基于TF-IDF算法的方劑構成相似度可視化研究
2019-09-02 13:58:27郭文龍羅熊姜惠娟謝永紅陳茂建
中國中醫藥信息雜志 2019年7期
關鍵詞:可視化
郭文龍 羅熊 姜惠娟 謝永紅 陳茂建

摘要:目的? 構建中藥方劑數據挖掘系統,直觀反映方劑屬性及方劑之間的相似度,為方劑研究及應用提供參考。方法? 應用爬蟲框架和手工錄入方式獲取一定數量的經典方劑,采用中文分詞工具和手工整理方式對方劑信息進行名稱、功能、來源、中藥組成、劑量、劑量單位、炮制方法、忌宜、主治等屬性拆分,構造語料詞庫,Python3.5環境下采用TF-IDF算法計算方劑間相似度并進行功能主治驗證,采用d3.js進行可視化展示。結果? 經過分詞和手工整理得到不同類型方劑7710首,包含藥物8957味,構建的中藥方劑數據挖掘系統實現了相似度和方劑構成等信息可視化展示。同時,相似度高的方劑在功能主治方面具相似性。結論? 本研究構建的中藥方劑數據挖掘系統可直觀展示方劑信息、方劑與藥物間的關聯關系及方劑之間的相似度。
關鍵詞:方劑;TF-IDF算法;相似度;可視化;中藥方劑數據挖掘系統
中圖分類號:R289.1;R2-05??? 文獻標識碼:A??? 文章編號:1005-5304(2019)07-0104-05
Abstract: Objective To construct a data mining system for TCM prescriptions; To visually reflect the prescription properties and similarity between prescriptions; To provide references for research and application of prescriptions. Methods A reptile framework and manual entry method were used to obtain a certain number of classical prescriptions. The Chinese word segmentation tool and the manual finishing method were used for splitting the information of prescriptions according to the name, function, source, TCM composition, dosage, dosage unit, processing method, contraindication and indication. The corpus was constructed. In Python 3.5 environment, the TF-IDF algorithm was used to calculate the similarity between prescriptions and to perform functional indication verification, and d3.js was used for visual display. Results Through word segmentation and manual finishing, 7710 kinds of prescriptions of various types were obtained, including 8957 kinds of Chinese materia medica. The constructed TCM prescription data mining