Spark平臺中Kafka偏移量的讀取管理與設計
2019-10-08 08:34:58高宗寶劉麗美張家銘宋國興
軟件 2019年7期
高宗寶 劉麗美 張家銘 宋國興


摘? 要: 隨著移動互聯網技術的大規模發展,創新型互聯網公司和迭代型各行各業應用產品層出不窮,門戶訪問、好友互動等操作產生的大規模日志記錄,對大數據處理的實時性、準確性和高可用性發起了挑戰。Kafka是一種高吞吐量分布式發布訂閱消息系統,其在高并發數據讀寫方面優勢明顯,但其提供的數據消費方式存在數據丟失和重復的風險。本文首先介紹Kafka架構及其Offset管理,介紹了新型流式數據處理框架SparkStreaming與Kafka的結合,并說明了Kafka數據消費方面存在的缺陷,最后提出了一種基于SparkStreaming讀取Kafka的近似Exactly Once方案實現。通過搭建實驗環境進行對比測試,驗證了該設計可以在保證數據讀取效率的前提下確保數據的準確性。
關鍵詞: Kafka;Offset;SparkStreaming;數據準確性
中圖分類號: TP302? ? 文獻標識碼: A? ? DOI:10.3969/j.issn.1003-6970.2019.07.022
【Abstract】: With the large-scale development of mobile Internet technology, the application products of various industries emerge in an endless stream. The large-scale log records generated by portal access, friend interaction and other operations challenge the real-time, accuracy and high availability of large data processing. Kafka is a high throughput distributed publish-subscribe messaging system, which has obvious advantages in high concurrent data reading and writing, but its data consumption mode has the risk of data loss and duplication. Firstly, this paper introduces Kafka architecture and its Offset management, introduces the combination of SparkStreaming and Kafka, a new streaming data processing framework, and illustrates the shortcomings of Kafka data consumption. Finally, an approximate Exactly One scheme based on SparkStreaming to read Kafka is proposed. By building an experimental environment for comparative testing, it is verified that the design can ensure the accuracy of data on the premise of ensuring the efficiency of data reading.
【Key words】: Kafka; Offset; SparkStreaming; Data accuracy
0? 引言
隨著IT和移動互聯網技術的飛速發展,互聯網[1]軟件產品迭代開發、層出不窮,數據量激增,如何存儲和及時處理這些海量數據,挖掘其中企業比較感興趣的價值信息(如用戶喜好等)進而提供更好的產品服務(如好友推薦、產品推廣等)是數據導向型公司迫切需要解決的問題。門戶網站訪問、好友聊天、支付交易記錄等用戶操作產生的大規模日志記錄,對大數據處理的實時性和高并發性發起了挑戰。傳統的數據存儲介質,如關系型數據庫、文件系統等無法滿足數據實時讀寫傳輸和流處理,Apache Kafka應運而生。Kafka是由Apache軟件基金會開發的一個開源流處理平臺[2],是主要用Scala編寫的一種高吞吐量分布式發布訂閱消息系統,因其擴展性好、高吞吐量、快速持久化、高可用性等優點被各大消息系統、日志分析平臺、流數據處理平臺、門戶網站等廣泛使用。
1? Kafka簡介
1.1? Kafka架構
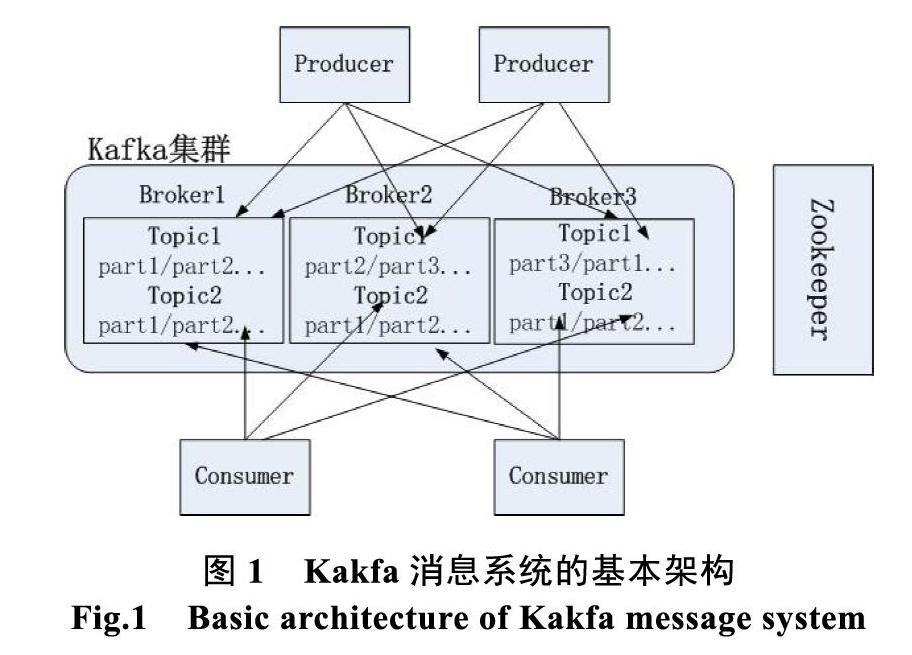
Kafka消息系統的基本架構如圖1所示。其架構主要包括以下幾個組件:
(1)Message:消息,通信基本單位。
(2)Broker:Kafka節點實例,對應為Kafka集群的一臺機器。
(3)Topic:主題,表示Kafka數據處理的消息源,數據的讀寫都要指定主題。
