基于SimHash的數據流分層遺忘概要結構
2019-07-16 03:14:59未春鳳趙淑賢
電腦知識與技術 2019年15期
未春鳳 趙淑賢

摘要:數據流處理的關鍵是應用高效的單趟掃描算法,創(chuàng)建數據流的概要結構。現有的概要結構存在著重構誤差較大的缺點。作者針對這個問題,結合數據流分層遺忘概要結構,采用simHash算法提取數據流中的概要信息,形成一種新的數據流分層遺忘概要結構(simHash-Based Hierarchical Amnesic Synopsis,SH-HAS)。本文將SH-HAS結構用在CUP99和Covertype數據集上,實驗驗證了該結構的可靠性和穩(wěn)定性。
關鍵詞:數據流;概要結構;simHash;分層遺忘
中圖分類號:TP311 ? ? ? ?文獻標識碼:A
文章編號:1009-3044(2019)15-0006-02
隨著計算機網絡和各類電子設備的應用,越來越多的數據以流的形式出現,這種新的數據形式被稱為數據流[1]。數據流具有實時性、有序性、高速性、演化性、無限性等特性[2]。這使得傳統(tǒng)的數據挖掘方法不能直接應用到數據流上。
因為數據流具有無限到達的特性,導致現有的計算機系統(tǒng)不能存儲全部的數據流。針對這一問題,學者提出了建立數據流的概要結構,以便保存數據流的概要信息和根據該結構提供數據流的近似處理結果。數據流概要結構是存儲數據流概要信息的一種結構,旨在使用較小的數據規(guī)模代表全體數據,稱為概要結構(synopsis structure)[3]。現有的數據流概要結構主要通過直方圖、抽樣、小波、隨機投影和散列方法獲取數據流的概要信息。
分層遺忘概要(Hierarchical Amnesic Synopsis,簡稱HAS)[4],是陳華輝提出的一種基于數據流遺忘特性的概要結構構造框架。其他學者在這方面也進行了許多的研究,例如文獻[5-7]。這些方法能有效地獲取數據流概要信息,但存在著重構誤差較大的缺點。
simHash算法由Google的工程師于2007年提出,在文檔去重和文本相似度檢索等領域。學者將SimHash算法用于數據的相似性檢索[8-10],并取得了較好的效果。
SimHash算法既可以高效地壓縮原始數據,又是一種降維方法。本文利用simHash算法在數據壓縮方面的高效性,結合數據流的HAS結構,提出一種基于simHash的數據流分層遺忘概要結構(simHash-Based Hierarchical Amnesic Synopsis,簡稱SH-HAS)。該算法的主要思想為:采用simHash算法提取數據流上新到的數據子序列的概要信息,創(chuàng)建對應的數據節(jié)點并添加到SH-HAS結構中;當SH-HAS結構中某層的數據節(jié)點個數達到上限,則將當前層節(jié)點相加成K個節(jié)點并插入該結構的上一層;隨著數據流的到來,動態(tài)調整該結構。本文將該結構用在CUP99和Covertype數據集上,實驗驗證了該結構的可靠性和穩(wěn)定性。
