一種同步語言多線程代碼自動生成工具*
2019-08-13 05:06:26楊志斌袁勝浩JeanPaulBODEVEIXMamounFILALI
軟件學報 2019年7期
楊志斌 , 袁勝浩 , 謝 健 , 周 勇 , 陳 哲 , 薛 壘 , Jean-Paul BODEVEIX, Mamoun FILALI
1(南京航空航天大學 計算機科學與技術學院,江蘇 南京 211106)
2(軟件新技術與產業化協同創新中心,江蘇 南京 210093)
3(上海航天電子技術研究所,上海 201109)
4(IRIT-University of Toulouse, Toulouse 31062, France)
安全關鍵軟件(safety-critical software)[1]是指應用于航空、航天、交通、能源等領域的安全關鍵系統中,且其運行情況可能引起系統處于危險狀態,從而導致財產損失、環境破壞或者人員傷害的一類軟件.隨著功能需求的發展,能夠提供更強計算能力而又能減少電子設備的體積、重量和功耗(size,weight and power,即SWaP特性)的多核處理器將在安全關鍵領域得到廣泛應用.例如,在航空領域,風河公司(WindRiver)提出了支持多核處理器的 Vxworks 653操作系統 V3.0版本[2];而為了滿足將來航天應用的復雜需求,歐空局(European Space Agency,簡稱ESA)開發了基于四核LEON4的下一代微處理器試驗板(LEON4-N2X)[3].
近年來,模型驅動(model-driven),尤其是采用形式化模型驅動的安全關鍵軟件設計與開發方法逐漸受到重視,并被工業界認為是切實可行的重要手段.例如,國際民航領域使用的機載系統適航審定中的軟件開發標準DO-178C[4]就將模型驅動和形式化方法(即 DO-331[5]和 DO-333[6])作為其核心標準的重要技術補充.模型驅動開發方法將模型作為整個軟件開發過程的核心元素,在設計階段就建立軟件模型,并盡早進行驗證和分析.同時,模型的重用以及基于模型的自動代碼生成,都有助于降低軟件開發時間和成本.
安全關鍵系統,是一類反應式系統(reactive system),它不斷地和環境進行交互,即從環境中得到輸入,經過計算,然后輸出給環境,并重復這一過程.其中環境包括:被系統控制的物理設備、系統的操作人員或其他的反應式系統.同步語言基于同步假設理論(synchronous hypothesis)來表達系統的功能行為.目前,有 ESTEREL[7]、LUSTRE[8]、SCADE[9]、SIGNAL[10]、QUARTZ[11]等同步語言,這些同步語言可以看作是對同步假設理論的不同實現,而且同步語言在安全關鍵系統領域得到實際應用.例如,空客使用 SCADE對 A350、A380的飛控子系統[12]進行建模和代碼生成.ESTEREL、LUSTRE和QUARTZ語言使用perfect synchrony模式(即純同步模式),即存在一個全局時鐘,而SIGNAL語言使用Polychrony模式(即多態同步模式),可能不存在一個全局時鐘,可以更加自然地表達分布式系統.現有的SIGNAL編譯器Polychrony目前主要支持串行代碼生成和仿真分析,較少考慮在多核處理器上的多線程代碼生成.
在同步語言多線程代碼生成方面[13-15],目前研究主要考慮基于全局異步局部同步(globally asynchronous locally synchronous,簡稱GALS)的多線程代碼生成,即系統由具有不同時鐘的多個進程組成,而每個進程是單時鐘的.然而,在同步語言模型中,單個進程內部也往往存在潛在的并行執行信息.尤其是可以自然表達分布式系統的SIGNAL語言,其語法的基本結構中包含多時鐘操作,可以比較自然地支持在進程內部描述并行執行操作.
本文研究基于 SIGNAL語言表達的單進程程序的多線程代碼生成方法,并給出一種基于函數式編程語言OCAML實現的同步語言 SIGNAL多線程代碼生成工具.該工具是 SIGNAL串行代碼生成工具 Min SIGNAL[16-18]在多線程代碼生成方面的擴展.整個生成器分為前端和后端:首先,已有 MinSIGNAL編譯器前端對輸入的 SIGNAL程序進行用戶程序標準化,轉換為中間表達式即同步多時鐘衛式動作(synchronous clocked guarded actions,簡稱S-CGA),并進行時鐘演算,生成S-CGA中間程序.其次,基于擴展的代碼生成器后端輸出可執行的多線程C/Java代碼.擴展的代碼生成器后端延續MinSIGNAL的模塊化設計思想,主要包括:構建時鐘數據依賴圖(clock data dependency graph,簡稱CDDG),以分析S-CGA程序中變量(全局的時鐘變量和數據變量)之間的依賴關系;在使用拓撲排序劃分算法分析CDDG的基礎上,分別提出拓撲排序優化算法和基于流水線方式的任務劃分方法以提高最終目標代碼執行速度;基于劃分結果生成虛擬多線程代碼,進一步生成可執行多線程C/Java程序,并在多核處理器上進行實驗.
本文第1節簡要介紹SIGNAL語言的基本概念和我們的一些前期研究.第2節給出同步語言多線程代碼生成方法的總體研究框架.第 3節介紹同步語言多線程代碼生成方法和步驟,包括多線程代碼生成器前端、構造時鐘數據依賴圖、任務劃分算法和多線程代碼生成.第 4節給出基于 OCAML的工具實現,并基于案例進行可執行多線程代碼實驗和分析.第5節給出相關工作比較.第6節是本文的總結和展望.
1 研究背景
1.1 同步語言SIGNAL
SIGNAL是由Le Guernic、Benveniste和Gautier等人提出的一種聲明式數據流同步語言.基于同步假設理論,SIGNAL語言中定義了一類對象,稱為信號(signal),是一種帶類型的無限長的值序列.在給定邏輯時刻下,信號可以是“存在”狀態并具有對應的數值,或者是“缺失”狀態,記為⊥.信號處于存在狀態對應邏輯時刻組成的集合構成信號對應的邏輯時鐘(簡稱時鐘).在SIGNAL中,兩個信號同步當且僅當其邏輯時鐘相同.
SIGNAL語言通過數據流等式進行建模,它提供 4類基本的數據流等式結構:(1) 瞬時函數(y:=f(x1,x2,…,xn));(2) 延遲(y:=x1$init c);(3) 條件采樣(y:=x1whenx2);(4) 確定性合并(y:=x1defaultx2).
此外,按照時鐘關系劃分,4類基本結構可以被分為單時鐘操作(瞬時函數和延遲)和多時鐘操作(條件采樣和確定性合并):前者要求所有信號都是同步的,而后者允許信號可以不同步.例如,在確定性合并中,給定邏輯時刻下x1或者x2處于存在狀態即可以保證y處于存在狀態.
SIGNAL不僅提供基本結構,還提供一些擴展結構以支持顯式的時鐘操作.例如,時鐘同步:x1^=x2;時鐘并運算x:=x1^+x2、時鐘交運算x:=x1^*x2、時鐘補運算x:=x1^-x2;時鐘小于運算x1^
進程是SIGNAL的編程單元(programming unit),由輸入、輸出以及數據流等式組合起來構成.進程包含組合(composition)與局部聲明(local declaration).
另外,SIGNAL語言具有多種形式語義,如基于蹤跡的指稱語義[19,20]、基于標簽模型的指稱語義[19]以及基于同步變遷系統[21]的操作語義等.在文獻[22]中,我們基于定理證明器 Coq[23]證明了 SIGNAL語言的蹤跡語義和標簽模型語義的等價性.
