動態社會網絡數據發布隱私保護方法*
2019-09-14 07:12:50董祥祥畢曉迪
計算機與生活 2019年9期
董祥祥,高 昂,梁 英,畢曉迪
1.中國科學院 計算技術研究所,北京 100190
2.中國科學院大學,北京 100190
3.移動計算與新型終端北京市重點實驗室,北京 100190
1 引言
“社會網絡”是指社會個體成員之間因為互動而形成的相對穩定的關系體系,已成為人們溝通交流、獲取信息和展示自我的重要途徑之一。近年來,隨著社會網絡的發展,數據泄露事件頻發,同時大數據挖掘技術的廣泛應用,造成社會網絡公開發布的數據和泄露的數據進一步暴露隱私,用戶隱私面臨威脅。表1 展示了2018 年十大數據泄露事件,其中涉及了使用范圍較廣泛的國內外社交網站與社交應用。由于這些線上社交網絡存儲了大量的用戶注冊與使用信息,具有隱私性,故成為時下數據泄露的重災區。
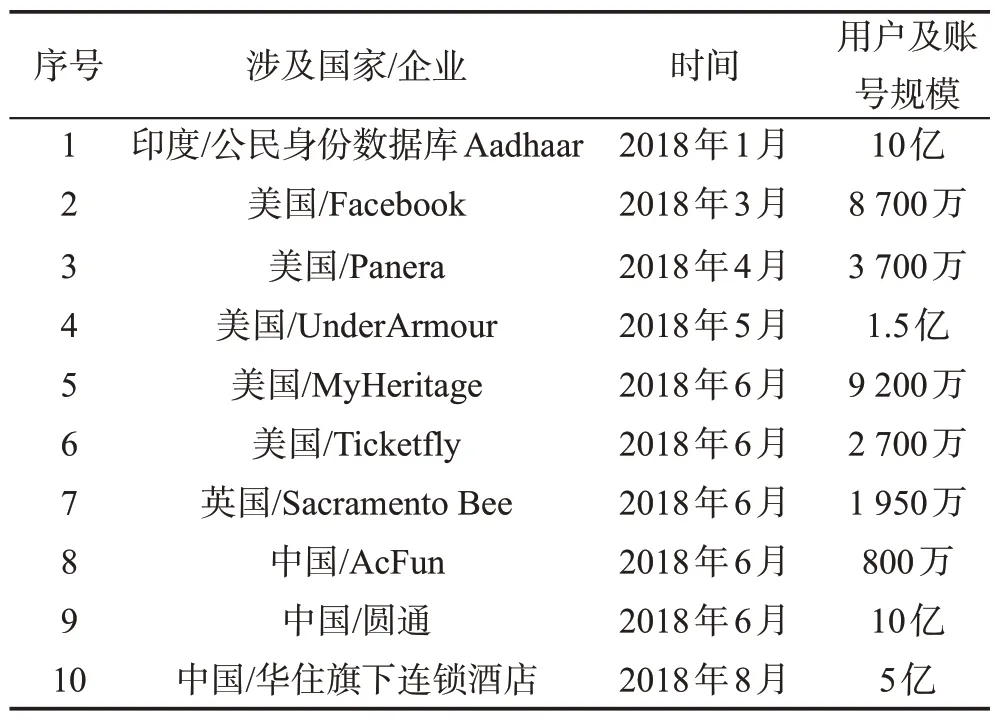
Table 1 10 biggest data breaches of 2018表1 2018年度十大數據泄露事件
據第27 次至39 次《中國互聯網絡發展狀況統計報告》顯示(如圖1 所示),2011 年1 月至2017 年1 月微博用戶量呈現緩慢波動的趨勢。這意味著隨著用戶加入和退出社交應用,社會網絡中的節點也存在增加和減少的變化,并且節點間會建立或去除連接關系。
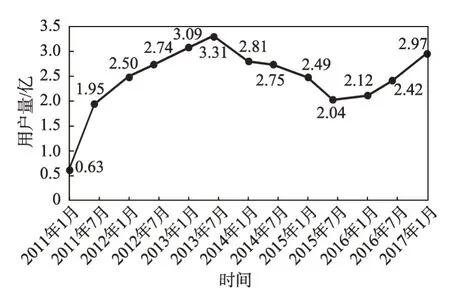
Fig.1 Sina Weibo user statistics圖1 新浪微博用戶量統計
Viswanath 等人[1]以Facebook 為例進行分析,得出社會網絡是具有動態性的,相應的匿名方法也適應隨時間變化的性質,具有動態性。社會網絡中的數據無時無刻不在進行更新迭代,社會網絡的動態性也決定了靜態隱私保護方法不能保證動態社會網絡的隱私安全[2]。攻擊者可以將前后發布版本進行關聯分析,可能得到個體的敏感信息,從而會導致社會網絡的數據泄露[3]。因此,開展動態社會網絡隱私保護方法研究,滿足用戶的個性化隱私保護需求,同時確保數據的可用性變得非常重要。
社會網絡中的隱私信息包括節點、邊和圖的隱私,這些隱私信息一旦被攻擊者獲取并進行攻擊與挖掘,將會威脅用戶自身及其好友的隱私。針對社會網絡數據發布的隱私泄露,隱私保護方法可分為靜態方法和動態方法。靜態方法指社會網絡數據單實例發布,即將社會網絡的每次更新視作一個新的網絡,在新的網絡發布時對數據進行匿名處理,隱藏敏感信息,并在發布后不再更改這些數據。而動態方法在新數據發布與匿名時,會涉及已發布的數據,再次對已發布的數據進行處理。
目前社會網絡數據發布隱私保護方法多為靜態的方法。在節點屬性隱私保護研究方面,主要包括傳統方法和關注實用價值的方法。如使用原始K-匿名、L-多樣性和T-近鄰對社交網絡用戶屬性進行屬性匿名[4],通過在圖中增加噪音節點保護用戶隱私,將相似的節點聚類成超節點[5]等。除上述傳統的匿名方法,將隱私保護結合其實用價值考慮也受到廣泛關注。針對實際問題,Sei等人[6]提出敏感準標識符屬性的概念,采用改進的L-多樣性和T-近鄰的方法可以有效地對敏感準標識符屬性進行匿名。Hartung等人[7]改進了NP-Hard問題——K度匿名,用動態規劃和啟發式方法進行求解,可以高效地應對大規模社會網絡的匿名問題,但對數據隨機性不敏感。付艷艷等人[8]將社會網絡中節點的屬性分為敏感屬性和非敏感屬性,以節點分割的方式保護用戶的敏感屬性,但其有效性很大程度上依賴于匿名區域內屬性是否相關。劉向宇等人[9]提出了一種保持節點可達性的高效社會網絡圖匿名方法,避免可達性信息損失,但在某種程度上會降低距離查詢的精度。節點屬性包含了用戶的基本隱私信息,上述隱私保護方法在保護節點屬性的同時,雖然涉及了圖結構數據的可用性,但是對于邊的保護不足,存在邊信息泄露的風險。在關系和邊的隱私保護研究方面,最基礎的圖結構隱私保護方法是隨機圖編輯,即在圖中進行隨機修改或交換邊的操作。Hay 等人[10]針對節點再識別和邊屬性攻擊提出了最簡單的社會網絡匿名方法,僅僅從圖中去掉n條邊再隨機增加n條邊,形成新的社會網絡圖,但是隱私保護強度很低。Li等人[11]使用概率方法對圖數據進行隨機更改,提出了兩種方法,分別為隨機稀疏化和隨機擾動化,但該方法僅以概率來衡量隱私保護,無法應對有背景知識的攻擊。Liu等人[12]將社會網絡中邊的權重作為隱私保護的對象,在保障圖中最短路徑序列以及每對節點間的最短距離的同時,通過對邊的權重增加高斯噪音進行擾動。Rong等人[13]把K-匿名思想應用到圖結構隱私保護中,提出一種K+-同構方法對圖數據進行修改,在子圖中達到K-匿名狀態。
