基于多注意力多尺度特征融合的圖像描述生成算法
2019-08-01 01:57:38陳龍杰張鈺張玉梅吳曉軍
計(jì)算機(jī)應(yīng)用 2019年2期
陳龍杰 張鈺 張玉梅 吳曉軍


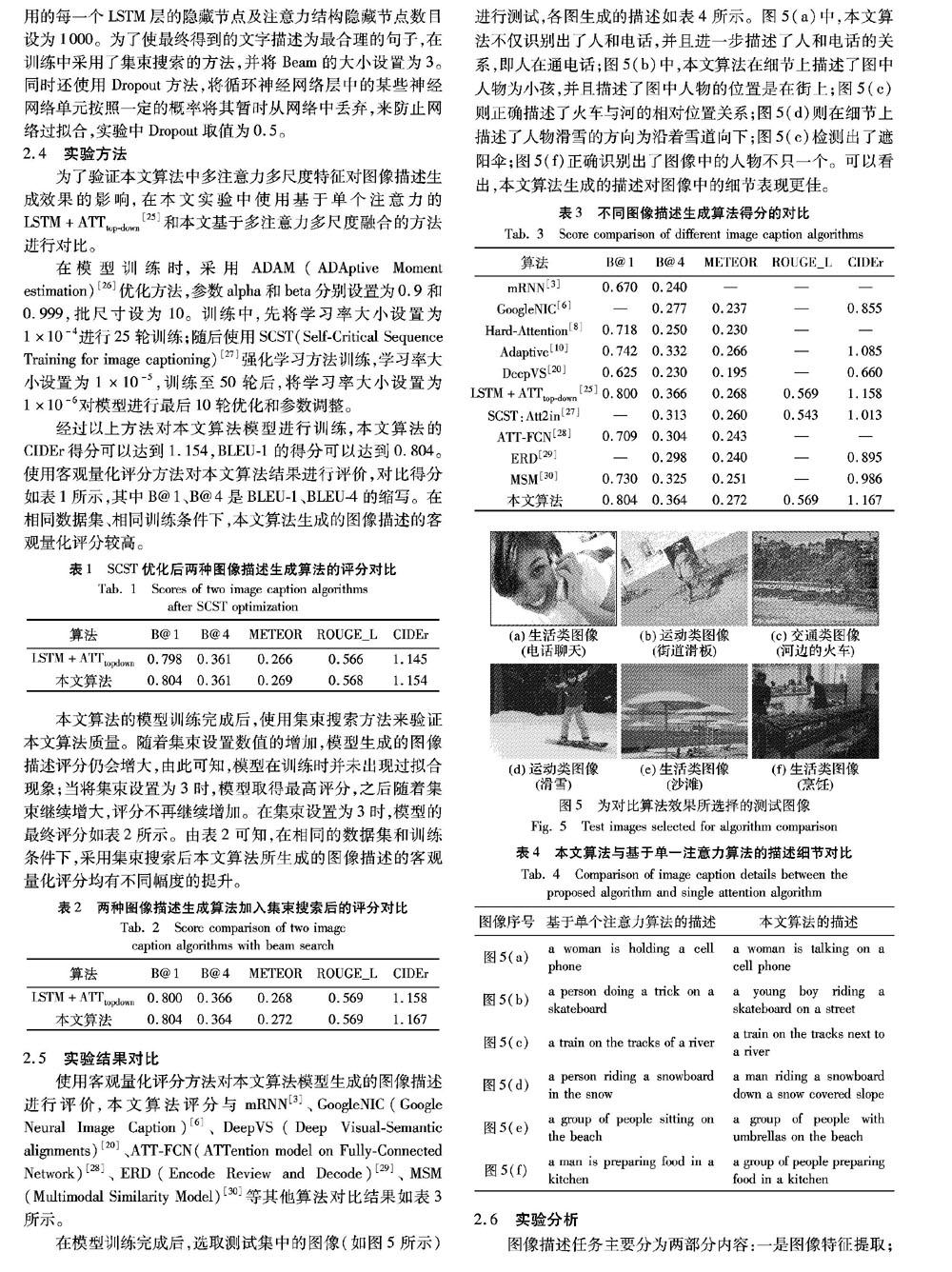
摘 要:針對(duì)圖像描述生成中對(duì)圖像細(xì)節(jié)表述質(zhì)量不高、圖像特征利用不充分、循環(huán)神經(jīng)網(wǎng)絡(luò)層次單一等問(wèn)題,提出基于多注意力、多尺度特征融合的圖像描述生成算法。該算法使用經(jīng)過(guò)預(yù)訓(xùn)練的目標(biāo)檢測(cè)網(wǎng)絡(luò)來(lái)提取圖像在卷積神經(jīng)網(wǎng)絡(luò)不同層上的特征,將圖像特征分層輸入多注意力結(jié)構(gòu)中,依次將多注意力結(jié)構(gòu)與多層循環(huán)神經(jīng)網(wǎng)絡(luò)相連,構(gòu)造出多層次的圖像描述生成網(wǎng)絡(luò)模型。在多層循環(huán)神經(jīng)網(wǎng)絡(luò)中加入殘差連接來(lái)提高網(wǎng)絡(luò)性能,并且可以有效避免因?yàn)榫W(wǎng)絡(luò)加深導(dǎo)致的網(wǎng)絡(luò)退化問(wèn)題。在MSCOCO測(cè)試集中,所提算法的BLEU-1和CIDEr得分分別可以達(dá)到0.804及1167,明顯優(yōu)于基于單一注意力結(jié)構(gòu)的自上而下圖像描述生成算法;通過(guò)人工觀察對(duì)比可知,所提算法生成的圖像描述可以表現(xiàn)出更好的圖像細(xì)節(jié)。
關(guān)鍵詞:長(zhǎng)短期記憶網(wǎng)絡(luò);圖像描述;多注意力機(jī)制;多尺度特征融合;深度神經(jīng)網(wǎng)絡(luò)
中圖分類號(hào): TP391.41
文獻(xiàn)標(biāo)志碼:A
Abstract: Focusing on the issues of low quality of image caption, insufficient utilization of image features and single-level structure of recurrent neural network in image caption generation, an image caption generation algorithm based on multi-attention and multi-scale feature fusion was proposed. The pre-trained target detection network was used to extract the features of the image from the convolutional neural network, then the image features were layered and put into caption model with multi-attention mechanism.which were input into the multi-attention structures at different layers.?Each attention part with features of different levels was related to the multi-level recurrent neural networks sequentially, constructing a multi-level image caption generation network model. By introducing residual connections in the recurrent networks, the network complexity was reduced and the network degradation caused by deepening network was avoided. In MSCOCO datasets, the BLEU-1 and CIDEr scores of the proposed algorithm can achieve 0.804 and 1167, which is obviously superior to top-down image caption generation algorithm based on single attention structure. Both artificial observation and comparison results velidate that the image caption generated by the proposed algorithm can show better details.
