所以通過線程池/進程池等方法實現數據包的并行處理,處理方式如所示。
3 ?仿真及算法過程
3.1 ?仿真環境
實驗在64位Linux環境下進行,計算機處理器Inter(R) Core(TM) i5-4200 CPU @ 1.60GHZ 2.30,內存4.00GB,實驗執行采用Windows客戶端遠程調用方式。編寫簡單的創建數據源的軟件,模擬創建了六批數據樣本,用于比較解幀、去重復和并行處理各兩批數據樣本。
3.2 ?實驗驗證
3.2.1 ?實驗過程
第一組實驗針對數據解析算法的比較,數據樣本的兩組數據特點:
(1)原始數據完整,幀按照1024步進完整,包數據長度隨機為1M左右;
(2)在完整的原始數據基礎上添加錯誤幀長、丟幀和錯誤包長的情況。
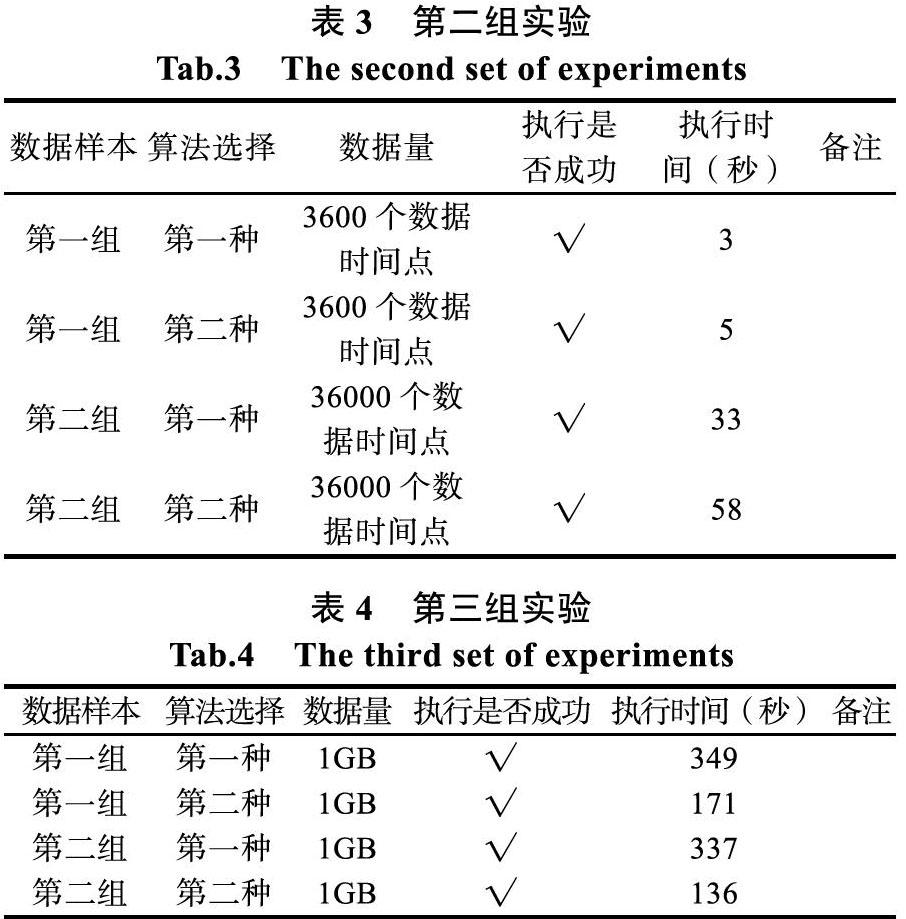
第二組實驗比較兩種排序算法的效率問題:
(1)按照時間2018-01-01 00:00:00~2018-01-01 01:00:00,一秒一個節拍,一共1小時:3600個數據時間點用于去重復,五倍的重復數據;
(2)按照時間2018-01-01 00:00:00~2018-01-01 10:00:00,一秒一個節拍,一共10小時:36000個數據時間點用于去重復,五倍的重復數據。
第三組實驗比較單線程和線程池處理包的效率問題:
(1)原始數據完整,幀按照1024步進完整,包數據長度隨機為1M左右,數據類型分為全脈沖和中頻兩種,總數據量1GB;
(2)原始數據完整,幀按照1024步進完整,包數據長度隨機為10M左右,數據類型分為全脈沖和中頻兩種,總數據量1GB。
3.2.2 ?實驗結果
部分實驗運行結果如下圖所示。
第一組實驗,具體結果參見表。
第一種逐字節查詢算法通過逐個字節的累加把每個位置的數據都與同步頭進行匹配,由于每個位置的數據都進行了匹配,所以容錯能力強,但是自身執行效率低。
第二種通過固定步進查找,匹配到一個同步頭后,當前位置加上步進直接獲得下一個同步頭,算法執行效率高,如果中間數據有錯誤或丟失將無法繼續匹配查找,沒有容錯能力,所以第二組數據無法通過測試[11]。當數據經過去除錯誤數據的初步處理,可以選擇這種方法,執行效率高,程序實現簡單。
第三種算法結合了前兩種方法的方式,具備了容錯能力和速度處理能力,由于需要結合兩種方法做程序設計,所以在編程實現過程中相對復雜。
第二組實驗,具體結果參見表。
使用STL中的list對數據進行去重復,第一組數據有3600個點,獲得一個時間點后需要與已經記錄的時間點作比較,比較次數為1到3600。使用哈希表方法每次需要計算當前包系統時間與數據起始時間的差值,獲得差值后可以直接訪問哈希表中對應的數據,比較一次可以就可以判斷是否重復。哈希表多一個計算時間差過程,極大的減少了查詢比較次數。
從第二組數據的實驗結果可看出,時間點個數增加,包時間數據的維度增加,第一種方法需要比較的次數也增加,比較次數從1到3600變成1到36000,需要消耗更多時間。使用哈希表的方法時間消耗只與總共需要比較的包時間個數有關,所以時間數據維度的增加在時間消耗上線性增長,但是遠小于第一種方法。
