數據挖掘在高職學生職業發展分析中的應用
2019-07-16 03:14:59武文廷
電腦知識與技術 2019年15期
關鍵詞:數據挖掘

摘要:隨著職業教育改革的不斷深化和畢業生人數的逐年遞增,學生就業工作和職業生涯發展指導工作任務越來越重。該文以甘肅林業職業技術學院信息工程學院近四年的畢業生數據作為挖掘對象,采用了改進的ID3決策樹算法對高職學校應往屆畢業生的基本信息、學業成績、實踐能力、就業狀況等數據予以挖掘,把挖掘到的規則運用到高職學生管理服務和教育教學中,為高職院校就業指導部門提供更多的理論決策支持。
關鍵詞:數據挖掘;ID3算法;職業發展分析
中圖分類號:TP311 ? ? ? ?文獻標識碼:A
文章編號:1009-3044(2019)15-0025-03
目前,許多高職院校都建立了諸如學生成績管理系統、就業數據一站式管理系統等。但因缺乏數據挖掘技術,因而只能用于數據統計與匯總,潛在的和有價值的信息得不到充分發掘。本文采用決策樹技術,探索和分析與高職學生職業發展相關的數據,利用改進后的ID3算法試圖找出其中的規則,構造分類決策樹,建立數據挖掘模型,利用該模型預測新數據,發掘高職學生職業發展的影響因素相關性研究及應用,以在學生職業規劃中提供幫助和指導。
1 數據挖掘實施過程
1.1 挖掘對象及目標確定
本文選取甘肅林業職業技術學院信息工程學院2015-2018年的畢業生資料。通過數據挖掘和分析,管理者可以根據高職學生的不同特點制定對應的職業生涯規劃指導方案。
1.2 數據采集
本文的數據主要來源渠道為:畢業生的基本信息和就業信息由招生就業處就業指導中心獲取,計算機等級成績、實踐能力數據由二級學院競賽情況數據獲得。學業成績、英語AB級成績來自教務管理系統。
1.3 數據預處理
因為學院各部門業務重點不同,各自的數據庫中所存儲的數據也會和預期的數據格式有很大的差異,因此需要進行合理的數據預先處理,以解決該問題。
1.3.1 數據集成
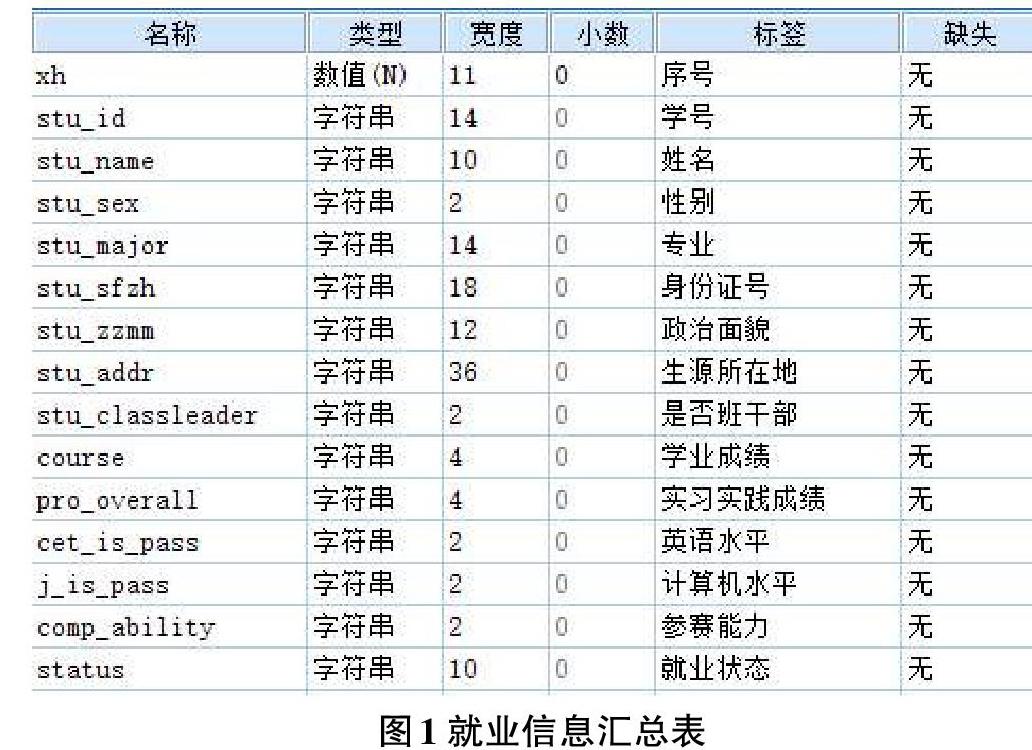
把不同來源、格式、特點性質的數據在邏輯上或物理上有機地集中稱之為數據集成。“學生基本信息表”“學業成績表”“畢業生就業匯總表”等數據表眾多,需要跨數據庫去查找多個表,因此在收集到數據之后,根據數據屬性間以及屬性所在表之間的關系,去除所有代碼項和無關的數據項,將全部所需數據項集成到一個數據表,命名為“就業信息匯總表”,如圖1所示。
1.3.2 數據清理
