LSTM網絡模型在Web服務器資源消耗預測中的應用研究①
2019-08-16 09:10:54譚宇寧黨偉超白尚旺潘理虎
計算機系統應用 2019年7期
譚宇寧,黨偉超,白尚旺,潘理虎
(太原科技大學 計算機科學與技術學院,太原 030024)
引言
軟件老化是指軟件(特別是大訪問量、大數據量的服務器軟件)在長期不間斷地運行一段時間后系統的性能持續下降、占用的資源不斷增加、錯誤不斷累積,最終導致軟件失效或系統宕機的現象[1].為盡可能地減少甚至避免損失,提高軟件的可靠性和可用性,Huang 等人提出一種主動性的容錯策略—軟件再生技術[2](Software Rejuvenation,SR),通過周期性地清除老化狀態,使得運行環境恢復正常,從而避免因軟件老化引起突發性失效.盡管通過抗衰操作可以消除軟件老化帶來的影響,然而對一個正常運行的系統執行抗衰操作勢必會帶來直接或間接的損失[3],因此如何能夠準確地對軟件老化趨勢進行預測,并及時采取相應恢復策略是當前預防軟件老化的研究重點.
目前對于軟件老化趨勢的預測主要是對影響軟件系統相關參數的資源損耗進行分析.梁佩[4]使用時間序列分析法以及馬爾可夫模型對軟件老化的資源消耗進行預測;蘇莉[5]等人使用非線性有源自回歸網絡模型來檢測軟件系統的老化現象;Jia[6]等人則使用多元線性回歸算法來分析和預測軟件老化問題;淵嵐[7]則建立了一個基于AdaBoost 算法的BP 神經網絡模型來預測資源的消耗.盡管很多學者使用回歸分析法、時間序列法以及BP 神經網絡算法等方法來預測遭受軟件老化影響的系統資源消耗情況,然而已有的單一模型很難達到理想的預測效果[8],因此文獻[8]提出使用混合模型,即將自回歸累積移動平均模型(Autoregressive Integrated Moving Average Model,ARIMA)和人工神經網絡結合來預測Web 服務器中的資源消耗.然而混合方法的構建過程復雜、人工依賴性強,不利于在實際中推廣和使用.
近年來,隨著深度學習技術的不斷發展,越來越多的深度學習模型逐漸被應用到各個領域.深度學習模型是一種擁有多個非線性映射層級的深度神經網絡模型,能夠對輸入信號逐層抽象并提取特征,挖掘出更深層次的潛在規律[9].其中循環神經網絡(Recurrent Neural Network,RNN)模型在結構設計中引入了時序概念,在學習具有內在依賴性的時序數據時能夠產生對過去數據的記憶狀態,能從原始數據中獲取更多的數據波動以及規律性特征,它的誕生解決了傳統神經網絡在處理序列信息方面的局限性.作為近年來深度學習領域熱點技術之一,在機器翻譯、語音識別及圖像識別領域都取得了巨大成功[10],然而在軟件可靠性領域對于資源消耗的預測目前還未發現展開過相關研究.
基于上述分析,本文提出了一種基于LSTM 的Web 資源消耗預測模型,該模型充分考慮了Web 資源損耗的時間特性,將當前的資源損耗情況動態的與歷史數據相關聯并將其與傳統模型進行實驗對比.結果表明該資源消耗預測模型在處理老化數據的時間序列建模問題上預測精度更高,能夠有效地應用于軟件老化趨勢的預測.
1 模型原理
1.1 循環神經網絡
RNN 是一類由各神經元相互連接形成的有向循環人工神經網絡,其基于時序展開后的結構如下圖1所示.與傳統的前饋神經網絡(Feedforward Neural Network,FNN)不同,RNN 不僅通過層與層間的連接進行信息的傳遞,而且通過在網絡中引入環狀結構,建立了神經元到自身的連接.每一步的輸出不僅包括當前所見的輸入樣例,還包括網絡在上一個時刻所感知到的信息即當前時刻的ht不僅僅取決于當前時刻的輸入xt,而且與上一時刻的ht-1也相關.
