MEPaxos:低延遲的共識算法*
2019-07-18 01:07:50趙守月葛洪偉
計算機與生活 2019年5期
關鍵詞:系統
趙守月,葛洪偉+
1.輕工過程先進控制教育部重點實驗室(江南大學),江蘇 無錫 214122
2.江南大學 物聯網工程學院,江蘇 無錫 214122
1 引言
分布式計算中的一個基本問題是在故障存在的情況下,依然能實現整體系統的可靠性[1]。這通常需要分布式系統中各個節點(副本)對處理過程中某一數值達成一致,即取得共識。共識問題是許多商業分布式系統[2-6]的核心。然而現實世界中,由于各種故障(進程故障、通信鏈路故障等)的存在,解決共識問題十分困難[7]。
FLP不可能定理[8]指出:在存在故障(即使只有一個進程故障)的異步系統中,不存在用于解決共識問題的確定性算法。這說明,解決共識問題的算法必須在安全性(safety)和靈活性(liveness)之間取舍。其中,確保安全性算法中影響最深遠的是Lamport提出的 Multi-Paxos(multi-decree Paxos)算法[9-10]。
Multi-Paxos致力于解決異步分布式系統[11]中非拜占庭故障[12]的共識問題。Multi-Paxos依賴單個領導者處理并發客戶端發送的命令,但在廣域網環境下的分布式系統中,單領導者的設置給客戶端和系統交互帶來了更大的延遲(和領導者不在同一局域網的客戶端需要更多的時間和領導者通信)。同時,領導者易成為整個系統的性能瓶頸。
針對上述單領導者的缺陷,許多Multi-Paxos算法變種被提出。Fast Paxos[13]允許客戶端將命令發送給所有副本,但在并發命令的情況下,會產生沖突(collision),造成延遲性能顯著下降。Generalized Paxos[14]可以按任意順序執行可交換的命令,但對于不可交換的命令,延遲性能顯著下降。Mencius[15]通過每個副本輪流當領導者的方式均衡負載,但延遲性能易受到單個較慢副本和客戶端負載不均衡的影響。S-Paxos(scalable Paxos)[16]中副本對客戶端發送的命令批處理之后發送給領導者,減輕了領導者的壓力,但在廣域網環境下,領導者依然是性能瓶頸。EPaxos(egalitarian Paxos)[17]允許客戶端將命令發送至任意副本(通常是距客戶端最近的副本),但延遲性能易受命令沖突的影響。
以上算法在某種程度上較Multi-Paxos降低了客戶端感知到的延遲,但在負載不均衡、命令沖突增大等情況下,延遲性能會變差。本文基于低延遲的設計目標,結合EPaxos和Multi-Paxos,提出了共識算法MEPaxos(modified egalitarian Paxos)。MEPaxos 綜合考慮客戶端的負載情況、并發客戶端的命令沖突情況以及網絡的實時情況提出了系統平均延遲的計算方法;接著引入超時機制對二階段提交算法進行改進;最后根據系統平均延遲計算公式,利用改進的二階段提交算法自動進行算法轉換,以獲取最優的延遲性能。
2 相關工作
2.1 Multi-Paxos算法
