基于深度學習的復雜網絡實時Sybil攻擊檢測算法
2019-07-16 01:18:58王春明
計算機應用與軟件 2019年7期
李 揚 王春明
1(江蘇商貿職業學院電子與信息學院 江蘇 南通 226011)2(南通大學計算機科學與技術學院 江蘇 南通 226019)
Deep neural network
0 引 言
社交網絡是一種典型的復雜網絡,目前已成為人們日常生活、社會活動與商業活動的一部分,Twitter、微博、微信、網易云音樂等社交平臺每天受到大量的關注與參與,社交網絡的安全性隨之成為一個亟待解決的問題。Sybil攻擊是指利用社交網絡中的少數節點控制多個虛假身份,利用這些身份控制或影響網絡中正常節點的攻擊方式[1]。目前主要有以下幾種類型的Sybil攻擊[2]:直接通信、間接通信、偽造身份、盜用身份、同時攻擊、非同時攻擊。Sybil攻擊對網絡的危害大、隱蔽性高,一旦發生攻擊則會造成巨大的破壞,因此對Sybil攻擊進行精確地預測是目前主要的研究方向。
目前社交網絡的Sybil攻擊檢測方法主要可分為基于網絡拓撲結構的檢測機制與基于社交網絡用戶特征的惡意用戶檢測兩種類型[3],這兩種檢測類型均需要分析明顯的Sybil攻擊行為。并且此類方案需要分析網絡中的每個節點與連接[4],因此對于大規模的動態網絡場景,這兩種方法的效率較低。基于網絡拓撲結構的方案假設信任關系多的網絡中攻擊量較低,并且假設用戶的連接時間較短,如果這兩個假設基礎不成立,直接導致Sybil防御系統無效。
近期對社交網絡的Sybil攻擊檢測研究主要集中于Sybil的用戶特征與網絡特征[3],以及社交網絡的拓撲結構[2],這些研究均通過10萬個用戶的數據進行實驗,評估特征集或者網絡拓撲結構對Sybil攻擊檢測的影響。實際情況下社交網絡的規模極大、拓撲復雜,而攻擊檢測系統的效率是另一個關鍵的性能指標,本文從另一個角度出發,采用深度學習技術同時提高對復雜網絡中Sybil攻擊的檢測準確率與時間效率。
極限學習機(Extreme Learning Machine,ELM)是一種單層人工神經網絡,無需專家知識并且學習速度較快,目前廣泛地應用于復雜網絡的惡意行為識別問題中[5]。極限學習機對于大規模數據的學習速度是一個瓶頸[6],本文對傳統ELM進行了改進,將傳統的學習時間從小時級別降低到秒級別。本模型包括三個模塊,分別為:數據采集模塊、特征提取模塊與深度學習模塊。本方案實現了較快的學習速度,對于Sybil攻擊實現了較快的響應速度。
1 基于ELM的半監督表示學習
ELM主要存在三個問題:(1) 每層的隨機投影機制導致性能不穩定;(2) 非自動地調節隱層節點的數量較為耗時;(3) 如果隱層規模較大,那么訓練時間較長,并且需要大量的存儲空間。多層核ELM[7]可解決前兩個問題,但處理大規模數據所需的計算成本與存儲成本仍然是個難題。提出新的ELM,解決了上述ELM的三個問題。

1.1 經驗核映射
假設X=[x1,x2,…,xn]T∈Rn×d表示一個n列、d行的輸入矩陣,通過核函數κ(·)計算特征空間的內積:
Ωk,j=κ(xk,xj,σ)={φ(xk),φ(xj)}
(1)
?k,j=1,2,…,n
式中:σ為一個可調節參數,Ω∈Rn×n為核矩陣,φ(x)為核空間特征映射。將核矩陣Ω分解為Ω=GGT,其中G=[φ(x1),φ(x2),…,φ(xn)]T∈Rn×D,D是Ω的秩,G稱為經驗核映射。
假設V=[v1,v2,…,vl]T∈Rl×d是l個路標點的集合,采用Nystrom方法[8]生成兩個小規模矩陣Ωnl∈Rn×l與Ωll∈Rl×l,其中(Ωnl)k,j=κ(xk,vj,σ),(Ωll)k,j=κ(xk,vj,σ)。采用Ωnl與Ωll近似核矩陣Ω:
(2)

