并發程序中數據競爭檢測方法
2019-08-01 01:35:23張楊梁亞楠張冬雯孫仕欣
計算機應用 2019年1期
張楊 梁亞楠 張冬雯 孫仕欣

摘 要:針對數據競爭檢測過程中的誤報和漏報問題,提出一種靜態數據競爭檢測方法。首先,使用控制流分析自動構造線程內和線程間函數調用圖;然后,收集線程內變量訪問事件信息,定義競爭產生條件并分析檢測出所有可能的競爭;其次,為了提高檢測的準確率,進行別名變量和別名鎖的分析降低漏報和誤報;最后,通過控制流分析來抽象訪問事件之間的時序關系,并結合程序切片技術對訪問事件的發生序關系進行判斷,以此避免因忽略線程交互帶來的誤報。依據該方法,使用Java語言在Soot軟件分析框架下實現了一個數據競爭檢測工具。在實驗中,對JGF和IBM Contest基準測試套件中的raytracer和airline等程序進行數據競爭檢測,并與目前已有的數據競爭檢測算法和工具(HB算法和RVPredict)進行對比。實驗結果表明,與HB算法和RVPredict工具相比,該方法檢測到的數據競爭總數分別增加了81%和16%,數據競爭檢測的準確率分別提升了約14%和19%,有效地避免了數據競爭檢測中的漏報和誤報現象。
關鍵詞:并發程序;數據競爭;控制流分析;別名分析;程序切片
中圖分類號: TP311.53
文獻標志碼:A
Abstract: Aiming at the problems of false positive and false negatives in data race detection, a novel static data race detection approach was proposed. Firstly, intra-thread and inter-thread function call graphs were automatically constructed via control flow analysis. Secondly, the information of variable-access events within thread were collected, and possible races were detected based on the defined data race conditions. Then, in order to improve the detection accuracy, alias variables and alias locks were analyzed to reduce false negatives and false positives, respectively. Finally, the sequential relationship between access events was abstracted through control flow analysis, and program slicing was used to determine the happens-before relationship of access events, thereby reducing false positives caused by ignoring thread interactions. A data race detection tool was implemented by Java and Soot framework based on this approach. In the experimentation, several benchmarks from JGF