深度學習的發(fā)展以及應用
2019-07-25 08:03:28陳仲為
現(xiàn)代計算機 2019年17期
關鍵詞:深度
陳仲為
(武漢科技大學計算機科學與技術學院,武漢430070)
0 引言
近幾年隨著科技的迅猛發(fā)展,人工智能行業(yè)發(fā)展火熱,被越來越多的人所關注。因而科幻電影如雨后春筍般涌現(xiàn)出來,讓觀眾大飽眼福。現(xiàn)實生活中的人機大戰(zhàn)也為各大媒體爭相報道:2016 年3 月,AlphaGo以4:1 擊敗韓國圍棋天王李世石;2017 年5 月,加強版的AlphaGo 又以3:0 的完美戰(zhàn)績擊敗人類最強棋手柯潔。AlphaGo 能夠在如此短的時間內(nèi)變得這么強大的秘密在于深度學習算法。
深度學習隸屬于機器學習,是機器學習領域里一個相當重要的分支,了解機器學習的原理有助于我們更好的去了解深度學習。機器學習是人工智能領域當中的一個分支,當人們談及人工智能的時候,往往都繞不開機器學習。顯然,機器學習研究的是如何能夠讓機器像人一樣獨立自主地學習某種事物。簡單來說,就是通過算法,讓機器從大量的樣本數(shù)據(jù)中發(fā)現(xiàn)某種規(guī)律,然后來識別新的樣本或者對未來作出一定的預測。
1 機器學習的發(fā)展階段
第一階段,機器學習將研究的側重點放在非符號的神經(jīng)元模型上。主要的目標是研制出一個通用的學習系統(tǒng),即神經(jīng)網(wǎng)絡或自組織系統(tǒng)。
第二階段為20 世紀70 年代中期至80 年代后期,機器學習主要側重符號學習的研究,即以離散符號的推理為基礎,運用已有知識,來對未知作出預測。
第三階段從20 世紀80 年代后期開始一直到今天[1]。一方面,關于傳統(tǒng)符號學習的各種方法已經(jīng)全面發(fā)展并且趨近完善,應用的領域不斷擴大,達到一個鼎盛時期;同時由于發(fā)現(xiàn)用隱單元來計算和學習的非線性函數(shù)方法,從而克服了早期神經(jīng)元模型只能解決線性問題的局限性;計算機硬件的飛速發(fā)展和處理器運行速度的提高以及并行計算機的普及使得演化計算的研究突飛猛進,在機器學習的各個領域都取得了不錯的成果。連接學習和符號學習這兩個學派爭奇斗艷,顯示出各自的魅力。另一方面,越來越多的人開始重視對機器學習基礎理論的研究,從1988 年起,美、德、日等國連續(xù)召開計算學習理論的學術會議,相關的學術論文也經(jīng)常出現(xiàn)在關于機器學習的雜志上。因此,在這一階段,機器學習的研究進入了一個全面化、系統(tǒng)化的時期。
2 機器學習的分類
大體上來說,機器學習算法可以劃分為有監(jiān)督學習、無監(jiān)督學習和增強學習三種形式[2]。
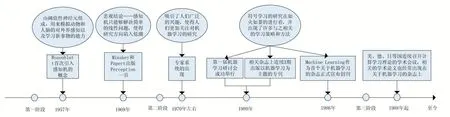
圖1 機器學習發(fā)展的時間軸