(4)Producer:數據生產者,向某個Topic發布消息的對象,即一種push操作,將消息推送給代理對象Broker進行存儲。
(5)Consumer:數據消費者,訂閱某個Topic并處理消息的對象,即一種pull操作,主動拉去數據,Consumer自己控制消息的讀取速度和數量,如果Topic中沒有數據,那么會周期性的pull操作直到有數據產生。
(6)Partition:分區,一個Topic可以有多個partition,一個消息實際存儲在Topic的某個Partition中,每個Parition可以保證消息的有序性。
(7)Replications:分區副本,每個分區都可以設定副本數目分布到不同的Broker中以便于容錯。
(8)ConsumerGroup:消費者組,一組consumer的集合,group訂閱的某個topic下的每個分區只能被其中的一個consumer消費,不會出現一個分區的數據被同一個group下的多個consumer消費的情況,可以理解為ConsumerGroup是Kafka提供的可擴展且具有容錯性的消費者機制,在開發過程中使用group.id來標識。
Kafka集群中的所有節點都是平等的,不采用Master-Slave結構,這樣就不會出現類似HDFS的單點故障問題。Kafka利用zookeeper來解決分布式一致性問題,將broker節點、topic元數據信息等全部存儲到zookeeper中。
為了保證較高的讀寫效率,對于每個partition,消息讀寫都有一個固定的副本完成,即Leader節點,其他的副本是Follower節點。Follower節點會定期同步Leader節點的數據。
當使用工具kafka-topics.sh創建topic后,kafka會根據選舉策略對每個partition都選出一個Leader節點和相應數量的Follower節點(通過參數replication- factor控制副本數量)。圖2描述的是創建主題t1,分區數量為4,副本數量為3的情況。
以partition=1為例,其讀寫節點是437(broker.id),副本節點分別是437、441、436,副本同步隊列分別是436、440、441。ISR(in-sync replica,副本同步隊列)是由Leader維護的與主節點數據同步的一個節點集合,當producer發送消息到leader后,follower會同步消息,如果某個follower沒有同步
leader的消息太多或者失效,那么leader會將其從ISR中剔除。
當leader失效后,kafka會從ISR中的副本中選舉出新的leader以保證服務的可用。
1.2? 讀寫offset管理
Topic可以簡單理解為一個queue,消息的生產與消費都要聲明消息所在的queue。為了提高數據讀寫效率和數據吞吐量,在物理上Topic被分成了多個partition,每個partition表示一個文件夾,命名為“topic名-分區號”,每個文件夾中保存消息數據、消息索引等。
任何發布到partition的消息都會被append到文件尾部,每條消息在文件中的存儲位置稱之為偏移量(offset,long型整數),通過partition+offset可以唯一標識一條消息。因為是追加操作,所以在partition中消息是有序寫入磁盤的,其寫入和索引讀取效率都很高。圖3表明了一個分區數量為3的topic消息寫入狀態。
當消息寫入時,kafka會按照默認規則規定消息會被寫入到哪個partition中。如果自定義規則合理,那么可以保證消息被均勻地分布到broker中。
可以看出,消息的消費,核心是對partition和offset的管理。Kafka由ConsumerGroup控制消息的消費和偏移量,而不是交給Broker去存儲,甚至可以加以控制回到一個之前的偏移位置再次消費消息。
Kafka提供了自動和手動2種偏移量管理方式[4,5]。
Kafka默認會定期自動提交偏移信息,即enable. auto.commit=true。在kafka0.10版本之前,offset信息提交到zk中保存,但由于zk不適合大批量數據的并行讀寫操作,自kafka0.10版本,offset信息自動提交到名為__consumer_offsets的topic存儲。該topic默認有50個分區,保存了每個ConsumerGroup消費的Topic所有partition的offset信息,如圖4所示。
當然也可以采用手動更新的方法提交offset。
在消息消費過程中,Kafka提供了如下3種可能的傳輸保障(consumer delivery guarantee)。
(1)At most once:這種模式下,消息可能會丟,但是絕對不會重復消費。如果consumer設定autocommit偏移量,consumer在讀取到數據后立即更新offset后未來得及處理消息(如consumer系統崩潰),下次重新工作時無法讀取之前未處理的消息,導致數據丟失。
(2)At least once:這種模式下,數據不會丟失,但是可能會存在重復消費。consumer在讀取到數據后立即處理,處理完成后沒來得及提交偏移量。下次重新工作時還會重新讀取已處理但是沒有提交偏移量的數據,導致數據重復。