現有動態社會網絡隱私保護方法可分為傳統的靜態社會網絡隱私保護移植方法、鏈路預測方法和增量式抽象方法。Cheng 等人[14]針對節點信息和連接信息攻擊,提出K-同構的概念,將節點的標識符進行泛化后發布于社會網絡中,可以有效地對節點信息進行保護,但數據的可用性和匿名的質量依賴于同構子圖的劃分,魯棒性比較低。谷勇浩等人[15]提出基于聚類的動態圖發布隱私保護方法,使用隱匿率作為評價指標,可以抵御多種背景知識攻擊,對社會網絡圖結構變化具有較好的適應性,但算法復雜度較高,執行效率低。Chen等人[16]通過K分組的方法將節點被攻擊識別的概率降低為1/k,但并未在真實的社會網絡中進行實驗,實用性未知。Bhagat等人[17]采用鏈接預測的方式預測未來圖結構,從而對邊和節點進行保護,但匿名效果很大程度上依賴于鏈接預測的質量,保護效果不穩定。郭彩華等人[18]首次提出加權圖增量序列K-匿名隱私保護模型,將動態社會網絡抽象為加權圖的增量序列,提高了算法效率,但邊權重的設置方式不具有普遍性。差分隱私作為隱私保護領域的一項重要技術被應用于動態社會網絡隱私保護中,但在動態數據發布的應用中面臨隱私預算耗盡時噪音驟增的問題。Chan等人[19]通過設置一個閾值來判斷當前時刻是否需要進行隱私保護處理,但隨時間增長隱私預算會被耗盡。蘭麗輝等人[20]提出了一種基于差分隱私模型的隱私保護方法,其實質也是通過對社會網絡的結構進行擾動實現隱私保護。
綜上所述,社會網絡數據發布隱私保護研究主要針對單實例發布的靜態網絡,即數據發布后不再進行任何改變。而社會網絡是一種動態網絡,由抽象的數學模型角度來看,動態網絡可以認為是一個圖快照序列[21]。針對單實例發布的隱私保護方法實際上就是對一個時刻的圖快照進行保護,不能適應具有高度動態性的社會網絡的更新迭代過程。比如,攻擊者可以根據2次單實例匿名的社會網絡分析出社會網絡圖中節點的度信息變化,結合其背景知識進行分析,獲取用戶隱私。其次,用戶的個性化隱私保護方案較少,難以滿足數以億計的社會網絡用戶的隱私保護需求,用戶偏好設置上只考慮了用戶隱私保護程度這一單一的偏好,忽略了用戶發布的社會網絡數據可用性。
本文針對動態社會網絡數據發布隱私泄露問題,基于匿名規則研究圖數據的隱私保護方法,支持用戶個性化隱私需求,抵御數據發布的關聯攻擊。同時采集了新浪微博數據和公開數據集進行實驗,對數據安全性和可用性相關指標進行了評估。
2 定義及流程
2.1 問題提出
社會網絡是一種實時更新的、動態的網絡。數據發布更新時,可能會和已發布的數據產生數據關聯,即使在兩個時刻分別對圖數據進行了隱私保護,攻擊者也可能通過兩個時刻的社會網絡圖進行關聯攻擊,挖掘其中的隱私信息。假設使用K-匿名技術對社會網絡進行隱私保護,k值取2,同時假設同一個匿名集中的節點之間不存在連接關系。T=0,T=1時刻的社會網絡圖分別如圖2(a)中的G0、G1所示,對這兩個時刻的社會網絡進行匿名后,得到如圖2(a)中的所示的社會網絡。從圖中可以看出,匿名后的社會網絡每兩個節點被分為一組,同一組節點之間不存在連接關系。但值得注意的是,T=0時,節點(1,2)(3,5)(4,8)(6,7)分別在同一個匿名集中;而T=1 時,節點(1,2)(3,5)(4,6)(7,8)分別在同一個分組中。根據前文所述規則可以進行猜測,節點4與節點6、節點8均可以在同一分組中,但是其不能與節點7 分在同一個組,由此可以推測,節點4與節點7可能存在連接關系。
圖2(a)中的G0、G1可以得到驗證,上述猜測是正確的,即攻擊者利用關聯攻擊獲取了隱私信息。
本文算法目的在于抵御關聯攻擊所帶來的隱私泄露威脅,對圖2(a)中的G0、G1進行隱私保護,隱私保護參數設置相同的情況下,得到如圖2(b)所示的執行結果,即這兩個匿名圖中的節點分組相同,可有效抵御關聯攻擊。

