基于Spark的電網工控系統流量異常檢測平臺①
2019-08-22 02:30:24張艷升李喜旺李錦程
計算機系統應用 2019年8期
張艷升, 李喜旺, 李錦程
1(中國科學院 沈陽計算技術研究所,沈陽 110168)
2(中國科學院大學,北京 100049)
3(國網遼寧省電力有限公司,沈陽 110004)
兩化融合的力度深度加強,在電網領域越來越多地應用的信息技術. 工業控制系統已廣泛應用于電力工業領域. 其中,在電網領域很大一部分的基礎設施需要依靠工業控制系統來實現自動化作業. 電網工控系統通常情況下采用通用的軟硬件和網絡設施,并越來越廣泛地與企業網和互聯網等集成,形成了開放的網絡環境. 由于傳統電網控制系統是基于物理隔離的,主要關注系統的功能安全,缺乏對網絡信息安全的考慮,沒有專門的安全防御措施. 例如,2010年震撼全球的“震網”病毒事件,專門攻擊工業控制系統設施,造成伊朗核電站推遲發電[1,2]. 電力控制系統網絡化的快速發展,相應導致了系統的安全風險不斷增加,面臨的網絡安全問題更加突出,再加上利用TCP/IP技術對工業網絡進行通信,對TCP/IP進行相關攻擊,能夠快速進入網絡,使得工控系統面臨更大的安全挑戰. 大數據技術的發展迅速,利用大數據技術來解決工業控制系統中異常流量檢測問題是當今研究的新的方向,如果當人力無法處理超出可控范圍內的異常流量數據時,這樣一些隱藏的網絡攻擊將有機可趁,這時利用大數據技術來處理大規模數據中的異常情況就非常有必要,相關工作人員能夠快速定位與分析,做出相應地措施.
隨著電力工控系統智能化建設的不斷發展,數據呈現出海量化、高維化、復雜化的趨勢. 傳統的網絡監測安全預警系統在面對海量高維度數據時,其在精度、實時性、擴展性以及效率上都無法滿足需求. 目前大多數的工業控制網絡安全預警方案主要以Hadoop數據處理平臺為載體,考慮在集群上部署Hadoop數據處理平臺,然后通過使用統計學習方法或者各種機器學習算法對采集到的海量數據進行建模,從而進行大規模的離線計算,然而利用Hadoop為載體的系統并沒有考慮到預警預測的實時性,也沒有考慮到其處理的速度問題,不能快速、實時的反饋安全預警,利用Hadoop為載體的機器學習方法也無法做到在內存中大量迭代. 要想快速、實時、高效的對網絡做出安全預警,需要研究其他大數據處理技術,例如,近幾年出現的新型的數據處理計算框架Spark,它作為一種基于內存的編程模型,它將迭代過程和中間結果放在內存中進行,數據處理速度上得到很大提升[3,4]. 它的組件Spark Streaming能夠對數據流進行實時處理,從而能夠滿足實時性的要求[5-7],但是它們都是利用Spark內置的簡單的機器學習模型來進行建模預測,在面對海量數據集時無法體現其優勢,本文在利用Spark計算框架的基礎上,結合與其相集成的Deep Learning 4J來進行深度學習模型的建模,這樣能夠統一技術棧,不論在精度、實時性還是擴展性、效率上都有進一步提升.
因此,在大數據環境下,為了能夠對工業控制網絡安全作出快速、精確和實時的預警,考慮使用Spark計算框架,結合利用深度學習建模,充分利用其低延遲、可擴展以及高可用的特性,這顯然是發展的一種趨勢.
1 電網工控系統流量異常檢測系統的設計
基于Spark的工業控制網絡安全預警平臺核心技術模塊主要包括數據采集與網絡流量深度包檢測協議解析模塊、實時數據分析處理模塊、安全預警預測模塊和數據存儲模塊共計4個系統功能模塊. 系統的整體結構圖如圖1所示.
