數據分析服務流程模型推薦
2019-07-09 11:43:48曾兆偉
小型微型計算機系統 2019年7期
曾兆偉,曹 健
(上海交通大學 計算機科學與工程系,上海 200240)
1 引 言
當前數據分析服務在許多領域已經變得至關重要.但同時,由于數據和方法的多樣性,執行數據分析可能是一項非常復雜的任務.例如數據分析中經典的案例——嘗試預測數據內存在異常情況時的信用風險,其模型便十分復雜.一般這些數據分析服務工作流模型都是由專業的數據分析人員進行建立的,對于經驗不足的人員來說,建立此數據分析服務工作流模型是一件具有挑戰性的任務.而對于經驗豐富的專業人員來說,這項任務同時也是十分費時費力的.
與此同時由于數據分析模型的多樣性,用戶想找到相似的模型進行借鑒或者復用時,也往往十分困難.如在流行的數據分析服務平臺OpenML上,用戶在上面上傳數據集,對數據集創建相應的數據分析任務,構建模型,并挑選模型在數據集上運行、分析.但在OpenML上其存在著20,000左右用戶上傳的數據集,針對這些數據集用戶創建了68,000左右的數據分析任務,并且構建約6,000個左右模型,在這些數據集上共運行了9,000,000次模型.用戶如果想要通過數據集的相似性或者模型的運行記錄來人工挑出一個符合當前數據集的模型,過程將十分困難并浪費精力.
因此對于數據分析人員進行專業和符合需求的數據分析工作流模型推薦是十分必要的.其一方面可以節省分析人員的時間,另一方面可以復用過去已建立的模型,無需用戶自己從頭構建模型,對建好的模型重復使用,節省成本.當前研究和市場上,也已經存在有相關的產品,如Microsoft的Azure機器學習平臺,和德國的RapidMiner數據挖掘平臺.但它們都或多或少存在一些不足之處或者可改進的地方,如RapidMiner通過用戶在設計數據分析工作流模型的過程中,針對用戶當前所設計完成的步驟,通過算法和庫中存在的模型進行比較,然后為用戶推薦模型下一步的設計方案.但是,其沒將數據的上下文信息考慮在內,即數據的特征和用戶的對分析結果的偏好(如非誤率等),而這些信息對于模型推薦的準確率的影響是十分之大的.比如,兩個數據集如果具有相似的特征,那么他們的數據分析工作流模型就有可能是相似的,可以復用的.同時,對于模型而言,其一般存在著文本語義標簽,用以對于模型進行描述.因此在設計模型時,同樣可以通過文本語義進行推薦,提高準確率和效率.
對于數據分析服務模型推薦,本文擬從每個用戶最基本的上傳信息入手,即數據集數據和文本描述信息.相比起傳統的在用戶建模過程中推薦下一步應該如何構建,本文通過數據集數據和文本描述信息在一開始為用戶進行推薦,其一方面節省用戶的時間,不需要從頭開始構建自己的數據分析服務流程模型,另一方面也可和傳統的建模過程中模型推薦相互補充.
本文基于OpenML數據分析服務平臺,通過針對數據集的數據特征和文本描述為用戶提供數據分析服務模型推薦.第二部分為背景與相關工作的介紹;第三部分直觀地介紹了進行模型推薦的總體流程;第四部分介紹了文中所用算法的一些基本概念;第五部分詳細介紹了所使用的算法;第六部分為實驗的結果;最后對本文進行總結與展望.
2 相關工作
工作流(服務流程)模型推薦,現有主要分為傳統的業務工作流模型推薦和隨著數據挖掘、大數據興起的數據分析工作流模型推薦.
對于傳統的業務工作流模型推薦[1],各種研究已較為完善[2-5],算法已較為成熟.目前主流的算法主要分為:分類(Classification)、概率圖模型(Probabilistic Graphical Models)[6].其中分類又主要分為:聚類(Clustering methods)、決策樹(Decision trees).概率圖模型又分為貝葉斯網絡(Bayesian networks)、馬爾科夫鏈(Markov Chains).它們都能較好的進行業務工作流模型的推薦.
而對于數據分析工作流模型推薦,一開始研究者們紛紛借鑒了業務工作流模型推薦的方法.在用戶設計模型時,對模型進行解析,與數據庫中模型進行比較,為用戶推薦模型下一步構建步驟[7,8].常見的方法有:上下文感知的KNN方法(A Context-Aware kNN Method)[9]、上下文感知共現方法(A Context-Aware Co-Occurrence Method)[10]、基于鏈接的方法(A Linked-Based Method)、基于鏈的方法(A Chain-Based Method)等等.
以上方法將傳統的模型推薦算法結合上下文信息,應用于數據服務流程模型推薦上,確實提高了推薦的準確率,但其同時也存在一些問題:
1)只考慮了模型的信息,但是數據分析工作流與傳統的業務工作流不同,還需要考慮數據的特征.相比起傳統的業務工作流模型,數據分析服務流程模型其擁有豐富的數據集信息,通過數據集信息的特征比較挖掘,往往能使得模型推薦擁有更好的效果.
2)可以利用模型描述的文本描述語義標簽,將其加入預測因子中,提高推薦的準確率.對于數據分析服務流程,其文本描述信息常常包含著其設計者所需達到的目標或是偏好,如其可能更加偏向非誤率等,這些信息對于模型推薦的結果有很大的影響,需將其考慮在內,用以提高模型推薦的準確率.