在有監(jiān)督學習中,訓練機器的目標是讓機器建立起從輸入到輸出一一對應的模型,訓練時,機器的每一次輸出都會與事先準備好的正確輸出進行比對并做出相應調(diào)整。例如,我們要訓練機器來識別各種水果的圖像,則需要使用大量已經(jīng)人工標注好的各種水果圖像來對機器進行訓練,得到一個模型,然后機器就可以用這個模型來對未知類型的水果進行識別判斷。
無監(jiān)督學習則沒有指導者進行指導,因此只有輸入數(shù)據(jù)過程而沒有輸出比對過程。訓練機器的目標是對輸入數(shù)據(jù)進行分析從而得到數(shù)據(jù)的某些知識,其典型代表是聚類。例如,我們要對1000 封電子郵件進行分類,我們并沒有事先定義好分類,也沒有已經(jīng)訓練好的模型。機器通過聚類算法自己完成對1000 封電子郵件的分類,保證同一類型郵件是同一個主題的,不同類型的郵件是不一樣的。
增強學習是一類比較特殊的機器學習算法。在一些應用中,機器需要輸出的是一個個動作所組成的序列而不是單個結果。排除在序列之外的某個動作并沒有什么意義,只有這些動作所組成的序列能夠完成給定的目標才是有意義的,即策略更加重要。所以機器在執(zhí)行的過程中也就不存在某個最好的動作。如果該動作最終能夠完成目標,即是某個策略的組成部分,那么該動作就是好的。在這種情況下,機器就應當能夠評估策略的好壞程度,并且從以前所學習到的好的動作序列中獲得提示,從而選擇成功率更高的策略來執(zhí)行。
3 人機大戰(zhàn)背后的算法
在人機大戰(zhàn)中大放異彩的AlphaGo 背后的算法便是深度學習算法。深度學習是機器學習領域的一個重要分支,因為在訓練機器時不需要人為進行指導,所以屬于無監(jiān)督學習。受到大腦神經(jīng)元結構的啟發(fā),深度學習算法通過構造一個人工神經(jīng)網(wǎng)絡來模仿人腦的神經(jīng)結構,并希望能夠像人腦一樣學習和處理相關事物。具體來說,該核心算法由兩種深度神經(jīng)網(wǎng)絡構成:“決策網(wǎng)絡”(Policy Network)和“價值網(wǎng)絡”(Value Network)。
“價值網(wǎng)絡”的作用是根據(jù)棋盤上白子和黑子的位置來作出評價,從而減少搜索的深度:AI 機器每走一步便會根據(jù)場上的局勢來推算出自己獲勝的概率,而不需要搜索所有結束棋局的路徑。當某些方法使得局面明顯不利于自己時,機器便會直接放棄這些路線,從而減少算法搜索的深度。
“決策網(wǎng)絡”的作用是預測下一步,來減少搜索的寬度:根據(jù)“價值網(wǎng)絡”的反饋信息,AI 機器不必給每一步相同的重視程度,主動放棄一些明顯的“壞棋步”而將注意力更多的放在那些有前景的“好棋步”上,將搜索范圍縮小至自己最有可能獲勝的那些棋步。
AlphaGo 利用這兩個工具來分析棋局,判斷每種下子策略的獲勝概率,從而選擇獲勝概率更高的棋步。除此之外,AlphaGo 還利用增強學習來讓AI 機器和自己對弈。通過和自己進行大量的對弈訓練,AlphaGo 能夠?qū)W會自己發(fā)現(xiàn)新的策略,從而提高“決策網(wǎng)絡”的效率。
