鐵路智能客服關鍵技術研究
2019-09-19 11:07:56張志強汪健雄
鐵路計算機應用 2019年9期
張志強,汪健雄,靳 超
(中國鐵道科學研究院集團有限公司 電子計算技術研究所,北京 100081)
新一代客票系統承擔了鐵路12306互聯網售票、窗口售票、自動售取票、電話訂票等多種渠道售票業務,目前,高峰日發售全國鐵路客票超1 200萬張,尤其是互聯網/手機APP渠道占售票總量的比例最高約75%,已經成為廣大人民群眾鐵路出行購票的主要渠道。由于售票量劇增,鐵路客運業務規則復雜,鐵路客票系統規模不斷擴張,導致12306互聯網售票系統(簡稱:12306系統)網絡客服的需求量與日俱增,給鐵路客服人員增加了大量的工作。由于人工客服存在維護成本高、服務時間受限、培訓成本高、線路忙、人為錯誤不利于控制等問題,急需采用技術手段解決人工客服存在的問題。
中國鐵路近年來為提升客運服務質量,不斷引入智能技術,持續開展智能客服語音平臺研究和建設。智能客服的發展是隨著人工智能及計算機硬件、軟件、網絡技術不斷發展而逐步推進的,隨著智能客服機器人在各個領域的成功應用,其價值已逐漸被社會所認可。在經歷了基于歷史、上下文理解概念、句子基于知識推理的簡單自然語言處理和搭建模型讓機器學習推理等階段,利用深度學習搭建神經網絡解決困擾著人們的模型學習復雜、模型維護復雜的問題,還為語言交互、圖像識別、人臉識別等領域帶來了全新的突破。鐵路智能客服基于語義理解和語言處理技術,利用深度學習和多場景交互技術,形成用戶畫像,使其具備快速反饋及精準推送能力,與人工座席協同工作。本文對鐵路智能客服的關鍵技術進行探究,提出鐵路智能客服總體框架,構建多渠道智能客服,為鐵路12306系統智能客服提供有力支撐。
1 鐵路智能客服設計
1.1 總體架構
總體架構設計是在保證安全的前提下引入“互聯網+”,構建統一接入、統一轉辦、統一輸出、統一監督、統一考核的智能客服體系,如圖1所示。
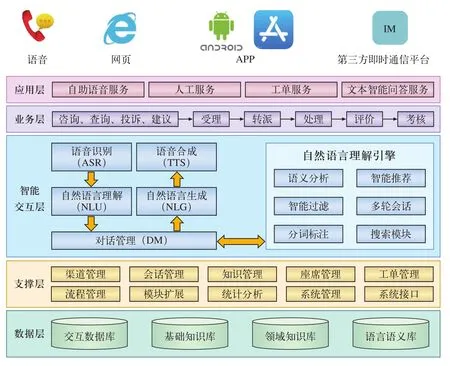
圖1 鐵路智能客服總體架構圖
(1)多媒體受理
支持熱線電話、Web端、移動終端、第三方即時通信平臺等多渠道的統一接入。
(2)業務層
包括咨詢、查詢、投訴、建議的受理、轉派、處理、評價和考核。
(3)應用層
采用自助語音、文本智能問答、人工、轉工單等方式對外提供服務。
(4)智能交互層
包括語音合成、語音識別,以及自然語言理解引擎等。
(5)支撐層
為前臺應用提供支撐,包括渠道管理、會話管理、座席管理、工單管理、知識管理、流程管理、統計分析、系統管理、系統接口等模塊。
(6)數據層
包括基礎知識庫、領域知識庫、交互數據庫以及語言語義庫,文本數據庫可以通過轉換形成語音庫,是語音輸出的基礎。
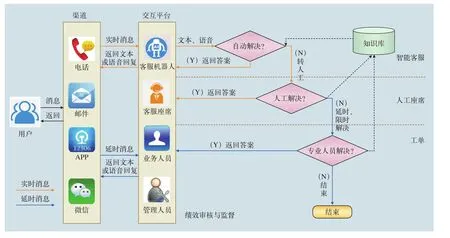
圖2 業務處理流程圖
1.2 業務流程
用戶通過各種接入渠道輸入語音或者文本信息,通過交互平臺以語音導航、人工客服、智能問答等方式進行接待,根據咨詢的業務分類(咨詢、查詢、投訴、建議)轉接到相關業務知識庫、相關業務部門人工座席等,根據具體情況,以語音、智能問答的方式進行實時回復,以工單的方式進行延時回復。具體流程設計如圖2所示。用戶可以通過鐵路12306系統客服電話、12306系統APP語音交互或者其他語音輸入模塊向智能終端表達自己的需求,包括咨詢或者辦理各種業務,鐵路智能客服通過語音識別和語義理解后,與后臺的知識庫進行對接,獲取用戶的關注信息后反饋給用戶。這樣的交互過程貼合用戶的使用習慣,方便快捷,可有效提升客服的準確性和效率。