1.1 數據采集與網絡流量深度包檢測協議解析模塊
數據采集層負責從不同的數據源采集數據. 利用網絡流量深度包檢測傳感器通過旁路接入的方式實現對網絡內數據的檢測. 深度包檢測技術(Deep Packet Inspection,DPI)是在傳統IP數據包檢測技術(OSI L2-L4之間包含的數據包元素的檢測分析)之上增加了對應用層數據的應用協議識別,數據包內容檢測與深度解碼. 一般網絡設備只會查看以太網頭部、IP頭部而不會分析TCP/UDP里面的內容這種被稱為淺數據包檢測; 與之對應的DPI會檢查TCP/UDP里面的內容,DPI數據包檢測如圖2所示.
利用Kafka(是一種高吞吐量的分布式發布訂閱消息系統)作為平臺數據的接入與分發. Kafka能夠靈活的處理流式數據,主要為本文系統平臺中的數據采集層與數據預處理層之間提供高性能與低延遲的數據流轉[8]. 一個典型的Kafka體系架構如圖3所示,主要包括若干Producer,若干broker,若干Consumer (Group),以及一個Zookeeper集群. Kafka通過Zookeeper管理集群配置,選舉leader,以及在consumer group發生變化時進行rebalance. 將數據采集層采集好的特征數據根據網絡流量深度包傳感器接入不同設備來劃分Kafka中不同的Topic,每一Topic又劃分多個partition,然后Kafka中的Producer使用push(推)模式將消息發布到broker,發送每一條數據到broker,Producer會根據這條消息的Key和partition機制來決定發到哪一個partition,數據處理層利用Consumer使用pull(拉)模式從broker中訂閱并根據Topic主題來消費消息.
