一種基于CPU-GPU混合系統(tǒng)的并行同態(tài)加密算法?
2019-09-03 06:46:16鄭志蓉
艦船電子工程 2019年8期
鄭志蓉
(91977部隊 北京 100036)
1 引言
同態(tài)加密算法這一類具有特殊性質(zhì)加密算法的出現(xiàn),真正從根本上解決了將用戶數(shù)據(jù)及其操作委托給第三方時的保密問題,滿足將計算托付給云服務提供商,并兼顧了數(shù)據(jù)的安全性。但是,同態(tài)加密具有不可忽視的計算復雜度,從而阻礙了同態(tài)加密算法的實際應用。因而本文致力于構建基于CPU-GPU混合系統(tǒng)搭建并行計算框架,實現(xiàn)基于整數(shù)同態(tài)加密算法的加速計算平臺。
1978年,Rivest等[1]首次提出了同態(tài)加密的概念,這是一種可以對密文直接進行操作的加密算法。RSA就是一種可以實現(xiàn)單一乘法的同態(tài)算法。但在2009年之前都沒有獲得滿意結果。僅僅只獲得了一些半同態(tài)的或者僅能做有限步的全同態(tài)加密方案。2009年,Gentry[2]基于理想格困難問題構造出了第一個全同態(tài)加密方案,也被稱為“隱私同態(tài)”或“全同態(tài)加密”,成為了信息安全領域的重要技術突破,使得加密信息,即刻意被打亂的數(shù)據(jù)仍能夠被深入和無限的分析,而不會影響其保密性。從此,學術界開始了對同態(tài)加密算法的廣泛關注和深入研究。
但是,全同態(tài)加密算法在實際應用中,由于全同態(tài)加密算法的計算復雜度巨大,從而失去了實際的應用價值。因此,在2010年,由Dijk,Gentry等[3]又提出了另外一種更加簡潔易懂的全同態(tài)加密方案,表示為DGHV,該算法僅使用整數(shù)上的加法、乘法和最基本的模運算,舍棄掉了Gentry的基于多項式環(huán)的理想格。因此,DGHV方案的計算效率與理想格的全同態(tài)方案相比,計算復雜度相對降低了,執(zhí)行效率相對更高,也便于利用計算機實現(xiàn)。然而,DGHV算法實際運算的復雜度還是很高的。例如:在一個簡單的明文檢索系統(tǒng)里應用DGHV算法,其計算量將增加數(shù)萬億次。因此,本文是基于DGHV算法進行的并行方案設計,以改善算法的實際應用效果。
近年來,許多并行計算框架被提出并成功應用到各個領域。因此,本文的核心思想是將同態(tài)加密算法與并行計算框架結合從而提高同態(tài)加密算法的執(zhí)行效率。文章基于CPU-GPU混合系統(tǒng)提出一種并行計算模式。并且,從運行時間定量分析文章提出的并行同態(tài)加密算法的有效性。文章為了進一步提高算法的并行度,設計了一種流水線處理模式,減少了系統(tǒng)內(nèi)各個單元等待的時間,從而進一步提高算法的執(zhí)行效率。