我們給出一個同步語言SIGNAL示例:Count進程.該進程的第2行、第3行聲明輸入信號y1,x1和x2;第4行聲明輸出信號y;第5行、第6行數據流等式屬于擴展結構,第7行~第11行數據流等式屬于基本結構;第13行是局部聲明.我們將此程序貫穿全文用于介紹整個多線程代碼生成器的工作過程.

Example 1 Count process in SIGNAL例1 Count進程
1.2 前期研究
在分析SIGNAL語言的已有編譯器Polychrony的基礎上,我們基于OCAML實現了一種新的SIGNAL串行代碼生成工具MinSIGNAL[16-18],其編譯步驟如圖1所示.
相比Polychrony,MinSIGNAL具有的特征包括:
(1) MinSIGNAL支持的輸入為SIGNAL的子集(稱為MinSIGNAL),包括SIGNAL語言中的基本結構、擴展結構、組合、局部聲明等,不包括Polychrony工具庫;
(2) 考慮將來支持多種同步語言的集成,提出了一種新的中間表達式,即同步多時鐘衛式動作S-CGA;
(3) 基于Coq完成代碼生成器前端SIGNAL到S-CGA之間的語義保持證明.
本文是MinSIGNAL在多線程代碼生成方面的擴展,而MinSIGNAL的最終目標是生成一個新的SIGNAL驗證編譯器(verified compiler),即在定理證明器 Coq中規約并證明編譯規則的語義保持,然后從證明中自動抽取編譯器的OCAML實現.目前基于OCAML的工具實現是在定理證明器Coq中進行規約的基礎,并將和自動生成的驗證編譯器進行對比分析.
2 MinSIGNAL多線程代碼生成研究框架
同步語言SIGNAL多線程代碼生成器的總體框架如圖2所示.整個生成器包括前端和后端兩個部分:編譯器前端對輸入的SIGNAL程序進行用戶程序標準化、轉換為S-CGA程序、進行時鐘演算等步驟生成S-CGA中間程序.其次,基于擴展的代碼生成器后端輸出可執行的多線程 C/Java代碼.擴展的代碼生成器后端延續MinSIGNAL的模塊化設計思想,主要包括:
(1) 定義并構建時鐘數據依賴圖 CDDG,以分析 S-CGA程序中變量(全局的時鐘變量和數據變量)之間的依賴關系;
(2) 在使用拓撲排序劃分算法分析CDDG的基礎上,分別提出拓撲排序優化算法和基于流水線方式的任務劃分方法,以提高最終目標代碼執行速度;
(3) 基于劃分結果生成虛擬多線程代碼(平臺無關),進一步生成可執行多線程C/Java程序(平臺相關).
串行代碼生成過程主要由時鐘樹驅動完成,多線程代碼生成過程主要由數據依賴圖驅動完成.即在串行代碼生成過程中,通過分析時鐘樹上包含的時鐘關系得到串行代碼的控制結構,分析數據依賴圖中包含的數據依賴關系確定控制結構中語句的執行順序;在多線程代碼生成過程中,還需要定義CDDG以便同時顯式地考慮時鐘和數據之間的依賴關系.
3 MinSIGNAL多線程代碼生成方法和步驟
MinSIGNAL多線程代碼生成器由前端和后端兩部分組成.首先簡要介紹代碼生成器前端,即已有 Min SIGNAL串行代碼生成器前端及時鐘演算.然后,按照編譯步驟依次介紹時鐘數據依賴圖、任務劃分和多線程代碼生成.
3.1 多線程代碼生成器前端
由于此代碼生成器前端主要是重用已有的MinSIGNAL串行代碼生成器前端(參見文獻[16-18]),這里,我們僅簡要給出其主要步驟:用戶程序標準化、中間語言S-CGA和時鐘演算.
(1) 用戶程序標準化
如第1.1節和第1.2節所述,MinSIGNAL支持的輸入為SIGNAL子集(稱為MinSIGNAL),包括SIGNAL語言中的基本結構、擴展結構、組合、局部聲明等,不包括Polychrony工具庫.所謂用戶程序標準化,即代碼生成器在對用戶程序進行詞法和語法分析之后,將用戶程序中使用的擴展結構轉換為 SIGNAL語言的基本結構.我們稱基本結構為kSIGNAL(kernel SIGNAL).kSIGNAL的抽象語法如下所示.
我們在文獻[16-18]中給出了用戶程序標準化的轉換規則.這里,針對例1給出部分轉換示例.
對于擴展結構,如時鐘同步操作x1^=x2,首先分別定義x1和x2的時鐘變量C___1和C___2,然后通過兩個時鐘變量相等表示時鐘同步操作^=.

時鐘同步操作 標準化后結果x1^=x2 C___1=x1==x1 C___2=x2==x2 C___3=C___1==C___2
另外,還需對復合的基本結構進行處理,目的是為了降低源程序到中間語言的轉換難度.例如,y2:=(y1+1)$ init 2的標準化結構如下.
(2) 中間表達式S-CGA
隨著同步語言的發展,學術界已提出多種同步語言,導致集成不同同步語言成為熱點研究問題[24,25],因為這不僅可以更深刻地理解不同同步計算模型之間的區別,更重要的是,可以提供或重用統一的驗證、仿真和代碼生成工具.集成的解決方案主要是給出一種通用的中間表達式.例如,Polychrony中使用HCDG[26]、L2C項目中使用S-Lustre*AST[27,28]、QUARTZ編譯器使用CGA[29,30]以及本文使用的S-CGA等中間語言.
定義1(同步多時鐘衛式動作(S-CGA)). 在S-CGA中衛式動作的形式為γ?A,其中,γ為衛式,A為要執行的動作.其直觀語義為,如果衛式γ為真,則執行動作A.γ?A主要包括5種形式,見表1.
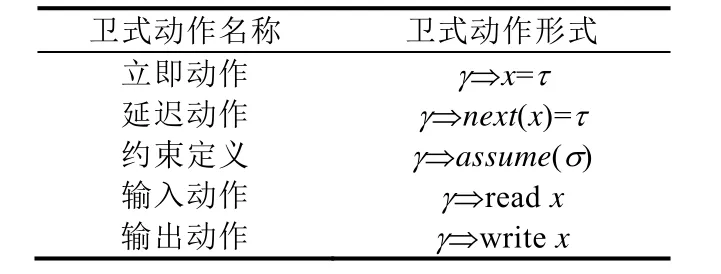
Table 1 Form of guarded actions表1 衛式動作形式
其中,
· 衛式γ是定義在信號變量X(源 SIGNAL中的輸入、輸出和局部變量)、X的邏輯時鐘(x∈X,其時鐘為?)及其初始時鐘(init(x?))之上的布爾條件.
· 動作A包括:立即賦值、延遲賦值、約束定義、輸入動作和輸出動作.其中,τ是定義在X上的表達式,σ則是定義在X及其邏輯時鐘上的布爾表達式.
(1) 立即賦值,給定邏輯時刻t,當γ中所有信號變量都處于存在狀態且γ為true、x和τ都處于存在狀態時,則將τ的取值賦給x;
(2) 延遲賦值,給定邏輯時刻t1,γ中所有信號變量都處于存在狀態,且γ為 true,x和τ在t1時刻都處于存在狀態,在下一邏輯時刻t2中,如果x處于存在狀態,則在t2時刻將t1時刻τ的取值賦值給當前時刻的x;
(3) 約束定義,如果γ中所有信號變量同時處于存在狀態且γ為 true,那么σ處于存在狀態并且為 true.所有S-CGA程序中的操作都需要滿足約束定義;
(4) 輸入動作,當γ=true時,從環境中讀取輸入變量x;
(5) 輸出動作,當γ=true時,將計算結果x輸出到環境.