Multi-Paxos將客戶端發送的命令復制到2F+1(F為能忍受的最大故障數)個副本來確保安全性,即:在F+1個(稱為法定人數)副本無故障的情況下,Multi-Paxos能確保安全性。算法具體過程如圖1所示。客戶端將命令C發送給單個領導者,領導者和所有副本(稱之為接受者)進行一輪信息交流(圖1中Prepare階段,每個領導者只執行一輪Prepare消息),確保接受者不再響應之前的命令。若收到法定人數接受者的回復,領導者和接受者再進行一輪信息交流(圖1中Accept階段),請求接受者復制C。若領導者收到法定人數接受者的回復,確認C被成功提交,發送確認消息給客戶端和所有副本(稱之為學習者),學習者本地提交C。
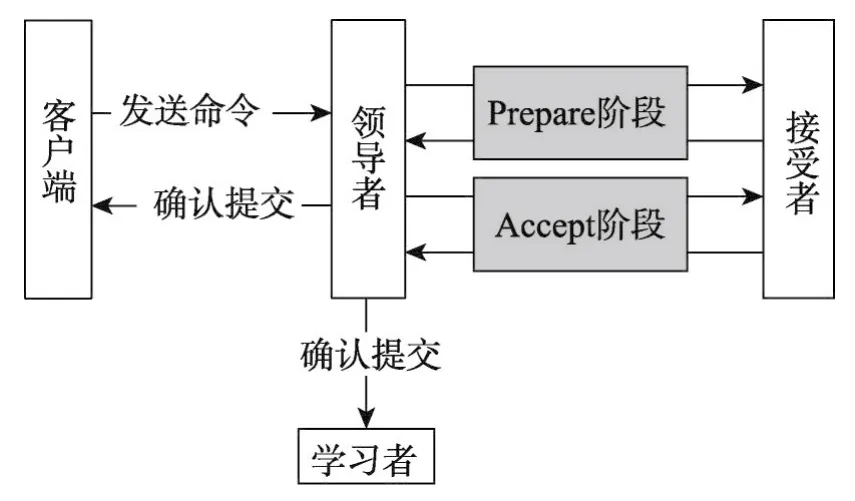
Fig.1 Multi-Paxos process圖1 Multi-Paxos處理過程
2.2 EPaxos算法
EPaxos是近年業內最認可,廣域網環境下延遲性能綜合最好的Multi-Paxos算法變種。和Multi-Paxos類似,EPaxos將客戶端命令復制到2F+1個副本上確保安全性。算法具體過程如圖2所示。通常情況下,客戶端將命令C發送給最近的副本(稱該副本為C的領導者)。C的領導者和所有副本進行一輪消息交流(圖2中Fast path階段)。期間,C的領導者將C和本地與C相關的命令集合一起發送,副本回復時包含本地與C相關的命令集合。若C的領導者收到個(稱為Fast path階段法定人數)相同的回復,發送確認消息給客戶端和所有副本,所有副本本地提交C。否則,C的領導者和所有副本再進行一輪消息交流(圖2中Slow path階段)。若C的領導者收到F+1個(稱為Slow path階段法定人數)副本的回復,發送確認消息給客戶端和所有副本,所有副本本地提交命令C。
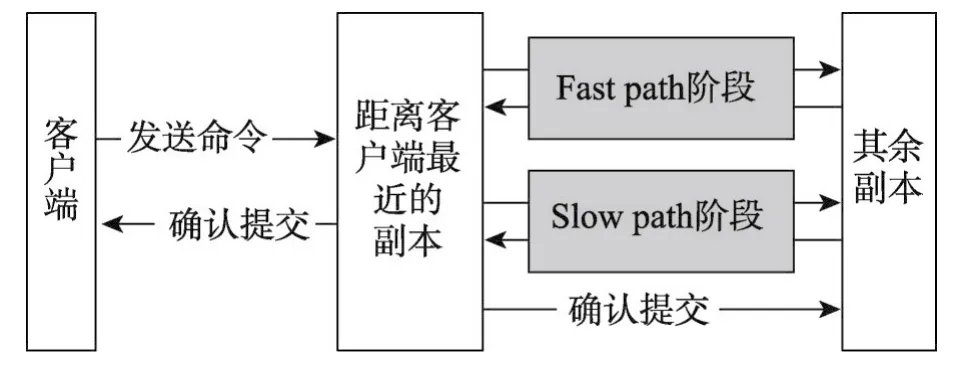
Fig.2 EPaxos process圖2 EPaxos處理過程
2.3 Multi-Paxos和EPaxos對比分析
由于Multi-Paxos中每個領導者只執行一輪Prepare消息,可忽略不計,故客戶端發送命令到收到回復大概需要經過4次消息交流(圖1中發送命令,Accept階段,確認提交);對于EPaxos,若Fast path階段領導者收到法定人數副本相同的回復,則客戶端發送命令到收到回復只需經過4次消息交流(圖2中發送命令,Fast path階段,確認提交);否則,還需進行一輪Slow path,需要6次信息交流。
EPaxos客戶端將命令發送給最近的副本,而Multi-Paxos客戶端將命令發送給指定的領導者,因此,EPaxos在4次消息交流提交命令的情況下,延遲性能優于Multi-Paxos。而EPaxos在6次消息交流提交命令的情況下,延遲性能通常劣于Multi-Paxos。
3 MEPaxos算法
