深度學習目標檢測算法在行車記錄儀上的應用
2019-08-15 08:58:30王新雨汪馳升舒齊奇柯君卓
智能城市 2019年14期
王新雨 汪馳升,3* 舒齊奇 柯君卓 高 青
(1.深圳大學城市空間信息工程廣東省重點實驗室,廣東 深圳 518060;2.深圳大學海岸帶地理環境監測自然資源部重點實驗室,廣東 深圳 518060;3.國土資源部城市土地資源監測與仿真重點實驗室,廣東 深圳 518000;4.深圳市南山區教育科學研究中心,廣東 深圳 518000)
隨著社會的發展,行車記錄儀已經得到了廣泛的應用。在交通管理規劃方面,行車記錄儀也起到了重要的作用,可以記錄駕駛全過程的視頻圖像和聲音,實現了車輛駕駛的實時視頻監控、交通信息的采集和監控錄像的回放,為交通安全和交通事故來提供證據,提高了規范的駕駛行為和行車安全,在這一方面已經有很多應用的說明[1-2]。自從2012年,AlexNet模型以絕對優勢在Imagenet競賽中取得勝利,迅速蓋過了傳統目標檢測算法DPM (Deformable Part Model) 的風頭,計算機視覺開始轉向深度學習,此后深度學習在物體識別、檢測等方面取得了重大的突破性進展和很多的成果,就備受學者們的重視,已經成為人工智能重點研究之一,各大科技公司也都投身于深度學習領域進行研發。
深度學習是一種利用深度神經網絡框架的機器學習技術,其中卷積神經網絡 (ConvNet) 是專門做圖像識別的深度神經網絡,它是模仿大腦視覺皮質進行圖像處理和識別圖像的深度網絡,將人工設定特征提取轉變為自動生成特征提取是卷積神經網絡的主要優點,還具有局部連接和權值共享的特點,在目標檢測方面已經遠遠超過傳統的檢測算法[3]。還有一個很重要的硬件因素就是GPU提供了強大的并行運算架構,訓練速度比CPU快數10倍[4]。基于以上思想,提出一種利用行車記錄儀記錄的運動車輛的周圍環境數據信息結合深度學習的目標檢測功能對道路的車輛進行檢測識別,然后得出行車過程中的道路上車的位置和數量。總而言之,即將深度學習的目標檢測模型引入到行車記錄儀的監控視頻中,給智能交通監控、道路設計、交通管制和行車安全提供信息。
1 深度學習目標檢測算法的原理