(3)
(4)
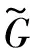
1.2 多層極限學習機(Multilayer extreme learning machine, ML-ELM)
H(i)Γ(i)=X(i)
(5)

(a) 變換矩陣Γ作為表示學習
(b) 計算的新輸入表示

(c) x(2)作為輸入學習的輸入

(d) 無監督表示學習結束圖1 多層ELM的結構
H(i)的計算方法為:
(6)
式中:h(i)(a(i),b(i),x(i))=gi(a(i)x(i)+b(i)),gi為第i層的激活函數,第i層的輸入a(i)與bias(偏差)b(i)均為隨機產生。Γ(i)的計算方法為:
(7)
式中:ILi與In分別表示維度為Li與n的單位矩陣,Ci為第i層的正則化項。
式(7)的X(i)與Γ(i)相乘獲得一個新的數據表示:
Xi+1=gi(X(i)(Γ(i))T)
(8)
通過圖1(d)的學習程序可獲得X(1)的最終數據表示Xfinal。ML-ELM直接將Xfinal作為隱層來學習輸出權重β:
Xfinalβ=T
(9)
式中:T=[t1,t2,…,tn]T,tk∈Rc是一個獨熱輸出向量,c是分類數量。通過求解以下方程獲得權重矩陣β:
(10)
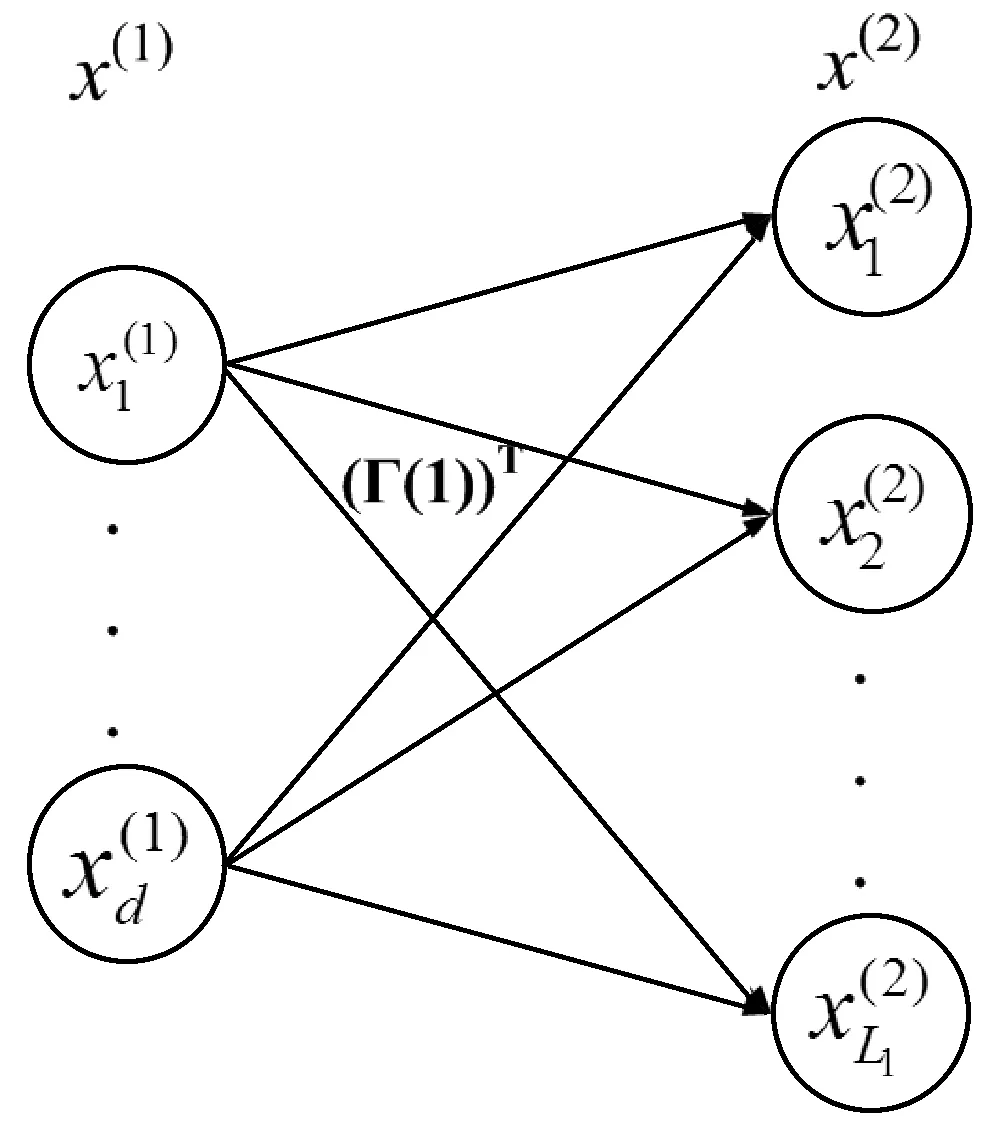