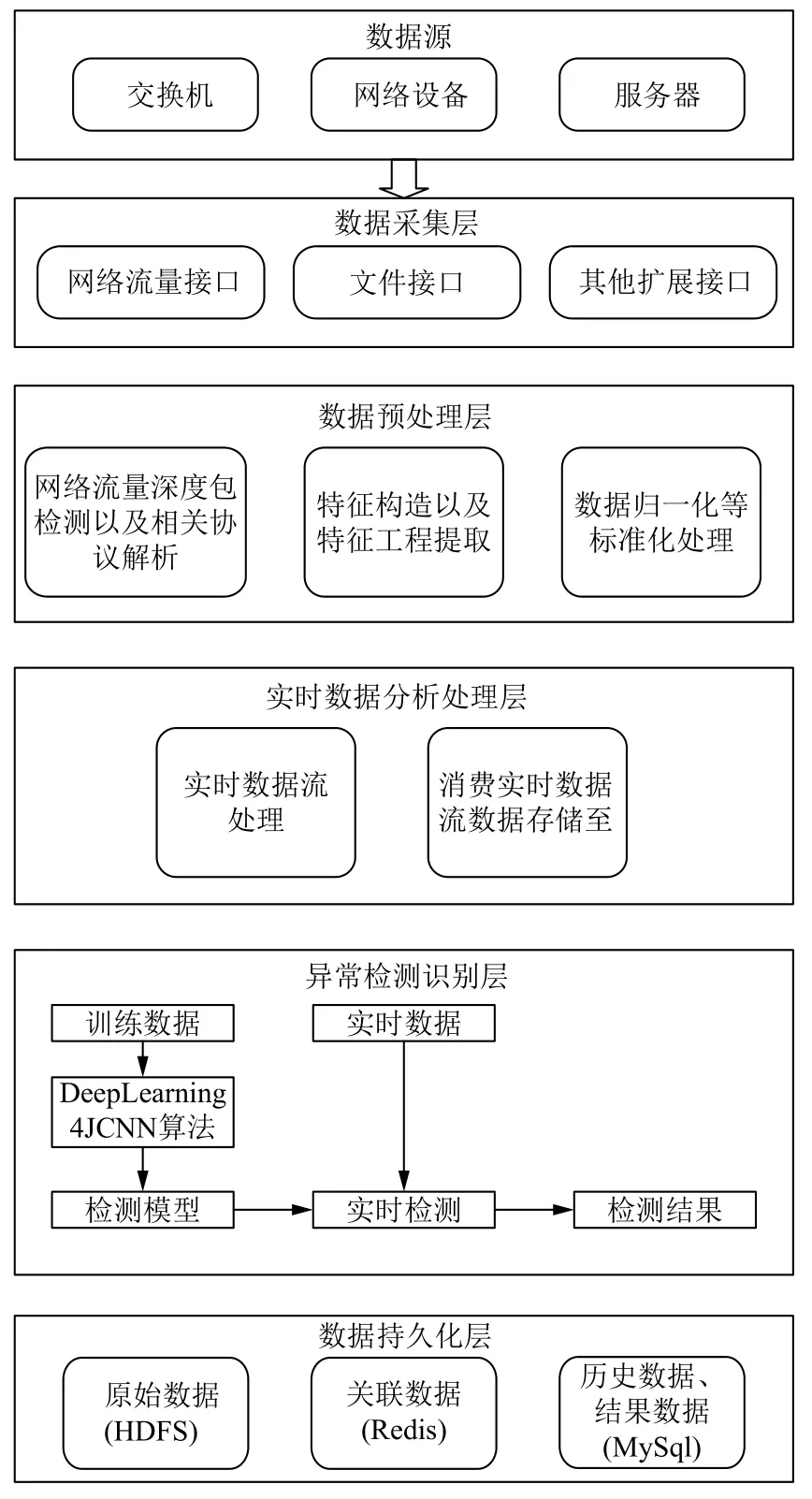
圖1 異常流量檢測系統整體架構圖
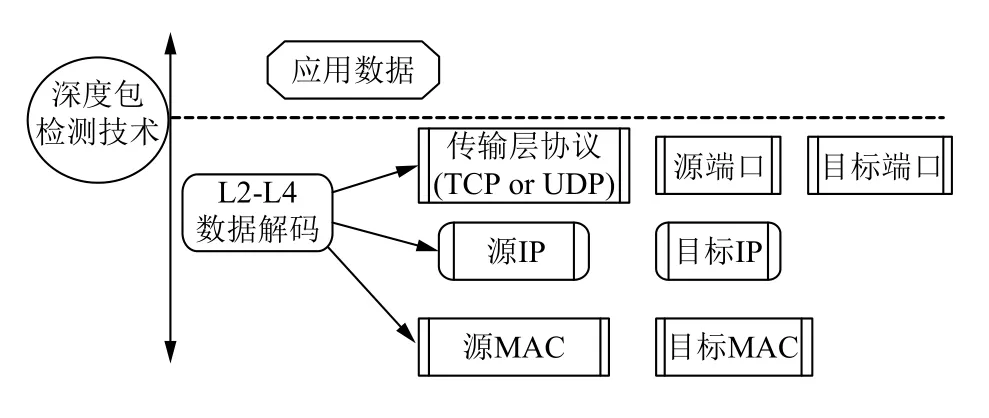
圖2 DPI數據包檢測圖
1.2 實時計算數據分析處理模塊
該模塊主要建立以Spark為核心的實時數據流處理模塊,主要面對大量實時監測的數據. 采用Spark Streaming(是建立在Spark上的實時計算框架,通過它提供豐富的API、基于內存的高速執行引擎,用戶可以結合流式、批處理和交互式查詢應用)技術進行實時事件流的處理,它將流式計算分解成一系列連續的DStream(Discretized Stream,DStream)[9-11]. DStream實質上RDDs的集合,主要是以時間為鍵,RDD為值的哈希表,保存以時間為順序產生的RDD,而每個RDD封裝了批處理時間間隔內獲取的數據,每次產生的RDD會被添加到哈希表中,如果不需要的RDD會從哈希表中刪除. 該模塊主要消費來自Kafka中的數據,利用Spark Streaming的Direct方式來消費來自Kafka中數據,這種方式能夠定期的查詢Kafka中的topic+partition中的偏移量,DStream會創建與Kafka分區一樣的RDD分區數,能夠并行的從Kafka中消費數據. Spark Streaming從Kafka中消費數據運行原理圖如圖4所示. 該模塊一方面消費Kafka中的數據,可以將處理后的數據存儲至歷史數據庫,方便數據分析以及Spark ML建模使用; 另一方面,Spark Streaming可以處理實時監測的數據,可以存入內存數據庫Redis實時展示網絡流量動態曲線,同時實時處理的數據輸入到已建立好的流量異常檢測模型中來檢測,這樣方便在出現異常時能夠實現及時預警,方便工作人員作出及時調整.