1基于simHash的數據流分層概要結構
simHash算法[9]屬于前述方法中的散列方法。它既是一種數據相似度計算方法,又是一種數據維度削減方法,用以解決數據流維度高和數據無限的問題。
1.1 分層概要結構
數據流除了具有前述的特點外,其數據的影響是隨時間衰減的,表現為近期的數據價值更大。在分層概要結構中,數據所處的層數越低,說明數據到達的時間較晚;層數越高說明數據到達的時間較早。
1.2 數據定義
在SH-HAS結構中數據節(jié)點[P(D)]=[ts,n,X,Γ],其中[ts]為該數據節(jié)點的時間戳,記錄D中最后一個數據的到達時刻;n為D中數據個數[D];[X]為D中數據的均值;[Γ]表示采用simHash算法計算出的數據概要信息。
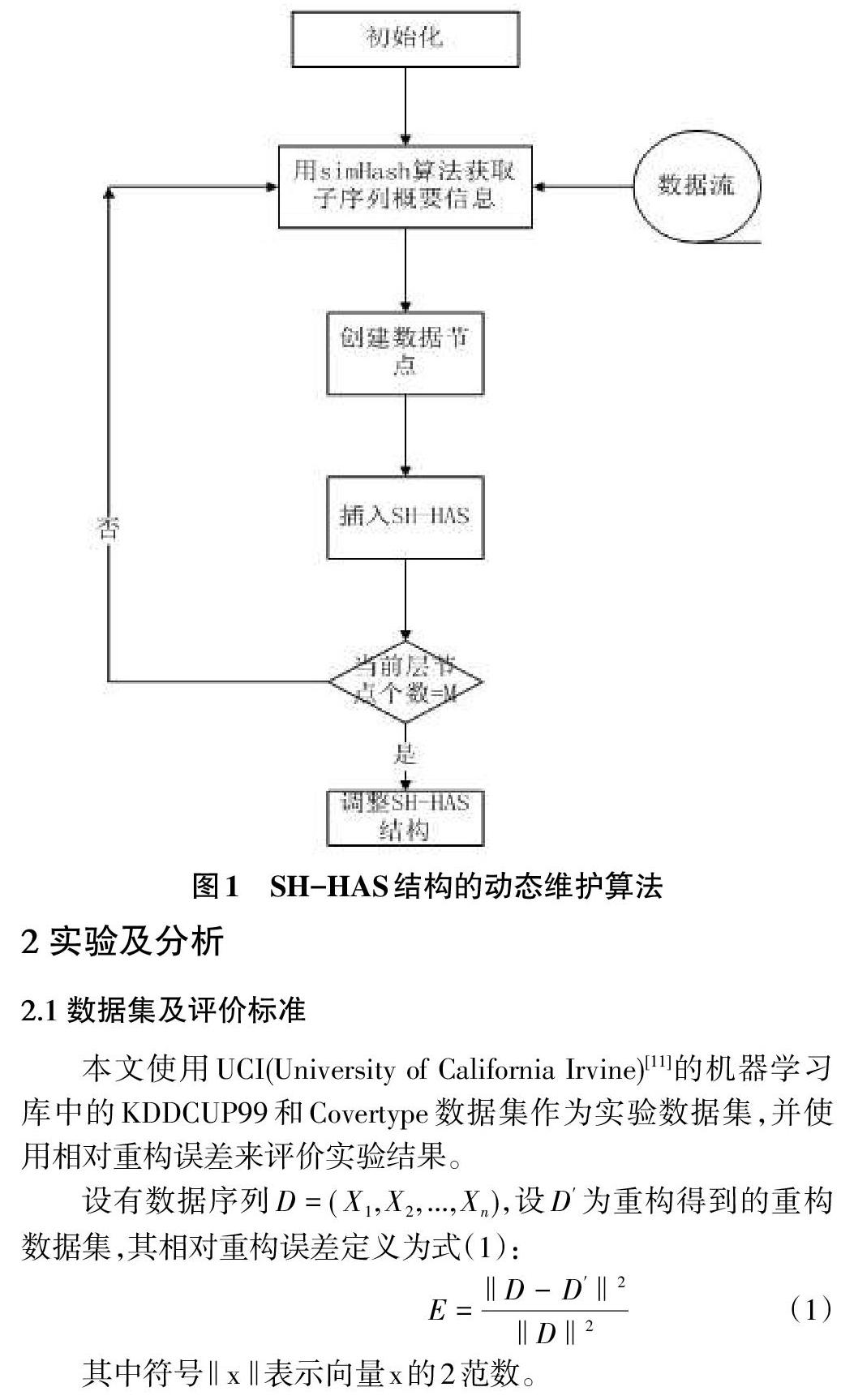
1.2.3 SH-HAS結構的動態(tài)維護
隨著數據的到達,為了使SH-HAS結構中保存的信息能無限接近真實的數據流,需要對此結構進行動態(tài)更新維護。數據流上的SH-HAS結構的動態(tài)維護算法如圖1所示。算法的空間和時間復雜性在文獻[4]中已經被證明,在此不再贅述。
2 實驗及分析
2.1 數據集及評價標準
本文使用UCI(University of California Irvine)[11]的機器學習庫中的KDDCUP99和Covertype數據集作為實驗數據集,并使用相對重構誤差來評價實驗結果。
設有數據序列[D=(X1,X2,...,Xn)],設[D']為重構得到的重構數據集,其相對重構誤差定義為式(1):
其中符號[∥x∥]表示向量x的2范數。
2.2 實驗及結果分析
2.2.1實驗設置
實驗中修改MOA系統(tǒng)lancher文件模擬數據流的到達,將數據流上每2000條數據劃分為一個子序列。本文實驗比較了Sampling、Histogram和SH-HAS方法在數據流上的相對重構誤差。
2.2.2實驗結果及分析
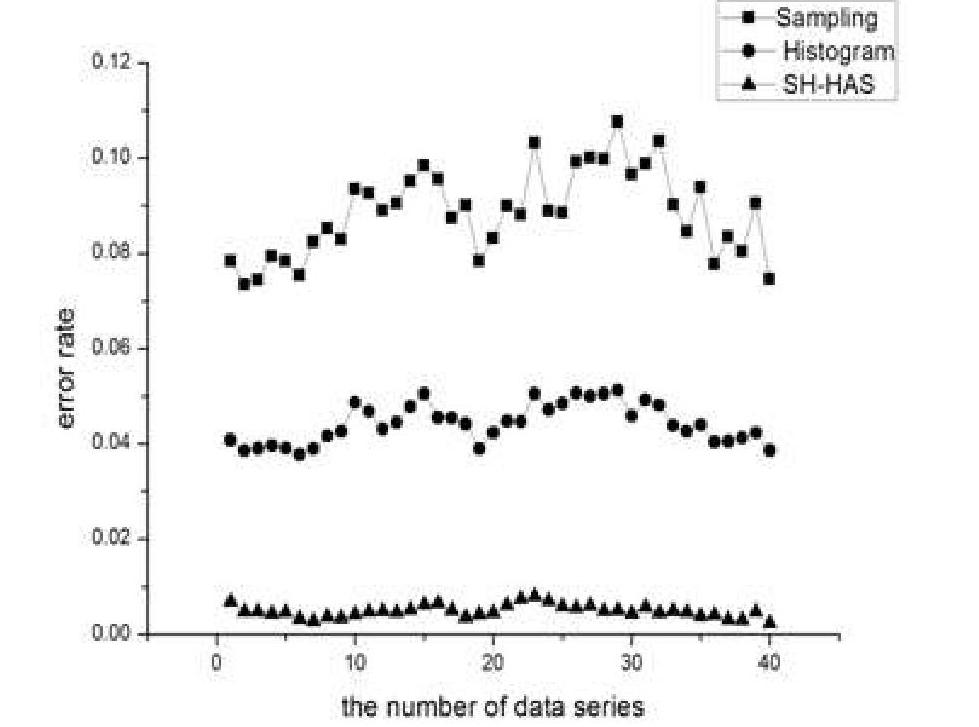