and IBM Contest benchmark suites, such as raytracer and airline, were selected for evaluation, and the results were compared with existing data race detection algorithm and tool (HB (Happens-Before) and RVPredict). The experimental results show that, compared with algorithm HB and tool RVPredict, total number of data races detected by the proposed approach are increased by 81% and 16% respectively, the accuracy of this approach for data race detection are respectively increased by 14% and 19%, which effectively avoids false negatives and false positives.
Key words: concurrent program; data race; control flow analysis; alias analysis; program slicing
0 引言
隨著多核處理器的普及和眾核處理器的發展,越來越多的人開始使用并發編程來提高程序的性能。并發編程具有很多優勢,它不僅可以減少程序的運行時間,而且可以提高程序的吞吐量和多核處理器的利用率。
雖然并發編程帶了很多好處,但并發程序內部的并發性和不確定性仍然會導致一些難以避免的問題,包括死鎖、數據競爭、原子性違背和順序違背等,這些并發問題都有著難以檢測、調試和修復的特點[1]。在這些并發問題中,數據競爭是指在多線程程序中,兩個或多個線程在無時序限制情況下訪問同一內存位置并且至少有一個線程執行寫操作[2]。數據競爭常常是引起其他非死鎖并發缺陷的根本原因,并且在所有并發缺陷中占有較大比例[3-4]。
依據檢測的時機,數據競爭檢測分為靜態分析和動態分析兩種。動態分析通過插樁來獲取變量和別名的準確信息,但由于線程調度策略不同,程序的執行結果可能不同[5],這使得動態檢測覆蓋面不全,往往存在很多的漏報,并且檢測開銷很大。與動態分析相比,靜態分析具有速度快、檢測更加全面等優點,但由于靜態分析的不可判定性,靜態檢測算法只是一種不完備的近似算法[6]。
很多國內外學者對數據競爭檢測的問題進行了研究。其中動態檢測主要分為三種:基于發生序關系的檢測方法、基于鎖集的檢測方法、二者結合進行檢測的方法。基于發生序關系方法中具有代表性的方法是Djit+[7],它使用向量時鐘進行數據競爭分析,FastTrack[8]和LOFT[9]等都是在向量時鐘基礎上進行的改進。Savage等[10]提出基于鎖集的檢測工具Eraser,通過共享變量持有的鎖集情況判斷競爭。ACCULOCK[11]是第一個采用輕量級邏輯時鐘平衡檢測精度與覆蓋率的二者混合方法。在靜態檢測方面,常用的檢測工具包括RacerX[12]、LOCKSMITH[13]和RELAY[14]。其中:RacerX利用流敏感和過程間分析檢測數據競爭和死鎖;LOCKSMITH首先使用標簽流約束和抽象控制流圖約束來進行鎖集分析,然后展開共享變量分析,最后結合線性分析檢測出數據競爭;RELAY由于其擴展性堪稱優良,能夠應用在百萬級別代碼量的程序上,實際使用中獲得了高度認可和廣泛接受。雖然很多學者在數據競爭檢測方面進行了相關研究,但針對競爭檢測出現的誤報和漏報現象有待于進一步研究與分析。