1.3 多層核極限學習機(Multilayer kernel extreme learning machine, ML-KELM)
為ML-ELM引入核學習來實現高度的泛化效果[9],ML-KELM包含兩個步驟:(1) ELM-AE棧式核的無監督表示學習;(2) 基于K-ELM的監督特征分類。
Ω(i)Γ(i)=X(i)
(11)
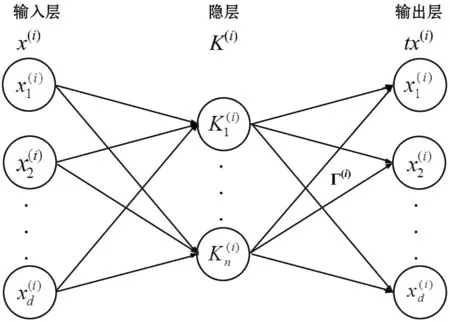
圖2 隱層到輸出層的學習過程
Γ(i)的計算方法為:
(12)
數據表示X(i+1)的計算方法為:
X(i+1)=gi(X(i)(Γ(i))T)
(13)
通過無監督表示學習獲得最終的數據表示Xfinal,并且用于訓練K-ELM分類器:
Ωfinalβ=T
(14)
式中:Ωfinal為核矩陣,權重矩陣的求解方法為:
(15)
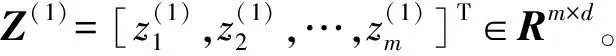
Z(i+1)=gi(Z(i)(Γ(i))T)
(16)
計算核矩陣ΩZ∈Rm×n獲得最終的數據表示Zfinal:
(17)
(18)
1.4 經驗核映射自編碼器(Empirical kernel map Autoencoder, EKM-AE)
(19)
(20)

