軟件開發活動數據集的層次化、多版本化方法*
2019-08-13 05:06:46朱家鑫周明輝
軟件學報 2019年7期
朱家鑫, 周明輝
1(北京大學 信息科學技術學院 軟件研究所,北京 100871)
2(高可信軟件技術教育部重點實驗室(北京大學),北京 100871)
3(中國科學院 軟件研究所 軟件工程技術研究開發中心,北京 100190)
隨著軟件開發支撐技術的發展,相關工具在軟件開發生命期中的覆蓋度以及在軟件項目中的普及程度越來越高.版本控制系統、問題(issue)追蹤系統、郵件列表是在開發中最為常見的支撐工具.它們的數據庫中(軟件倉庫)記錄了軟件的新功能開發、缺陷修復、代碼審查等多種活動.隨著開源運動的不斷發展壯大,開放的軟件開發活動數據在不斷地累積并達到了非常可觀的規模[1].通過分析這些數據,人們可以獲取對開發活動更為準確和深刻的認識,進而有效地改進軟件開發實踐[2-4].
對軟件開發活動數據的分析通常需要人們投入大量的時間與精力收集、清洗與組織數據[5].在過去,大多數研究工作都是獨立地進行數據準備工作,而這種方式非常低效:一方面,很多研究問題所需要的數據是相同的,因而整個研究社區中會出現大量重復性的工作;另一方面,基于不同數據集的分析結果在重現和對比時容易出現數據集缺失(例如分析者沒有公開所研究的數據集、數據集的鏈接失效等)、數據格式不統一、數據集差異引入混雜因素等問題.因此,很多工作嘗試著去構建和共享公共的數據集來解決這些問題[5-9].
雖然有越來越多的研究者與實踐者關注了軟件開發活動數據的共享,但這些工作的關注點主要在于數據的公開和推廣,關于數據可用性[10-13]的考慮還存在較大不足.首先,現有的共享數據集有原始數據和定制數據這兩種形式.共享原始數據的做法減少了使用者在數據收集方面的成本,共享定制數據可以進一步減少數據預處理的成本.然而,大多數定制數據集的構建過程可追溯性差,即數據收集與處理的過程不清晰,缺少中間結果,不利于數據質量的驗證以及分析異常的排查,適用范圍也相對有限.其次,現有數據集往往是通過一次收集或者若干次增量收集而得到的,并沒有考慮到數據收集環境的變化以及軟件開發活動的變化,這些變化對數據可用性的影響也就無法得到揭示和處理.針對上述問題,本文提出一種層次化、多版本化的數據集構建及使用方法.首先,該方法提出根據數據處理的不同程度劃分不同的數據層次,使數據集包含原始、中間和最終多個層次的數據,從而建立數據集構建過程的可追溯性,并兼顧應用時的普適性;其次,該方法提出使用不同的方式在不同的時間段進行多次數據收集,形成數據集的多個版本,盡可能地將數據變化納入其中,為數據質量及分析結果有效性的驗證和提高創造條件.基于我們構建的 Mozilla問題追蹤數據集[14],本文展示了這種改進的數據集的構建和使用方法,并驗證了其效果.
本文第 1節介紹軟件開發活動數據集的構建與共享現狀,揭示其中的不足,并有針對性地提出層次化、多版本化的數據構建與使用方法.第2節詳細闡述該方法.第3節給出一個具體的數據集構建實例.第4節展示基于該實例的5個應用示例.第5節對全文進行總結.
1 軟件開發活動數據集的構建與共享現狀
利用軟件開發支撐工具所記錄的數據來支持軟件開發實踐的改進是當前軟件工程研究的一大趨勢[3].這種數據驅動的軟件開發活動分析主要包括了圖 1所示的一系列步驟.首先,從目標項目所使用的開發支撐工具的數據庫,即軟件倉庫中收集原始數據;其次,對這些原始數據進行清洗,去除無關數據、噪音數據;接下來,對這些預處理后的數據進行適當的組織及存儲,方便后續的使用;在具體的研究中,分析者會根據研究問題建立相關的量度,從數據中得到度量結果并進行分析;最后一步是分析結果的驗證與應用.可以看到,在進行分析之前,研究者要進行數據的收集、清洗、組織、存儲,而這部分工作的成本可能非常高昂,特別是面向大規模數據的時候[15].需要特別注意的是,這種成本包括了以下兩個方面:首先,數據的可得性由項目的數據開放政策決定,有些項目的數據需要與業務繁忙的項目管理者進行漫長的交涉,最終簽署協議才能獲得,即便是公開的數據,由于要保障開發活動的正常進行,對開發支撐工具高頻率的數據獲取請求也是被禁止的,因此數據收集需要大量額外的時間開銷;其次,分析者個人的網絡條件也可能造成一些困難,例如網絡帶寬、網絡訪問的限制等,這些因素也會增大數據收集的復雜性.除了數據的收集,大量異構原始數據的清洗、組織也需要較大的人力和數據存儲成本.因此,很多研究者提出通過數據共享來提高數據分析的效率:減少每一次分析的數據準備成本,減少整個研究社區中的重復數據準備工作,方便數據分析結果的重現與對比.
目前,研究社區中已經有了相當多構建與共享數據集的工作,它們主要包括兩類:一類是構建與發布特定的數據集,另一類是建設數據集共享的平臺.挖掘軟件倉庫的代表性會議 Int’l Conf. on Mining Software Repositories(MSR)[4]設有Data Showcase專區,其中發表的大多數數據集是其作者在各自的研究中所構建的.這些數據集中有的將軟件項目的開發歷史數據進行整合,例如Spinellis將UNIX系統44年的代碼演化歷史整合到一個Git倉庫中,通過Git命令人們可以查詢到過去UNIX代碼發生的改變[16];有的則對某些項目托管網站的數據進行大規模收集,為研究者提供數量眾多的軟件項目的多種開發活動數據,包括版本控制數據、問題追蹤數據等,例如Gousios領導的收集、共享GitHub平臺上眾多開源項目開發數據的GHtorrent項目[17],還有一些是從軟件倉庫中提取與加工面向特定問題的數據集,例如Amann等人基于Sourceforge和GitHub上眾多版本控制庫構建的用于測試 API誤用檢測器性能的標桿數據集 MUBench[18].數據集共享平臺建設的典型項目有FLOSSmole[5]和 PROMISE[6],旨在為研究者們提供一個協作化的數據共享平臺,人們可以貢獻與獲取符合一定規范的各類軟件開發活動數據,并分享自己基于這些數據所得到的研究成果.而MSR會議的Mining Challenge專區為研究者提供了一個數據分析競賽平臺,研究者基于一個公共的數據集來開展各種分析并一較高下.為了促進跨軟件倉庫挖掘的研究,Keivanloo等人又在平臺的建設上提出了將各類開發活動數據進行連接[19],他們設計了一種軟件開發活動數據模型,該模型中包含了一系列軟件開發所涉及到的對象,例如項目、代碼、缺陷、開發者、代碼提交等,從版本控制、問題追蹤等軟件倉庫中提取出這些對象并建立它們之間的關系,如開發者A執行了代碼提交B,代碼提交B修復了缺陷C.基于該模型,開發者們搭建了SeCold平臺來共享有連接的軟件開發活動數據集.