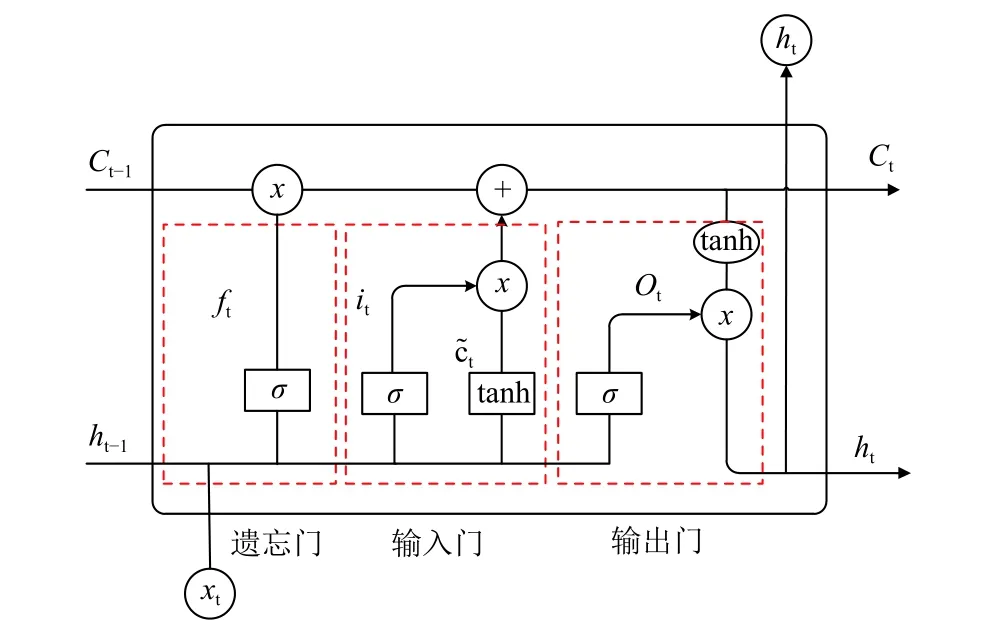
圖1 按照時序展開的RNN 結構圖
簡單的循環神經網絡由1 個輸入層、1 個隱含層以及1 個輸出層組成.給定輸入向量序列x=[x1,x2,…,xT],通過迭代下列公式(1)首先計算出t=1 至t=T的隱含層狀態序列h=[h1,h2,…,hT],然后根據公式(2)計算出輸出序列o=[o1,o2,…,oT].
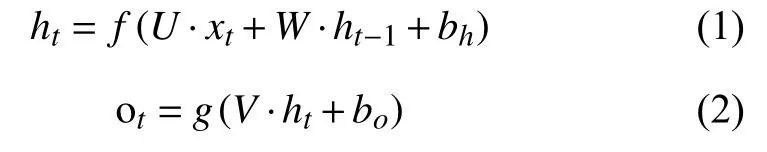
式中,U為輸出層到隱含層的權重矩陣;W為隱含層到隱含層的權重矩陣;V為隱含層到輸出層的權重矩陣,f和b分別表示輸入層到隱含層的激活函數以及偏置,g和b分別表示隱含層到輸出層的激活函數以及偏置.相比于FNN 需要n個時刻來幫助學習一次權重,RNN 可以用n個時刻學習n次W和U,實現了在時間結構上的共享特性.
將式(1)帶入式(3)可得:
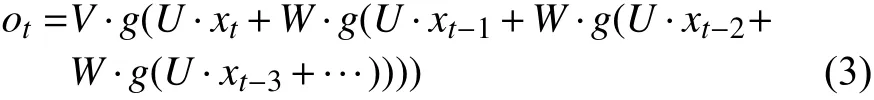
由式(3)可知循環神經網絡在計算過程中雖然加入了上一時刻的輸入,但隨著時間的推移,后面節點對前面節點的感知能力下降,即RNN 存在梯度消失問題.
1.2 長短時記憶單元
與傳統RNN 結構相比,LSTM 在其基礎上增加了一個細胞狀態(cell state).在傳遞過程中,通過當前輸入、上一時刻隱藏層狀態、上一時刻細胞狀態以及三個基于Sigmod 函數的門結構來增加或刪除細胞狀態中的信息,其具體單元結構如下圖2所示.其中門結構用來控制即時信息對歷史信息的影響程度,通過線性積累,使得網絡模型能夠較長時間保存并傳遞信息[11].
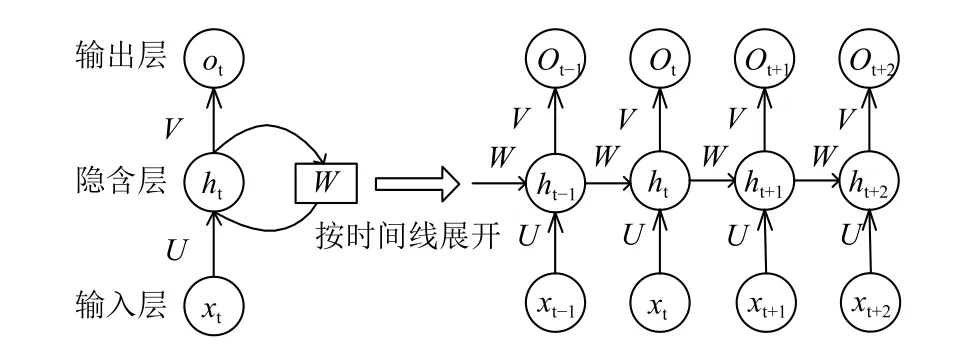
圖2 LSTM 單元結構圖
一個典型的LSTM 單元共有三個門:遺忘門、輸入門以及輸出門[12].其中遺忘門和輸入門主要用來控制上一時刻細胞狀態Ct-1以及當前輸入新生成的中有多少信息可以加入到當前的細胞狀態Ct中來,通過遺忘門和輸入門的輸出,更新細胞狀態,輸出門基于更新后的細胞狀態輸出隱藏狀態ht,各門計算公式如式(4).
