列車在站技術作業時間寫實管理信息系統設計
2019-08-28 01:52:20楊廷宇倪少權陳釘均王柄達
鐵路計算機應用 2019年8期
楊廷宇,倪少權,陳釘均,王柄達
(1. 西南交通大學 交通運輸與物流學院,成都 610031;2. 西南交通大學 全國鐵路列車運行圖編制研發培訓中心,成都 610031;3. 綜合交通運輸智能化國家地方聯合工程實驗室,成都 610031;4. 中鐵上海設計院集團有限公司,上海 200070)
當前,我國鐵路制定的列車在站技術作業時間標準與實際作業時間存在不相符的情況,造成部分列車慣性晚點,降低了列車運行的正點率,影響鐵路運輸服務質量的進一步提高。現階段,列車在站技術作業時間主要依靠專業寫實人員到鐵路現場查定,整個過程復雜、繁瑣,且個體差異較大,已越來越不能滿足鐵路運營管理需求。隨著既有鐵路的提速和高速鐵路的相繼開通運營,對精確查定鐵路行車技術作業時間的要求也越來越高,如何對技術作業寫實數據進行自動化匯總、處理、計算,進而確定各種技術作業的時間標準,成為研究內容。
通過文獻調研發現,國內學者在鐵路行車技術作業時間的機理、流程及模擬仿真方面進行了廣泛的研究,如王健[1]、羅常津[2]、張明[3], 何潔[4],張蘭[5]等人從機制、方法、保障對策、算法等視角研究列車在站技術時間的方案,給出了概要設計;彭文高[6]、冉鋒[7]、岳琦均[8]等人建立了虛擬仿真模型,驗證鐵路行車作業時間,提升了鐵路行車的精度。這些研究都是針對某一個具體的技術作業時間,雖在理論層面形成了一系列的研究成果,卻缺乏系統性,且對實際情況的技術條件考慮較少。國外學者的研究主要聚焦于實踐,如Dewei Li[9]等人以荷蘭火車站為例,基于到發線占用數據模型對列車中間站停站時間進行預估,模型對高峰期停站時間預測的準確率高達85.8%~88.5% ,對平峰期的預測準確率達到80.1%,證明了模型的高相關性。