目標檢測是指在特定環境下找出目標進行檢測(where) 和識別 (what),基于深度學習的目標檢測發展起來后,其實效果也一直難以突破,一直到R-CNN (Regionbased Convolutional Neural Networks) 出現后,它是第一個真正可以工業級應用的解決方案,后來經過不斷地改進卷積模型,讓大量的卷積層實現共享以提升效率,就出現了一系列的基于區域建議的方法:R-CNN 、SPP-net、Fast R-CNN、Ross B.Girshick[5]在2016年提出了新的Faster R-CNN,成為經典的模型。基于區域建議的目標檢測算法發展過程如下:
R-CNN結構框架如圖1所示[6],R-CNN的區域建議采用的是選擇性搜索 (Selection Search) 代替傳統的滑動窗口檢測方法,從原始圖片提取2 000個左右的候選框,再把所有候選框縮放到固定大小進行區域大小歸一化、用卷積神經網絡對這些候選框進行提取特征,將提取到的特征送入到SVM分類器中進行識別,再用線性回歸來修正邊框位置與大小[3]。但存在很多缺點:重復計算導致計算量很大,分類回歸的SVM模型是線性模型無法將梯度向后傳播給卷積特征提取層、訓練分為多步,訓練的空間和時間代價都很高。
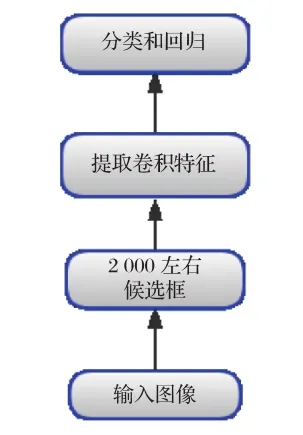
圖1 R-CNN框架
Fast R-CNN主要是解決了2 000候選框帶來的重復計算問題,卷積變成對整張的圖片進行,減少了很多的重復計算,其思想為使用一個簡化的SPP層,訓練和測試不再分為多步,不再需要額外的硬盤來存儲中間層的特征,梯度能夠通過RoI池化層直接傳播;此外,分類和回歸用Multi-task的方式一起進行,使用SVD分解全連接層的參數矩陣,壓縮為兩個規模小很多的全連接層[5]。Fast R-CNN比R-CNN的訓練速度快8.8倍,測試速度快213倍,比SPP-net訓練速度快2.6倍,測試速度快10倍左右。但是Fast R-CNN使用選擇性搜索來進行區域提名,速度依然不夠快[3]。
Faster R-CNN算法主要由兩大部分組成:RPN候選框提取部分和Fast R-CNN檢測部分[7]。在結構上已經將特征抽取、區域建議、區域判定和回歸、分類都整合在了一個網絡中,使得網絡的綜合性有了較大的提高[8-10]。它的主要思想為拋棄了選擇性搜索,引入了RPN (Region Proposal Networks),從而讓特征區域建議圖、分類、回歸一起共享卷積特征,在檢測速度方面尤為明顯[7]。