多個 S-CGA組合采用同步組合操作||.因此,S-CGA具有與 SIGNAL語言一致的表達確定性并發行為的能力.
表2給出kSIGNAL2S-CGA的轉換規則.基于轉換規則,SIGNAL語言中的基本結構(即kSIGNAL)所表達的功能關系和時鐘關系一一映射為S-CGA中的對應表示.SIGNAL到S-CGA之間具體的轉換規則解釋以及語義保持證明思路參考文獻[16].

Table 2 Rules of kSIGNAL2S-CGA表2 kSIGNAL到S-CGA的轉換規則
(3) 時鐘演算
同步模型除顯式地表達功能關系外,還隱式地表達了時鐘關系.因此,在代碼生成之前,一般同步語言編譯器都需要經過時鐘演算,從而確定該同步模型可執行,并優化生成后的代碼.首先,根據S-CGA語義,從 S-CGA表達式中生成時鐘關系等式集合,其基本產生規則見表3.

Table 3 Rules of S-CGA2Clock equations表3 S-CGA到時鐘關系等式的轉換規則
針對例1給出部分轉換示例及其時鐘關系等式如下.

SIGNAL 部分S-CGA 部分時鐘關系等式s1:=y1 when x1 s2:=y2 when x2 x:= s1 default s2 sassume yx sassume yx xassume ss ?()? ?()1 11 2 22 12????? ????(?)xyxyx ???()()=??? 1122......
等式左側?x為時鐘變量,而右邊等式是對應的定義,時鐘關系等式x→y和y→x可表示為x=y.在時鐘關系等式集合中,需要對具有相同時鐘的不同時鐘關系等式進行優化以保證生成后的代碼執行效率更高.時鐘關系等式集合的消解原理為:將等式右側中的時鐘變量用其定義進行替換,并不斷地迭代,最后檢查不同時鐘變量之間是否等價(基于BDD或SMT).如果等價,則歸為同一個時鐘等價類,時鐘演算之后的程序中時鐘等價類用于替代S-CGA對應的時鐘變量.
針對例1,代碼生成器前端生成的部分S-CGA程序如圖3所示.S-CGA程序中包括輸入動作、輸出動作、立即動作和延遲動作.此外,約束定義只用于時鐘演算,不參與之后的任務劃分等步驟.
3.2 時鐘數據依賴圖
SIGNAL程序中的所有信號變量可具有各自的時鐘,如果生成串行代碼,即需要確定性的執行順序,編譯器基于時鐘等式和時鐘等價類,構造出一棵時鐘樹(clock hierarchy).能夠構造時鐘樹,代表所有時鐘都隸屬于一個全局時鐘(master clock),即可以給出一個確定性的串行執行順序,在同步語言中,稱其為Endochrony性質.在同步語言串行代碼生成中,根據時鐘等價類之間的時鐘蘊含關系構建時鐘樹,基于遍歷時鐘樹結構,生成串行代碼的控制結構,并根據等式之間的讀寫依賴關系生成執行順序,依次填寫到對應的控制結構中.而在多線程代碼生成中,需要進一步構造數據依賴圖,從而分析出更多的并行信息.
首先,使用時鐘等價類替換對應的所有時鐘變量以簡化程序.其次,基于 S-CGA表達式中的變量間讀寫依賴關系構建數據依賴圖.例如,對于衛式動作γ?x=τ,只有當獲得γ和τ中變量的取值后,才可以執行該衛式動作對x進行賦值,此時,γ和τ為讀依賴變量,x為寫依賴變量.RdVars/RdActs用于表示讀依賴變量/動作集合,WrVars/WrActs用于表示寫依賴變量/動作集合.
定義2(讀寫依賴).設FV(τ)為表達式τ中的自由變量的集合.S-CGA等式中的動作到變量的依賴定義為
·RdVars(γ?x=τ):=FV(γ)∪FV(τ)
·WrVars(γ?x=τ) :={x}
而變量到動作的讀寫依賴定義如下.
·RdActs(x):={γ?A|x∈RdVars(γ?A)}
·WrActs(x):={γ?A|x∈WrVars(γ?A)}
MinSIGNAL多線程代碼生成器采用基于周期的目標代碼執行方式:(1) 初始化程序;(2) 計算程序體;(3) 更新變量.然后進入下一個周期,迭代執行(2)和(3).我們主要分析程序體中的依賴關系.含有初始時鐘值init(x?)的立即動作主要用于程序初始化,而延遲動作用于更新變量,γ?assume(σ)則主要用于定義時鐘約束關系,因此,這3類衛式動作不用于構造數據依賴圖.
在數據依賴圖中,只有當一個動作的所有讀變量都有取值時,該動作才可以被執行.類似地,只有當一個變量的所有寫動作都已經完成計算后,該變量才能夠有取值.例如,在上述 S-CGA 程序中,ID_4?ID_5=x1依賴于ID_4?readx1獲得的x1值.
定義 3(時鐘數據依賴圖(CDDG)).時鐘數據依賴圖 CDDG 為一個有向圖〈V,DR〉,V代表衛式動作集合,DR?V×V代表衛式動作之間的依賴關系集合.
時鐘數據依賴圖的構造規則如下.對任意的動作a∈A以及變量x∈RdVars(a),在WrActs(x)對應的衛式動作到a對應的衛式動作之間增加一條有向邊.
圖4為Count進程對應的S-CGA程序依據構造規則生成的時鐘數據依賴圖CDDG.
我們使用 S-CGA 程序中的行號表示對應的衛式動作,使用不同的形狀區分衛式動作.其中,橢圓表示輸入動作,矩形表示輸出動作,圓形表示立即動作.而箭頭→表示依賴關系,例如,22→23表示ID_4?ID_8=ID_4 andID_7依賴ID_4?ID_7=x2獲得的ID_7值.
3.3 任務劃分
任務劃分用于分析CDDG中包含的并行執行信息,直接影響目標代碼的并行度,是多線程代碼生成器的核心步驟.首先,CDDG是一個有向圖,根據拓撲排序思想對 CDDG進行任務劃分;其次,基于劃分結果分別提出優化算法和基于流水線方式的任務劃分,其中前者用于處理劃分結果中可能存在丟失依賴關系和線程數目過多的問題,后者用于嘗試尋找劃分中更大的并行度.
3.3.1 基于拓撲排序的任務劃分
多線程代碼生成是基于已經融合時鐘關系的數據依賴圖,并需要在數據依賴圖中進行任務劃分(partition).CDDG是有向無環圖,我們基于拓撲排序方法對CDDG進行任務劃分.
劃分算法如圖5所示:算法輸入為時鐘數據依賴圖CDDG,輸出為任務劃分結果topoPartition.算法第1步分別對NodeSet、EdgeSet和topoPartition進行初始化(第4行~第6行),然后進入拓撲排序劃分迭代(第7行).迭代過程包含以下步驟:首先從 NodeSet中計算出所有入度為0的點組成的集合Pi,i表示迭代次數(第8行);其次,如果Pi不為空,則將Pi加入到topoPartition的末尾.如果Pi為空,表明CDDG中存在環,則算法終止,輸出異常信息“CDDG中存在環”(第9行);最后將Pi中出現的點從NodeSet中移除以及從EdgeSet中移除與這些點有關的邊(第10行、第11行).當NodeSet為空時迭代終止.
例1對應的CDDG生成劃分結果topoPartition如下所示.