2 相關工作
由于云計算平臺中,許多常用的加密算法不適用。因此,同態(tài)加密算法由于代數(shù)同態(tài)的特征而引起學者的注意。但同態(tài)算法的高計算復雜度阻礙了實際應用。因此,近年來許多學者研究了如何提高同態(tài)加密算法的效率,從而在云計算環(huán)境中推廣同態(tài)加密算法的應用。文獻[4]試圖提出一種有效的算法,結合了概率知識和同態(tài)加密技術的特征,以從同態(tài)算法本身的角度提高執(zhí)行效率。然而實驗卻表明,時間的復雜性并沒有減少多少。因此,我們放棄了改進的同態(tài)算法本身,以提高效率。
在并行計算模型方面,Sethi等[5]提出了一種基于MapReduce框架的并行同態(tài)加密的模型。類似的,文獻[6]利用16個核心和4個節(jié)點構造基于MapReduce環(huán)境的并行同態(tài)加密方案。上述兩項研究的證據(jù)表明,一個好的并行方案可以提高同態(tài)加密的性能。這也是本文利用CPU-GPU混合系統(tǒng)構造并行同態(tài)加密算法的動機。尤其在醫(yī)療和金融領域,保護敏感個人信息的隱私是一個重要的研究內(nèi)容。文獻[7]建議使用GPU加速同態(tài)加密算法,以進行安全的醫(yī)療計算。文獻[8]設計了一個利用GPU輔助計算的同態(tài)加密算法,用于部分同態(tài)加密算法里的矩陣乘法運算。因此,本文提出了一種基于CPU-GPU混合系統(tǒng)的大規(guī)模數(shù)據(jù)加密的并行處理方案,這與現(xiàn)有的研究方案有所不同。并且,流水線處理方式也沒有相關學者研究用于提高并行同態(tài)加密算法的并行度。
3 本文方案
近年來,許多并行方案采用GPU輔助加速計算。此外,隨著架構的不斷改進,GPU由于其強大的計算能力,已經(jīng)成功應用于并行、多線程、多核處理器等系統(tǒng)中數(shù)據(jù)的并行處理。本文設計的并行方案利用GPU輔助加速數(shù)據(jù)加密的執(zhí)行,其他任務則是由CPU執(zhí)行。具體來講,本文采用CPU-GPU混合系統(tǒng)構造同態(tài)加密算法的并行計算方案。并且,通過對比實驗,定量地分析并行方案相比串行方案在系統(tǒng)性能和時間上的改進。
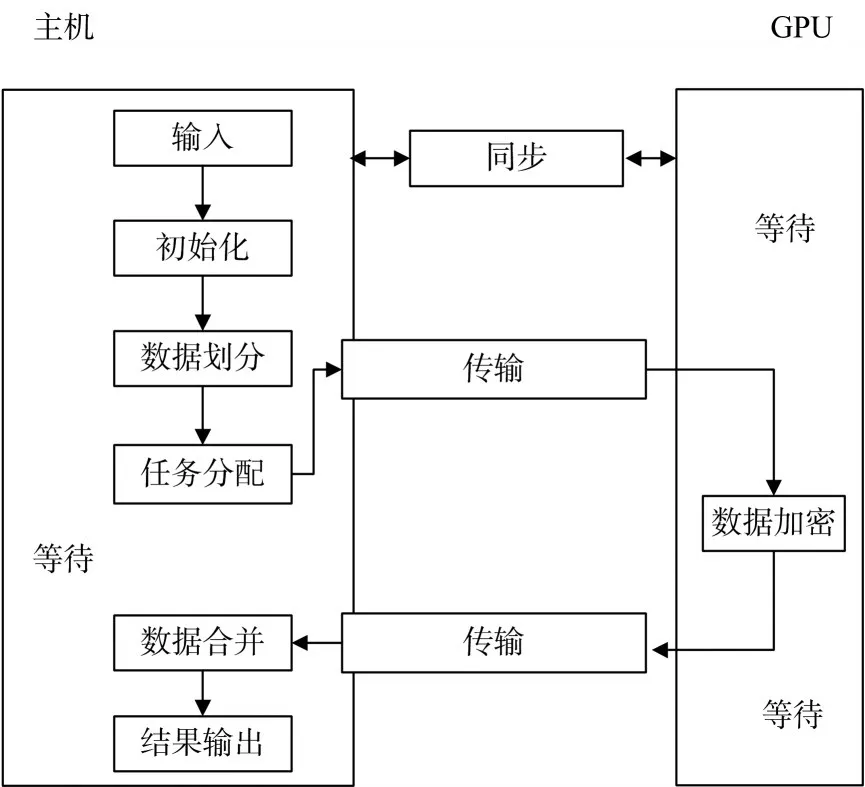
圖1 基于CPU-GPU混合系統(tǒng)的并行同態(tài)加密方案
圖1 顯示了基于CPU-GPU混合系統(tǒng)中主機、系統(tǒng)總線和GPU的任務處理和執(zhí)行狀態(tài)。并且,為了盡可能地縮短等待時間,設計了流水線處理模式如圖2所示,目的是減少系統(tǒng)內(nèi)各個單元等待的時間,從而進一步提高并行同態(tài)加密算法的執(zhí)行效率。
