數據中心服務器資源監控系統的設計與實現
2019-07-15 11:18:24臺憲青吳夢悅馬玉峰趙旦譜
計算機應用與軟件 2019年7期
臺憲青 吳夢悅 馬玉峰 趙旦譜
1(中國科學院電子學研究所蘇州研究院 江蘇 蘇州 215121)2(江蘇物聯網研究發展中心 江蘇 無錫 214135)
0 引 言
當前,隨著云、分布式、虛擬化等技術的發展,多層級、分布式、多中心的服務體系架構已經普遍存在于公司、企業、政府等多種單位機構中。服務器在服務體系架構中扮演著重要的角色,并且會影響該體系架構的服務質量。因此,為了保障服務體系架構的穩定運行,運維人員需要通過對服務器進行監控的方式,時刻記錄服務器資源的狀態信息[1-3]。
然而,隨著服務體系架構的不斷擴大,對服務器集群的運維和監管變得日益復雜。另外,由于服務器集群上的數據量巨大,對服務器狀態的監控和故障定位已然給運維人員帶來了很大的難度[4-5],導致投在運維上的人力物力成本逐漸加大。此時,如何設計一種直觀、高效的服務器資源監控系統,從而規范、合理的管理服務器集群,已經是一個亟待解決的問題[6-9]。
本文考慮了數據中心中服務器資源的有效監控問題,并結合中科院先導科技專項(編號:XDA19000000)軟件平臺對數據中心服務器集群的監控需求,建立一套完整的實時針對分布式集群服務器資源的監控系統。該系統可以實現如下功能:
(1) 統一管理數據中心的用戶權限、服務器及相關設備;
(2) 實時采集服務器運行的狀態信息,并進行統計分析和異常報警;
(3) 全面掌控應用系統的進程狀態和計算資源使用情況,以便第一時間察覺服務宕機等情況的發生,減少服務失效造成的損失。
1 總體設計
本系統主要由六個模塊組成:① 數據采集模塊,② 數據存儲模塊,③ 統計分析模塊,④ 異常報警模塊,⑤ 系統管理模塊,⑥數據可視化模塊。系統架構圖如圖1所示。
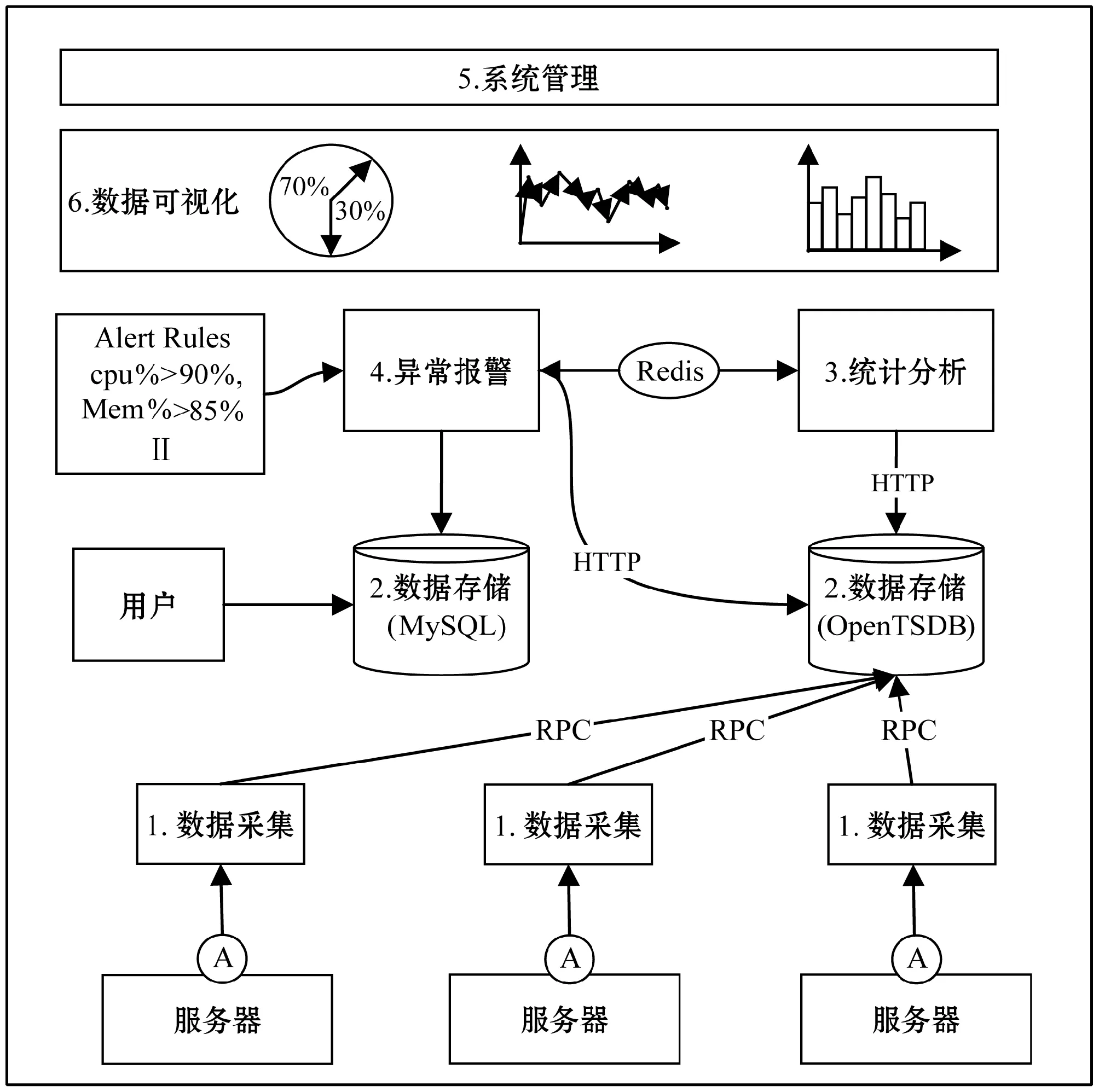