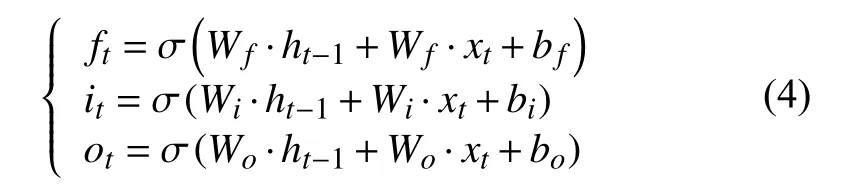
其中:ft、it、ot分別表示遺忘門、輸入門、輸出門的結算結果;Wf、Wi、Wo分別為遺忘門、輸入門、輸出門的權重矩陣;bf、bi、bo分別為遺忘門、輸入門、輸出門的偏置項.最終的輸出由輸出門和單元狀態共同確定,具體計算公式如式(5)所示.
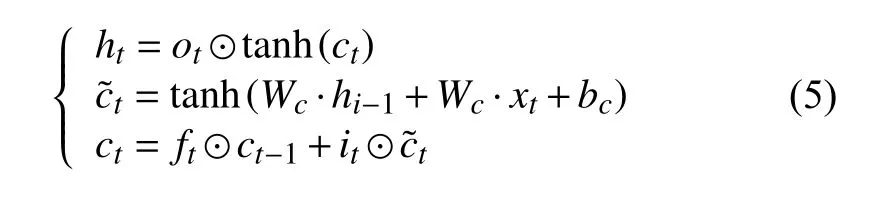
式中,xt為t時刻輸入的單元狀態;Wc為輸入單元狀態權重矩陣;bc為輸入單元狀態偏置項;tanh()為激活函數,⊙表示hadamard 乘積.
1.3 LSTM 預測模型具體構建過程
Web 服務器資源消耗預測就是根據前t時刻老化指標的資源使用特征來預測t+1 或者t+x時間內的資源損耗,以此判斷Web 服務器的老化狀況.因此通過使用老化數據對LSTM 神經網絡進行訓練,構建基于LSTM 網絡的軟件老化資源預測模型,其具體構建步驟如下所示:
(1)首先將原始老化數據清洗后進行特征表示和特征提取:定義老化資源損耗時間序列F={f1,f2,…,f},將其劃分為測試集Ftrain={f1,f2,…,fm}和訓練集Ftest={fm+1,fm+2,…,fn},其中m<n且m,n∈N,對Ftrain集合中的元素max-min 標準化,處理后的訓練集表示為式(6).
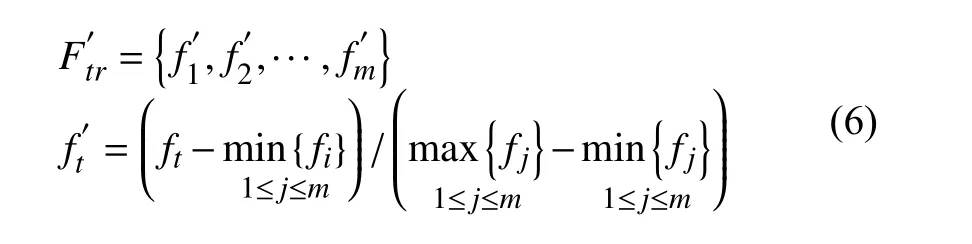
(2)構建訓練輸入以及對應的訓練輸出:對數據集進行時間融合,按照滑動窗口的大小s 進行分割,則模型輸入、輸出分別變為式(7)、式(8).通過設置s 的值,旨在訓練LSTM 網絡學習樣本數據前后的關聯及規律.
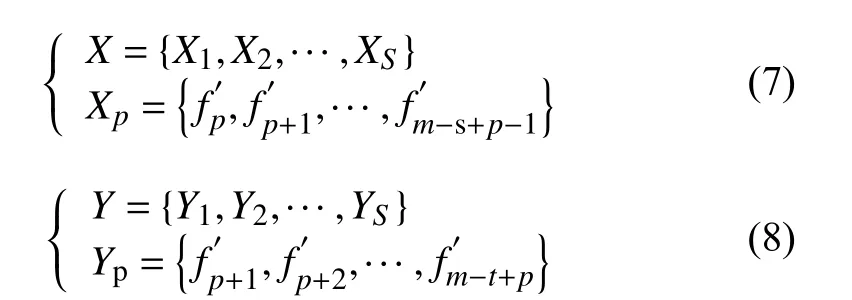
(3)確定網絡結構并初始化LSTM 網絡:確定每層激活函數的選擇、每層網絡節點的舍棄率以及誤差計算方式、權重參數迭代的更新方式.給定初始權值矩陣,設置最大迭代訓練次數和最小誤差值,通過改變網絡的各項參數來訓練網絡.