上述工作的關注點主要在于促進數據的公開和傳播,而數據共享中的數據可用性問題還有待進一步研究.數據可用性被關注最多的方面是數據質量[20],研究者們提出了數據的時效性、一致性、精確性、完整性、代表性等多個方面[21-26]的屬性來刻畫數據質量.從應用的角度來講,數據質量決定了上層分析結果的有效性,例如在預測缺陷修復時間時,數據中標定的缺陷修復完成時間的精確性非常關鍵,錯誤的時間記錄會使得預測模型無法得到有效的訓練而給出錯誤的結果[27].再如,在訓練缺陷預測模型時,訓練數據中若包含非缺陷相關的噪音數據,則模型的性能會出現一定的下降[28].數據可用性還有另一個關注較少的方面——數據的適用范圍,即一個數據集能夠幫助解決多少問題,例如基于某個項目的版本控制數據定制的一個關于缺陷修復活動的數據集可以用來度量該項目的缺陷密度、項目中開發者修復缺陷的經驗等,但因為它只包含了缺陷修復的活動而無法用來度量版本控制數據中記錄的其他開發活動,如實現軟件的新功能.
之前的數據集構建工作在數據可用性的保障上都或多或少地存在一些不足.這些不足主要表現為兩點:一是數據集缺乏構建過程的可追溯性,即從原始數據到最終數據的整個數據處理過程沒有詳盡而準確的描述,中間結果缺失;二是對數據收集與軟件開發活動的改變所引發的數據變化欠考慮.
可追溯性決定數據使用者能否處理分析中遇到的異常、驗證數據質量、解決更多的軟件開發問題.有些數據共享工作提供所收集的原始數據,例如MSR07的Mining Challenge專區提供的問題追蹤數據集[29],而更多的工作則提供經過清洗、轉換等處理后定制化的數據,例如 Habayeb等人的 Firefox Temporal Defect Dataset(FTDD)[30],Gousios等人的GHtorrent MySQL database dump數據集[17].相對于原始數據,分享定制化的數據可以降低數據預處理的成本,然而,這些數據集大都以黑盒式的方式提供,原始數據以及中間的處理過程、中間數據都較為模糊或者完全缺失,可追溯性較差,由于缺少中間的過程及數據,數據質量驗證以及分析異常的處理,這些需要追溯數據處理過程的工作難以開展,定制過程中被移除的開發活動信息也無法得到恢復,能夠用以解決的軟件開發問題只能是特定的.
對數據變化的考慮程度決定了數據分析的結果是否有效以及在什么樣的條件下有效.當前大多數數據共享工作并沒有對可能的數據變化予以考慮,共享的數據集大都是一次收集或者若干次增量式收集所得到的,由于缺少參照,數據收集環境的變化以及軟件開發活動的變化無法被揭示,其中,數據收集環境的變化可能引起數據質量的改變,例如訪問受限、網絡連接中斷、腳本缺陷等會導致數據的缺失和出錯,軟件開發活動的變化可能導致原有數據分析結果不再有效,如Ioannidis指出很多已有數據分析結果在新的數據集上無法得到重現[31].
為幫助解決上述問題,本文提出一種改進的數據構建及使用方法,通過層次化使數據集的構建過程可追溯,使數據集的適用范圍可伸縮,通過多版本化來捕獲數據的動態變化.在下一節中我們分別對這兩種設計進行詳細的介紹.
2 數據集的層次化與版本化
2.1 數據集的層次化
本文所提出的“層次化”概念中的“層次”指的是依據對數據進行預處理的程度而劃分的不同數據層次.考慮多個數據層次既可以降低數據收集與預處理的成本,又可以通過保留全部業務信息來兼顧數據的適用范圍,與此同時,數據集構建過程的追溯性也得到了建立,保障了數據質量與數據分析結果的有效性.
如圖2所示,層次化的數據集包含兩個基本的層次:原始數據層(層次0)和標準化數據層(層次1).層次0中的數據是從開發支撐工具中所收集到的未經其他處理的數據,這些數據保留了數據共享者在數據收集時能夠獲取的全部開發活動信息,并且不包含數據預處理所可能引入的偏倚.但是,層次 0中數據的數據模式由支撐工具所定義,在使用前需要進行特定的解析來獲取相關的信息,例如從版本控制系統的庫中獲取提交信息需要使用系統提供的接口(命令行或圖形化用戶接口、編程接口)來進行查詢,從問題追蹤系統中獲取問題追蹤信息需要對 Web頁面進行解析.此外,原始數據中可能包含大量的與開發活動無關的數據及冗余數據(如Web頁面中用來布局和美化頁面的標簽等),增加不必要的數據傳播和存儲開銷.因此,對原始數據進行數據提取和標準化十分必要.本文設計了層次 1來加入標準化數據.標準化數據包含了從原始數據中提取出的全部開發活動相關數據,并且以方便后續使用的數據格式來組織,例如解析簡便、以純文本方式存儲的 CSV(comma-separated values)格式[32].在層次 1之上,數據共享者還可以增加面向特定研究問題的層次2+的數據.這些較高層次中的數據經由對層次1中數據的進一步處理而得到.這些處理與研究問題相關,可以是特定開發活動信息的提取、數據的拼接、數據的轉換等,例如從郵件列表的數據中只提取出那些關于代碼審查的會話,構建代碼審查數據集[33];將一個缺陷的報告與解決該缺陷的代碼提交進行連接[34];將問題報告的解決活動進行抽象、編碼[30].