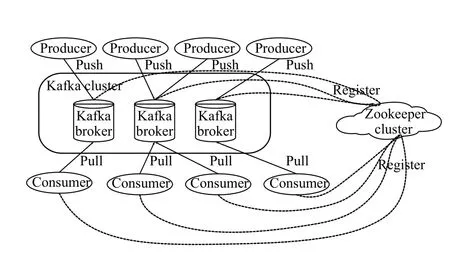
圖3 Kafka體系架構圖
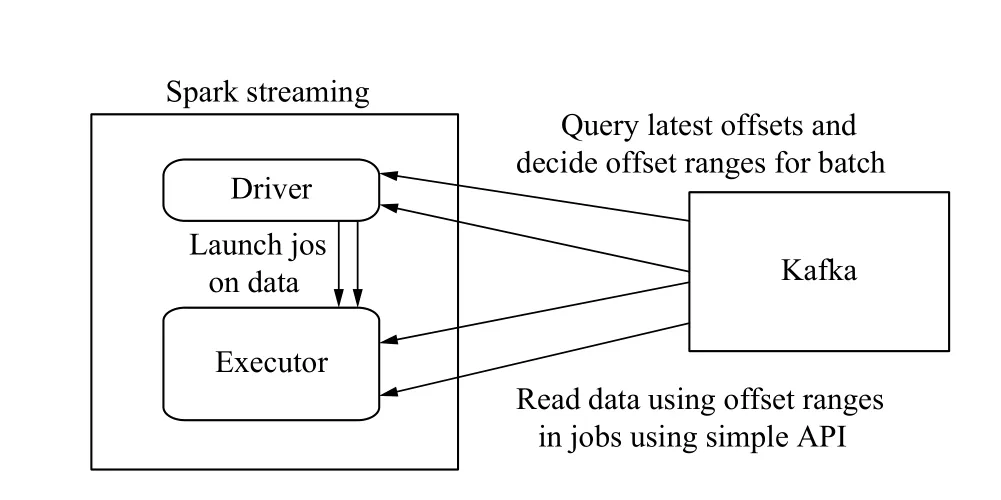
圖4 Spark Streaming消費Kafka原理圖
Spark Streaming 消費Kafka中的數據,首先識別原始數據中的每條特征是否是字符形式的數據,如果是,將該特征進行數值化處理,最終每條數據都是數值化的形式,然后將轉化為數值化后的數據進行最大值最小值標準化處理,方便接下來利用Deep Learning 4J設計的卷積神經網絡的使用,將其一維轉二維化處理.
1.3 安全預警預測模塊
電網工控系統數據海量化以及復雜化,對異常流量檢測安全預警需要要求準確性,實時性等要求,通過讀取歷史數據庫中的數據,利用Deep Learning 4J建立以卷積神經網絡為基礎的流量異常檢測模型,Deep Learning 4J集成了Hadoop及Spark,能夠與該平臺實現統一的技術棧,實現統一的pipeline,節省了研發成本[12-14]. 該模塊能夠根據歷史數據庫實現模型的建立,每過一段時間可以增量更新模型,同時根據Spark Streaming實時處理的數據,利用該模型進行檢測,能夠做出極高的準確率,極大地提高了異常流量的效率以及精度.