同時,也證明了可以不通過客流數據對列車停站時間進行預測。Wen-jun Chu[10]等人提出基于極限學習機(ELM,Extreme Learning Machine)模型對城市軌道交通列車停站時間進行了分析和預估,證實了其效果優于既有的其它兩個模型。雖然國外學者的模型在精度層面有了顯著提升,但是與我國鐵路在站技術時間的統計分析存在較大的差異。近年來,也有學者提出利用微機聯鎖設備實現鐵路技術作業時間獲取與推算的半自動查定方法,但該方法缺少后端數據管理功能,無法投入高效使用,故仍有必要設計與開發出一套集數據獲取、記錄、匯編、分類與存儲一體化的列車在站技術作業時間寫實管理信息系統。
1 系統設計目標與需求分析
1.1 系統設計目標
列車在站技術作業時間寫實管理信息系統涉及車、機、工、電、輛多個部門,需適應分工細、連續性強、各個部門作業相互制約等特點,其總體設計目標如下:
(1)實現列車在站技術作業時間實時采集、記錄,同時,兼容傳統的數據提交方式;
(2)提出列車在站技術作業時間數據匯總與分層管理辦法;
(3)提出列車在站技術作業時間查定方法;
(4)實現基于用戶權限的列車在站技術作業時間數據差異性共享。
1.2 系統需求分析
1.2.1 業務需求
列車在站技術作業時間寫實管理信息系統的功能性需求可概括為“1主1輔3層次4應用”,系統功能層次如圖1所示。“1主”為一條主線,即列車在站技術作業時間數據的采集、傳輸、處理、查詢與反饋;“1輔”為系統輔助功能,即系統基礎數據(如車站數據、行車數據)與系統基本信息(如用戶信息、權限信息) 