使用層次化數據集的第 1步是選取適當層次的數據.一般而言,當確定要使用某個軟件開發支撐工具所記錄的數據時,任何分析都可以使用相應數據集中層次 1的數據.這是因為層次 1的數據包含了目標工具中記錄的全部開發活動信息,能夠滿足不同問題的數據需求.雖然使用層次 0的數據也可以達到同樣的目的,但使用層次 1的數據既可以減小數據下載及存儲的代價,又不需要進行數據的提取及標準化.如果要重現某項研究的結果,或者是進行相似問題的研究,那么可以考慮直接使用更高層次的數據,省去相關的數據提取、拼接甚至度量的工作.例如,如果要研究問題報告(issue report)解決過程中的活動模式,則可以直接使用Habayeb等人所構建的FTDD數據集[30]而不是MSR07 Mining Challenge的數據集[29],該數據集已對原始的問題追蹤數據進行了數據標準化之外的深層處理,其中的數據相當于本文介紹的層次2或層次2+中的數據.利用這樣的數據集可以免去對問題處理活動與問題報告屬性之間的拼接(在原始數據中這兩類數據是分別保存的)、對問題處理活動的編碼等.但是,該數據集并不是層次化的,其所包含的問題追蹤信息可能無法滿足其他研究的需求.例如,該數據集在對活動編碼時過濾了問題報告狀態的變遷信息,對于需要考慮該信息的研究,FTDD顯然是不適用的.這個時候就需要回到層次1,基于層次1中的數據重新構建更高層次的數據.
層次化數據集的可追溯性對于提高數據分析結果的有效性非常有幫助.在使用高層次的數據進行分析時,數據使用者如果遇到異常,可以回退到較低層次來排查異常產生的原因.這些異常可能來自于軟件開發活動本身,也可能來自數據收集以及后續處理的過程.隨著數據層次的提高,原始數據被處理的程度在不斷加深,其間出現差錯的概率也會隨之增大.利用層次化的數據集,使用者可以以逐層回退的方式查找異常的源頭.如果異常僅出現在某個層次以上的數據層中,那么它是由相關數據收集或處理腳本的缺陷所引起的.此時,要對錯誤進行修正并重新構建有問題的數據層.如果支撐工具的數據庫中也存在該異常,那么它很可能由軟件開發活動中的某些特殊情況所引發.此時,要對該異常作進一步的探查及解釋,并在數據處理中根據具體情況對異常數據進行分離、過濾或者保留.
2.2 數據集的多版本化
本文提出的“多版本”概念中的“版本”指的是通過不同的方式或是在不同的時間所收集到的各個數據快照.包含多個版本的數據可以將數據收集及軟件開發中發生的各種變化納入到數據集中,為提高數據的質量及分析結果有效性建立基礎.
如圖 3所示,多版本的數據要以多種方式在多個時間段以不同的方式進行數據收集.數據的收集一般有兩類方式:一類是通過開發支撐工具的交互接口間接地獲取數據,另一類是直接導出開發支撐工具后臺數據庫中的數據.對于前者,工具的交互接口又可以分為圖形化的或命令行的人機交互界面,以及應用程序編程接口(API),例如GitHub API[7];對于后者,數據庫的類型可能是普通的關系型數據庫,如Bugzilla的MySQL關系型數據庫,也可能是工具自定義的數據庫,如 Git基于對象的有向無環圖數據庫.在這些收集方式中進行切換、對比可以揭示不同方式對原始數據所產生的影響,進而建立評估每種方式所得數據的質量的基礎.間隔一定的時間,例如 1年,進行多次數據收集則可以納入我們在第 1節中提到的數據變化,這些變化可以分為兩類:一類是數據收集環境的變化,另一類是軟件開發活動的變化.數據收集環境的變化可能導致數據收集過程中異常情況的發生,例如數據源訪問受限導致部分信息無法獲取.這些異常情況將使收集到的數據發生殘缺或錯誤.開發活動的變化會改變相應的數據,可能使其具有不同的特點和性質.
在進行數據分析時,數據使用者需要充分考慮上述數據收集方式的不同及數據本身的變化,分析它們是否反映了數據質量問題,對數據分析結果的有效性存在怎樣的影響.使用多版本數據的核心思想是對不同版本數據進行交叉對比,實現數據質量的驗證、開發活動變化的分析、數據分析有效性的評估和提高.
數據質量的驗證在單一版本的數據集上相對困難,數據使用者需要對軟件開發活動本身有深入的理解、擁有分析相關數據的豐富經驗[2]才能發現其中存在的質量問題.而利用多版本進行對比則容易得多.具體來說,數據使用者首先找出版本間的不同,然后探究這些不同是否反映了數據質量問題.例如在第4.2.2節中提到的不完整的用戶郵件地址顯然屬于數據質量問題.該問題可以利用多版本中的冗余數據(其他版本中完整的地址)進行修復.
軟件的開發活動在不斷推進演化,多版本間的不同也包含了開發活動變化.我們可以借助該特點拓展研究問題的范圍,探究新的有價值的問題.例如,探索識別敏感問題報告的技術、解決敏感問題報告的最佳實踐.
當在單一的數據集上進行數據分析時,分析者對分析結果的有效性缺乏足夠的認識,無法對分析過程及分析模型進行改進.而多版本的數據集中納入了多種實際發生的開發活動的變化.該特點可以幫助評估和提高數據分析有效性.例如,在開源項目長期貢獻者形成的研究[35]中,我們使用了 3個版本(這里簡稱版本 A、B和 C)的Mozilla問題追蹤數據.版本A與B是通過爬取Bugzilla的Web頁面所得到的,版本C是后來取得的官方的Bugzilla數據庫dump.借助于這3個版本的數據集,我們對研究結果的有效性進行了兩項驗證,在第1項驗證中,我們使用版本A擬合(訓練)模型,使用版本B測試模型;在第2項驗證中,我們使用版本C重現前面得到的模型.通過這種方式,我們在更大程度上保障了研究結果的有效性.