為了降低數據競爭檢測的誤報率和漏報率,本文提出一個面向并發程序的靜態數據競爭檢測方法。該方法在Soot軟件分析框架[15]下使用控制流分析、別名分析、時序分析、程序切片等分析技術對并發程序中的數據競爭進行檢測,并開發了相應的檢測工具。在實驗中,將本文方法和HB(Happens-Before)算法[16]、RVPredict[17]工具進行了對比,實驗結果表明,相對于其他兩種方法,本文方法能夠有效地發現并發程序中的數據競爭,可以改善檢測過程中的誤報和漏報問題。
1 相關工作
HB的概念最初由Lamport[16]是哪個文獻?是文獻16嗎?請明確。若不是文獻16,注意在正文中的文獻的依次引用順序。提出,Lamport使用HB來定義分布式系統中事件之間的偏序關系,并且提出了一個分布式算法用于同步邏輯時鐘系統,將偏序關系擴展為事件的某種全序關系。
FastTrack是一個精確、有效的基于發生序關系的動態檢測方法,它是在經典的HB方法Djit+上進行的改進。Djit+使用向量時鐘進行數據競爭分析,而FastTrack采用基于epoch的輕量級邏輯時鐘將Djit+的時間復雜度從O(n)降到接近于O(1)。
由于發生序關系對線程交錯比較敏感,單純使用這一方法會導致很多漏報。鎖集算法通過判斷訪問操作發生時的鎖集情況來進行數據競爭分析,它不敏感于線程交錯,而單純使用鎖集算法會忽略其他的一些同步原語,導致很多誤報,因此結合鎖集算法和發生序關系的混合算法應運而生。ACCULOCK采用二者混合的方法,使用FastTrack中提到的輕量級邏輯時鐘來進行發生序關系分析,同時對解鎖操作增加時間戳,根據鎖集的時間戳去掉一些冗余的分析。由于該方法保留的是共享內存最后一次讀和寫相關的epoch和鎖集,因此也存在一定的誤報和漏報。
在靜態檢測方面,Choi等[18]實現了對并發程序作自動分析的靜態工具。它以訪問事件為中心,分別對特定路徑和所有路徑作別名分析,得到確定的競爭和可能競爭的對象對,但是由于它沒有對線程間訪問事件的發生序關系進行抽象分析(start/join原語等),因此會導致很多誤報。
RacerX對C語言的競爭按模式匹配檢測,它是一個靜態工具,使用流敏感的過程間分析來檢測競爭。RacerX用于在大型復雜的多線程系統中,且分析速度很快,但是它不進行別名分析,只是根據經驗對分析產生的競爭對按照可能性等級排列,所以準確度比較低。
吳萍等[19]提出了一種精確、有效的對多線程程序靜態檢測的框架JTool,它的分析算法將競爭問題分解為跨線程的控制流分析,應用了上下文敏感和流敏感的別名分析,并靜態模擬了訪問事件的時序關系以進行約束求解。
近幾年,出現了很多數據競爭預測分析工具,RVPredict采用因果預測分析方法,將抽象化的控制流信息添加到執行模型中,把競爭檢測作為一個約束求解問題,利用SMT(Satisfiability Modulo Theories)求解器來查找競爭。Liu等[20]利用指針分析對預測分析方法進行了改進,實現了一個競爭預測分析工具。它是第一個允許改變訪問位置的預測分析工具,通過指針分析和預測分析的結合來解決訪問變量依賴于訪問位置的問題,并采用了混合編碼方式以提高實用性。
2 競爭檢測
2.1 檢測框架
