交通場景下的行人和車輛實時檢測算法
2019-08-21 03:50:48周騰蘭時勇
現代計算機 2019年21期
周騰,蘭時勇
(1.四川大學視覺合成圖形圖像技術國防重點學科實驗室,成都610065;2.四川川大智勝軟件股份有限公司,成都610045)
0 引言
隨著城市的發展和汽車數量的快速增長,交通場景越來越多樣,行車環境也越來越復雜,這帶來了一系列交通擁堵以及道路行車安全問題,智能輔助駕駛和深度學習發展為解決這些問題提供了新的思路,通過攝像頭檢測周圍行人和車輛的位置,智能輔助駕駛系統可以根據這些信息控制行車速度并且提前做出預判,能有效減少事故發生的幾率。因此能在復雜多變的交通場景中提前且準確檢測到行人與車輛尤為重要。
SVM[1]結合HOG 特征[2]、AdaBoost[3]結合Haar 特征[4]都是基于紋理特征的目標檢測算法。前者先從訓練圖像中提取梯度方向直方圖(HOG)特征,送入SVM 分類器進行訓練,使用SVM 分類器滑窗式檢測圖像中的行人車輛。后者使用Haar-like 特征構建弱分類器,通過AdaBoost 算法把弱分類器提升成強分類器,然后將多個強分類器串聯得到級聯分類器。這些傳統算法共同的缺點是不能很好處理物體間遮擋的問題,還存在因人體姿勢幅度過大和行人車輛朝向改變難以檢測的問題,再加上現實環境復雜多樣,這些算法容易出現誤檢,漏檢,精度不高,定位不準,魯棒性較差,也不能滿足實時性要求。以上傳統檢測算法都依賴于人工設計的特征,物體外觀、形狀、姿態各有不同,光照影響、遮擋問題都會影響特征提取質量。深度學習和卷積神經網絡(Convolutional Neural Network,CNN)的發展為目標檢測提供了新的思路,CNN 直接將圖像數據作為輸入,無需人工對圖像進行額外的特征抽取,因此在基于圖像的識別,檢測等方面具有獨特的優勢。
Faster R-CNN[5]是一種基于卷積神經網絡的二階段(two-stage)目標檢測算法,它提出了區域提議網絡RPN(Region Proposal Network)這一概念,替換了費時的選擇性搜索(Selective Search)[6],結合滑動窗口和錨窗(anchor)機制得到建議窗口。Faster R-CNN 只在Conv5_3 層進行ROI Pooling 操作,然后在該層特征圖像的每一個位置生成9 種不同尺度的錨窗用于匹配目標,但由于生成的錨窗數量太少,難以針對行人車輛檢測任務覆蓋到各個尺度,并且分類網絡帶有全連接層,參數量大,速度慢,也不能滿足實時性要求。
SSD(Single Shot MultiBox Detector)[7]是一種基于全卷積網絡的多尺度檢測算法,SSD 結合了Faster RCNN 生成錨窗的思路,在多個不同尺度的特征圖上生成預選框,并在每個層級上獨立預測,這使得目標檢測精度非常高。SSD 一種基于全卷積網絡的檢測算法,在參數量上比Faster R-CNN 少得多,因此相比于Faster R-CNN 精度更高且速度更快,但原始SSD 對于小尺寸的目標識別效果較差。主要原因分析如下:SSD 使用分辨率較高的Conv4_3(38×38)淺層特征層檢測小目標,由于Conv4_3 層位置比較靠前,使得目標特征提取不充分,上下文語義信息不夠豐富。深層特征的語義信息雖然豐富,但經過多次下采樣后特征圖非常小,丟失了部分位置信息且先驗框(prior box)較大無法用來檢測小目標,綜上所述,當任務中包含較多的小目標時,SSD 算法性能較差。為解決上述問題,通常采用結合SSD 與FPN(Feature Pyramid Networks)[8]的思想,將高分辨率的淺層特征和具有豐富語義的深層特征進行融合。DSSD[9]設計了一種Top-Down 結構,將語義信息從高到低一層接一層反向傳遞回去,這一結構雖然提升了精度,但過多的特征融合模塊卻使速度大幅下降,行人車輛檢測對實行性要求較高,DSSD 不能滿足要求。
本文基于SSD 算法改進,將主干網絡由VGG16[10]替換為密集連接的DenseNet[11],優化了DenseNet 結構,提升了特征提取能力。針對SSD 算法小目標檢測性能差的問題,設計了特征融合模塊,融合了深層和淺層的特征。修改損失函數為Focal Loss[12],正負樣本不平衡的問題得到一定改善。改進算法在提升精度的同時保證了速度并且在一定程度上提升了小目標檢測能力,魯棒性較好。
1 改進SSD行人車輛檢測算法
1.1 改進的DenseNet
近些年為不斷提升網絡的性能VGG、GoogleNet、ResNet[13]、DenseNet 等相繼誕生。針對行人車輛檢測任務,這里將SSD 的主干網絡由VGG16 替換為更加高效的網絡DenseNet。不同于基于深度殘差結構的ResNet采用Element-Wise 方式將特征相加,DenseNet 采用了Concatenation 方式實現通道的連接,Dense block 基本結構如圖1 所示,DenseNet 將特征輸出到Dense block余下的每個特征層上,特征復用更加充分,Dense block先利用1×1 的卷積壓縮了通道,再使用3×3 的卷積進行特征提取,卷積操作后接BatchNorm 層,這些設計使DenseNet 網絡結構變得更深更窄,在增加了非線性和提高了網絡性能的同時降低了參數量和計算量,還緩解了由于網絡過深引起的梯度爆炸,梯度消失和過擬合問題。