Key words: Long Short-Term Memory (LSTM) network; image caption; multi-attention mechanism; multi-scale feature fusion; deep neural network
0 引言
圖像是人類社會(huì)活動(dòng)中最常用的信息載體,其中蘊(yùn)含了豐富的信息。隨著互聯(lián)網(wǎng)技術(shù)的發(fā)展及數(shù)碼設(shè)備的普及,圖像數(shù)據(jù)增長(zhǎng)迅速,使用純?nèi)斯?duì)圖像內(nèi)容鑒別已成為一項(xiàng)艱難的工作。因此,如何通過(guò)計(jì)算機(jī)自動(dòng)提取圖像所表達(dá)的信息,已成為圖像理解領(lǐng)域的研究熱點(diǎn)。圖像描述生成是融合了自然語(yǔ)言處理和計(jì)算機(jī)視覺的一項(xiàng)較為綜合的任務(wù),目的是將視覺圖像和語(yǔ)言文字聯(lián)系起來(lái),通過(guò)對(duì)所輸入圖像的特征進(jìn)行提取分析,自動(dòng)生成一段關(guān)于圖像內(nèi)容的文字描述。圖像描述生成能夠完成從圖像到文本信息的轉(zhuǎn)換,可以應(yīng)用到圖像檢索、機(jī)器人問(wèn)答、輔助兒童教育及導(dǎo)盲等多個(gè)方面,對(duì)圖像描述生成的研究具有重要的現(xiàn)實(shí)意義。
圖像描述生成是一種克服了人類主觀認(rèn)識(shí)的固有限制,借助計(jì)算機(jī)軟件從一幅或多幅圖像序列中生成與圖像相對(duì)應(yīng)文字描述的技術(shù)。圖像描述的質(zhì)量主要取決于以下兩個(gè)方面:一是對(duì)圖像中所包含物體及場(chǎng)景的識(shí)別能力;二是對(duì)物體間相互聯(lián)系等信息的認(rèn)知程度。按照?qǐng)D像描述模型的不同,圖像描述的方法可以分為三類:1)基于模板[1]的方法,該類方法生成的圖像描述依賴于模板類型,形式也較為單一;2)基于檢索的方法,依賴于數(shù)據(jù)集中現(xiàn)存的描述語(yǔ)句,無(wú)法生成較為新穎的圖像描述;3)基于神經(jīng)網(wǎng)絡(luò)的方法,通過(guò)將卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)[2]與循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)[3]結(jié)合,使用端對(duì)端的方法訓(xùn)練模型,利用CNN提取特征的優(yōu)勢(shì)和RNN處理文字序列的優(yōu)勢(shì),共同指導(dǎo)圖像文字描述的生成。
隨著深度學(xué)習(xí)的發(fā)展,以文獻(xiàn)[4]中提出的多模態(tài)循環(huán)神經(jīng)網(wǎng)絡(luò)(multimodal RNN,m-RNN)為代表的基于神經(jīng)網(wǎng)絡(luò)的方法嶄露頭角。m-RNN首次將圖像描述生成分割成兩個(gè)分支任務(wù),分別使用CNN提取圖像特征,利用RNN建立語(yǔ)言模型。m-RNN中的CNN采用AlexNet[5]結(jié)構(gòu),RNN使用兩層嵌入層將文字序列編碼為獨(dú)熱表示形式,之后輸入到循環(huán)層中,mRNN將CNN和RNN結(jié)合起來(lái),使用深層CNN提取圖像特征并輸入到RNN循環(huán)層的多模態(tài)層中,最后經(jīng)過(guò)Softmax層得到輸出結(jié)果。雖然m-RNN成功地將CNN引入圖像描述任務(wù)中,但其RNN結(jié)構(gòu)較為單一,網(wǎng)絡(luò)學(xué)習(xí)能力較弱。文獻(xiàn)[6]則使用長(zhǎng)短期記憶(Long Short-Term Memory,LSTM)網(wǎng)絡(luò)代替普通的RNN,并使用了帶有批標(biāo)準(zhǔn)化層的CNN提取圖像特征,算法精度和速度均有提升。在視頻自然語(yǔ)言描述任務(wù)中,文獻(xiàn)[7]使用AlexNet模型及牛津大學(xué)視覺幾何組(Visual Geometry Group,VGG)提出的VGG16模型分別提取視頻空間特征,采用多種特征融合的方法,將空間特征與通過(guò)提取相鄰幀的光流得到的運(yùn)動(dòng)特征與視頻時(shí)間特征融合后輸入LSTM自然語(yǔ)言描述模型,提升了視頻自然語(yǔ)言描述的準(zhǔn)確性。