(3)Exactly once:這種模式下,數據既不會丟失也不會重復消費,需要協調消費數據和offset進行精確事務管理,如將數據和offset信息寫入到HDFS等外部介質中,這種模式對處理效率有一定影響。
2? SparkStreaming簡介
SparkStreaming是基于spark的流式批處理引擎,可以實現高吞吐量的、具備容錯機制的實時流數據的處理,能夠與RDD算子、機器學習、SparkSQL以及圖形圖像處理框架無縫連接[3-6]。類似于Apache Storm,用于流式數據的處理。SparkStreaming支持多種數據源,如Flume、Kafka、HDFS、套接字等,經過一系列RDD算子或windows等高級函數進? 行處理后,將結果寫入到文件系統、數據庫等輸出源中。
SparkStreaming接收實時數據流,并以某一時間間隔(batchDuration)劃分為一個個數據批次(batch)交給Spark Engine處理。SparkStreaming的數據處理流程如圖5所示。
Dstream是SparkStreaming中特有的數據類型,表示一系列連續的RDD集合,即數據批次集合,存儲方式是Map
SparkStreaming+Kafka進行流數據處理被廣泛采用,本文后續討論基于spark2.3+kafka0.10展開。
3? 一種可靠的Kafka消費方案
3.1? 方案設計
SparkStreaming通過KafkaUtils.createDirectStream創建數據流Dstream,默認情況下enable.auto.commit= true自動提交offset,即對應At most once模式。并且無論StreamingContext是否安全終止,都會出現在一段時間后已消費offset值等于最新offset值,盡管此時數據還遠沒有消費完數據。具體見方案測試。
設置enable.auto.commit=false可以手動提交offset更新,如Spark中可通過stream.asInstance-Of[CanCommitOffsets].commitAsync (offsetRanges)來進行數據處理完后手動提交更新。需要注意的是,此方法將offsetRanges保存在一個隊列中,只有等consumer獲取下一批次數據后才提交offsetRanges。方案測試中通過5次實驗對比進行驗證。具體見方案測試。
在很多設計方案中將offset更新到zk中存儲。然而zk并不適合大規模數據并發讀寫,尤其是寫效率不高。Kafka允許多個ConsumerGroup并行讀寫數據,如果offset全部在zk中管理會影響zk性能,進而影響kafka的leader選舉、集群同步等功能。
因此,綜合考慮kafka集群性能和數據讀寫效率,本文設計實現了一種At least Once方案SEO (Similar Exactly Once),每個ConsumerGroup在本地系統中維護offset信息,KafkaCluster提供維護信息,在不影響讀取效率的情況下趨向于Exactly Once保障。
SEO方案實現的假設條件是zk不可靠或存在延遲,實現目的是數據不可丟失,極端情況下允許數據重復。方案的一些專有名詞包括:
客戶端:運行SparkStreaming程序所在的機器;
gtoffset文件:客戶端存儲的偏移量文件,文件存儲路徑類似于...groupid/topicname/gtoffset,文件包括groupid消費topicname所有分區的offset信息。
偏移量越界:包括低越界、高越界。低越界指的是gtoffset記錄的偏移量信息小于Kafka目前可用的offset最小值,高越界指的是gtoffset記錄的偏移量信息超過Kafka目前最新的offset值。
方案的實現思路如下。
(1)在客戶端是否存在gtoffset文件,若不存在,說明groupid是第一次消費Topic,那么按照auto.offset.reset=earliest從當前可用的最小offset讀取數據;如果存在,說明groupid已經消費過Topic,讀取得到offset集合A。
(2)使用spark-streaming-kafka-0-8中的Kafka?Cluster構建Kafka集群連接,進行偏移量越界判斷。使用getEarliestLeaderOffsets得到Topic的最小可用offset集合M,使用getLatestLeaderOffsets得到Topic的最大可用offset集合N。
(3)如果A中所有分區的offset都滿足offset_ (M,par)≤offset_(A,par)≤offset_(N,par)那么說明A有效,A不需要更新;如果A中存在分區的offset滿足offset_(M,par)≥offset_(A,par),即A中有的分區offset比最小值都小,低越界,那么更新這些offset為M中對應分區的offset;同樣道理,如果A中存在分區的offset滿足offset_(A,par)≥offset_(N,par),即A中有的分區offset比最大值都大,高越界,那么更新這些offset為N重對應分區的offset。