本文利用Soot分析工具對Java源代碼進行中間轉換,采用Jimple作為中間表示(Intermediate Representation, IR),通過控制流分析構造線程內和線程間的函數調用關系圖,收集線程內的所有訪問事件;通過定義數據競爭產生的條件,并依據條件收集所有可能產生競爭的訪問事件對;為了提高檢測的精確度,對所有的競爭訪問事件進行別名分析和發生序關系分析,別名分析不僅考慮了別名變量的影響,還考慮到了別名鎖帶來的誤報問題;在發生序關系分析中,本文采用控制流分析抽象線程內和線程間訪問事件的時序關系,對訪問事件進行切片分析并定義發生序關系產生的條件,完成兩個事件的發生序關系判斷,排除某些因線程交互造成的假競爭。競爭檢測框架如圖1所示。
2.2 Soot分析
本文提出的框架使用Soot軟件分析工具輔助完成。Soot框架提供了一組用于分析和變換的中間表示Jimple,它是一個緊湊、無棧、類型化的三地址代碼中間表示法。在Jimple的基礎上,Soot不僅提供了一系列類和方法用于源程序的分析,還提供了以Pack為中心的擴展機制,一個Pack包括若干個變換,用戶可以自行設計新的變換,將其加入到Soot的調度執行過程中以實現特定的功能。例如,本文利用Soot工具提供的類ReachableMethods和TransitiveTargets中的若干方法獲取線程的所有直接和間接調用函數,并自定義方法排除調用函數中無變量訪問操作以及那些屬于Java開發工具包(Java Development Kit, JDK)的函數,最后將本文的函數調用圖分析作為一個新的轉換添加的Soot的調度過程中,完成線程內和線程間的函數調用關系圖分析。
2.3 訪問事件
由于競爭檢測經常發生在一對事件之間,所以本文使用“訪問事件對”來描述數據競爭檢測情況。使用Soot擴展機制進行控制流分析,構建主線程和子線程關于線程內和線程間的函數調用關系圖,每個線程對變量進行一次訪問操作記作一個訪問事件。從每個線程的函數調用圖中收集該線程的所有訪問事件。
將一個訪問事件表示為:
其中:threadID為訪問線程的ID,accessObject表示線程的訪問變量,iswrite(布爾型)表示訪問操作是否為寫操作,lockset表示訪問操作發生時所擁有的鎖集。
下面給出一個可能存在數據競爭的示例程序,如圖2所示(第4行與第9行代碼存在競爭)。該示例程序包含3個線程:main、t1和t2。主線程main創建了兩個子線程t1和t2;線程t1在第5行和第7行分別獲取鎖和釋放鎖,因此第4行的訪問操作不受鎖保護;線程t2在第8行獲取鎖之后該線程中的變量訪問操作均受鎖保護,直至第11行釋放鎖。第1行在沒有鎖保護的情況下,主線程main對變量x的域g進行了寫操作,記作訪問事件ACCESS1:〈main,x.g,1,{null}〉;類似地,線程t1在第4行和第6行的訪問事件分別為ACCESS4:〈t1,x.g,1,{null}〉和ACCESS6:〈t1,x.f,1,{lock(a)}〉;線程t2在第9行和第10行的訪問事件分別為ACCESS9:〈t2,y.g,1,{lock(b)}〉和ACCESS10:〈t2,y.f,1,{lock(b)}〉。
2.4 數據競爭判定條件
兩個訪問事件ACCESSi和ACCESSj存在數據競爭當且僅當它們滿足以下條件:
依據數據競爭發生的條件,對訪問事件進行判斷,能夠得到所有可能的數據競爭。
2.5 別名分析
別名現象是指兩個互為別名的引用變量共同指向同一個對象時,其中一個引用對象改變,另一個引用變量的對象值也會跟著改變。
對兩個訪問事件的訪問對象進行別名分析,目的是判斷兩個變量訪問操作所指向的內存位置是否一致,避免因忽略變量的別名現象而帶來的漏報。假設圖2中x,y是一對別名,那么第4行和第9行的訪問對象x.g和y.g將指向的是同一內存位置;而假如沒有考慮到x,y互為別名的現象,在競爭檢測過程中,x.g和y.g被作為兩個不同的訪問對象,那么會導致線程t1,t2之間實際的數據競爭〈ACCESS4,ACCESS9〉被漏報。