其中,Pi=id1||id2…||idn為一個劃分,表示id1,id2,…,idn可以并行執行,id代表CDDG中對應節點的行號.以P1為例,1||2||3||8表示衛式動作ID_4?ready1,ID_4?readx1,ID_4?readx2和ID_4?C___4=y2==y2彼此可以并行執行.Pi;Pi+1表示兩者之間串行執行.即當Pi中衛式動作執行結束,開始執行Pi+1中衛式動作.
然而,這種劃分方法得到的劃分結果可能存在以下問題.
首先,劃分結果可能導致在最后代碼生成的線程調度時,增加多余的同步開銷.以P2中衛式動作ID_4?C___1=x1==x1為例,根據 topoPartition,該衛式動作開始執行需要等待P1中所有衛式動作執行結束.但根據CDDG可知,ID_4?C___1=x1==x1開始執行依賴ID_4?readx1執行結束.劃分結果導致生成的線程之間也存在多余的通信信息,增加了線程之間的同步開銷時間.在實際執行目標代碼過程中,原本可以執行的線程必須等待其他額外的線程執行結束才可以開始執行,從而可能影響目標代碼的執行效率.
其次,由于使用基于拓撲排序的劃分方法,劃分結果中的每個衛式動作在代碼生成時將對應轉換為一個線程.以P4中17(對應圖3中ID_6?s1=y1)為例,其轉換對應生成的線程的步驟包括:17對應生成線程名Thread_17;衛式動作轉換為線程的計算部分;該線程開始執行依賴獲得P3對應的所有線程的執行結束信息;當該線程執行結束,則將結束信息通知P5對應的所有線程.因此,當衛式動作數目過多時,導致線程數目過多,可能會增加線程間的資源競爭,從而影響目標程序的執行效率.
3.3.2 劃分優化
針對劃分結果 topoPartition可能存在的問題,我們給出基于拓撲排序劃分的優化算法,即記錄時鐘數據依賴圖CDDG中的依賴關系以及嘗試減少目標線程數目.
首先,我們給出如下定義.
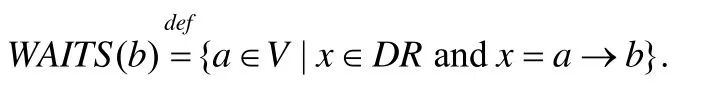
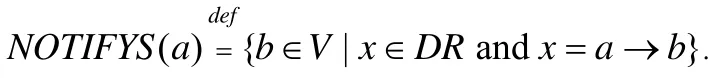
特別地,當WAITS(b)={a},即|WAITS(b)|=1 時,記為WAITS(b)={a}.同樣地,當NOTIFYS(a)={b}時,記為NOTIFYS(a)={b}.根據定義4和定義5,遍歷CDDG中依賴關系計算出所有衛式動作對應的等待和通知,并將其加入到優化劃分結果topoOptimization中,從而在topoOptimization中記錄時鐘依賴圖的依賴關系.此外,定義4和定義5也便于在后續步驟中找出可以合并的線程以及處理目標代碼中線程之間的同步.
其次,給出嘗試減少目標線程數目的方法.
如果衛式動作a和b滿足WAIT(b)={a}&&NOTIFY(a)={b},則合并a和b為一個特殊的“衛式動作”,記為Ma=[a;b],其中,WAITS(Ma)=WAITS(a),NOTIFYS(Ma)=NOTIFYS(b).Ma表示衛式動作a和b在生成目標代碼中將合并為一個線程.
圖 6給出基于拓撲排序劃分優化算法.首先,計算出所有衛式動作對應的等待和通知并加入到優化結果中(第4行~第6行);其次,在原有并行執行部分的基礎上進行線程合并(第7行).
我們對第3.3.1節給出的劃分結果進行優化,得到優化劃分結果topoOptimization如下所示.
其中,劃分P2的[15;16]、[22;23],P4的[17;18]和P6的[26;4]為合并后的衛式動作.例如,[17;18]表示在目標代碼生成時,衛式動作ID_6?s1=y1和ID_6?x=s1將會被分配到一個線程中順序執行.同時,等待和通知記錄依賴關系,例如WAITS(22)={3}表示衛式動作ID_4?ID_7=x2依賴于輸入動作ID_4?readx2得到的x2值.
3.3.3 基于流水線方式的任務劃分
當基于拓撲排序獲得的任務劃分存在并行度不高(即大部分Pi中可并行執行的衛式動作數目都較少)的情況下,我們提出基于流水線方式(pipeline style)對劃分結果進行再劃分,嘗試提高執行并行度.考慮一個特殊情況為劃分結果中所有Pi中都只有一個衛式動作,則經過任務劃分生成的多線程代碼執行情況實際上“等同”于串行程序執行,而通過引入流水線方式劃分支持多條流水線并行執行,從而提高目標程序的執行效率.
本文的流水線方式的任務劃分算法(如圖7所示)包括3個步驟:首先,根據劃分結果定義流水線階段;其次,針對各流水線階段增加流水線中間變量;最后,針對不同流水線以及同一流水線下不同流水線階段之間增加通信函數.
(1) 定義流水線階段(算法第4行、第5行)
首先將劃分結果topoPartition中每個劃分Pi對應于一個流水線階段Stage(i).由于topoPartition中并未考慮延遲動作γ?next(x)=τ,在確定流水線階段的同時需要將所有延遲動作γ?next(x)=τ加入到相應的 Stage中,便于之后處理不同流水線間的通信,并保證不同流水線執行結果的正確性.例如,對于延遲動作ID_4?next(y2)=F___7,將其加入到ID_4?F___7=y1+K___8所在的Stage中.
每個Stage(i)有兩種不同的狀態:激活狀態和阻塞狀態.一個Stage(i)稱為阻塞狀態當且僅當該流水線階段中存在需延遲動作寫入的值未被更新.只有處于激活狀態的流水線階段才可以被執行.在定義流水線階段時,每個流水線階段默認為激活狀態.
(2) 增加流水線中間變量(算法第6行~第9行)
得到流水線階段后,需要考慮如何在每條流水線的各個流水線階段之間加入流水線中間變量.因為每條流水線的每個階段同時處理不同邏輯時刻的數據,所以需要一些中間變量來存儲各個流水線階段中生成的臨時結果.為此,需要確定流水線中間變量在流水線階段中加入的確切位置.
對Stage(i)中任意的衛式動作a,如果變量x∈WrVars(a),則在Stage(i)和Stage(i+1)之間,增加變量x對應的流水線中間變量.需要注意的是:一個流水線中間變量只適用于一條流水線.對于多條流水線,通過根據流水線條數N將流水線中間變量調整為一維流水線中間變量數組,從而保證各條流水線之間不產生數據沖突.例如,對于變量x以及流水線條數N,需要增加的流水線中間變量數組為m_x[N],其中,m_x[0]表示第0條流水線中x對應的流水線中間變量.
(3) 增加通信函數(算法第10行和第13行)
增加流水線中間變量后,需要在流水線中間變量與S-CGA變量之間建立起數據通信的映射關系,包括兩種數據通信函數:數據輸入函數inp_exchange,負責將流水線中間變量值傳輸到對應的S-CGA變量;數據輸出函數outp_exchange,負責將已經更新的S-CGA變量值傳輸到對應的流水線中間變量中.例如,對于立即動作γ?(x)=τ,對γ、τ調用inp_exchange函數,當衛式動作執行結束,調用outp_exchange函數更新x.若變量x在某條流水線中需要的流水線中間變量為k個,設置N條流水線,則對于變量x來說,共需要中間變量為k×N個.
