云環境下基于函數編碼的移動應用克隆檢測
2019-08-29 08:09:40楊佳付才韓蘭勝魯宏偉劉京亮
通信學報 2019年8期
楊佳,付才,韓蘭勝,魯宏偉,劉京亮
(1.華中科技大學計算機學院,湖北 武漢 430074;2.北京航空精密機械研究所,北京 100876)
1 引言
近年來,隨著移動智能終端設備的迅速發展,Android 應用占據了移動應用市場的主要份額。據統計,2017 年已有超過15.5 億部智能手機被使用,其中超過80%的手機搭載了Android 系統。海量規模的各類移動應用(App)投放在多個第三方應用市場供用戶下載,例如谷歌應用市場中Android 應用數量已經接近140 萬。這些移動應用已在辦公、娛樂等各個方面深入人們的生活,成為不可或缺的一部分。
然而,由于Android 系統的開放性和Android 應用的易被破解性,許多非法開發者利用克隆技術或者反編譯工具仿造出大量的克隆App。目前,應用重打包已經成為惡意軟件傳播的主要途徑之一。目前,有超過85%的安卓應用存在重打包行為,這不僅侵害了原開發者的知識版權和利益,也對移動用戶的安全和隱私造成危害。此外,一些攻擊者會修改原始App中的函數邏輯,如去除App 中的支付函數、修改原App 中的廣告庫,甚至插入各種各樣的惡意代碼,再用一個新的簽名重新打包這些惡意App。克隆App在第三方應用市場中大量地被下載使用,嚴重干擾了應用市場的正常環境。為保護合法用戶和原創開發者的正當權益,如何實現高效準確的App 克隆檢測是當前移動應用市場面臨的技術挑戰。
由于App 市場的規模龐大,App 的數量不斷快速增長,僅基于本地的計算資源進行App 克隆檢測會因為硬件配置較低而出現計算能力有限、電源功耗過高等問題,本地檢測技術已不能滿足百萬數量級的App 分析需求。移動互聯網中的云計算、大數據及虛擬化技術為解決大規模App 克隆檢測問題提供了技術支撐。本文基于云環境提出了一種高效App 克隆檢測方法,構建了檢測原型系統,提高了App 克隆檢測的效率,能有效應對大規模App 克隆檢測挑戰。
許多研究者提出了多種App 克隆檢測技術,主要有以下三類:基于簡單散列特征提取的技術[1]、基于靜態語義特征提取的技術[2-6]、更加復雜有效的基于Android 應用UI 結構特征的提取技術[7-10]。第三類檢測技術中基于UI 結構特征的檢測方法主要分析用戶接口之間的使用相似度進而判斷App是否克隆。目前,Androguard[11]和FSquaDRA[12]是用于App 克隆檢測的主要公用工具。Androguard 能夠在Dalvik 字節碼層進行比較,FSquaDRA 能夠基于源文件進行相似度分析。然而這些研究還存在以下問題:基于散列值和某一特定靜態語義分析方案的適應性還需增強,例如,在克隆中使用代碼混淆可避免被基于靜態語義特征的方法檢測出來;而UI 結構特征提取方案需要提取整個App 的UI 調用結構,同時需要復雜的圖匹配計算來比較App 相似度,因此對于小結構UI 圖的App 難以達到較好的檢測效果。
本文主要從以下3 個方面來討論目前的工作。
1)二進制層函數克隆檢測方案
在二進制層的克隆檢測方案中,一種通用的方法是使用基于函數執行序列的路徑進行代碼相似度檢測。這種方法能夠檢測控制流程圖(CFG,control flow graph)的變化,但是不能準確地檢測在不同平臺或者代碼混淆下的函數克隆。另一種方法是利用代碼的靜態特征進行App 克隆檢測。但當惡意開發者對這些靜態特征進行修改的時候,例如修改字段變量的常數或API Call 的調用序列等,這種方法的正確率就無法得到保障。Rendezvous[13]在二進制代碼上使用代碼搜索的辦法進行克隆檢測,這種方法有2 個限制:首先,需要代碼的ngram 特征來提高準確率;其次,需要將整個CFG 分為幾個子圖來處理。Pewny 等[14]提出了一種基于已知的漏洞簽名的搜索方案,該方案計算二進制代碼塊的語義散列來進行函數的克隆比較,然而這種方案并不高效。Feng 等[15]提出了基于控制流程圖的惡意代碼檢測方案,但是需要復雜的圖匹配過程。
2)App 克隆檢測
傳統方法檢測惡意App 主要通過權重很大的靜態和動態特征來進行黑白名單檢測,但是不能檢測未知的惡意代碼,如果之前并沒有收錄這種惡意代碼,則無法進行檢測。例如,Zhou[16]利用軟件權限、API 調用順序等靜態特征進行檢測,但是僅利用這些靜態特征進行檢測會導致較低的準確率。David[17]能夠自動劃分一個函數調用圖的社區結構,這些劃分的社區結構能夠用于新的惡意代碼檢測。Arp 等[18]提出一種新的輕量級的檢測方案,這種方案從安卓應用中提取八類特征,然后對這些特征用SVM 進行分類實現檢測[3]。