Fig.2 Associated attack schema in dynamic social networks圖2 動態社會網絡中的關聯攻擊示意圖
2.2 概念定義
為方便閱讀,本文常用的符號、公式及字母用表2進行統一說明。
定義1(隱私偏好preference)隱私偏好指用戶在社會網絡中的個性化隱私保護需求,包括隱私保護強度和社會網絡數據可用性的需求,可用二元組表示。其中levels表示用戶對其隱私的保護強度需求等級,levelu表示用戶對其發布的數據在社會網絡中的數據可用性需求等級。levels=0,1,…,N-1,levelu=0,1,…,N-1,N為自然數。levels的值越大,表示隱私保護強度越高;levelu越大,表示社會網絡數據可用性越高。

Table 2 Explanation of symbols表2 符號說明
定義2(靜態社會網絡Gt)靜態社會網絡特指某一時刻t狀態下的社會網絡,是一個有向圖,可用一個二元組表示,其中:
(1)Vt是t時刻圖中所有節點(node)的集合,每個節點代表社會網絡中的一個用戶,即Vt={node},其中每個node定義為:

式中,uid表示用戶唯一id。level表示隱私偏好級別,是隱私保護強度等級levels和社會網絡數據可用性等級levelu的函數,可表示為level=f(levels,levelu),
其中f為levels與levelu映射到level的函數。time表示用戶加入社會網絡的時間。property表示用戶屬性集合,可表示為property={pi|i=1,2,…,np},其中pi代表用戶的一種屬性。
(2)Et是t時刻圖中所有邊(edge)的集合,即Et={edge},本文假設Gt中從nodesrc到nodedest的邊代表nodesrc在社會網絡中主動產生與nodedest的聯系,可表示為:

式中,nodesrc表示Gt中關系的主動產生者,nodedest表示Gt中關系的被動接收者。為了敘述方便,可以使用edgeij表示nodei到nodej的連接邊,如在新浪微博中edgeij表示nodei關注了nodej;Gt、Vt表示t時刻靜態社會網絡圖Gt中的節點,同理Gt、Vt表示t時刻靜態社會網絡圖Gt中的邊,日常生活中使用的社會網絡,在某一時刻數據達到相對穩定狀態時,均可視作一個靜態社會網絡。
定義3(動態社會網絡G)動態社會網絡是一個有向圖集合G:

其中,Gt為t時刻的靜態社會網絡,t為時間。當時間由t時刻增加至t+1 時刻時,社會網絡中可能會出現節點和邊數量的增加或減少,節點屬性的更新,因此社會網絡由當前時刻t的Gt更新為t+1 時刻的Gt+1,一系列時間范圍內的靜態社會網絡則構成了動態社會網絡。其中,動態強調了社會網絡的結構(包括節點和邊)會隨時間變化而變化。為了敘述方便,下文中將動態社會網絡簡稱為社會網絡。日常使用的社會網絡均存在數據的頻繁更新,實際上都是動態社會網絡。
G中每個時刻的靜態社會網絡中的節點屬性更新時,其隱私偏好也可以更新,故每個時刻的隱私偏好級別(node.level)可以不同,支持用戶個性化隱私需求。
定義4(匿名動態社會網絡G*)匿名動態社會網絡G*指動態社會網絡G經匿名算法處理后的,滿足某些約束條件的動態社會網絡圖。即,已知一個動態社會網絡G={G0,G1,…,Gt,…,GT},t∈[0,T],稱G*=為G的匿名動態社會網絡圖,其中G*t為t時刻Gt的匿名圖,由變換得到。
定義5(匿名規則)匿名規則是隱私保護方法在進行節點聚類時遵循的規則。包括5個規則,其中Vgj為滿足匿名規則的節點集合,稱作匿名集。
規則1(節點K-匿名規則)
?Vgi?|Vgi|≥k
規則2(屬性多樣性規則)
?Vgi?Diversity(Vgi)≥L
規則3(時間一致性規則)
?v,w∈VT,ifv∈Vgi∧w∈Vgi?
規則4(關系約束規則)
?
規則5(邊約束規則)
?Vgi,Vgj,Vgi與Vgj為兩個匿名集,m為Vgj與Vgj之間邊的數量,且滿足m≤(|Vgi|×|Vgj|)/k。
這5 個規則約束了匿名動態社會網絡圖的狀態以及匿名分組過程,其中規則1約束了匿名后的社會網絡中,每個匿名集中的節點數量不少于k個,節點識別率不超過1/k;規則2 約束了每個匿名集中的節點屬性需要滿足L多樣性,其中Diversity(Vgi)表示匿名集中節點屬性多樣性,抵御同質攻擊,其計算方法見算法1;規則3 約束了同一個匿名集中的節點都是同一時刻生成的,此規則確保逆向更新的正確性,避免在逆向更新的過程中出現節點缺失的情況;規則4約束了同一個匿名集中的節點不能存在連接邊,因為存在連接的兩個節點必然存在某種關系,他們的隱私信息存在關聯,故同一個匿名集中的節點應減少連接,防止由于分析節點信息造成的隱私泄露;規則5從數學的角度約束了本文的方法,當任意兩個匿名集內的節點之間的邊數小于某個值時,可保證社會網絡圖中每條邊的隱私泄露概率不超過1/k。綜上所述,經過上述5 條規則匿名后的動態社會網絡,在一個穩定的時刻,其節點和邊被識別的概率均不大于1/k。其證明過程如下:
首先,每個匿名集中的節點數至少為k個,則每個節點被唯一識別的概率至多為1/k,且同一個匿名集中的節點屬性滿足L-多樣性,保障了節點被識別的概率不超過1/k;其次,同一個匿名集中的節點不存在連接邊,則邊的起點或終點至少有k個可能的節點;接下來本文定義邊的識別率EI,代表當前社會網絡圖中真實存在的邊占全部可能邊的比重,其計算公式如下:
EI=|(Vgi×Vgj)?Et|/(|Vgi|×|Vgj|)
令m=|(Vgi×Vgj)?Et|,即Vgi、Vgj之間t時刻連接邊的數量,可以得出:

綜上所述,當社會網絡處于某一確定的時刻時,節點與邊的識別率均不大于1/k。
定義6(T時刻匿名圖)T時刻匿名圖為滿足匿名規則1~5的二元組,其中:
2.3 主要流程
本文設計了基于匿名規則的動態社會網絡圖數據隱私保護方法,在數據發布階段對社會網絡數據進行匿名處理,以保護用戶隱私。為了抵御關聯攻擊,在每次數據更新時,通過圖的差集對已發布的數據進行逆向更新。

Fig.3 Flow chart of method圖3 方法流程圖
圖3 展示了動態社會網絡圖數據隱私保護方法的全部執行過程。首先進行個性化參數計算,判斷是否符合匿名條件,若符合匿名條件則進行數據更新,接收T時刻的社會網絡數據。然后根據屬性優先級進行節點排序,得到一個有序節點集合。接下來根據本文所定義的匿名規則進行節點聚類,得到若干匿名集,每個匿名集中包含若干節點。進而計算T時刻數據連接關系生成匿名圖。最后根據不同時刻圖的差集,逆向更新已發布的數據。具體步驟如下:
步驟1T時刻接收動態社會網絡中更新的數據,加入到時間窗口中。
步驟2判斷時間窗口是否符合時間窗口大小設置,若符合,進入步驟3;否則返回步驟1。
步驟3判斷時間窗口內的數據是否符合匿名閾值大小設置,若符合,進入步驟4;否則返回步驟1。
步驟4對當前社會網絡中的節點屬性的優先級排序。
步驟5對當前社會網絡中的節點依據匿名規則進行節點聚類。
步驟6刪除當前時刻社會網絡中不是同一時刻生成的邊,得到當前社會網絡的匿名圖。
步驟7對于t∈[0,T-1]時刻的社會網絡數據,刪除與當前時刻不屬于同一時刻生成的數據,進行逆向更新。
上述步驟描述了一次完整的包含時間窗口和匿名閾值的基于匿名規則的動態社會網絡圖數據隱私保護方法,下文將進行詳細介紹。
3 動態社會網絡圖數據隱私保護方法
3.1 隱私保護參數計算
為了支持用戶個性化隱私保護,本文設置了兩個隱私保護參數,分別為時間窗口和匿名閾值。用戶的隱私偏好經函數計算得到隱私偏好級別level,時間窗口和匿名閾值的取值隨level的變化而變化。
3.1.1 時間窗口
由于社會網絡圖數據隱私保護針對的是社會網絡這個整體,不能由單一的用戶作為社會網絡隱私保護級別的決策者,故本文以網絡中所有用戶作為隱私保護級別的設置者。社會網絡中節點的度反映了用戶與其他用戶的關聯情況,一個用戶的度越大,說明其與其他用戶產生越多的聯系,若此用戶的隱私信息泄露,可能會危及很多用戶的隱私。故本文使用加權的方式來度量社會網絡中的平均隱私偏好級別levelaverage,計算方法見式(4)。
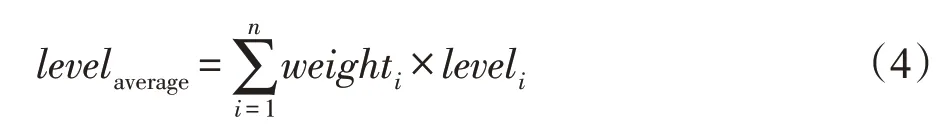
其中,weighti表示用戶i的度所占權重,weighti=表示用戶i的度,leveli表示由用戶i的隱私偏好所計算出來的隱私偏好級別。
本文設置了兩個隱私保護參數。其一為時間窗口(time window),它代表實際執行圖數據更新的時間間隔。由于圖數據是流式更新的,無法保證數據每次更新時的時間。然而,每當有數據更新時就進行圖數據匿名對于數據量龐大的社會網絡來說是很大的開銷,但長時間不對數據進行處理則會增大用戶隱私泄露的風險。故本文使用時間窗口來進行衡量,由社會網絡中的平均隱私偏好級別確定。其計算公式見式(5)。其中window表示基礎匿名窗口,單位為秒(s),window=0,1,…,N,N為自然數。
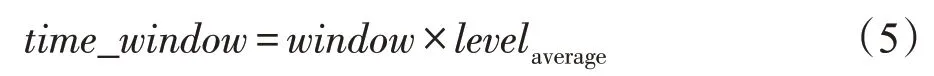
3.1.2 匿名閾值
匿名閾值(cost threshold)代表當前社會網絡已更新的數據量。由于社會網絡數據的匿名過程包含逆向更新過程,若每當社會網絡中數據有更新時就進行匿名,會增大網絡中的時間開銷,但是數據大量積累會造成用戶隱私泄露。故本文使用匿名閾值來計算當前網絡中已更新的數據量,若此數據量小于閾值,則不進行匿名。其計算公式見式(6)。其中threshold表示基礎匿名閾值,threshold=0,1,…,N,N為自然數。
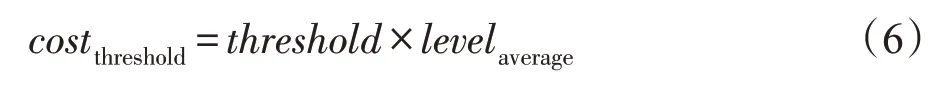
至此,本文得到了用于圖數據隱私保護的參數。
3.2節點聚類
節點聚類是把社會網絡中的節點聚類成若干個超級節點(稱作匿名集),每個超級節點至少包括k個節點,并對超級節點的屬性進行泛化處理,達到隱私保護的目的。本文遵循定義5 的匿名規則進行節點聚類,不僅確保節點和邊的再識別攻擊概率小于1/k,同時兼顧節點的屬性多樣性,抵御同質攻擊。
社會網絡中,每個節點都可能存在若干個屬性property={pi|i=1,2,…,np},這些屬性可能是敏感信息,導致用戶隱私泄露,比如用戶在社會網絡所填寫的職業可能推理出其可能的工作單位;其興趣愛好可能會反映出他的社交圈。本文對于用戶的屬性進行K-匿名和L-多樣性保護,即匿名后的社會網絡中,對于每一個匿名集中至少有k個用戶,且同一個屬性的取值滿足至少有L個。然而在實際的社會網絡中,幾乎不可能找到兩個一模一樣的節點,因為用戶所填寫的屬性信息無論是內容、句式還是結構都會有區別,故本文使用SimHash語義指紋[22]來衡量不同用戶的屬性之間的相似程度。SimHash 算法的特點是語義指紋包含了文本特征的散列值。相似的文本有相似的散列值,不同于MD5 等加密方式中細微的差別都會映射為不同的指紋,相比于MD5 等方式只能排查完全重復的文本,SimHash的應用范圍更廣。
本文將每個屬性作為一個token,為其分配權重后按如下步驟進行處理,可以得到文本的語義指紋[23]:
(1)將一個f維的向量V初始化為0;f位的二進制數S初始化為0。
(2)對每一個特征,用傳統的Hash算法對該特征產生一個f位的簽名b。對i=1 到f,如果b的第i位為1,則V的第i個元素加上該特征的權重;否則,V的第i個元素減去該特征的權重。
(3)如果V的第i個元素大于0,則S的第i位為1,否則為0。
(4)輸出S作為語義指紋。
文本的語義指紋S均為f位的二進制字符串,度量兩個文本之間的相似程度使用的是海明距離。海明距離是兩個字符串對應位置的不同字符的個數。兩個文本越相似,其海明距離越小。該算法被應用于Google 搜索引擎的網頁相似度檢測中,指紋長度為64 bit。由于用戶在社會網絡中填寫的屬性信息基本為短文本,其粒度與分詞后的文本基本無差別,故本文將用戶在社會網絡中所填寫的每一個屬性信息視作一個特征,進行語義指紋的計算。當用戶的屬性更新后,重新計算語義指紋。相對于網頁中的文本,用戶屬性的文本數量會少很多,因此本文取f=32,使用32 bit 語義指紋進行相似度判斷。進行節點聚類時,為了保障每個匿名集中的節點具有L-多樣性,本文使用算法1計算一個匿名集中的屬性多樣性。
算法1屬性多樣性計算算法Diversity