system realized information visualization of similarity and prescription composition. At the same time, prescriptions with high similarity were similar in terms of functional indications. Conclusion The TCM prescription data mining system constructed in this study can visually display the relationship between the prescription information, the prescription and the Chinese materia medica, and the similarity between the prescriptions.
Keywords: prescriptions; TF-IDF algorithm; similarity; visualization; TCM prescription data mining system
部分中藥方劑包含的藥物數據非常相似,組成藥物僅有微小差別,總體成分大致相同。這些相似方劑在治療某一種或某一類病證時的功效存在某種潛在聯系。從所有的方劑中找出與之相似的方劑可提供用藥的多維度參考[1]。因此,通過方劑的相似性分析可較好挖掘其相似關系。目前中藥方劑相似度模型主要從成分和功效兩方面進行相似性分析。
本研究在Python3.5環境下應用TF-IDF(term frequence-inverse document frequence)算法進行方劑相似性的計算,把所有方劑看作一個方劑集合整體,每一方劑的藥物構成看作關鍵詞,并構造詞庫,計算TF-IDF值后,依照系數矩陣計算相似性。構建中藥方劑數據挖掘系統,直觀反映方劑屬性及方劑之間的相似度,為方劑研究及應用提供參考。
1? 方劑相似度計算方法
不同研究者從多角度進行了方劑的相似度研究,取得了一定成績。操牡丹等[2]在《中醫藥方劑近似度模型》中提出基于字符串的方劑名稱的相似度計算,分別應用基于編輯距離的算法、基于最大公共字符串的算法和基于統計和字典的名稱相似度算法,在方劑名稱層面進行研究。黃運高等[3]在《基于K-means和TF-IDF的中文藥名聚類分析》中使用TF-IDF方法計算藥名相似的方法并采用K-means聚類算法進行藥名的聚類。朱志鵬等[4]在《基于LDA主題模型的中醫藥方劑相似度計算》中利用LDA主題模型發掘“方劑-證型-組成成分”的隱含關系的方法,將“方劑-組成成分”轉換成“方劑-證型”和“證型-組成成分”2個概率分布,并利用KL距離來計算相似度,但由于在LDA主題模型中馬氏鏈的平穩狀態需要迭代多少次才能到達卻很難確定,所以迭代次數只能依賴人為設置。顧錚[5]《基于文本分類技術計算中醫方劑相似度》利用自然語言處理領域的知識,基于KNN算法,計算方劑相似度,而KNN算法中K值的選擇直接影響計算結果。
本研究從方劑的藥物組成層面,在計算過程中根據藥物的重要程度依照TF-IDF算法賦予其權值,在給定方劑集合中計算與某一首方劑相似度高的其他方劑。
2? 基于TF-IDF算法的方劑藥物構成相似度計算原理
TF-IDF主要應用于搜索、文獻分類、網絡信息相關性的分析和其他相關領域[6-7]。
本研究把每首方劑看作由中藥名稱構成的關鍵詞的集合,即1首方劑包含n個關鍵詞w1,w2,…,wn,其在1首特定方劑中的詞頻分別是tf1,tf2,…,tfn。TF計算公式如下:
ni,j是該關鍵詞在所有方劑dj中的出現次數,而分母則是在所有方劑dj中所有字詞的出現次數之和。
如果作為關鍵詞w的一種中藥在Dw首方劑中出現,Dw的值越大,藥物w在方劑中區別于其他方劑的作用就越小。如甘草是很多的方劑中的組成藥物,出現的頻率非常高,但是它在方劑中的區分度貢獻小。因此,可以給方劑中的每種藥物賦予一定的權重,如果它很少在方劑中出現,通過比較可以較容易找到相似方劑,在方劑中用于區別其他方劑的作用大,其權重也就越大,反之其權重越小。
IDF逆向文本頻率指數是信息檢索中應用最多的權重計算方法,同樣可以使用到中藥方劑中藥物的計算。計算公式如下:
| D|:語料庫中的方劑總數
|{j:t∈dj}|:包含藥物ti的文件數目(即ni,,j≠0的文件數目)如果該藥物不在語料庫中,就會導致被除數為零,因此一般情況下使用1+|{j:t∈dj}|
假定方劑數量D=1000首,若甘草在所有方劑中均出現,則其idf=log(1000/1000)=log(1)=0,若當歸在20首方劑中出現,則其idf=log(1000/20)= log(50)=1.698 97。
因此,采用TF-IDF=tfi×idfi的值可評價某種中藥組成在某首方劑中的重要程度。計算某首方劑所有組成的tf×idf和sim,從而評價方劑之間的相似性。
上述相似度計算公式可有以下tf×idf的和,即:
依據以上公式,可把1首方劑分解成關鍵詞集合,然后在所有的方劑中計算這些關鍵詞的tf×idf的和,從而找出相似度高的方劑。
3? 應用計算過程
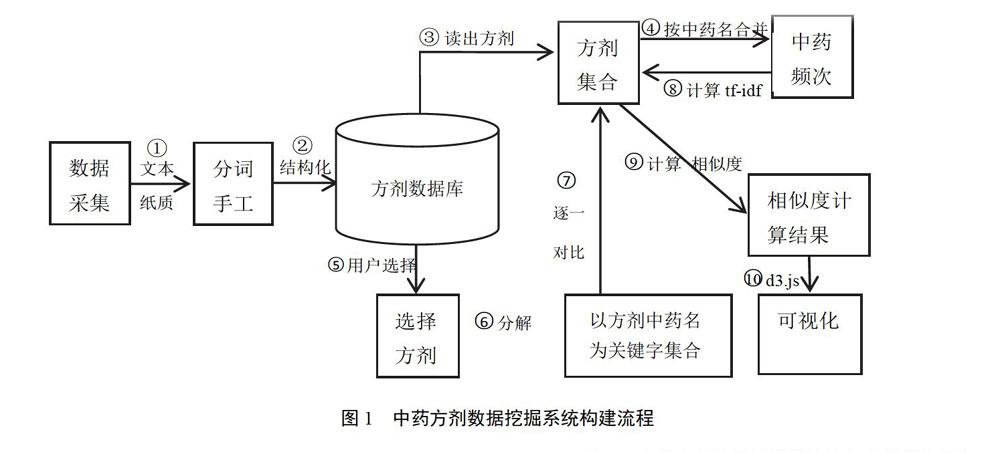
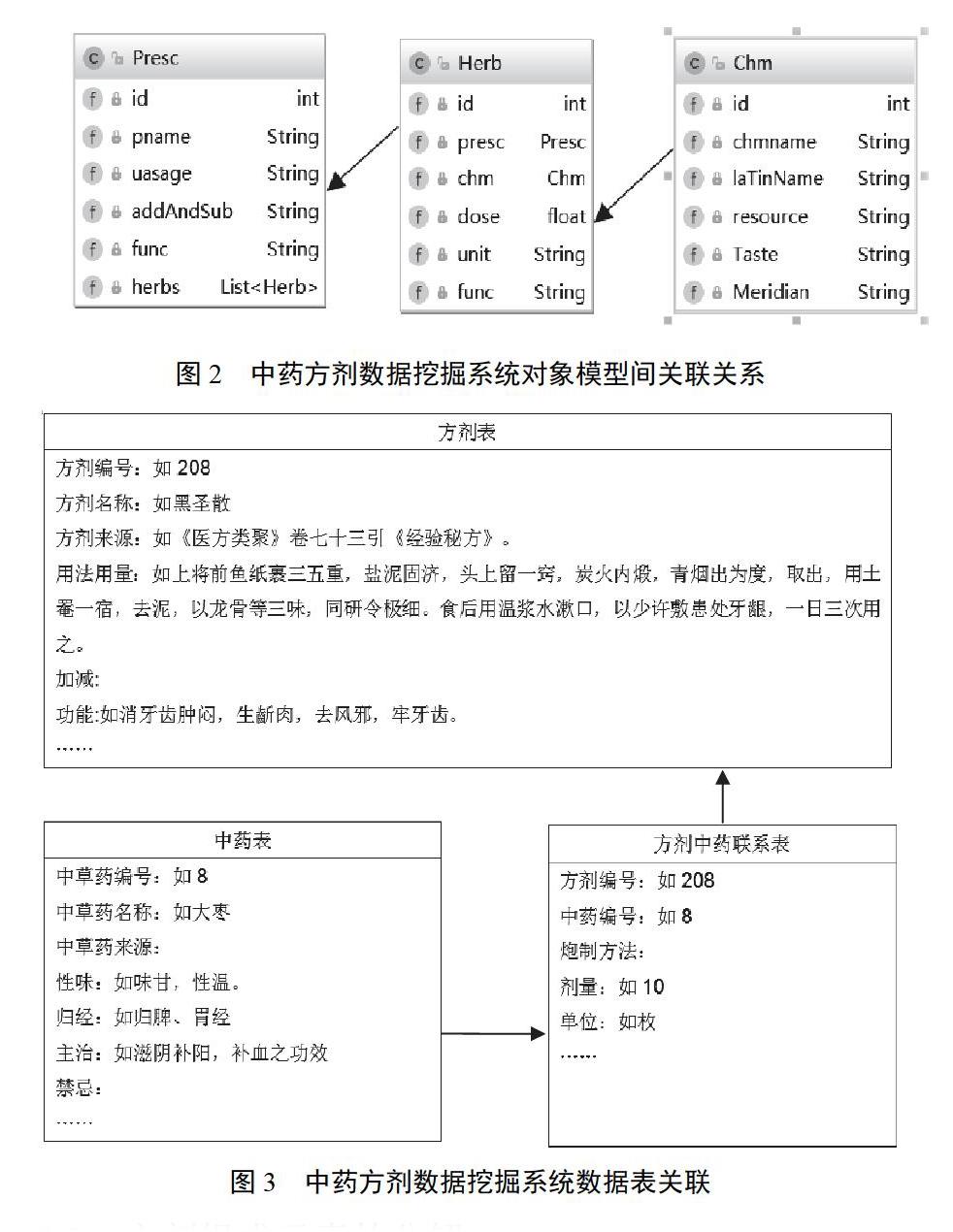
方劑相似度的計算及中藥方劑數據挖掘系統構建流程見圖1,其對象模型空間關聯關系見圖2。
3.1? 數據收集
數據集包括方劑表、中藥表和方劑中藥關系表。經過分詞和手工整理得到不同類型方劑7710首,包含藥物8957味,方劑表、中藥表和方劑中藥關系表的關聯見圖3。
3.2? 計算過程
1首方劑的藥物組成可看做由若干個關鍵字構成的整體,每味藥物的名稱即為1個關鍵字。
用集合p={chm1,chm2,chm3,…,chmi}表示方劑p由i個藥物chmk組成。其中chmk是經過分詞和相關處理形成的中藥名稱,因此,可避免語義方面引入的處理問題,降低了難度。如方劑小青龍湯p=
{麻黃,芍藥,細辛,干姜,甘草,桂枝,五味子,半夏}。
3.3? 方劑組成元素的分解
首先把每一方劑分解成若干個關鍵字,并構成[[杏仁,甘草,桂枝,麻黃,生姜,大棗,石膏],[附子,芍藥,甘草],[麻黃,芍藥,細辛,干姜,甘草,桂枝,五味子,半夏],[前胡,柴胡,知母,貝母,牡丹皮,桔梗,羌活,獨活,荊芥穗,黃芩,山茵陳,山梔,升麻,麻黃,大黃,麥門冬,杏仁,紫菀,玄參,秦艽],[柴胡,黃芩,人參,半夏,甘草,生姜,大棗],……]方劑集合。
3.4? 詞頻統計
把方劑分解的結果合并到一起,并統計各組成藥物的頻次。部分統計結果見表1。
3.5? 計算TF-IDF和相似度
從以上的統計結果中可以看出,甘草在中藥方劑中的應用頻次最高,但在方劑中的重要程度并不是最高,適合使用TF-IDF計算其重要程度。計算每一方劑中的所有方劑中藥組成的tf×idf的和。
如抽取方劑小青龍湯與所有方劑一一計算相似度。在500首方劑中計算與小青龍湯的相似度高的方劑,小青龍湯的組成是{麻黃,芍藥,細辛,干姜,甘草,桂枝,五味子,半夏},在500首方劑中的頻次分別是{41,18,33,35,181,7,36,60},即以{麻黃,芍藥,細辛,干姜,甘草,桂枝,五味子,半夏}為關鍵字分別在500首方劑中計算相關性。
4? 結果分析