3 數據集構建示例
根據上一節提出的方法,我們構建并發布了一個Mozilla問題追蹤數據集(該數據集已發表于MSR 2016的Data Showcase Track[9].本文系統化地闡述了構建此類數據集的方法論,并基于該數據集做了多項具體應用),其訪問地址為https://github.com/jxshin/mzdata.Mozilla是一個具有20多年歷史的大型開源軟件項目,它旗下有我們耳熟能詳的Firefox瀏覽器、Thunderbird郵件客戶端等產品.該項目使用了Bugzilla問題追蹤系統[36]來管理各類開發問題,例如軟件缺陷、新功能請求(它們被總稱為“問題”)的報告及解決.在Bugzilla中,問題報告的報告時間、報告者、處理進度、處理結果等信息被跟蹤記錄,關于這些信息的細節,第 3.1節有詳細的介紹.目前,已有非常多軟件工程的研究使用了問題追蹤數據,所研究的問題包括缺陷的預測[37]、定位[38]、分類[39]和修復[40],開源代碼的貢獻的機制[41]等,其所具有的價值可見一斑.因此,我們利用上一節提出的方法構建具有更高可用性的Mozilla問題追蹤數據集來支撐相關研究.下面兩個小節分別從層次化和多版本化兩個方面詳細介紹了該數據集.
3.1 層次化的Mozilla問題追蹤數據集
該數據集包含了層次0和層次1兩個基本數據層.其中,層次 0是從 Bugzilla所獲取的原始數據,對于不同版本的數據(詳見第 3.2節),原始數據的形式會有所區別,在某些版本中,層次 0的數據是通過Bugzilla的用戶 Web界面所獲取的 Web頁面,而在其他的版本中,這些原始數據是從Bugzilla后臺數據庫中導出的脫敏dump.如圖4所示,這兩種形式的原始數據包含了相同類型的信息,包括每個問題報告的報告者、報告時間、嚴重程度、狀態等屬性,某些屬性(如問題狀態)的變更歷史以及關于該問題報告的評論、評論者.在 Bugzilla的 Web界面中,這些信息由兩類頁面所記錄,一類是關于問題報告基本信息的頁面(HTML或XML格式),包括問題報告的當前屬性和相關評論,另一類是部分問題報告屬性變更記錄的頁面(HTML格式);而在 Bugzilla的后臺數據庫中,每一類問題追蹤信息記錄于相應的數據表中.關于這些原始數據的數據模式,XML及HTML文件中的標簽的name說明了每個域的含義,而數據庫中有一張叫作fielddef的表,表中包含了各個域的含義.
從Web界面獲得的層次0數據除了包含開發中人們報告和解決問題的活動記錄,還包含了大量的HTML及XML標簽,這些標記使得數據產生較大的膨脹,不利于數據的傳播及存儲.此外,為了從Web頁面中分離出問題追蹤的業務數據,還需要對這些頁面進行解析.因此,我們進一步構建了層次 1的標準化數據,將層次 0中的XML、HTML頁面、數據庫dump標準化.這種標準化處理僅僅是數據格式的轉換,所有層次 0中的問題追蹤信息都得到了保留,但層次1數據的體量有了大幅度的減小.層次1的數據采用了CSV格式,數據的解析與提取相比于原始的Web頁面要容易得多.該層數據分為問題報告基本信息與問題報告處理活動歷史兩部分,圖5描述了基本信息(a)與活動歷史(b)的數據模式,每一項基本信息由record_id唯一標識,每一條評論域的命名方式為“long:〈評論 id(此條記錄內)〉:〈評論屬性名〉”,每一個問題屬性域由對應的屬性命名,“=”后接各個域的值;每一項活動歷史同樣由record_id唯一標識,每個域的命名方式為“〈活動id〉:x”,其中,x編碼了活動的屬性,0為活動執行者,1為執行時間,2為被修改的問題屬性,3為屬性原值,4為屬性新值,Bug表示對應問題報告的id,“=”后接各個域的值.
在層次 1之上,數據使用者可以對數據進行提取、組合、計算等處理,構建面向某些特定研究問題的定制化問題追蹤數據,例如第4.2.1節中所介紹的示例.
3.2 多版本化的Mozilla問題追蹤數據集
目前,我們的Mozilla問題追蹤數據集共有4個版本,每個版本最直觀的區別體現在原始數據獲取的時間及方式的不同上.首先,這4個版本的原始數據分別收集于2011年、2012年、2013年和2016年,為了方便闡述,我們以這4個年份來命名這4個版本的數據;其次,這4次數據收集使用了兩種不同的方法:一種是目前研究社區中最常使用的基于爬蟲的方法,我們批量地下載Bugzilla的用戶Web頁面;而另一種方法則與眾不同,我們通過積極地與Mozilla社區溝通,獲得了的經過脫敏處理的Bugzilla后臺數據庫dump.我們使用前者收集了2011年與2012年的數據,而通過后者收集了后兩個版本的數據.相對于Web頁面,數據庫dump的下載要容易很多,它既不會干擾社區的正常工作,也不會受到訪問頻率及下載速度的限制以及爬蟲自身 bug的影響.表 1是這 4個版本數據的概況,從中我們可以看到,它們在問題報告數量、參與者人數等各個方面都存在明顯的不同.
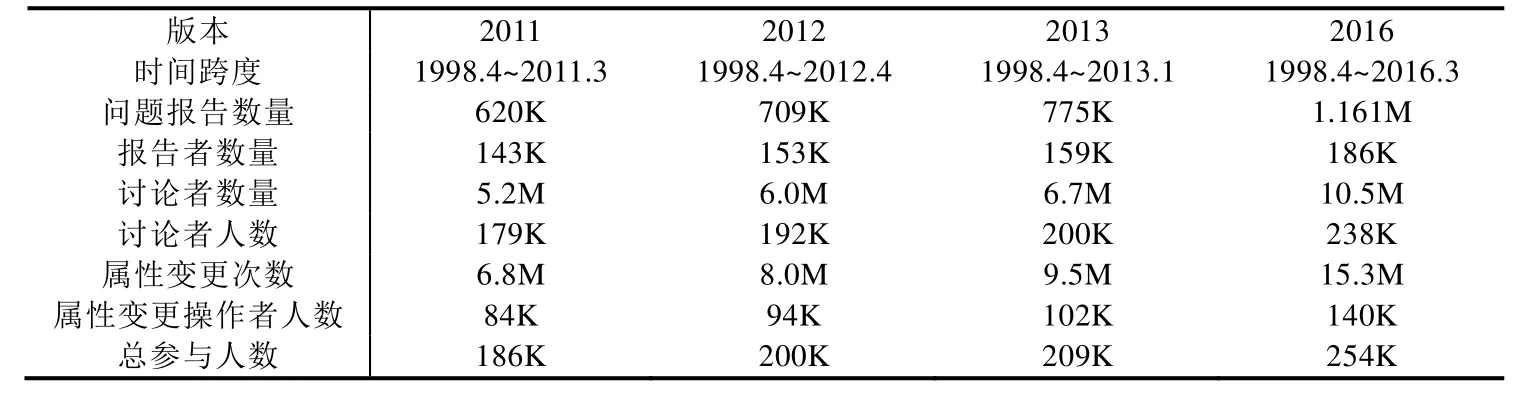
Table 1 Summary of the Mozilla issue tracking dataset表1 Mozilla問題追蹤數據集的概況
我們進一步對比和總結了各個版本間的差異.首先,本文在第 3.1節已經闡述過,不同的數據收集方式獲得的原始數據模式不同.其次,爬取的數據由于經歷了較長的數據下載過程,一致性較弱.例如,一小部分問題報告的屬性值與其最后一次變更的值不匹配,這是因為第 3.1節提到了兩類 Web頁面是分開收集的,存在一定的時間差,這期間可能發生相關屬性的修改活動.最后,新版本的數據還包含了一些新的變化,主要包括以下5類.
