江蘇大學圖書推薦系統讓學生借書“不迷路”
2019-07-19 09:35:32吳云龍
中國教育網絡 2019年6期
文/吳云龍
高校圖書館圖書推薦現狀
隨著社會的發展,國內高校之間百舸爭流,圖書館作為高校的文化載體,也發生了巨大的變化,主要體現在館藏量和服務方式上。在如今這個信息爆炸的時代,高校圖書館作為學生獲取知識的主要來源,自然圖書藏量也飛速遞增,甚至出現了信息過載的情況[1]。對于學生來說,可以在如此多的圖書中獲取多方面的知識,本身是一件令人興奮的事。但如何尋找感興趣或者想要的書籍,對于學生和圖書館來說,都是一個亟需解決的問題。
傳統的高校圖書館系統提供基于圖書信息檢索的方式,學生根據想要尋找的圖書名或者作者姓名等信息進行檢索,從大量的圖書中找到對應的書籍。這種方式,針對明確知道圖書信息的學生來說,尚能夠解決問題,但更常見的情況是學生面對如此大量的書籍,不知道哪本書適合自己目前的階段,不知道什么書能提高自己的成績。那如何將圖書館中的書籍推薦給適合它的學生,或者為學生找到有助他的書籍成為了圖書館書目推薦的本質目的。
目前在高校圖書館中較流行的圖書推薦大致分為兩種。一種是基于圖書相似度的推薦,根據圖書的借閱歷史記錄,為學生推薦其感興趣的相似的圖書;第二種是根據學生基本信息和行為,挖掘出具有相同特征信息的學生,從而推薦互相的感興趣的書目。
系統需求分析
目前圖書推薦存在的問題
當前高校常見的圖書推薦,很大程度上與電子商務領域的推薦系統類似,這種模式的推薦不一定適合高校這樣的特殊環境,繼而推薦效果上可能大打折扣;其次因為數據源較多、推薦算法復雜和數據量龐大等問題,在推薦系統的可行性上也存在疑問。比如基于圖書相似度的推薦,由于高校圖書館藏書量大,并且每年會采購新的書籍,在計算圖書相似度上會建立一個龐大的矩陣,導致推薦成本變大;另外將相似的圖書推薦給學生,也不一定是學生滿意的書目。再比如基于學生行為的推薦,傳統的基于行為的推薦是分析學生的日常生活軌跡數據,得到興趣愛好相同的學生,從而進行圖書的推薦。學生的行為數據源多且數據量大,增大了數據分析的難度;而且興趣愛好相同的學生在課程和學業上所需要的書籍也不一定是相同的。
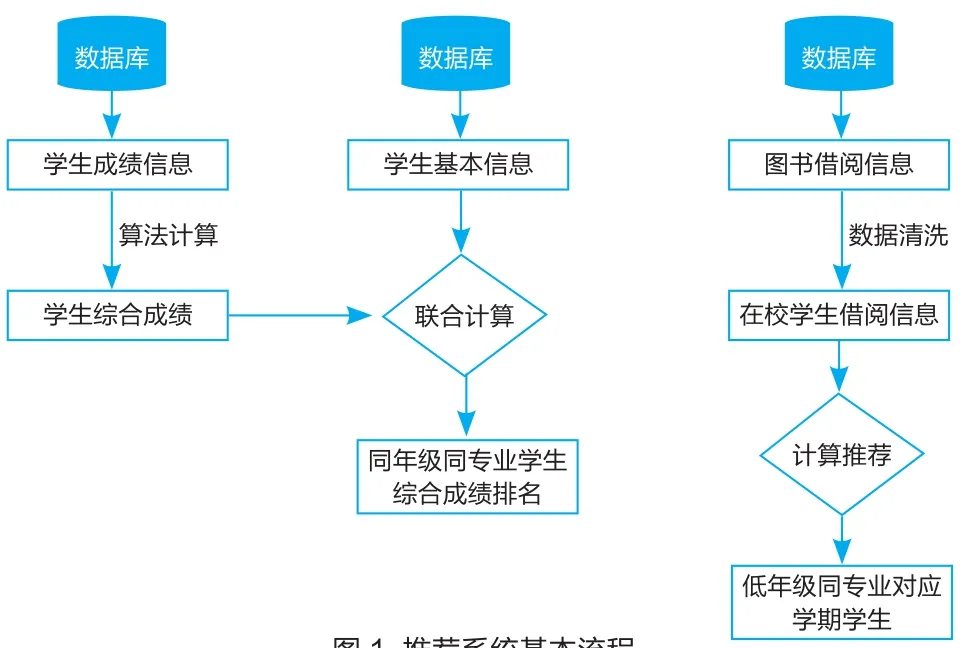
圖1 推薦系統基本流程
推薦系統架構
本系統結合高校的特點和學生的需求,并結合學生成績數據、學生基本信息數據和圖書館借閱數據,利用分布式文件系統HDFS和大數據計算引擎Spark進行計算,將專業綜合成績優秀學生的借閱書目,推薦給相同專業低年級同時期的學生。本推薦系統的基本業務流程如圖1所示。
整個系統的流程主要由三塊構成,第一是從數據庫中獲取某學期的學生成績信息,清洗后用自定義的算法計算出每個學生當前學期的綜合成績;第二是從數據庫中抽取學生的基本信息,然后聯合第一步中的成績數據,計算出同年級同專業學生的綜合成績排名情況;第三從數據庫中清洗出在校學生的圖書借閱歷史數據,聯合第二步中的成績排名數據,將當前學期優秀學生的借閱圖書,推薦給低年級同專業的學生。
推薦方法過程
計算工具介紹
本文提出的圖書推薦方法涉及到多個數據源,特別是學生成績數據和圖書借閱歷史數據,隨著高校的不斷發展和圖書館規模的不斷擴大,這兩項數據量也越來越大。特別是處理過程中還涉及到多次多種數據源之間的聯接操作,傳統的數據計算框架會遇到一定的挑戰。

圖2 Spark運行流程
Hadoop的Mapreduce是一種并行處理大數據的計算框架,它的核心思想是采用分而治之的策略,其中Map將要處理的任務分成很多子任務,交給各個不同的進程進行計算;最后的計算結果由Reduce進行統計[2]。但是因為Mapreduce的計算過程中采用的是多進程模型,這樣會導致在反復迭代計算的任務中花費太多時間在啟動進程上,同樣在執行中需要內存和磁盤不斷進行數據交互,也很大程度上影響計算性能。
Spark誕生于伯克利大學的AMPLab,起初是該大學的一個研究項目,后被正式開源并成為Apache的頂級項目[3]。Spark與Mapreduce相同,也是作為近年常用的大數據計算框架;不同的是Spark采用分布式內存計算和彈性分布式數據集RDD[4](如圖2所示),將計算中需要重復使用的數據緩存在內存中,使大規模數據的處理速度和容錯率相較Mapreduce提升了很多。