4 深度學習算法的基本網(wǎng)絡框架
目前基于深度學習算法的網(wǎng)絡框架很多,但大抵都是基于以下四個基本網(wǎng)絡框架:無監(jiān)督預訓練網(wǎng)絡、卷積神經(jīng)網(wǎng)絡、循環(huán)神經(jīng)網(wǎng)絡和遞歸神經(jīng)網(wǎng)絡。
無監(jiān)督預訓練網(wǎng)絡[3]:使用無監(jiān)督學習算法來訓練深度神經(jīng)網(wǎng)絡,即先訓練網(wǎng)絡的第一個隱藏層而封鎖其他的隱藏層,之后再訓練第二個隱藏層……以此類推直到最后一層,然后將訓練時獲得的網(wǎng)絡參數(shù)值作為整個神經(jīng)網(wǎng)絡的初始參數(shù)值參與到之后的訓練當中。
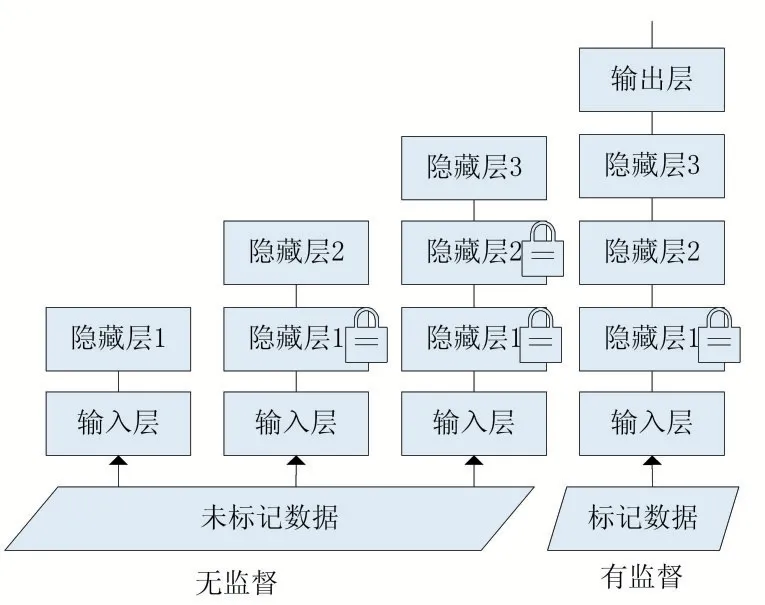
圖2 無監(jiān)督預訓練網(wǎng)絡
卷積神經(jīng)網(wǎng)絡:該深度神經(jīng)網(wǎng)絡主要是用來識別二維圖像[4]。第一個隱藏層通過卷積運算,將原本的像素點壓縮后存儲;第二個隱藏層對前面的數(shù)據(jù)進行子抽樣,提取數(shù)據(jù)特征,然后根據(jù)共享權值來進行局部平均……兩個相鄰的隱藏層之間不斷重復進行著卷積和抽樣的操作,一步步地將處理后的結果往更高一層傳遞,直至輸出層將結果進行輸出。
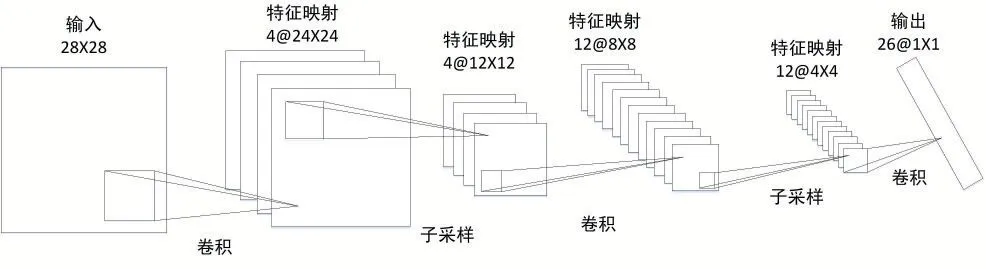
圖3 卷積神經(jīng)網(wǎng)絡中卷積和子采樣過程
循環(huán)神經(jīng)網(wǎng)絡[5]:主要是為了識別序列(如語音或者文本)而在時間上進行拓展的多層感知機。在卷積神經(jīng)網(wǎng)絡之中,每個元素之間是相互獨立互不干擾的,輸入和輸出自然也是獨立的。而在該網(wǎng)絡中,每一個單元結構都可以重復使用,能夠像人一樣擁有短暫的記憶功能,所以它的輸出依賴于當前的輸入和之前的記憶。
遞歸神經(jīng)網(wǎng)絡[6]:與分層網(wǎng)絡的原理很相似。該網(wǎng)絡能夠把長短不一的輸入序列劃分為一個個長度相等的數(shù)據(jù)塊,然后再將這些數(shù)據(jù)塊按順序輸入到樹狀網(wǎng)絡中進行分層處理,從而使得解決變長輸入問題成為可能。在該網(wǎng)絡中,每一個語義樹的結構信息被預先編碼為一個向量,與向量空間里的某一個點一一對應。如果兩個語義樹意思相近,那么對應的向量之間的距離也比較近;反之,如果兩個語義樹意思完全不同,那么對應的向量之間的距離也會很遠。例如圖5中的Monday 和Tuesday 距離較近,而與代表國家的France 距離很遠。
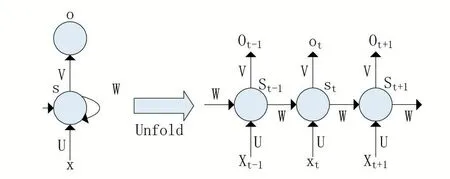
圖4 循環(huán)神經(jīng)網(wǎng)絡的大致結構
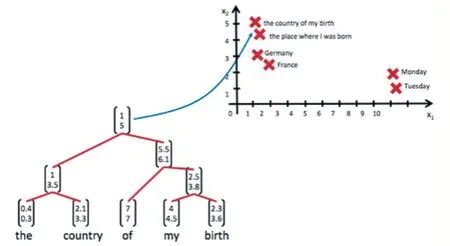