3)動態檢測
該檢測方式需要App 在一個虛擬的環境下運行,從動態特征中提取信息。Andrubis[19]即是動態地進行檢測,但是耗時過長。Enck[20]提出了一個系統Taintdroid,通過追蹤敏感信息的流動來進行克隆行為的檢測,這種方法同樣非常耗時,在效率上有所欠缺,無法應對大規模的檢測。
實現云環境下高效的函數層App 克隆檢測方案存在以下一些困難和挑戰。
1)相比面向源代碼的克隆分析,移動應用App中基于可執行字節碼的克隆分析更為復雜。移動應用的源碼并不能輕易獲取,同時,Android 應用中大量使用的代碼混淆技術也給重打包檢測增加了難度。
2)海量的應用規模為克隆檢測效率提出了更高的要求。隨著各類Android 應用的普及,App應用數量呈現出飛速增長的趨勢,通過App 的UI 調用圖或者動態分析等方法都無法應對大規模級別的克隆分析。
3)移動應用中第三方庫函數的大量使用干擾了克隆檢測的效率與準確率。只有App 自身核心函數代碼來源于其他應用才能認定是克隆App,之前的工作僅通過黑白名單過濾第三方庫函數,在正確性和效率方面存在很大的問題。
4)系統需要具備良好的可擴展性。在有新應用添加到云端時,既要快速分析判斷,又要將新應用特征快速融合到整體克隆特征庫中,實現增量特征更新。如果需要和之前的App 克隆檢測數據庫同時學習與提煉,其應用效率會受到影響。
針對上述問題,本文面向云環境提出了一種基于函數編碼的App 克隆檢測方法,并實現了該方法的原型系統,稱為Pentagon。該方法在App字節碼層面對函數的控制流程圖與基本代碼塊進行特征編碼,從函數層面比較2 個App 之間的相似度。所有的特征提取過程和檢測算法均在云環境下構建和實施。本文主要貢獻如下。
1)設計了根據App 字節碼提取函數基本代碼塊特征的方法。每個執行函數由多個基本代碼塊通過跳轉連接組成,首先針對每個執行函數提取原始CFG,然后提取每個CFG 圖形節點的特征,即基本代碼塊特征,這些特征值表示了該代碼塊的靜態統計特征以及該代碼在CFG 中調用跳轉結構特征。
2)提出了融合代碼塊特征和函數CFG 特征的編碼算法。該編碼算法將App 中任一函數編碼成幾個關鍵值的特征向量,提取的函數CFG 有向圖特征空間被壓縮成低維的數字特征空間;然后,基于該特征空間使用高效的聚類方法過濾第三方庫函數;同時,證明了算法中函數特征編碼的單調性,一個特征編碼僅代表一個函數。
3)解決了規模化App 增量更新的問題。Pentagon對App 中每個函數進行獨立編碼,對于新增加的應用程序,Pentagon 可單獨編碼該App 中所有函數特征,然后在數據庫中對App 進行搜索比較,避免了同時整體提煉所有App 特征值的復雜過程。
4)從第三方應用市場收集了超過152 789個應用程序,對原型系統進行了大規模的實驗驗證。實驗結果表明本文方法的預處理效率和克隆檢測效率是目前典型App 克隆方案的8~100 倍。在1 000 個函數中一個克隆函數的平均搜索時間為7.9 ×10-9s。同時,App 克隆檢測的正確率達到97.6%。
2 問題描述和方案總覽
本節首先說明設計移動應用App 克隆檢測系統需要解決的問題,然后介紹本文提出的面向云環境下的App 克隆檢測方案。
2.1 問題描述
本文需要解決的關鍵問題是在云環境下如何快速判斷一個未知App 是否為克隆App,并判斷克隆App 中具體哪些函數是相似的及其相似度大小。判斷App 是否克隆,需要滿足以下條件。1)不同的開發源有相同的App 功能函數。通過查看 Android 應用的簽名密鑰和App 中所有函數的特征來判斷該App 是否為克隆。如果這些不同簽名的App具有相似或相同的核心函數特征,則說明是克隆App。2)相似的函數不能包括第三方庫函數。App的代碼中一般包含了許多相同的第三方庫函數,這些庫函數不能作為判斷克隆的依據,克隆檢測方案需要過濾這些第三方庫函數。
檢測App 是否克隆的基本步驟如下。從非結構化的App 字節碼中提取CFG 特征,然后將每個含有基本代碼塊特征信息的CFG編碼為一個低維數字特征,該特征向量表示App 中的函數特征。通過不同App中所有的函數特征匹配來實現App 函數層的克隆檢測。App 克隆檢測問題數學描述如下。
問題1如何設計一個函數f計算每個App 函數的編碼特征。通過App 中所有函數的編碼特征獲得App 的矩陣表示,即其中,表示整個函數的編碼特征向量,j=1,2,…,m,也是矩陣A中第j列列向量;m表示App中函數的個數。在函數f中,表示CFG 中基本代碼塊i的特征,|v|表示一個CFG 中代碼塊的個數。