(1) 新增加與減少的問題報告.新增問題報告主要是隨時間推移而新提交的報告,此外,還包括了過去未被公開的敏感報告.減少的問題報告主要包括因具有敏感性而被隱藏的報告.
(2) 新增的問題報告屬性值.隨著開發的演進,某些問題報告屬性的值域會產生一定變化,例如某個問題所屬的軟件版本,在較新版本的數據集中,該屬性的取值范圍會增加后續編排的新版本號.
(3) 新增的開發活動參與者.開發社區中不斷地有新的人員參與進來,如新的問題報告者、開發者、評論者等,他們的活動記錄會出現在較新版本的數據集中.
(4) 新增的問題處理活動.在一次數據收集中,會有相當一部分問題報告還處于處理過程中,因此,在新收集到的數據中會增加這些問題報告的后續處理記錄.
(5) 問題報告屬性值的變化.根據變化的原因我們將其歸為 4種類型:① 由問題的后續處理活動所引起的,例如,問題被分配到新的開發者,問題的處理狀態更新;② 由開發者對自己賬戶修改所引發的,如用戶郵件地址的變更;③ 由于收集過程異常而導致的,如因爬蟲丟失登錄狀態而導致的用戶郵件地址后綴的缺失;④ 不同數據收集方式下原始數據格式不同造成的,例如Web頁面中的時間戳有時區信息而數據庫中的時間戳缺少該信息.
4 數據集應用示例
我們通過層次化使數據集具備了可追溯、可擴展性,通過多版本化在數據集中納入了數據的變化,我們期望數據使用者可以利用這些特性來提高數據質量、提高數據分析結果的有效性、拓展研究范圍等.本節以上一節中介紹的Mozilla問題追蹤數據集為例,從對數據變化性的挖掘及對數據集構建過程的追溯兩個方面來展示5個應用,示范層次化、多版本化數據集的使用,驗證本文方法的有效性.
4.1 數據變化性的發掘與應用
軟件開發活動會使相應的數據產生多種變化,某些變化可能會給數據使用者的分析造成一定的困難,例如同一個開發者在不同階段使用不同的身份標識,造成開發者識別的困難;而某些變化則會給人們帶來探索新問題的機遇,例如新數據集中所包含的在過去敏感的數據為敏感問題的研究提供了機會.將數據多版本化之后,我們可以通過對比某些對象及其屬性在不同的版本間的變化來檢查和修復數據的不一致,驗證分析模型的有效性或者研究新的軟件開發問題.
第3.2節總結了示例數據集新舊版本間的變化情況,下面就其中的3項具體變化:Bugzilla用戶賬戶的改變、活動時間戳的改變以及新增問題報告與活動數據,我們做了示范性的3個應用.
4.1.1 Bugzilla用戶賬戶的改變
Bugzilla用戶,即軟件開發活動的參與者在使用該系統時需要創建自己的賬戶,該賬戶以用戶所填寫的郵件地址作為用戶標識.因此,數據分析者通常利用郵件地址來對不同的用戶進行識別,然而這種方法存在一定的局限性.圖6展示了用戶與賬戶、賬戶與郵件地址之間的對應關系.其中,一個用戶可以注冊多個Bugzilla的賬戶,而一個賬戶在使用過程中也可能更換郵件地址.因此,直接以郵件地址來識別用戶可能會把一個實際的用戶當作多個.目前,已有研究者嘗試提出識別這些“別名”的方法[42,43].然而,“別名”的識別仍然存在很多的困難尚待解決,尤其是問題追蹤數據中的“別名”識別,其中最主要的是缺乏檢驗這些方法是否有效的測試數據(特別地,基于有監督學習的方法缺乏必要的訓練數據).因此,我們嘗試在多個版本的Mozilla數據間進行比對,探究是否可以發現“別名”實例,是否可以進一步利用多版本的手段更完全地抽取出開發者們所使用的“別名”,建立“別名”的數據集.

Table 2 Usage of multiple e-mail address and accounts表2 用戶使用多郵件地址、多賬戶的情況
Bugzilla中每個問題的報告者是某一個特定的開發者,不會發生改變,這是客觀事實.對于某個問題,如果系統中記錄的報告者的郵件地址在不同版本的數據集中不同,那么這些不同的郵件地址一定都屬于該報告者,他們代表同一個人.根據該原理,我們將 4個版本的數據集中的同一個問題的報告者的郵件地址提取出來進行對比、聚集.具體地,我們首先將關聯到同一個問題的郵件地址收集到同一個集合中,然后通過非大小寫敏感的字符串完全匹配將這些集合中包含相同地址的集合合并,最終得到使用過多個郵件地址用戶以及他們使用過的郵件地址.此外,在一個版本的數據集中,作為一個賬戶的標識的郵件地址一定是唯一的,如果一個用戶的多個郵件地址出現在了一個版本的數據集中,說明該用戶使用了多個賬戶.我們利用得到的每一個用戶的郵件地址集合,在每一個版本的數據集中進行郵件地址的完全匹配查找,結果發現,確實存在一個用戶使用多個賬戶的實例.表2是對用戶使用多個賬戶、多個郵件地址的情況的總結.從中可以看到,大約有2 046個(1949+88+9,約1%)用戶使用過兩個及以上郵件地址,所涉及的郵件地址有 4 198個.使用多個賬戶的用戶則要少很多,我們只發現了35個,占比不到萬分之二.