(4)前向計算:將X輸入網絡,根據前向計算公式(4)-(5)計算遺忘門、輸入門以及輸出門的值,經過隱藏層后的輸出結果可表示為:其中CP-1和HP-1分別表示上一個LSTM 細胞的狀態以及隱含層的輸出.
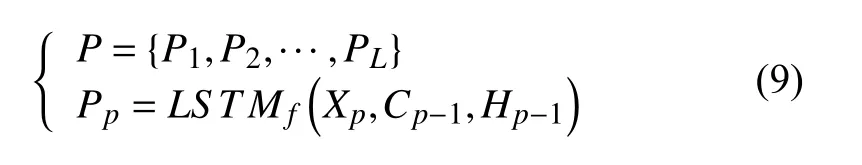
(5)誤差反向傳播:采用批量梯度下降算法對訓練數據進行批次(batch)劃分,通過對當前批次的損失函數進行優化,實時調整LSTM 網絡的權值和偏置,使網絡誤差不斷減小,既保證了參數的更新又減少了模型收斂所需要的迭代次數.
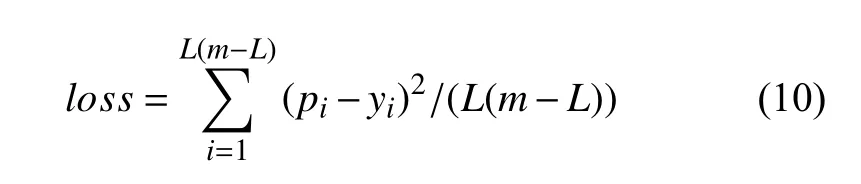
(6)將訓練好的模型用于預測:當迭代次數和最小誤差值滿足要求時停止訓練模型,并將未知的樣本數據通過迭代輸入模型得到預測序列Pte={pm+1,pm+2,…,pn},并對其進行反標準化處理得到最終預測序如式11.
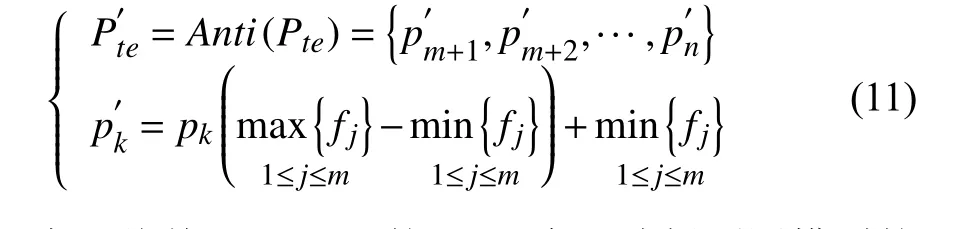
為評估基于LSTM 的Web 資源消耗預測模型的性能,運用平均絕對誤差(Mean Absolute Error,MAE) 和均方根誤差(Root Mean Squared Error,RMSE)作為評價指標來衡量模型的預測精度,其計算公式分別如式(12)和式(13)所示.
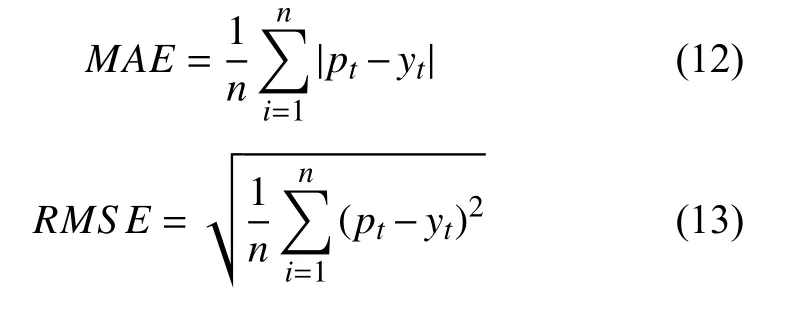
其中,n為Web 老化資源參數的樣本數目,pt為老化資源參數的預測值,yt為老化資源參數的真實值或觀測值,MAE 和RMSE 越小,模型預測能力越好.
2 實驗與結果分析
由于軟件老化是一個錯誤不斷累積的過程,一個Web 系統出現老化現象時并不會立刻失效,需要耗費很長時間才能觀察到系統故障.當前絕大多數的老化實驗只是簡單識別老化效應,很難準確把握軟件老化的整體趨勢[13].因此針對軟件老化的特性,本文根據R.Matias 等人提出的系統化方法,將工業領域已成熟應用的加速測試理論[14]引入到軟件領域,通過監測軟件系統的運行狀況,根據采集到的老化數據,建立一個基于LSTM 的Web 資源消耗預測模型.