在數據庫中的數據中含有噪聲、數據表示方式不一致等,有些數據不完整,有些感興趣的屬性可能缺少屬性值,例如學生的全國計算機等級考試,如果未參加考試或者考試沒有通過,則該項數據為Null,需要通過一些方式予以補充。同時對數據庫中無效的數據記錄進行清除,如有退學、開除的學生等,可將其記錄予以刪除。對于休學、留級的學生數據需要歸集到復學后的班級中再予以挖掘。
1.3.3 數據歸約
在收集到的學生相關信息數據庫中所包含屬性非常多,但是有些數據和數據挖掘并不是很相關,并且規約后執行數據挖掘結果與規約前執行結果相同或幾乎相同,可通過冗余屬性的刪除,將屬性有大量不同的值但是這個值影響因子較小的刪掉;將各屬性值進行轉,如把就業狀態分為“就業”“應征入伍”“升學”“待就業”四種情況;對連續數據值數據離散化,如學業課程成績通常以百分比表示,需將所有課程的成績進行匯總后計算平均值,利用GPA標準公式計算后將其離散為“優秀”“良好”和“一般”三類。
1.4 訓練集與測試集的選擇
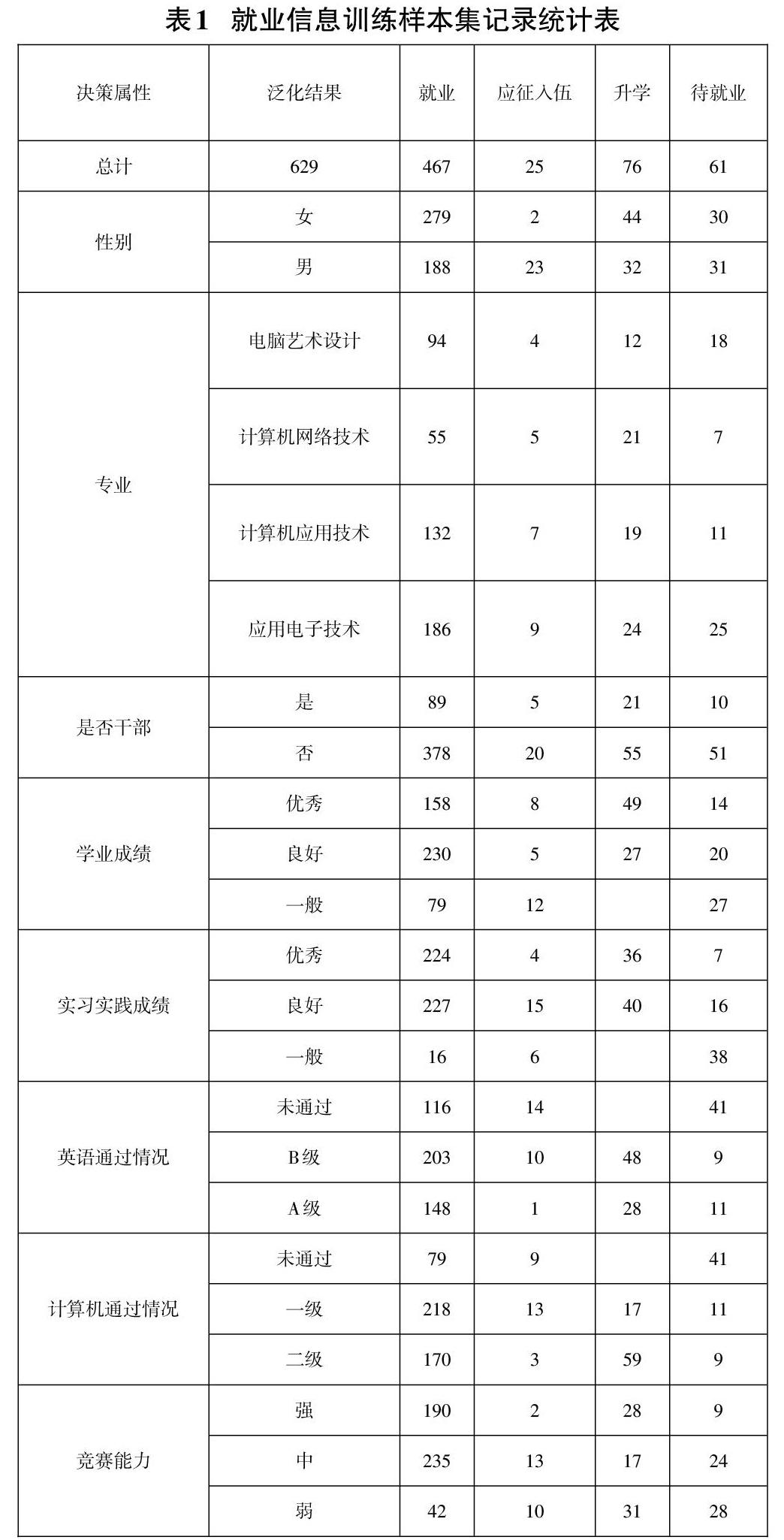
本文對收集到1048條的學生相關信息進行整理,將2015-2017屆畢業生數據處理后得到的629條有效記錄作為訓練樣本數據,通過改進的ID3算法生成決策樹模型,然后用2018屆畢業生的228條數據作為測試數據集,作為驗證模型驗證規則。通過數據的歸約,最終得到的數據樣本集統計如表1所示。
2 改進的ID3算法在畢業生就業分析中的實施
改進的ID3決策樹構造的步驟為:
(l)將表中屬性值作數據源,通過公式[IX=-j=1mPjlog2Pj]分別計算各個屬性的信息熵;
(2)通過改進的基于動態屬性權值的ID3算法公式Gain(S,C)=I(S)–[ωI]*E(S,C)計算信息增益,將最大信息增益的屬性設置為根節點;
(3)遞歸計算每個子集,步驟(1)和(2)被每一個子集依次調用。用相同的算法計算其余各屬性值的信息增益并進行分類,直到每個屬性對應于單一值或者樹的增長超過一定的規模為止。
2.1 構造決策樹
根據就業信息訓練樣本集記錄統計表(表1),將其中2015-2017屆畢業生數據共629條,作為訓練樣本數據集S,根據畢業生就業狀況分為四類:就業(A)、應征入伍(B)、升學(C)、待就業(D)。
訓練樣本集S中有629個元組,A、B、C、D四個子集中元組個數分別為:S1=467,S2=25,S3=76,S4=61。
所以性別的熵值為:
用相同方式分別計算專業、是否為學生干部、學業成績、實習實踐成績、英語AB級獲得情況、計算機等級證獲得情況、競賽能力的熵值。
