廣電監管數據資產管理系統的關鍵技術及實現
2019-08-28 07:12:12王洋
中國傳媒科技 2019年7期
關鍵詞:數據庫
文/王洋
前言
廣播電視監管事業經歷了從模擬到數字、從地面到衛星、從單機到網絡等一系列技術體系的重大變革,隨著技術的不斷發展,廣播電視節目的頻率數、頻道數、播出時長也在快速增加,開路電視、有線電視、衛星電視、IPTV等多種傳輸方式也在快速出現,因此,監管工作所面臨的數據量在急劇膨脹,早期工作中是以結構化的業務數據為主,主要是廣播電視節目在播出和傳輸過程中的相關技術性指標,廣播電視內容以實時監聽監看為主,錄音錄像保存時間很有限。在過去的十幾年中,大規模海量數據的存儲和處理方案在商業公司和開源軟件社區中涌現出來,這源于互聯網的發展導致互聯網公司迫切需要發展適合于大數據環境下的全新技術體系,達到低成本、易擴展、并發性高、兼容不同類型數據的目的。現實的應用需求使得一些技術方案快速成熟,這樣就為廣播電視監管工作提供了可行的解決方案,大量音視頻節目的存儲成為可能。與此同時,海量數據處理技術和分析技術的發展也能夠滿足不斷提升的監管業務需求。
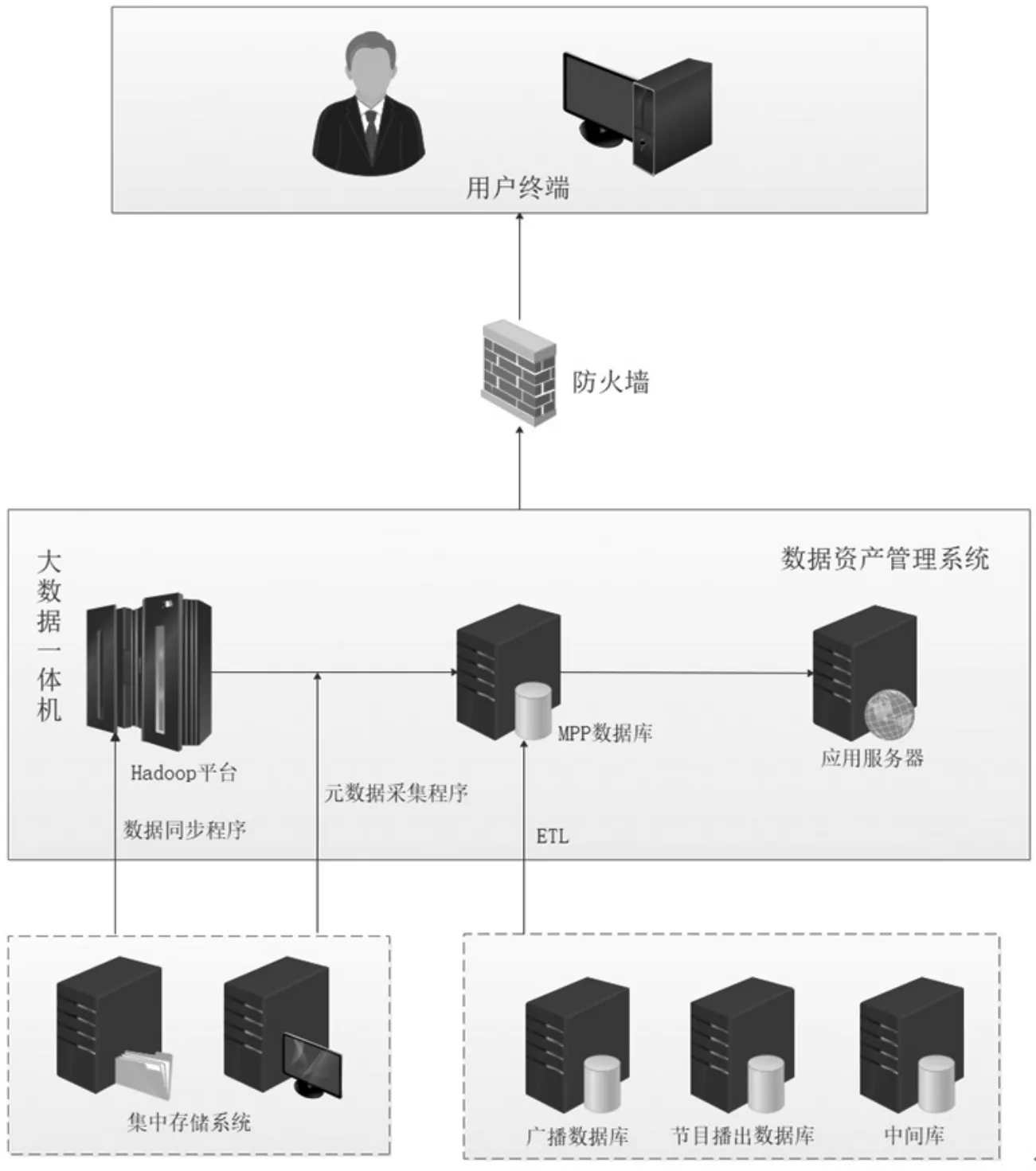
圖1 數據資產管理系統技術架構圖
就目前來講,廣電監管工作主要用到兩大類數據,一類是對應廣播電視節目的音視頻文件,另一類是相關監管業務數據,如廣播效果情況、電視節目播出表等,前者為非結構化數據,后者為結構化數據。音視頻文件的存儲容量已經達到PB級,每天的增量達到了TB級,包括了大部分的衛星和有線廣播電視節目,由于存儲容量已達極限,需要定期從存儲中刪除舊的音視頻文件,業務數據雖然容量只是GB級,但某些數據增長快速,已經達到億級的條目數。隨著以上兩類數據的積累,對數據存儲的擴展性和安全性要求逐漸提升,必須要在數據讀取性能和可靠性之間取得平衡,需要以較低成本較簡單的操作實現較高的并發訪問和分布式存儲。此外,海量數據帶來數據分析的需求,需要新的技術方案彌補現有系統數據倉庫能力不足的問題。最后,類似Oracle這樣的傳統商業型數據庫雖然能很好地滿足關系型數據管理和分析的需求,但使用成本較高,分布式架構操作復雜,源代碼不開放,存在數據資產的安全性問題。綜上所述,我們需要針對音視頻文件和相關業務數據組成的數據資產管理需求,利用開源軟件社區的成熟大數據技術方案彌補已有技術體系的不足,實現性價比更高、更加安全的數據資產管理系統。
1.技術架構介紹