別名現象還存在于鎖集分析中,對鎖集進行別名分析,能夠在一定程度上降低誤報。例如,圖2中第6行和第10行的競爭訪問對:〈ACCESS6,ACCESS10〉,兩個訪問操作所持有的鎖集分別為{lock(a)}和{lock(b)}。假設a,b是一對別名,那么lockset6∧lockset10≠null(其中,lockseti表示第i條語句所在的鎖集),根據鎖的排他性,那么線程t1和t2將不可能同時訪問域f。如果不考慮別名現象,那么兩個訪問事件的鎖集的交集為null,該訪問事件對很可能被報告為一個真實競爭,這會導致誤報,因此,針對鎖的別名分析能夠避免某些誤報情況的發生,提高數據競爭檢測的精確度。
2.6 控制流分析
本文基于Jimple構造并發程序的控制流圖(Control Flow Graph, CFG)。CFG為用在編譯器中的一個抽象數據結構,它是一個有向圖,可以用G=(N,E,nentry,nexit)表示。其中,N為節點集,N= {n1, n2,…},程序中每條語句對應圖中的一個節點;E為有向邊集,E= {〈n1, n2〉| n1,n2∈N},且n1執行后可能立即執行n2;nentry和nexit分別為程序的入口和出口節點。
對圖2示例程序進行控制流圖分析,可以得到:
基于所在線程,對N中所有節點進行分類;通過收集每個節點的出度邊,對E中所有邊進行分類,得到如表1所示的基于線程的節點集和邊集。
2.7 發生序關系分析
2.7.1 時序關系圖
通過相應的有向邊將程序中的節點連接起來,能夠得到各節點之間的時序關系圖,圖3中每一個節點代表程序中語句的一次執行,有向邊表明了各節點之間的執行順序。線程內的有向邊用實線箭頭表示,〈2,4〉和〈3,8〉為跨線程有向邊,用虛線箭頭表示。
在一個時序關系圖中,當兩個訪問事件的節點之間能夠通過一個或多個有向邊單向連接時,它們之間是存在發生序關系的。兩個訪問事件ACCESSi和ACCESSj存在發生序關系當且僅當它們滿足以下條件:
1)ACCESSi能夠通過若干有向邊到達ACCESSj(保證連接性);
2)ACCESSj不能通過有向邊到達ACCESSi(保證單向性)。
例如,對于圖3中節點1和節點4(訪問事件對〈ACCESS1,ACCESS4〉),雖然訪問對象相同均為x.g,但兩者可以通過若干有向邊單向連接,因此具有發生序關系,不會產生競爭;而節點4和節點9(不能通過若干有向邊單向連接)之間不具有發生序關系。
2.7.2 訪問事件切片分析
本文方法對時序關系圖中的訪問事件進行程序切片,然后定義產生發生序關系的條件,依據所得的切片是否滿足特定條件判斷是否具有發生序關系。程序P的切片S是一個可執行的程序,對某個程序點s處的變量v而言(〈s,v〉稱為切片準則),S由程序P中可能影響s處變量v的值的所有語句構成[21]。例如,對于節點1和節點4(即針對訪問事件對〈ACCESS1,ACCESS4〉),分別以切片準則〈1,g〉和〈4,g〉向后進行程序切片,收集所有通過有向邊可達的可能影響變量g的節點,分別得到切片S1:〈1,4,9〉和S4:〈4〉。
針對任意兩個訪問事件的切片,定義產生發生序關系的條件。當兩個訪問事件分別以〈si,v〉和〈sj,v〉作為切片準則得到程序切片Si和Sj時,它們具有發生序關系需要滿足的條件1)和2)可以抽象定義為:(si∈Sj)∧(sjSi)。
例如,對于訪問事件對〈ACCESS1,ACCESS4〉,由于兩個訪問事件存在start原語產生的線程交互,因此兩個訪問事件不可能同時發生。對兩者的切片進行發生序關系條件的判斷,得到(4∈S1)∧(1S4),所以節點1和節點4之間具有發生序關系,〈ACCESS1,ACCESS4〉為假競爭。同理,可以對節點4和節點9進行切片并進行條件判斷,能發現〈ACCESS4,ACCESS9〉不具有發生序關系。