最后,需要考慮不同流水線之間的數據延遲通信問題.在多條流水線中,S-CGA 程序中延遲動作γ?next(x)=τ會影響相鄰兩條流水線之間的數據通信.因此,為了保證基本流水線的正確信息流,對于那些由延遲動作寫入的變量(稱為更新值),在每個流水線中必須保證觸發一個動作來完成延遲動作.如果當前流水線中具有延遲動作中的節點對應的所有衛式動作的衛式都為false,則需要增加一個衛式動作來保存更新值,使之保證:如果當前流水線相鄰的下個流水線中需要使用延遲動作中的變量,則這個變量的值等于前個流水線中的對應的值.同時設置標志符update表示當前流水線中涉及更新值的階段是否已被更新,update為真,表示更新值已被更新,否則,該階段處于阻塞狀態.假設更新值的個數為t,設置N條流水線,則一共需要t×(N-1)個通信函數,在實際情況下,通信函數的個數可能會小于上述數值.因為對于更新前后的值始終不變的更新值,即由源 SIGNAL程序中常量生成的變量,其對應的不同流水線之間的通信函數可以進行優化而被去掉.
這里,我們給出針對第3.3.2節中topoOptimization進行流水線方式的任務劃分,默認采用3條流水線.首先定義流水線階段并添加延遲動作,例如 Stage(2)中添加兩個延遲動作(序號 12和序號 14);其次定義流水線中間變量,如圖8所示,Stage(1)和Stage(2)之間增加流水線中間變量數組y1、x1、x2和C__4;最后添加通信函數,包括數據通信函數(outp_exchange/inp_exchange)和延遲通信函數(f_y2),如圖9所示.
Pipeline1中Stage(4)的更新值y2默認由init函數激活,所以設置為激活狀態,而Pipeline2和Pipeline3中Stage(4)分別由前一個Pipeline中的Stage(2)觸發,所以后者設置為阻塞狀態(灰色).此外,序號12和序號27對應的衛式動作ID_4?next(K___8)=K___8和ID_4?next(K___9)=K___9是根據源SIGNAL程序中的常量而生成,可以優化其對應的延遲通信函數,因此不需要修改更新值.
3.4 多線程代碼生成
本文將多線程代碼生成過程分為平臺相關和平臺無關兩個層次:首先,根據劃分結果生成基于 Wait/Notify機制的虛擬多線程VMT(virtual multi-thread)代碼;其次,從虛擬多線程代碼中生成具體的可執行多線程代碼,如C或者Java.
3.4.1 虛擬多線程代碼
優化劃分中每個衛式動作或合并的衛式動作對應一個線程,如圖10右側線程所示,本文采用串行調度方式來確保線程間通信保持同步語義,根據優化劃分結果中WAITS和NOTIFYS信息實現基于Wait/Notify機制的虛擬多線程代碼.主函數首先執行初始化(例如,y2=2),然后進入主循環,等待所有線程完成執行,最后處理延遲賦值操作(更新y2取值).而在主循環中,每個線程(thread1,…,thread26)都執行一個循環:等待(wait)輸入、測試衛式、產生輸出、通知(notify)其他線程.
另外,針對基于流水線方式的任務劃分結果生成虛擬多線程結構,則需要對圖10所示結構做出如下調整.
(1) 保留虛擬多線程的通用結構,即初始化、主函數和線程組.主函數中的call_threads()函數修改為call_threads(PN),即在主循環中調用PN條流水線下的線程.延遲賦值操作從主函數轉移到特定的線程中,具體線程是根據流水線階段中延遲動作加入的位置加以確定.
(2) 增加數據交換和數據通信.數據交換用于處理單個流水線中線程與流水線中間變量的數據交換.數據通信用于處理不同流水線之間線程間的通信.
生成虛擬多線程代碼的目的是方便對多線程代碼進行形式化驗證和仿真分析,如使用模型檢測工具UPPAAL對多線程代碼的無死鎖性等性質進行驗證,以及在仿真工具Simulink上進行仿真實驗.同時,支持生成多種目標代碼,增加代碼生成器后端的可擴展性.
3.4.2 多線程C代碼
在多線程C代碼自動生成過程中,使用POSIX的同步機制來實現Wait/Notify.首先,所使用的同步結構由互斥量(pthread mutex)、條件變量(pthread condition variable)以及一個線程所等待事件的數量(value)組成.例如,thread13需要等待thread1的事件,因此,其value為1.
counter_wait用于表示 Wait機制,即,當前線程的value值大于 0(意味著該線程的一些等待事件還沒有到達),則將當前線程設為等待.
counter_notify用于表示Notify機制,用于喚醒等待線程隊列中的某個線程.
以圖 10中虛擬多線程為例,我們給出對應多線程 C代碼中部分線程:thread_15和thread_17,如圖 11所示.thread_15開始執行需要等待thread_2的事件發生,即讀取輸入信號x1.條件語句中順序執行語句ID_5=x1和ID_6=ID_4 &&ID_5是根據劃分結果 topoOptimization中P2對應的[15;16]生成.當完成計算后,通知線程thread_17,thread_19和thread_21.如果thread_1已經執行完成,則下一步可以執行thread_17.
3.4.3 多線程Java代碼
在生成多線程Java代碼階段,我們使用線程同步柵欄的方式完成線程之間的同步,生成的Java文件主要包括如下兩個Java類.
(1) 輸入輸出類.對于 S-CGA中每一個輸入動作,對應生成一個 read方法,每個輸出動作則對應生成一個write方法.在線程類執行前,調用 read方法讀取輸入數據,在線程類執行結束后,調用 write方法寫入輸出數據.通過單獨生成輸入輸出類,保證不同任務劃分算法生成的線程類可以重用輸入輸出類.
(2) 線程類.線程類中包含了若干子類,如classthread_15等.子類實現了Runnable方法,對應于虛擬多線程中單個線程.在子類中重寫run函數:等待所依賴的事件發生,執行條件語句,通知其他線程.
以圖10中虛擬多線程為例,我們給出對應多線程Java代碼中部分線程:thread_15和thread_17,如圖12所示.首先thread_15調用Wait方法,進入阻塞狀態,當所依賴的線程全部執行完之后,解除thread_15的阻塞狀態.if語句執行結束后,調用countDown方法通知其他線程thread_15已執行結束.類似地,如果thread_1已經執行完成,則下一步可以執行thread_17.
4 工具和實例分析
MinSIGNAL多線程代碼生成器基于OCAML編程實現,代碼生成器采用模塊化思想,包括已有串行代碼生成器前端和擴展多線程代碼生成器后端.本節將主要介紹MinSIGNAL多線程代碼生成器的工具設計與實現以及多線程代碼在多核處理器上的實驗分析.
4.1 工具實現和分析
多線程代碼生成器的主要編譯步驟及其對應的OCAML代碼數量統計見表4.