各個監管業務系統之間彼此封閉,每個系統內形成封閉的回路,沒有達到有效的數據共享,因此,首先需要對數據進行有效整合,消除數據孤島,建立統一規范的數據標準,形成對數據的全景統計,在此基礎上開發可視化數據統計分析功能,實現對數據資產的準確掌握和有效管理,輔助建立跨系統、跨部門、跨地區的溝通協調機制。下圖是根據上述需求形成的技術架構圖,目前已經完全實現并正常運行。
下面一層是原有的數據存儲系統,包括音視頻數據和業務數據,中間一層是以大數據一體機為形式的新系統,包括用于存放音視頻文件的Hadoop平臺和存放文件元數據和業務數據的MPP數據庫,基于這些數據建立數據資產管理系統,包括數據資產目錄、數據存量統計、數據增量統計、數據流量監控、作業監控等功能,這些功能經過防火墻在上面一層呈現在用戶終端上。
集中存儲系統采用的是浪潮的Lustre系統,存放著歷年的廣播電視節目音視頻文件,廣播數據庫是指廣播播出的技術性業務數據,節目播出數據庫是指廣播電視節目編目數據,中間庫是其他系統同步過來的技術性業務數據,這三個數據庫均采用Oracle一體機,以RAC(Real Application Cluster)方式進行存儲。以上兩類數據經過大數據一體機中的Hadoop軟件和ETL工具,實現了數據轉移和提取,形成數據資產管理系統可以直接利用的數據源。
2.關鍵技術及實現
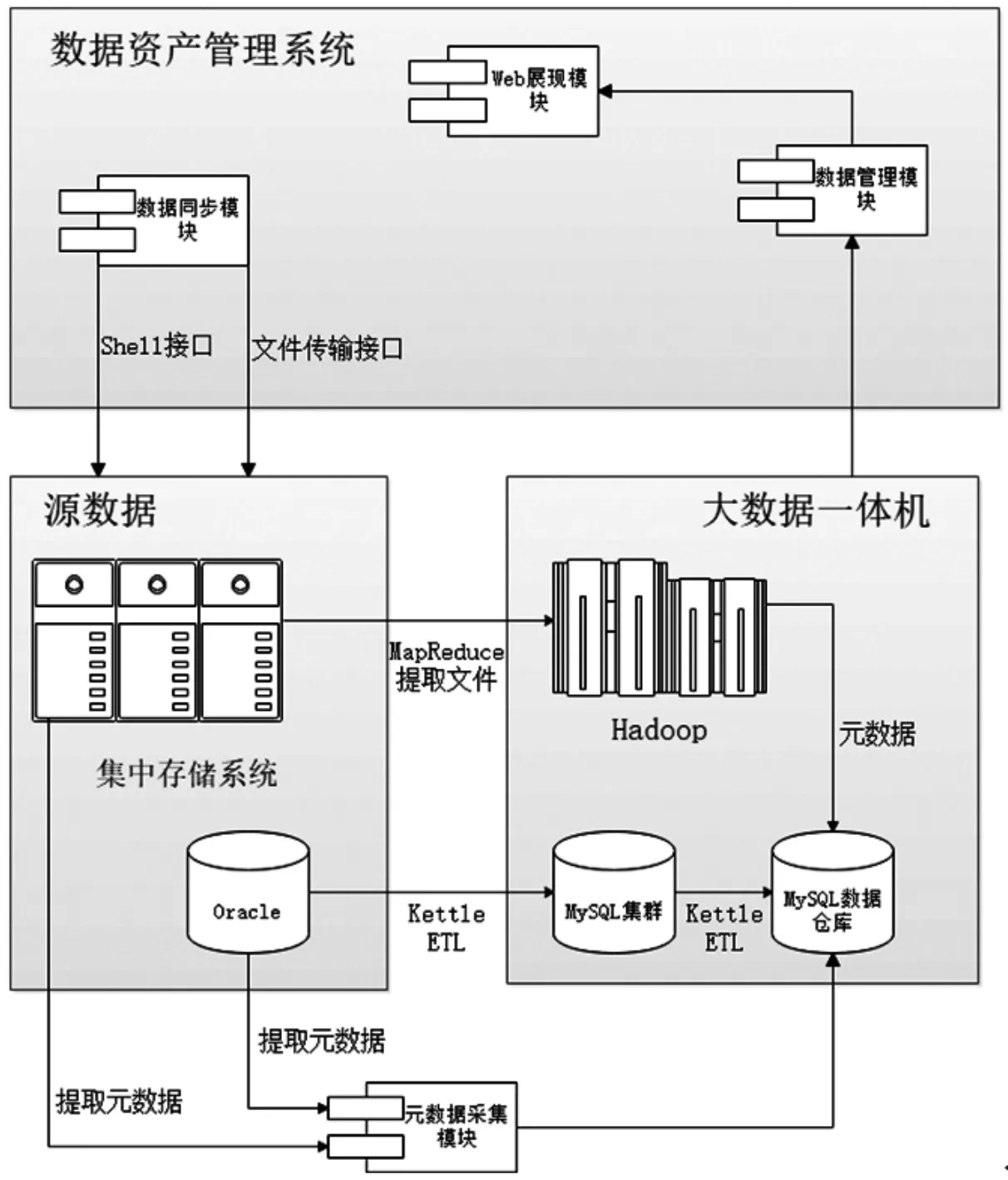
圖2 數據資產管理系統軟件結構圖
根據技術架構的要求,我們接下來要決定采用哪些關鍵技術實現其中的數據同步、ETL等功能。下圖體現了不容軟件模塊之間的數據流向和用到的一些技術或產品。
集中存儲系統中的Lustre系統是一種基于Linux的開源分布式文件系統,Lustre的最大特點是讀寫能力很強,特別是對于大文件,利用Stripe條帶化技術實現文件的并行訪問,元數據服務器存儲文件的元數據信息,對象存儲服務器用于存儲文件,Lustre的主要問題是對數據的保護比較差,底層的對象存儲結構不支持數據的備份和回復,另外,元數據存在單點故障的問題,采用了共享存儲層支持主備切換,一旦共享存儲層出現問題導致元數據無法訪問,進而影響整個系統。我們選擇了Hadoop 2.0來讀取和存放音視頻文件,HDFS支持多個副本在不同節點的存儲,可以實現數據的保護,并具有數據校驗的功能,文件的操作雖然不像Lustre支持POSIX接口,只能通過API實現,讀取性能不如Lustre,但適合需要長期保存的文件以及建立數據倉庫。另外,HDFS生態環境非常豐富,有很多強大的開源框架可以使用,這一點要比Lustre好很多。在這個項目中我們使用了2個管理節點和20個數據節點,管理節點使用Zookeeper實現平臺集群的負載均衡,數據節點通過HDFS存放了數百TB的音視頻文件。