1.3 主要功能
(1)自然語言處理
通過實時捕獲座席和用戶對話,通過語音識別和語義去理解通話,具備處理自然語言中廣泛存在的各種各樣歧義性或多義性的能力,構建座席的人工智能(AI)助理,協同作業,提高效率。
(2)知識庫管理
存儲、組織、管理各種互相聯系的知識片集合,包含覆蓋程度較為全面的常用業務詞匯和常用鏈接。
(3)最佳答案推薦
回答用戶提出的問題時,采用場景式多輪會話交互模式,基于歷史、上下文理解概念和句子,基于知識推理增強泛化能力,最終提供最優答案。
(4)在線留言與轉接
當在線客服提供的結果無法解答用戶問題時,允許用戶在線留言或轉接人工客服,解答用戶問題。
(5)評估分析
將用戶多種信息內容結構化,打上各類標簽,并進行深入的挖掘分析,形成用戶畫像進行評估判斷,可自動為每個用戶的服務與政策制定等提供數據與決策支持。
2 智能客服關鍵技術
2.1 語義理解與語言處理
語義理解類似于人類閱讀理解,當語言符號出現時,人類喚起大腦中語言符號所代表的含義,以此含義為代表去理解語言符號所代表的客觀事物。通常為了降低語義理解實現難度,可通過人工構造數據集、應答所需要的單詞、意境以及相應的問題回答,常見的任務形式包括人工合成問答、Cloze-style queries和選擇題等方式[1]。
通過對鐵路12306系統客服語料(含網站、APP、語音渠道)進行標注和分析,總結客服交互式語句的特點及對話特點,并采用深度學習技術進行12306系統客服領域的實體識別,提出針對12306系統客服環境的語義理解方案,解決旅客屬性混雜、口音眾多、口語表達不符合規范的語法導致的模糊性和二義性問題
2.1.1 語義三角模型與語義網
語義三角關系定義了概念以及概念和概念之間的關系。這種定義使人與人之間、人與計算機之間能基于共享的概念進行語言交流,讓機器通過理解人的認知模型,建立機器理解人類自然語言的框架模型,如圖3所示。
通過語義三角模型將事物根據屬性劃分歸類成語義網。語義網又稱本體,語義詞典,是共享概念模型的明確的形式化規范說明。語義網定義了概念,以及概念和概念之間的關系,這種定義使得人和人之間,人和計算機之間能基于共享的概念進行語言交流。語義網由類(class)或概念(concepts)、關系(relations)、函數(functions)、公理(axioms)、實例(instances)組成。
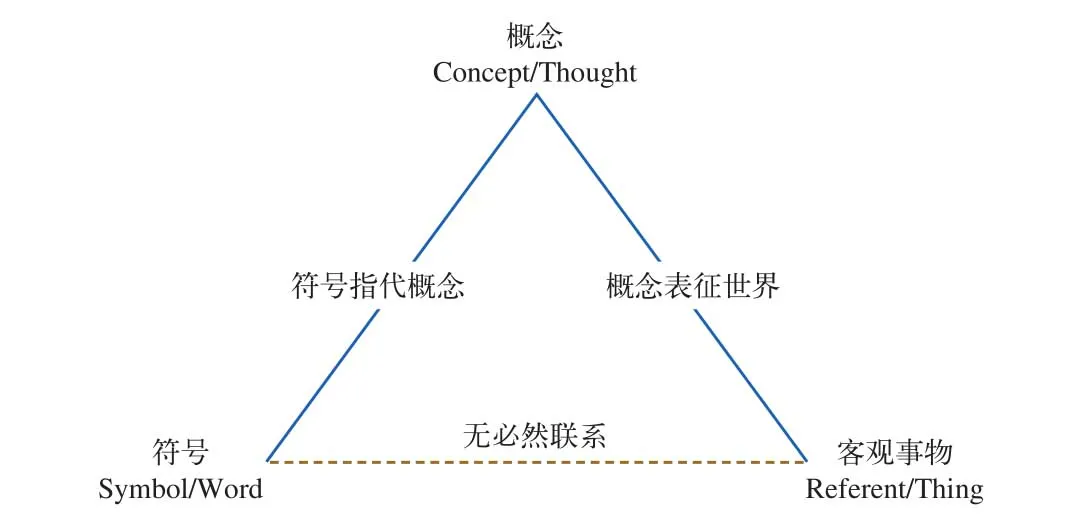
圖3 三角模型
語義網分為領域語義網和通用語義網,用于分層分領域建模。通用語義網由來自互聯網積累的、商用多年以上被業界所共識的物體概念與狀態及其間的關系組成;領域語義網由各領域在生產中積累、加載的信息構成。鐵路12306系統領域類關系展示如圖4所示。

圖4 鐵路12306系統語義網分類關系示例
2.1.2 智能語音交互
為使得智能客服像真人一樣有聽說能力,需要綜合語音合成、語音識別等智能技術[2]。語音識別技術是讓機器通過識別和理解過程將語音信號轉變為相應的文本或命令,目的是將人類語音中的詞匯內容轉換為計算機可識讀的輸入,并可以識別語音內容、說話者、語種等信息,用于識別不同客戶語音所蘊含的語義。語音合成可以將輸入的文字信息轉化為自然流暢的語音,替代人工為客戶提供標準化的語音應答。鐵路人工客服采用智能語音交互服務,實現客戶語音的“可視化”,完成客戶咨詢問題詞條及關鍵字的識別,輔助座席人員快速進行相關知識庫、知識節點的搜索匹配,提高客戶座席人員的工作效率和服務能力。