算法中的hammingDistance 用于計算兩個語義指紋的海明距離。算法的輸入為一個有序節點集合Vx,以及判斷兩個語義指紋是否相似的距離閾值minDis,針對每一個節點集合,若存在任意兩個節點的語義距離大于閾值,則認為增加了集合中的多樣性。算法的時間復雜度為O(n2),n為集合Vx的大小。
3.3 連接關系計算
節點聚類后生成了一系列匿名集,匿名集中包含若干節點,本節將介紹邊的連接規則,將匿名集中的節點進行連接,生成匿名圖。
邊連接規則:
規則1生成連接邊集合
規則2若存在node.degree=0,生成連接邊
上述邊連接規則描述了如何用匿名集中的節點生成邊構成匿名圖。規則1 描述了圖中的真實節點的邊的生成規則,對于一個真實節點在候選補圖的邊集中篩選出所有與它相連的邊,即以node為起始節點或終止節點的連接邊。規則2 描述了圖中噪音節點的邊的生成規則,對于一個噪音節點,若存在與不在同一個匿名集中的噪音節點,且該節點的度為0,即未與其他節點產生連接關系,則構造一條以為起始節點,為終止節點的連接邊。
圖4中展示了兩個匿名集,匿名集1中所有節點的tag均為{1,3},其中1號為真實節點,3號為噪音節點。同理,匿名集2 中所有節點的tag均為{2,4},其中2號為真實節點,4號為噪音節點。圖中所示,真實節點只能與和其具有原始連接關系的真實節點相連接,而噪音節點只能與和其不在同一個匿名集中且符合度數要求的噪音節點相連接。

Fig.4 Diagram of connection rules圖4 邊連接規則示意圖
3.4 匿名圖生成與逆向更新
對于T時刻的社會網絡圖GT,候選補圖和邊連接規則生成匿名圖與基于圖的差集進行逆向更新的方法見算法2。
算法2匿名圖生成與逆向更新算法
輸入:G={G0,G1,…,Gt,…,GT-1},UpdateGraph,ksets,k。