由此可見,發生序關系分析能夠對線程交互造成的訪問事件之間的時序限制進行分析,排除部分假競爭,提高檢測的準確度。
3 實驗
3.1 實驗環境與測試程序
在實驗中,使用了Dell Z820工作站,該工作站中配備了兩個Intel Xeon E5-2650處理器,主頻為2.60GHz,每一個CPU有8個處理核,每個處理核均支持超線程,可支持32個線程同時運行,內存128GB。在軟件方面,使用了64位Windows 7操作系統,JDK版本是1.8.0_31。
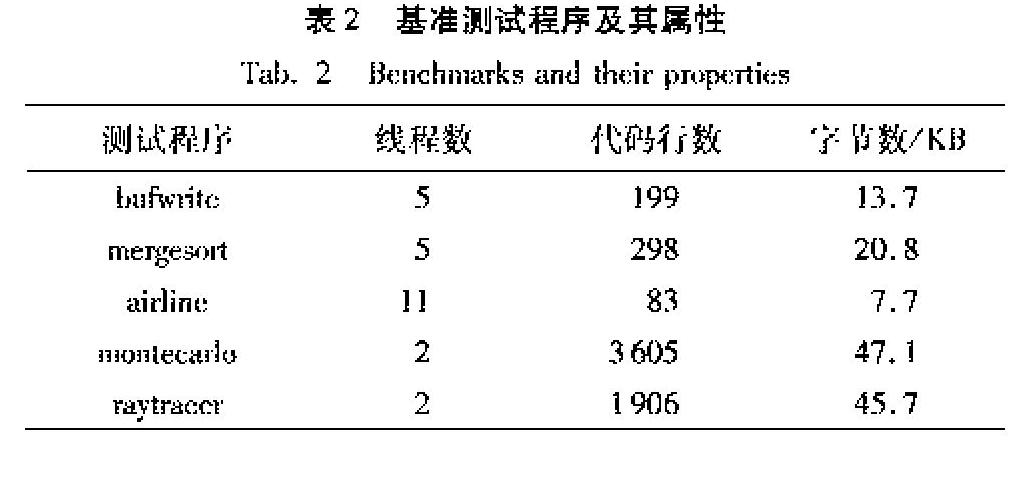
在測試程序的選擇上,本文從JGF(Java Grande Forum)基準測試套件[22]中選取了光線追蹤程序raytracer和蒙特卡羅程序montecarlo,這兩個測試程是JGF測試程序中較大規模的測試程序,它們分別提供了SizeA和SizeB兩種輸入,在實驗中選擇使用較大數據集SizeB作為輸入,這兩個測試程序分別存在一個已知的數據競爭;此外,本文從IBM Contest基準測試套件[23]中選取了3個測試程序,分別是bufwrite、mergesort和airline。表2對實驗選取的測試程序的相關屬性進行了說明。
3.2 實驗結果與分析
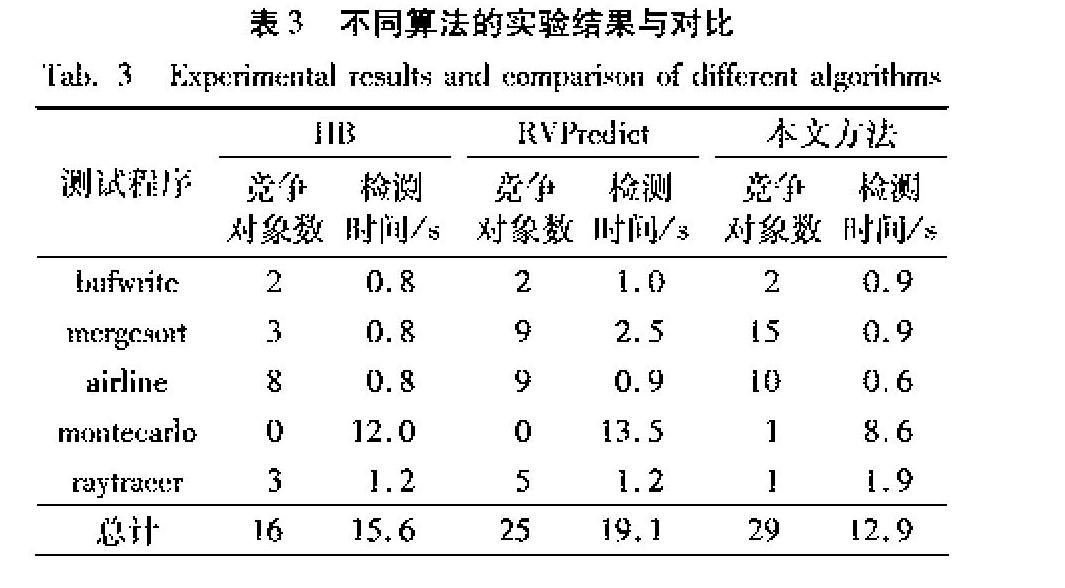
為了驗證本文提出的方法的有效性,將本文方法分別與HB算法和RVPredict方法進行了比較。在實驗中,對檢測的數據競爭數和檢測所耗費的時間進行了測試,實驗結果如表3所示。
從表3的實驗結果可以發現:
1)本文方法能夠有效地發現潛在的數據競爭,從而更大限度地避免漏報。
對于測試程序bufwrite,三種方法檢測的數據競爭數相同;而對于mergesort、airline和montecarlo三個測試程序,本文方法檢測的數據競爭數均多于HB算法和RVPredict。其中最為明顯的是mergesort測試程序,本文方法檢測到數據競爭15個,而HB算法和RVPredict檢測結果均不足10個。為了保證檢測結果的正確性,對相關代碼進行了分析,經過確認,這些數據競爭均真實有效。
綜上,能夠看出本文方法具有較高的檢測覆蓋率,能夠更大限度地避免漏報現象。這是因為:本文通過構造時序約束圖來進行發生序關系分析,在時序約束圖中并沒有指定訪問事件的執行路徑;而HB算法對線程調度比較敏感,線程調度不同,訪問事件的執行路徑不同,因此存在很多漏報;RVPredict將執行路徑抽象為一系列訪問事件序列,因此也可能會遺漏某些路徑而導致漏報。此外,本文方法中別名變量的分析也在一定程度上降低了漏報的發生。
2)本文方法能夠顯著避免誤報的發生。
對于測試程序raytracer,已知實際有害競爭數為1,本文方法檢測的數據競爭數為1,而HB算法和RVPredict檢測的數據競爭數分別為3和5,這表明本文方法不僅能夠準確檢測實際競爭,而且還能夠避免誤報。從檢測結果總數來看,本文檢測到的競爭共29個,與RVPredict相比,本文方法檢測到的數據競爭總數增加了16%;與HB算法相比,本文方法的檢測競爭總數甚至增加了約81%。從檢測的準確率來看,本文方法檢測準確率為100%,而HB算法和RVPredict的準確率分別為87.5%和84%,與這兩種方法相比,準確率分別提升了約14%和19%。這說明本文方法在提高數據競爭檢測覆蓋率的同時,能夠保證檢測的正確性,避免誤報的發生。
本文方法中對于別名鎖的分析能夠降低某些數據競爭的誤報現象,此外,通過時序約束圖和程序切片的結合進行發生序關系分析能夠避免那些因忽略線程交互帶來的誤報。