問題2如何設計一個有效的過濾函數F以去除App 中第三方庫函數。這是提高App 克隆檢測正確率的重點問題,由于App 克隆檢測需要比較所有的代碼塊特征,如果不同App 中有大量相同的第三方庫函數,一方面會增加克隆檢測時間,另一方面會干擾克隆檢測的準確率,相同的第三方庫函數不能作為克隆的檢測依據。
2.2 方案總覽
本節主要介紹函數層的特征編碼方案,并說明本文方案如何解決第2.1 節中提出的問題。本文的App 克隆檢測方案的基本思想是:首先,提取App反編譯smali 文件中每個函數的CFG;然后,針對每個CFG 中的每個基本代碼塊提取關鍵特征值,并根據編碼算法將所有的基本代碼塊特征和CFG 跳轉結構編碼為低維的向量表示,將該向量存儲到App 特征數據庫中;最后,用余弦相似度計算2 個函數特征之間的向量距離,通過該距離判斷App 是否克隆。
如圖1 所示,Pentagon 有以下3 個檢測步驟。1)CFG 提取云環境,包括安卓市場下載App、反編譯和CFG 提取過程。2)函數特征生成及過濾云環境,主要為Pentagon 編碼過程,Pentagon 編碼的函數特征用來進行第三方庫函數過濾。3)云環境下App 克隆檢測,主要為特征向量相似度比較。每一個步驟都在云環境下實現,具體實現過程為:首先編寫自動下載App 的爬蟲引擎,將下載的App 存儲到對應的服務區中;然后通過并發方式對每個下載的App 進行CFG 提取以及函數特征編碼;結合云環境下內存流計算方式并行地處理這些App,獲得App 中每個函數的低維數據表示,并將編碼特征存儲在云端的非結構化數據庫中。
上述檢測步驟中,第一步,主要提取函數CFG中的基本代碼塊屬性。在Pentagon 中,CFG 的每一個節點提取5 個屬性值,這5 個屬性值分別表示字節碼特征和該基本代碼塊在CFG 中的拓撲結構。第二步,根據CFG 的拓撲結構,設計了一種基于圖形嵌入的編碼算法,將CFG 中的所有節點特征編碼為一個單調的低維數字特征,并通過反證法證明其單調性;使用函數編碼特征進一步過濾第三方庫函數,在過濾之前,先刪除每個App 中重復的函數,然后通過聚類算法刪除第三方庫函數。第三步,給定一個待檢測的App,使用局部敏感散列(LSH,local sensitive hash)搜索算法實現高效的函數特征匹配。由于函數特征是獨立編碼,不需要更新之前的App函數特征庫,只需在數據庫中增加新的App 特征。
3 Pentagon 函數編碼
本節重點描述Pentagon 函數特征編碼算法,該算法將App 中每個函數編碼為一個一維向量,該一維向量能夠單調表示App 中的函數特征。
3.1 原始CFG 提取
Android 應用一般是由開發者將所有的源碼和資源打包成APK (Android package)文件,然后發布供用戶下載。APK 文件是一個壓縮包,解壓縮之后的文件夾內主要包含該應用的Dalvik 字節碼、UI資源、UI 布局、配置文件、簽名信息等。其中,Dalvik 字節碼是App 的可執行函數文件。Android應用程序通常用Java 語言實現,然后被編譯成Dalvik 字節碼。
APK 文件本質上是一個壓縮文件。反編譯的classes.dex 文件是App 主要的代碼文件,源代碼編譯成class 后,轉成jar,再壓縮成dex 文件。dex 文件是可以直接在Android 虛擬機上運行的文件。smali語言是davlik 的寄存器語言,語法上和匯編語言相似,一個smali 文件中包含了很多函數,每個函數中包含了一系列的操作碼及該操作碼對應的寄存器和處理數據。本方案首先對smali 文件提取CFG。CFG 中的每個節點代表函數中的一個代碼塊。CFG中跳轉結構開始于一個代碼塊,結束于另一個代碼塊,有向邊表示控制流程圖的跳轉結構。
3.2 函數特征編碼
編碼函數特征的主要思想是從App 的smali 文件的字節碼中提取一個帶有代碼塊特征的CFG,并將該特征CFG 投影編碼為一個包含5 個屬性值的低維向量特征。與函數代碼塊的其他特征(如I/O特征和其他語義特征[16])不同,CFG 能更加全面地匹配函數的執行流程特征。CFG 中的邊表示基本代碼塊之間的調用關系,CFG 中的每個代碼塊包含了一系列的操作碼和數據。本文基于圖形嵌入的思想來編碼帶有代碼塊信息的 CFG 結構。Pentagon 融合了CFG 拓撲結構和基本代碼塊的靜態特征綜合完成函數特征編碼。圖2 表示CFG 的抽象圖,一個圓圈表示一個基本代碼塊,也是CFG圖中的一個節點,圓圈中的字母表示該基本代碼塊的序號,圓圈旁邊每一行表示一行dex 匯編代碼,其中包含了操作碼及使用的寄存器(v0~v4表示寄存器),圖中的箭頭表示2 個代碼塊跳轉的一條有向邊。
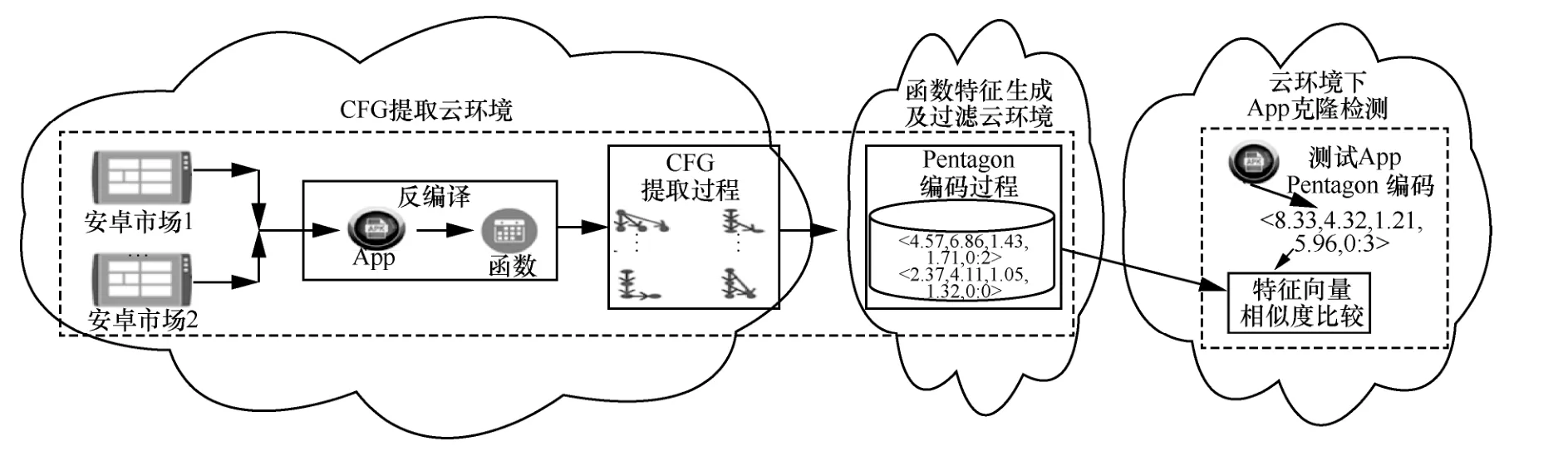
圖1 Pentagon 檢測步驟
