基于卷積神經網絡的人臉圖像質量評價
2019-07-31 12:14:01李秋珍欒朝陽汪雙喜
計算機應用 2019年3期
關鍵詞:人臉識別
李秋珍 欒朝陽 汪雙喜
摘 要:針對人臉識別過程中人臉圖像質量較低造成的低識別率問題,提出了一種基于卷積神經網絡的人臉圖像質量評價模型。首先建立一個8層的卷積神經網絡模型,提取人臉圖像質量的深層語義信息;然后在無約束環境下收集人臉圖像,并通過傳統的圖像處理方法以及人工篩選進行過濾,得到的數據集用以進行模型參數的訓練;其次通過在圖形處理器(GPU)上加速訓練,得到用于擬合人臉圖像到類別的映射關系;最后將輸入在高質量圖像類別的概率作為圖像的質量得分,建立人臉圖像的質量打分機制。實驗結果表明,與VGG-16網絡相比,所提模型準確率降低了0.21個百分點,但是參數規模減小了98%,極大地提高了模型運算效率;同時所提模型在人臉模糊、光照、姿態和遮擋方面都具有較強的判別能力。因此,可將該模型應用在實時人臉識別系統中,在不影響系統運行效率的前提下提高系統的準確性。
關鍵詞:人臉識別;卷積神經網絡;圖像質量;質量評價;圖像質量評價;人臉圖像質量評價
中圖分類號: TP391
文獻標志碼:A
文章編號:1001-9081(2019)03-0695-05
Abstract: Aiming at the low recognition rate caused by low quality of face images in the process of face recognition, a face image quality evaluation model based on convolutional neural network was proposed. Firstly, an 8-layer convolutional neural network model was built to extract deep semantic information of face image quality. Secondly, face images were collected in unconstrained environment, and were filtered by traditional image processing method and manual selecting, then the dataset obtained was used to train the model parameters. Thirdly, by accelerating training on GPU (Graphics Processing Unit), the mapping relationship of fitted face images to categories was obtained. Finally, the input probability of high-quality image category was taken as the image quality score, and the face image quality scoring mechanism was established. Experimental results show that compared with VGG-16 network, the precision rate of the proposed model is reduced by 0.21 percentage points, but the scale of the parameters is reduced by 98%, which greatly improves the efficiency of the model. At the same time, the proposed model has strong discriminant ability in aspects such as face blur, illumination, posture and occlusion. Therefore, the proposed model can be applied to real-time face recognition system to improve the accuracy of the system without affecting the efficiency.