集中存儲系統文件信息讀取的接口采用MapReduce實現,MapReduce程序對集中存儲系統的內容進行解析,提取出集中存儲系統的音視頻文件的元數據,并完成兩項任務,一是將音視頻文件同步到大數據Hadoop平臺上;二是獲取到音視頻文件的屬性信息并同步到MPP數據庫中。數據同步管理策略包括文件同步和元數據同步兩個方面,元數據同步每15分鐘進行一次,主要是通過find命令查詢當天日期目錄下最近一個小時新增的文件,并將元數據保存到數據庫中。同步定時任務通過Linux的crontab命令實現,元數據抽取的日志文件位于與jar包同級的logs文件夾里。文件同步每天晚上0點進行,根據數據庫中前一天的元數據信息,將前一天所有的文件復制到HDFS中,在主要文件完成之后根據文件增加情況和同步需求不定期執行文件同步。
對于結構化數據的存儲我們采用了基于MysSQL的MPP(Massively Parallel Processor)數據庫,MPP是大規模并行處理的意思,系統由很多松耦合處理單元組成,每個單元內的CPU都有自己的私有資源,在每個單元內都有操作系統和管理數據庫的實例副本。MPP架構數據庫具有的特征是任務并行執行、數據分布式存儲、分布式計算、私有資源、橫向擴展和Share Nothing架構。橫向擴展是MPP數據庫的主要設計目標,MPP數據庫支持嚴格的關系模型,比如SQL92、加擴展、加存儲過程,支持事務、保證數據強一致性,所解決的問題包括提升數據處理性能和數據處理量。與各個節點使用自己私有資源的Shared Nothing架構不同,原有數據庫采用的Oracle RAC屬于Shared Disk架構,各個節點使用自己的CPU和內存,磁盤存儲共享,也就是數據共享,當存儲性能達到瓶頸時,增加節點便不能獲得并行能力的擴展,另外,Oracle RAC源代碼不開放,存放于Oracle一體機中,這種一體機價格較為昂貴。