我們利用4個版本的數據集挖掘出了4 000多個“別名”郵件地址.排除外部的客觀因素,例如Bugzilla系統的bug可能引入的錯誤數據,該方法所識別的多郵件地址、多賬戶一定都是真正例(true-positive),達到了本示例的目的.至于識別的完整性,該方法無法保證.如果擁有更多的版本,我們可以得到更為完全的結果.當擁有這樣的“別名”數據集后,研究者便可判斷“別名”對所要分析的問題所造成的威脅大小,對“別名”進行去重,甚至可以對用戶使用“別名”的習慣進行挖掘,尋找相關的模式.
4.1.2 活動時間戳的改變
在全球開發背景下,數據分析者要特別注意開發活動時間戳的時區,如果時區信息被忽略,那么計算中的某個活動的時間誤差可能會高達24小時(地理位置最多可差24個時區),這種誤差會對某些較為精細的時間度量造成較大的威脅,例如開發者在一天當中的工作時段及在不同時段中工作的效率.在從Bugzilla的Web界面獲取的原始數據中我們可以看到,所有的時間戳都標注了時區(如圖7(a)所示),而在Bugzilla的數據庫dump中,時區信息是缺失的(如圖 7(b)所示),那么我們能希望知道在 Bugzilla數據庫 dump中的時間是否是以統一的時區來進行記錄的.
如果只有Bugzilla數據庫的dump,我們很難去回答這個問題.但當我們擁有了從Web界面獲取的數據,就可以對比同一個事件,例如一個問題報告的提交在兩個不同版本數據集中的時間.我們對比了通過所有報告在Web界面獲得的數據中記錄的提交時間和數據庫dump中記錄的提交時間,結果發現,數據庫dump中的時間戳比Web界面中的時間戳少了時區,其他數字一致.這說明,數據庫dump中所記錄的活動時間是不準確的.為了探查這種偏差的程度以及是否有可能修復,我們進一步分析了Web界面中時間戳的時區,結果發現,只涉及到了兩個時區,分別是太平洋標準時間(PST-0800)和太平洋夏季時間(PDT-0700).其中,太平洋夏季時間在美國的夏季使用:在2006年以及之前,PDT始于每年4月第1個星期日深夜二時正,并終于10月的最后一個星期日深夜二時正.在2007年及以后,PDT始于每年3月的第2個星期六深夜二時正,并終于每年11月的第1個星期日深夜二時正.我們對Web界面獲取的數據集進行了分析,查看了PST與PDT在月份上的分布,結果符合上述規則.因此,我們可以利用該規則對數據庫 dump中的時間進行修正,填補相應的時區信息,例如在數據庫 dump中,第665317號問題的報告時間是2011-06-18 13:35:00,它發生于2007年之后,具體時間在6月,處于3月的第2個星期六深夜二時和 11月的第 1個星期日深夜二時之間,填補時區 PDT.再如第 619558號問題的報告時間為2010-12-15 16:22:00,在上述范圍之外,填補時區PST.
4.1.3 新增問題報告與活動數據
在挖掘問題追蹤數據工作中,有很多都是構造某種分類模型,幫助提高問題處理的效率.例如,對問題報告是否為重復報告(與某個正在處理的報告反映的是相同的問題)進行識別的模型.這些模型需要訓練數據來構造,也需要測試數據來評估模型的性能并對其進行調整.獲取這兩類數據的通常的做法是將一個完整的數據集分成兩個部分:一部分作為訓練數據,另一部分作為測試數據.這樣的測試數據是否能有效地代表實際應用中的輸入數據決定了模型的可用性,是一個值得關注的問題.當我們擁有了兩個在不同時間段所收集的數據集時,便可以構造出3類數據:實驗中的訓練數據、測試數據(較早版本中的數據)、實際應用中的數據(較新版本中的數據)來回答該問題.下面,我們就以2013年與2016兩個版本的Mozilla數據以及識別重復問題報告的分類器為例進行研究.
首先,我們構造一個簡單的識別重復問題報告的分類器:該模型基于邏輯斯蒂回歸,使用問題報告提交者的問題報告熟練程度作為預測因子(很多研究顯示,開發者的經驗與其工作產出的質量相關[44]),其中,問題報告是否是重復報告以問題的在Bugzilla中所記錄的Solution來標定,Solution為DUPLICATE的為重復報告;問題報告的熟練程度以問題報告提交者在此之前所提交的問題數量來量化,由于熟練程度還與距離上一次提交問題報告的時間間隔存在一定的關聯性,我們將時間限制為半年內,即問題報告提交者在此之前半年內所提交的問題數量(NR).只要該模型的判定能力強于隨機猜測即可達到實驗目的.模型如下所示:
其次,基于2013年的數據集進行模型的訓練、測試及調整.我們選取了數據集中最近5年,即2008年1月1日(北京時間,下同)后得到解決的(有Solution的)問題報告.此外,問題的最終解決需要經過一段時間的驗證,即發現 Solution的錯誤并糾正,因此,數據集中最后一段時間的問題報告的 Solution有相對較高的不穩定性,無法準確地判斷其是否是重復問題報告.我們對關于DUPLICATE的Solution錯誤出現的頻率及其糾正時間進行了統計,發現有約 2%的報告存在這樣的錯誤,其中超過75%的報告在 1年內得到了糾正.因此,我們過濾掉其中最后一年的問題報告,即保留2008年1月1日~2012年1月1日之間提交的問題報告,保證其中不準確報告的數量小于 0.5%(2%×(1-75%))(由于部分錯誤的糾正需要 10年以上的時間,為了保證有足夠的數據,本文以損失 1年的數據為代價使不準確的報告數量控制在 0.5%以內).對剩余報告,我們按照其被提交的先后順序選取了前80%作為訓練數據,而后20%作為測試數據.訓練結果見表3,可以看到,NR的系數顯著不為0,其解釋度為2.9%,這說明,該模型具備判定能力,滿足本示例的需求.