Key words: face recognition; Convolutional Neural Network (CNN); image quality; quality evaluation; image quality evaluation; quality evaluation of face image
0 引言
近年來,伴隨著計算機視覺技術的飛速發展,人臉識別已經成為工業界和學術界研究的熱點。人臉識別即根據某種模式判斷物體或者物體的一部分是否滿足人臉結構,并依據其特征信息標識出其身份的過程,具體可分為:人臉檢測、特征提取和人臉檢索。人臉識別作為身份校驗的一種重要方式,在安全認證方面具有極其重要的意義。傳統的門禁卡、身份證等認證方式,極其不方便且容易被盜用,給人們的日常生活帶來許多麻煩。而人臉識別作為一種生物認證的手段,具有安全、可靠、簡單、友好等特點,備受人們的青睞;因此,人臉識別技術在機器學習、計算機視覺、模式識別等科研領域具有極其重要的研究意義[1]。
然而,隨著人臉識別系統的大范圍應用、場景環境的多樣性以及復雜性,監控系統抓取的同一個人的人臉圖像呈現的效果差別很大,比如圖像模糊、光照不均勻、非正臉等因素,這些因素導致人臉圖像的特征不明顯或者缺失,嚴重影響到人臉圖像識別的準確度。有研究指出,人臉識別的準確性不僅僅與識別算法的優劣有關,還與人臉圖像的質量高低有關[2-3]。因此,如何過濾掉低質量人臉圖像、保留高質量人臉圖像是目前人臉識別領域面臨的一個巨大挑戰。
目前,國際上公認的人臉圖像質量標準ISO/IEC 19794-5(International Organization for Standardization/International Electro technical Commission 19794-5)[4]和ICAO 9303(International Civil Aviation Organization 9303)[5],給用于證件照中的高質量人臉圖像提供了參考依據。基于這些標準,科研工作者提出了許多分析人臉圖像質量的方法,可以總結為兩類:一類是分析人臉圖像質量是如何影響檢測和識別的性能,一般通過在低質量圖像的測試來分析模型的健壯性;另一類研究是通過辨別低質量的圖像來克服實際場景中低質量圖像帶來的問題。Berrani和Garcia等[6]最早研究了人臉圖像質量問題,并采用了PCA(Principal Component Analysis)算法來移除低質量的人臉圖像。然而由于監控視頻場景中低質量的圖像占據多數,所以這種方法在監控視頻場景中無法得到好的效果。目前已知的大部分人臉圖像質量評價方法都是基于對人臉特殊屬性的分析,這也是最直接的方案。Yang等[7]使用一種樹形結構來對姿態進行估計,并把結果用來評估人臉質量。Gao等[8]利用人臉的不對稱性來量化人臉的非均勻光照和姿態。Sellahewa等[9]通過計算與一張特殊的標準參考圖像的差異來獲得人臉圖像質量分數。Wong等[10]使用了概率模型,通過訓練均勻光照、中性表情的正臉圖像來評估高質量的可能性,但是這種方法的效果取決于篩選的高質量人臉圖像。
雖然現有的人臉圖像的質量評價很多,但大多數方法都是通過分析其客觀因素,比如是否對稱、亮度是否均勻、是否有較高的對比度等,或是挑選一張標準圖像定義為“基準臉”,計算捕獲的人臉圖像與“基準臉”的差異來衡量人臉圖像的質量。這些方法主觀性較強,在復雜的環境中適應性較差。