MPP數據庫集群共有6個節點,共分為三類,即管理節點、數據節點和SQL節點。管理節點有2個,作用是管理集群內的其他節點,如提供配置數據、啟動并停止節點、運行備份等,由于這類節點負責管理其他節點的配置,應在啟動其他節點之前首先啟動這類節點,管理節點用命令ndb_mgmd啟動。數據節點有4個,用于保存集群中的數據,數據節點的數目與副本的數目相關,用命令ndbc啟動。SQL節點有4個,用于訪問集群數據,通常SQL節點使用命令mysqld -ndbcluster啟動,或將ndbcluster添加到my.cnf后使用mysqld啟動。管理節點負責管理集群配置文件和集群日志,集群中的每個節點從管理節點檢索配置數據,并請求確定管理節點所在位置,數據節點內出現新的事件時,將關于這類時間的信息傳輸到管理節點,然后將這類信息寫入集群日志。
從Oracle RAC到MPP數據庫的ETL過程采用了開源ETL工具 Kettle,ETL即數據抽取(Extract)、轉換(Transform)、裝載(Load)的過程,它是構建數據倉庫的重要環節。傳統的ETL工具有集中執行、對服務器性能要求高等缺點,針對這些缺點,本項目采用了一種基于分布式原理的ETL技術,該系統在分布式文件系統基礎上實現了集群分布式ETL流程。該分布式ETL系統具有較高的可擴展性和吞吐效率,同時能夠自動實現負載均衡,執行效率高。分布式ETL技術包括四個組件:Spoon、Pan、Chef、Kithcen。Spoon實現了通過圖形界面來設計ETL轉換過程,通過SPoon設計ETL工作的轉換和作業,轉換定義了ETL抽取地源、目標和抽取規則,是ETL的主體,作業控制著轉換的執行,Pan實現了批量運行由Spoon設計的ETL轉換;Pan是一個后臺執行的程序,沒有圖形界面,Chef可以創建任務,任務通過允許每個轉換、任務、腳本等,更有利于自動化更新數據倉庫的復雜工作,任務將會被檢查,看看是否正確地運行了;Kitchen允許你批量使用CHEF設計的任務,例如使用一個時間調度器,Kitchen也是一個后臺運行的程序。分布式ETL集群共有8個節點,2個主節點和6個從節點。
結語
以上我們從業務發展的需要出發,介紹了數據資產管理系統的技術架構和關鍵技術,以及一些具體的實現方式,經過這個項目,音視頻和業務數據資源得到了整合,數據存儲容量更大并且更加安全,而且易于擴展,為進一步的數據挖掘工作奠定了良好的基礎。隨著大數據開源軟件社區新的成熟項目不斷出現,數據資產管理系統可以充分融合新的工具實現功能的不斷增加。
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