3)從檢測時間上看,本文提出的方法沒有明顯的開銷,而且大多數情況優于其他兩種方法。
對于bufwrite、mergesort程序,本文方法比HB方法的檢測時間略長,但是少于RVPredict的檢測時間;對于airline和montecarlo程序,本文方法的檢測時間明顯少于其他兩種檢測方法;對于raytracer程序,本文方法的檢測時間略長。總的來說,盡管本文方法對于某些程序的檢測時間多于其他兩種方法,但是這些檢測時間也都在可接受的時間范圍之內,本文方法并沒有產生明顯的開銷。
4 結語
本文提出了一種面向并發程序的靜態數據競爭檢測方法,該方法采用控制流分析、別名分析、時序分析以及程序切片技術對數據競爭進行檢測,降低數據競爭檢測過程中的誤報和漏報。在實驗中本文通過5個基準測試程序驗證了該方法的有效性,并與HB算法和RVPredict工具進行實驗對比,結果表明在沒有增加檢測開銷的前提下,本文方法不僅能夠有效地檢測數據競爭,而且能夠降低誤報率和漏報率。進一步研究包括選取更多樣化以及規模更大的基準程序對本文的方法進行測試。
參考文獻 (References)
[1] YANG J, JIANG B, CHAN W K. HistLock+: precise memory access maintenance without lockset comparison for complete hybrid data race detection [J]. IEEE Transactions on Reliability, 2018, 68(3): 786-801.
[2] 禹振,楊振,蘇小紅,等.多線程程序數據競爭檢測和驗證方法研究綜述![J].智能計算機與應用,2017,7(3):123-126.(YU Z, YANG Z, SU X H, et al. A survey on methods of data race detection and verification on multithreaded program [J]. Intelligent Computer & Applications, 2017, 7(3): 123-126.)
[3] 蘇小紅,禹振,王甜甜,等.并發缺陷暴露、檢測與規避研究綜述[J].計算機學報,2015,38(11):2215-2233.(SU X H, YU Z, WANG T T, et al. A survey on exposing, detecting and avoiding concurrency bugs [J]. Chinese Journal of Computers, 2015, 38(11): 2215-2233.)
[4] LU S, PARK S, SEO E, et al. Learning from mistakes: a comprehensive study on real world concurrency bug characteristics [J]. ACM SIGARCH Computer Architecture News, 2008, 44(3): 11-21.
[5] 吳俞伯,郭俊霞,李征,等.基于并發程序數據競爭故障的變異策略[J].計算機應用,2016,36(11):3170-3177.(WU Y B, GUO J X, LI Z, et al. Mutation strategy based on concurrent program data racing fault [J]. Journal of Computer Applications, 2016, 36(11): 3170-3177.)
