基于稀疏鄰域的主動不平衡學(xué)習(xí)算法
2019-07-15 01:52:12古平凌照
現(xiàn)代計算機(jī) 2019年16期
關(guān)鍵詞:定義
古平,凌照
(重慶大學(xué)計算機(jī)學(xué)院,重慶 400044)
0 引言
不平衡學(xué)習(xí)是機(jī)器學(xué)習(xí)中一種重要的分類問題,其中包含樣本數(shù)目較多的為多數(shù)類,而樣本數(shù)較少的為少數(shù)類。在許多實際應(yīng)用中都存在不平衡問題,例如網(wǎng)絡(luò)入侵檢測[1]、信用卡欺詐檢測和垃圾郵件檢測。自不平衡學(xué)習(xí)問題被提出以來,已有大量的學(xué)習(xí)方法被開發(fā)用于解決該問題,這些工作大多分為兩類:重采樣技術(shù)和代價敏感學(xué)習(xí)技術(shù)[2]。重采樣是一種重新平衡類分布的技術(shù),它通過對少數(shù)類進(jìn)行過采樣或?qū)Χ鄶?shù)類進(jìn)行欠采樣而實現(xiàn)。代價敏感方法則為每個類提供不同的錯誤分類代價,而且一般少數(shù)類的分類錯誤的代價較大。與現(xiàn)有的方法不同,Ertekin等人提出了基于主動學(xué)習(xí)[3]策略的不平衡學(xué)習(xí)算法[4](AL-SVM)來處理虛擬樣本合成以及信息量的度量問題。最近,P Vateekul等人提出了一種基于G-means的主動學(xué)習(xí)模型來解決不平衡問題,并發(fā)現(xiàn)尤其適用于大規(guī)模數(shù)據(jù)集[5]。
直覺上主動學(xué)習(xí)在不平衡學(xué)習(xí)中的應(yīng)用是從未標(biāo)記的數(shù)據(jù)集中主動選擇可能的少數(shù)類樣本,然后標(biāo)記并添加它們到初始訓(xùn)練集中以產(chǎn)生平衡的數(shù)據(jù)集。不幸的是,該技術(shù)可能會在不平衡的設(shè)定下遭受標(biāo)記成本較大的風(fēng)險,也就是說,由于初始數(shù)據(jù)分布是傾斜的,所以未標(biāo)記的多數(shù)類樣本將比少數(shù)類樣本更頻繁地被查詢和標(biāo)記,最后導(dǎo)致主動學(xué)習(xí)在降低不平衡率的效果上將受到較大的限制。
經(jīng)過對主動學(xué)習(xí)和半監(jiān)督學(xué)習(xí)[6]的研究啟發(fā),我們通過計算樣本的少數(shù)類置信度,提出了一種新的針對不平衡學(xué)習(xí)的主動學(xué)習(xí)算法:基于稀疏鄰域的主動不平衡學(xué)習(xí)算法(ASS-SN)。它有效地克服了虛擬樣本合成的局限性,并且具有針對少數(shù)類樣本有效查詢的優(yōu)點。其基本思想是僅使用小規(guī)模的有標(biāo)記數(shù)據(jù)和大量未標(biāo)記數(shù)據(jù)計算出未標(biāo)記樣本的少數(shù)類置信度,然后選擇置信度最高的未標(biāo)記樣本作為迭代查詢的標(biāo)準(zhǔn)。其中我們利用半監(jiān)督學(xué)習(xí)技術(shù)來確定每個未標(biāo)記樣本的少數(shù)類置信度,受稀疏編碼的啟發(fā),與其他基于圖結(jié)構(gòu)的半監(jiān)督方法不同,我們通過求解一個L1最優(yōu)化問題來計算出圖結(jié)構(gòu)的頂點與邊權(quán)重信息,從而不需要預(yù)先設(shè)定相關(guān)參數(shù)的大小。
1 算法過程及框架
1.1 相關(guān)概念以及動機(jī)
給定不平衡數(shù)據(jù)集X={x1,x2,…,xm+n},xi∈Rd,1≤i≤m+n,其中d為維數(shù)。可以將該不平衡數(shù)據(jù)集X劃分為XL和XU,其中XL=(x1,y1)…(xm,ym)是有標(biāo)記的數(shù)據(jù)集,而且每一個樣本包含有獨一無二的屬于(0,1)的樣本標(biāo)簽,yi代表其類別標(biāo)簽。XU=(xm+1,ym+1)…(xm+n,ym+n)代表未標(biāo)記的數(shù)據(jù)集,其類別標(biāo)簽未知。在有標(biāo)記的數(shù)據(jù)集XL中,IR代表該數(shù)據(jù)集的不平衡比率。
我們所提出的問題是如何在以下情況使用未標(biāo)記數(shù)據(jù)來提高監(jiān)督學(xué)習(xí)算法的準(zhǔn)確性:①只有少量有標(biāo)記的樣本可用。②有大量未標(biāo)記的數(shù)據(jù)。③在有標(biāo)記的數(shù)據(jù)集中,少數(shù)類樣本數(shù)量遠(yuǎn)遠(yuǎn)少于多數(shù)類。經(jīng)過AL-SVM算法的啟發(fā),我們發(fā)現(xiàn)該方法存在一個主要的缺點:直接將SVM算法應(yīng)用到不平衡的數(shù)據(jù)集會導(dǎo)致該超平面存在偏倚,并且偏向于多數(shù)類樣本,因此該算法并沒有考慮查詢有效性的問題,即希望不平衡學(xué)習(xí)算法能夠有效地查詢未標(biāo)記的樣本盡可能為少數(shù)類樣本以達(dá)到均衡數(shù)據(jù)集的目的,從而降低人工標(biāo)注成本。為此,我們采用了一種完全不同的主動采樣策略,其目標(biāo)是盡可能多地標(biāo)記少數(shù)類樣本,從而均衡初始的有標(biāo)記數(shù)據(jù)集并提高分類性能。因此該策略包含本文的核心問題定義:少數(shù)類置信度。
定義1少數(shù)類置信度(MC):對于任意未標(biāo)記樣本xi∈XU,假設(shè)其屬于少數(shù)類或者多數(shù)類的概率為yui mi或yui ma,那么該樣本xi的少數(shù)類置信度(MC)可以通過以下公式計算:

Mci越大,表示該樣本屬于少數(shù)類的可能性就越高。如果我們根據(jù)少數(shù)類置信度相應(yīng)地對未標(biāo)記的樣本進(jìn)行主動采樣,則更有可能正確地選擇并標(biāo)記它們?yōu)樯贁?shù)類樣本。
1.2 半監(jiān)督學(xué)習(xí)技術(shù)求解少數(shù)類置信度問題
根據(jù)定義1,我們的主動采樣策略是根據(jù)未標(biāo)注樣本的少數(shù)類置信度選擇最可能的少數(shù)類樣本,也就是說,這個問題可以轉(zhuǎn)換為求解未標(biāo)記樣本分別屬于多數(shù)類和少數(shù)類的概率。為了解決這個問題,在機(jī)器學(xué)習(xí)中我們知道半監(jiān)督學(xué)習(xí)旨在對標(biāo)記樣本和未標(biāo)記樣本進(jìn)行學(xué)習(xí),尤其是基于圖的半監(jiān)督學(xué)習(xí)方法。大多數(shù)現(xiàn)有的半監(jiān)督學(xué)習(xí)方法是基于k最近鄰(knn)圖提出的,但k值在實際應(yīng)用中難以預(yù)先確定,且尤其是在不平衡數(shù)據(jù)集中。受稀疏編碼的啟發(fā),我們通過求解L1最優(yōu)化問題來構(gòu)建稀疏鄰域圖[7],這避免了在不同場景中預(yù)先定義k值的難題。最后通過在樣本的稀疏鄰域中實現(xiàn)標(biāo)簽傳播來測量未標(biāo)記樣本的少數(shù)類置信度。
(1)構(gòu)建稀疏鄰域圖
假設(shè)定義一個線性方程組:xi=Xiαi,其中xi是要表示的樣本,αi是重建系數(shù)的向量,Xi是除了xi的其他樣本,可以表示為:Xi=[x1…xi-1,xi+1…xm+n]。通過稀疏編碼的啟發(fā),激勵我們通過解決以下最優(yōu)化問題來尋求xi=Xiαi的最稀疏的解決方案:

通過求解結(jié)果我們發(fā)現(xiàn)在系數(shù)重建過程中某些距離表示樣本較遠(yuǎn)的“壞的”樣本的重建系數(shù)一般較小而且會對標(biāo)簽傳播起到負(fù)面作用。為了解決這個問題,我們定義了給定樣本xi的稀疏鄰域。
定義2稀疏鄰域(SN):給定參數(shù)ε,樣本xi的稀疏鄰域定義為:如果重建過程中樣本xj,i≠j的重建系數(shù)αj滿足αj>ε,則認(rèn)為樣本在xj給定樣本xi的稀疏鄰域中,或者xj∈SN(xi)。
根據(jù)定義2,對于給定的樣本xi,我們刪除了那些所謂的“壞的”樣本,即這些樣本的重建系數(shù)很小。也就是說,我們強(qiáng)調(diào)那些在稀疏鄰域中的樣本的作用并且認(rèn)為這些樣本與被表示的樣本“相似”。因此,構(gòu)造的稀疏鄰域圖的目標(biāo)函數(shù)由下式給出:

其中G表示稀疏鄰域圖,如果αij<ε,則αij=0。這表明如果樣本xj不在樣本xi稀疏鄰域中,則重建系數(shù)將為0。
(2)基于稀疏鄰域的標(biāo)簽傳播
假設(shè)對于樣本xi,xi的標(biāo)簽可以由來自xi的稀疏鄰域的那些樣本標(biāo)簽線性重建。并且我們假設(shè)標(biāo)簽空間和樣本空間共享相同的局部線性重建權(quán)重,因此通過以下式子估計所有樣本的標(biāo)簽:

基于基本的代數(shù)知識,可以很容易地推斷出:
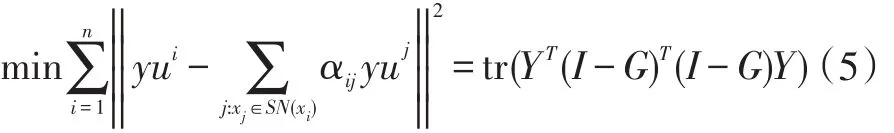
I是一個單位矩陣,令W=(I-G)T(I-G),我們可以得到結(jié)論:tr(YTWY),tr(·)表示矩陣的跡。將Y進(jìn)行劃分:Y=[YL;YU],YU表示待求解的未標(biāo)記樣本的標(biāo)簽矩陣,YL表示有標(biāo)記樣本的標(biāo)簽矩陣。將矩陣W劃分為四個部分:

通過結(jié)論(5):tr(YTWY),我們求出關(guān)于Y的偏導(dǎo)數(shù):

最后求解上式,獲得所有未標(biāo)記樣本的標(biāo)簽概率矩陣:

通過將上述推導(dǎo)過程應(yīng)用于訓(xùn)練數(shù)據(jù)集,每個未標(biāo)記樣本將分別獲得屬于少數(shù)類和多數(shù)類的概率,該求解結(jié)果可以表示為因此跟據(jù)定義1,我們可以計算每個未標(biāo)記樣本的少數(shù)類置信度,即
1.3 算法框架
基于稀疏鄰域的主動不平衡學(xué)習(xí)算法(ASS-SN)包括兩個關(guān)鍵步驟。首先我們通過求解L1最優(yōu)化問題的方式構(gòu)建稀疏鄰域圖,并在其基礎(chǔ)上進(jìn)行標(biāo)簽傳播,以計算每個未標(biāo)記樣本的少數(shù)類置信度。其次,通過主動學(xué)習(xí)技術(shù)結(jié)合這種查詢策略進(jìn)行迭代學(xué)習(xí),并在每一次迭代中更新標(biāo)簽傳播矩陣,直到數(shù)據(jù)集幾乎平衡。ASS-SN算法的框架如下:
輸入:XL:有標(biāo)記的數(shù)據(jù)集
XU:大量的未標(biāo)記數(shù)據(jù)集
輸出:XL:有標(biāo)記數(shù)據(jù)集
(1)根據(jù)定義2以及公式(3)求解以下最優(yōu)化問題,并構(gòu)建稀疏鄰域圖G:

(2)while(IR>1):
①根據(jù)圖G,構(gòu)建傳播矩陣W:W=(I-G)T(I-G),基于W進(jìn)行標(biāo)簽傳播,并計算出未標(biāo)記樣本的標(biāo)簽矩陣
②對每一個未標(biāo)記樣本xi∈XU,根據(jù)定義1和標(biāo)簽矩陣計算樣本xi的少數(shù)類置信度,Mci:

③根據(jù)Mci,選擇其中少數(shù)類置信度最大的ul個樣本交與專家標(biāo)注,并將其中標(biāo)注的少數(shù)類樣本添加到過渡集V中。最后讓XL=XL?{V},XU=XU{V}
④基于貝葉斯分類器重新訓(xùn)練XL并跟新標(biāo)簽傳播矩陣W
(3)end while
2 實驗結(jié)果與分析
實驗主要在來自UCI機(jī)器學(xué)習(xí)庫的數(shù)據(jù)集上進(jìn)行,即Prima數(shù)據(jù)集。為了深度分析不平衡數(shù)據(jù)集對ASS-SN算法的影響,我們通過隨機(jī)刪除Prima數(shù)據(jù)集中樣本的標(biāo)簽來獲得主動學(xué)習(xí)中所需的未標(biāo)記樣本。表1顯示了在這種情況下選擇的數(shù)據(jù)集。為了評估不同算法在不平衡問題上的分類性能,我們采用了針對不平衡問題的經(jīng)典評估方法,即F-measure[8]。在本文算法第1.2小節(jié)中,需要對是否處于稀疏鄰域中的樣本進(jìn)行判定,我們根據(jù)經(jīng)驗和稀疏表示的特征選擇ε的值,并且將稀疏鄰域ε的半徑固定在0.02。本文算法與兩種流行的主動學(xué)習(xí)算法進(jìn)行比較,即AL-EN[3]和AL-SVM,其中AL-EN是一種基于信息熵測量的主動學(xué)習(xí)方法。

表1 實驗所采用的數(shù)據(jù)集
從圖1可以看出,對于每種主動學(xué)習(xí)技術(shù),每次查詢的樣本中少數(shù)類樣本的數(shù)量都受到不平衡數(shù)據(jù)集的強(qiáng)烈影響。例如,如果查詢284個未標(biāo)記的樣本,通過本文算法可以有效地標(biāo)記181個少數(shù)類樣本,而在AL-EN和AL-SVM中則只能標(biāo)記98和73個少數(shù)類樣本。從算法整體來分析可以看出由于本文算法有效地利用稀疏標(biāo)簽傳播算法使得在主動學(xué)習(xí)采樣的過程中,少數(shù)類未標(biāo)記樣本的采樣概率大幅度提升。因此在每一輪標(biāo)注占比上,本文算法完全優(yōu)于其他主動學(xué)習(xí)算法,并且會提前完成對大部分少數(shù)類樣本的標(biāo)注。
從圖2中,可以看到在每次的迭代過程中,F(xiàn)1值隨著主動采樣過程而逐漸增加,但是可以觀察到,ASSSN的F1值優(yōu)于AL-EN和AL-SVM。例如,AL-EN和AL-SVM的最佳 F1值分別為 0.6278和 0.5098,而ASS-SN算法可以達(dá)到0.7107。總之,這種性能提升是由于通過這種有傾向性的主動學(xué)習(xí)算法在少數(shù)類上具有強(qiáng)大的搜索能力,特別是當(dāng)這些樣本遠(yuǎn)離最初的少數(shù)類群體時;傳統(tǒng)的主動學(xué)習(xí)算法傾向于丟棄這些樣本,而本文的標(biāo)簽傳播機(jī)制可以有效地找到它們。

圖1 少數(shù)類的標(biāo)記效率

圖2 每次迭代采樣后的分類性能
3 結(jié)語
本文中我們提出了一種自適應(yīng)的主動學(xué)習(xí)方法針對不平衡學(xué)習(xí)問題,本文算法的一個優(yōu)點是利用稀疏鄰域的標(biāo)簽傳播策略計算未標(biāo)注樣本的少數(shù)類置信度,并專注于采樣其置信度較高的樣本,從而有效地解決不平衡問題并降低標(biāo)記成本。其次通過引入主動學(xué)習(xí)技術(shù)的迭代過程,使得本文算法能夠有效地提高不平衡數(shù)據(jù)集的分類性能。雖然ASS-SN算法在大多數(shù)情況下都能獲得更好的性能,但仍有許多問題需要解決,例如我們所提出的算法比其他算法消耗更多的時間。
猜你喜歡
幼兒教育·父母孩子版(2022年4期)2022-05-08 21:35:35
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年3期)2021-06-09 06:09:14
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:38
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年2期)2021-03-19 08:54:04
海峽姐妹(2020年9期)2021-01-04 01:35:44
華人時刊(2020年13期)2020-09-25 08:21:32
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
山東青年(2016年1期)2016-02-28 14:25:25
汽車維護(hù)與修理(2015年6期)2015-02-28 12:16:55
當(dāng)代修辭學(xué)(2014年3期)2014-01-21 02:30:44