的管理與維護;“3層次”為操作員及其車間(科室)層、車站層、鐵路局集團公司(簡稱:鐵路局)層,鐵路局層包含有多個車站,各車站又包括多個技術作業工種,每個工種對應一個科室(車間)及若干名技術作業人員;“4應用”為4類系統使用者—操作員(技術作業人員)、車間用戶、車站管理員、鐵路局管理員,他們分別對應系統的操作員及車間層、車站層和鐵路局層。
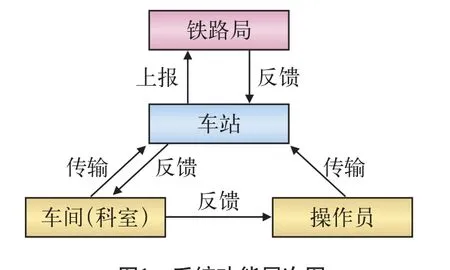
圖1 系統功能層次圖
1.2.2 數據庫需求
(1)基礎信息數據庫:車站基本信息、行車信息和用戶信息。車站基本信息包括:車站名、車站代碼和車站時鐘等;行車數據包括:車次號、停站代碼、列車種類(性質)、計劃到(發)點等;用戶信息包括:用戶工號、用戶姓名、用戶職務及用戶單位等。
(2)技術作業時間數據庫:各單項技術作業時間寫實數據和列車在站技術作業全過程時間數據。以始發普速旅客列車為例,其在站技術作業由圖2所示的列車始發技術檢修作業、上水等平行的單項技術作業組成,每個單項技術作業的耗時即為單項技術作業時間,作業總時分即為列車在站技術作業全過程時間。
(3)業務報表數據庫:用于儲存各層用戶的業務報表信息。
物理結構上看,各車站需要建立一個本地數據庫(局部數據庫),管理本站內部數據,同時,將處理好的數據向鐵路局層提報。鐵路局需要建立和管理一個匯總所有信息的全局數據庫,還要滿足所轄各站及車間工作人員間的環比查詢需求,故需使用分布式數據庫。該數據庫還需充分考慮數據存儲、維護和操作等功能性需求與訪問權限、加密管理和日志管理等安全性需求。
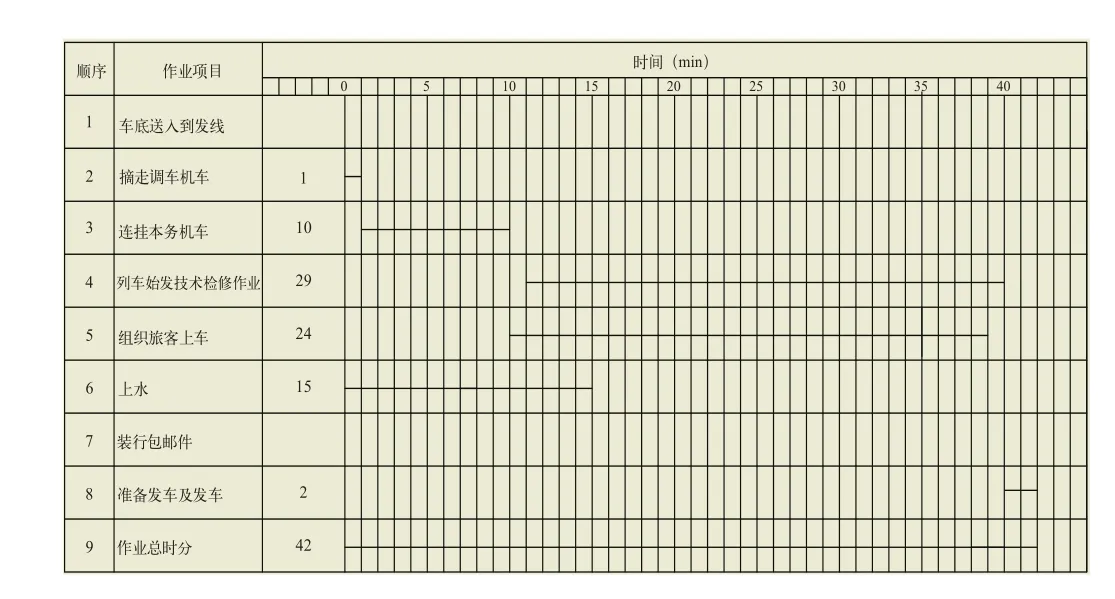
圖2 始發普速旅客列車技術作業流程
2 系統架構
基于安全性要求高、人機交互頻繁、用戶群組固定等特點,列車在站技術作業時間寫實管理信息系統采用C/S架構。