根據改進的屬性權值選擇方法,在此對訓練樣本集的計算屬性權值和信息增益,最終結果如下表2:
通過以上結果分析發現,改進后的算法計算所得的實習實踐成績的信息增益值為0.360,遠高于其余屬性的信息增益值,所以“實習實踐成績”將作為決策樹的根節點。計算每個分支并根據信息增益導出下一個決策屬性,通過改進后的ID3算法計算信息增益,構建了初始決策樹,通過后修剪決策樹的方法,剪枝后的決策樹如下圖2所示:
2.2 規則提取
決策樹分類規則的信息表示一般為生成規則方法,即對生成的決策樹先序遍歷,使用已建立的決策樹,在每個節點上生成“IF...THEN”規則。根據上面生成的決策樹,本文生成以的部分重要分類規則如下:
(1)IF(實習實踐成績=“優秀”)AND(是否班干部=“是”)THEN Prediction='就業'Probability=0.673
(2)IF(實習實踐成績=“優秀”)AND(是否班干部!=“是”)AND(學業成績=“優秀”)THEN Prediction='就業'Probability=0.860
(3)IF(實習實踐成績=“優秀”)AND(是否班干部!=“是”)AND(學業成績=“良好”)THEN Prediction='就業'Probability=1
(4)IF(實習實踐成績=“良好”)AND(競賽能力=“強”)THEN Prediction='就業'Probability=0.848
(5)IF(實習實踐成績=“良好”)AND(競賽能力=“中”)AND(性別=“男”)THEN Prediction='應征入伍'Probability=0.089
(6)IF(實習實踐成績=“良好”)AND(競賽能力=“弱”)THEN Prediction='升學'Probability=0.508
(7)IF(實習實踐成績=“良好”)AND(競賽能力=“弱”)THEN Prediction='就業'Probability=0.426
(8)IF(實習實踐成績=“一般”)THEN Prediction=“待就業” Probability=0.633
從決策樹規則中可以得出,對于高職院校畢業生,實習實踐成績、計算機水平、專業課成績、競賽能力和是否班干部對職業發展的影響因子比較大,實習實踐成績、專業課成績、競賽能力和是否班干部高效的投入力度將對畢業生的職業發展起到極其重要的作用。
2.3 分類規則驗證