[6] 張昱,郝允允.Java程序數據競爭的增量式檢測[J].西安交通大學學報,2009,43(8):22-27.(ZHANG Y, HAO Y Y. Incremental detection of data race for Java programs [J]. Journal of Xian JiaoTong University, 2009, 43(8): 22-27.)
[7] POZNIANSKY E, SCHUSTER A. MultiRace: efficient on-the-fly data race detection in multithreaded C++ programs [J]. Concurrency & Computation Practice & Experience, 2007, 19(3): 327-340.
[8] FLANAGAN C, FREUND S N. FastTrack: efficient and precise dynamic race detection [C]// Proceedings of the 30th ACM SIGPLAN Conference on Programming Language Design and Implementation. New York: ACM, 2009: 121-133.
[9] CAI Y, CHAN W K. LOFT: redundant synchronization event removal for data race detection [C]// Proceedings of the 2011 IEEE 22nd International Symposium on Software Reliability Engineering. Washington, DC: IEEE Computer Society, 2011: 160-169.
[10] SAVAGE S, BURROWS M, NELSON G, et al. Eraser: a dynamic data race detector for multi-threaded programs [J]. ACM Transactions on Computer Systems, 1997, 31(5): 27-37.
[11] XIE X, XUE J. ACCULOCK: accurate and efficient detection of data races [J]. Software Practice & Experience, 2013, 43(5): 543-576.
[12] ENGLER D, ASHCRAFT K. RacerX: effective, static detection of race conditions and deadlocks [C]// SOSP 03: Proceedings of the 19th ACM Symposium on Operating Systems Principles. New York: ACM, 2003: 237-252.
[13] PRATIKAKIS P, FOSTER J S, HICKS M. LOCKSMITH: context-sensitive correlation analysis for race detection [J]. ACM SIGPLAN Notices, 2006, 41(6): 320-331.
[14] VOUNG J W, JHALA R, LERNER S. RELAY: static race detection on millions of lines of code [C]// Proceedings of the 6th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering. New York: ACM, 2007: 205-214.
[15] LAM P, VERBRUGGE C, POMINVILLE P, et al. Soot (poster session): a Java bytecode optimization and annotation framework [C]// OOPSLA00: Proceedings of the 2000 Conference on Object-Oriented Programming, Systems, Languages, and Applications. New York: ACM, 2000: 113-114.
[16] LAMPORT L. Time, clocks, and the ordering of events in a distributed system [J]. Communications of the ACM, 2008, 21(7): 558-565.
[17] HUANG J, MEREDITH P O, ROSU G. Maximal sound predictive race detection with control flow abstraction [J]. ACM SIGPLAN Notices, 2014, 49(6): 337-348.
[18] CHOI J D, LOGINOV A, SARKAR V. Static datarace analysis for multithreaded object-oriented programs [R]. Yorktown Heights, NY: IBM Research Division, 2001: 1-18.
[19] 吳萍,陳意云,張健.多線程程序數據競爭的靜態檢測[J].計算機研究與發展,2006,43(2):329-335.(WU P, CHEN Y Y, ZHANG J. Static data-race detection for multithread programs [J]. Journal of Computer Research and Development, 2006, 43(2): 329-335.)
[20] LIU P, TRIPP O, ZHANG X. IPA: improving predictive analysis with pointer analysis [C]// Proceedings of the 2016 International Symposium on Software Testing and Analysis. New York: ACM, 2016: 59-69.
[21] WEISER M. Program slicing [J]. IEEE Transactions on Software Engineering, 1984, SE-10(4): 352-357.
[22] SMITH L A, BULL J M, OBDRIZALEK J. A parallel Java grande benchmark suite [C]// Proceedings of the 2001 ACM/IEEE Conference of Supercomputing. Piscataway, NJ: IEEE, 2001: 8-8.
[23] FARCHI E, NIR Y, UR S. Concurrent bug patterns and how to test them [C]// Proceedings of the 2003 International Symposium on Parallel and Distributed Processing. Washington, DC: IEEE Computer Society, 2003: 286-296.