圖3 第i個EKM-AE的結構
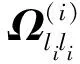
(21)

(22)

學習EKM-AE的第i個變換矩陣Γ(i):
(23)
Γ(i)的求解方法為:
(24)
數據表示X(i+1)計算為:
Xi+1=gi(X(i)(Γ(i))T)
(25)
1.5 改進的ELM
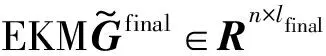
(26)
輸出權重β的計算方法為:
(27)
將測試數據Z(i)與第i個變換矩陣Γ(i)相乘,獲得數據表示:
Z(i+1)=gi(Z(i)(Γ(i))T)
(28)
(29)

(30)
2 Sybil攻擊的預測模型
設計了Sybil節點的預測方案,采用深度學習模型檢測Sybil節點發出的請求,并且融合社交網絡中用戶的社交屬性作為攻擊檢測的一個重要依據。本模型能夠在線地檢測社交網絡中的Sybil攻擊。
2.1 系統架構
本文在線的Sybil攻擊檢測流程如圖4所示。首先,從網絡中采集數據,提取合適的特征,然后通過深度學習技術預測網絡中的攻擊行為。
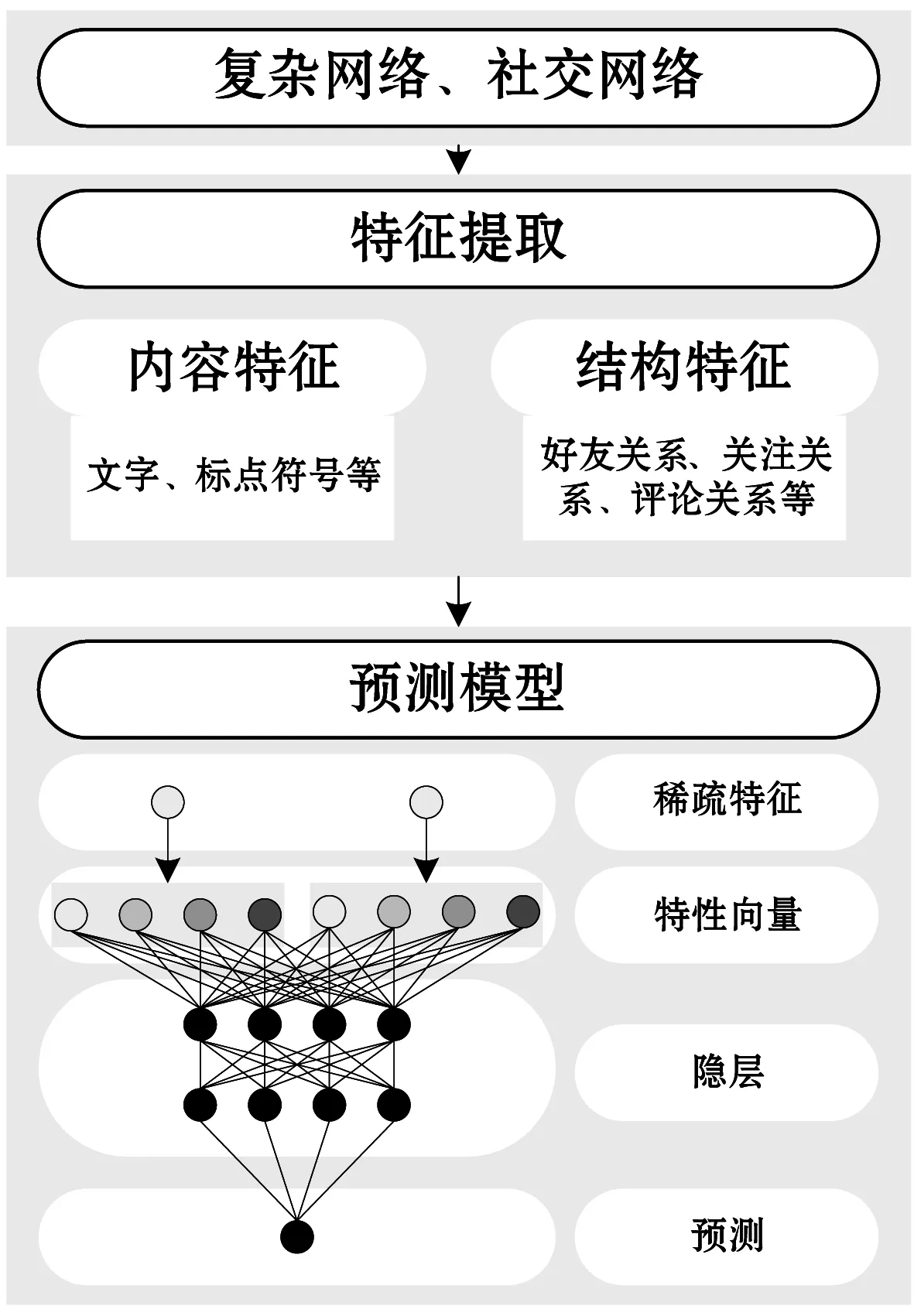
圖4 在線的Sybil攻擊檢測流程
2.2 網絡數據的采集模塊
選擇“微博”作為研究的社交網絡模型,利用新浪微博提供的開放應用程序編程接口API編程提取微博的內部信息。
2.3 特征提取模塊
為了準確地識別Sybil行為,該模塊提取了用戶不同類型的特征。通過新浪微博提供的開放API采集原始樣本數據,然后將樣本分為三種類型,如圖5所示。