RPN的網絡結構如圖2所示[7],以一張任意大小的圖片為輸入,輸出一批矩形區域提名,使用的是滑動窗口加anchor的結合,每個區域對應一個目標分數和位置信息,且RPN網絡能和整個Fast R-CNN檢測網絡共享卷積層[7],使得區域建議階段在GPU上完成,且幾乎不花費時,所以,Faster R-CNN 比Fast R-CNN 在速度和精確性上有明顯的提高,盡管在后來的發展中,SSD和YOLO這些模型能夠在檢測速度得到提升,但是它們的精度卻沒有能超越Faster R-CNN的,例如:Tensorflow 應用Inception ResNet打造的Faster R-CNN,是速度最慢,但卻最精準的模型[9-10]。
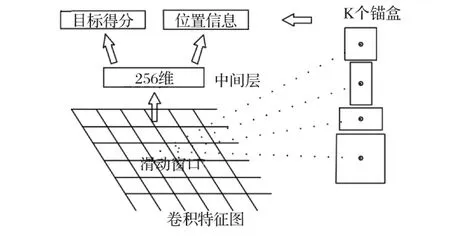
圖2 RPN結構
整個Faster R-CNN網絡的流程圖如圖3所示,分為4部分內容。
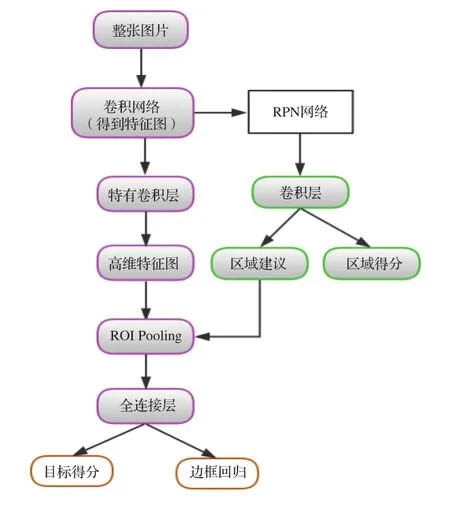
圖3 Faster R-CNN流程圖
(1) 先輸入一副任意大小的圖像,使用一系列的conv+relu+pooling層提取特征圖,被用于的RPN層的輸入和繼續向前傳播到特有卷積層得到高維特征圖用于全連接層。
(2) RPN網絡用第一步得到的特征圖進行兩部分的計算,分別為區域建議與區域得分,最后得到的區域建議用于下一步。
(3) ROI池化層是通過輸入的高維特征圖和區域建議提取一系列的特征區域建議圖 (proposal feature maps) 送入后續的全鏈接層進行目標識別。
(4) 最后是利用全連接層與分類層計算這一系列的特征區域建議圖通每個具體屬于那個類別,同時再次利用邊框回歸獲得每個目標的位置偏移量,從而獲得目標檢測框的精確位置。
最后,再由不同目標檢測方法的指標得出[3](見表1):在不在乎時間的前提下Faster R-CNN是準確率最高的,所以,本文使用Faster R-CNN算法。
我的第五次辭工申請終于獲準。離開大發廠時,我久久回眸。三步一嘆息,五步一回首,牽強的笑容牽動了幾滴清淚,在風中飄然落下。
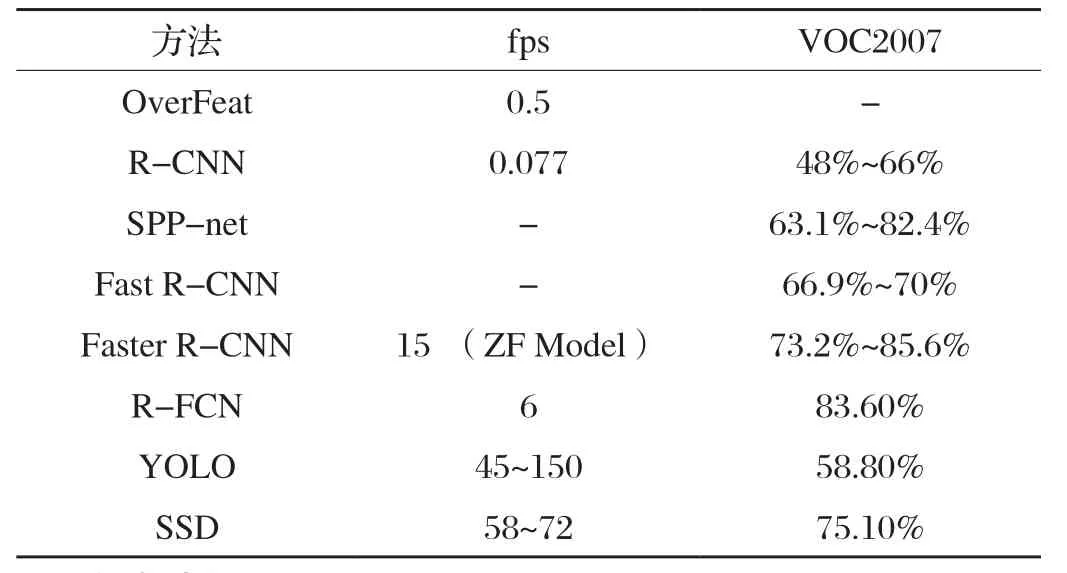
表1 不同檢測方法的指標對比
2 實驗過程
本文使用matlab的深度學習工具Faster R-CNN實現進行車輛檢測,實驗環境:MATLAB R2018a (自帶深度學習工具);CPU:i7-8750HQ;顯卡:GTX1060;內存容量:8 G。