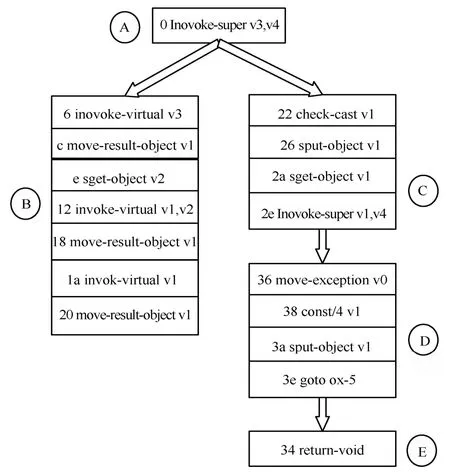
圖2 CFG 抽象圖
定義CFG 為一個有向圖(V,E),其中,V是一個函數的代碼塊集合,E?V×V是一系列代碼塊之間的連接邊。每個基本代碼塊的特征表示為一個一維向量。其中,si為代碼塊i在CFGj中的使用序列,pi為代碼塊i的操作碼的數目,ai為調用不同的API Call 的個數,oi為代碼塊i的出度,l i為代碼塊的循環結構的個數,并定義代碼塊i有唯一的權重ωi。根據提出的算法,使用權重ωi編碼所有的節點特征。具體的計算過程如式(1)所示。
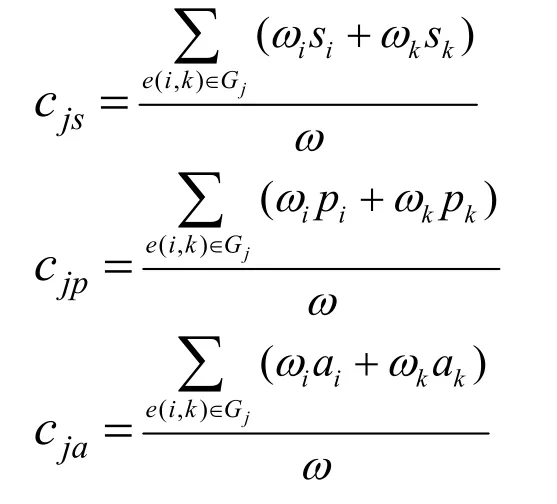
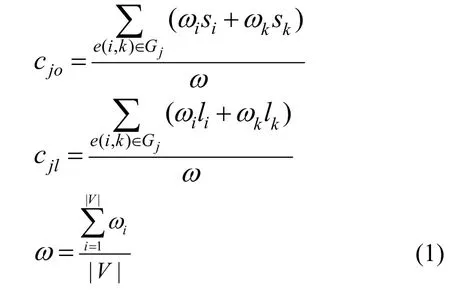
其中,e(i,k)表示Gj中節點i到節點j之間的一條邊|V|表示節點數。計算結果是每個函數的特征,其中,c js、cjp、cja表示代碼塊的統計特征,cjo、cjl表示CFG 拓撲結構的跳轉結構。
3.3 權重參數生成
Pentagon 的關鍵是計算每個節點i的權重ωi,ωi用于函數特征的融合編碼。為了得到每個節點的權重,首先定義帶有代碼塊特征的CFG 一級跳轉結構和全局跳轉結構[21-22]。
1)一級跳轉結構。一級跳轉結構L描述CFG中任意2 個節點之間的跳轉情況。
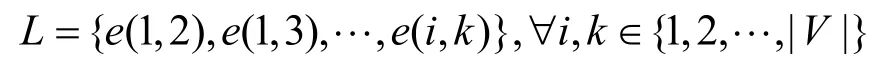
如果節點i和k之間至少有一條有向邊,則e(i,k)=1;否則e(i,k)=0。一級跳轉結構對CFG 編碼非常重要,表示在函數代碼中CFG 結構代碼塊的一級繼承和調用情況。
2)全局跳轉結構。全局跳轉結構N描述了節點與CFG 中的其他節點之間的一級跳轉情況。
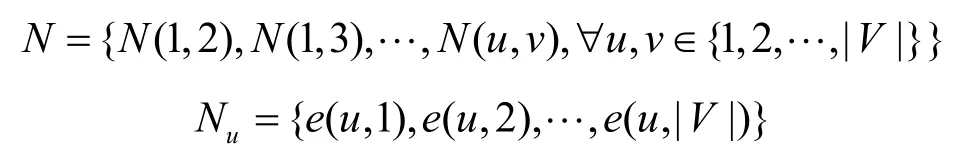
其中,Nu表示節點u和CFG 圖中其他節點的一級跳轉,節點的總數為|V|。比較Nu和Nv之間的相似度,獲得節點u與節點v之間的全局跳轉N(u,v)。直觀來說,全局跳轉結構表示如果2 個節點連接了更多相同的節點,則它們之間的聯系會更加緊密,這些設想在很多領域都被合理證明。
在CFG 的有向邊e(i,k)中,定義從節點i到節點k之間的跳轉概率為
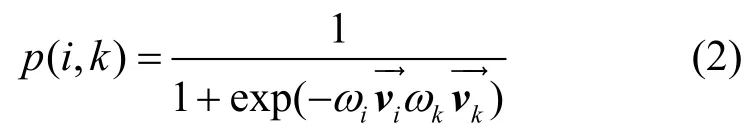
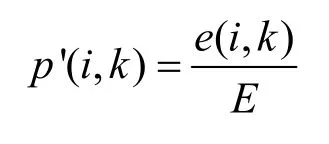
其中,
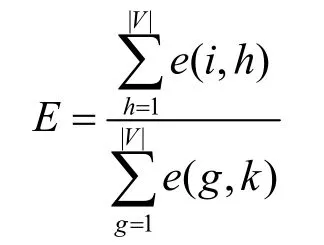
經驗概率表示節點i和k在圖CFG 的實際跳轉概率。為了計算權重參數,本文將跳轉概率分布和經驗概率分布之間的距離函數作為目標函數,通過計算2 個概率之間 KL(Kullback-Leibler)距離,得到損失函數O1。
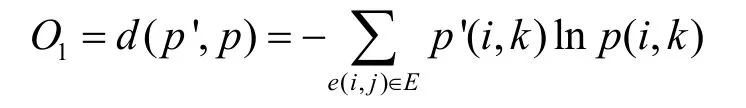
全局跳轉結構定義了代碼塊和CFG 中其他節點的連接情況,以及該代碼塊在CFG 中的上下文。本文定義全局跳轉結構的連接概率為
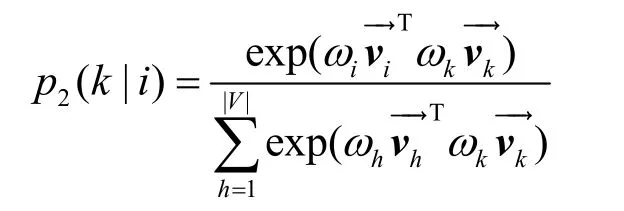
其中,|V| 表示節點的個數。為了保留圖CFG 中的全局跳轉結構,需要上下文條件概率分布接近于經驗概率分布,上下文經驗概率為
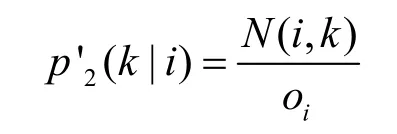
其中,oi表示節點i的出度。同樣根據KL 距離定義以下的損失函數。
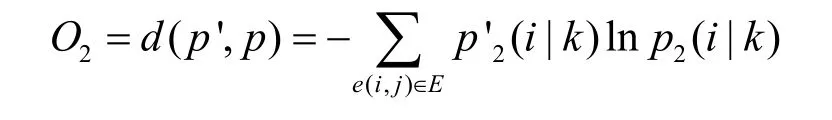
Pentagon 在編碼函數之前,需要先計算每個節點的權重ωi。根據一級跳轉結構和全局跳轉結構獲得的損失函數O1和O2,對CFG 中的所有邊進行取樣,然后對目標函數進行求導,如式(3)所示。
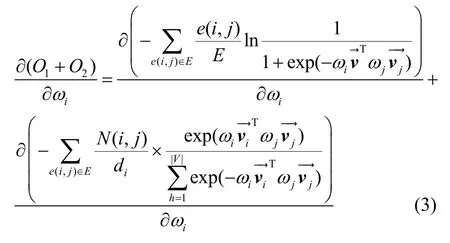
由于損失函數是凸函數[19],當式(3)中導數為0時,可得到損失函數的最小值。令其一階導數趨近于0,求得所有的權重參數ωi。然后,使用權重序列Ω={ω1,ω2,…,ω n}編碼整個CFG 獲得函數的特征。
3.4 Pentagon 的單調性
由Ω編碼 CFG 結構計算的函數特征為。編碼過程需要確保每個特征向量能唯一表示一個函數特征。
函數特征由?組成的一系列的線性等式函數計算而得。由于不同的CFG 有不同的跳轉結構,所以當?不同時,即有不同的線性等式,可以使用反證法來證明單調性。假設不同的CFG 有相同的特征,即對于CGFi和CFGj考慮到節點個數不同其?也不同,本文使用反證法,假設2 個CFG的節點個數相同,根據和式(1),得到式(4)。
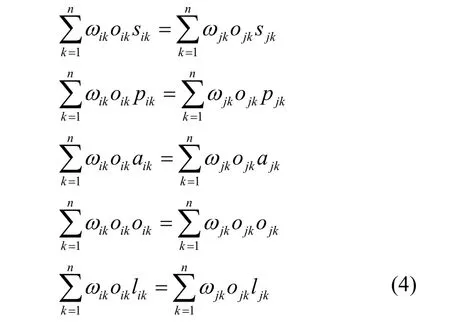
