基于多特征融合密集殘差CNN的人臉表情識別
2019-07-16 01:18:04馬中啟朱好生楊海仕胡燕海
計算機應用與軟件 2019年7期
馬中啟 朱好生 楊海仕 王 琪 胡燕海*
1(寧波大學機械工程與力學學院 浙江 寧波 315211)2(寧波戴維醫療器械股份有限公司 浙江 寧波 315712)
0 引 言
隨著計算機技術的不斷發展,人機交互相關產品正逐漸走入大眾視野。在計算機視覺領域中,人臉識別技術日益成熟,人臉表情識別成為了熱點研究課題。相比較人臉識別,人臉表情識別不僅需要考慮光照、遮擋和姿態等問題,同時還要考慮人臉身份特征以及人臉表情變化非剛性的特點。在傳統機器學習中,人臉表情研究主要由圖像預處理、特征提取和分類三個步驟完成。傳統特征提取過程中表情特征點為手工標注,使得人臉表情特征提取很大程度上依賴于人為干預,算法的魯棒性較差。近年來,隨著深度學習技術的不斷發展,卷積神經網絡在圖像分類與識別方面取得巨大優勢,特征提取這一過程不再需要人為干預,神經網絡依據所提供樣本特征自動學習表情特征,然后通過分類器進行分類,這種方法很大程度上減少了人為干預的影響,提高了算法的魯棒性以及準確率。
卷積神經網絡在面部表情識別應用領域屬于起步階段,Mollahosseini等[1]使用了GoogleNet的網絡結構,結合多個數據集,并對數據進行歸一化處理,訓練結果接近人類能夠識別的水準。實驗結果表明深度神經網絡能夠有效提取表情特征,但是該方法并未充分利用不同特征圖之間的關系,未使得表情特征信息最大流動。Xie等[2]使用了FRR-CNN的結構對CK+數據集進行分類,通過多個輸入進行訓練,然后進行特征融合,使用TI-pooling方法進行特征池化,最后進行分類,多輸入的集成算法能夠提升算法的魯棒性。但文中僅使用了兩層的卷積網絡,不能很好提取表情的特征。Pramerdorfer等[3]通過對比目前各種數據集的start of art 結果,提出了集成深度神經網絡解決現在表情識別的瓶頸問題,說明了使用深度神經網絡集成能夠很好地進行特征提取與分類。Lu等[4]使用了一種利用眾包標簽的正則化CNN損失函數的人臉表情分類,通過優化數據標簽,提高了算法的準確性。