圖1 Dense block基本結構
本文并不直接使用DenseNet-121 作為預訓練模型,DenseNet 第一個卷積核大小為7×7,步長(stride)為2,對于目標檢測任務,輸入圖像通過一個7×7 的卷積后直接經過最大池化(MaxPooling)下采樣,特征還未充分提取就損失了某些圖像信息,這些信息也十分重要。因此這里參照DSOD[15]的Stem 模塊設計思路,將第一個7×7 卷積替換成3 個連續的3×3 卷積,相比于7×7 卷積,3 個連續的3×3 卷積可以得到相同大小的感受野,這一改動減少了參數量,Stem 模塊可以減少原始輸入圖像的信息損失,并且更好地進行了特征提取,保留了相關細節信息。
1.2 改進SSD的網絡結構和特征融合模塊
為進一步解決原SSD 算法由于淺層特征提取不充分,語義信息不夠引起的小目標檢測性能差的問題,參照DSSD 的思路設計了特征融合模塊實現了深層特征與淺層特征融合,改進SSD 算法網絡結構如圖2 所示。改進SSD 算法的網絡由1 個Stem block,4 個Dense block,3 個Transition 層,3 個用于下采樣的3×3卷積和3 個特征融合模塊構成。每個Dense Block 之間通過Transition 層相連,Transition 層的1×1 卷積進一步控制了通道數量壓縮了模型,這里使通道數降為輸入的一半,然后通過平均池化(Average Pooling)下采樣。Dense block 4 之后接3 個連續的3×3 卷積進行下采樣。網絡輸入圖片尺寸為300×300 時,經過特征提取網絡后得到38×38×512,19×19×1024,10×10×1024,5×5×256,3×3×256,1×1×256 的特征圖分別記為Conv3_x,Conv4_x,Con5_x,Conv6,Conv7,Conv8。其中Conv6,Conv7,Conv8 的特征圖直接用于預測,Conv3_x與Conv5_x,Conv4_x 與Conv6,Con5_x 與Conv7 通過特征融合模塊得到38×38×512,19×19×512,10×10×512的特征圖用于預測。

圖2 改進SSD算法網絡結構
特征融合方式并不采用DSSD 方式將語義信息從高到低一層接一層反向傳遞回去,而是采用跨層融合方式,主要基于以下考慮,DSSD 使用了更多的特征融合模塊,這些模塊使計算量顯著增加,速度下降明顯,Conv6,Conv7,Conv8 特征圖語義信息已經比較豐富了,因此這里直接用于預測;由于相鄰層間的特征信息相似性比較高,因此采用跨層融合的方式,由于Conv8 所含信息較少且Conv6 語義已經較為豐富,因此不用于特征融合。改進后的SSD 與DSSD 相比降低了模型復雜度,提升了速度。特征融合模塊如圖3 所示。