2.1.3知識搜索排序
知識搜索是增強智能客服響應問題的即時性和準確性的關鍵技術。采用“語義相似度”和“業務相似度”相結合的評分排序算法,滿足客戶對搜索排序的個性化要求,具體步驟如下:
(1)根據搜索內容和知識本身的語義關系得到兩者的相似度,通過相似度排序得到智能搜索的雛形;
(2)根據知識搜索的點擊率、熱點知識得到問題和知識之間相關度的指數,有效區別排序權重;
(3)劃分知識等級時,與銷售業務相關的權重比管理類知識劃分的權重更高;(4)將過期知識的權重降低,提高知識有效性;(5)對個別知識的搜索權重可以通過規則來配置設定。
2.1.4 語音情感識別
在鐵路智能客服中引入語音情感識別,可根據用戶情感的變化提供更人性化的服務,有效提高鐵路智能客服的服務質量,提升用戶滿意度。例如,當語音情感識別程序檢測到當前用戶存在不滿情緒時可及時轉接至人工服務。而當話務員遭遇態度惡劣的客戶時,自身情緒容易發生波動,系統可以提醒其保持冷靜。
情感識別本質上是模式識別,核心在于尋找合適的識別模型[3]。目前,主要采用模式分類方法,其中,人工神經網絡、隱馬爾可夫模型、支持向量機等方法取得了較好的效果。
2.2 深度學習
2.2.1 深度學習模型
鐵路智能客服采用深度學習模型,可分為一維匹配模型、二維匹配模型、推理模型[4],其中,一維匹配模型和二維匹配模型是基礎模型,推理模型則是在基礎模型上重點研究如何對內容進行推理。
(1)一維匹配模型
一維匹配模型的基本思路為:假設用戶問題記為Q,而某段文本中存在某個單詞Di可能是問題Q的答案的可能性記為F(Di,Q),或者理解為語義和問題Q整體語義的匹配程度,用點積表示為:

對每個單詞的匹配函數值通過歸一化指數函數進行歸一化,該過程被稱作為注意力(Attention)操作,用于增強單詞是該問題答案的可能性。對于整個文本中某單詞多次出現的情況,其注意力操作結果不同,即該單詞在上下文中對應答案的概率,最后將同一單詞的注意力概率值累加作為該單詞是問題Q答案的可能性,問題答案則被認為是可能性值最大的單詞。多數主流模型基本都采用一維匹配模型結構,主要區別主要是匹配函數的定義不同[5]。
(2)二維匹配模型
二維匹配模型與一維匹配模型不同的是:其采用問題表示法進行問題表達。相較于一維匹配模型將問題的語義表達為一個整體,二維匹配模型文本中的每個單詞都采用獨立的單詞表達(Word Embedding)向量表示。由于Word Embedding向量是每個單詞及其上下文語義的二維結構,引入了更多細節信息,整體而言,二維匹配模型效果優于一維匹配模型。
(3)推理模型
自然語言推理是判斷兩個句子(Premise,Hypothesis)或者兩個詞之間的語義關系。自然語言文本不能明確地定義并表達符號之間的邏輯關系,所以,自然語言表達有相當大的模糊性,推理過程的實現難度較大。目前,主流的推理模型有AMRNN[6]、GA Reader[7]和 IA Reader[8]。