其中,n表示CFGi和CFGj的節點的個數,ωik表示CFGi中的節點k的權重。由于式(2)中,sigmoid 是單調函數,并且當2 個CFG 的結構不同時,這2個CFG 的實際邊分布概率也不相同,即pi≠pj,p是單調函數,則對任意k,CFGi和CFGj中每個節點的權重ωik≠ωjk。當節點的數目相同時,節點的序列集是相同的,但是每一對有相同的調用序列的函數對都有不同的權重參數序列,并且由于CFG的結構不同,即oik≠ojk且lik≠ljk,因此,式(4)不成立。
通過上述反證法,證明了不同的CFG 能編碼為不同的特征,Pentagon 編碼的函數是單調的。證畢。
3.5 CFG 編碼舉例
根據圖2 提取的原始CFG,以下用i,j表示該CFG 中基本代碼塊的編號,首先根據一級跳轉結構和全局跳轉結構計算權重參數,具體的計算過程如下。
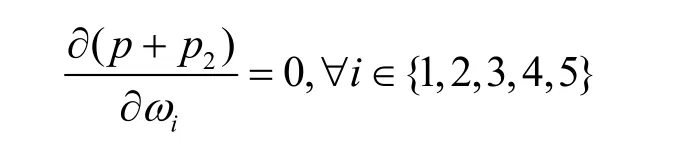
考慮到kω iωj?1,令
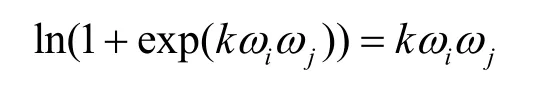
并且CFG 結構中最后一個出口節點的權重ω5=0,然后對導數兩邊同時取對數,有以下的等式。
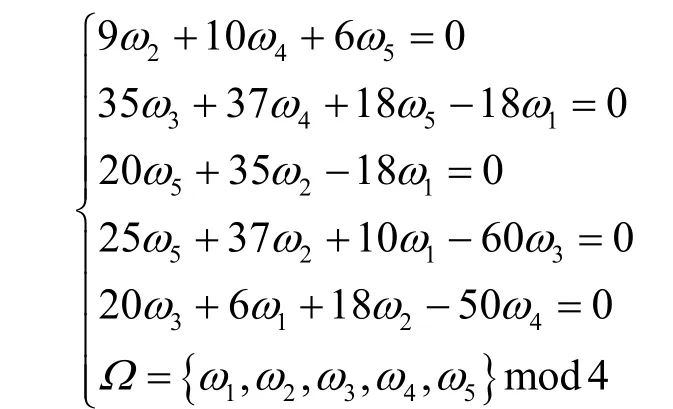
最后,得到權重參數為Ω=[1,2,3,1,0],計算函數的特征如下

3.6 基于函數編碼特征的App 表示
一個完整App的smali文件中包含了很多函數,每個函數被編碼成一維向量特征根據App 中所有函數的編碼特征,獲取每個App 的矩陣表示A,對于不同大小的App,所包含函數的個數m不同,由于App 中會有重復函數,重復函數的字符串特征和CFG 拓撲結構相同,重復的函數編碼表現為矩陣A中有相同的列。
大量的重復函數需要重復比對,降低了效率和正確率。根據統計調研,App 所包含的函數個數集中在2 000~20 000,實驗的預處理過程首先要刪除重復的函數。使用python 庫的numpy 包中的“unique()"函數來刪除每個App 矩陣中的重復函數。最后App 的矩陣表示為
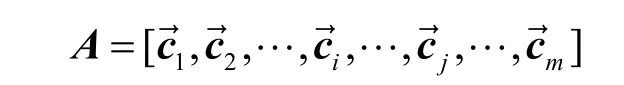
4 Pentagon 的第三方庫函數過濾
App 的代碼中一般包含了許多相同的第三方庫函數,這些相同函數不能作為克隆依據,克隆檢測方案需要過濾這些第三方庫函數。本節描述如何根據聚類算法刪除第三方庫函數。
假設App 數據庫足夠大,并且第三方庫函數在許多App 中都被使用。由于編碼之后的函數特征能夠單調表示App 中的函數,這些函數特征可用于過濾第三方庫函數。為了提高效率和準確度,本文主要通過兩大步驟來過濾第三方庫函數:第一步根據每個函數特征對應的平均權重參數進行粗粒度過濾;第二步在第一步的基礎上,進行嚴格比對聚類。具體如下。
第一步,統計所有函數中相同ω出現的頻率,使帶有相同的ω的函數特征聚集在同一類中,第三方庫函數會被聚集到一個遠遠大于其他類別的類中,計算所有不同ω的類中的函數個數,選取其中聚類函數個數在前60%的聚類作為下一步需要比較的對象。第二步,實施嚴格比對,只有當2 個函數向量特征完全對應相同時,才會重新將這些函數放置到同一類別中,最后將聚類中函數數目較多的一些函數作為第三方庫函數,刪除每個App 表示矩陣中包含這些第三方庫函數的特征,剩下的就是App 核心功能的函數。
5 Pentagon 克隆決策
Pentagon 系統克隆決策由2 個層面的相似度比較功能構成,首先是函數級別的特征相似度比較,其次是App 之間的相似度比較。
5.1 函數特征相似度比較
本系統使用余弦相似度函數進行相似度計算,每個函數特征向量有5 個值。任意2 個函數的特征向量的相似度定義如下
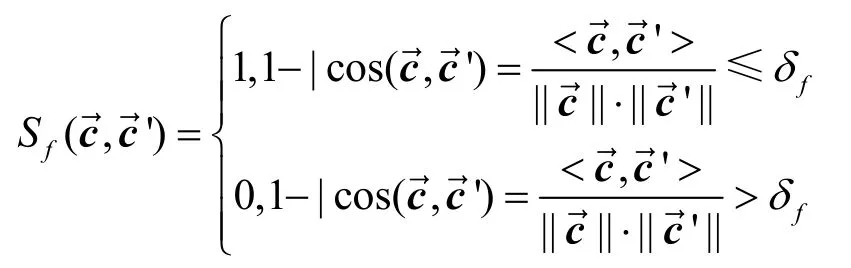
其中,δf表示函數之間差異度閾值。如果2個函數相同,則Sf=1。
根據Pentagon 的函數特征編碼過程,如果修改了原始執行代碼塊中操作碼的一小部分,函數特征的編碼結果不會更改過多;如果改變某一個代碼塊中操作碼的執行順序,同樣也不會過多地改變函數特征;但如果整個CFG 的跳轉結構發生了大量的變化,或者代碼塊的統計特征改變了很多,對函數特征就會產生相應的影響。
5.2 App 相似度比較
函數層相似度比較用于檢測相似的App,但是相似的App 不一定是克隆的App。有以下2 種情況不屬于App 克隆。1)2 個App 中,一個App 相比另一個App 有超過某一固定數目的不同的核心函數。2)App 來自相同的作者,僅是不同的版本。
首先,比較2 個App 中函數的個數。Appa和Appa′中包含的函數個數分別為|c|和|c′| 。如果