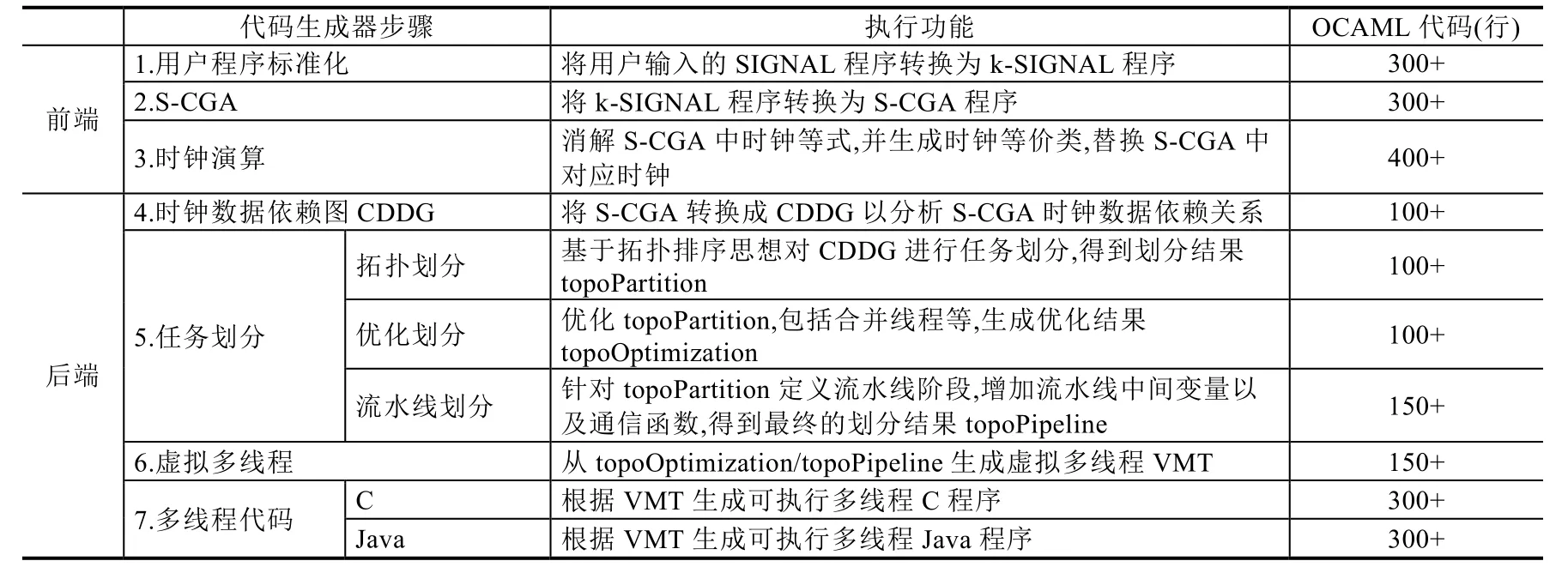
Table 4 Main steps of MinSIGNAL parallel code generator表4 MinSIGNAL多線程代碼生成器主要步驟
工具開發環境為基于Eclipse平臺的OcaIDE插件環境.如圖13所示,左側為文檔結構,每個文件對應一個執行功能.我們在main.ml文件中配置MinSIGNAL代碼生成器執行步驟,并通過配置文件設置同步語言源文件路徑、代碼生成器執行文件路徑等參數,運行配置文件(如圖14所示),從而生成多線程代碼.
如圖15所示,目標程序通過從輸入信號對應的文件Input.txt中讀取數據,執行計算結束后將輸出信號保存到文件Output.txt中.
4.2 實驗與分析
本實驗的目的在于通過實驗分析基于拓撲排序優化算法和基于流水線方式的任務劃分是否提高目標代碼的執行效率,以支持比較基于不同劃分方法下自動生成的程序的質量.我們測試基于不同劃分算法生成的多線程代碼,具體包括:使用基于拓撲排序劃分生成的多線程代碼(C_1/JAVA_1),以及在拓撲排序劃分的基礎上分別使用基于優化拓撲排序劃分生成的多線程代碼(C_2/JAVA_2)和基于流水線劃分方式的多線程代碼(C_3_i/JAVA_3_i),其中,流水線條數i分別設置為 3/4/6/12條.C_1/JAVA_1的運行結果作為基準,用于和后兩種劃分方式進行比較.整個測試環境參數包括操作系統Win10 64bit、8核core i7-6700 CPU 3.40GHz、8G RAM、C編譯環境Dev_C++(TDM-GCC 4.8.1)和Java編譯環境Eclipse Oxygen(JDK1.8).
實驗選取3個SIGNAL測試程序:測試程序1為例1中Count程序;測試程序2為數學中冪運算計算程序,輸入兩個整型(integer)參數分別是底數和指數,輸出冪運算的結果;測試程序 3為模擬采樣,對輸入的波形(整型值序列),根據設置不同的采樣要求(假設有兩種布爾條件),分別輸出對應的波形.實驗通過在不同CPU核數下運行不同SIGNAL測試程序生成的多線程C和Java代碼,計算其循環執行1 000次的平均執行時間,見表5.
平均執行時間反映多線程代碼執行效率.圖16給出表5((1)~(3),共3張表)對應的折線圖,橫軸為CPU核數,縱軸為不同目標代碼在給定CPU核數下的平均執行時間.如圖16所示,在CPU核心數相同的情況下,基于流水線方式的劃分算法生成的多線程代碼(C/Java)執行效率最高,而采用基于拓撲排序劃分優化算法次之,但仍比基于拓撲排序劃分算法對應的執行效率要高.同時,由圖16可知,在給定任務劃分算法和CPU核數的情況下,生成的多線程C程序的執行效率高于生成的多線程Java程序.這可能是因為二者的多線程機制存在差異,C程序直接調用Windows底層程序,而Java程序是借助于JVM實現多線程機制.因此,不同目標語言的選取也會影響多線程代碼自動生成方法所生成目標程序的執行效率.
此外,通過分析四核CPU和八核CPU下對應的平均執行時間可知,四核CPU對應的執行時間更快,即并不是 CPU核心數越高,程序執行速度越快.這可能是由于隨著 CPU核數的提升,不同核之間調度和數據交換花費的時間更多,并且Cache訪問沖突也會造成執行時間的增加.因此,在嵌入式系統的設計過程中,在考慮軟件建模的同時,也需要考慮適配硬件平臺,避免造成資源浪費.