4 實驗及效果評估
4.1 實驗數據
實驗收集了新浪微博169 246 個用戶的屬性數據和4 485 488條關注關系。為了模擬社會網絡的動態更新過程,本文通過隨機增刪的方式,模擬社會網絡中節點、邊的增刪過程,并進行多次迭代;除此之外,還獲取了SNAP公開的歐洲某研究中心986個用戶的332 334 條郵件往來信息(https://snap.stanford.edu/data/email-Eu-core.html),包含郵件收發的相對時間,可直接用來更新動態社會網絡。
4.1.1 社會網絡用戶關注關系網絡分析
為了評價隱私保護方法的數據安全性與可用性,本文采集了2009 年8 月至2012 年10 月期間的新浪微博169 246 個用戶的2 031 393 條屬性數據和4 485 488條關注關系數據進行實驗。
為了更加真實地模擬社會網絡數據動態更新的過程,結合《中國互聯網絡發展狀況統計報告》(第27次至39 次)發布的2011 年1 月至2017 年1 月期間的新浪微博用戶量的真實變化趨勢,擬合了圖5所示的用戶量隨時間變化的數據曲線。其含義為12個月內新浪微博用戶量隨時間變化的趨勢,其中圖5(a)約涉及1 600名用戶,圖5(b)約涉及10 000名用戶。為了模擬準確,使用了6 次方程進行擬合,其公式分別為y1=-0.037 3x6+1.582 9x5-25.813x4+208.14x3-913.48x2+2 266.9x-1 218.1,(如圖5(a)所示);y2=-0.224 1x6+9.497 1x5-154.88x4+1 248.8x3-5 480.9x2+13 601x-7 308.9,(如圖5(b)所示)。
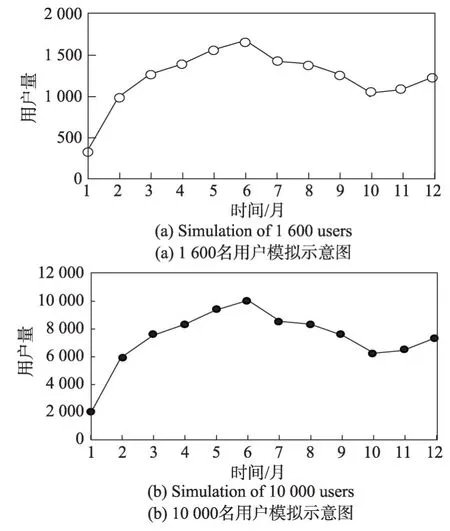
Fig.5 Changes in user quantity over time圖5 用戶量隨時間變化曲線
本實驗中將進行12 次迭代,即x=1,2,…,12,得到社會網絡中用戶總數,每次迭代的過程中,隨機刪除部分節點及與其相連的邊,再隨機增加節點與邊,達到擬合曲線的標準。為了能夠充分利用社會網絡中的關系數據,采用廣度優先搜索的方式,首先選取一個種子節點,然后搜索與此種子節點相連的節點,依次加入到實驗集合中,接下來進行第2輪廣度優先搜索,直到實驗集合中的節點個數滿足上述公式,最后執行匿名算法,對社會網絡數據進行保護后發布。本實驗將會記錄x=1時刻的原始社會網絡,記為G0,在每次迭代并逆向更新之后記錄,共可以得到12個
4.1.2 社會網絡郵件收發關系網絡分析
新浪微博數據雖然屬于典型的動態社會網絡,但未記錄用戶在社會網絡中行為數據(更新上述屬性)的時間信息。為了驗證本文方法適用于動態社會網絡中數據真實的更新情況,選取了由SNAP所提供的歐洲某研究機構由2003 年10 月至2005 年5 月(共18 個月)期間的郵件往來數據,共986 個用戶的332 334條郵件往來信息。每條數據包含一個時間戳,其含義為距相對起點(時間戳為0)間隔的秒數,可以按照時間戳信息還原郵件網絡的動態更新過程。
本文對郵件數據度-用戶數進行了統計,結果如圖6所示。其中度數最小值為1,最大值為10 571,平均度數為337。度的取值共604 種情況,平均每種情況約有1.6個用戶。此數據集中,用戶數隨度數的增加迅速減少直至趨于平緩,其分布基本符合冪律分布。

Fig.6 User quantity-degree statistics of email data set圖6 郵件數據集度-用戶數統計
由于此數據集中包含時間戳,為了更好地還原動態社會網絡數據更新的過程,本文對時間戳信息進行了統計,時間戳的相對起點為0,每隔1 s增加一個時間單位,相對終點為45 405 138,郵件發送的最小時間間隔為0 s,最大時間間隔為58 s,平均間隔為0.625 s。圖7展示了郵件發送的時間間隔統計情況,可以分析出,時間間隔-郵件數分布同樣符合冪律分布。