自從Hinton等[11]于2006年發表論文提出深度學習的概念,并在2012年采用深度學習贏得了ImageNet圖像分類比賽的冠軍后,深度學習即成為了學術界的研究熱點之一。深度卷積神經網絡(Convolutional Neural Network, CNN)在圖像的分類方面表現出色,同時其提取的特征向量更具有表達性。因此本文提出了通過CNN來評估人臉圖像質量的方法,以此來解決人臉識別系統中圖像質量問題。
1 人臉質量評價模型
人臉圖像質量評價可以被看作一個二分類問題,人臉圖像被分為兩類:一類是高質量人臉圖像,另一類是低質量人臉圖像。通過模型來將輸入映射到質量標簽空間中,在人臉識別時首先判斷輸入人臉圖像的質量高低,將質量低的進行剔除,質量高的保留以進行后續處理。下面將對本文提出的人臉質量評價網絡模型進行詳細介紹。
1.1 網絡模型結構
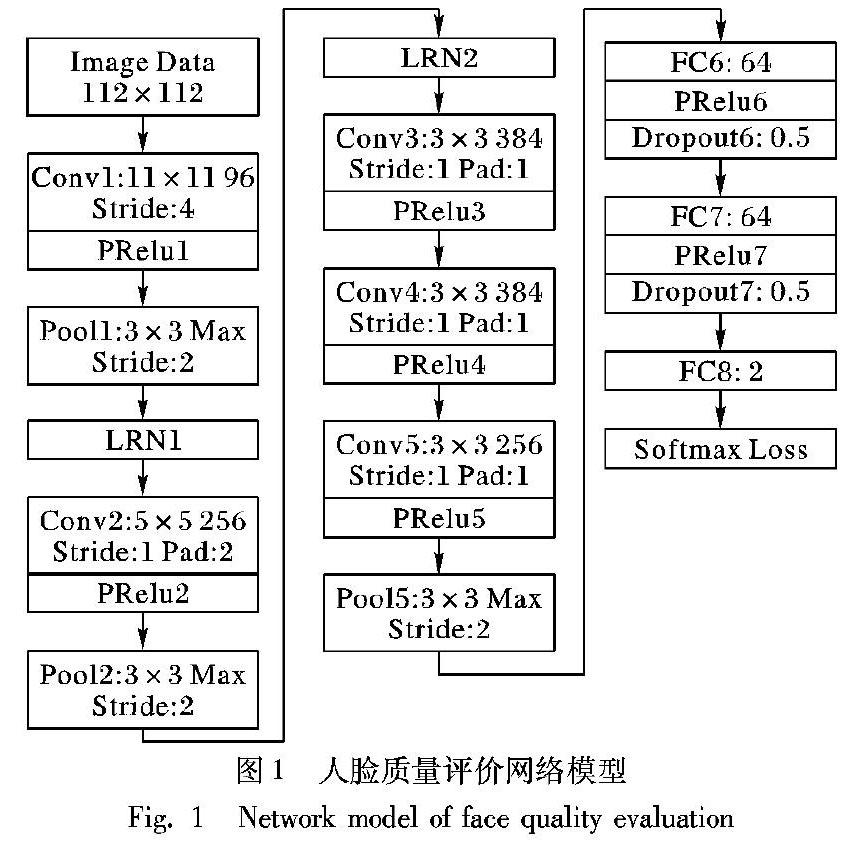
本文設計的人臉質量評價網絡模型是由5層卷積層(Convolution)、3層降采樣層(即池化層Pool)和3層全連接層(Fully Connected, FC)堆疊而成的深度CNN,其中還使用了PRelu(Parametric Rectified Linear Unit)激活層、LRN(Local Response Normalization)層和Dropout層等多種不同類型的結構,這些多種類型結構的組合共同擬合出從樣本空間到標簽空間的映射關系。人臉質量評價網絡模型如圖1所示。
從圖1可以看出,除了第3個、第4個卷積層(Conv)外,其他3個卷積層后都接著降采樣層(即池化層Pool)。網絡的輸入尺寸是112×112×3的三通道人臉圖像。
第1個卷積層(Conv1)使用96個11×11×3的卷積核對輸入進行卷積運算,移動步長為4個像素,因此輸出的特征圖尺寸為(112-11)/4+1=26個像素。由于有96個卷積核,所以最后會生成的特征圖的規模為26×26×96。這些特征圖先經過PRelu1激活函數操作后,再經過一個最大池化層Pool1的處理,池化核的尺寸為3×3,移動步長為2,則池化后圖像的寬高分別為(26-3)/2+1=13個像素,數量為96個。
第2個卷積層(Conv2)的輸入是13×13×96尺寸的特征圖,并在特征圖每個通道的周圍各填充2個像素,再通過256個5×5×96的卷積核處理,移動步長為1,輸出的特征圖尺寸為(13-5+2×2)/1+1=13,有256個。輸出的結果經過PRelu2激活后再經過一個最大池化層Pool2的處理,池化核的大小是3×3,移動步長是2,得到輸出的特征圖規模為6×6×256。
第3個卷積層(Conv3)使用3×3大小的卷積核,移動步長為1,該層同樣在輸入圖像每通道的周圍填充了一個像素,使得輸出的尺寸跟輸入一致。該層卷積核數量為384個,產生的輸出特征圖規模為6×6×384。
第4個卷積層(Conv4)的參數與第3個卷積層(Conv3)一樣,輸入是6×6×384的特征圖,經過填充和卷積運算,得到的輸出特征圖規模依然為6×6×384。
第5個卷積層(Conv5)使用的卷積核尺寸仍為3×3,數量為256個,移動步長為1個像素。對輸入特征圖各通道的上下左右填充一個像素后,經過卷積核的卷積運算,產生了6×6×256個特征圖。這些特征圖經過激活層PRelu5后,輸入到一個池化層Pool5。該池化層采用3×3大小的池化核,移動步長為2。最后的輸出特征圖為3×3×256。
第6層全連接層(FC6)的輸入尺寸為3×3×256,采用3×3×256尺寸的濾波器對輸入進行卷積運算,每個濾波器都會生成一個一維的運算結果。共有64個這樣規模的濾波器,所以最后的輸出為64維的向量,再通過PRelu6激活函數和Dropout6操作后,得到本層最后64維的輸出值。該層的參數總數為3×3×256×64=147456。
第7層全連接層(FC7)的神經元與第6層的輸出結果進行全連接,共有64個神經元,所以最后的輸出為64個數據。該層的參數總數為64×64=4096。