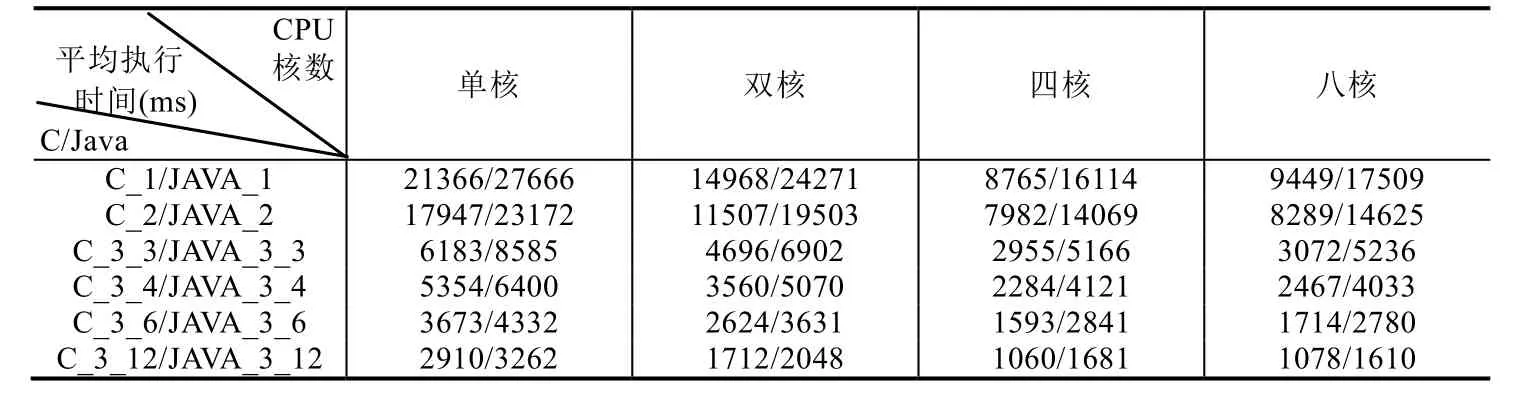
Table 5 Testing results on multi-core platform (1)表5 多核執行平臺下的測試結果(1)
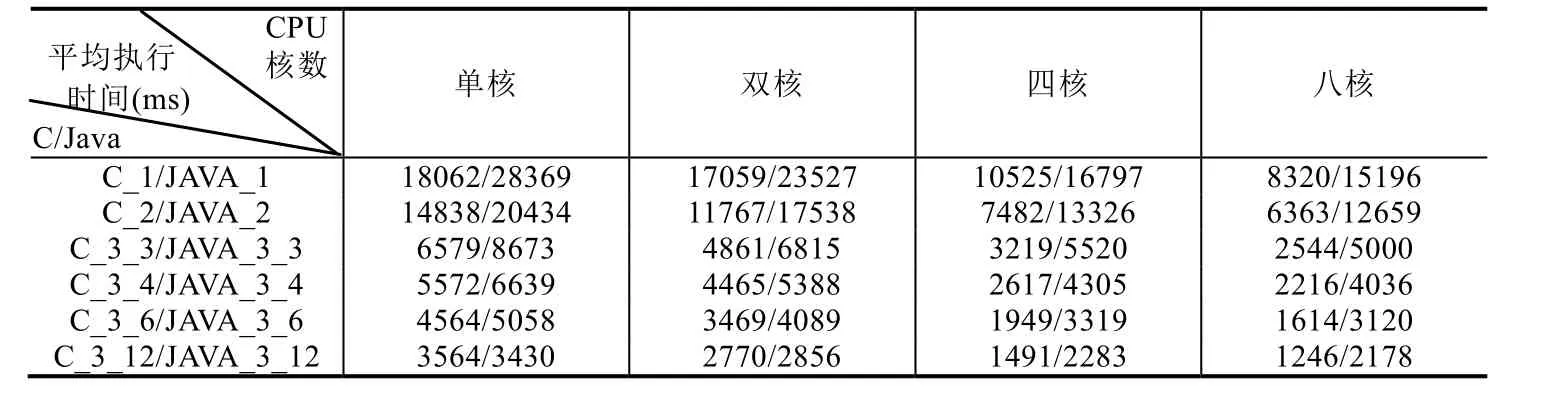
Table 5 Testing results on multi-core platform (2)表5 多核執行平臺下的測試結果(2)
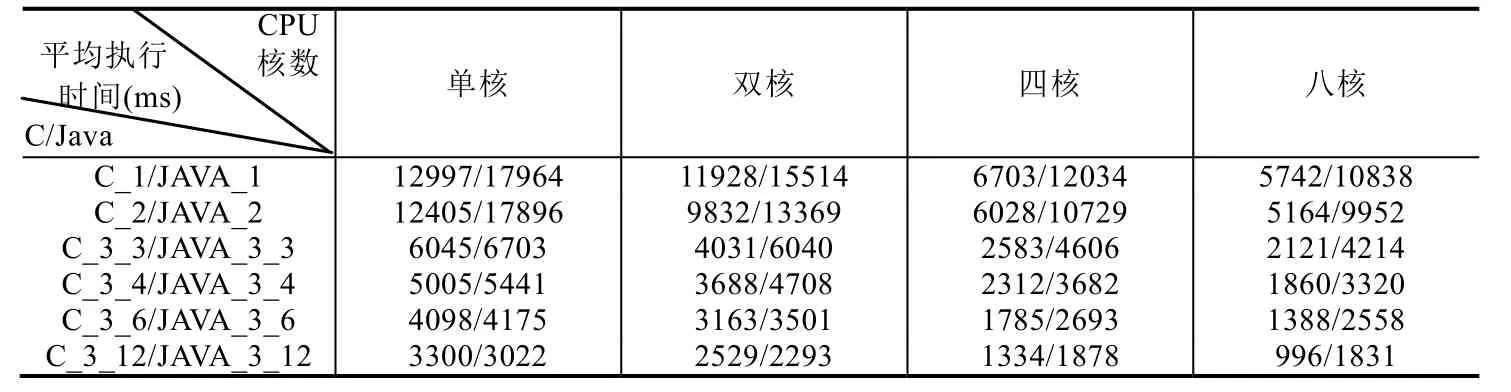
Table 5 Testing results on multi-core platform (3)表5 多核執行平臺下的測試結果(3)
綜上所述,通過分析基于不同劃分算法生成的多線程 C/Java代碼在多核平臺上實驗的數據,可以得出以下結論.
(1) 基于拓撲排序優化算法和基于流水線方式的任務劃分算法縮短了目標代碼執行時間,其中,流水線劃分算法較為明顯地提高了執行速度.
(2) 不同目標語言的多線程代碼執行速度存在差異,在實際生成代碼時需要綜合考慮目標語言以及多線程機制等因素.
(3) 當考慮同步模型生成多線程代碼時,需要考慮部署在哪種多核平臺上,以保證資源的合理利用.
本文基于OCMAL實現同步語言SIGNAL的多線程代碼自動生成工具.在已有SIGNAL編譯器研究工作中:例如,與原有SIGNAL編譯器Polychrony[26]相比,本文的S-CGA能夠支持多種同步語言的集成;文獻[14]主要考慮基于GALS的多線程代碼生成,生成的線程粒度較大,本文主要考慮更細粒度的線程,以便尋找到更多的并行信息,目前已實現與體系結構分析和設計語言 AADL的混合建模;與文獻[31]相比,該文獻主要考慮同步語言的跨平臺代碼生成,在任務劃分中僅使用拓撲排序劃分算法,且時鐘信息需要后期單獨增加,相比而言,本文考慮多種劃分算法,優化目標代碼的執行效率.此外,本文的未來目標是基于Coq多線程代碼生成器的驗證工作.
5 相關工作
同步語言的串行代碼生成研究已經比較成熟.隨著多核處理器的發展,同步語言的多線程代碼生成成為研究熱點.已有研究大致可以分為如下3類.
· 基于 GALS的多線程代碼生成,即系統由具有不同時鐘的多個進程組成,而每個進程是單時鐘的,目前所有同步語言基本都支持此類的多線程代碼生成.
· 基于單進程的多線程代碼生成,主要是針對 SIGNAL語言以及其他單時鐘同步語言的擴展,這是由于單個進程中的所有信號變量也可以具有不同時鐘.
· 考慮硬件平臺特性,涉及到多核架構或時間可預測處理器的執行及程序最壞執行時間分析.
(1) 基于GALS的多線程代碼生成
同步語言支持進程間的并發操作,例如 QUARTZ和 ESTEREL提供同步并發運算符‘||’以支持進程間的并發,LUSTRE使用‘;’表示不同節點的并行執行,SIGNAL中不同進程間的組合操作‘|’也隱含著并行執行[32].同時,在分布式系統上,由于進程間通信受到物理載體的影響而產生不可預測的延遲[13],導致不同進程間的時鐘可能不滿足同步關系,被稱為全局異步局部同步GALS系統.
文獻[14]提出一種非侵入式的多線程代碼生成方法,即在不改變已有SINGAL編譯器Polychrony結構的基礎上,利用其串行編譯功能生成多個獨立的進程,并基于主控函數完成調度,實現進程之間的并行執行.文獻[15]提出從實際工業需求中導出功能行為等價的Heptagon程序[33](一種類Lustre同步語言)并進一步生成多線程代碼.與文獻[14]所提方案類似,首先基于Heptagon編譯器生成多個串行節點,然后在集成規約中描述任務間通信和同步.通過構建節點間的依賴圖,利用串行調度來保證確定性并發語義.除功能需求外,該研究還考慮了非功能性需求(如周期等實時性質)的代碼生成.