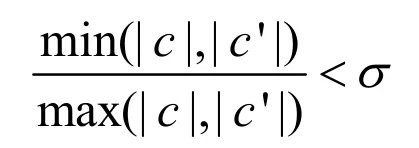
則判定這2 個App 不是克隆的。其中,σ是任意2個App 的函數數目比例常數,具體根據實驗App中的函數數目決定,。
其次,需要通過使用函數層的相似度來比較App 的相似度,具體計算式如下
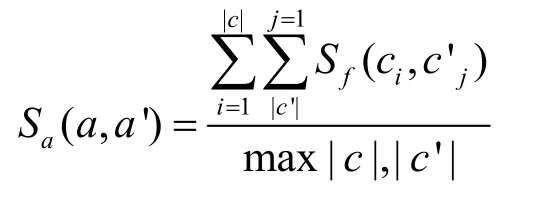
設定δa是App 相似度閾值,如果S a>δa,這2個App 定義為克隆App。
6 性能測試與分析
本文實驗分為以下3 個主要部分:App 中所有函數CFG 特征提取、函數編碼、App 克隆檢測。在準備階段,使用Python 語言編寫爬蟲程序,該程序自動在6 個Android 市場中下載App。然后,使用Androgurad 工具,將App 文件反編譯為smali 文件。根據smali文件提取每個函數的CFG,使用Pentagon對每個函數的CFG 進行特征編碼。由于函數間的編碼互不影響,Pentagon 能夠并行編碼每個App 中的函數。在克隆檢測部分,比較2 個待檢測的App中的所有函數,來確定這2 個App 是否為克隆App以及其中具體的克隆函數。
本文提出的原型系統在Linux 平臺實現,并且添加了對OS X 平臺的支持。在應用程序預處理模塊,使用了3 個開源工具Androguard、Keytool、Dex2jar。Androgurad 工具用來反編譯App 產生原始CFG,Keytool 用來提取應用程序的簽名信息,Dex2jar 用來將得到的Dalvik 字節碼文件反編譯成JAR 包。通過編寫腳本,將這些工具組合成一個自動化的工具鏈,可以批量對應用程序進行預處理。Pentagon 特征提取和相似度分析主要用Python 來實現。App 樣本庫的特征提取后保存在云端文件系統中,所有應用的預處理和特征提取只需要進行一次。
6.1 實驗環境與數據來源
本文共進行了2 個階段的實驗,第一階段是小規模實驗,用來驗證第三方庫函數過濾的效率及本文方法的準確性;第二階段是大規模實驗,用來測試系統的可擴展性和性能。實驗數據集包含以下幾個數據庫:游戲App 數據庫、社交App 數據庫、娛樂App數據庫、金融數據庫和其他數據庫。在這5 個數據庫中共下載了152 789 個應用程序,其中,包含的函數個數為7 490 721 877 個。數據庫1 中函數個數為1 596 096 888 個,數據庫2 中函數個數為1 142 135 436 個,數據庫3 中函數個數為2 151 246 841個,數據庫4 中函數個數為1 120 121 321 個,數據庫5 中函數個數為1 481 121 391 個。
測試數據包含兩部分。一部分是從網絡中下載的克隆App,從知名的Android 第三方應用市場以及各種Android 論壇下載有可能是重打包的應用(通過名字、描述來判斷,如破解版、修改版等),并且從其他官方市場尋找可能對應的原版應用。另一部分是通過人工重打包應用獲取的克隆App。對下載的合法應用進行一些簡單修改(更改變量和函數名、添加刪除代碼和第三方庫等),最后將修改后的應用重新簽名并且打包。本文選取大小在 50 KB 到 68 MB 之間的App 做實驗,這個區間的App 大小基本能代表Android 市場中一般應用程序的大小。在實驗之后手動安裝和檢查應用代碼來驗證結果的準確性。實驗運行在12 核 1.6 GHz 的Linux 服務器,內存為16 GB,硬盤為7 TB,同時開啟4 個線程并行處理。
6.2 實驗比較
在函數層的克隆分析方面,本文在準確率和效率上對比目前一種較好的基于函數層的App 克隆檢測方法:基于CFG 質心運算提取特征的App 克隆檢測方案Centroid[23]。在App 克隆檢測層面,本文對比當前較好的工作:FSquaDRA[12]、Wukong[24]、Centroid[23]。
6.3 重復函數刪除
圖3 表示刪除重復函數前不同函數數目的App出現的次數,也就是對應于某一具體函數數目App的個數,橫坐標表示每個App 中函數的數目,縱坐標表示這一函數數目的App 的出現頻率。圖4 表示刪除重復函數之后不同函數數目的App 出現的次數。可以看出在整個樣本中函數的個數下降了17.07%~67.27%。某些App 中,重復函數的個數超過了一半,一些大的App 中包含了更多的重復函數。可以看出,重復函數的個數和App 的大小呈現下降的趨勢。一些只含有20 個函數的App 中基本沒有重復函數。刪除一個含有17 863 個函數的App中的重復函數的平均時間少于1 s。
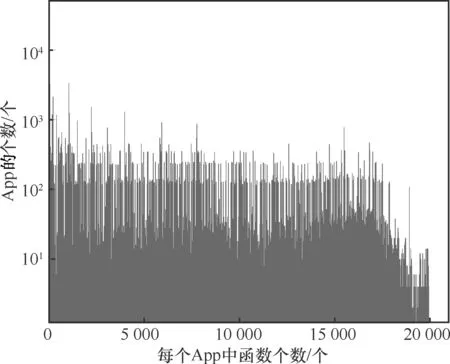
圖3 刪除前的函數分布