第8層全連接層(FC8)共輸出兩個值,與第7層全連接層(FC7)的所有神經元進行全連接,輸出網絡最終的訓練值。該層的參數總數為64×2=128。
最后的Softmax層是該網絡的終點,采用Softmax損失函數來計算訓練的結果與實際值之間的誤差,該誤差越小,表明網絡的分類效果越好。通過反向傳播算法不斷優化網絡參數,減小損失函數值,直到其收斂,即可得到最終的網絡模型參數。
1.2 數據準備及訓練
由于人臉質量評價沒有統一明確的定義,目前學術界還沒有一套公開標準的人臉圖像質量評價數據集可供選擇。其他許多公開的人臉數據集,比如:CASIA-WebFace(Institute of Automation, Chinese Academy of Sciences WebFace)[12]、LFW(Labeled Faces in the Wild)、FERET(Face Recognition Technology)[13]等,大多是在有約束的環境中采集的,圖像質量普遍偏高,導致高質量人臉圖像和低質量人臉圖像的比例分布不均,對模型的訓練有誤導作用。
本文實驗所使用的人臉數據集,是利用監控設備,在實際無約束條件下采集的。使用了FFmpeg(Fast Forward MPEG)抓取視頻流數據,通過MTCNN(Multi-Task Cascaded Convolutional Network)人臉檢測算法檢測視頻幀中人臉的位置,裁剪后將圖像數據保存在本地磁盤上。總共收集有效人臉圖像498459張。
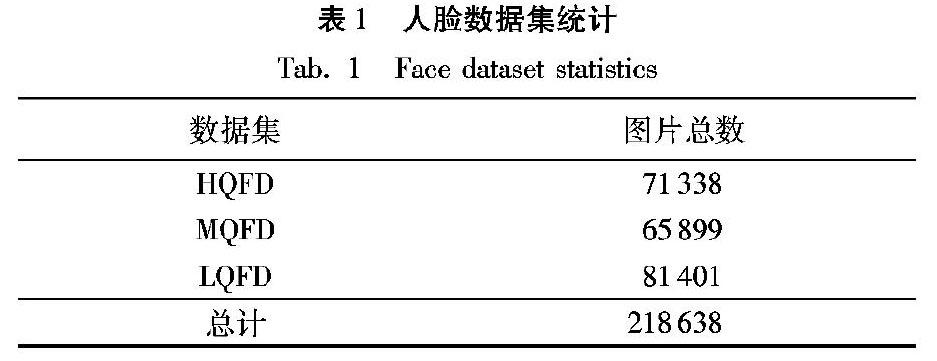
對這些人臉圖像,首先對人臉圖像的光照、模糊度、姿態進行計算,采用的方法分別為:通過圖像直方圖對光照均勻度進行判別,使用PnP(Perspective-n-Point)方法對人臉姿態進行估計,采用Brenner梯度函數對人臉模糊度進行分析;然后將這三種因素的得分歸一化后加權計算總得分,用總得分進行粗分類;最后人工篩選進行精細分類。這些人臉圖像共分為三類,一類是高質量人臉圖像數據集簡稱為(High Quality Face Dataset, HQFD),這類數據集中的人臉圖像具有面部清晰、五官分明、呈對稱分布,且光照均勻、無遮擋的特點;一類是低質量人臉圖像數據集簡稱為(Low Quality Face Dataset, LQFD),這類數據集中的人臉圖像的特點是模糊、側臉、光照分布不均或者遮擋嚴重;還有一類是介于高質量和低質量圖像之間,難以界定的數據集MQFD(Middle Quality Face Dataset),一般面部的輕微遮擋、表情夸張等屬于這類數據集。通過清洗篩選,最終得到的人臉圖像數量如表1所示。
為了使CNN提取人臉圖像具有辨識度的質量特征,更好地擬合人臉圖像到質量空間的映射關系,訓練模型時只選取HQFD和LQFD兩個數據集,其中令HQFD的樣本標簽為1,LQFD的樣本標簽為0。對HQFD和LQFD兩個數據集再進行劃分,分別劃分為訓練集、驗證集和測試集,比例為3∶1∶1。對數據集進行預處理,計算所有圖像像素的均值和標準差,然后將圖像的像素值減去均值后除以標準差作標準化處理;并且在模型訓練過程中,對輸入圖像進行鏡像操作,即圖像像素左右翻轉,這樣數據集規模將增大一倍。
2 實驗結果與分析
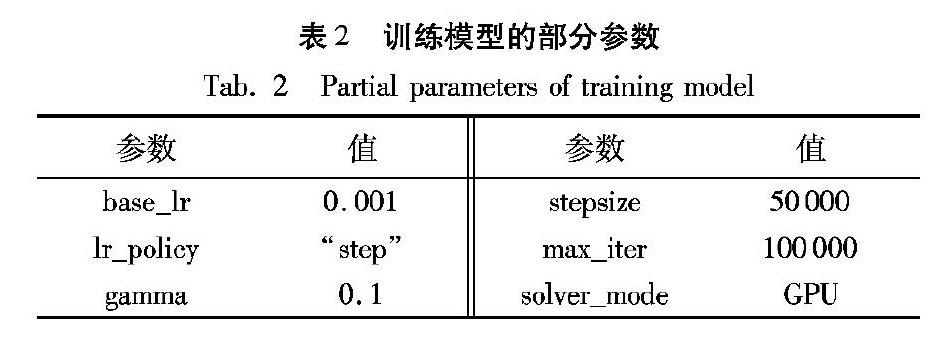
本文采用了深度學習框架Caffe進行模型的訓練和測試,運行環境是Ubuntu14.04,硬件平臺使用了GPU加速訓練,其型號是GeForce GTX TITAN X。模型的部分訓練參數如表2所示。
由于該訓練是個二分類問題,且數據特征的差異較明顯,所以在訓練時該模型的準確率很快就得到了巨大的提升,最后的測試準確率穩定在了99.41%。圖2、圖3分別展示了模型訓練損失和測試準確率隨迭代次數的變化關系。
從圖2、圖3中可以看出,隨著迭代次數的增加,模型很快達到了收斂,大約在迭代了15000次后,模型的測試準確率也達到了99%以上。當訓練完成后,模型的損失函數值處于穩定的收斂狀態,此時網絡的參數達到了最優。