李勇等[5]使用了一種基于跨連接的LeNet-5模型結構對人臉面部表情進行識別,該方法有效地將低層次特征與高層次特征結合,實驗結果的準確率比僅使用高層次特征有明顯提升。文中只是提取了不同層次的特征,沒有對層與層之間的特征進行更深層次的連接,從而使得特征提取不夠充分。何志超等[6]提出了一種多分辨率特征融合的卷積神經網絡,將圖片經過兩個相互獨立且深度不同的通道進行特征提取,然后融合不同分辨率特征進行分類。
本文提出一種多特征密集殘差卷積神經網絡,該網絡實現對每層卷積特征的重復利用與融合。首先在殘差網絡的基礎上,為了增加層與層之間的連接,將每層網絡提取出的特征分別傳遞給后面若干層網絡。在特征傳遞的過程中,設計一個密集模塊,在每個密集塊中共有3個3×3卷積層和一個1×1卷積的Bottle layer層,后一卷積的輸入均為前面所有層卷積輸出特征圖之和。隨著密集塊個數的增加,卷積層輸出特征圖數也隨之以2的倍數增加。這樣可以最大程度地利用每層特征圖之間的關系以及特征信息的最大流動。其次將不同層的特征提取出來,使其在全連接時與網絡的輸出層進行融合,最后將融合后的特征添加Island loss以增大類間距離,縮小類內距離,隨后送入softmax分類器進行分類。實驗表明,該模型不僅能有效提高準確率,而且可以充分提取表情特征,防止梯度消失。同時,由于密集塊的使用,使得每層網絡中的卷積核數量均有所降低,進而減少了該模型的參數量,在一定程度上能夠降低過擬合。
1 卷積神經網絡
卷積神經網絡一般包括卷積層、降采樣層、激活函數、全連接層和分類輸出五部分。
通常外部輸入的圖片直接與卷積層相連,根據圖片尺寸不同,卷積層的卷積核大小也不盡相同。卷積層一般可以表示為:
(1)
f(x)=max(0,x)
(2)
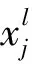
降采樣層(池化層)一般可以表示為:
(3)
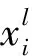
全連接層是將卷積神經網絡提取到的特征圖進行全連接,每個神經元的輸出可以表示為:
F(xl)=f(wTxl+b)
(4)
式中:F(·)表示全連接的輸出,w為全連接權重,b為偏置,f(·)為激活函數。
對于分類輸出,本文選用softmax分類器,對于屬于的特征,softmax分類可表示為:
(5)
計算輸入類別j時的概率,其中w表示的權重值,x表示輸入的特征,k代表的是類別總數。
本文除上述的卷積層等之外還使用了批歸一化[12](Batch Normalization, BN)、dropout等方法抑制過擬合。
2 多特征融合密集殘差CNN
神經網絡中較淺層的特征圖尺寸比較大,對于較小的特征信息比較敏感,但是缺少了對物體整體特征的表達,較深層的特征圖則與其相反,能夠很好地表達物體輪廓和外觀等方面的信息,但缺乏對小特征信息的敏感性。普通的卷積網絡不能很好地利用這些特點,張婷等[10]提出的跨連接卷積神經網絡能夠有效地將較淺層次特征與深層次特征有效的結合,構造出了良好的分類器,實驗結果表明跨連接分類器是有效的。隨著網絡模型的加深,圖像特征在傳播過程中梯度相關性會逐漸減小,He等[8]提出的ResNet深度殘差網絡跨連接方式以及Relu函數的使用,使得圖像特征在傳播過程中保持了很大的梯度相關性,從而得到更深層次結構的神經網絡模型。Huang等[9]提出的DenseNet密集型卷積神經網絡使得整個神經網絡中所有層之間都相互連接,每一層網絡的輸入都來自之前所有網絡的輸出,這樣能確保神經網絡中特征信息的最大流動。Ioffe等[7]提出了BN網絡,通過對每個卷積層輸出參數的歸一化,進而解決了神經網絡在訓練過程中梯度消失與梯度爆炸的問題。
綜合以上問題,本文提出一種多特征密集殘差卷積神經網絡。
(1) 該模型結構不僅充分利用了卷積網絡中層與層之間的緊密連接,同時也提取了不同層次的特征,多特征融合能夠更好地提取人臉表情細微特征與整體輪廓特征,密集網絡可以更有效地提取有用的表情特征。
(2) DenseNet模型把所有特征進行連接,造成了大量的冗余,本文縮短每個block長度,加大每個block特征圖的數量,對于每個卷積層使其輸入的特征圖盡量保持在2的冪次方,這樣能夠加快運算速度。結合ResNet網絡能夠在減少冗余的情況下最大化信息流。具體結構模型見圖1、圖2。