圖1 服務器資源監控系統架構圖
每個模塊的功能概括如下:
① 數據采集模塊:該模塊負責實時采集服務器資源狀態信息,并將信息發送到存儲模塊進行長期保存。為了減少采集代理對宿主機產生大負載,本系統的采集模塊將基于輕量級的采集工具Telegraf進行開發[10]。
② 數據存儲模塊:該模塊用于接收采集模塊的數據并進行持久化存儲。本系統設計將根據業務需求,采用關系數據庫MySQL和時序數據庫OpenTSDB組合的方式,對服務器進行實時監控。MySQL主要用于存儲用戶權限、機房設備等基本數據,而OpenTSDB主要用于存儲實時監控數據,并提供高并發訪問特性。
③ 統計分析模塊:該模塊對數據存儲模塊(OpenTSDB)中的實時數據進行多個維度(比如物理維度、時間維度等)的統計和處理。統計分析的結果主要用于分析服務器的資源使用特性和規律,并為服務器的異常判斷提供依據。
④ 異常報警模塊:該模塊將對采集的數據進行實時的異常檢測,并對硬件資源和進程狀態異常進行實時報警,避免服務器長時間故障和受到安全威脅造成的損失。
⑤ 系統管理模塊:該模塊將對中心機房設備、應用服務進程、用戶權限等信息進行統一管理,提高機房管理人員的監管效率。
⑥ 數據可視化模塊:該模塊提供多維、直觀的可視化效果,用戶可依據自己的需求來定制化配置界面。
2 詳細設計
2.1 數據采集模塊
由于數據中心的數據量巨大,為了不影響數據中心的整體性能,數據采集模塊將基于占用內存小、對宿主機器產生負荷小的Telegraf采集器進行開發。首先介紹采集模塊需要采集的信息項,然后詳細地介紹基于Telegraf的采集插件開發。
2.1.1采集信息項
本監控系統需要從數據中心服務器中采集到的詳細信息如表1-表7所示。這些信息主要分為三種類型:系統信息(表1)、計算資源狀態信息(表2-表5)、服務進程信息(表6和表7)。
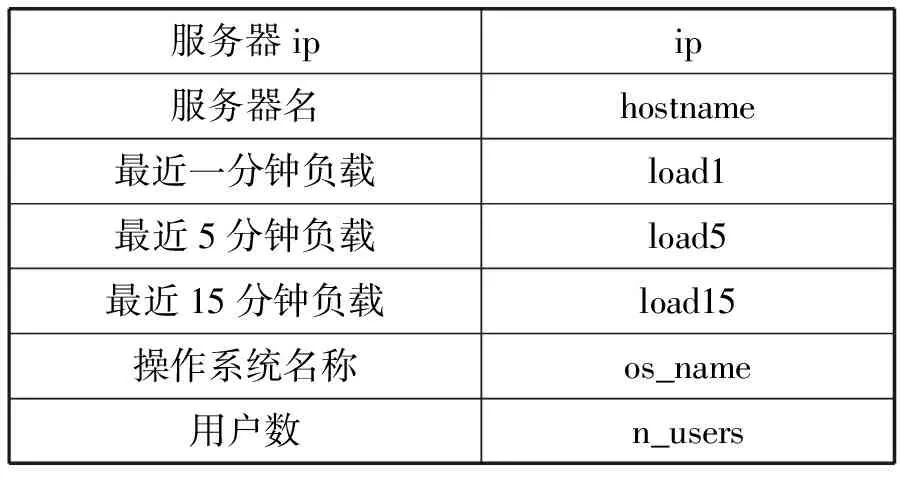