MEPaxos適用于非拜占庭故障下的異步分布式系統,是一種低延遲的共識算法。觀察到EPaxos存在需要多執行一輪Slow path才可提交命令,延遲增加的情況,MEPaxos將EPaxos與Multi-Paxos結合。首先,MEPaxos提出了系統平均延遲的計算方法,并對二階段提交算法進行改進。接著,每隔時間段t,計算EPaxos和Multi-Paxos系統平均延遲。根據計算結果,利用改進的二階段提交算法自動轉換到系統平均延遲較小的算法模式,以獲得最優的延遲性能。
3.1 命令沖突
為了方便描述EPaxos需要執行一輪Slow path才可提交命令,延遲增加的情況,本文提出命令沖突的概念。
定義(命令沖突)如果q個相關命令(command interference)[17]a1,a2,…,aq同時被提出,且 EPaxos在處理命令ai(i∈[1,q])時,受到其余相關命令ak1,ak2,…,akn(k1,k2,…,kn∈[1,q])的影響,多執行一輪Slow path才可提交,那么說命令ai和命令ak1,ak2,…,akn是沖突的。
由命令沖突的定義和EPaxos處理步驟[17]可知,EPaxos中,并發客戶端向同一副本提交相關命令,命令之間不會產生沖突。只有不同副本處理相關命令時,命令之間才可能產生沖突。不同副本處的并發客戶端提出具有相關性的命令越多,命令沖突也就越多。本文通過系統平均延遲的計算,利用轉換算法自動對不同命令沖突下的情況做出反應,以取得更優的延遲性能。
3.2 系統平均延遲
MEPaxos設計的主要目標是最小化客戶端感知到的延遲(本文所指的延遲均為提交延遲[17]),給客戶端帶來更好的用戶體驗。本節考慮整個系統響應客戶端的平均延遲,提出系統平均延遲的計算方法。
在MEPaxos中,共有N個副本(N=2F+1,其中F是能容忍的副本最大故障數)。用Ri表示第i個副本 (i∈[1,N]);tri表示從Rr到Ri所需時間;副本tci表示消息從客戶端到Ri所需的時間。由于客戶端和最近的副本進行交流,因此和同一副本進行交流的客戶端到該副本所需的時間大致相同,這里不進行區分。
系統平均延遲的計算,主要考慮三個因素:
(1)算法運行過程中客戶端的負載情況,可用算法運行過程中副本處理客戶端提交的命令數表示。
(2)算法運行過程中并發客戶端的命令沖突情況,可用副本作為領導者執行Slow path的命令數表示。
(3)算法運行過程中網絡的實時情況,可用客戶端與副本以及副本與副本之間消息傳輸所需時間表示。
故EPaxos模式下,系統平均延遲ELat可表示為:
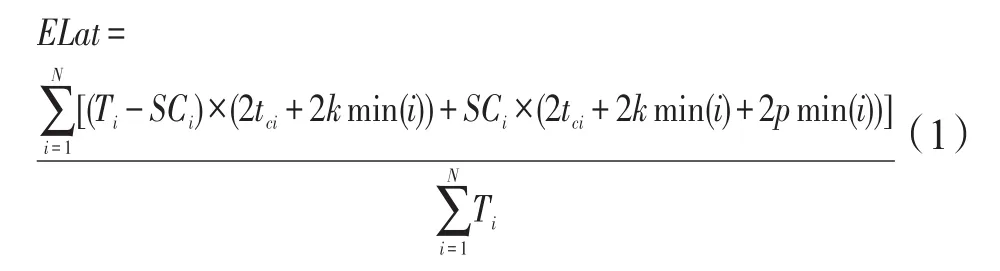
其中,Ti表示Ri處理客戶端提交的命令總數;SCi表示Ri作為領導者執行Slow path的命令數;kmin(i)表示對于r∈[1,N],第k小的tri,其中k表示Fast path中的法定人數;pmin(i)表示對于r∈[1,N],第p小的tri,其中p表示Slow path中的法定人數。以上數據每隔時間段t統計得出。
Multi-Paxos模式下,系統平均延遲MLat可表示為:
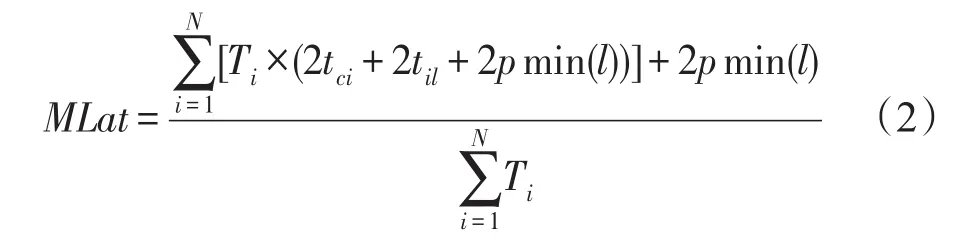