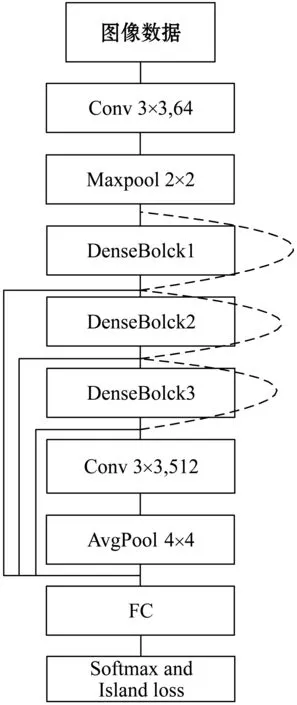
圖1 CNN模型圖
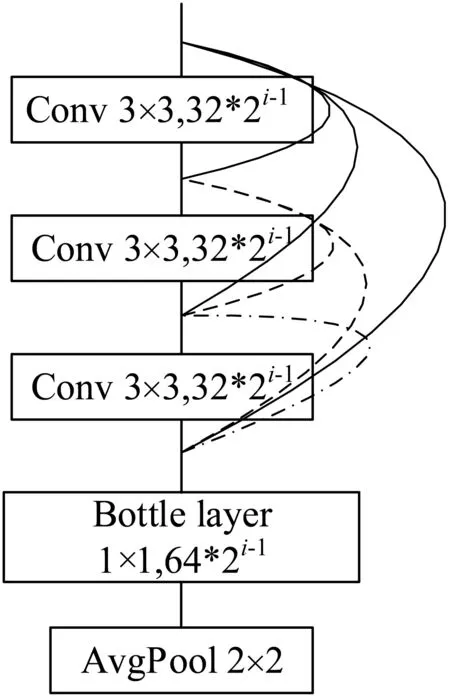
圖2 DenseBlock(i)(i=1,2,3)
(3) 添加了Island_loss層,增大了不同表情類間距離LC,縮減了表情類內距離LIL。
(6)
(7)
式中:xi表示全連接層輸出的第x個樣本。c表示所有同一類別yi的所有樣本的中心值。
(4) 密集塊和殘差網絡的使用可以提高深度網絡的梯度相關性,同時密集塊的使用也在一定程度上降低了網絡參數量,使得模型具有一定的抗過擬合效果。在最終的softmax分類之前進行融合。
圖1中虛線代表殘差連接,實線代表多尺度特征融合。本文使用了三個密集塊連接,在DenseBlock模塊中,起始卷積特征圖個數為32,隨著模塊增加,每層卷積輸出的特征圖增加方式如圖2所示,根據密集塊的順序逐次按照2(i-1)次冪增加卷積層的個數,這樣既可以使輸入卷積核的個數大部分為2的冪次方以增加計算機運算速度,又可以增加特征圖個數從而提取更多信息。
3 實 驗
本文所做的實驗是基于Python的Tensorflow進行的,硬件平臺Intel Core i7-7700,GPU為NVIDIA GeForce GTX1070,顯存為8 GB。
3.1 數據集
本實驗所采用的數據集為CK+和FER2013數據集,數據集包含了7種基本的表情:高興、悲傷、憤怒、恐懼、驚訝、厭惡與中性,如圖3所示。
CK+數據集[11]:包含來自123個人的593個表情視頻序列。這些視頻包含了從中性表情到其他6種表情的變化,本次實驗僅選取每個序列表情張量最大的3幅圖片,檢測出人臉部分并裁剪至256×256,然后隨機使用其中一幅圖像再隨機裁剪成兩幅227×227像素的圖片。最后將所有的圖片歸一化大小為64×64的圖像。