表1 系統信息

表2 CPU類信息
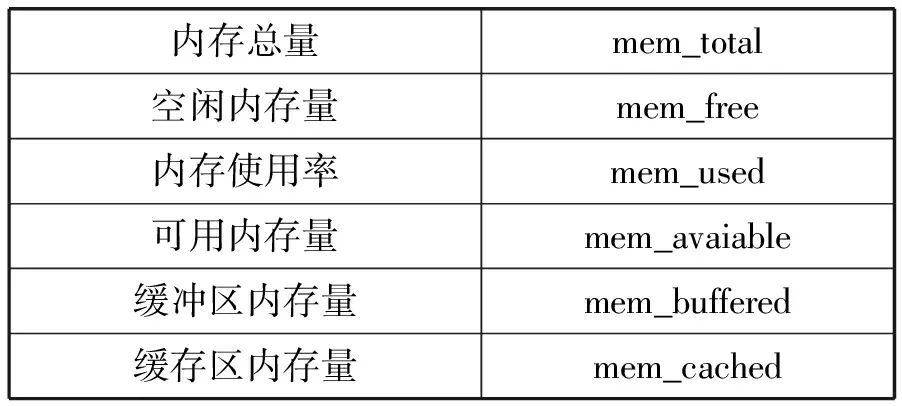
表3 Mem類信息

續表3
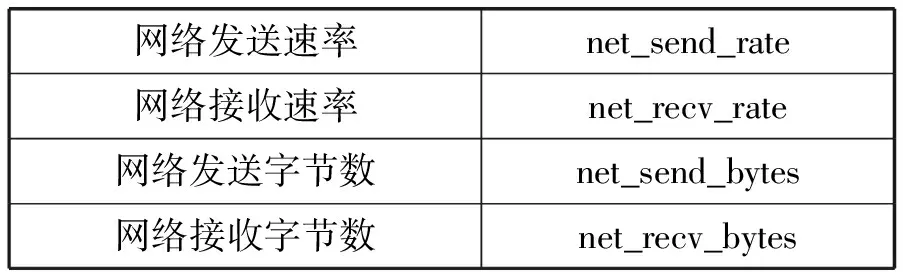
表4 Net類信息
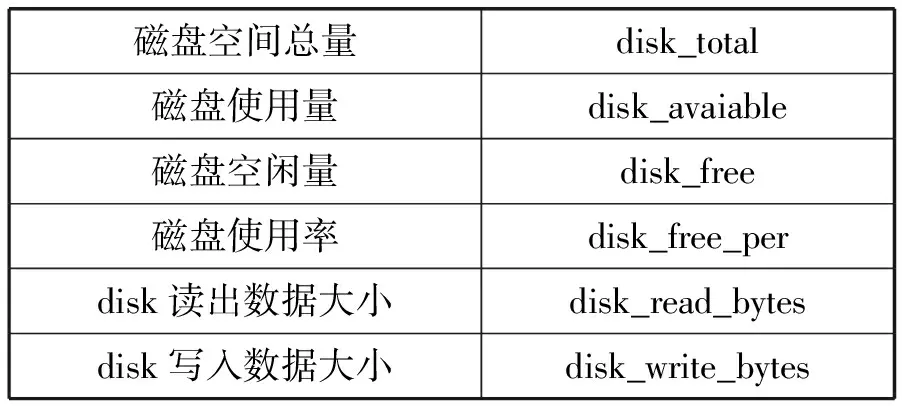
表5 Disk類信息

表6 Process總體信息
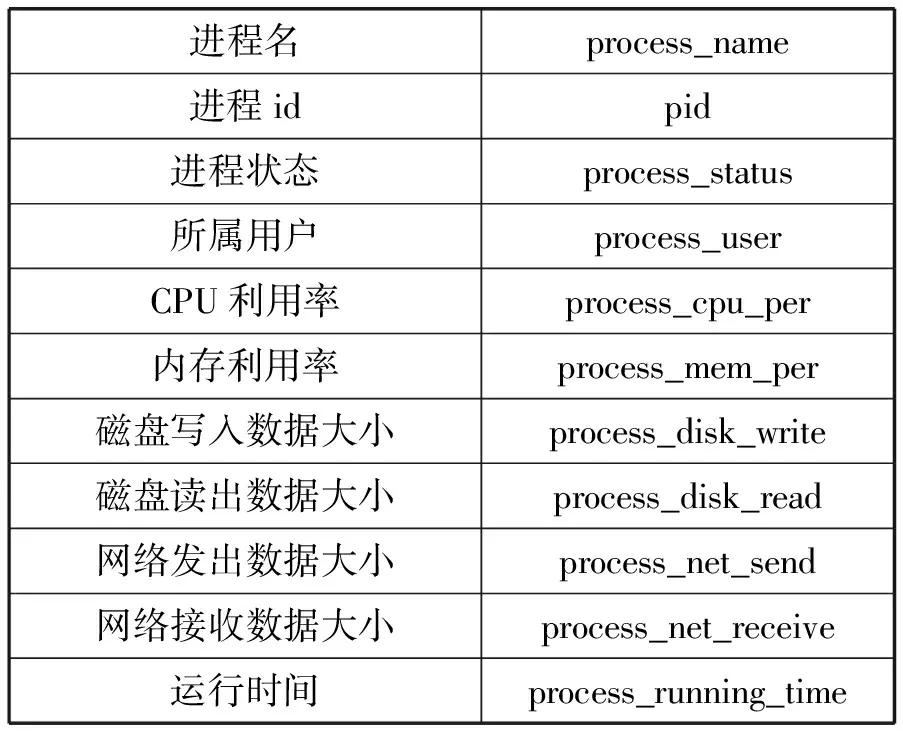
表7 Process詳細信息
計算資源狀態信息包括CPU、內存、網絡、磁盤的相關運行狀態信息。服務進程信息包括服務器進程總體信息和進程的詳細信息,其中進程總體信息是指系統進程總數以及處在各種狀態的進程數量;詳細進程信息是指單個進程信息的進程名、進程ID以及計算資源利用率。
2.1.2采集器Telegraf插件化開發
Telegraf結構由Input、Processor、Aggreator和Output四個模塊組成,如圖2所示。其中,Input是數據輸入端,支持多種協議方式的數據采集;Processor對采集的數據進行簡單的格式化、編碼和過濾;Aggregator提供數據的簡單聚合功能,如最大值、最小值操作;Output是數據輸出端,主要用于將采集到的數據發送到存儲端,能夠支持的多種類型的數據庫和存儲方式,如關系數據庫、時序數據庫、文件系統等。
由于Telegraf僅支持服務器端的系統信息和計算資源狀態信息采集,而不支持應用進程相關信息的采集,所以,為了能夠采集到服務器的進程信息,我們需要在Input插件模塊中添加“process”插件。
圖3是Process插件的主函數開發流程圖。在該流程中,首先,調用Init()函數初始化Input插件,將其命名為“process”。然后,定義Description()函數對其功能、屬性進行描述;定義SampleConfig()函數對其參數進行配置。最后,創建核心函數Gather()用來進行監控數據的統計,統計好的數據在Gather()函數中進行封裝,并回到主函數中完成插件的注冊。