其中,Ti表示Ri處理客戶端提交的命令總數;til表示從副本Ri到領導者Rl的時間;pmin(l)表示對于r∈[1,N],第p小的trl(EPaxos中Slow path的法定人數和Multi-Paxos中法定人數相同)。以上數據每隔時間段t統計得出。
3.3 轉換算法
MEPaxos在二階段提交算法的基礎上引入超時機制,提出了EPaxos和Multi-Paxos之間的轉換算法,具體步驟如下:
(1)算法轉換的發起者RI給各個副本Ri(i∈[1,N])發送更改算法的通知并設置超時時間TO。
(2)副本Ri確認收到通知,發送確認消息以及本地信息LMi給RI,進入轉化狀態(副本在轉化狀態時不會分配新實例,即:對于收到的客戶端命令,放入緩存,在非轉化狀態時再進行處理),同樣設置超時時間TO。
(3)若RI在TO到達之前收到所有副本的確認消息以及本地信息LMi,則對LMi進行統計,統計結果記為CLM={LMi|i∈[1,N]},發送CLM以及算法轉換的執行命令給所有副本;否則,發送算法轉換的取消命令給所有副本。
(4)若副本Ri在TO到達之前收到CLM以及算法轉換的執行命令,根據CLM執行相關命令RCOM。之后跳出轉化狀態,進入要轉換的算法模式。否則,副本Ri跳出轉化狀態,返回之前算法模式(副本在一種算法模式下,不會響應另一種算法模式下的任何消息)。
其中,LMi和RCOM根據MEPaxos轉換模式的不同,也有所不同,具體如表1所示。
3.4 MEPaxos算法步驟
MEPaxos詳細步驟如下:
(1)MEPaxos進入EPaxos算法模式,處理客戶端提交的命令。

Table 1 DifferentLMiandRCOMunder different change modes表1 LMi和RCOM在不同轉換模式下的選取
(2)每隔時間段t,對式(1)所需數據進行統計,計算出ELat,并估計MLat。估計方法如下:
(2.1)假設Ri(i∈[1,N])為領導者,根據式(2)計算出系統平均延遲RMLati;
(2.2)取MLat=min({RMLati|i∈[1,N]}),領導者為此時的Ri。
(3)若MLat<ELat,執行轉換算法,MEPaxos進入Multi-Paxos算法模式處理客戶端提交的命令,轉至步驟(4)執行;否則,轉至步驟(2)繼續執行。
(4)每隔時間段t,對式(2)所需數據進行統計,計算出MLat,并估計ELat。估計方法如下:
(4.1)統計時間段t內Ri(i∈[1,N])處理客戶端提交的命令中對關鍵字Km(m∈[1,M],M表示關鍵字總數)操作的命令數CKim;
(4.2)則Ri處理的對關鍵字為Km操作的命令中執行Slow path的命令數SCim為:
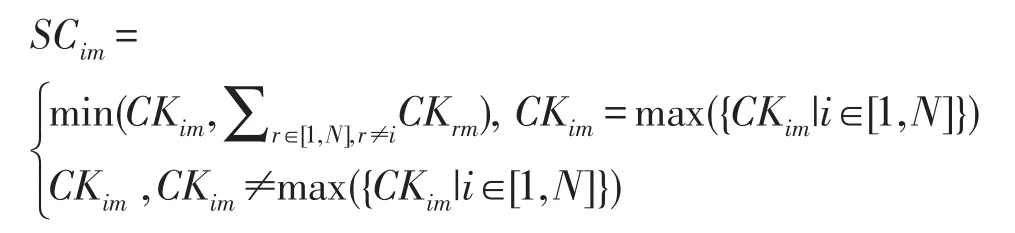
(4.3)時間段t內Ri執行Slow path的命令總數;
(4.4)根據統計的數據以及SCi,按照式(1)算出ELat。
(5)若ELat≤MLat,執行轉換算法,MEPaxos進入EPaxos算法模式處理客戶端提交的命令,轉至步驟(2)執行;否則,轉至步驟(4)繼續執行。