1.4 數據存儲模塊
該模塊主要根據數據的類型以及使用的情況進行選擇,數據采集的原始數據可以存放至HDFS,方便Spark快速讀取,以及歷史數據挖掘分析. 為提高平臺數據處理分析以及異常流量檢測的實時性,使用分布式內存數據庫Redis,主要利用Redis數據庫的鍵值存儲,對實時數據處理的結果進行存儲. 為方便利用Deep Learning 4J中的卷積神經網絡建立模型,將平臺的離線歷史數據存儲用Mysql進行存儲,同時將異常流量檢測模型檢測的結果數據也存儲至Mysql中,這樣可以積累訓練數據,同時滿足增量更新的要求,更有利于提高模型的準確性.
2 基于Spark的異常檢測模型
電網工控系統中流量異常檢測是非常重要有必要的,網絡運行安全時網絡各個維度的特征都比較平穩.但當異常發生時會產生較大的波動,當某些維度的數值超過閾值時判定異常發生. 異常有許多種,并且一種異常發生時對應的特征波動情況也相對穩定,本文中主要對電網工控系統采集流量數據,分為正常流量和部分少量異常流量,采用Spark框架對數據進行處理,為結合Spark以及達到實時性已經準確性的要求,建立模型部分采用與Spark計算引擎集成的Deep Learning 4J,設計好卷積神經網絡的網絡結構,這樣能夠很好捕捉好異常的波動,達到較高的識別率. 異常檢測模型如圖5所示,基于Spark的異常檢測模型的算法如下:
1) 首先采集電網工控系統的數據,將字符型數據轉化為數值型,并將數據進行標準化的形式處理.
2) 將每條數據即一維特征進行二維化處理,將每條樣本數據轉化為圖片的形式.
3) 設計卷積神經網絡結構,有卷積層,池化層,Dropout層,全連接層以及反卷積層實現.
4) 利用設計好的卷積神經網絡對訓練數據集進行訓練,并利用測試樣本對模型進行調參,使模型達到最優.
5) Spark Streaming實時處理的監測數據用訓練好的模型進行預測,從而作出識別預警,并將識別結果存儲至結果數據庫中.
6) 定期增量更新模型,方便提高系統的性能.
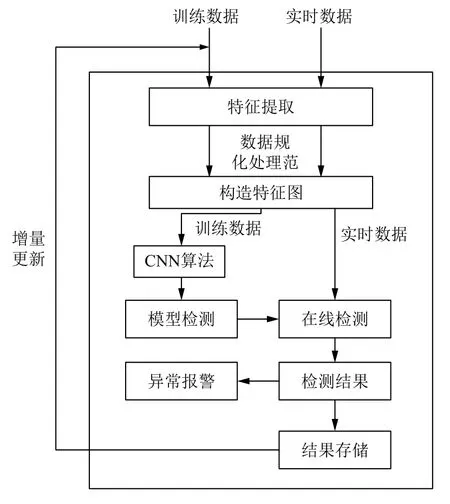
圖5 Deep Learning 4J異常檢測模型
卷積神經網絡基本結構有輸入層、卷積層、池化層、全連接層和輸出層這幾部分交替組合而成. 設計的卷積神經網絡如圖6所示.
本文中在卷積神經網絡模型設計中加入了dropout技術,其目的是為了提高模型的泛化能力,進而能夠對模型的過擬合現象得到有效的改善. 在實驗環節,對不加入dropout技術與加入dropout技術兩個模型做了相關對比,在模型設計與測試時,根據經驗值將dropout設置成0.4,統計模型在最后的損失與準確率趨于穩定的結果,如表1所示.
表1可知,不帶dropout技術的模型的訓練時的損失值要小于加入dropout技術的損失值,由此可知,在不加入dropout技術時,當訓練模型時,模型為了最小化損失函數,從而對訓練數據過分擬合,使得模型的損失值最小. 但加入dropout技術的模型的準確率要大于不加入dropout技術的準確率,因為加入dropout的模型在模型參數更新時會隨機選擇一部分參數進行更新,避免對固有模型參數的學習記錄. 即模型再每一次迭代過程中,都會生成一個個的小網絡,每次只針對此次生成的小網絡進行參數學習更新,各個神經元之間不會形成特定的組合對模型學習的影響,使得參數的分布趨于均勻. 因此,使得模型在測試數據集的表現效果更佳.