圖5 微博的特征分類
2.3.1用戶檔案的特征
用戶檔案的信息可用于將用戶與用戶行為分類。采用微博的官方接口獲取該類信息,包括:被關注數量、每天發布量、轉發量等。此外,微博中“@”操作也是一種社交關系,將“@”操作作為一種社交關系。
2.3.2內容的特征
內容特征進一步分為四個子類型:
① 時間特征:微博發布的日期與時間作為一個關鍵變量,此類特征在市場變化的研究中具有重要的價值。該類特征包括了多個時間敏感的特征,例如:發微博的時間戳、兩條微博之間的間隔。
② 標題特征:微博標題反映了一條微博的核心內容。其中關鍵詞、共生詞匯、標簽、作者信息均為重要的特征。
③ 質量特征:語句的特點有助于理解微博和消息的潛在意思。Sybil用戶的消息一般采用簡單的詞語與語法,本方案則考慮了用戶消息的詞匯量。采用文獻[10]的“中文詞匯分割與POS”技術對中文內容進行語言評級。
④ 表情特征:表情是觀察消息語氣的重要特點。本文采用多個表情分析對消息內的表情進行處理,提取消息的表情特征,所采用的表情評級策略包括:活躍度、嚴肅性、滿意度評級、表情符號等。
2.3.3基于網絡圖的特征
社交網絡的結構直接決定了節點之間的互動情況。根據用戶在社交網絡中的操作方式也是發現Sybil攻擊的有效方式。本系統追蹤三個操作指標,分別為轉發操作、用戶訪問操作、共生微博標簽。前兩個操作表示該用戶不是直接社交關系,第三個操作同時出現多個標簽,說明該用戶消息具有廣播的特點。
2.4 基于深度學習的Sybil攻擊預測
采用基于極限學習機的深度學習技術對用戶進行分類(Sybil用戶與合法用戶)。將每個用戶表示為一個特征集,用戶Ui表示為特征集F=(f1,f2,…,fk),k=80。為每個特征分配一個權重,權重集表示為一個向量W=(w1,w2,…,wk)。加權的特征集計算為下式:
(31)
Sybil攻擊的極限學習機隱層方程為:
(32)

采用交叉熵損失方程(Cross-entropy Cost Function,CCF)作為極限學習機的計算方程,CCF成本方程如下:
(33)

2.5 算法復雜度分析
2.5.1存儲復雜度
ML-KELM的訓練階段,第i層需要O(n2)的存儲空間(Ω(i)與X(i))。本文的ELM方案保存第i層矩陣G(i)與X(i),其存儲成本與數據規模n為線性關系。因此,存儲成本從二次方級降低至線性級。
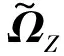
2.5.2時間復雜度

假設l1=l2=l3=np,因為p遠小于1,那么ML-KELM與本文ELM方案訓練階段的計算復雜度分別為O(n3)與O(p2n3)。ML-KELM與本文ELM方案測試階段的計算復雜度分別為O(n2)與O(p2n2)。
3 性能評估與分析
3.1 實驗數據集
采用新浪微博提供的開放API提取數據集,從關注量超過10萬的賬號中隨機選擇25 510個賬號作為訓練集,13 957個賬號作為測試集,這些用戶作為正常用戶,如表1所示。采用Erdos-renyi模型[11]為訓練集與測試集分別生成1 000個Sybil節點。