2.1 系統總體結構設計
系統總體呈如圖3所示的“串-并行”結構。鐵路局級、車站級與操作員級分別對應系統功能性需求的3個層次,而車間作為技術作業時間的最終查定與運用者,與前3個層級呈平行關系。
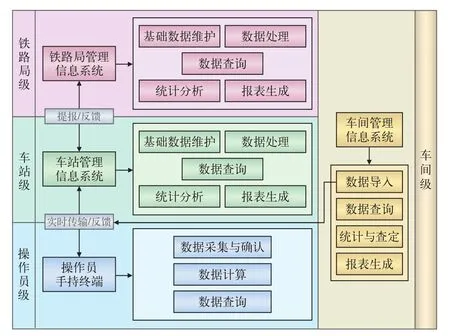
圖3 系統總體結構圖
2.1.1 鐵路局級
(1)數據匯總與處理。接收所轄各車站發送的列車在站技術作業流程時間數據、單項技術作業時間寫實數據,并對相關數據進行增加、刪除和修改。
(2)數據查詢。按車站、車次等形式查看各站單項技術作業時間寫實數據和列車在站技術作業流程時間數據,結合車站信息、行車數據進行多表聯合查詢。
(3)數據統計與分析。統計分析同性質列車在鐵路局內不同車站辦理技術作業時間的差異,跟進重點車次在鐵路局內各站辦理技術作業的情況。
(4)向下轄各車站發送反饋信息。
2.1.2 車站級
(1)數據匯總。接收操作員或車間用戶傳輸的各單項技術作業時間寫實數據。
(2)數據處理。計算各列車在站技術作業時間,并對其進行增加、刪除、修改。
(3)數據查詢。查看鐵路局內各站的各單項技術作業時間、列車在站技術作業流程時間數據,其中,本站數據可查看和修改,其它站數據僅供查看。
(4)數據統計與分析。統計本站各性質列車在站技術作業流程時間的平均值、中位值、極值、方差(標準差)等指標,并生成報表。
(5)數據提報。車站每隔固定時間(周/月)就要向鐵路局層提報各單項技術作業時間寫實數據和各列車在站技術作業流程時間數據。
(6)接收來自鐵路局層的反饋信息,并向車間層發送反饋信息。
2.1.3 操作員級
(1)數據采集與確認。技術作業人員通過手持終端采集技術作業時間原始數據,并通過邏輯判斷語句對時間數據進行初步檢驗,剔除不合理數據。