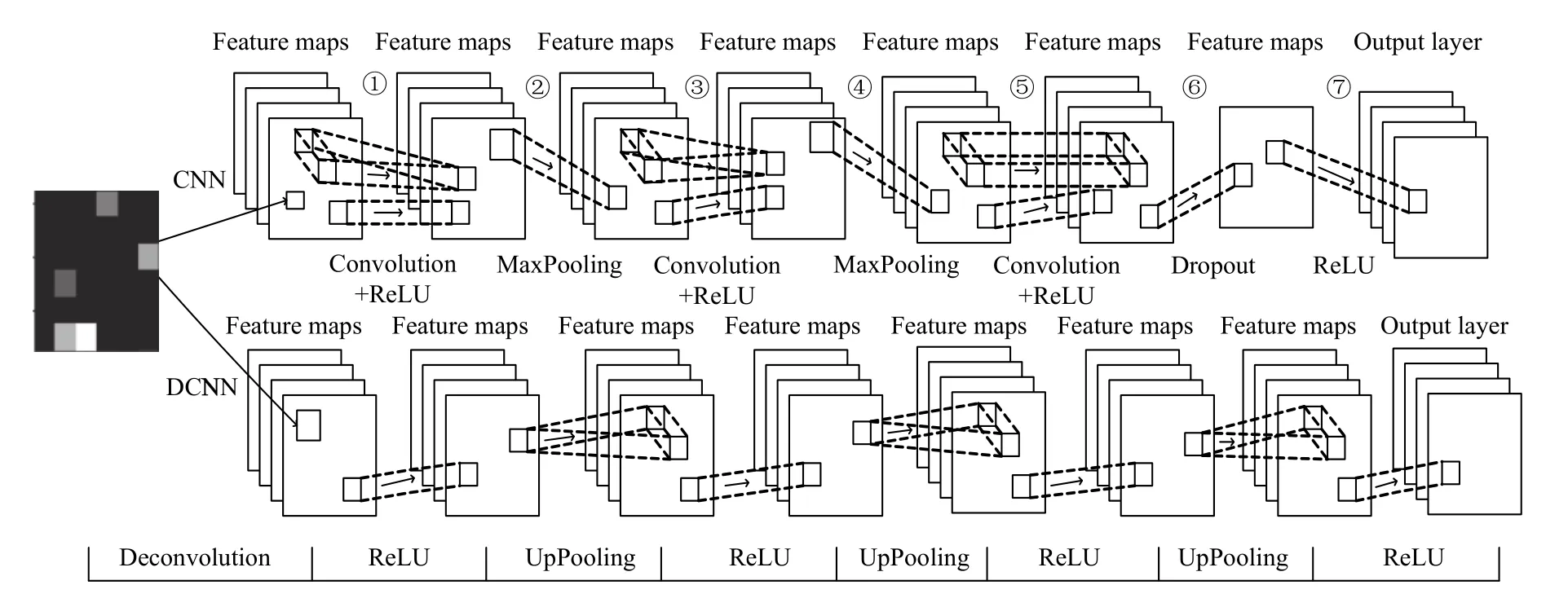
圖6 DeepLearning 4J卷積神經網絡結構圖

表1 Dropout的影響
本文在卷積神經網絡模型設計中加入了反卷積操作,其反卷積操作的關鍵是卷積層的逆過程,是能夠對原始輸入圖像的重建,從而訓練得到參數更新,能夠降低模型的損失誤差,增加模型的泛化能力. 如表2,為模型在趨于穩定的時候統計的模型的損失與準確率的平均值. 從表2也可以看出加入反卷積層的模型的損失值更小,泛化能力更強,識別準確率更高.

表2 反卷積層的影響
3 實驗與結果分析
3.1 實驗環境
平臺的實驗環境是基于分布式系統基礎架構Hadoop安裝的Spark集群,集群中共有10機器作為節點,是基于Hadoop中資源調度器Yarn來部署Spark為Yarn Cluster模式,每臺機器的內存為32 GB. 集群軟件配置如表3.