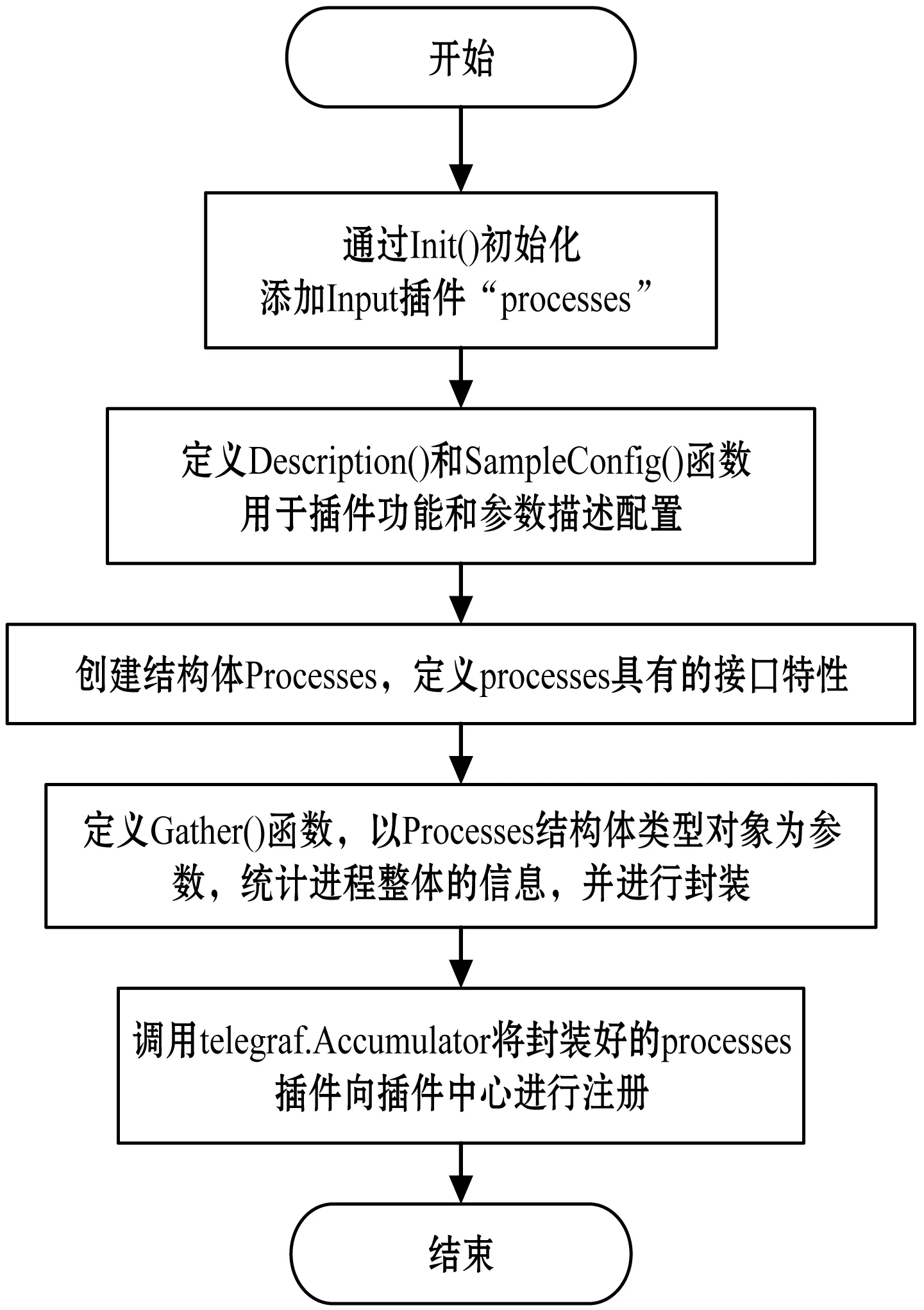
圖3 Telegraf input插件開發主函數流程圖
Gather()函數的開發流程如圖4所示。首先,傳入參數acc。接著,獲取空的fields數組進行屬性定義。然后,通過runtime.GOOS獲取系統類型,并調用getFromProc()函數(圖5)讀取服務器/proc目錄下的內核信息進行進程信息的統計,最后對measurement、fields數組封裝。
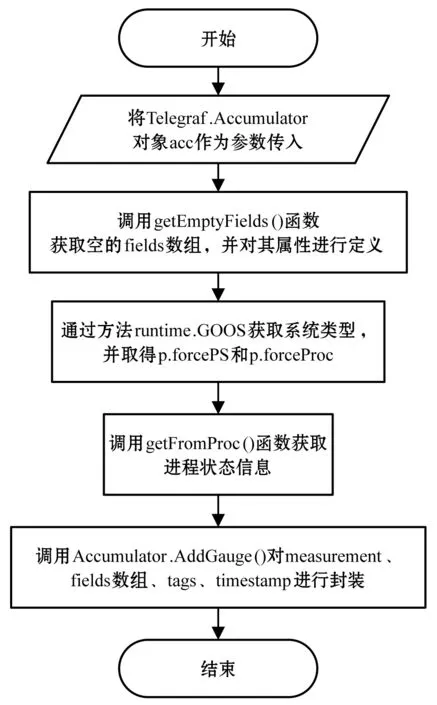
圖4 gather()函數流程圖
2.2 數據存儲模塊
本監控系統的存儲模塊主要用于存儲兩類信息:靜態的基本信息和動態的監控信息。基本信息包括用戶、權限、機房、機柜、服務器、應用服務等,多為結構化數據,主要用于聯表查詢,因此采用關系數據庫MySQL來存儲。MySQL中包含的表ER圖如圖6所示。
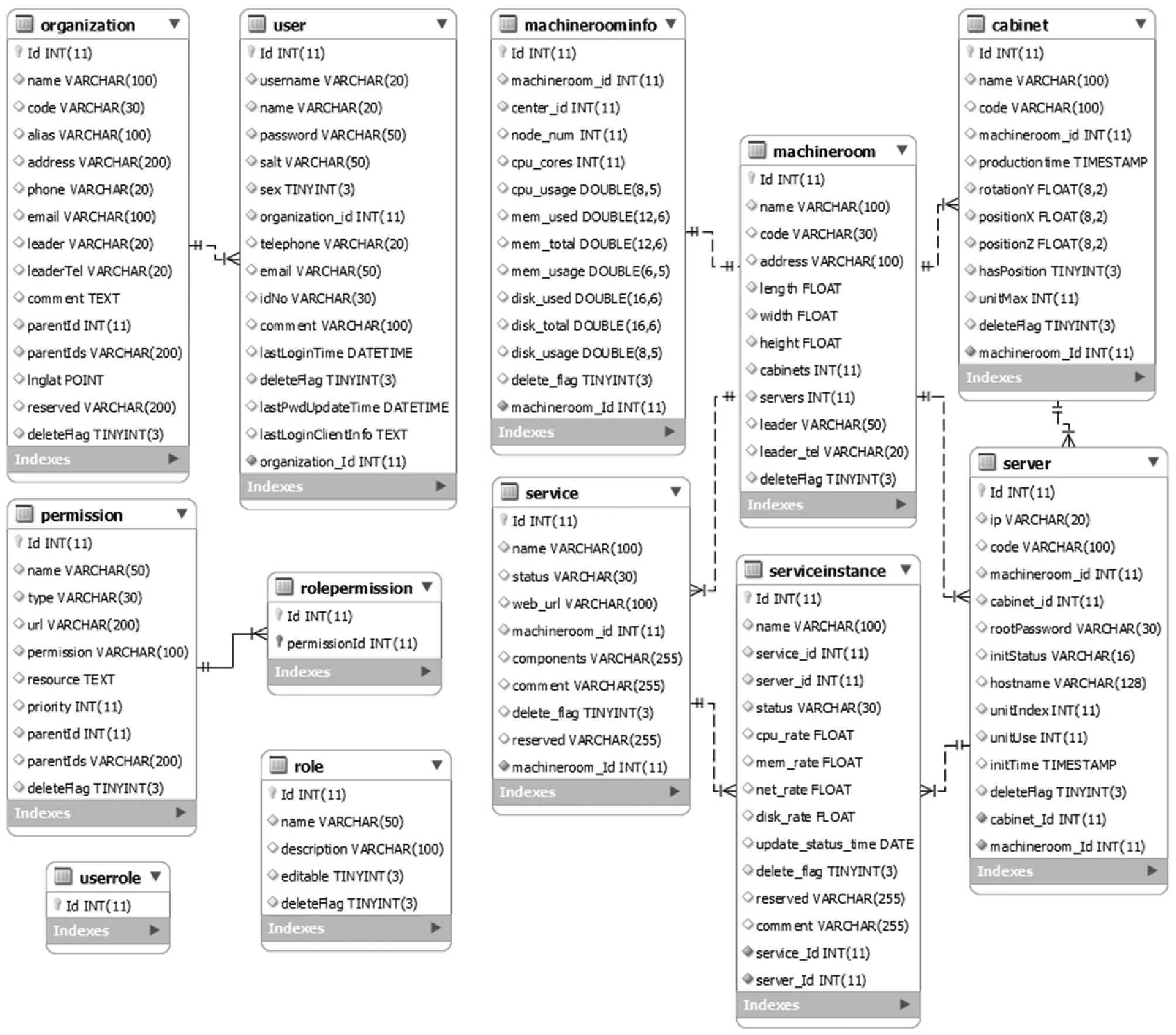
圖6 MySQL表ER圖
監控信息多為海量連續的時間序列數據信息。為了提高該種類型數據的存儲效率,采用基于HBASE改進的OpenTSDB時序數據庫來對監控信息數據進行存儲。在該數據庫的執行過程中,為了提高存儲和傳輸效率,采用key-Value的存儲形式,以此來減少傳輸和存儲過程中所占用的空間大小,其中key的值可以結合具體應用場景來設置為時間、機器編號等值。監控信息的數據存儲格式如下所示:
metric:cpu_usage
timestamp:1234567890
value:0.42
tags:host=web42,pool=static