FER2013數據集:FER2013是2013年Kaggle比賽用的數據集,圖片均為網上爬取,符合自然條件下的表情分布。數據集包含28 709幅Training data,3 589幅Publictest data和3 589幅Privatetest data。每幅圖都是像素為48×48的灰度圖。該數據集中共有7種表情:高興、悲傷、憤怒、恐懼、驚訝、厭惡與中性。

Angry Disgust Fear Happy Neutral Sad Surprised圖4 FER2013表情庫7種表情實例
3.2 實驗結果分析
CK+數據采用了交叉驗證的方法,將數據的圖片分為5份,每次取其中4份作為訓練集,另外一份作為測試集,對5次測試的準確率求平均值作為整個數據集的準確結果。并且數據集中訓練部分進行數據增強,隨機左右翻轉、沿對角線翻轉、調整圖像亮度,以及隨機增加噪聲點以減小外界環境對識別的干擾,增強魯棒性。
FER2013數據集直接對測試數據集進行10crop:分別對圖片左上角、左下角、右上角、右下角以及圖片中間裁剪至44×44尺寸,并進行翻轉操作。訓練數據直接隨機裁剪至44×44的尺寸。表1表示的是本文所提出的方法在CK+數據集上的交叉驗證結果。可以看出,對于厭惡、高興以及驚訝三種表情得到了較高的準確率,生氣和悲傷的準確率稍微下降一些,其主要原因可能是生氣和悲傷等與其他的表情之間存在模糊定義,檢測時引起識別率下降。圖5給出的是其FER2013測試集的混淆矩陣。圖6是對比改進前的DenseNet的網絡模型和ResNet網絡模型在訓練過程中收斂的速度。可以看出改進后的網絡的收斂速度與ResNet的相當,遠高于DenseNet。
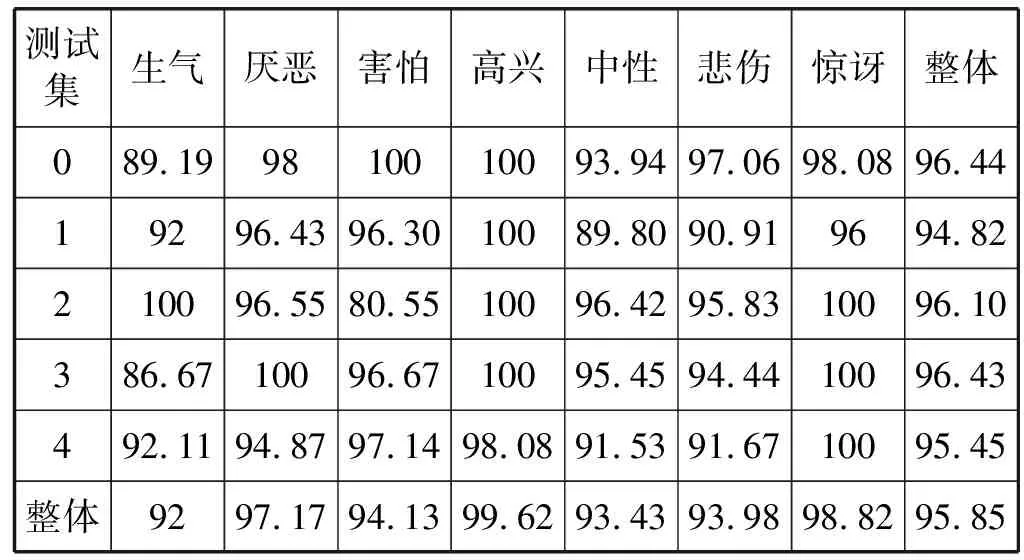
表1 CK+不同種類表情的分類正確率 %
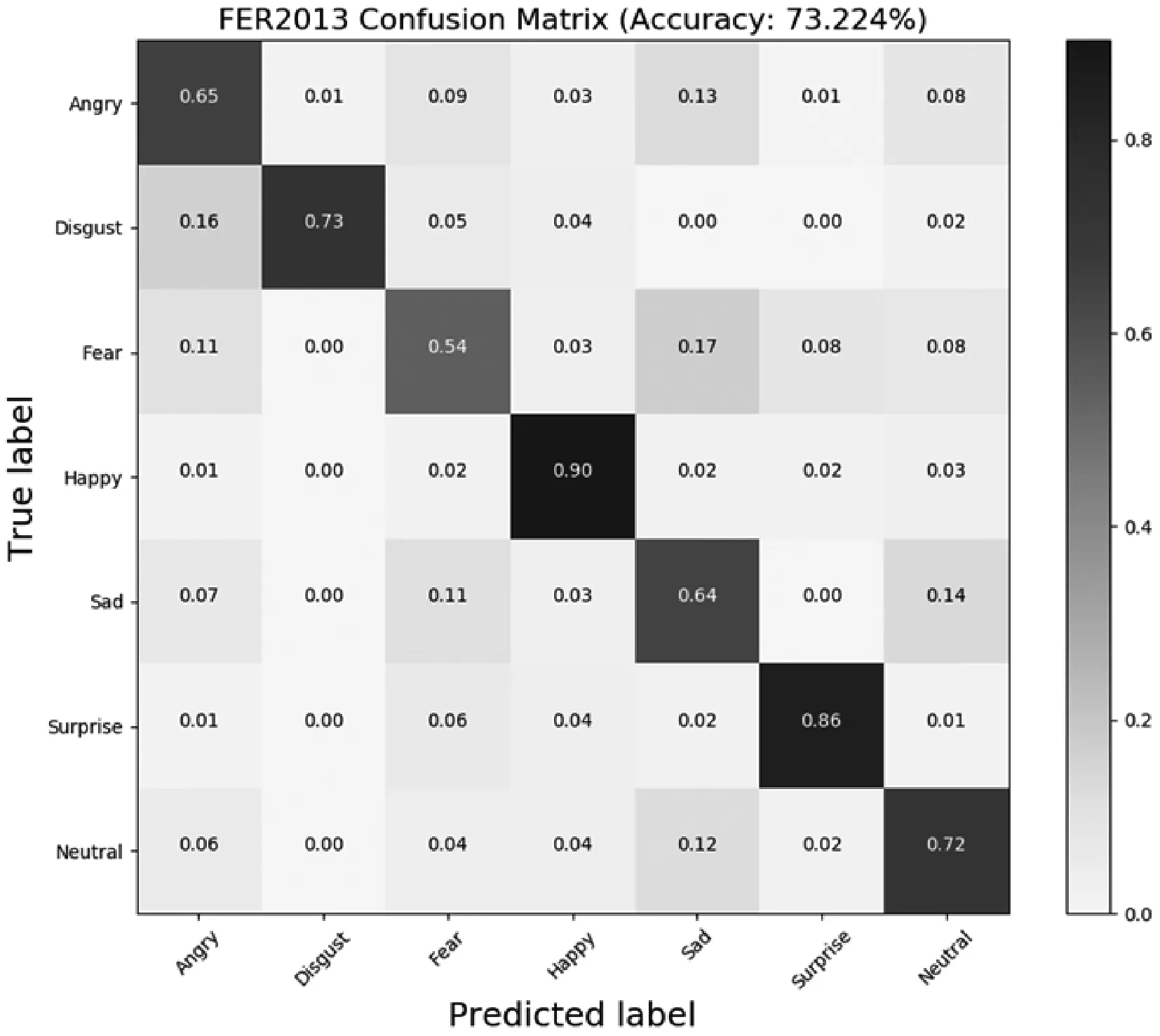
圖5 卷積神經網絡預測Fer2013混淆矩陣
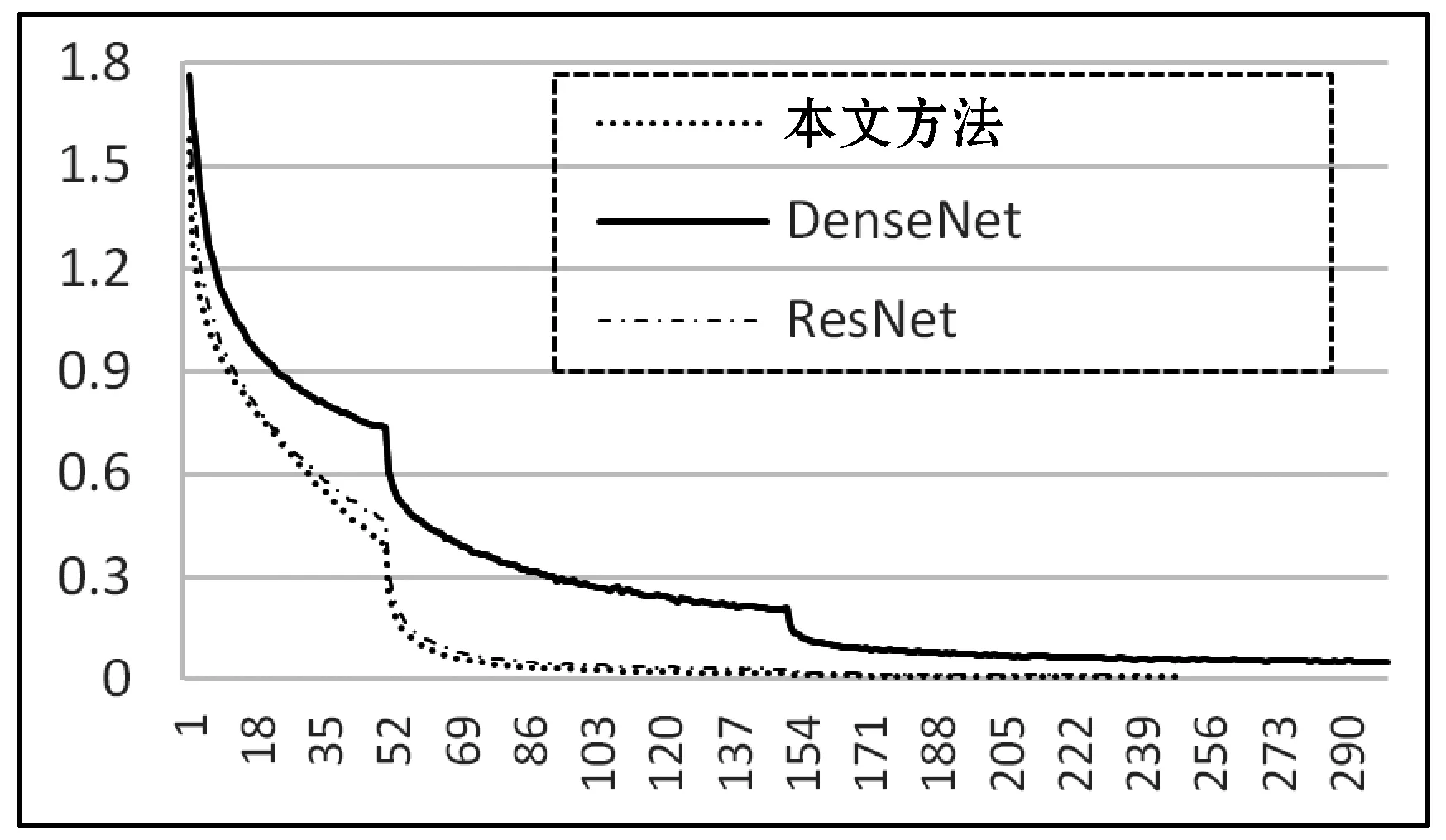
圖6 訓練過程中的損失函數