圖3 特征融合模塊
具有豐富語義信息的深層特征通過跳躍連接的方式與淺層特征融合,深層特征經過兩個步長為2 的反卷積層4 倍上采樣得到的特征圖與淺層特征經過兩個3×3 的卷積操作后得到的特征圖進行Contact 通道相連,之后的1×1 卷積用于控制通道數量。3 個特征融合模塊充分利用了上下文語義信息,提升了算法的性能,又不至于使速度損失過大,相比于DSSD 算法更加高效。
1.3 損失函數
原SSD 算法分類損失默認為Softmax Loss,對于行人車輛檢測,負樣本即背景類所占的比重會很大,雖然

采用Focal Loss 訓練SSD 不需要使用OHEM[15]算法,Focal Loss 引入了兩個參數α和γ,這兩個參數起到了調整正負樣本的權重和難易分類樣本的權重的作用,通過實驗測得γ取2,α取0.25 時的效果最好。根據上述公式可知,樣本越難分,損失衰減越大,Focal Loss沒有單純舍棄易分負樣本,而是利用了損失較小負樣本,根據損失的不同賦予不同的權值,有效改善了正負樣本不平衡的問題。定位損失使用了Smooth L1 損失,定位損失函數如公式(2)所示,Smooth L1 損失函數公式(3)所示。負樣本的損失較小,但是大量的易分負樣本在訓練過程中會干擾損失,正負樣本不平衡的問題會導致模型訓練的效果不好。兩階段(two-stage)的Faster R-CNN通過RPN(Region Proposal Network)生成建議框,這一過程篩選了一部分框,使正負樣本不平衡問題得到一定緩解。SSD 是一種單階段(one-stage)模型,SSD 訓練時通過難分樣本挖掘(Hard Negative Mining)算法選取負樣本,使正負樣本比例為1:3。該算法在訓練時更專注那些于難分類的樣本,選出了損失較大的樣本用于訓練,忽略了損失較小的易分類的樣本。為解決行人車輛檢測過程中樣本不平衡的問題,這里使用了Tsung-Yi Lin,何凱明等人提出的Focal Loss 替換原來的Softmax Loss,其損失函數如公式(1)所示。

其中l 為預測框相對于默認框的偏移量,g 為真實框相對于默認框的偏移量,cx、cy、w、h 分別為框的中心坐標x,y,默認框的寬度,高度的偏移量。總損失函數如公式(4)所示,N 為正樣本個數,其中α取值為1。

2 實驗與分析
2.1 實驗平臺與數據集
本文數據集以KITTI 數據集為主,這里將“Van”、“Truck”合并到汽車類別,由于KITTI 數據集中的行人樣本相對較少并且場景相對單一,因此對KITTI 數據集進行擴充,收集Caltech 數據集,COCO 數據集中包含行人車輛的道路場景圖片并重新標注,擴充后的數據集一共11000 張,將其轉換為PASCAL VOC 數據集格式并按照8:1:1 分別劃分為訓練集、驗證集、測試集,以VOC2007 test 標準評估,其中IOU 閾值設為0.5。
實驗平臺配置為:操作系統:Ubuntu16.04;CPU:Intel i5-8400;內存:12G DDR4;GPU:NVIDIA GeForce GTX1060;深度學習框架:PyTorch。訓練中采用帶動量的SGD 梯度下降法,批(Batchsize)大小為4,初始學習率為0.001,動量(Momentum)為0.9,權重衰減因子(Weight Decay)為0.0005。在訓練過程中不斷調整學習率大小,總共迭代訓練數據120 個epoch。
2.2 性能評價指標mAP
本文采用mAP(mean Average Precision)作為評價模型檢測精度的指標。要計算mAP 需要先得到每類的PR 曲線,其中P(precision)為精準度,R(recall)為召回率,其計算如公式(5)所示:

其中TP(True Positive)表示真正例,(False Positive)表示假正例,FN(False Negative)表示假反例,TN(True Negative)表示真反例,當預測框與真實框(Ground Truth)的IoU 值大于0.5 這個閾值時,該預測框才被認定為TP,反之就是FP。VOC2007 test 下的AP 計算采用11-point interpolated average precision,首先對每一類目標檢測給出的置信度按降序順序排列,設置一組閾值為[0,0.1,0.2,…,0.9,1],計算召回率大于閾值組中的某個閾值時對應的最大精確度,得到11個精確度后取平均值,AP 計算如公式(6)所示,將各個類別的AP 加起來取平均得到的就是mAP 值。