其中:metric表示監控信息名稱;timestamp表示數據產生的時間;value表示監控信息(metric)的具體值;tags是對監控數據的描述,通過tags可實現數據的快速定位、檢索和統計分析。
2.3 統計分析模塊
統計分析模塊對數據分析過程分為三部分:數據讀取、聚合分析、數據存儲,如圖7所示。首先,讀取OpenTSDB中存儲的原始數據。然后,進行多維度的計算分析,依靠服務協調來保證計算過程的準確性、實時性、擴展性,獲取數據的周期特性和統計特性,便于管理人員和運維人員掌握數據中心服務器總體資源的概況。最后,將統計結果存入到OpenTSDB數據庫。

圖7 統計分析過程圖
在數據的讀取過程中,采集器以秒級頻率采集數據。由于單線程讀取數據的時間效率很低,當時間跨度較大時,讀取過程采用多線程方式。而當時間長度大于小時級別時,為進一步提高讀取效率,對時間間隔進行劃分,采用低粒度的時間間隔讀取數據,每一個小的時間間隔用一個線程來讀取,讀取的數據發送到統計分析服務器進行分析處理。數據讀取邏輯如圖8所示。
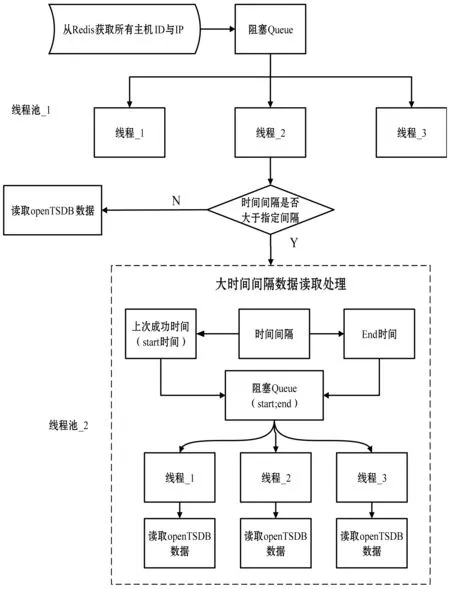
圖8 多線程數據讀取邏輯圖
另外,OpenTSDB支持http接口協議,對服務器IP、時間戳、監控信息項進行封裝,通過httpClient向OpenTSDB發出請求,其將結果通過同樣的格式返回,統計分析模塊對結果進行Json解析,最后以Java對象格式獲取數據。HTTP請求OpenTSDB邏輯如圖9所示。
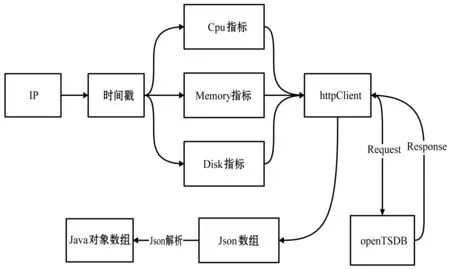
圖9 OpenTSDB HTTP協議訪問流程圖
聚合分析模塊使用HTTP接口從OpenTSDB讀取監控信息進行分析處理,并將結果使用HTTP接口寫回時序數據庫,以備前段頁面進行展示和歷史紀錄查詢。
