OCR技術在報刊加工中的應用分析
2019-07-16 20:08:32姜嘉佳
科技傳播 2019年10期
姜嘉佳
摘 要 OCR技術在圖書數字化加工過程中發揮了巨大作用,實現了報刊的電子化形態,由于技術的限制,目前OCR技術的利用并不是最佳狀態,在文字識別率過程中,會受到圖像外在因素影響如掃描參數、圖像質量等,降低識別率,未來對OCR技術的研究升級還有待完善和提高。
關鍵詞 OCR技術;數字化;掃描參數;識別率
中圖分類號 G2 文獻標識碼 A 文章編號 1674-6708(2019)235-0159-02
隨著數字化時代的趨勢,越來越多的圖書館致力于圖書的信息化建設來實現信息資源的整合,以保證圖書館的生存和發展。通過將館藏文獻如期刊、報紙、圖書等進行數字化加工,形成電子資源數據庫,實現數字圖書館的功能。在圖書數字化加工領域,OCR技術發揮了作用,最大限度地降低了人工著錄時發生問題的概率,既節約成本,又提高效率。本文就以上海圖書館報刊數字化加工項目為例,探討OCR技術在報刊加工中的應用及難點和解決方法。
1 OCR技術概念特點
何為OCR?OCR的全稱是Optical Character Recognition,意為光學字符識別,是指利用電子設備查看印刷體字符,以檢測亮暗方式來確定字符輪廓,通過字符識別方式將其轉換成計算機文字,整個過程分為圖像處理與文字識別兩大步驟。圖像處理,即對通過掃描儀存儲到計算機的圖像進行預處理,處理工作包括圖片降噪、灰度值、二值化、傾斜矯正、文字切分等步驟。圖像預處理過后,后期將通過文字特征來識別提取文字。
2 我國OCR技術的發展現狀
OCR是由德國科學家Tausheck于1929年提出來的,隨后美國科學家Handel也提出了文字識別的想法,隨后世界各國就開始了文字識別的研究。我國OCR技術起步較晚,70年代初才開始研究數字、字母、符號的識別,90年代清華大學推出了首套中文OCR產品,這一成果標志了國內在OCR技術研究領域有了質的飛躍。隨著技術不斷地推陳出新,目前國內已有多家大型公司致力于OCR技術的研究發展,像漢王科技公司、點通數據公司、合合信息技術公司等。從單一的印刷體字體識別,到多字體簡繁混合、中英文混合識別,到現在各種識別系統的推出,OCR技術已經逐漸成熟并融入了各行各業。
3 OCR技術的應用及流程
為順應數字化時代的潮流,上海圖書館致力于圖書的數字化加工工作,從最初的印刷月刊到網絡平臺一體化,每年數字化加工處理的期刊文獻達500萬條,創辦的《全國報刊索引》亦是知名信息服務品牌,提供期刊、報紙、特輯資源數據庫,包括《晚清期刊全文數據庫》、《字林洋行中英文報全文紙數據庫》、《現刊索引數據庫》等。
以《現刊索引數據庫》為例,建立一個索引篇名數據庫需要的信息包括期刊的期刊名、年卷期、題名、頁碼、作者、單位、分類號、主題詞、摘要等。假設人工著錄信息必須要大量的人力物力財力,且非常容易出錯,比如錄入錯字,錯行,甚至錯篇等。使用OCR技術著錄信息,就可以大大節省時間和成本,以下是OCR技術在實際運用中的大致流程,如圖1。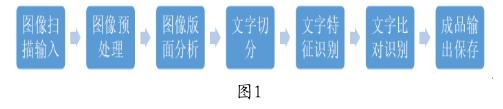
1)圖像掃描輸入。用掃描儀把期刊整本輸入進計算機,為確保存儲的圖像質量及后續的識別工作,在掃描過程中,設備參數至關重要,包括色彩模式、分辨率、掃描閾值、亮度、對比度、保存格式等。2)圖像預處理。掃描的時候由于不同紙張的厚薄度、光滑度、印刷質量等情況會出現圖像模糊、畸變、斷筆、粘連、傾斜等問題,所以需對其進行預處理,可使用Photoshop或其他工具,處理包括降噪、灰度化、二值化、去黑邊、去底色等,如此一來可減少后期文字識別時遇到字跡模糊不清楚等問題。3)圖像版面分析。圖像版面分析即識別圖像的區域屬性,是橫排文字還是豎排文字,表格還是圖片、規則版面還是不規則版面等。4)文字切分。分為自動切分與人工切分。自動切分是計算機通過對圖像的初步識別,按照字符每一行的上界限、下界限、每個字符的左右邊界將文字自動切割成獨立的個體。人工切分即在自動切分的基礎上對完成切分的文字進行校對,在切割有誤的地方重新切分,保證單詞、詞組、句子的完整性。5)文字特征識別。因為每個文字都有其固定的特征,根據特征對文字進行識別,通過特殊特征提取,如筆畫位置、交叉點數等結構特征,就可以得到字符。6)文字比對識別。初步得到的字符通過對比文字數據庫,可以得到文字。文字比對識別需人工干預進行錯字標改。7)成品輸出保存。文字校對結束后,系統根據內容自動進行格式排版,確認無誤后,成品導出需要的文件格式,即完成了數字化工作。