Table 3 Model training result表3 模型訓練結果
模型 1的輸出值表征了一個問題報告是否是重復報告的概率,在應用該模型做判定前還要設置一個閾值,當模型的輸出大于這個閾值時,即判定該問題報告是重復的.為了選取合適的閾值,我們對輸入訓練集得到的輸出的分布進行統計,每10%分位點取一個值(即10%,20%,30%,…,90%分位數)作為9個候選的閾值,利用測試集分別評估選取不同閾值時模型的性能,模型的性能以F1-score,即準確率與召回率的調和平均數的兩倍來度量.表4展示了在不同閾值下模型的性能,從中我們可以看到,在閾值為0.214 2(60%分位點)時,模型性能達到最優.
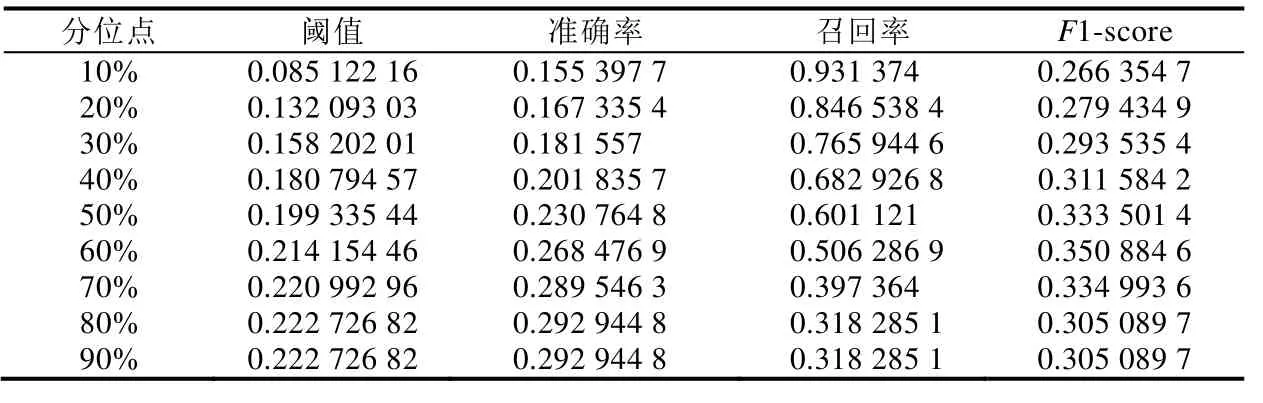
Table 4 Threshold selection and model performance in test表4 閾值選擇及模型在測試中的性能
接下來,我們探究在實際應用中,選取這些閾值的模型是否也能夠有相同的表現.我們使用 2016年數據集來模擬實際應用的場景.同樣,考慮到問題處理結果的穩定性,除去數據集中最后一年的問題報告,為了測試已有模型在未來應用中的性能,選取2013年數據集收集1年之后所提交的新報告,即從2016年數據集中節選2014年1月~2015年1月的1年間提交的已解決的問題報告.實驗結果見表5,從中可以看到,60%分位點的閾值已不具有最佳的分類表現,并且在新的數據集上無論選取哪個閾值,模型的F1-score都不如實驗階段的結果.為了探索其中的原因,我們首先比較了自變量NR在訓練數據和實際應用數據中的均值和平均數,它們分別從40和15上升到 831和 43,發生了較大的改變;其次.我們使用新增數據對模型重新訓練,結果表明,報告者近期提交報告的數量的解釋度遠高于使用 2013年數據訓練的模型(見表 6),也就是說,模型預測能力的下降是因為實驗中的模型參數已不再適用于新的應用場景.而模型解釋度的提升反映出,隨著時間的推移而新增的數據出現了新的特點,我們推測在 2013年之后,Mozilla社區的一些實踐方法的優化措施,例如Bugzilla問題報告引導程序的改進有效地訓練了新手完成問題報告的能力.
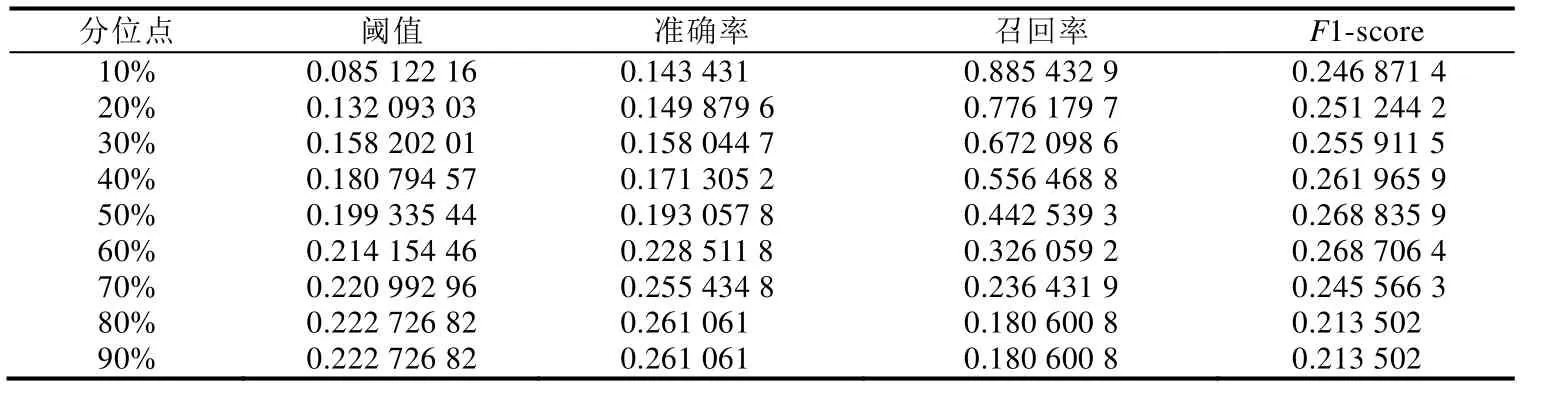
Table 5 Threshold selection and model performance in application表5 閾值選擇及模型在實際應用中的性能

Table 6 Result of model training with new data表6 使用新增數據進行模型訓練的結果
4.2 數據可追溯性的應用
本文第 2節闡釋了數據集構建過程的可追溯性可以解決兩個方面的問題:一是數據集的適用范圍,當數據使用者發現其他人定制的高層數據(例如FTDD數據集[30])中缺少了所需要的信息時,可以去回溯到層次1,尋找缺失的數據,重新構建層次 2的數據;二是數據質量的保障,由于整個數據集構建的處理過程及中間數據都是公開的,任何人都可以對數據的處理腳本進行測試,對數據進行比對,發現數據存在的缺陷或者局限,并評估他們對上層分析結果的影響.在下面兩個小節中,我們繼續以 Mozilla問題追蹤數據集為例,分別展示面向這兩方面問題的應用.