聚合分析主要是對一段時間內各類監控信息數據求均值,用于資源狀態的評估。對于秒級和分鐘級的聚合操作直接利用時序數據庫的高并發特性聚合讀取,而對于小時、日、月、年等級別的數據聚合則要通過數據分級統計,粗粒度時間聚合在細粒度數據聚合基礎之上進行計算。分級統計邏輯如圖10所示。
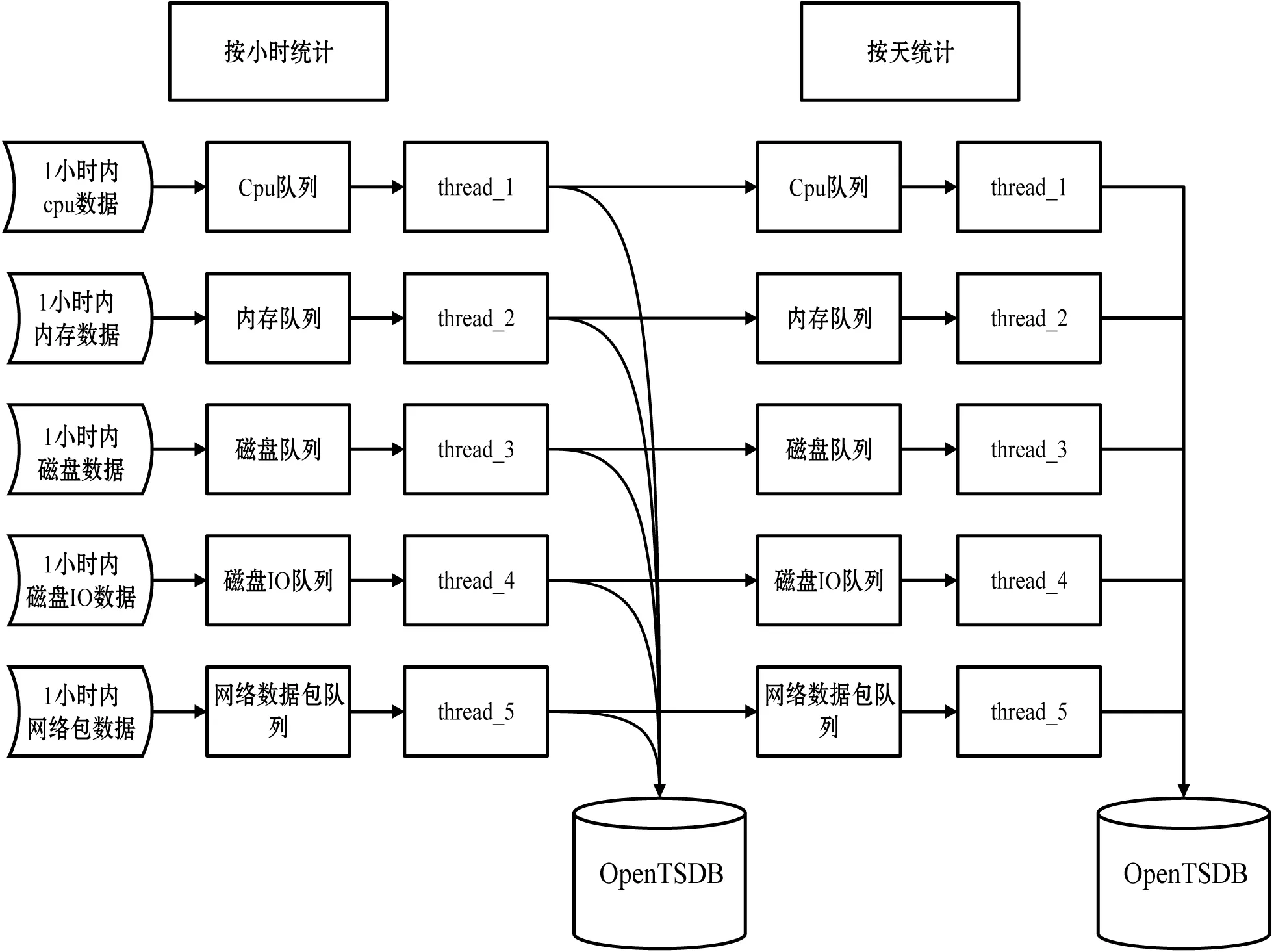
圖10 分級統計邏輯圖
在圖10中,分級統計采用雙隊列多線程池方式,細時間粒度的數據完成自身數據的聚合操作,同時將數據存入數據庫作為粗時間粒度數據聚合的基礎,實現一次數據讀取、多次數據處理的效果。同時計算型線程和IO型線程分離,提高了統計分析的效率。
本系統需支持多個機房百臺至千臺級別服務器的監控,實時采集周期最小支持為1秒,監控信息項為60條,統計分析維度達10個維度。為滿足海量數據的實時處理要求,系統采用分布式集群方式對監控信息進行處理,通過服務協調來保障新增服務器數據被處理、且只被單個統計服務實例處理。其中為防止統計分析服務實例宕機造成的個別服務器數據不被處理,使用Hash取模法對服務器id進行計算,獲得該服務器所屬的服務實例。當出現服務實例宕機的狀況便對所有服務器id進行重Hash計算。統計分析模塊實現流程圖如圖11所示。
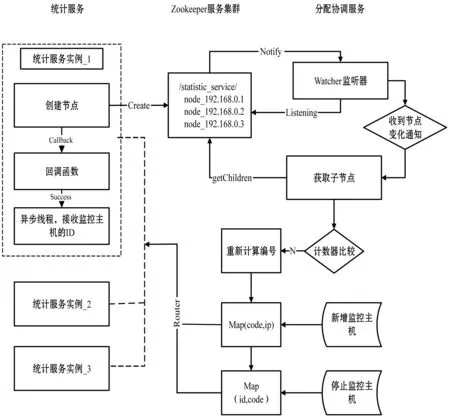
圖11 統計分析模塊實現流程圖
各個統計服務是并行計算的,統計服務實例可以根據監控服務器數量增加或減少,實現了統計服務的彈性部署,合理利用資源。
采用zookeeper集群監控當前在線的統計服務實例的運行狀態,當一臺統計服務器上線時,會向其注冊臨時節點,該臨時節點的值為當前服務器的IP地址和端口號構成的可路由的地址,當一臺統計服務實例下線的時候,臨時節點便被刪除。當服務器增加或者服務器減少,zookeeper集群都會通知協調分配服務,重新進行任務的劃分。
協調分配服務通過watcher監聽器監聽服務器的變化,更新本地緩存表并對新增加的服務器進行編號,利用Hash算法對服務器id進行取模計算,獲取對應的統計服務實例,或者刪除某服務器id。