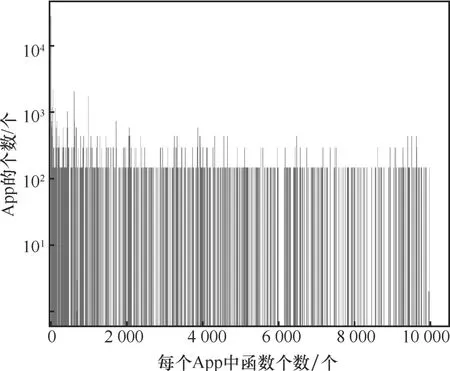
圖4 刪除后的函數分布
6.4 第三方庫函數過濾
本節實驗對數據集中所有App 編碼的函數特征進行聚類,用于第三方庫函數的過濾,前文說明了不同的權重代表不同的函數,即如果則i和j表示2 個不同的函數,首先,計算所有不同的權重的出現次數。圖5 中分別展示了所有ω值對應的所有函數特征的函數數目分布,以及所有ω值對應的不同的函數特征的函數數目的分布。比如,同一個ω可能出現多個函數特征,即有ω的函數特征可能相同也可能不同,因此要區分同一個權重ω對應的函數特征是否相同。圖5 橫坐標表示出現的所有ω的值,縱坐標表示權重為該ω的函數數目,也就是函數的出現頻率。從圖中可以看出,出現頻率較高的函數數目的權重ω為1~103。然后選擇權重ω為1~103對應的函數特征作為第三方庫函數的特征。其次,在相同ω的聚類中嚴格比較函數特征,選取聚類中函數各數較大的類作為第三方庫函數,并查看這些函數特征對應的函數名和函數可執行代碼。實驗顯示函數個數在前十的聚類都是安卓支持庫,或者廣告支持庫,這些都不在白名單中。為了刪除第三方庫函數,在聚類之后需要求得聚類大小的閾值作為下一步聚類的條件。
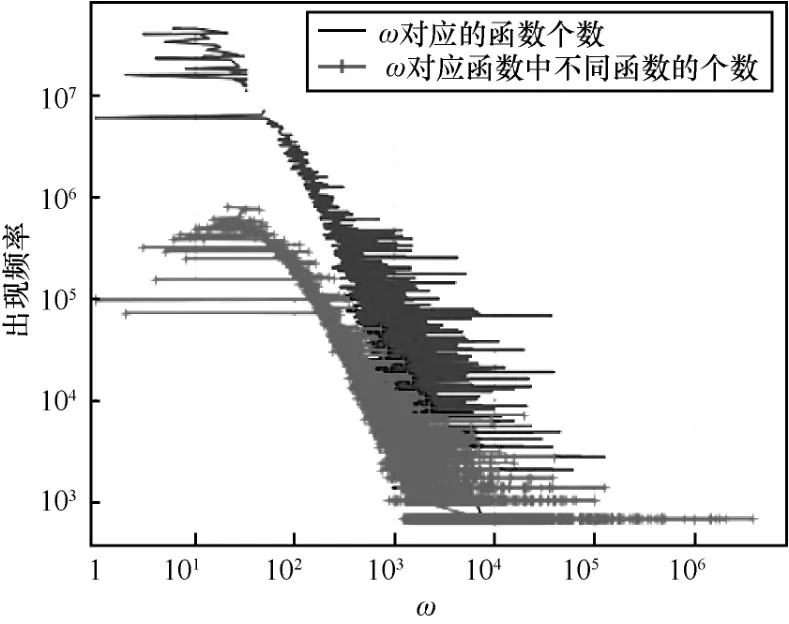
圖5 不同權重中所有的函數和不同的函數的數目分布
本實驗使用2 種方法來決定第三方庫函數的過濾閾值。首先,下載300 個App,這些App 中包含超過14 個不同的已經確定的第三方庫。手動反編譯這些App,對相應的函數進行標記,在最后的檢測結果中,將出現的頻率數目的前29.02%的聚類作為第三方庫函數進行過濾。其次,將所有數據庫的App 的函數特征進行聚類,選擇大小在前29.02%的聚類,手動檢測這些類別的函數特征對應的函數,標記為“第三方庫函數”“關鍵代碼”或者“不能確定”。根據這些標記判斷聚類閾值選擇的準確性。
結合上述的2 種方法,最終選擇聚類大小的數目為1 610,如果相同函數特征的聚類數目超過了1 610,則判定為第三方庫函數。過濾了第三方庫函數后,整個App 數據庫中的函數數目下降了79.26%。過濾前,有超過63.60%的App 中包含的函數數目在504~5 973 之間,平均每個App 有2 259個函數;過濾后,大部分的App 包含的函數數目為84~1 976,平均每個App 只有627 個函數,超過249、419、203 個函數被過濾。
6.5 準確率
為了表示App 函數檢測的正確率,用以下2 個參數來評估實驗的好壞,即TPR(true positive rate)和FPR(false positive rate),TPR 是在搜索問題中正確找到克隆函數的比例,FPR 表示找到的克隆匹配是不正確的匹配函數的比例,由TPR 和FPR 的數據組成的曲線為ROC 曲線。從測試數據庫隨機選取一些檢測樣本序列q,一個樣本實際上有m個克隆函數,在樣本函數數目L中,如果認為前F個函數是檢測出來的克隆函數,實際上,F個函數中正確匹配的克隆函數有c個,剩下的L-c,就是誤報率。設當F越大的時候,TPR 和FPR 都會逐漸變高,這兩者的相加值不為1。
由于本文是基于函數層編碼的App 克隆檢測方法,為了說明本文的準確率,本文將和目前的函數克隆檢測的方案進行比較,根據本文提供的測試集,將這些測試集的App 反編譯的函數編碼成一維特征后作為輸入,進行App 克隆搜索檢測,同時與本文前面提到的方法進行比較,圖6 表示數據庫中不同大小的App 對應的數目。圖7 表示設置不同的函數向量差異閾值時,對應的失敗率大小。從圖中可以看出,如果函數差異閾值小于0.005 7,則在函數層的檢測失敗率為2.4%。如果函數差異閾值大于0.02,則函數的錯誤率大于20%。函數差異閾值越大,則FPR 越大。閾值需要確保相似的函數有相近的特征,由于Pentagon 編碼的特征是單調的,不同的函數之間的特征差異比較大,如果閾值被設置得過大,那么相似的函數就被認為不同的函數,這樣就會增加FPR。
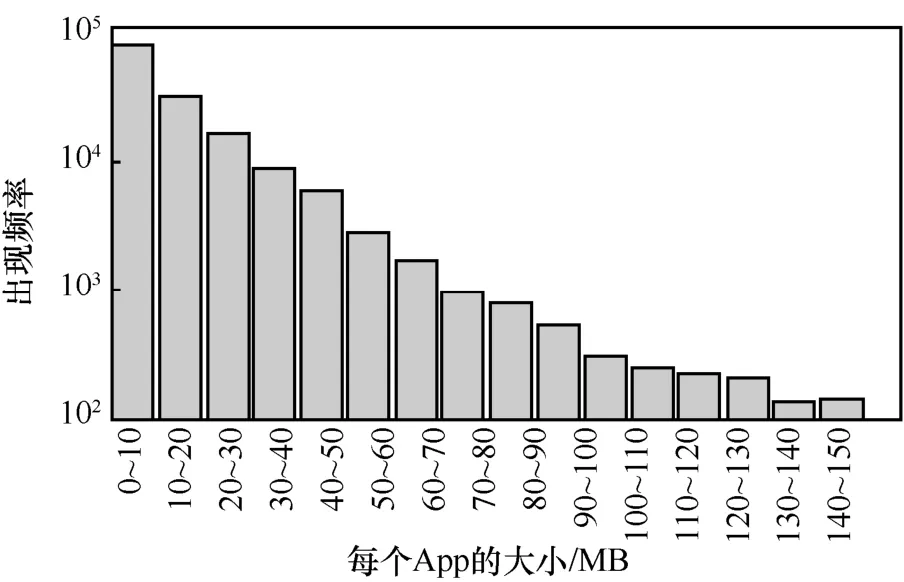
圖6 不同大小的 App 的總數
Pentagon 系統在當前已經投放市場正在使用的游戲App 中檢測發現了2 個克隆樣本(為了保護版權,本文不對這2 個App 樣本進行具體說明)。這2 個App 在應用市場都顯示為具有自主知識產權,但經過本文系統檢測發現,它們之間存在克隆關系,并且通過動態調試,也確認了這2 個App 中存在克隆關系,表現出本文方案的實際應用效果。
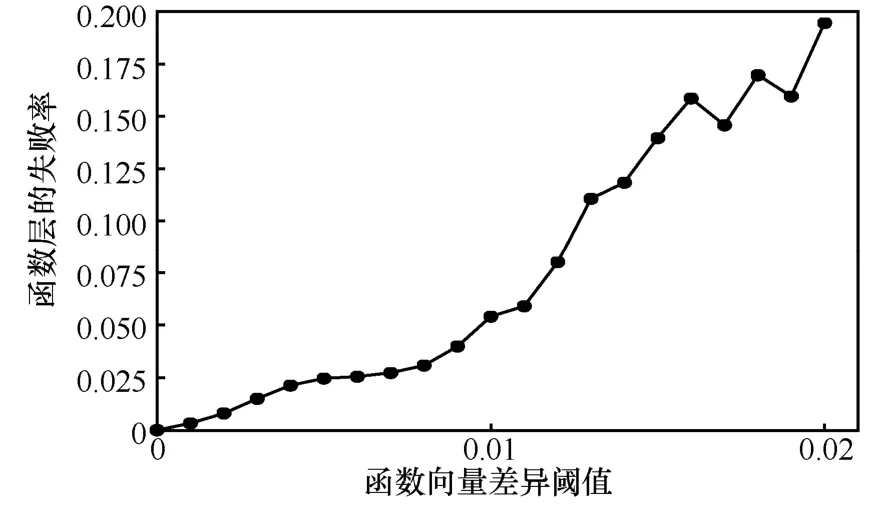
圖7 錯誤率和閾值之間的關系