2.1 數據集的建立
本文采集的數據是在白天的情況下,從行車記錄儀導出的100多個不同道路的行車視頻 (mp4) 文件,然后把視頻轉化為一幀幀的圖片 (jpg),每隔100幀提取一張的圖片,共1 500張,都是駕駛在城市道路,其中,小汽車數目居多,800張為訓練的圖片,100張為測試的圖片,600張為驗證圖片,用于標記的圖像樣本示例,如圖4所示。
2.2 數據集的標注
使用了matlab自帶的trainingImageLabeler.m這個M文件來對圖片進行標注,圖片標記界面如圖5所示,全部標注好后導出一個table的data.mat文件,得到標注信息,如圖6所示,一共包含1 400張圖片的車輛數據集,每個圖片有1個或多個標記的車輛實例。
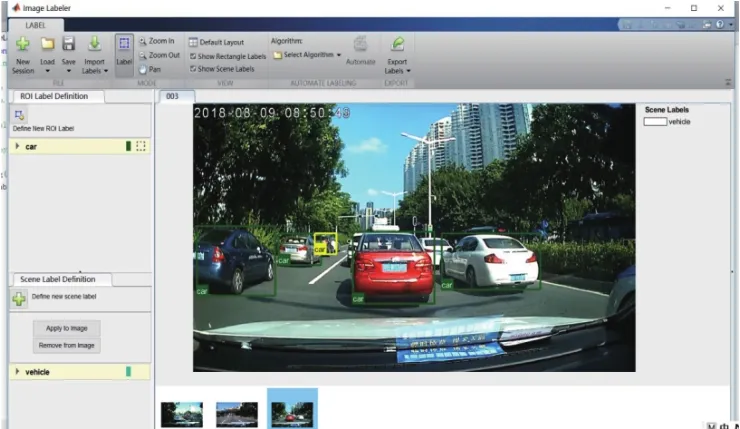
圖5 圖片標記界面
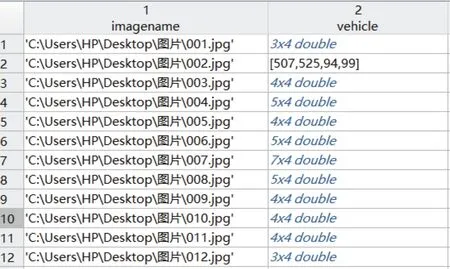
圖6 圖片標注信息
2.3 訓練過程
由于CNN檢測模型的訓練需要大量的標記好的圖片且訓練的時間太長,所以,本次實驗采用遷移學習,把訓練好的模型進行微調來進行目標檢測,因為是檢測車輛,所以只有有車和無車兩個類別,變成二分類問題[11],將全連接層改為2,然后再接上softmax和classification層,開始想使用ResNet50模型,但是在嘗試訓練過程中發現trainFasterRCNNObjectDetector這個函數不支持 DAG networks,像ResNet-50、 Inception-v3和 GoogLeNet這些模型就都不能用了。其實各網絡就是在卷積層提取特征時有細微差異,對于后面的RPN層、池化層、全連接層的分類和目標定位基本相同。后來選擇使用VGG16Net這個模型進行遷移學習,VGGNet網絡是從ImageNet 數據庫上的100萬多張圖像進行訓練的,可將圖像分類為1 000個對象類別,如鍵盤、鼠標、鉛筆和許多動物,因此,網絡為各種圖像學習了豐富的功能制圖表達,網絡共有41層,有16層可學權重,13層卷積層和3層完全連接層。