2.4 異常報警模塊
進程掛機或者資源占用異常會影響服務器的處理速度或提供服務的能力,因此需要設定報警規則對異常事件進行報警。異常報警模塊將提供報警規則設定和管理、歷史報警事件記錄的功能。
本文主要針對系統負載、計算資源和服務狀態三個方面進行異常檢測和報警通知。其報警模塊架構圖如圖12所示。
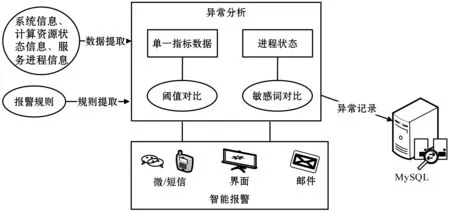
圖12 異常報警模塊架構圖
在本系統的報警規則中,當各個指標滿足一定的報警條件時,報警模塊將根據不同的閾值觸發不同級別的報警。表8定義了warning和critical兩種默認的報警級別。
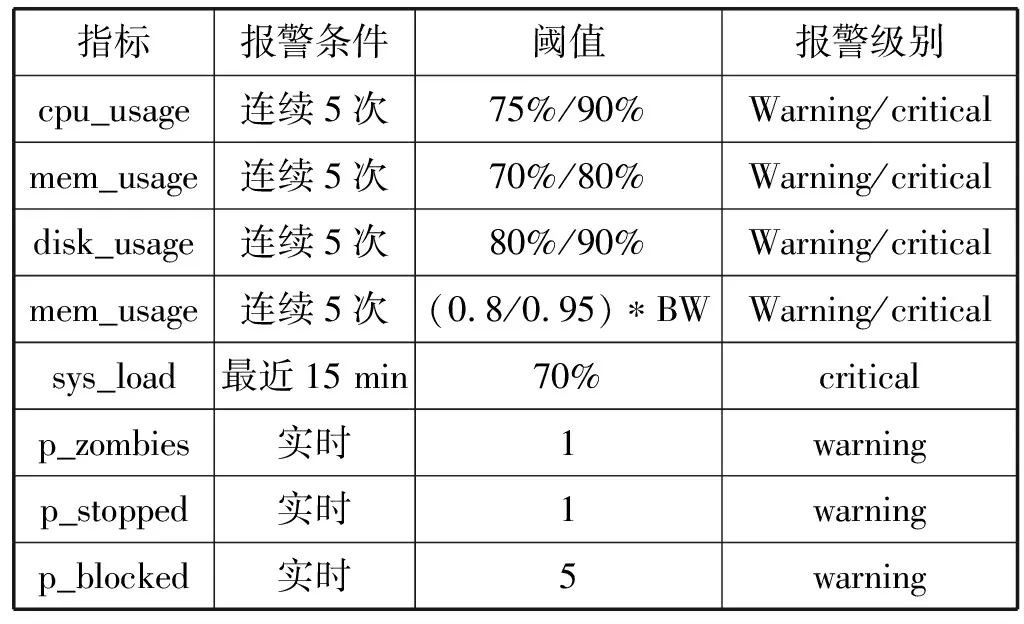
表8 默認報警規則表
另外,本系統還提供報警規則配置接口,供用戶進行規則的自定義。異常報警模塊的原理如圖13所示。

圖13 異常報警模塊邏輯圖
從OpenTSDB數據庫中讀取最新采集到的數據經過預處理操作,并和redis緩存的報警閾值數據進行對比,對于連續超過閾值和限定次數的事件判定為異常,可為各種報警方式提供觸發信息。
2.5 管理模塊
系統管理模塊包括對用戶權限信息管理和中心機房設備管理兩部分,如圖14所示。

圖14 系統管理模塊功能結構圖
在用戶權限的管理中,系統根據用戶的角色和所屬機構進行角色權限訪問控制。在機房設備管理中,系統采用樹形層級結構來管理中心機房中的所有設備,以便維護人員可以根據層級關系查看總體概況。
3 系統實現
在本節中,我們將依次展示所開發的資源監控系統在數據采集、異常報警和系統管理方面的效果。
圖15展示了系統在部分硬件指標上的數據采集結果。通過可視化分析工具,我們可以通過文字、柱狀圖、折線圖等多種方式,直觀、清晰地發現服務器在CPU、磁盤以及網絡方面的實時狀態結果。