為了驗證本文方法的有效性,將文獻[1-3,5-6]的方法與本文進行對比,由表2可以看出,本文的方法具有明顯優勢。這是因為本文使用了密集殘差網絡的結構,能夠有效地對特征進行提取,利用跨連接融合的方式得到局部細節和全局輪廓,因此能夠很好地提升表情識別的準確率。文獻[1]使用了Inception layer作為基本的模型結構,這種模型使用了多個不同的卷積核進行卷積,但是特征圖與特征圖之間沒有有效密集連接,無法更有效地進行特征梯度的傳遞。文獻[6]使用了多分辨率特征融合的方法,利用兩個不相關的卷積層進行疊加融合,但網絡結構比較簡單,沒有更好地利用不同層特征圖之間信息傳遞,這樣在每個卷積層里面不能完全提取出表情的有效特征。
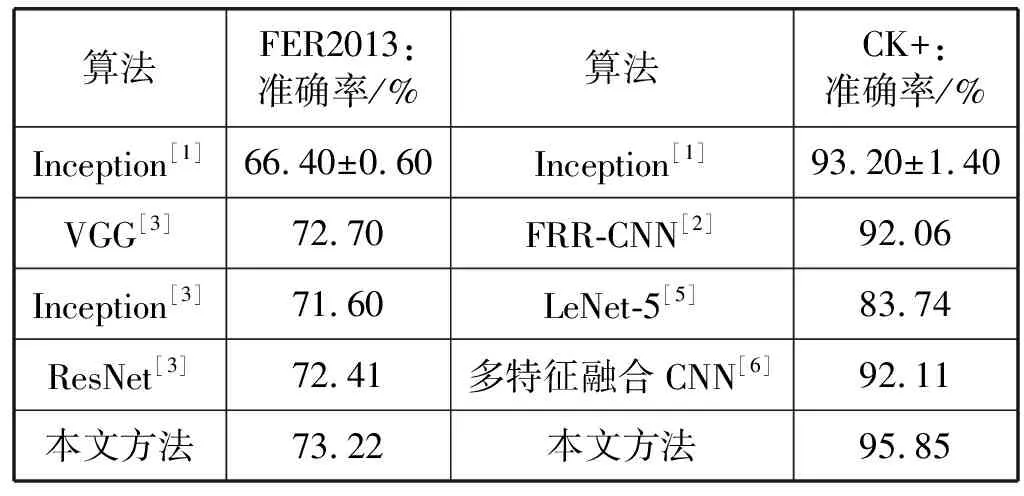
表2 不同算法的識別率對比
4 結 語
本文提出了一種多特征密集殘差型卷積神經網絡,該網絡通過對不同的卷積層進行融合疊加,充分利用了每個卷積層輸出的特征。密集殘差網絡的使用能夠有效減少在訓練過程中梯度消失問題。多特征提取的方式使得網絡能夠在最終分類層時使用不同分辨率特征,通過卷積網絡訓練結果的對比,表明了本文的提取方法準確率更高和魯棒性更好以及更快的收斂速度。
基于深度學習的卷積神經網絡,能夠自動提取輸入數據的特征,不需要人工干預,在圖像分類、檢測與識別等計算機視覺方向得到了很好的應用,其檢測結果遠遠高于一般機器學習的方法。但是深度學習需要大量的有標簽數據,這對于缺少標簽數據的表情識別領域提出了很大的挑戰,同時也是下一步要研究的重點。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
艦船科學技術(2022年15期)2022-09-14 09:21:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年19期)2018-11-14 02:37:08
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
自動化學報(2017年11期)2017-04-04 02:52:58
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