Fig.7 Time interval-email quantity statistics圖7 時間間隔-郵件數統計
4.2 評價指標
本文將從數據安全性和數據可用性兩方面評價算法的有效性,評價指標見表3。
4.3 結果分析
理論上,根據K匿名算法的性質,k值越大,匿名性越好,安全性越高;數據發布時間點越密集,間隔越短,圖更新的速度越快,可以執行更多次的匿名方法,匿名性也越好;網絡中節點與邊的數量也會影響匿名性。當節點數量和邊增加時,需要更大的k值進行保護。在節點數量不夠,數據發布時間間隔較長的情況下,本文算法會通過增加隨機節點的方式保證匿名性,具體的匿名程度和算法中選取的k值有關。
4.3.1 社會網絡用戶關注關系網絡分析
本文使用新浪微博的用戶屬性數據進行模擬實驗,將每個用戶視作社會網絡中的一個節點,用戶間的關注關系視作社會網絡中的有向邊,起點為關注者,終點為被關注者。每個用戶選取節點id為用戶的唯一標識,除此之外選取5個用戶屬性作為節點排序的依據,分別為性別、所在地區、描述、用戶標簽和教育信息。
由于新浪微博數據集中不存在用戶更新屬性信息、用戶關注關系的具體時間,本文采用模擬的方式,將全部數據集視作全集。在數據更新的過程中,第1次數據更新時,隨機選取M個節點及其之間的連接關系作為原始社會網絡,稱這個過程為初始化。在之后的每次數據更新過程中,隨機去掉N個節點以及與這些節點相關的邊,并從全集中隨機增加P個節點,以及相關的邊,得到一次更新后的數據。其中M、N、P為合法的隨機數即N≤M,其余參數無約束條件。
(1)數據安全性
為了衡量不同隱私保護參數下的隱私保護效果,將對200個節點的社會網絡進行匿名,計算k值為3~10 時的匿名率,通過匿名率來判斷數據安全性。如圖8所示,隨著k值的增加,匿名率呈現增長趨勢。可知隨著k值的增大,數據的安全性逐漸增大,當k=10時,匿名率約為26%。
為了驗證本文算法的屬性多樣性的設置效果,分別在使用與不使用屬性多樣性的條件下進行了實驗,對比屬性多樣性在算法中的作用。本文設置當兩個節點的屬性語義指紋距離小于H時,認為它們為相似的,不會增加多樣性,執行匿名算法后,統計每個匿名集中語義指紋的多樣性,實驗結果如圖9 所示。其中,H=5,選取100個節點及其相關的邊,k值取10,不設置L值,算法結束后未增加噪音節點,故產生的多樣性均為節點的真實屬性匿名后的結果。
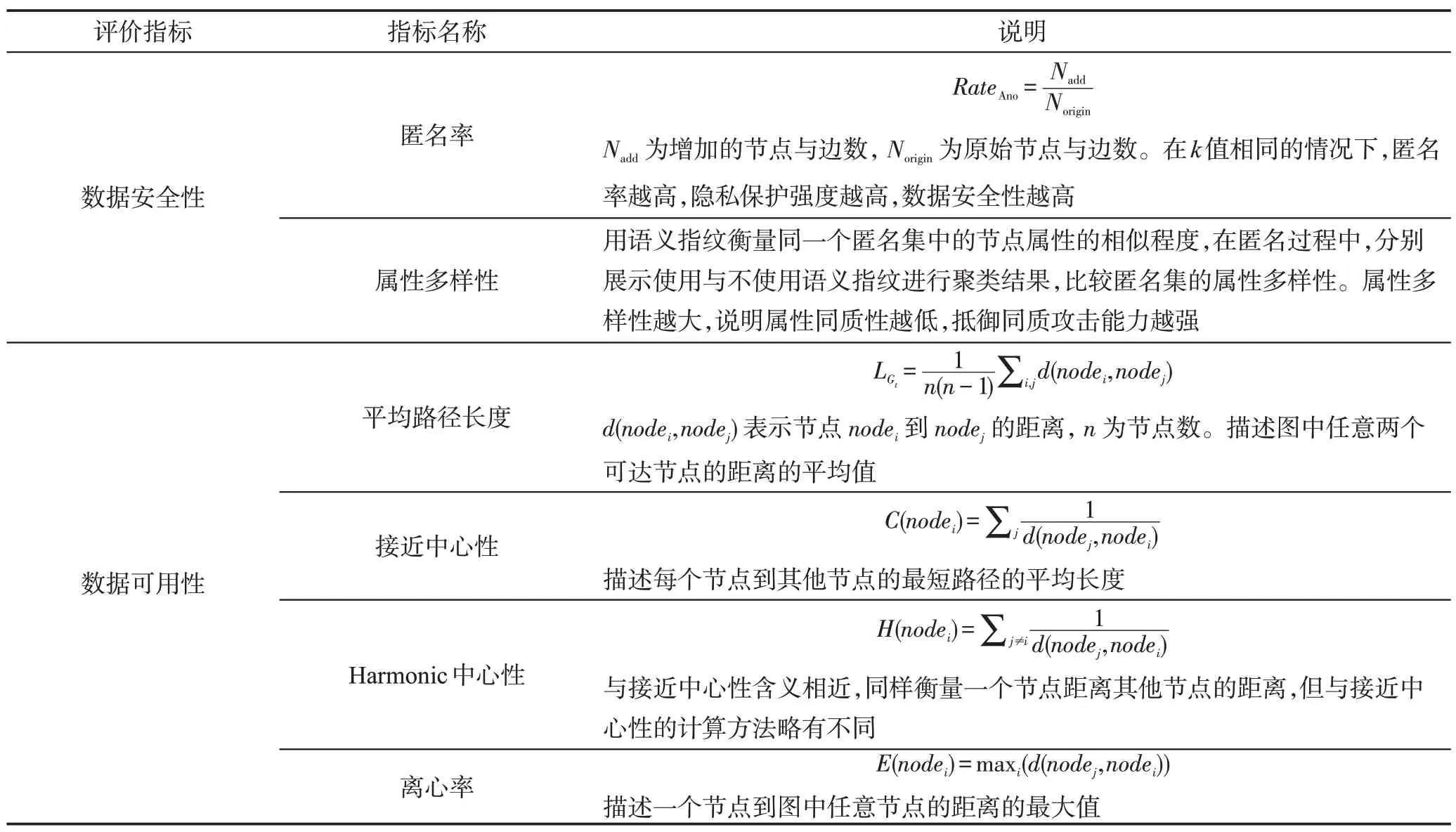
Table 3 Evaluation indexes表3 評價指標

Fig.8 Anonymity rate statistics of Sina Weibo data set圖8 新浪微博數據集匿名率統計

Fig.9 Semantic fingerprint and diversity result圖9 語義指紋與多樣性結果
由圖9可知,從多樣性、海明距離兩個指標來看,含語義指紋計算出的匿名方法基本優于不含語義指紋的情況。其中平均海明距離為同一個匿名集中的節點屬性兩兩之間的距離平均值,最大最小距離雖有一定的偶然性,但使用語義指紋的方法效果普遍更好。多樣性方面,通過語義指紋的設置,提高了同一個匿名集中屬性的多樣性。
除此之外,本文測試了數據安全性與迭代次數的關系,使用新浪微博數據進行兩組實驗,分別進行12輪迭代,并使用聚集系數、中介中心性作為衡量指標,分別記錄了測量值與匿名前后的變化率。結果如圖10 所示,圖10(a)展示了原始圖與經過12 次迭代的匿名圖的聚集系數和中心中介性變化率統計結果,兩項指標隨著圖數據的迭代而變化。隨著迭代次數的增加,聚集系數變化率和中介中心性變化率均呈現上升趨勢,說明數據安全性與迭代次數呈正相關關系,進一步說明本文所述方法在圖數據匿名后可以在圖結構上產生差異性,保護原始圖結構。圖10(b)展示的是10 000名用戶的模擬實驗結果,本文方法對于大數據集同樣可以進行擾動,保護社會網絡數據隱私。但由于數據量大,在變化數量相對穩定的情況下,變化率結果略低于小數據集實驗。