因為篇幅有限,在此僅列出數據集Covertype上的部分實驗結果。圖2分別截取了一部分實驗數據,記載了將Sampling、Histogram、SH-HAS方法應用在Covertype數據集的相對重構誤差。從圖2中可以看出, SH-HAS方法較Sampling、Histogram方法相對重構誤差明顯降低。
3結語
本文針對現有數據流概要結構存在著重構誤差較大的缺點,采用simHash算法提取數據流中的概要信息,形成一種新的數據流分層遺忘概要結構(SH-HAS)。該結構采用simHash算法提取數據流上新到的數據子序列的概要信息,創(chuàng)建對應的數據節(jié)點并添加到SH-HAS結構中;當SH-HAS結構中某層的數據節(jié)點個數達到上限,則將當前層節(jié)點相加成K個節(jié)點并插入該結構的上一層;隨著數據流的到來,動態(tài)調整該結構。實驗結果表明SH-HAS結構可以大大減小相對重構誤差。下一步可開展基于SH-HAS結構的數據流相似性判斷和分類等處理方法的研究。
參考文獻:
[1] 黃樹成,曲亞輝.數據流分類技術研究綜述[J].計算機應用研究,2009,10:3604-3609.
[2] 李南.概念漂移數據流分類算法及應用[D].福建師范大學,2013.
[3] 龍門,夏靖波,張子陽.基于概要數據結構的網絡異常檢測方法[J].計算機應用與軟件,2011,04:186-188.
[4] 陳華輝.基于遺忘特性的數據流概要結構及其應用研究[D].復旦大學,2008.
[5] Pang C,Zhang Q,Zhou X,et al.Computing unrestricted synopses under maximum error bound[J].Algorithmica,2013,65(1):1-42.
[6] Pham D S,Venkatesh S,Lazarescu M,et al.Anomaly detection in large-scale data stream networks[J]. Data Mining and Knowledge Discovery,2014,28(1):145-189.
[8] Graham Cormode;S.Muthukrishnan.An Improved Data Stream Summary:The Count-Min Sketch and Its Applications[A].2004
[10] Xu X,Gao C,Pei J,et al.Continuous similarity search for evolving queries[J].Knowledge and Information Systems,2014:1-30.
[11] http://www.ics.uci
【通聯編輯:唐一東】