(4)解決偏移量越界后,使用更新后A集合拉取Kafka中的數據進行處理,處理成功后將最新offset信息寫入到gtoffset文件中。因為offset更新到本地文件,無需與zk、kafka等建立外部連接,可以保證更新效率,程序異常也可控制,所以該方案可以類似實現Exactly once傳輸保障。
3.2? 方案測試
本次測試共包括3次試驗,3次實驗環境完成相同,軟硬件環境如下。
第一次實驗為enable.auto.commit=true,此時存在數據丟失情況,且出現offset更新為最大值的bug。實驗過程是:topic=test1共4個分區,寫入100006條記錄,設定程序時間間隔為2 s,每秒每分區最大讀取50條記錄,過10 s時間后停止spark程序,此時數據沒有處理完,但是已消費offset(CURRENT-OFFSET)已達到最大值(LOG-END- OFFSET),具體結果見圖6。再次啟動程序后沒有數據可讀,數據丟失。經過10次修改時間間隔和處理數據條數,都復現同樣的問題。
第二次實驗為通過CanCommitOffsets手動提交偏移量,共包括5次驗證。實驗過程是:topic=test2共4個分區,寫入100000條記錄,測試5次,每次修改批次間隔和每分區每秒最大讀取消息數,每次在消費過程中終止spark程序一次,然后重啟程序直到消費完數據。得到的實驗結果如表1。
通過實驗結果發現每次均存在重復消費,重復消費的數量等于分區數、間隔時間、每分區每秒最大消息數三者的乘積(假設在消費過程中只有一次終止)。
第三次實驗為通過SEO方案手動提交偏移量,共包括5次驗證。實驗過程是:topic=test3共4個分區,寫入100000條記錄,測試5次,每次修改批次間隔和每分區每秒最大讀取消息數,每次在消費過程中通過ssc.stop(true, true)安全終止spark流程序一次,然后重啟程序直到消費完數據。得到的實驗結果如表2。
通過實驗結果發現每次均不存在重復消費也不存在數據丟失,整個實現過程中沒有頻繁與第三方數據源進行交互,達到了數據不丟失的目的,近似實現了Exactly Once模式。當然,在極端情況下,如果某個批次數據已經處理結束(如導入到數據庫中)后,即使安全終止spark任務也未能更新本地gtoffset文件,此時重啟spark任務會出現數據重復消費的問題。
4? 結束語
互聯網飛速發展,數據質量和數據價值最大化是每個互聯網企業和傳統企業都需要考慮的問題,數據存儲與計算的并發性、實時性導致的產品性能優劣直接影響了用戶的體驗。本文首先介紹新型流式數據處理框架SparkStreaming與Kafka的數據消費結合,提出了一種基于SparkStreaming讀取Kafka的近似Exactly Once方案實現并搭建集群環境繼續數據準確性驗證。
參考文獻
[1] 趙旭劍, 鄧思遠, 李波, 等. 互聯網新聞話題特征選擇與構建[J]. 軟件, 2015, 36(7): 17-20.
[2] Wang J, Wang W, Chen R. Distributed Data Streams Processing Based on Flume/Kafka/Spark[C]//International Conference on Mechatronics and Industrial Informatics. 2015.
[3] Ichinose A, Takefusa A, Nakada H, et al. A study of a video analysis framework using Kafka and spark streaming[C]// IEEE International Conference on Big Data. IEEE, 2017: 2396-2401.
[4] 王巖, 王純. 一種基于Kafka的可靠的Consumer的設計方案[J]. 軟件, 2016, 37(1): 61-66.
[5] 王鄭合, 王鋒, 鄧輝, 等. 一種優化的Kafka消費者/客戶端負載均衡算法[J]. 計算機應用研究, 2017, 34(8): 2306-2309.
[6] 鄭健, 馮瑞. 基于Spark的實時視頻分析系統[J]. 計算機系統應用, 2017, (12). doi:10.15888/j.cnki.csa.006112.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
心理學報(2022年4期)2022-04-12 07:38:02
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
水泵技術(2021年3期)2021-08-14 02:09:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
當代化工研究(2016年9期)2016-03-20 16:22:13
西華師范大學學報(自然科學版)(2015年3期)2015-02-27 15:31:22
測繪科學與工程(2013年3期)2013-03-11 15:07:36