3.5 MEPaxos性能分析
由MEPaxos算法步驟可知,為實現最優化延遲性能的目標,MEPaxos主要進行了以下改進:
(1)算法運行過程中進行系統平均延遲的計算。
(2)根據改進(1)計算結果,利用轉換算法轉換至系統平均延遲較小的算法模式。
在共識算法實際應用中,副本之間通常需要定期發送心跳信息進行交流[18]。計算系統平均延遲所需數據可附帶在心跳信息中一起發送,所需計算資源對整個系統來說可忽略不計,因此改進(1)只需少量可忽略不計的計算資源。
轉換算法的引入,使MEPaxos可轉換至系統平均延遲較小的算法模式。雖增加了算法的處理過程,但轉換后系統的延遲性能更優。
MEPaxos做出了增加少量可忽略不計的計算資源以及算法處理過程的權衡,以實現更優的系統延遲性能。
4 MEPaxos算法保證及其證明
和Multi-Paxos、EPaxos類似,MEPaxos提供以下算法保證:非平凡性(nontriviality)、一致性(consistency)以及進展保證(progress guarantee)。本章將對三種算法保證進行詳細介紹并證明MEPaxos可提供這三種算法保證。
4.1 變量說明
在MEPaxos,定義如下表示:T表示MEPaxos算法從開始運行到結束運行之間的時間;Modets表示任意時刻ts,MEPaxos算法所處模式;Modebef表示MEPaxos算法轉換前的模式;CM表示算法轉換模式;EM表示EPaxos模式;MM表示Multi-Paxos模式;Command表示客戶端提交命令的集合;CT(Commandi)為判定命令Commandi是否被提交的函數,若是,為true,否則為false;Moi表示命令Commandi以模式Moi被提交;Nontri(Modets)為判定模式Modets是否滿足非平凡性的函數,若是,為true,否則為false;Consis(Modets)為判定模式Modets是否滿足一致性的函數,若是,為true,否則為false;Process(Modets)為判定模式Modets是否滿足進程保證的函數,若是,為true,否則為false。
4.2 算法保證描述及證明
根據MEPaxos算法步驟,以下公式成立:
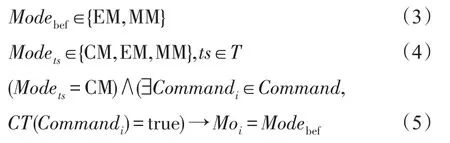
根據文獻[9]和文獻[17],以下公式成立:

下面將詳細介紹三種算法保證并在以上公式的基礎上,證明MEPaxos算法非平凡性、一致性以及進展保證。
非平凡性只有客戶端提出的命令才能被提交。
證明要證明非平凡性,只需證明以下公式成立:
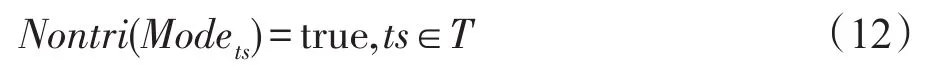
由式(4)、式(6)、式(7)知,要證明式(12)成立,只需證明:

由式(3)、式(5)、式(6)、式(7)知,式(13)成立。因此,非平凡性滿足。 □
一致性對于同一實例(instance),最多只有一個命令被提交,即對于同一實例,如果副本Rp和副本Rq分別提交了命令Cp和Cq,則Cp和Cq相同。