表3 集群軟件配置
3.2 實驗數據與結果分析
本文所用數據是通過對東北電網采用網絡流量深度包檢測,將檢測的數據包進行捕獲解析,將解析的數據生產到Kafka相應話題,利用Spark Streaming的時間窗的流式處理對數據進行處理,采集網絡數據時主要關注網絡間與連接特征相關的信息. 例如,在TCP連接的基本特征中可以提取連接的持續時間、網絡協議的類型、目標主機的網絡服務類型、從源主機到目標主機的數據字節數等,目前采集的網絡流量數據集大小約為4.62 GB.
在數據集的每條數據中都記錄攻擊類型,其中攻擊類型一共包括4個大類以及28個小類,為了方便建模將數據集分為訓練集與測試集,28個小類攻擊類型中的12個小類出現在測試集中,這樣可以檢驗模型的泛化能力.
采集的流量數據樣本特征值并不都是在0~255之間,有些特征還是以字符串的形式采集下來的. 拿其中一條樣本來看,0,tcp,smtp,SF,787,329,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,1,1,0.00,0.00,0.00,0.00,1.00,0.00,0.00,76,117,0.49,0.08,0.01,0.02,0.00,0.00,0.00,0.00,normal.
首先將字符特征轉化成數值型特征,分別將Internet 控制報文協議(Internet Control Message Protocol,ICMP)、用戶數據包協議(User Datagram Protocol,UDP)和Tcp 3種協議類型,簡單郵件傳輸協議(Simple Mail Transfer Protocol,SMTP)、目標主機服務類型ecr_i、private、超文本傳輸協議(Hyper Text Transfer Protocol,HTTP)等70種網絡服務類型,SF(Symbol Flag)、REJ(REJECT)等11種網絡連接狀態以及Smurf攻擊(Smurf)、Ping掃射(ping-sweep)、端口掃描(port-scan)23種攻擊類型和一種正常狀態轉化數字標識. 對每一條轉化好的數值特征采用數據標準化處理,本文采用最大最小值歸一化處理,取每條數據的最大值最小值,然后對每一個數據進行處理,公式如下:

將數據歸一化的數據生成特征圖的方式,利用設計好的異常檢測模型,利用訓練集與測試集來訓練模型以及調優模型,對Spark Streaming消費Kafka中的實時數據,對數據進行相應處理,利用訓練好的模型進行相關預測,以便做出安全預警.
檢測結果主要利用檢測率,誤報率和未知攻擊檢測率三個指標,公式如下:

由表4列舉出了3種攻擊類型和整體情況的檢測結果. 可以看出相比于基于大數據的K-means的檢測方法和基于大數據的DBScan檢測方,本文使用基于Spark的卷積神經網絡的方法很大程度上提高了檢測率和未知攻擊檢測率,降低了誤報率,取得了比較好的成果.

表4 各算法測試結果對比
4 結論
本文結合電力控制網絡的數據特點,以及滿足對精確性、實時性及效率的要求,構建出了一個基于Spark的電網工業控制網絡安全預警平臺,通過深度檢測技術采集電力工控系統中的數據,進行協議解析并存入Kafka相應話題,然后利用Spark Streaming消費Kafka數據進行數據預處理并利用Spark ML與Deep Learning4J構建異常檢測模型,該方法在面對海量高維數據時不僅能快速有效地識別出異常流量的已有攻擊以及未知攻擊,而且能夠應用到各種工控系統,體現了該系統的泛化能力與可擴展性高的優勢. 本文方法能夠做到實時處理及安全預警,方便工作人員做出對應措施,節約了人力成本,極大地提高了工作效率,提高了網絡的安全性能.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中等數學(2022年2期)2022-06-05 07:10:50
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
小學生學習指導(低年級)(2020年6期)2020-07-25 02:31:36
數學物理學報(2020年2期)2020-06-02 11:29:24
小學生學習指導(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