(2)數據處理。技術作業人員在一次采集完畢后,前端能自動計算本次技術作業的時間,并通過如自動彈出對話框的形式使技術作業人員即時地獲取本次技術作業的時分。
(3)數據查詢。操作員在自身權限范圍內查看相關信息。
(4)數據實時傳輸。采集完畢后,技術作業時間寫實數據能實時傳輸至所屬的車站數據庫,用以存儲、處理和分析。
(5)接收車間用戶的信息反饋。
2.1.4 車間級
(1)導入寫實數據。手持終端設備故障條件下,允許通過接口手動導入用Excel等方式記錄的技術作業時間寫實數據。
(2)數據查詢。在自身權限范圍內查看本工種的技術作業時間歷史數據,既包括本車間又包括其它站同一性質車間。
(3)數據統計和分析。車間用戶可按作業員、車次、時段統計技術作業時間平均值、中位值、極值、方差(標準差)等指標,統計的結果能夠靈活生成曲線、柱狀圖等形式的分析報表。
(4)接收來自車站層的反饋信息,并向操作員發送反饋信息。發送的反饋信息可分為個性化反饋信息和固定反饋信息。個性化反饋信息是車間用戶針對指定技術作業員發送的消息,主要內容是對員工近一段時間工作的評價或提醒,提供意見咨詢、發揮監督作用;固定反饋信息,即按固定時間面向全體員工發布的工作信息,如周報、月報,供每個技術作業員學習,提高工作素養。
2.2 系統分層結構設計
采用3層架構:(1)數據訪問層,是系統構建的基礎;(2)業務邏輯層,介紹系統構建的功能和關系結構;(3)表示層,即系統用戶層。系統的分層結構如圖4所示。
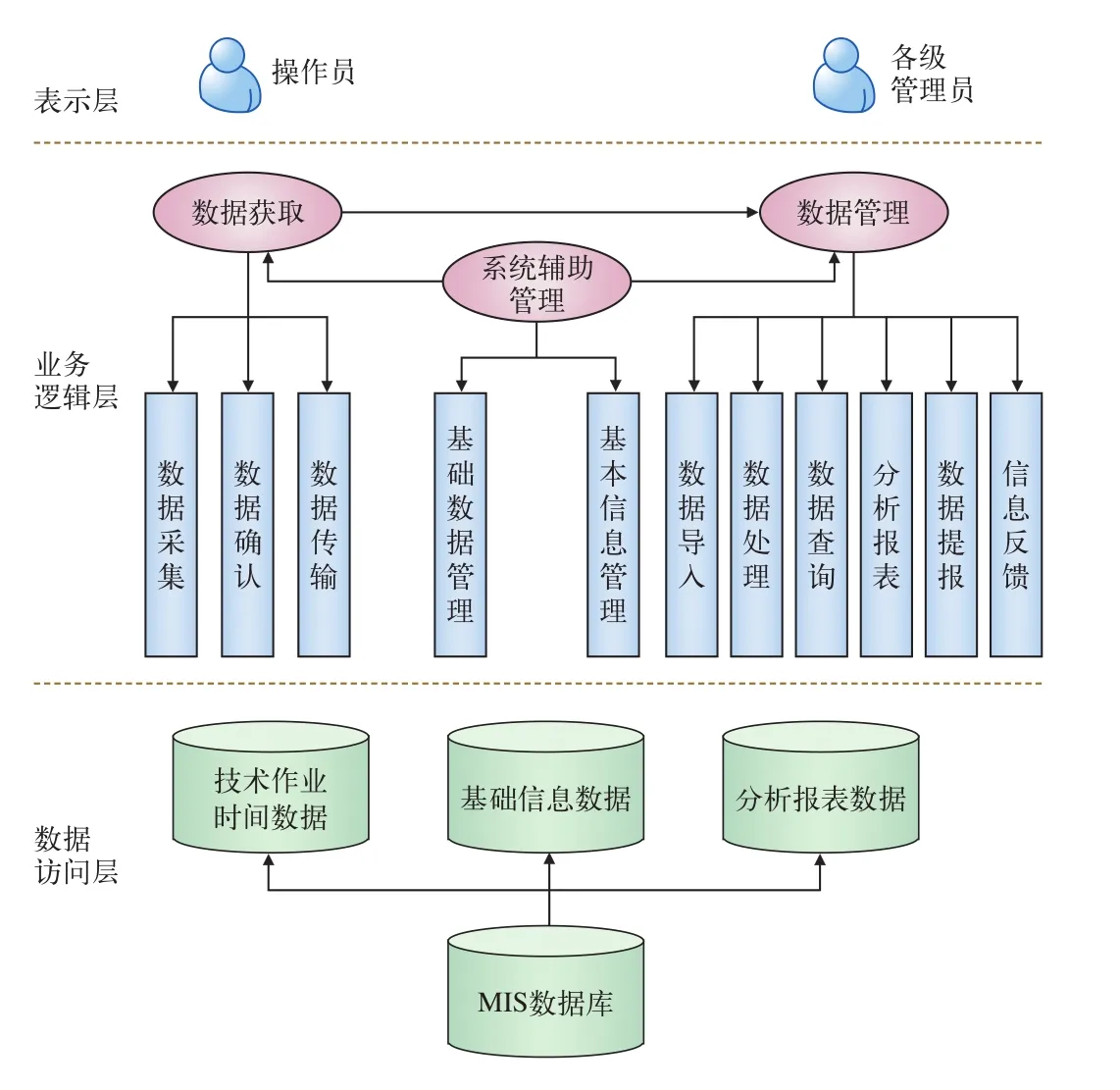
圖4 系統分層結構圖
(1)操作員與各級管理員兩類用戶是表示層人機交互的主要對象,不同身份用戶可操作界面亦不相同。
(2)業務邏輯層主要實現基于系統輔助管理的數據獲取和數據管理。