3 結(jié)語(yǔ)
本文設(shè)計(jì)了基于多注意力多尺度融合深度神經(jīng)網(wǎng)絡(luò)的圖像描述生成算法,該算法通過(guò)使用Faster R-CNN目標(biāo)檢測(cè)模型提取圖像不同尺度上的特征,然后將圖像不同尺度上的特征依次輸入多個(gè)注意力結(jié)構(gòu),并最終連入多層循環(huán)網(wǎng)絡(luò)語(yǔ)言模型中。本文通過(guò)在多層語(yǔ)言模型中加入殘差映射來(lái)增加網(wǎng)絡(luò)學(xué)習(xí)效率。在實(shí)驗(yàn)中采用ADAM優(yōu)化方法,并通過(guò)在訓(xùn)練過(guò)程逐步降低學(xué)習(xí)率,可以有效地促進(jìn)網(wǎng)絡(luò)收斂。本文算法的圖像描述效果和BLEU、ROUGE_L、METEOR、CIDEr等評(píng)價(jià)指標(biāo)皆取得較高得分,其中BLEU-1、CIDEr得分可以達(dá)到0.804和1.167。實(shí)驗(yàn)結(jié)果表明,基于多注意力多尺度融合的神經(jīng)網(wǎng)絡(luò)模型在圖像描述生成任務(wù)上能取得出色的表現(xiàn),通過(guò)加入多個(gè)注意力結(jié)構(gòu)可以有效提高對(duì)圖像細(xì)節(jié)及位置關(guān)系等的描述效果。下一步,將結(jié)合現(xiàn)有圖像描述的方法,在視頻描述及圖像問(wèn)答等相關(guān)任務(wù)方面展開進(jìn)一步研究。
參考文獻(xiàn):
[1] FANG H, GUPTA S, IANDOLA F, et al. From captions to visual concepts and back [C]// CVPR2015: Proceedings of the 2015 International Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 1473-1482.
[2] LeCUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[3] HOPFIELD J J. Neural networks and physical systems with emergent collective computational abilities [J]. Proceedings of the National Academy of Sciences of the United States of America, 1982, 79(8): 2554-2558.
[4] MAO J, XU W, YANG Y, et al. Explain images with multimodal recurrent neural networks[EB/OL]. [2018-06-10]. https://arxiv.org/pdf/1410.1090v1.pdf.
[5] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]//NIPS 2012: Proceedings of the 2012 International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada: Curran Associates Inc. 2012: 1097-1105.
[6] VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator [C]//CVPR 2015: Proceedings of the 2015 International Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 3156-3164.