在訓練過程中如果要使用GPU訓練需要 Parallel Computing Toolbox這個工具箱,在附加功能資源那里下載即可,還需要用到Computer Vision System Toolbox、Image Processing Toolbox和Deep Learning Toolbox這幾個工具箱。在訓練參數中:選擇了一個最小的16像素×16像素的窗口,網絡誤差算法使用的是動量隨機梯度下降算法,學習率設置的0.001,每次輸入的最小批次的大小是32,迭代次數20次,其余選項為默認[12-13]。訓練用trainFasterRCNNObjectDetector
這個函數訓練目標檢測器,在訓練過程中,從訓練圖像中處理多個圖像區域,每個圖像的圖像區域數由NumRegionsTo Sample控制,PositiveOverlapRange和NegativeOverlapRange名稱-值用于控制訓練的圖像區域,正面訓練樣品是那些與地面真相箱子重疊由0.6到1.0,由聯合度量的邊界框相交測量,負訓練樣本是重疊的0到0.3。
Faster RCNN訓練分為以下四個步驟:
第一步是單獨訓練RPN網絡,用預載入的模型來初始化。
用第一步的RPN 網絡提供的區域建議來單獨訓練Fast R-CNN目標檢測網絡。
用第二步訓練好的Fast R-CNN網絡的權重來重新訓練第一步的RPN模型,繼續訓練RPN。
用第三步訓練好的RPN網絡輸出的區域建議圖作為輸入,再次訓練Fast R-CNN,微調Fast R-CNN中的參數,得到目標檢測模型。至此網絡訓練結束。
2.4 測試過程
車輛檢測模型訓練好以后進行保存,把100張的測試數據集循環到檢測模型里進行檢測,從檢測的圖片可以得到前方車輛的個數、位置 (bboxes) 和得分 (scores),車輛檢測結果示例如圖7所示,只顯示檢測出的車輛得分 (scores) 0.9以上的圖片。

圖7 車輛檢測情況示例
2.5 驗證過程
matlab的計算機視覺工具箱提供了目標檢測器的評估功能,在這里用平均精度指標 (evaluate detection precision),Precision-recall曲線來驗證模型的準確率,評估結果如圖8所示,從評估結果來看,模型的平均精度達到0.92,滿足檢測的需求。
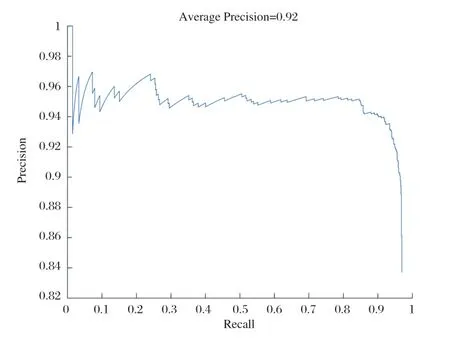
圖8 模型的評估結果
3 實驗結果分析