預處理:主要包括三個子任務,即初始化、數(shù)據(jù)劃分和任務分配。這三個步驟都是在CPU和主機內(nèi)存中處理的,組合在一起稱為預處理過程。首先,主機獲取輸入數(shù)據(jù)。下一步,數(shù)據(jù)劃分的任務主要是將數(shù)據(jù)塊分割成更小的數(shù)據(jù)單元,供GPU內(nèi)的多線程并行執(zhí)行加密運算。
傳輸和加密:輸入的數(shù)據(jù)從主機傳輸給GPU,GPU執(zhí)行加密運算。并且,當GPU執(zhí)行加密運算時,主機仍然可以執(zhí)行預處理等操作,從而讓CPU和GPU并行執(zhí)行各個子任務,這也是并行方案相比串行方案效率提高的根本原因。在整個過程中,GPU一直處于工作狀態(tài)。因此,GPU和系統(tǒng)總線都是CPU-GPU混合系統(tǒng)的關鍵執(zhí)行單元。
合并和輸出:主機需要把加密的數(shù)據(jù)合并,以構成完整的密文信息。并且,CPU-GPU混合系統(tǒng)采用了流水線模式的管道體系結構,如圖2所示。各個執(zhí)行單元如同流水線生產(chǎn)中的各個設備,不間斷的執(zhí)行各個子任務,極大程度的提高算法的并行度。
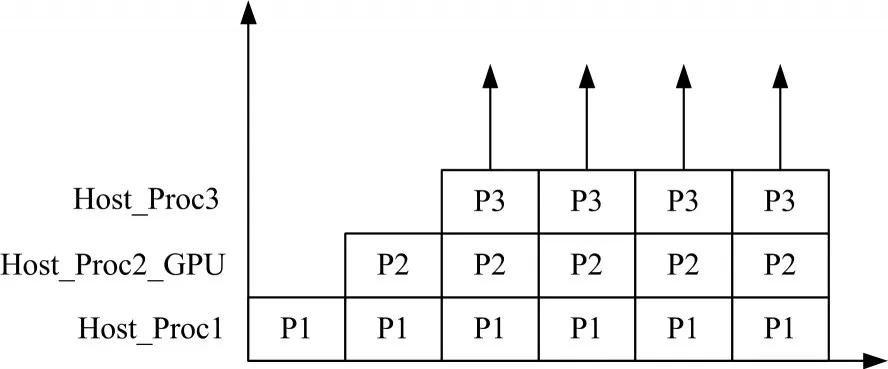
圖2 基于CPU-GPU系統(tǒng)的流水線處理流程
最后,主機把數(shù)據(jù)單元的密文合并成數(shù)據(jù)塊的密文并作為輸出。這些步驟將被視為合并和輸出的過程。基于上面的抽象,為CPU-GPU混合系統(tǒng)提供管道體系結構的流水線處理模式如圖3所示。
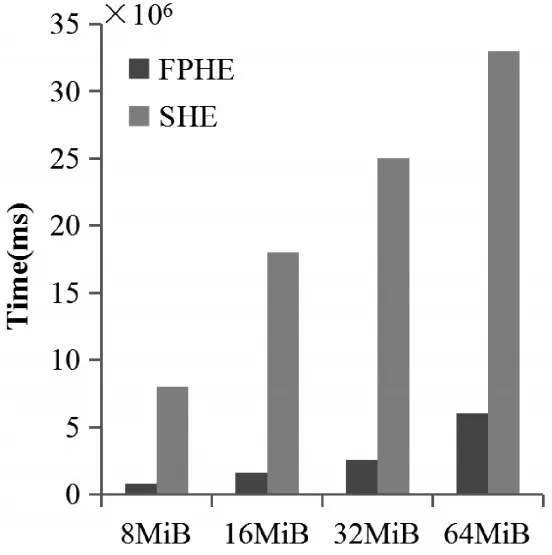
圖3 同態(tài)加法的運行時間對比
其中,預處理步驟主要由主機中的執(zhí)行單元CPU處理,表示為Host_Proc1,傳輸和加密步驟主要由系統(tǒng)總線和GPU執(zhí)行單元處理,表示為Host_Proc2_GPU,合并和輸出步驟主要由主機中的執(zhí)行單元CPU處理,表示為Host_Proc3。由于處理數(shù)據(jù)的粒度對執(zhí)行效率非常重要,因此,實驗部分將分析不同粒度數(shù)據(jù)對系統(tǒng)吞吐量和響應時間的影響。
4 實驗分析
4.1 實驗環(huán)境
本文的實驗中采用了C++和CUDA的混合編程模式。具體而言,實驗采用英特爾酷睿的型號為i5-5200u的CPU,包括2個2.20 GHz時鐘頻率的內(nèi)核,12G內(nèi)存以及Windows 10操作系統(tǒng)。GPU采用NVIDIA Tesla c2050,具有3 GB的內(nèi)存。編程環(huán)境采用C++和CUDA混合編程模式,這是一個NVIDIA GPU的SDK,它是一個針對C++和CUDA的集成包。