2.1 Web 軟件老化加速壽命實驗
為研究因內存泄漏而導致應用程序故障的老化效應,本文以一個典型的Web 應用服務器為研究對象,搭建了一個引入內存泄漏的軟件老化測試實驗平臺.該平臺由一個Web 服務器,一個數據庫服務器以及一組模擬的客戶端組成,具體配置如表1所示.
服務器端實現了一個符合TPC-W 基準測試規范的多層電子商務網站系統.該系統模擬了一個在線售書網站,包括主頁、暢銷頁面、新書頁面、搜索頁面、購物車和訂單狀態頁面等14 種不同類型的網頁,并規定了一系列模擬真實環境下顧客的訪問規則.客戶端則是一系列模擬瀏覽器(Emulated Browser,EB),以會話(Session)為單位與服務器端建立邏輯請求,按照上述規則訪問服務器.模擬瀏覽器可以產生三種不同類型的工作負載,分別是Browsing 類型、Shopping類型以及Ordering 類型[15].因Shopping 類型的工作負載處于Browsing 和Ordering 之間,因此本實驗客戶端主要模擬Shopping 這種類型的工作負載,以隨機生成的概率對不同頁面進行訪問.

表1 實驗環境配置描述
內存泄漏是造成軟件老化的一個重要原因,因此內存使用情況是衡量軟件老化的一個重要指標,通過使用采集到的Java 虛擬機(Java Virtual Machine,JVM) 可用內存對Web 資源消耗進行預測來驗證LSTM 預測模型的準確性.為產生軟件老化現象,修改了服務器端商品查詢請求的TPC-W_search_request_servlet 類,為其注入內存泄漏代碼.由于JVM 有垃圾回收(Garbage Collection,GC)機制,任何不再被引用的對象都會被垃圾回收器回收,其占用的內存也會被釋放以便新對象使用.為模擬內存泄漏現象,增加了一個HeapLeak 類,使得Tomcat 的整個生命周期保持對該類HeapLeak 對象的引用,HeapLeak 對象在程序運行期間不會被垃圾回收器回收.修改JVM 堆內存的配置(表2),使實驗在受控環境下進行操作.由于Java 堆存的是對象實例,所以當創建的對象實例數量達到最大堆容量限制后會造成堆溢出.
運行客戶端,每隔1 秒采集一次JVM 內存使用量,實驗持續14 400 s,共4 個小時,采集到樣本14 400 個.每30 s 取一次均值,得到實驗數據(圖3).
2.2 LSTM 資源消耗預測建模
本文使用Keras 框架搭建并訓練LSTM 預測模型,所使用的網絡主要由循環層(Recurrent)中的LSTM 層和全連接層(Dense)組成.取前9650 個點(真實時間近似2.6 個小時)對未來4750 個點(真實時間近似1.4 小時) 進行建模預測,即使用67% 的數據作為訓練集,33%的數據作為測試集.根據2.3 節提出的模型具體構建過程對標準化后的JVM 內存序列建立一個含30 個隱藏神經元的單層LSTM 老化資源消耗預測模型,根據網格搜索參數尋優法確定模型參數,設置迭代次數epoch=20,batch=10,time steps=10,lr=0.001,損失函數為MSE.采用Adam(Adaptive Moment Estimation)算法對lr 進行優化,利用梯度的一階矩和二階矩估計動態調整每個參數的學習率,使得lr 平穩迭代,模型參數有效更新.由于深度神經網絡含有多個網絡層以及大量參數,為防止模型發生過擬合現象,采用Dropout對數據進行正則化處理即在每輪權重更新時隨機選擇隱去一些節點,從而限制模型單元之間的協同更新[16].該模型使用的Dropout 為0.5,即含有Dropout 的網絡層在訓練過程中,會有50%的節點被拋棄.

表2 JVM 堆內存配置描述
2.3 實驗分析
為驗證LSTM 模型在循環神經網絡中的優勢,將LSTM 中的隱含層單元替換為RNN 結構,按照上述相同參數進行實驗,結果如圖4所示.該圖從整體上反映出了RNN 以及LSTM 資源消耗預測模型的預測能力,其中實線表示真實值,虛線表示測試值.由圖4可知兩種預測模型測試值與真實值接近,預測趨勢與實際資源消耗趨勢基本一致,對于出現較大波動處的點也有較好的擬合,說明RNN 以及LSTM 模型能有效地對軟件老化趨勢進行預測.