證明要證明一致性,只需證明以下公式成立:
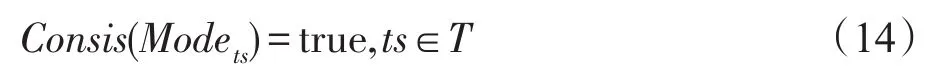
由式(4)、式(8)、式(9)知,要證明式(14)成立,只需證明:

由式(3)、式(5)、式(8)、式(9)知,式(15)成立。因此,一致性滿足。 □
進程保證在大多數副本沒有故障并且在接收者超時之前消息能送達的情況下,客戶端的命令最終會被非故障副本提交。
證明要證明進程保證,只需證明以下公式成立:
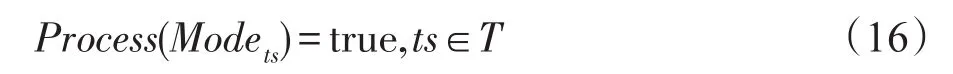
由式(4)、式(10)、式(11)知,要證明式(16)成立,只需證明:

在CM期間,若存在少數副本故障且在接收者超時之前消息能送達的情況下,根據轉換算法步驟,MEPaxos會跳出轉化狀態,返回Modebef,根據式(3)、式(10)、式(11)知,此時式(17)成立。
在CM期間,若無副本故障且在接收者超時之前消息能送達的情況下,根據轉換算法步驟,MEPaxos會進入EM或MM模式,根據式(10)、式(11)知,此時式(17)成立。
故式(17)成立。因此,進程保證滿足。 □
5 實驗與分析
5.1 實驗環境與參數設置
本文實驗運行在亞馬遜彈性計算云(elastic compute cloud,EC2)平臺,采用實例配置如下:1個2.5 GHz的vCPU,內存為1 GB,存儲空間為8 GB,網絡性能低到中等,64位ubuntu16.04操作系統。采用go語言(1.6.2版本)實現MEPaxos,并將其與EPaxos和Multi-Paxos進行對比分析。
實驗采用節儉模式[17]:在節儉模式下,副本將消息發送給法定人數副本,而不是全部副本。
參數設置:
(1)時間段t。t越大,計算EPaxos和Multi-Paxos系統平均延遲所耗費的副本計算能力以及網絡帶寬等資源越少,算法的穩定性越好,但算法的靈敏度越低。在實際生產實踐中,t的選取可根據可使用資源的多少,客戶端命令沖突變化情況以及對算法的靈敏度需求決定。本文實驗中t設置為15 s。
(2)超時時間TO。TO越小,算法轉換所需的最大時間越小,客戶端等待的時間越少,但算法轉換失敗的概率越大。在實際生產實踐中,TO的選取可根據客戶端負載情況,所能容忍的算法轉換時間以及所需的算法轉換成功率確定。本文實驗中TO設置為1 s。
5.2 均衡負載下的延遲
本節在副本數為3和5,客戶端負載均衡的情況下,分別比較MEPaxos、EPaxos和Multi-Paxos的延遲性能。當副本數為3時,將3個副本部署在加利福尼亞北部(California,CA),弗吉尼亞北部(Virginia,VA)和愛爾蘭(Ireland,IE);當副本數為5時,另外兩個副本部署在俄勒岡(Oregon,OR)和東京(Tokyo,TKY)。Multi-Paxos的領導者一直為CA處的副本。在每個副本實例上同時也設置了10個客戶端,它們同時發送相同數量的命令(客戶端發送命令時,收到前一條命令的回復之后才會發送后一條命令)。由于命令沖突只在不同副本處理相關命令時才會發生,因此副本實例上客戶端的數量對體現3種共識算法延遲性能差異影響不大,這里設置為10個客戶端。圖3和圖4分別記錄了各副本處的客戶端從發送命令到收到回復感知到的中位數和99%ile延遲(算法后的百分比表示具有相關性的命令所占的百分比)。