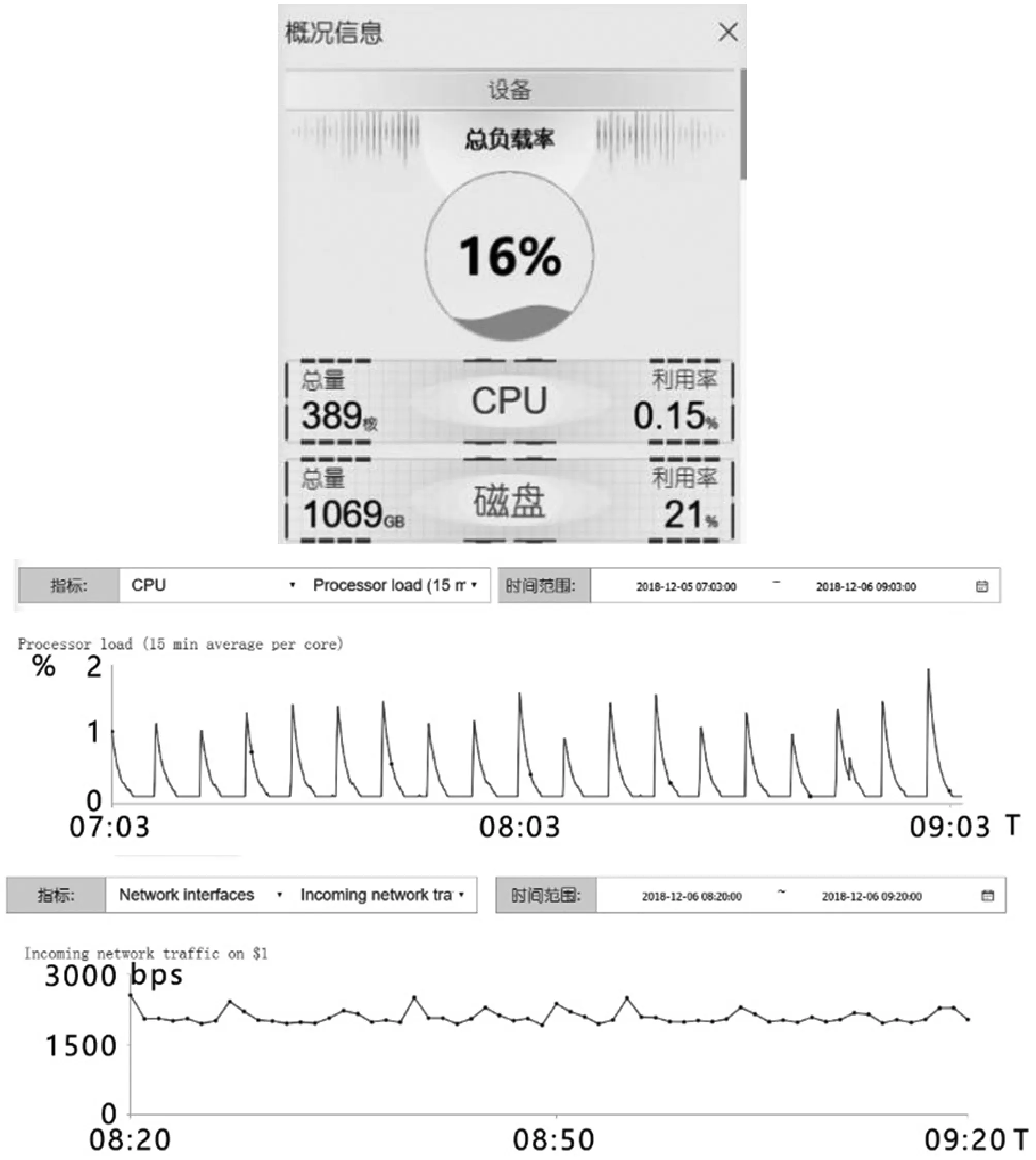
圖15 硬件指標數據實時顯示
圖16展示了報警規則設置界面,供用戶根據實際情況進行報警規則自定義,用戶可定義指標閾值和報警條件,并選擇報警方式。
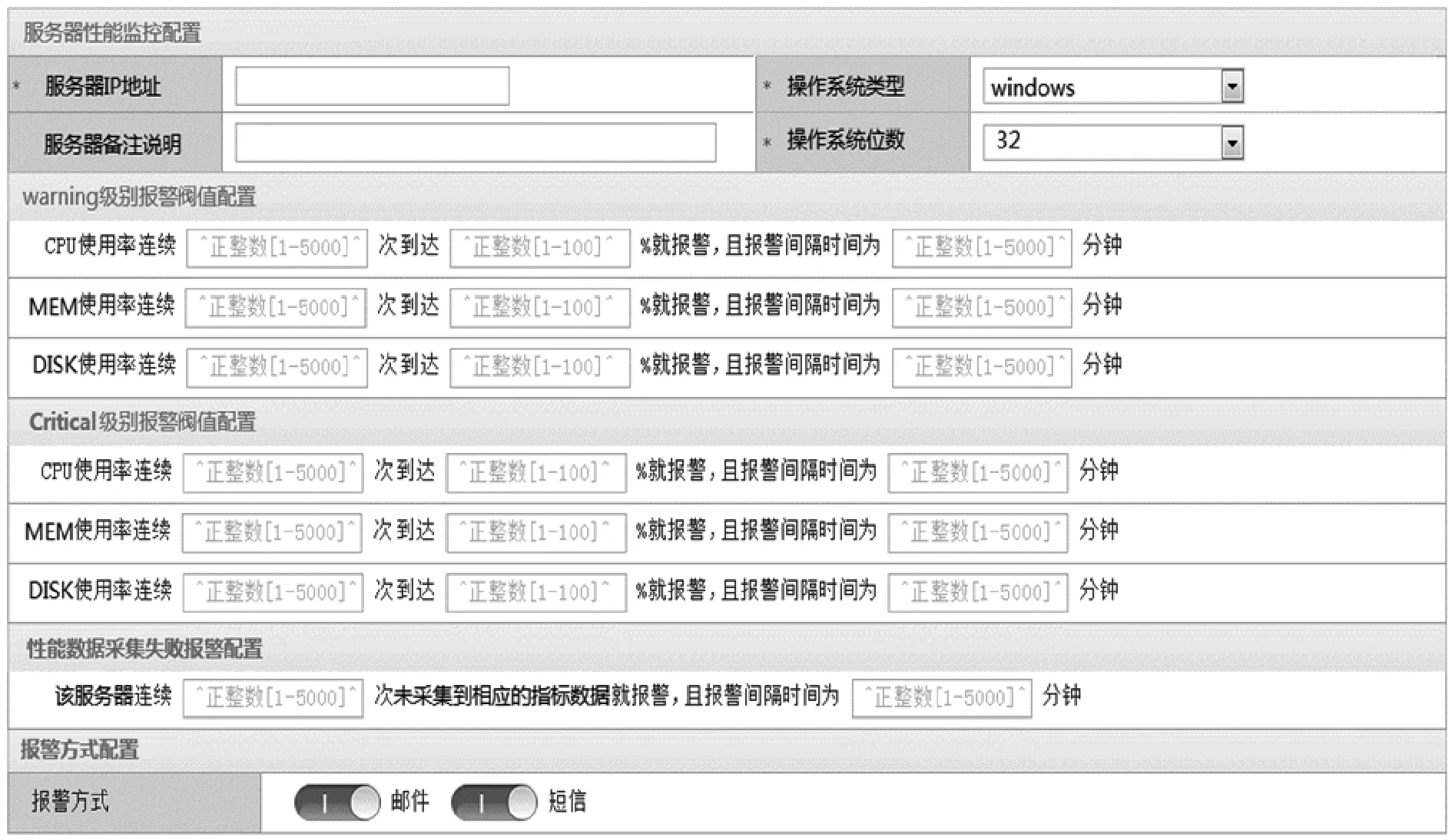
圖16 報警規則配置界面
圖17展示了系統給操作者提供的信息管理統一接口,以列表和表格的形式展示用戶、角色、機構、權限、機房、機柜、服務器、應用服務、服務實例的信息,用戶可在界面對數據進行查看、編輯和刪除操作。
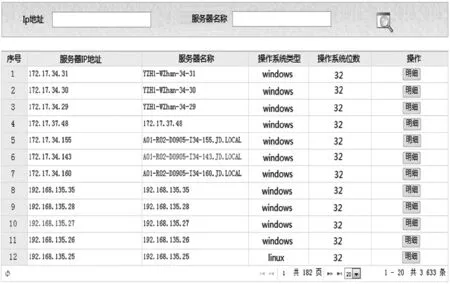
圖17 系統管理模塊界面
4 結 語
本系統針對數據中心大規模服務器資源的監控需求,設計并實現了一套完整的解決方案。在該方案中,采集端使用輕量級負載小的采集代理Telegraf,對服務器系統信息、計算資源狀態信息、服務進程信息進行采集,并將采集結果發送到時序數據庫OpenTSDB中存儲。OpenTSDB以較小的存儲空間和時序函數優越的查詢性能,保證監控時序數據的高效存儲和快速處理海量數據的能力。統計分析模塊采用分布式集群技術、多機協同數據處理方法和分級聚合分析算法,對海量監控數據實現實時的分析處理。異常報警模塊提供多種報警方式和報警手段。資源可視化模塊提供了豐富的可視化形式和直觀的監控信息展示方式。最后,系統實現用戶信息、機房設備、服務應用的統一管理,將繁雜的信息管理系統化和條理化。
猜你喜歡
中國外匯(2019年20期)2019-11-25 09:54:58
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
民主與科學(2014年3期)2014-02-28 11:23:03
教育與職業(2014年7期)2014-01-21 02:35:04
計算機與網絡(2013年1期)2013-06-05 05:31:50