將生成的規則按照IBMSPSS語法進行規范后,連同驗證數據集導入SPSS軟件,通過決策樹分類預測功能,生成2018屆228條畢業生的就業狀態數據,預測結果保存到畢業去向字段中。
通過實驗所得預測結果如表3所示。將預測得到的分類結果與學生初次就業情況統計表予以比較,其中正確的記錄有172個,不正確的記錄56條,正確率為75.4%,分類的準確度還是比較高的,模型可用于對準畢業生數據進行預測和決策支持。
對預測結論和誤差分析,2018屆畢業生中選擇就業的人數大于了70%,為高職畢業生的發展主渠道,基本符合實際情況。應征入伍預測為4,屬性對結果影響較小,很難準確預測。升學人數誤差較大,這是因為部分學生會放棄升學而選擇就業的情況。而待就業誤差,主要是因政策原因有業不就的影響,但隨著甘肅省就業政策的變動,因各類招考而有業不就的情況將有所減少。對于預測結果為未就業的學生,要加大關注度,從而提高畢業生的就業質量。
3 職業發展決策支持系統的實現
在前文得出模型的基礎上,進一步建立決策支持系統,針對本文內容,經過分析系統的需求和功能之后,開發一個就業決策支持系統,系統中應用前文所得決策規則,實現學生就業狀態的統計和預測,獲得“職業生涯預測”結果,也可通過學生或姓名抽取學生信息,將預測出個體學生的就業狀態,顯示在預測狀態欄中,如圖3所示。
4 結語
本文首先提出了目前高職院校就業制度的實際情況,然后指出利用決策樹技術挖掘學生職業發展信息的必要性,完成了問題確定、數據收集、集成、清理和轉換等一系列的數據挖掘和處理任務,并利用改進的基于動態屬性權值的ID3算法利用生成的決策樹產生的分類規則,建立就業狀態預測模型,通過在高職院校學生職業發展預測中的應用,并利用信息工程學院2018屆畢業生的信息對就業狀態預測模型進行驗證。利用所得規則開發了職業發展決策支持系統。經分析驗證,優化后的ID3算法——基于動態屬性權值的ID3算法應用于解決高職院校學生職業發展預測問題效果良好,所得結論可為學院管理者做出合適的決策有所幫助,進一步提升職業生涯指導工作效果。
參考文獻:
[1] 孫麗爽.決策樹技術在高校就業分析系統中的應用[D].西安理工大學,2017.
[2] 武文廷.一種基于動態屬性權值的ID3算法改進[J].電腦知識與技術,2019(2).
[3] 陰亞芳,孫朝陽.決策樹算法在實踐教學中的應用研究[J].計算機與數字工程,2018(06):1078-1088.
【通聯編輯:代影】
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