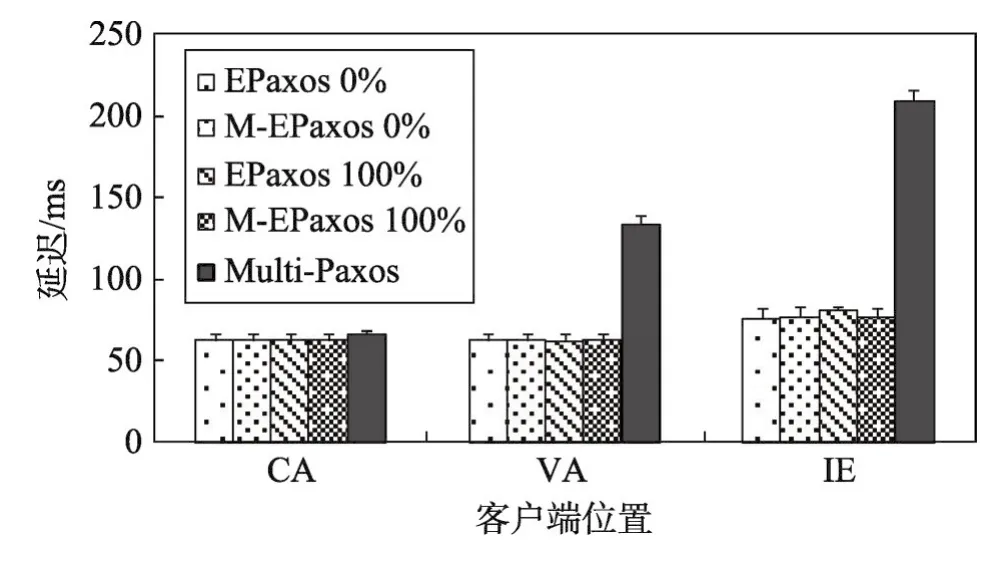
Fig.3 Median commit latency(99%ile indicated by lines atop bars)perceived by clients at each replica when Nis 3圖3 N=3時各副本處客戶端感知到的延遲的中位數(頂部的線表示99%ile)
副本數為3時,無論不同副本處并發客戶端發送的相關命令所占百分比為多少,EPaxos模式下,相關命令都不會產生沖突(節儉模式導致,具體原因詳見參考文獻[17])。此時,EPaxos的延遲性能要優于Multi-Paxos延遲性能。根據系統平均延遲計算結果,MEPaxos一直執行EPaxos模式。因此圖3中各副本處,EPaxos延遲性能不受相關命令所占百分比的影響,優于Multi-Paxos延遲性能。MEPaxos客戶端感知到的延遲和EPaxos客戶端感知到的延遲大致相同,小于Multi-Paxos客戶端感知到的延遲。
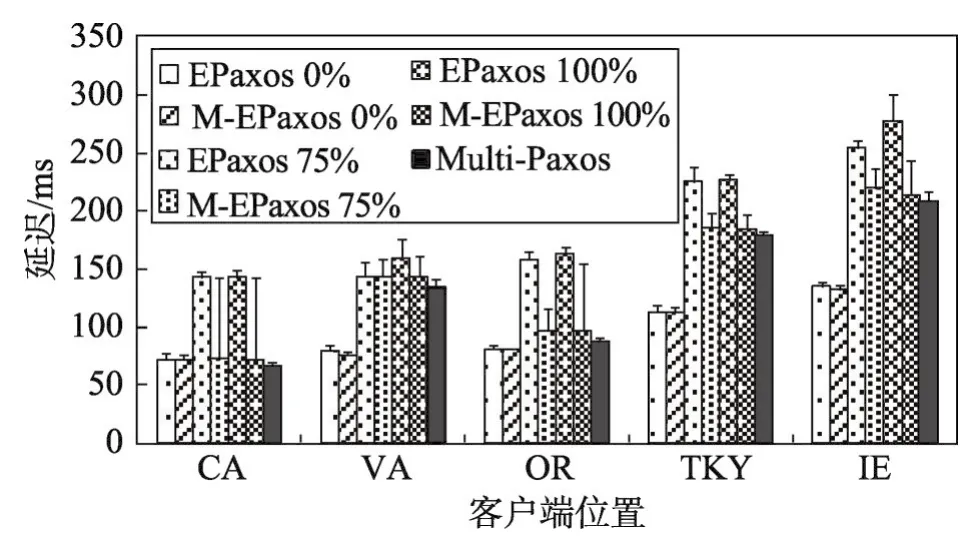
Fig.4 Median commit latency(99%ile indicated by lines atop bars)perceived by clients at each replica when Nis 5圖4 N=5時各副本處客戶端感知到的延遲的中位數(頂部的線表示99%ile)
副本數大于3時,隨著不同副本處并發客戶端發送的相關命令所占百分比的增大,EPaxos模式下,命令沖突數也增加,延遲性能變差。而Multi-Paxos延遲性能不受并發客戶端相關命令百分比的影響。此時MEPaxos根據ELat和MLat的計算結果,利用轉換算法自動地轉換至系統平均延遲較小的算法模式。故在圖4各副本處,EPaxos隨著相關命令所占百分比的增大,延遲性能變差,Multi-Paxos不受相關命令所占百分比的影響。當相關命令所占百分比為0時,MEPaxos客戶端感知到的延遲和EPaxos客戶端感知到的延遲大致相同,小于Multi-Paxos客戶端感知到的延遲;當相關命令所占百分比為75%和100%時,MEPaxos客戶端感知到的延遲和Multi-Paxos客戶端感知到的延遲大致相同,小于EPaxos客戶端感知到的延遲。副本數大于5的情況和副本數為5的情況類似,這里不再贅述。
由以上實驗結果可以看出,在不同副本處并發客戶端發送的相關命令所占百分比增大時,EPaxos算法延遲性能顯著下降。而MEPaxos能根據系統平均延遲,自動轉換到系統平均延遲較小的算法模式,延遲性能要優于EPaxos。
5.3 不均衡負載下的延遲