(3)數據訪問層主要包含技術作業時間數據、基礎信息數據、分析報表數據等。
3 系統功能
3.1 數據獲取
依靠作業人員通過手持終端實時采集列車在站技術作業過程中各單項技術作業的開始時刻、結束時刻,同時,允許相應的車間級管理員手動導入。
3.2 數據匯總與處理
系統獲取的原始數據為各單項技術作業的開始時刻、結束時刻,將原始數據通過識別與關聯數據庫、作差運算等技術手段,計算出時間間隔數據,即單項技術作業時間和列車在站技術作業全過程時間。采用分類匯總法,對關鍵詞詞段值相同的記錄進行匯總。系統層級不同,匯總對象也不同,其具體對應關系如表1所示,此外,還包括數據基本表的定義、修改、刪除和更新表中數據等功能。

表1 數據匯總層級及其對象
3.3 數據查詢
數據查詢分為本地查詢和環比查詢。本地查詢的對象是用戶所在單位的本地數據庫,查詢結果可供修改;環比查詢(即聯機查詢)的對象是系統其它同層級、不同單位的數據,需要訪問全局數據庫,查詢結果僅支持鐵路局級管理員修改,其具體對應關系如表2所示。數據查詢可按車站、員工、技術作業類型等多種條件進行,基于用戶權限的多表聯合查詢技術是實現該功能的基礎,用戶查詢權限如表3所示。
3.4 數據統計分析與業務報表生成
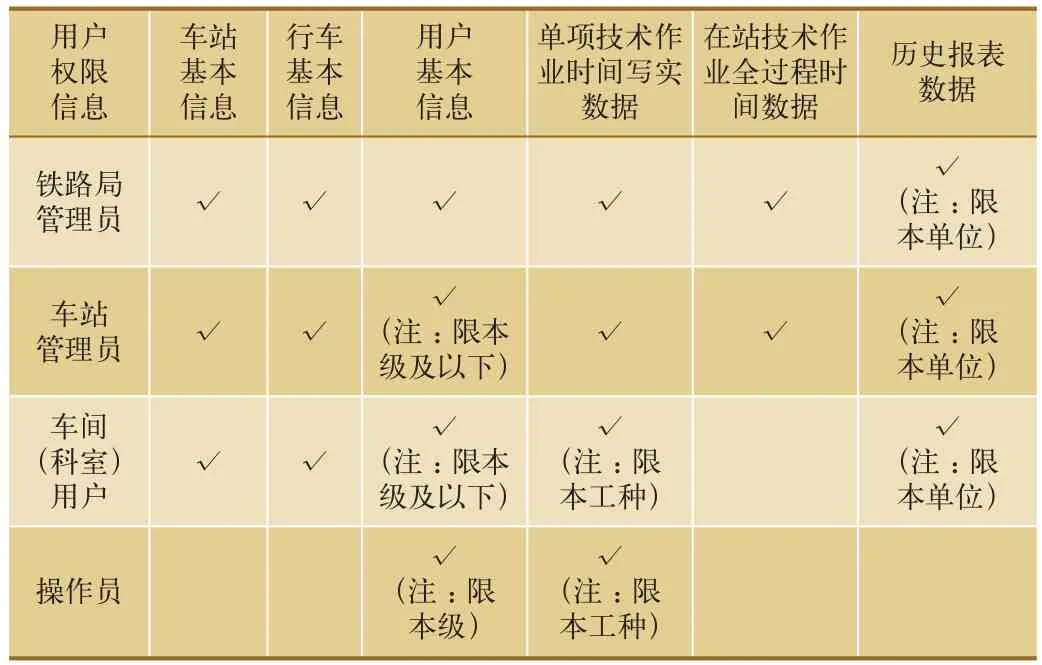
表2 不同級別用戶對應的查詢范圍表

表3 不同層級的本地查詢與環比查詢對象
系統數據統計與分析工作基于數據查詢功能展開,并生成業務報表。不同層級單位業務報表對應的核心任務與具體內容如表4所示。
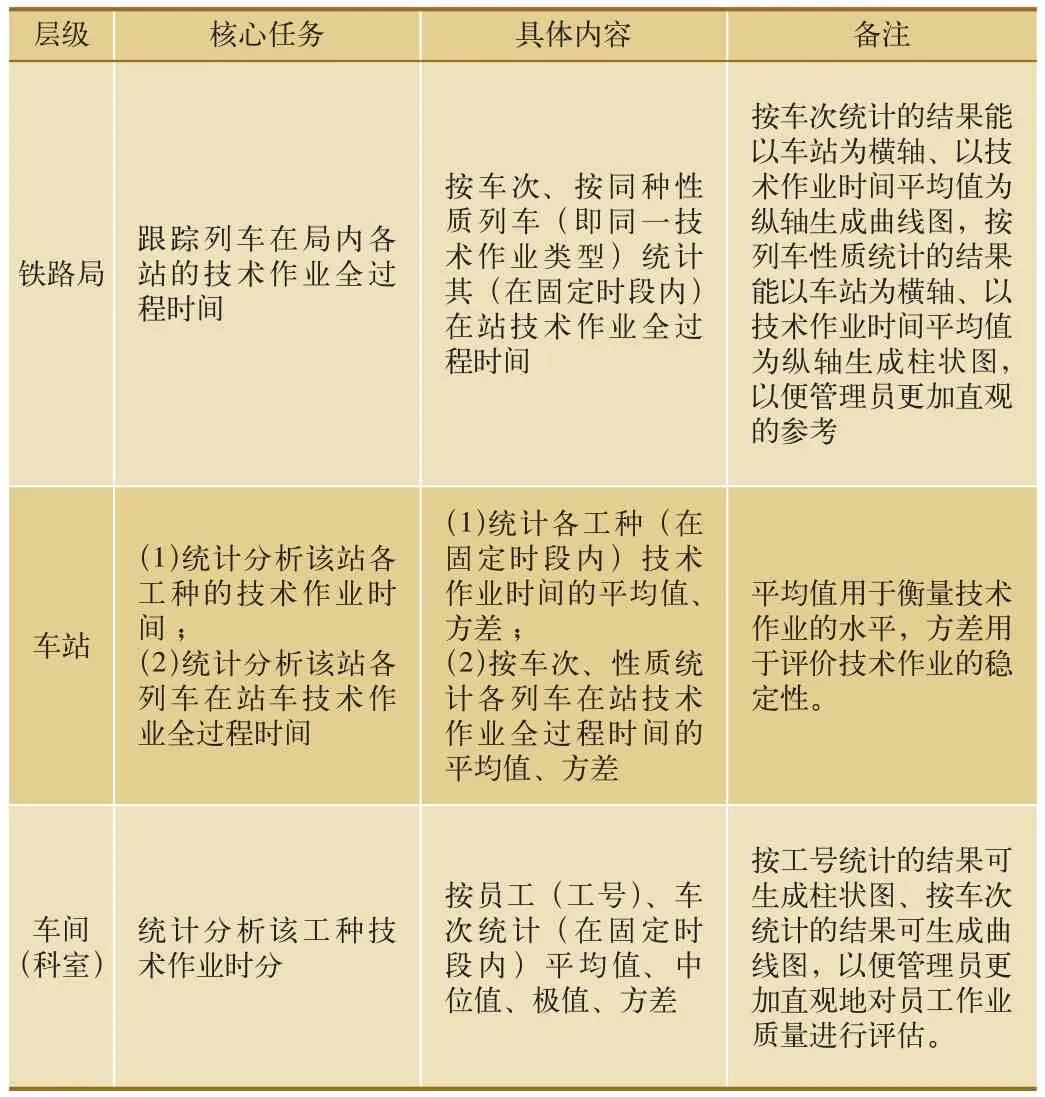
表4 不同層級單位業務報表的具體內容
3.5 系統輔助管理