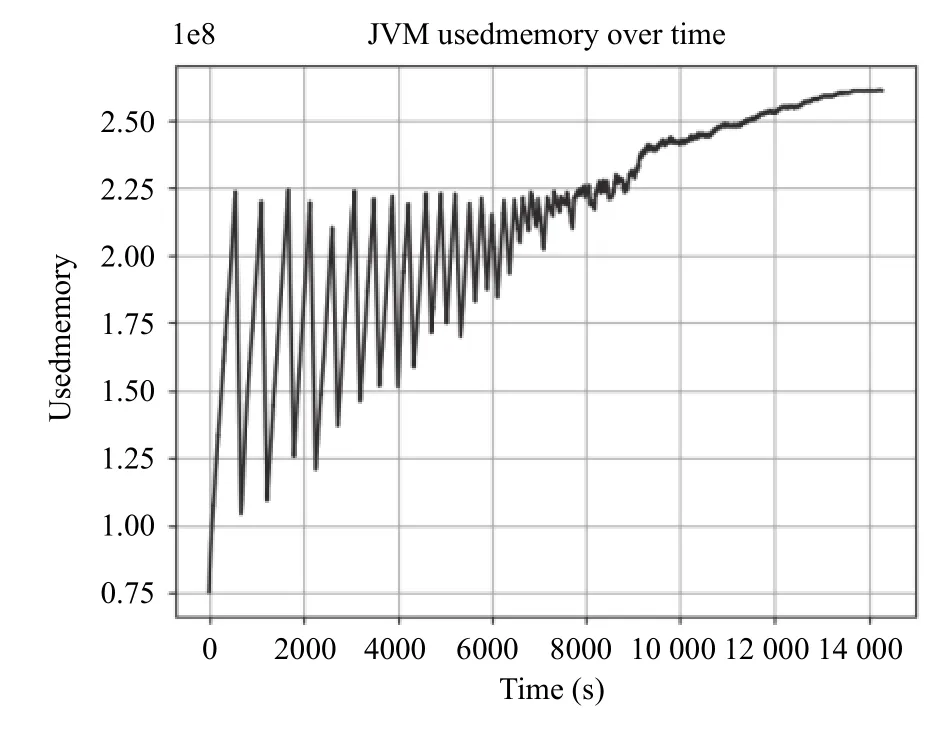
圖3 實驗數據
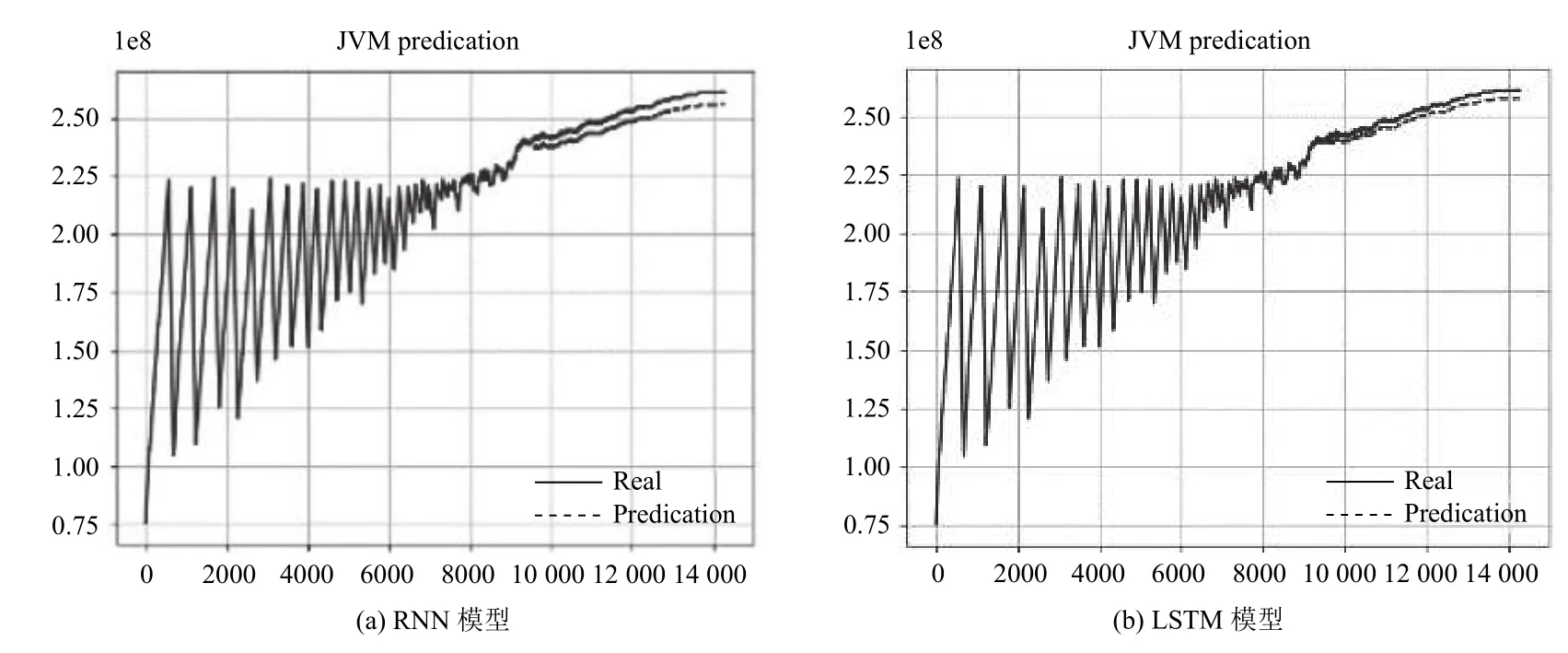
圖4 實驗預測結果圖
由2 種模型對應的損失函數圖5(a)、5(b)可知:在老化資源時序預測問題上,相比于RNN,LSTM 算法訓練過程相對穩定,測試集上的誤差波動較小.