Fig.10 Data security of Sina Weibo data set圖10 新浪微博數據集安全性
(2)數據可用性
按照4.1 節中的模擬方法,本文使用新浪微博數據集進行兩組實驗,分別進行12輪迭代,以接近中心性、harmonic 中心性、平均路徑長度和離心率等指標測試數據可用性。
圖11(a)至圖11(d)分別展示了兩組數據的原始社會網絡圖與經過12 次更新及匿名后的評價指標。由圖11(a)與圖11(c)可知,兩組數據經匿名后,四種衡量指標均呈現波動性變化,對原始圖數據產生了擾動。由圖11(b)與圖11(d)可知,兩組數據匿名后的四種變化率除平均路徑長度外,不超過15%,從圖中節點間距離的角度來衡量,保持了數據可用性。與前文所述類似,由于相同的變化量在小數據中產生的變化率更大,故小數據集實驗的變化率略高于大數據集。
4.3.2 郵件收發關系網絡實驗結果分析
社會網絡是一個動態網絡,數據的更新迭代的時間不可控,它由用戶參與社會網絡的時間、頻率和動作決定。僅僅通過模擬動態社會網絡生成的方式是不能夠完全展現其更新迭代過程的,也不能驗證算法的有效性。故本文使用歐洲某研究機構的郵件往來數據進行實驗,按照郵件的收發時間進行社會網絡的動態更新,體現時間窗口、匿名閾值的作用與算法的實用價值。
(1)數據安全性
通過統計k值為3~10 時的匿名率來衡量數據的安全性。如圖12 所示,匿名率隨著k值的增大而增大,社會網絡數據的安全性逐漸增大。
本實驗從數據集中按照時間順序進行圖數據的動態更新,參數設置為:時間窗口為86 400 s,匿名閾值為0,即對于每一輪數據更新都進行匿名,進行10次迭代。對比匿名后的圖數據與網絡初始化時的圖數據結構的差異性,使用聚集系數、中介中心性及它們的變化率來衡量圖結構的變化。
由圖13(a)可知,本文方法可以對真實數據集進行圖數據匿名,在不同的迭代中產生不同的匿名效果。圖13(b)中的變化率顯示,當迭代次數為10 時,聚集系數與中介中心性的變化率分別約為40%和60%,對原始數據產生了擾動。且隨著迭代次數的增加,變化率逐漸增大。
(2)數據可用性
為了驗證本文方法在真實的動態社會網絡隱私保護中依然有效,與之前實驗類似,使用接近中心性、harmonic 中心性、平均路徑長度和離心率等指標進行方法驗證。本實驗從數據集中按照時間順序進行圖數據的動態更新,參數設置為:時間窗口為86 400 s,匿名閾值為0,即對于每一輪數據更新都進行匿名,進行10 次迭代。對比匿名后的圖數據與網絡初始化時的圖數據的差異性,結果如圖14所示。
圖14(a)中接近中心性、harmonic中心性、離心率和平均路徑長度這4 項指標在數據迭代的過程中均有不同程度的變化,說明本文方法在真實數據集中也可產生效果。圖14(b)中的變化率指標表明,隨著數據的更新,除平均路徑長度外,各項指標的變化率均在10%以內,保持了較好的數據可用性。平均路徑長度由于圖結構的變化,產生了相對較大的變化。
5 結束語
目前,社會網絡中用戶個性化隱私保護主要針對單實例發布的靜態網絡,不能適應具有高度動態性的社會網絡的更新迭代過程,不能保證社會網絡的隱私安全。本文開展了動態社會網絡數據發布個性化隱私保護研究,提出基于匿名規則的圖數據隱私保護方法。使用新浪微博數據和公開數據集驗證,實驗結果表明本文方法兼顧了用戶數據隱私保護和數據可用性的個性化需求。
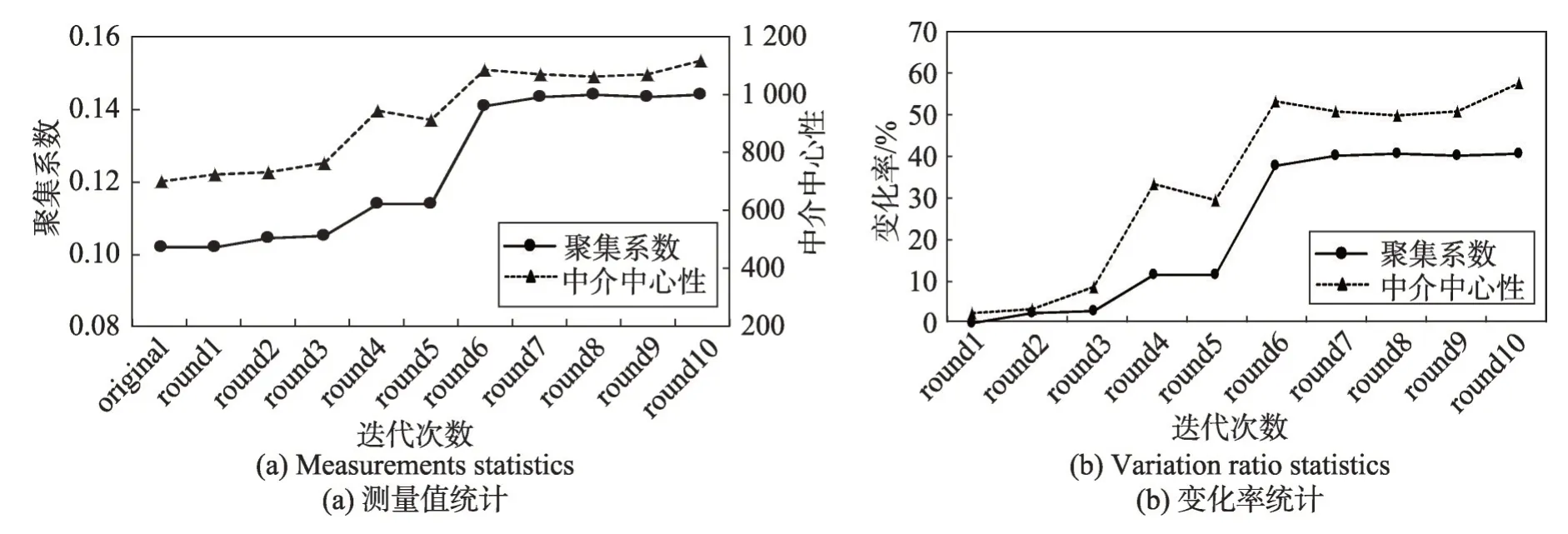
Fig.13 Data security of email data set圖13 郵件數據集數據安全性

Fig.14 Data availability of email data set圖14 郵件數據集數據可用性
未來研究工作將基于多維度用戶隱私保護方法開展深入研究,構建多特征的聯合匿名保護方案,構建隱私保護方案安全評價體系,為用戶提供更加可靠的社會網絡環境。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