本次實驗結果的分析是在行車視頻中依次轉化的一幀幀圖片上面進行的,通過檢測出的車輛可以得出標記框(bboxes) 的信息,bboxes是一個N×4矩陣,用于表示對象的邊界框,前兩列x、y代表了邊界框的位置,后兩列為w、h代表邊界框的寬和高,w、h相乘得出標記框的像素面積,除了面積通過從bbxoes中的參數n可以得到檢測到的標記框的個數既車輛個數,圖片的視野像素面積為圖片分辨率1 287×724=931 788,通過以上信息,本文進行以下分析。
3.1 基于行車舒適性的分析
在道路上交通量較小車速較快時,車頭間距較大,交通密度小,駕駛員可以自由選擇行駛車速,行車比較舒適;交通量較大車速較慢時,車頭間距縮小,密度加大,車輛行駛時相互制約,產生擁擠情況,行車過程中不再舒適。根據行車的舒適性這個概念,本文對于多個不同路段的視頻進行了檢測,計算出每幀圖片上檢測到所有車輛標記框的像素面積占視野面積的比例和車輛個數,計算得出:當每幀圖片的面積比超過0.4這個臨界值時,車輛個數較多,密度較大,行車不再舒適。然后用百度地圖測出每個行車視頻中起點和終點的距離,得到的距離除以行車記錄儀記錄的時間求出行車速度,用行車速度進行驗證,判斷是否合理。以其中記錄深圳市的香梅路、南海大道、新洲路、安托山一路、僑香路、深南大道六條道路的行車視頻為例,每個行車視頻記錄時間為65 s,統計過程如表2所示。根據表2的驗證:面積比保持在0.4以下,車速較快,行車比較舒適。所以這個指標合理。我們可以根據這個指標測出每個路段的行車是否舒適,然后為道路的交通規劃和設計提供參考。
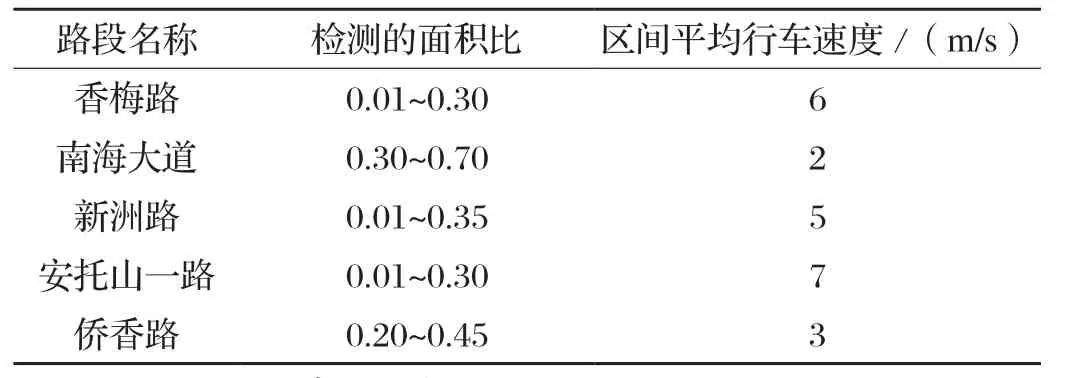
表2 面積比與行車速度的對比
3.2 基于車間距離的分析
目前常用的車間距離測量方法主要包括超聲波、雷達、激光等,這些測量手段基本都是成本比較高的,如果行車記錄儀可以測量輛車之間的距離,那么成本就會降低很多,也會非常的便捷[14]。 在道路行駛過程中為了保證車輛間的安全距離,駕駛員在駕駛過程中需要時刻注意周圍的車輛運動情況,以免發生追尾碰撞的問題。據網上調查,車輛追尾事故中80%是因為行駛時跟車太近引發的,據交警介紹,很多追尾事故是因為車速過快,未與前車保持安全距離引起的[15]。本文中每幀圖片上面標記框的面積大小代表了道路上的車輛和駕駛車輛之間的距離,距離近的標記框的像素面積較大,距離遠的標記框的像素面積較小,所以本文提出根據標記框的面積大小計算出道路上各個目標車輛與駕駛車輛之間的距離,顯示在行車記錄儀上,距離過近時給出警報,也可以給駕駛員的行車安全距離提供參考。