模型訓練完成后,在測試數據集上進行測試。在低質量數據集上,正確分類的占比為99.1%,在高質量數據集上,測試的準確性為98.7%,整體的測試準確性達到了98.9%,如表3所示,說明模型在測試集上仍具有很好的分類效果。
由于Softmax的輸出表示輸入屬于每一類的概率值,屬于高質量一類的概率值越高,則輸入是高質量人臉圖像的可能性越大。本文使用屬于高質量一類的概率值作為對輸入圖像的質量評分。用打分方法對測試集人臉圖像進行打分,同時在通過電腦合成的兩張完美人臉上用本文提出的方法進行打分,打分的部分結果如圖4所示。
圖4說明了人臉遮擋、模糊、光照不均勻、姿態等因素較差時,得分也較低,而兩張完美人臉的得分都為1,屬于高質量人臉圖像。同時對打分結果進行統計分析,高質量的人臉圖像的得分大部分高于0.8,而在低質量測試集上,大約90%的圖像得分都低于0.1,說明模型在測試集上仍具有較好的表現。
為了驗證模型在人臉模糊、光照、姿態以及遮擋方面的性能,本實驗使用公開數據集Color FERET、FIIQD(Illumination Quality Assessment for Face Images DataSet)[14]和FDDB(Face Detection Data Set and Benchmark),分別驗證模型在人臉姿態、光照和遮擋上的表現性能,并取部分Color FERET數據集進行高斯模糊,來驗證模型在人臉模糊上的表現性能。實驗結果表明,模型對人臉圖像的模糊因素具有明顯的區分度,在模糊度高于一定值后,模型給出的評分急劇降低,越模糊的人臉圖像得到的評分越低,如圖5(a)所示。在光照方面,模型對光照不均勻、光線較暗的人臉圖像評分很低,對光線均勻的人臉圖像評分很高,說明模型在光照方面表現出優越的性能,如圖5(b)所示。在人臉姿態方面,對于偏轉小于45°的人臉,模型都評判為高質量,而偏轉角度過大的人臉都被評判為低質量,說明模型對人臉姿態也有很好強的適應性,如圖5(c)所示。在遮擋方面,對于少量遮擋,且能夠清晰辨別出五官的前提下,模型打分較高,對于遮擋住面部五官的少量遮擋或者大范圍遮擋的情況下,模型給出的得分較低,實驗結果如圖5(d)所示。
上述實驗表明:本文提出的用于人臉圖像質量評價的CNN模型,在人臉圖像模糊、光照、姿態和遮擋方面都表現較好,具有一定的判別能力;同時模型的參數較少,只有9.5MB,但是達到了較高的判別準確率,其前向傳播一次耗時為4.1ms,運算速度快,能夠實時響應,可用于人臉識別系統中人臉質量的實時評價。表4列出了數據集在不同網絡結構下的準確率等信息,可以看出,在準確率相差不大的情況下,該模型的參數規模比AlexNet(Alex Network)、VGG-16(Visual Geometry Group)、VGG-19分別降低了95.6%、98.1%、98.2%,運算效率得到極大的提高。
本文模型在實際應用中,可根據實際情況設定一個閾值,當評分高于該閾值時,判定是高質量人臉圖像,可進行后續步驟處理,否則判定是低質量人臉圖像,進行拋棄。
3 結語
本文針對人臉識別中的低質量圖像造成識別準確率低下的問題提出了解決方案。將人臉質量評價轉化為二分類問題,采用流行的CNN對訓練集進行學習,提取人臉圖像的深層質量特征,并加以分類。網絡模型在測試集上達到了98.9%的分類準確率。通過將人臉圖像屬于高質量一類的概率作為其質量評價,建立了人臉質量打分機制。最后實驗結果表明,模型對人臉圖像的模糊、光照、姿態和遮擋等因素造成的影響具有較強的判別能力,同時具有較高的運算效率。下一步工作是不斷提高模型的準確性和適應性。
參考文獻 (References)
[1] 徐曉艷.人臉識別技術綜述[J].電子測試,2015(5X):30-35.(XU X Y. Survey of face recognition technology [J]. Electronic Test, 2015(5X): 30-35.)