表1 實驗數據集
3.2 Sybil攻擊的檢測效果
首先選擇ML-ELM[12]與HELM[13]兩種極限學習機與本方案比較,評估本方案對ELM的改進效果,然后,選擇SRSUIM[14]與GSF[15]兩個Sybil檢測算法與本方案進行比較,評估本方案的檢測性能。
采用攻擊檢測率、誤檢率與漏檢率三個指標評估對Sybil攻擊的檢測性能,檢測率指識別出的Sybil用戶數量與Sybil用戶總數的比例,誤檢率指錯誤識別的正常用戶數量與正常用戶數量的比例,漏檢率指未能識別的Sybil用戶與Sybil用戶的比例。
圖6所示是五個檢測算法對于實驗數據集的檢測結果。可以看出,本方案的檢測率高于ML-ELM與HELM兩種基于極限學習機的檢測算法,本方案對EML實現了有效的增強,GSF框架通過對社交網絡的社交關系進行深入的分析,實現了較好的檢測率,優于ML-ELM與HELM兩個算法。三個基于ELM的檢測算法表現出極為接近的誤檢率與漏檢率,均低于SRSUIM與GSF兩個算法,SRSUIM主要通過節點影響力分析識別Sybil用戶,而有些正常用戶與Sybil用戶的行為較為相似,導致出現誤檢與漏檢。綜合檢測率、誤檢率與漏檢率三個指標可得出結論,本方案實現了較好的檢測效果,并且實現了對ELM的增強。
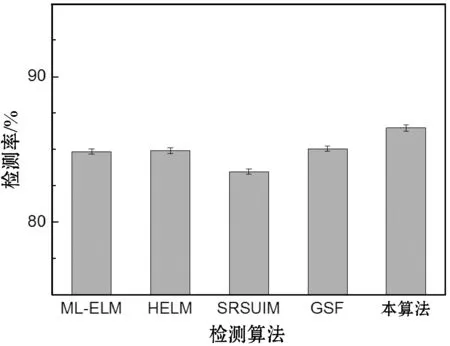
(a) 檢測率

(b) 誤檢率
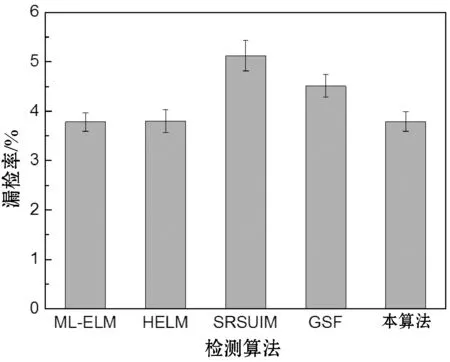
(c) 漏檢率圖6 五個檢測算法對于實驗數據集的檢測結果
3.3 Sybil攻擊的時間效率與存儲成本

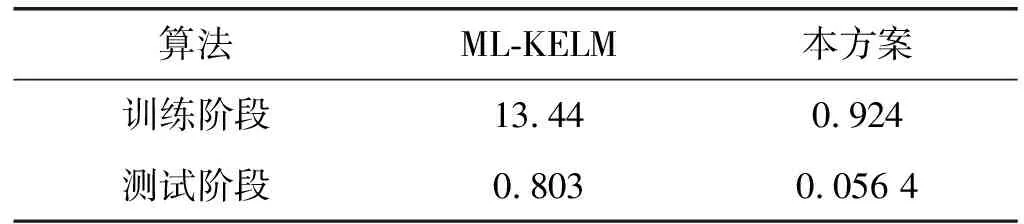
表2 兩種ELM的時間效率 s

表3 兩種ELM的存儲成本 MB
4 結 語
社交網絡的規模極大、拓撲復雜,本文從攻擊檢測系統的效率出發,采用深度學習技術同時提高對復雜網絡中Sybil攻擊的檢測準確率與時間效率。極限學習機對于大規模數據的學習速度是一個瓶頸,本文對傳統ELM進行了改進,將傳統的學習時間從小時級別降低到秒級別。實驗表明,本方案提高了ELM的時間效率與存儲效率,并且實現了較高的Sybil用戶檢測效果。本方案將ML-ELM隨機產生的隱層替換為估計的隱層,該處理提高了訓練階段的速度,但是對模型的精度會產生微小的影響,未來將重點考慮在模型精度與時間效率之間取得平衡。