(1)對所有基礎數據進行核實、添加、刪除、修改,如車站基本數據、行車基本數據、用戶基本數據;(2)對系統基本功能進行管理,如用戶操作、權限管理等。
4 關鍵技術
4.1 數據庫設計
系統采用如圖5所示的分布式數據庫,將分散存儲在多個網絡節點上的數據有機統一起來,以獲取更大的存儲容量和更高的并發訪問量。
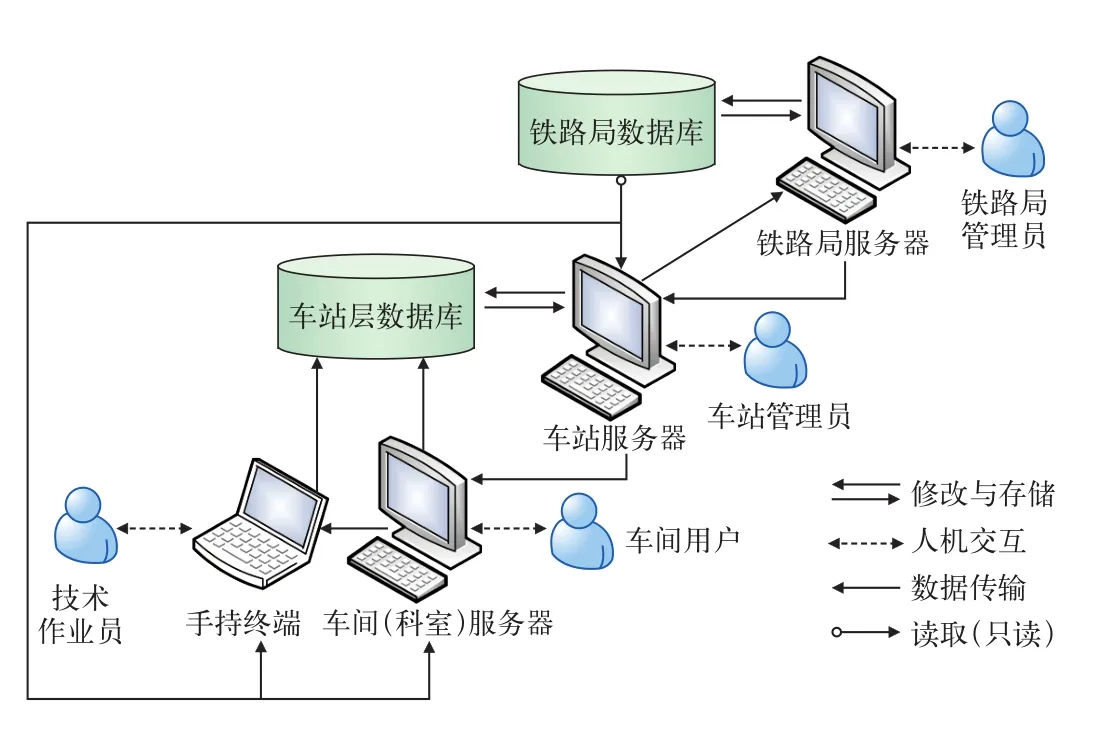
圖5 系統數據庫結構設計
基于設計,物理上分散的各車站需建立和管理一個局部數據庫,鐵路局將所有數據匯總管理后建立一個全局數據庫。全局數據庫可以供所有用戶在自身權限內訪問(只讀),而局部數據庫的數據既可以供本地用戶查詢,又可以供本地用戶修改。
此外,系統需要設計合理的數據表結構,滿足不同層級單位對技術作業時間存儲與匯總的需要。以某站某列車在站技術作業為例,用結構體類型定義的數據結構描述如下:

ZYSJ;//作業時間}單項技術作業時間寫實數據TYPEDEF STRUCT列車在站技術作業全過程時間

ZYSJ;//作業時間}列車在站技術作業全過程時間數據。
當進行車站層匯總時,系統以技術作業代碼作為第1關鍵詞,以工號作為第2關鍵詞,以(車次號,時刻)作為第3關鍵詞;當進行鐵路局層匯總時,系統以車站代碼作為第1關鍵詞,以技術作業代碼作為第2關鍵詞,以(車次號,時刻)作為第3關鍵詞,以工號作為第4關鍵詞進行數據匯總。
4.2 分布式數據查詢優化
系統為適應鐵路點多、線長等特點,采用分布式數據庫,實現數據查詢“物理分散,邏輯集中”。受地域因素影響,查詢速度是影響系統性能的關鍵,本系統采用的是基于代價的優化策略。以某車站用戶要查詢兩個遠程數據庫(即其它車站)中的表remote a,remote b,以及一個當地數據庫(即本站)的表local c中數據的操作為例,優化后的查詢語句可以寫為:
SELECT r.CC,r.XC_no,r.LCLX,r.Station_no,c.Begintime,c.Endtime
FROM (SELECT a.LCLX,a.Station_no,b.Begintime,b.Endtime
FROM remote a,remote b
WHERE a.XC_no=b.XC_no) r,local c
WHERE c.XC_no=r.XC_no
這種在多個遠程站點通過構造行中視圖的方法減少了查詢數量與網絡傳輸代價,進而提高了查詢速度。
5 結束語
本文分析列車在站技術作業流程,以及技術作業時間寫實管理信息系統的需求,設計系統總體結構和功能。后續的工作可考慮從以下方面展開:
(1)豐富系統功能,擴展系統應用范圍,實現對移動設備場庫內檢修作業時間、列車行車間隔時間等其它類型的鐵路技術作業時間的一體化管理;
(2)運用大數據技術與方法,進一步完善數據分析與管理功能等。
猜你喜歡
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
財經(2017年2期)2017-03-10 14:35:35
商用汽車(2016年11期)2016-12-19 01:20:16
故事大王(2016年7期)2016-09-22 17:30:08
商用汽車(2016年6期)2016-06-29 09:18:54
財經(2016年15期)2016-06-03 07:38:02
商用汽車(2016年4期)2016-05-09 01:23:12
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
創業家(2015年5期)2015-02-27 07:53:25