[2] DODGE S, KARAM L. Understanding how image quality affects deep neural networks [C]// Proceedings of the 2016 8th International Conference on Quality of Multimedia Experience. Piscataway, NJ: IEEE, 2016:11-16.
[3] KARAHAN S, YILDIRUM M K, KIRTAC K, et al. How image degradations affect deep CNN-based face recognition? [C]// Proceedings of the 2016 International Conference of the Biometrics Special Interest Group. Piscataway, NJ: IEEE, 2016: 22-29.
[4] ISO/IEC 19794-5, ANSI美國國家標準:Information technology-biometric data interchange formats-Part 5: face image data [S]. New York: American National Standard Institute (ANSI), 2001.
ISO/IEC 19794-5. Information technology-biometric data interchange formats—Part 5: face image data [S]. New York: American National Standard Institute (ANSI), 2001.
[5] ICAO 9303. International civil aviation organization: machine readable travel documents [S]. Canada[S. l.]: International Civil Aviation Organization, 2006.
[6] BERRANI S A, GARCIA C. Enhancing face recognition from video sequences using robust statistics [C]// Proceedings of the 2005 IEEE Conference on Advanced Video and Signal based Surveillance. Washington, DC: IEEE Computer Society, 2005: 324-329.
[7] YANG Z, AI H, WU B, et al. Face pose estimation and its application in video shot selection [C]// ICPR '04: Proceedings of the 17th International Conference on Pattern Recognition. Washington, DC: IEEE Computer Society, 2004, 1: 322-325.
[8] GAO X, LI S Z, LIU R, et al. Standardization of face image sample quality [C]// Proceedings of the 2007 International Conference on Biometrics, LNCS 4642. Berlin: Springer, 2007: 242-251.
[9] SELLAHEWA H, JASSIM S A. Image-quality-based adaptive face recognition [J]. IEEE Transactions on Instrumentation and Measurement, 2010, 59(4): 805-813.
[10] WONG Y K, CHEN S K, MAU S, et al. Patch-based probabilistic image quality assessment for face selection and improved video-based face recognition [C]// Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ: IEEE, 2011: 74-81.
[11] HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks [J]. Science, 2006, 313(5786): 504-507.
[12] YI D, LEI Z, LIAO S C, et al. Learning face representation from scratch [J]. Computer Science, 2014, 1(1): 1411-1438arXiv Preprint, 2014, 2014: arXiv.1411.7923.
[13] PHILLIPS P J, MOON H, RIZVI S A, et al. The FERET evaluation methodology for face-recognition algorithms [C]// Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition(CVPR), Piscataway, NJ: IEEE, 1997, 22(10):137-143.
PHILLIPS P J, MOON H, RIZVI S A, et al. The FERET evaluation methodology for face-recognition algorithms [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(10): 1090-1104.
[14] ZHANG L, ZHANG L, LI L. Illumination quality assessment for face images: a benchmark and a convolutional neural networks based model [C]// Proceedings of the 2017 International Conference on Neural Information Processing, LNCS 10636. Berlin: Springer, 2017: 583-593.
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
學生天地(2020年31期)2020-06-01 02:32:06
電子制作(2019年14期)2019-08-20 05:43:34
中國交通信息化(2018年1期)2018-06-06 07:29:55
電子制作(2017年17期)2017-12-18 06:40:55
中國公共安全(2017年7期)2017-10-13 08:18:26
電子制作(2017年1期)2017-05-17 03:54:46
中國公共安全(2017年9期)2017-02-06 03:05:32
現代工業經濟和信息化(2016年6期)2016-05-17 05:36:23
華東理工大學學報(自然科學版)(2015年2期)2015-11-07 09:16:51