第三組實驗,具體結果參見表。
使用單線程對包數據進行參數解算,線程搜索匹配包同步頭后進行參數解算,一直到所有數據處理結束,整個過程是順序的過程,總的時間消耗為每一步時間消耗的總和。使用線程池進行計算,主線程搜索匹配包同步頭,獲得一包數據后交給線程池中的子線程進行計算,直到所有數據搜索匹配結束并且包解算子線程都完成計算,整個過程是并行交互的過程,處理同時進行降低了總時間的消耗。
第二組數據的包數據長度增加,包內解算的運算量隨之增加。由于更多的時間消耗的處理在線程池中進行,所以線程池并行處理的效果更明顯。
3.3 ?實驗結果分析
通過分析和實驗驗證,得出如下結論:
第一組實驗:
(1)第一種逐字節查詢算法容錯能力強,錯誤數據影響小,但是自身執行效率低;
(2)第二種算法執行效率高,沒有容錯能力;
(3)第三種算法效率高,具有容錯能力,錯誤數據影響較小。
第二組實驗:
(1)建立哈希表去重復算法,效率高;
(2)兩種方法對于時間點的增長,時間消耗都保持線性增長。
第三組實驗:
(1)利用線程池比單線程效率高;
(2)單包內運算量越大、處理耗時越長,效果越明顯。
4 ?結論
本文首先概述了通信協議的數據解析的關鍵技術和算法。根據衛星通訊需求,構建了一種數據解析的節本框架。在一定的通訊協議下,針對不同場景的數據樣本,給出了不同的解析算法。通過實驗分析對各種解析算法的處理能力、容錯性、效率進行了分析和比較。依據并行設計的原理,增加了線程池在數據解析過程中的使用,通過合理利用計算資源,較大的提高執行效率。在優化通信協議的數據解析算法的研究方面做了有意義的嘗試與實踐,并做了相應的實驗,對學習和工作有一定的指導作用。
參考文獻
[1] 蔡治軍. 基于因特網IPv6協議的數字視頻傳輸系統的應用與研究[D]. 暨南大學, 2003年.
[2] 陳金超, 謝東亮. 無線網絡TCP 擁塞控制算法研究綜述[J]. 軟件, 2015, 36(1): 82-87.
[3] 李峰, 陳向益. TCP\IP協議分析與應用編程. 人民郵電出版社, 2006.8.
[4] 龐之浩. 英國新一代軍用通信衛星亮相太空. 中國航天, 2007(7)-28-31.
[5] 翁子凡, 鄧偉. 互聯網絡TCP 單向時延被動測量方案[J]. 軟件, 2015, 36(1): 47-50.
[6] 岳鋼, 王楠. 網絡學習中知識可視化效率研究[J]. 軟件, 2015, 36(2): 92-96.
[7] 王梓斌. 線性非再生雙向中繼協同無線通信關鍵技術研究. 國防科學技術大學, 2012.
[8] 曹龍江, 張勖, 王錕, 等. 網絡應用流量模擬技術[J]. 軟件, 2015, 36(2): 14-19.
[9] 劉皓. 分布式環境下可靠數據同步及通訊的協議分析[J].軟件, 2015, 36(9): 113-116.
[10] 王歡. 分布式移動性管理協議研究[J]. 軟件, 2015, 36(2): 80-85.
[11] 王云. 《軟件測試》課程教學探索與思考[J]. 軟件, 2015, 36(7): 129-131.