圖5 遞歸神經(jīng)網(wǎng)絡中語義向量與向量空間
5 深度學習算法的應用[7]
深度學習算法被廣泛運用于各行各業(yè)之中,在這其中以語音識別、圖像識別和自然語言處理三個方面為主,取得了不少矚目的成果。
語音識別[8]:將聲信號輸入到電腦中,通過數(shù)字采樣轉(zhuǎn)化為易處理的電信號,然后將電信號輸入到深度神經(jīng)網(wǎng)絡中進一步處理。由于每個人發(fā)音的長短不一樣,因此電信號所對應的英文字母可能會有所重復,這時候就需要刪除多余的字母。這樣處理完畢之后便可以得到一個單詞,因為存在連讀以及某些字母讀音相同現(xiàn)象,單詞會出現(xiàn)錯誤,這時再與基于書面文本(書籍、新聞等)的大數(shù)據(jù)庫進行比對,找出最有可能的結果作為最終結果進行輸出。
圖像識別[9]:通過多層次的卷積神經(jīng)網(wǎng)絡來處理和識別輸入的圖片信息。最低層從原始像素開始卷積,描繪出局部的邊緣和紋理特征,如直線或者曲線等;中間層將上一層的信息進行整合加工,抽象到更高層次,如某種形狀;最高層描繪的是整個圖片的整體特征。如此反復,機器最終可以學會如何識別該物體。而在整個過程中,機器完全是自主學習,圖片中的某些特征是機器自己去尋找發(fā)現(xiàn)的,無須人為干預。
自然語言處理[10]:能夠使用自然語言和計算機進行交流是人們長期追求的目標,這就要求計算機能夠識別和理解輸入的自然語言信息,也能夠使用自然語言來給予相應的反饋。機器通過算法使用一個低維稠密的向量來表示一個詞語(詞嵌入),讓這些詞向量代替原來的詞語的特征,便于識別和處理。然后通過另外的算法,將這些詞向量進行語義組合,來獲得短語和句子的概念,從而使機器能夠理解自然語言。
6 結語
總的來說,深度學習的出現(xiàn)將機器學習的地位提升到一個全新的高度,受到各界人士的廣泛關注,也帶動了其他領域的技術革命。深度學習的快速發(fā)展既得益于計算機計算能力的飛速提升,也離不開過去理論和算法的貢獻。雖然存在一些局限性,如需要大量數(shù)據(jù)訓練、良好的底層硬件支持、訓練時間長等,但是它對非線性問題的處理能力和強大的自我學習能力是其他算法所不能比擬的。筆者相信,隨著算法理論的進一步發(fā)展和計算成本的大幅度降低,深度學習必將在更多的領域里大展拳腳。深度學習,未來可期!
猜你喜歡
中學生數(shù)理化·七年級數(shù)學人教版(2022年6期)2022-06-05 06:50:50
快樂學習報·教育周刊(2022年16期)2022-05-01 21:25:05
中學生數(shù)理化·七年級數(shù)學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
新聞傳播(2016年10期)2016-09-26 12:14:59
新聞傳播(2015年10期)2015-07-18 11:05:40
交通建設與管理(2015年15期)2015-03-20 15:18:57