4.2.1 數據的定制與適用范圍
定制化的數據為解決某些特定的問題提供了一定的便利.在第2.2節中我們提到了Habayeb等人的FTDD數據集[30],該數據集記錄了缺陷處理過程中的各類事件及其發生時間,可以幫助人們研究它們發生的模式及產生的影響.該數據集以Firefox所使用的Bugzilla問題追蹤數據為原始數據,作者編碼了3大類10種事件,據此提取出每個缺陷報告中的事件.按照本文所提出的數據層次的概念,該數據集屬于定制層,即層次2或層次2+的數據.由于具有同源性,該數據集可以由我們Mozilla問題追蹤數據集中層次1的數據加工而成.圖8所示為該數據集的數據模型,可以看到,相對于原始數據,每個問題丟失了一部分信息,比如缺陷報告的優先級、嚴重程度等屬性,缺陷報告的標題、具體描述等文本信息.如果某個研究者想要研究不同類型的缺陷的處理模式,由于缺少這些問題屬性和描述,FTDD數據集并不能提供相應的數據支撐.
層次化的數據集為解決這種定制數據應用范圍有限的問題提供了有效的解決途徑.對于缺陷的類型,我們可以從很多角度進行分析,可以按問題所屬的產品、模塊分類,也可以按缺陷報告的優先級、嚴重程度分類,還可以利用主題生成模型從缺陷的描述文本中挖掘主題并根據主題對缺陷報告進行分類.因此,我們嘗試回溯到層次1,對相關的信息進行再提取,包括缺陷報告的4種屬性(所屬產品、所屬模塊、優先級、嚴重程度)以及每個報告的標題和描述.之后,根據缺陷的 ID,我們將這些信息關聯到 FTDD數據中的每一個缺陷報告,構建了一個新的如圖9所示的層次2數據集,它可以支撐不同類型缺陷的處理模式的研究.FTDD的作者在相關文獻中同樣提到了數據集擴展的問題,但沒有說明如何獲取擴展所需的數據,而當該數據集以層次化的方法構建與使用時,這種擴展在實際應用中的可行性將大為增加.
4.2.2 數據質量的保障
產品質量是消費者們最為關心的一種屬性.很多食品生產廠商通過使食品生產過程可追溯[45],讓每一個生產環節公開、可查驗來保證食品的質量.同樣,通過使數據集的構建過程可追溯來保證其面向最終用戶的質量同樣值得數據發布者們嘗試.層次化的Mozilla數據集實現了數據集構建過程的可追溯.除了直接面向數據使用者的定制數據外,我們還保留了定制數據構建的全過程:在層次 0,有從數據源獲取的全部原始的數據和數據獲取的描述及腳本.在層次 1,有將原始數據標準化后的中間數據及進行標準化處理的腳本.數據集構建的所有環節都是可查驗的,當數據使用者在使用過程中發現了可疑的問題時可以追溯到上述任意一個處理環節,查找問題的根源.
下面是我們在使用該數據集時所遇到的一個典型的例子.當我們利用Bugzilla用戶的郵件地址來識別不同的用戶時,發現2011年數據集中有一些用戶的郵件地址并不完整.這很可能會導致同一個用戶被當作不同的用戶來處理.為了查找問題的根源,我們取得含有不完整地址的問題報告的ID,直接在 Mozilla的Bugzilla頁面中進行查詢,此時看到的郵件地址是完整的,也就是說,問題出在了數據集構建的某個環節上.我們首先從層次0的原始數據開始排查,結果發現,原始數據中這些郵件地址已不完整.這說明,我們的頁面下載腳本存在問題.Bugzilla有這樣一種訪問規則:只有登錄的用戶才可以查看其他用戶的完整郵件地址,因此,數據下載的腳本要進行登錄操作并在下載過程中保持登錄狀態.雖然之前的腳本中有登錄機制,但存在不能保證登錄狀態的缺陷,部分數據的下載是在未登錄狀態下進行的,因而沒有獲取到完整的用戶郵件地址.據此,我們修復了該腳本,提高了下載到的數據的質量.
5 結束語
共享數據集的構建與使用是提高軟件開發活動數據分析效率的一種途徑,而現有工作存在對數據可用性欠考慮的問題,直接威脅數據質量與數據分析結果的有效性.為此,本文提出一種層次化、多版本化的數據集構建與使用方法,通過劃分不同的數據層建立數據的可追溯性,通過多版本數據的收集納入可能出現的數據變化.利用這兩項設計,使用者可以驗證、提高數據質量和數據分析結果的有效性.目前,我們已在該方法框架下完成了 Mozilla問題追蹤數據集的構建與使用,本文中也分享了我們的相關經驗,驗證了該方法的有效性.近期,我們注意到有些工作同樣嘗試了在定制數據之外提供原始數據,以此方便數據使用者開展更多的分析,例如 Beller等人的 TravisTorrent數據集[46].在未來工作中,我們將繼續實踐該方法,構建其他類型軟件開發活動的數據集,如代碼審查等.我們也將繼續使用層次化、多版本化的數據集開展軟件開發問題的研究,積累更多的經驗,進一步完善該方法.特別地,當數據集的層次2和層次2+中積累了紛雜的定制數據時,基于信息檢索等方法,實現面向特定用戶需求的自動化數據推薦.此外,數據規模的不斷擴大也會給數據集的使用帶來新的挑戰,我們在未來也將嘗試借鑒Gousios等人的方法[7,17],通過分布式、P2P等方式使大規模數據的存儲與訪問更為高效.
猜你喜歡
少先隊活動(2022年5期)2022-06-06 03:45:04
家庭科學·新健康(2022年3期)2022-05-10 00:32:13
中老年保健(2021年2期)2021-08-22 07:31:10
少先隊活動(2021年1期)2021-03-29 05:26:36
快樂語文(2020年30期)2021-01-14 01:05:38
海峽姐妹(2018年3期)2018-05-09 08:20:40
南方人物周刊(2017年32期)2017-10-28 22:48:36
南風窗(2016年26期)2016-12-24 21:48:09
南風窗(2015年22期)2015-09-10 07:22:44
南風窗(2015年14期)2015-09-10 07:22:44