由于本文是采集了前方車輛的數據和小汽車這類車型,所以只計算前車車距并且不適用于公交車和卡車等車型,測量方法借鑒[16]中的車距模型并修改得出:當相機焦距固定時,兩車之間的實際距離的平方與車輛在圖片中的標記框像素面積的乘積是個定值,如公式1所示。實驗先采集大量的數據,實際測量兩車之間的距離和對應的標記框的像素面積的大小,代入公式1計算,然后統計得出大概的定值為18左右,再根據這個定值和標記框的像素面積求出前方車距。求出車間距離后,再用實際的距離做驗證,如表3所示,可以看出檢測距離和實際距離雖存在誤差,但是大概相符。車間距離和像素面積擬合的曲線如圖9所示,隨著車間距離的增加,檢測到的車輛標記框的像素面積在減小。所以,根據像素面積大小來大概判斷車間距離時可行的,可以為駕駛員提供參考。

式中:L—兩車的實際距離 (m) ;
S—標記框的像素面積 (10-5) ;
F—定值。
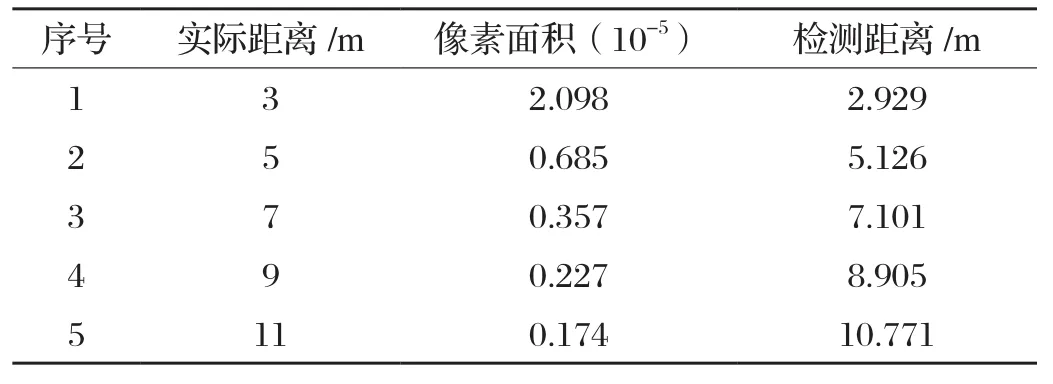
表3 實際距離與檢測距離的對比
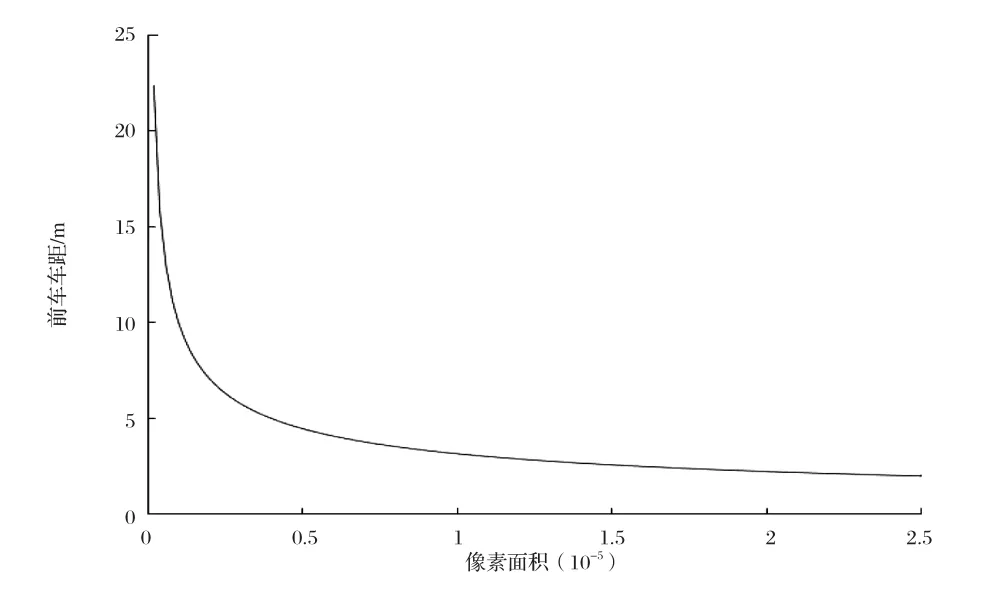
圖9 像素面積大小和車間距離的關系
4 結語
本次實驗是將深度學習的目標檢測功能引入到了行車記錄儀中,側重點是深度學習的應用上面,所以沒有對已有的算法進行改進和各類已有框架精度的比較。模型訓練算法為主要分析圖像區域的Faster R-CNN算法,標記的數據均來自白天,標記的車型比較全面,還需考慮夜晚的情況。實驗得出模型的檢測準確率為0.92,說明準確性較高,但是過小的目標車輛檢測不到,同時存在由于處理的數據量較多而不能實現實時檢測的要求,所以檢測算法有待優化,接下來的工作打算用海量的無標注的行車視頻數據來訓練,從而達到實時檢測的要求。檢測出目標車輛后,根據檢測到的標記框獲得前方車輛的信息,提出行車舒適性和駕駛車與前方車輛的車距,本次實驗由于車型、角度、道路場景和計算方法的欠缺[16],所以提供的指標、參數存在一定的誤差,只供大概的參考,還需進行更詳細的工作,但是希望通過行車記錄儀得出的這些信息能給智能交通監控、交通管理規劃設計和輔助駕駛提供幫助。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