實驗使用的是由一系列隨機整數(shù)構成的大小為128MiB的數(shù)據(jù)集作為明文。其中,每一位整數(shù)由64個比特的二進制數(shù)據(jù)表示,這也是系統(tǒng)處理的最小數(shù)據(jù)單元。實驗中對數(shù)據(jù)集進行了劃分,分別對大小從8MiB到64MiB的數(shù)據(jù)集進行實驗分析,以評估并行同態(tài)加密算法的性能。
4.2 實驗驗證
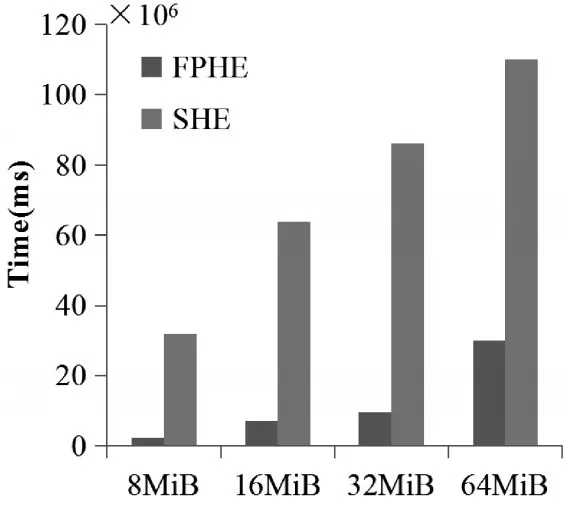
圖4 同態(tài)乘法的運行時間對比
為了驗證本文提出的并行計算架構的有效性,定量地對串行同態(tài)加密(SHE)與快速的并行同態(tài)加密(FPHE)關于執(zhí)行同態(tài)加法和同態(tài)乘法的運行時間進行對比,驗證本文提出的基于CPU-GPU混合系統(tǒng)的并行性同態(tài)加密算法的有效性。圖3和圖4分別是在不同大小的數(shù)據(jù)塊上執(zhí)行同態(tài)加法和同態(tài)乘法時,SHE和FPHE的運行時間對比。實驗結果表明,F(xiàn)PHE相比SHE在執(zhí)行同態(tài)加法時,效率提高了90%;FPHE相比SHE在執(zhí)行同態(tài)乘法時,效率提高了71%。從實驗結果得出結論,基于CPU-GPU混合系統(tǒng)的同態(tài)加密算法可以極大地提高執(zhí)行效率。
5 結語
本文研究基于CPU-GPU混合系統(tǒng)的并行同態(tài)加密方案,其中CPU負責管理、調(diào)度、輸入/輸出、合并等任務,GPU負責執(zhí)行加密運算。實驗結果表明GPU可以有效地輔助提高執(zhí)行效率。但是,為了進一步改善本文提出的方法的有效性,未來仍有很多問題需要解決。例如研究基于CPU和多GPU的并行計算框架等。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
甘肅教育(2020年14期)2020-09-11 07:57:42
中學生數(shù)理化(高中版.高考數(shù)學)(2020年5期)2020-06-02 09:19:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
商周刊(2017年9期)2017-08-22 02:57:49
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國衛(wèi)生(2014年11期)2014-11-12 13:11:32