圖8 展示了實驗結果的ROC 曲線,可以看到本文提出的 Pentagon 編碼方式的正確率高于Centroid 方案,取App 差異閾值為圖7 所示的約為0.01 時候,根據ROC 曲線可以看到檢測的準確率可以達到97.6%。由于Pentagon 是單調的,而且對函數的信息編碼得更完整,不僅獲取了每個代碼塊的主要統計特征信息,還獲取了每個CFG 的結構特征,所以Pentagon 的準確率很高。Centroid 并不是嚴格單調地表示特征,相比較,本文提出的編碼方案能更正確地表示函數的特征。
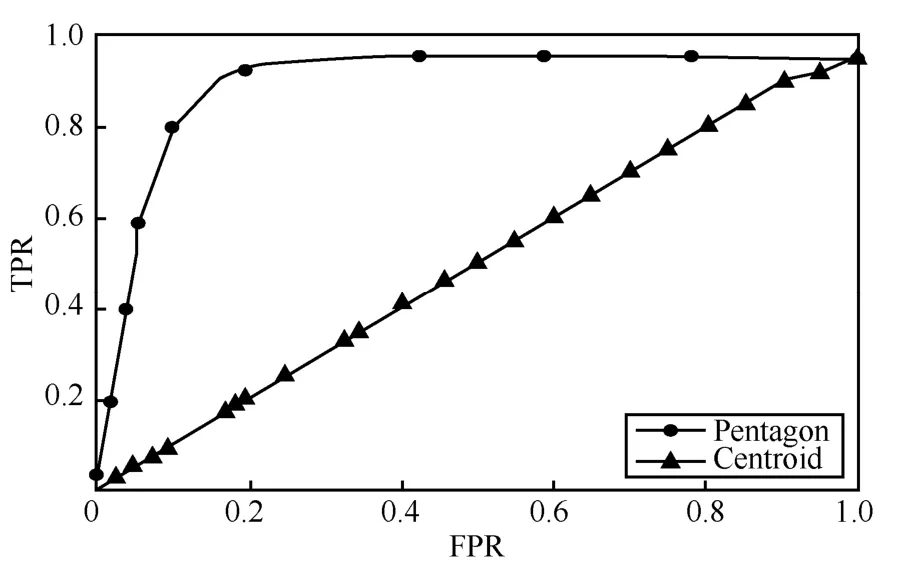
圖8 ROC 曲線
6.6 函數層效率
本文主要從以下3 個方面對系統效率進行比較:CFG 特征的提取效率;Pentagon 編碼時間;函數克隆檢測時間。這三方面指標表示App 克隆檢測的預處理效率。本文有關效率的實驗使用全部的152 789 個App,對所有的App 提取特征進行存儲,并生成用于App 克隆檢測的數據庫。
1)CFG 特征提取時間。圖9 展示了Pentagon 的CFG提取時間。該特征提取時間不包含App生成CFG時間,因為Pentagon 的編碼只需要給CFG 的每個代碼塊提取5 個值,Centroid 給CFG 的每個代碼塊提取3 個值,但Centroid 在給CFG 中的基本代碼塊進行編號的過程稍微復雜一些,所以需要更多的時間,但總體來說,2 種方案的CFG 特征提取時間相差不大。
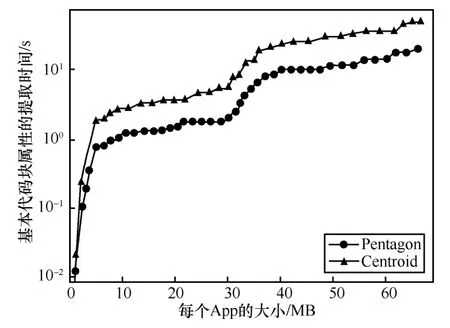
圖9 每個函數的 CFG 中代碼塊的特征提取時間
2)Pentagon 編碼時間。圖10 展示了Pentagon生成時間隨著函數的數目增加而增長。Pentagon 將APP中一個函數的CFG編碼為一個特征,Pentagon是一種線性計算的編碼,當函數個數有20 000 個時,即使串行編碼,Pentagon 的編碼時間僅僅需要1 h。由于Pentagon 的編碼方式是解耦合的,因此利用并行的方式可以大大縮短編碼時間。
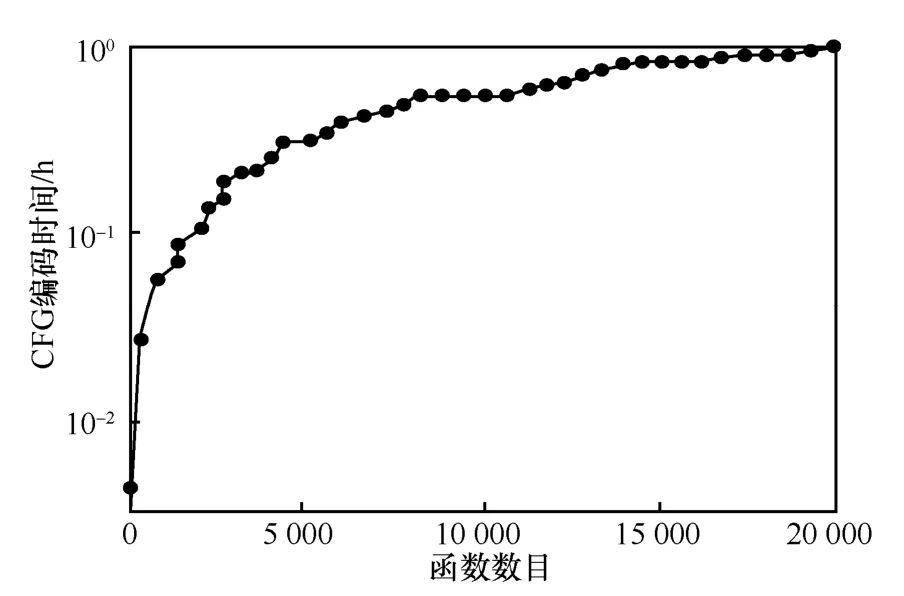
圖10 Pentagon 編碼時間
3)搜索時間。圖11 表示Pentagon 的編碼特征用于App 克隆檢測出的搜索時間,使用6 個不同度量的樣本大小來檢測搜索效率,這6 個文本中函數個數c為1 03~108,隨機選擇1 到10 000 個函數序列作為提交的搜索序列,平均搜索時間隨著函數數目的增加持續增長,在1 000 個函數中平均的搜索時間為7.9 ×10-9s。
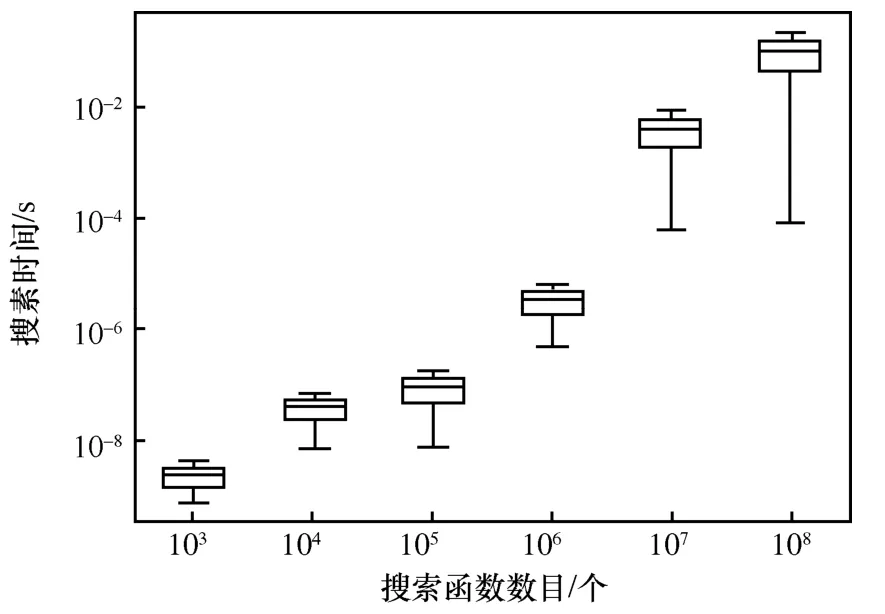
圖11 Pentagon 函數層的克隆搜索檢測時間
6.7 App 克隆檢測時間
當獲取了所有的App 函數特征之后,先按照本文方案刪除第三方庫函數,每個App 大概需要0.01 s去除重復的函數,刪除了第三方庫函數之后,檢測一個App,需要比較檢測的App 和待檢測的App之間所有的函數,實驗表明,本文方案計算2 個App 之間的相似值需要0.079 s。表1 比較了當前幾個比較好的App 克隆檢測方案FSquaDRA[5]、Wukong[20]、Centroid[4]和本文方案之間的效率。
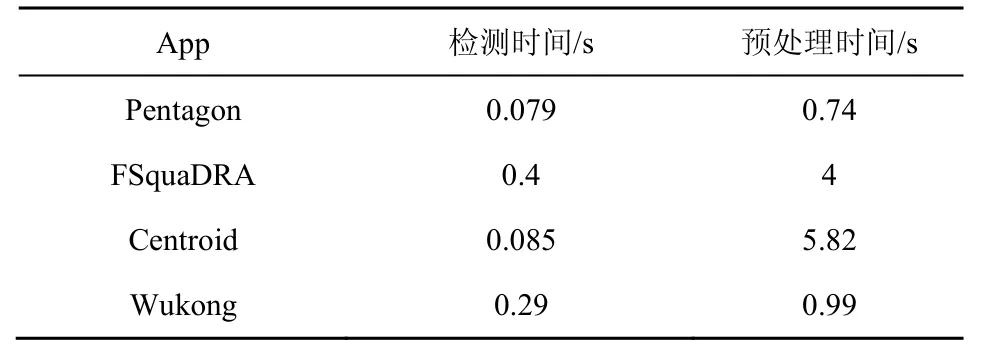
表1 App 克隆檢測效率
7 結束語
與現有的App 克隆檢測方案相比較,本系統具有以下2 個突出的優勢。1)在對第三方庫函數過濾的方案中,不局限于已有的白名單進行過濾,過濾更為精確有效。現有方案使用白名單通過App 函數中的包名來過濾第三方庫函數,在準確性上面存在問題,因為首先不可能完整全面地確定第三方庫函數,其次,混淆可能改變包函數的名字,使過濾方案失效,本文發現部分第三方庫函數沒有具體的名稱。 2)本文方案不僅考慮了基本代碼塊之間的靜態特征,同時也考慮了CFG 中代碼塊之間的跳轉結構,現有的App 檢測方案主要考慮靜態特征,比如提取不同的API Call 調用順序來檢測克隆,這些特征同樣會因為混淆而失效。本文的方法采用CFG 函數結構編碼,并融合代碼塊屬性特征,相比較其他方案在克隆分析上可靠性更高,實驗結果也驗證了上述結論。
Pentagon 能夠快速應用于云環境下大規模App函數層克隆檢測,實現了更準確高效地查找克隆App 以及定位具體克隆函數的目標,對維護移動互聯網應用知識產權的良好生態具有積極支撐意義。下一步將在特征自動化提取、第三方函數庫優化、跨平臺克隆檢測等方面做進一步工作,以促進Pentagon 系統應用推廣。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