為了測試在客戶端負載不均衡情況下MEPaxos的性能,在5處CA、VA、IE、OR和TKY分別部署了1個副本;Multi-Paxos的領導者依然為CA處的副本;副本數為3時,MEPaxos一直執行EPaxos算法模式,不進行算法轉換,這里不再贅述。在OR和IE處的副本實例上同時設置了10個客戶端,它們同時發送相同數量的命令(客戶端發送命令時,收到前一條命令的回復之后才會發送后一條命令)。圖5記錄了OR和IE處的客戶端從發送命令到收到回復感知到的中位數和99%ile延遲(算法后的百分比表示具有相關性的命令所占的百分比)。
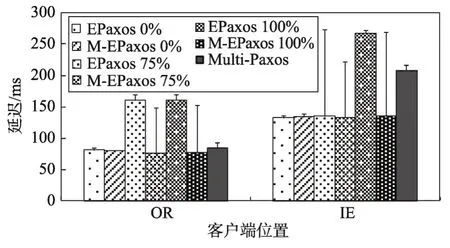
Fig.5 Median commit latency(99%ile indicated by lines atop bars)perceived by clients at OR and IE when Nis 5圖5 N=5時OR和IE處客戶端感知到的延遲的中位數(頂部的線表示99%ile)
如圖5,當只在OR和IE處的實例部署客戶端時,EPaxos隨著不同副本處并發客戶端相關命令百分比的增大,命令沖突數增加,延遲性能變差。Multi-Paxos延遲性能不受并發客戶端相關命令百分比的影響。在相關命令所占百分比為0時,EPaxos延遲性能優于Multi-Paxos,MEPaxos一直執行EPaxos模式,和EPaxos延遲性能大致相同。在相關命令所占百分比為75%和100%時,MEPaxos根據ELat和MLat的計算結果,自動轉換至系統平均延遲較小的算法模式。在轉換至Multi-Paxos算法模式時,根據MEPaxos算法的步驟(2),會選擇使系統平均延遲最小的副本(OR處副本)擔任領導者,故此時,MEPaxos客戶端感知到的延遲要小于Multi-Paxos客戶端感知到的延遲。副本數大于5的情況和副本數為5的情況類似,這里不再贅述。
以上實驗在客戶端負載不均衡時,進行EPaxos、Multi-Paxos和MEPaxos算法的對比。實驗結果表明,在客戶端負載不均衡時,MEPaxos始終能選擇系統平均延遲最小的算法模式,確保了算法的系統平均延遲最優。同時,轉換至Multi-Paxos算法模式時,能自動選擇最適合當前客戶端負載情況的領導者,延遲性能要優于Multi-Paxos。
6 結束語
本文基于低延遲的設計目標,提出了共識算法MEPaxos。MEPaxos綜合考慮算法運行過程中客戶端的負載情況、并發客戶端的命令沖突情況、網絡的實時情況,提出了系統平均延遲的計算方法,并引入超時機制對二階段提交算法進行改進。MEPaxos可根據系統平均延遲計算結果,利用改進的二階段提交算法自動選擇平均延遲較小的算法模式。實驗表明,MEPaxos比當前算法具有更好的延遲性能。由于客戶端環境的多樣性,未來的研究重點將放在進一步有效加強MEPaxos算法在各種客戶端環境下的穩定性,并將其應用到實際生產實踐中。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