學生綜合成績計算
數據庫中存放的學生成績信息包含有14個字段,包括XH(學號),XM(姓名),XN(學年),XQ(學期),KCDM(課程代碼),KCMC(課程名稱),KCXZ(課程性質),KCGS(課程概述),XF(學分),CJ(成績),BKCJ(補考成績),CXCJ(重修成績),BZ(備注),CXBJ(重修標記)。從成績字段信息可以發現,計算學生一學期的綜合成績,將會面臨以下問題:學生的成績因為課程性質分為必修課和選修課,不同課程性質的要求可能不一樣;有些課程的成績是等級制,很難做到量化;不同課程可能對應不同的學分;有些學生的課程可能存在補考或者重修現象,那同一門課程可能有兩個分數等等。
針對以上問題,首先將課程成績和等級成績量化成具體分數,具體量化方式為:優秀=90,良好=80,中等=70,及格=60,不及格=40;然后根據不同課程性質劃分權重(必修課權重為1.0;選修課權重為0.8),結合學分計算每門課程的最終成績。計算方法為:
最終成績 = 課程權重 ×學分 × 原始成績
計算得到每個學生每門課程的最終成績,接下來根據學號和課程代碼為鍵,找到有多個成績的課程即補考或重修的課程,取最大分數為當前學生該課程分數。最后以學號為鍵,調用groupByKey后將該學生所有成績進行求和計算,則得到了該學生在當前學期的綜合成績。
同專業學生成績排名
通過對教務成績數據計算得到學生一學期的綜合成績,接下來將結合學生基本信息數據,得到同專業學生綜合成績排名。學生的基本信息存在bzks表中,該表有69個字段,截取其中以下字段:XM(姓名),XBDM(性別代碼),YXDM(院系代碼),XZNJ(現在年級),XZZYDM(現在專業代碼)。學生基本信息數據和成績數據進行join操作,然后以現在年級和現在專業代碼作為聯合鍵,將同級同專業的學生數據聚集后,利用spark對相同鍵的學生成績進行降序排序。
優秀學生借閱推薦
圖書借閱信息中包含了全部的借閱信息,數據量較大,首先需要過濾掉已經畢業學生和非學生的借閱信息。然后結合上述已經計算得到的同級同專業學生一學期綜合成績排名數據,選取排名靠前的優秀學生(可配置,本文選取各個專業成績排名前15),得到這些優秀學生在當前學期的圖書借閱信息。接下來對這些優秀學生的圖書借閱信息進行分析,統計借閱次數降序排序和借閱時長降序排序。最后選取借閱次數超過兩次的書籍,如果該數量超過15,則選前15的書目;如果該數量未超過,則按借閱時長排名自前往后篩選補充至15本。最后我們將這15本書目做為往屆優秀學生的借閱書目,推薦給對應低一級同專業且對應學期的學生。
綜上所述,本文結合高校學生的基本數據、教務數據和圖書借閱歷史數據,分析得到每個專業綜合成績優異學生借閱的書籍;再將這些書籍經過一定的分析統計后推薦給對應借閱學期和同專業的低年級學生。這樣的圖書推薦方式不同于目前主流的應用于電子商務領域的推薦,更加符合高校學生的需求,推薦的指向性和目的性也更加明確[5]。但是也存在一定的缺點,比如可能會因為優秀學生借閱的局限性而錯過一些優秀書籍;也可能因為優秀學生借閱的一些興趣類的書籍而因此做了低質量的推薦。當然基于高校圖書館的圖書推薦因為面向群體的針對性,將會是一個長期值得研究和優化的課題,希望能通過本文為此提供一定的參考價值。
猜你喜歡
內蒙古教育(2021年20期)2021-03-08 01:09:14
計算機教育(2020年5期)2020-07-24 08:53:38
家庭影院技術(2019年11期)2019-12-09 09:14:30
小太陽畫報(2018年1期)2018-05-14 17:19:25
中華手工(2017年2期)2017-06-06 23:00:31
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
中外會展(2014年4期)2014-11-27 07:46:46
小天使·一年級語數英綜合(2014年8期)2014-06-26 14:42:04
祝您健康(1987年3期)1987-12-30 09:52:32