為進一步驗證LSTM 的預測能力,將其與傳統預測方法:ARIMA 以及BP 神經網絡做對比,實驗結果如下圖6所示,由圖可知LSTM 模型的擬合程度更好.通過對3 種不同預測模型的評價指標進行對比,由表3可知,采用LSTM 網絡預測算法在預測Web 老化資源時,預測精度明顯高于其他兩種算法.
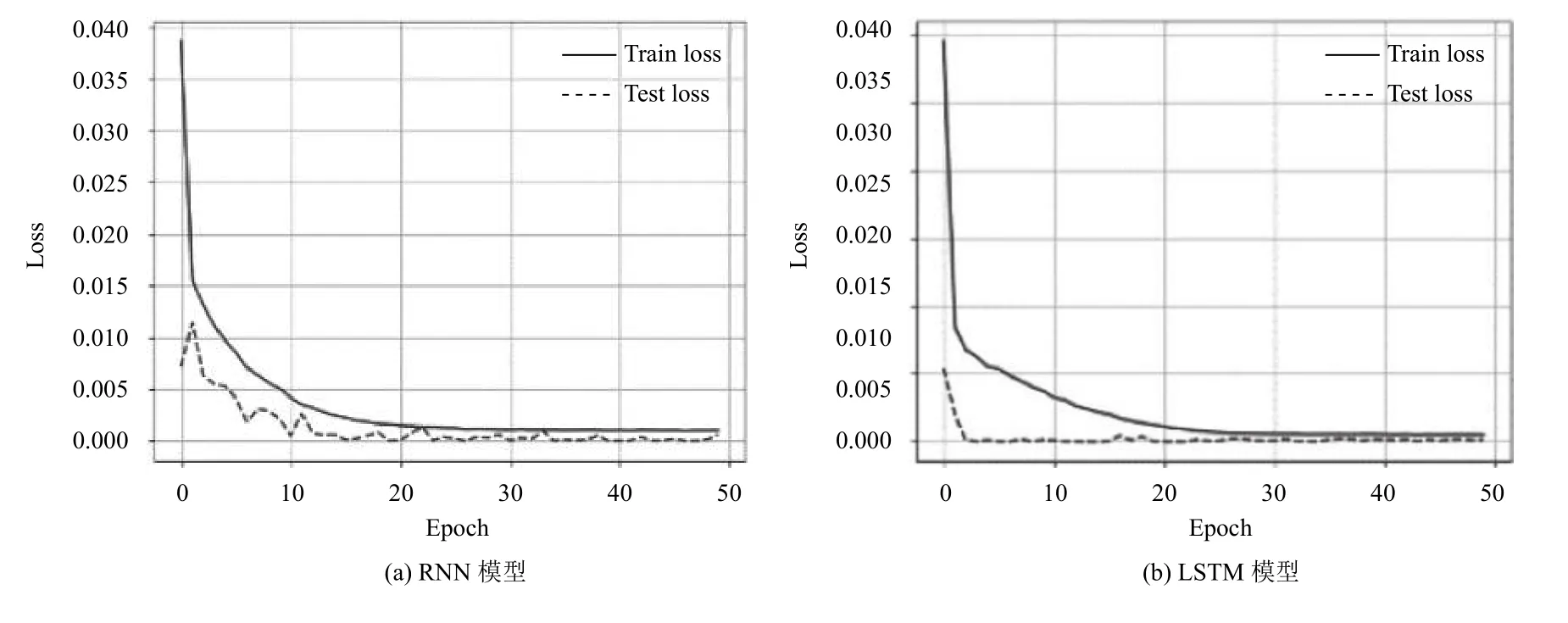
圖5 實驗損失函數圖
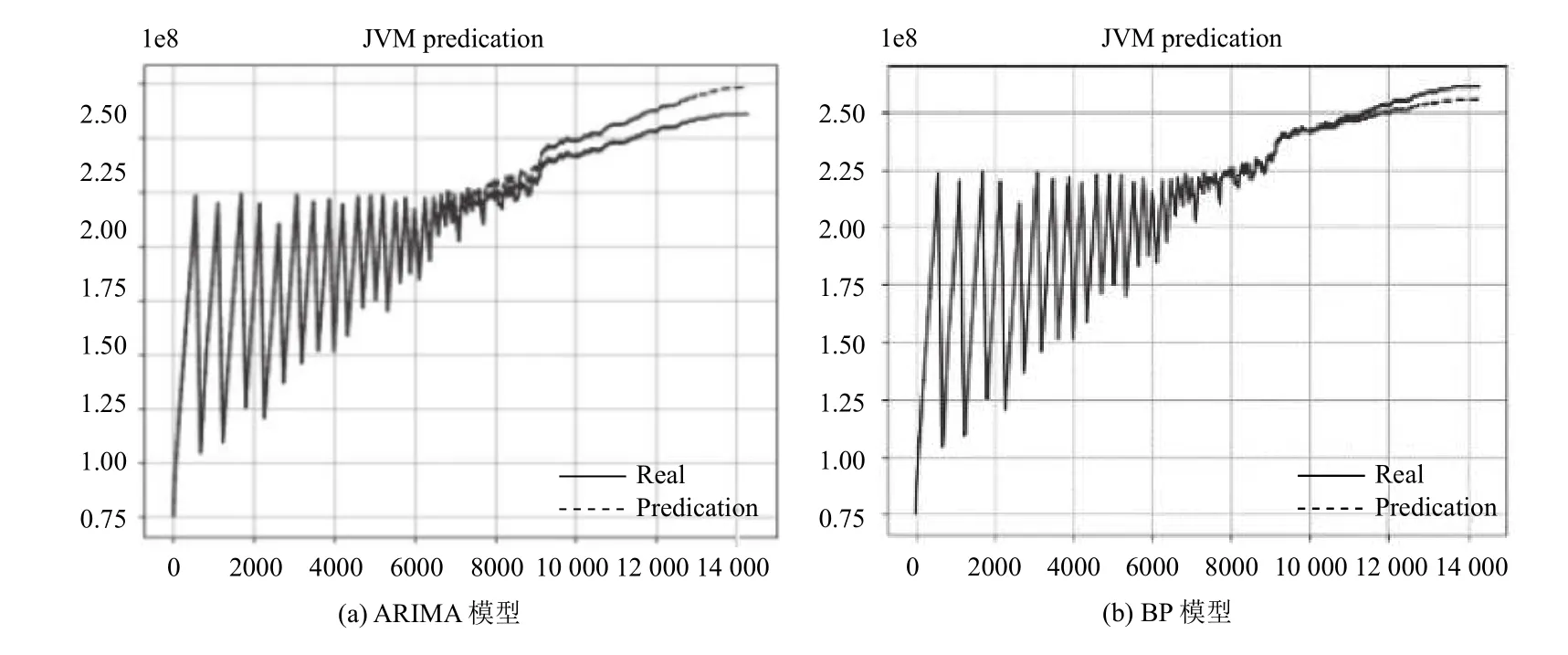
圖6 實驗對比結果預測圖
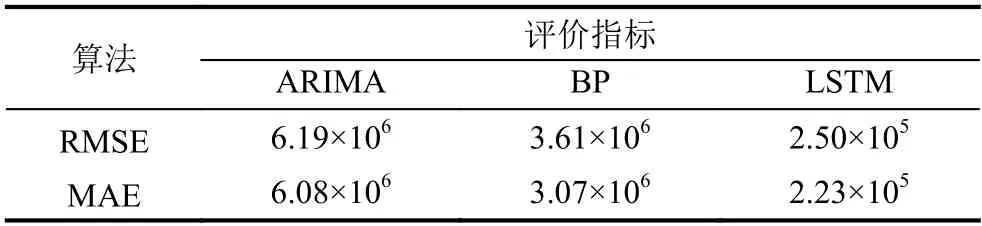
表3 預測精度對比
3 結束語
軟件老化是影響軟件系統可靠性的重要潛在因素,本文以一個典型的Web 應用服務器為實例,通過隨機注入內存泄漏的方式設計加速壽命測試實驗來加速系統老化過程,根據獲取的老化數據構建了基于LSTM 的Web 服務器資源消耗預測模型.結果證明該預測模型與Web 服務器資源老化趨勢一致,擬合度很高,能準確地描述軟件老化現象.與ARIMA 以及BP神經網絡相比預測度高、泛化能力好、誤差較小,說明LSTM 網絡模型能夠很好地描述Web 服務器資源的動態、非線性變化規律,適用于老化參數的時間序列建模.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
光學精密工程(2016年6期)2016-11-07 09:07:19