此外,文獻[34]提出從高層建模語言(AADL,SysML,SystemC等)轉換為SIGNAL同步程序并進一步生成多線程代碼的方法.其中,同步程序基于Weekly Endochronous理論[35]:即程序中允許多個根時鐘.在多線程生成過程中,采用符號化原子表達式和合并分支條件的策略約減線程數目.不過,其同步程序中僅考慮有限的數據類型(事件、布爾和枚舉類型)和布爾操作(相等和取反操作).
多個進程之間并行劃分的“粒度”相對較大[14],但在同步語言模型中,單個進程內部也往往存在潛在的并行執行信息.尤其是可以自然表達分布式系統的SIGNAL語言,其語法的基本結構中包含多時鐘操作,可以比較自然地支持在進程內部描述并行執行操作.
(2) 基于單進程的多線程代碼生成
文獻[26]中介紹了同步語言SIGNAL編譯器Polychrony中的代碼生成策略,在多線程生成方面分為靜態調度和動態調度.靜態調度下的分簇(多線程)代碼生成:將生成的代碼劃分到簇中來模擬調度圖的結構.分簇的原則是:將調度圖劃分為對那些依賴于完全相同的輸入集合進行計算.只要一個簇的所有輸入都有確定值,那么這個簇就可以被自動執行,一個簇的時鐘取決于簇中所有信號在時鐘樹上的公共父節點.動態調度下的分簇(多線程)代碼生成:按任務實現分簇,并生成任務之間的同步信息.任務由簇來生成,主要思想是使用信號量的方式并行執行各個任務.然而,這種方式下生成的多線程數目太多,并且使用特定的線程庫來生成仿真代碼.
文獻[29,30]是對純同步語言 Quartz編譯過程的多線程代碼的研究.文獻[29]提出同步衛式動作(clocked guarded action,簡稱CGA)到基于OpenMP的多線程C程序的編譯方案.作者提出“垂直劃分”的概念,即從數據依賴圖中抽取出獨立的線程,并生成對應的 C代碼.文獻[30]引入軟件流水線的概念,提到的軟件流水線方法包含:分析衛式動作之間的依賴關系、創建流水線變量存儲各階段之間的中間結果以及衛式動作到流水線之間的轉換.這種方法被稱為“水平劃分”.
文獻[31]對 SIGNAL多線程代碼生成進行了研究,提出基于方程依賴圖(equation dependency graph,簡稱EDG)的OpenMP并行代碼生成方法.其中的并行代碼生成算法主要是對數據依賴圖進行拓撲排序,生成多個鏈表:多個鏈表之間順序執行、單個鏈表內部節點并行執行.不過,文獻[31]使用拓撲排序作為任務劃分算法,沒有考慮優化工作,而且需要在劃分之后對劃分結果單獨加入時鐘信息.而本文使用的CDDG中包含時鐘依賴關系,即在劃分過程中已經考慮時鐘信息.
本文主要考慮單進程的多線程代碼生成方法,同時給出優化策略和流水線方式的任務劃分方法,能夠較好地約減線程數目以及提高目標多線程代碼執行效率.
(3) 多核架構執行及WCET分析
ITEA 3計劃中的(affordable safe & secure mobility evolution,簡稱ASSUME)項目[15,36]提出一種用于在多核/眾核架構上提供可信的嵌入式軟件工程方法,包括從LUSTRE同步模型到自動生成并行代碼并在多核/眾核平臺上執行.ASSUME項目擴展了SCADE工具的KCG編譯器,以支持生成面向MPPA眾核架構[37]的并行代碼,但是當前的并行信息是通過用戶來驅動的,即用戶指定程序中并行執行區域.此外,在代碼生成過程中提供每個任務在實時調度期間所需的屬性(如WCET、內存訪問的最壞次數等).
法國國家航天航空研究中心ONERA的SchedMCore環境[38,39]為形式化多處理器調度分析和實驗性多核運行時基礎架構提供了一套驗證和執行工具.SchedMCore將同步語言Prelude[40]編譯生成一組相互通信的周期任務(包含信息有:任務的周期、WCET、首次到達時間和 Deadline),并基于工具自帶的不同多核調度策略實現任務在多核架構上的調度.文獻[41]中給出一個基于 SchedMCore設計并運行在多核/眾核架構上的航空經度控制器案例.
德國Kaiserslautern工業大學嵌入式系統小組(http://es.cs.uni-kl.de/)基于同步語言QUARTZ開發了一個用于并行嵌入式系統的規約、驗證和實現的框架AVEREST(http://www.averest.org/).該框架可同時生成硬件電路邏輯代碼和多線程代碼,并且支持軟硬件分析[42].此外,他們還研究了基于指令集并行(instruction level parallelism,簡稱 ILP)的同步語言 SCAD 最優化代碼生成,包括使用回答集編程(answer set programming,簡稱ASP)處理 SCAD代碼生成過程中的最優資源/時間約束調度問題[43],以及利用 SMT求解器生成實現最大化指令級并行(給定處理器單元數目)的最優化代碼[44]等.
綜上所述,同步語言多線程代碼生成涉及到多核硬件執行平臺以及考慮WCET分析.我們在已有工作[18]中給出在同步語言代碼生成過程中的時間可預測多核體系結構模型及軟硬件映射方法.而本文主要側重同步語言多線程代碼生成方法及其實現,提出任務劃分優化策略以及基于流水線方式的劃分以提高目標代碼的執行速度.
6 總結與展望
同步語言廣泛用于安全關鍵嵌入式系統建模與驗證,近年來,同步語言的多線程代碼生成成為學術界的一個研究熱點.本文提出一種基于OCAML的同步語言SIGNAL多線程代碼生成方法和工具.首先將SIGNAL程序轉換為經過時鐘演算的 S-CGA中間程序;之后將S-CGA中間程序轉換為時鐘數據依賴圖以分析依賴關系;然后對時鐘數據依賴圖進行拓撲排序劃分,并針對劃分結果提出優化算法和基于流水線方式的任務劃分方法;最后將劃分結果轉換為虛擬多線程結構,然后進一步生成可執行多線程 C/Java代碼.通過在多核處理器上的實驗驗證了本文提出方法的有效性.
編譯器的形式化驗證是一項重要工作,例如:CompCert編譯器(C編譯器)[45]、清華大學L2C項目(LUSTRE編譯器)[27,28]以及Vélus編譯器(LUSTRE編譯器)[46].我們已經給出SIGNAL多線程代碼生成器前端的語義保持證明,下一步工作將基于Coq完成代碼生成器后端的語義保持證明.其次,擴展同步語言以支持描述實時性質,以及考慮在時間可預測多核處理器(如 Patmos[47])上執行多線程代碼并進行 WCET分析也是未來一項重要工作;最后,針對復雜嵌入式系統,我們正在開展嵌入式實時系統體系結構分析與設計語言 AADL(描述系統架構)[48]和同步語言(描述AADL單構件內的功能)的混合建模方法研究.
致謝感謝匿名評審專家給予的寶貴意見.另外,感謝法國法國國家信息與自動化研究所(INRIA)Jean-Pierre Talpin教授給予了很多重要的建議.
猜你喜歡
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
瘋狂英語·新策略(2017年8期)2017-05-31 08:13:46
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