推理過程更適用于有一定難度的問題,通常對于簡單問題沒有明顯作用。其推理作用效果與數據集難度相關聯,以常見的通用推理 數據集為例,Google采用的新聞語料庫CNN數據集整體偏容易,因此無需復雜的推理步驟也能得到正確回答,而在Facebook采用的新聞語料庫CBT數據集上,有推理過程的評價指標比無推理過程評價指標提高了2.5%~5%[9]。
2.2.2 自動巡檢機制
(1)通過網頁爬蟲、文檔錄入等數據預處理手段進行碎片化加工后,形成專業領域的知識庫,對過期知識進行下架或刪除處理;
(2)自動對未識別的問題集進行非結構化分析,形成主題類別和優化建議,便于采編人員對重點問題進行優化。
2.2.3 自我調整
自我調整是采用場景式多輪會話交互模式支持圖形化配置對話的流程,采用寒暄等場景對用戶進行甄別,從而不斷調整機器的對話方式,實現對用戶的逐步引導。
2.3 精準營銷
2.3.1 用戶畫像
通過與用戶的交流可以收集到用戶的基本信息,智能客服對這些信息進行建模,抽象出用戶的標簽,形成用戶畫像[10]。
(1)數據收集
主要收集網絡行為數據、用戶偏好數據、用戶交易數據等。
(2)建模
行為建模是對收集到的數據進行處理,該階段注重的是大概率事件,通過算法模型盡可能排除用戶的偶然行為。
(3)成型
畫像成型是行為建模的深入,對收集數據進行處理后對用戶進行標簽化,根據用戶的基本屬性(例如年齡、性別、地域等)、心理特征、興趣愛好等方面細化分類。用戶畫像無法100%準確描述一個人,只能盡可能準確。因此,需要不斷收集數據、根據變化的基本數據不斷修正,才能使得用戶畫像越來越立體、越來越真實。
2.3.2 營銷推送
當用戶畫像成型后,使用大數據可視化分析,針對某個標簽或是某個群體,細化出不同類別的用戶,評估用戶的趨勢行為及價值空間,對接業務接口,推送最新資訊或公告,做出針對性的營銷[11]。
3 結束語
基于鐵路智能客服關鍵技術的12306系統客服平臺已經在中國鐵路上海局集團有限公司試運行,取得了良好效果,為鐵路企業與海量用戶之間建立了基于自然語言、快捷有效溝通的技術渠道,同時,為鐵路企業提供了細粒度知識管理技術和精細化管理所需的統計分析信息,有效解決了傳統人工服務維護成本高、服務時間受限、培訓成本高、線路忙等諸多問題,減少了人為錯誤,規范了服務標準,達到了精準營銷和服務整合的目的,提高了鐵路12306系統客服接通率和滿意度,提升了鐵路用戶體驗,樹立了鐵路良好社會形象。隨著科技進步持續升級,將構建多渠道全方位智能客服,為鐵路客服和出行旅客提供更便捷、更友好、更準確的全流程解決方案。
猜你喜歡
云南畫報(2021年12期)2021-03-08 00:50:54
開放教育研究(2020年2期)2020-03-31 01:54:14
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
鐵道通信信號(2018年7期)2018-08-29 01:17:04
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
現代語文(2016年21期)2016-05-25 13:13:44
通信電源技術(2016年4期)2016-04-04 02:58:04
工程建設與設計(2016年3期)2016-02-27 10:50:46
大連民族大學學報(2015年2期)2015-02-27 08:28:11
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