2.3 實驗結果對比分析
在本文數據集下分別訓練SSD,DSSD 和本文改進的SSD 算法共120 個epoch,在本文數據集進行測試,mAP 的變化如圖4 所示,三種算法初始學習率均為0.001,在40 個epoch 時,三種算法的mAP 達到了70%左右,可以看出本文算法的mAP 最后略高于DSSD算法。

圖4 不同算法mAP變化圖
為進一步驗證本文改進算法的性能,在本文數據集上選取了SSD、DSSD、改進SSD 進行了詳細對比,主要對比了不同算法的精度指標和速度,對比結果如表1所示。

表1 本文數據集下不同算法性能對比
DSSD 主干網絡為殘差結構的ResNet-101,深層特征通過反卷積的方式一層一層傳遞回去,與SSD 算法相比精度提升明顯,比SSD 提高了1.6%,但DSSD 的主干網絡ResNet-101 參數量過多,并且過多的特征融合模塊使得耗時明顯增加,檢測速度僅為11FPS,不能滿足交通場景下行人車輛檢測任務的實時性要求。改進SSD 算法選取了參數量更少的Stem-DenseNet-121作為主干網絡,特征融合模塊數量也更少,相比于原SSD 和DSSD 在mAP 上分別提高了1.9%,0.3%,改進SSD 算法的檢測速度達到了39FPS,與原SSD 算法相比在速度上稍有下降,但是速度遠高于DSSD,在檢測速度與精度上取得了很好的平衡。可以看出改進SSD算法在行人目標上提升更大,但由于本文數據集中行人數量有限,針對行人的訓練仍不夠充分,數據集中的行人多為極小目標且較為模糊,因此對行人的檢測精度不如車輛。
為驗證Stem 模塊的有效性,對比了VGG16-SSD、DenseNet-SSD、DenseNet-SSD(Stem)、Ours、Ours(Stem)共五種算法,在本文數據集上的測試結果如表2 所示。Stem 模塊使DenseNet-SSD 的mAP 提高了0.7%。但Stem 模塊使本文算法的mAP 僅提高了0.3%,分析原因可能是由于特征融合模塊充分利用了特征,一定程度上減輕了由于圖像信息損失帶來的影響,但可以看出Stem 模塊依然可以帶來精度上的提升。
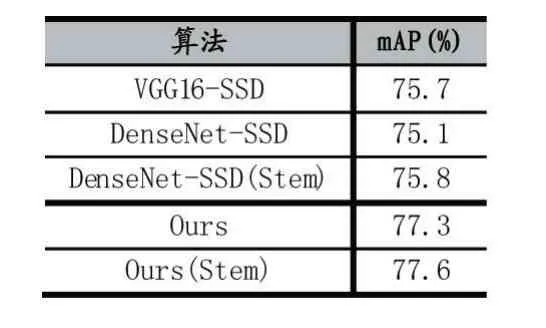
表2 本文數據集下不同算法性能對比
SSD 算法和改進的SSD 算法在不同場景的檢測效果分別如圖5-6 所示,前兩幅圖取自Caltech 數據集,后兩幅圖取自KITTI 數據集。可以看出SSD 算法存在的問題主要是對于較小的車輛和行人都存在一定程度上的漏檢,SSD 算法在前三幅圖均出現了漏檢問題,在分類置信度上也稍低。第四幅圖光線反差較大,兩種算法對光線良好處的車輛檢測效果均較好,但SSD 算法對樹蔭下的行人定位卻不夠準確。由此可見,改進SSD 算法精度更高,魯棒性較好。

圖5 原SSD算法檢測效果

圖6 改進SSD算法檢測效果
3 結語
為了滿足智能輔助駕駛中對行人和車輛檢測的精度要求與實時性要求,本文提出了一種改進SSD 算法,本文算法與原SSD 算法進行了詳細對比,實驗結果表明,改進后的SSD 算法在提升精度和小目標檢測能力的同時還保持了較高的檢測速度。未來的工作將繼續研究SSD 算法,設計更加輕量級的網絡,利用模型壓縮技術以滿足更大分辨率圖像檢測的需要,提高精度的同時保證速度。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