整個數字化加工流程看似復雜繁瑣,實際用到OCR技術識別圖像只有零點幾秒,難點就在于前期的圖像處理與后期的校對處理,前期的圖像全文掃描與預處理工作,直接導致了整體的文字識別率。而后期的人工校對也是在識別率基本正確的情況進行校對。
4 OCR技術的難點
雖然圖像的前期與后期工作較為繁瑣復雜,但比起傳統人工手動文字錄入,OCR技術的使用在速度、準確、便捷等方面略勝一籌,人會因為疲勞等各種原因犯錯,但機器不會,因此使用OCR技術加工整體消耗的人力物力都比人工著錄要少的多。盡管OCR技術很先進,在保證圖像掃描質量的前提下,后續的文字識別過程仍會遇到下面幾種問題:
1)文字切分錯字。在進行文字自動切分時,部分固定詞組會因為分行而造成切分錯誤。2)相近文字識別不出來。目前對于那些結構特征相近的字,OCR技術仍不能完全分辨出來,如分和兮,人或入,藝和芝等。3)英文單詞識別困難。比起漢語,英文字母識別更困難,尤其是中文、英文和數字混合排列的時候,問題最為明顯,原因在于結構大都比較相近,掃描的時候會由于光線問題造成識別混亂,如a和d,大寫i和小寫L,小寫L和1,G或6等。
5 提高識別率方法
1)選擇合適的數字掃描儀。一般從圖像傳感器性能、掃描分辨率大小、掃描適應能力、操作便捷性幾方面考慮,針對不同的掃描資料選擇簡便的掃描儀。2)合理設置掃描儀參數。包括色彩模式、分辨率、黑白值、亮度、對比度等。對于常見的文檔資料,建議設置成黑白模式,或在特殊要求下選擇彩色模式;合理確定分辨率,選擇300dpi模式,除非有特殊情況,否則分辨率過高不僅會降低掃描速度、增加計算機存儲,還會降低OCR識別;掃描后,如果字體顏色較淺或較粗,可以調節亮度和對比度。3)選擇圖像存儲格式。掃描結束后圖像的存儲需要保證分辨率不受影響、無損壓縮,且適應主流圖像編輯軟件和識別軟件,建議選擇JPEG或Tiff格式。4)即時更新文字比對數據庫。對于可能出現的繁體字、象形字、外文字符,即時更新可避免識別率問題。5)人工校對的重要性。正是由于OCR技術的不夠完善,不能做到100%的正確識別,后期的人工校對是提高識別率的重要環節,雖然人工校對費時,但相比于手工錄入,總體耗時與錯誤率都要低很多。
6 結論
從技術角度出發,OCR技術的出現到發展,給圖書數字化發展帶來了翻天覆地的變化,它改變了傳統紙質媒介的概念,實現了文字識別功能,提高了資料加工的效率,為文獻的存檔、數據查詢開辟了新的篇章。使用OCR技術可以有效地提高工作效率,減少不必要的工作量。但是,OCR技術的識別率問題目前還是一個比較大的挑戰,畢竟電腦不如人腦這么靈活,碰到圖像掃描模糊、相近文字、換行斷字、英文字符等識別率就會降低,如何降低錯誤率或利用其他工具來提高識別率,是OCR技術未來發展的一個重要環節。
參考文獻
[1]錢炎.醫療保險系統中信息處理關鍵技術研究[D].南京:南京航空航天大學,2005.
[2]曾伊蕾,喻世俊,陶俊.基于OCR技術的圖像驗證碼識別[J].軟件,2013,34(10):106-107,110.
[3]張志遠.復雜背景下文字增強算法研究與應用[D].上海:上海交通大學,2010.
[4]李冠藝.OCR技術在電子商務信息采集中的應用研究[J].電腦與電信,2013(8):56-58.
[5]陶新宇.《全國報刊索引數據庫》芻議[J].現代情報,2004(9):9-10.
[6]劉明英.檔案數字化過程中OCR技術的應用分析[J].中國高新技術企業,2017(5):55-56.
[7]蔡旸.JPEG靜態圖像壓縮算法的研究[D].武漢:武漢科技大學,2009.
[8]郭軍.基于數字掃描儀性能的文本型數字圖像OCR識別準確度提高策略研究[J].網絡安全技術與應用,2017(9):118-120.
[9]王玲麗.淺談OCR技術在圖書館文獻資源加工中的應用——以上海圖書館近代文獻全文OCR數據制作項目為例[J].數字與縮微影像,2015(1):23-26.
[10]張肇玲.圖書資料檢索與信息化建設[J].人力資源管理,2018(4):396.