[7] 梁銳,朱清新,廖淑嬌,等.基于多特征融合的深度視頻自然語(yǔ)言描述方法[J].計(jì)算機(jī)應(yīng)用,2017,37(4):1179-1184. (LIANG R, ZHU Q X, LIAO S J, et al. Deep natural language description method for video based on multi-feature fusion[J]. Journal of Computer Applications, 2017,37(4):1179-1184.)
[8] XU K, BA J L, KIROS R, et al. Show, attend and tell: Neural image caption generation with visual attention[EB/OL]. [2018-06-08]. https://arxiv.org/pdf/1502.03044.pdf.Computer Science, 2015: 2048-2057.沒(méi)找到
[9] BAHDANAU D, CHO K H, BENGIO Y. Neural machine translation by jointly learning to align and translate [EB/OL]. [2018-06-10]. https://arxiv.org/pdf/1409.0473.pdf.Published as a conference paper at ICLR 2015
[10] LU J, XIONG C, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning [C]//CVPR2017: Proceedings of the 2017 International Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 3242-3250.
[11] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[EB/OL]. [2018-05-10]. https://arxiv.org/pdf/1706.03762.pdf.
沒(méi)找到NIPS2017: Proceedings of the 2012 International Conference on Neural Information Processing Systems. Long Beach, USA. 2017: 6000-6010.
[12] LI J, MEI X, PROKHOROV D, TAO D. Deep neural network for structural prediction and lane detection in traffic scene[J]. IEEE Transactions on Neural Networks and Learning Systems, 2017,28(3): 690-703.
[13] QU Y, LIN L, SHEN F, et al. Joint hierarchical category structure learning and large-scale image classification[J]. IEEE Transactions on Image Processing, 2017, 26(9): 4331-4346.
[14] SHELHAMER E, LONG J, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640-651.
[15] GONG C, TAO D, LIU W, LIU L, YANG J. Label propagation via teaching-to-learn and learning-to-teach[J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(6): 1452-1465.
[16] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// CVPR2016: Proceedings of the 2016 International Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 770-778.
[17] WANG P, LIU L, SHEN C, et al. Multi-attention network for one shot learning [C]// CVPR2017: Proceedings of the 2017 Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 22-25.
[18] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.https://arxiv.org/pdf/1506.01497v3.pdf
[19] LIN T-Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common Objects in COntext [C]//ECCV2014: Proceedings of the 2014 European Conference on Computer Vision. Cham: Springer, 2014: 740-755.
[20] KARPATHY A, LI F-F. Deep visual-semantic alignments for generating image descriptions [C]//CVPR2015: Proceedings of the 2015 International Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 3128-3137.
[21] PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]// ACL2002: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA: ACL, 2002: 311-318.
[22] LIN C-Y. Rouge: a package for automatic evaluation of summaries [C]//ACL2004: Proceedings of the ACL 2004 Workshop on Text Summarization. Stroudsburg, PA: ACL, 2004: 74-81.
[23] BANERJEE S, LAVIE A. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments [C]//ACL2005: Proceedings of the 2005 ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Stroudsburg, PA: ACL, 2005: 65-72.https://en.wikipedia.org/wiki/METEOR
[24] VEDANTAM R, ZITNICK C L, PARIKH D. CIDEr: consensus-based image description evaluation [C]//CVPR2015: Proceedings of the 2015 International Conference on Computer Vision and PatternRecognition. Washington, DC: IEEE Computer Society, 2015: 4566-4575.https://arxiv.org/pdf/1411.5726v2.pdf
[25] ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and VQA[EB/OL]. [2018-05-07]. https://arxiv.org/pdf/1707.07998.pdf.
[26] KINGMA D P, BA J. ADAM: a method for stochastic optimization [EB/OL].[2018-04-22]. https://arxiv.org/pdf/1412.6980.pdf.Published as a conference paper at ICLR 2015
[27] RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning [C]//CVPR2017: Proceedings of the 2017 International Conference on Computer Vision and PatternRecognition. Washington, DC: IEEE Computer Society, 2017: 1179-1195.https://arxiv.org/pdf/1612.00563.pdf
[28] YOU Q, JIN H, WANG Z, et al. Image captioning with semantic attention [C]//CVPR2016: Proceedings of the 2016 International Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 46514659.https://www.cvfoundation.org/openaccess/content_cvpr_2016/papers/You_Image_Captioning_With_CVPR_2016_paper.pdf
[29] YANG Z, YUAN Y, WU Y, et al. Encode, review, and decode: Reviewer module for caption generation[EB/OL]. [2018-06-10]. https://arxiv.org/pdf/1605.07912v1.pdf.
[30] YAO T, PAN Y, LI Y, et al. Boosting image captioning with attributes[EB/OL]. [2018-03-10]. https://arxiv.org/pdf/1611.01646.pdf.未查到OpenReview, 2016, 2(5): 8.,應(yīng)該是 ICLR 2017https://arxiv.org/pdf/1611.01646.pdf