得出的相似度結果中,以大青龍湯為例,對與其相似度較高的桂枝加芍藥湯、麻桂各半湯、小柴胡湯、杏子散、麻黃湯、小青龍湯、溫肺湯、麥湯散、百部丸、保真湯等,從主治功能方面進行分析驗證。結果見表3。
結果表明,與大青龍湯相似度高的方劑在功能與主治方面有較高相似性,主治風寒引起的發熱、頭身疼痛、肺熱等證,而且麻黃湯、小青龍湯同屬辛溫解表方。因此,應用TF-IDF進行方劑計算有實用價值。
5? 可視化展示
構建中藥方劑數據挖掘系統,應用d3.js可視化技術對以上計算的方劑相似度結果和方劑構成進行可視化展示,顯示與某一方劑相似度較高的若干方劑、方劑的構成、方劑的信息和組成中藥相關信息,見圖4。
在中藥方劑數據挖掘系統界面左側的方劑列表或方劑欄目中選擇某首方劑(如核桃承氣湯)作為輸入,得到的結果以橫向柱狀圖形式直觀展示了與方劑核桃承氣湯相似性高的方劑名和相似度值,見圖5。與核桃承氣湯相似度較高的方劑有厚樸七物湯(30.83%)、溫脾湯(24.81%)、小承氣湯相(23.71%)、三化湯(20.54%)、苓桂術甘湯(20.52%)、麻黃湯(15.92%)等。
6? 小結
本研究從藥物構成研究方劑,應用TF-IDF算法實現了中藥方劑相似度的計算,結果精確度較高。構建的中藥方劑數據挖掘系統可直觀展示方劑信息、方劑與藥物間的關聯關系及方劑之間的相似度,并通過可視化框架進行表達,推薦相似度高的方劑。數據分析應用Python3.5實現,可視化應用d3.js實現。但研究維度相對單一,今后研究可從藥物、劑量、藥性、藥物成分等多維度計算相似度,并給出合理閾值,確定相似度模型。
參考文獻:
[1] PETERS C. Cross-language information retrieval and evaluation[C]//Proc. of Intl Conf. on Lecture Notes in Computer Science. Berlin:Springer Verlag,2001.
[2] 操牡丹,何前鋒,王柏.中醫藥方劑相似度模型[J].計算機工程,2009, 16(8):275-277.
[3] 黃運高,王妍,邱武松,等.基于K-means和TF-IDF的中文藥名聚類分析[J].計算機應用,2014,34(S1):173-174.
[4] 朱志鵬,杜建強,劉英鋒,等.基于LDA主題模型的中醫藥方劑相似度計算[J].計算機應用研究,2017,34(6):1668-1670,1676.
[5] 顧錚.基于文本分類技術計算中醫方劑相似度[J].微計算機信息, 2010,26(12):199-201.
[6] 徐建民,王金花,馬偉瑜.利用本體關聯度改進的TF-IDF特征詞提取方法[J].情報科學,2011,29(2):279-283.
[7] 吳軍.數學之美[M].北京:中國工信出版社,2014:104-109.
猜你喜歡
江蘇安全生產(2022年7期)2022-08-24 02:11:52
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
北京測繪(2022年6期)2022-08-01 09:19:06
選煤技術(2022年2期)2022-06-06 09:13:12
師道·教研(2022年1期)2022-03-12 05:46:47
云南化工(2021年8期)2021-12-21 06:37:54
北京測繪(2021年7期)2021-07-28 07:01:18
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
山東農業工程學院學報(2019年11期)2020-01-19 02:49:22
傳媒評論(2019年4期)2019-07-13 05:49:14