3 模型推薦
對于數據分析服務流程模型推薦,通過從OpenML下載數據集、模型、模型運行信息,其中可以直觀的觀察到在數據集中可以用于模型推薦的信息有數據集的數據信息和數據集的文本描述信息.然而,直接用數據集數據信息和文本信息進行模型推薦是較為難以做到的.
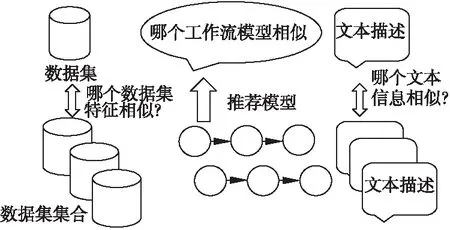
圖1 全局模型推薦步驟Fig.1 Global model recommendation steps
故對于數據集數據,如圖1所示,其可以在之上進行特征的提取,將數據信息轉化為數字的模型特征.之后便可以利用協同過濾計算相似性.
同時,對于文本描述信息,其可以轉換為計算文本相似性.同時,可以通過轉換為文本多分類問題計算模型的類型,提高準確率.
4 基本概念
文本相似性:由于文本相似性在不同領域其內涵有所不同,因此沒有統一公認的定義.從信息論的角度而言,文本相似度與文本之間的共性和差異有關,當文本之間的共性越大、差異越小時,則相似度越高;當文本之間的共性越小、差異越大,則相似度越低.文本完全相同便是相似度最大的情況.基于假設可以推論出相似度定理,如公式(1)所示.
(1)
其中,common(A,B)是描述文本A和B的共性信息,description(A,B)是描述A和B的全部信息,從公式(1)可以看出相似度與文本共性成正相關.同時在實際應用中其計算文本相似性主要的方法有如圖2所示.
協同過濾[11]:協同過濾是利用集體智慧的一個典型方法,其主要目的便是預測和推薦.協同過濾算法的核心思想便是:人以類聚,物以群分.其通過對用戶歷史行為數據進行挖掘,發現用戶的偏好,基于用戶不同的偏好為用戶進行群組劃分,并且為各個群組推薦符合用戶偏好的商品.
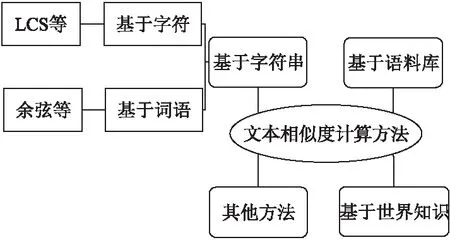
圖2 文本相似度計算方法分類Fig.2 Text similarity calculation method category
協同過濾算法主要可以分為兩類:基于用戶的協同過濾算法(user-based collaborative filtering)和基于用戶的協同過濾算法(item-based collaborative filtering).
其中,協同過濾算法最重要的便是相似度的度量.相似性的度量的方法有很多種,不同的度量方法適用于不同的應用.相似性度量方法的設計也是機器學習算法設計中很重要的一部分,尤其是對于聚類算法,推薦系統這類算法.
相似性的度量方法必須滿足拓撲學中的度量空間的基本條件:
假設d是度量空間M上的度量:d:M×M→R,其中度量d滿足:
非負性:d(x,y)≥0,當且僅當x=y時取等號;
對稱性:d(x,y)=d(y,x);
三角不等性:d(x,z)≤d(x,y)+d(y,z)
這里主要介紹三種相似性的度量方法:歐式距離、皮爾遜相關系數和余弦相似度.
歐式距離,即歐幾里德距離(Euclidean Distance)最初用于計算歐幾里德空間中兩個點的直線距離.假設點x和y是n維空間的兩個點,它們之間的歐幾里德距離計算公式為:
(2)
可以看出,當n=2時,歐幾里德距離即為平面上兩個點的直線距離.用歐幾里德距離表示相似度時,一般采用公式(3)進行轉換:
(3)
由公式可以看出,當x,y間距離越小,它們的相似度便越大.
皮爾遜相關系數(Pearson Correlation Coefficient)則一般用于計算兩個定距變量間聯系的緊密程度,它的取值在 [-1,+1] 之間.在歐氏距離的計算中,不同特征之間的量級對歐氏距離的影響比較大,例如A=(0.05,1),B=(1,1)和C=(0.05,4),我們就不能很好的利用歐式距離判A和B,A和C之間的相似性的大小.而皮爾遜相似性的度量就對量級不敏感:
(4)
sx,sy是x和y的樣品標準差.
余弦相似性[12](Cosine Similarity)則為計算兩個向量的夾角,有著與皮爾遜相似度同樣的性質,對量級不敏感,被廣泛應用于計算文檔數據的相似度:
(5)
5 算 法
利用數據文本描述信息和特征進行數據分析服務流程模型推薦,本文利用OpenML上的數據集及模型數據信息,其構建模型步驟如圖3所示.
1)對數據集及模型信息進行預處理;
2)提取數據集數據特征;
3)提取數據集文本描述特征;
4)利用數據集數據和文本特征構建SVM模型類型分類器,得到模型類型;
5)利用協同過濾算法計算數據集間數據特征和文本描述信息特征的相似性,根據相似性和模型類型推薦模型.
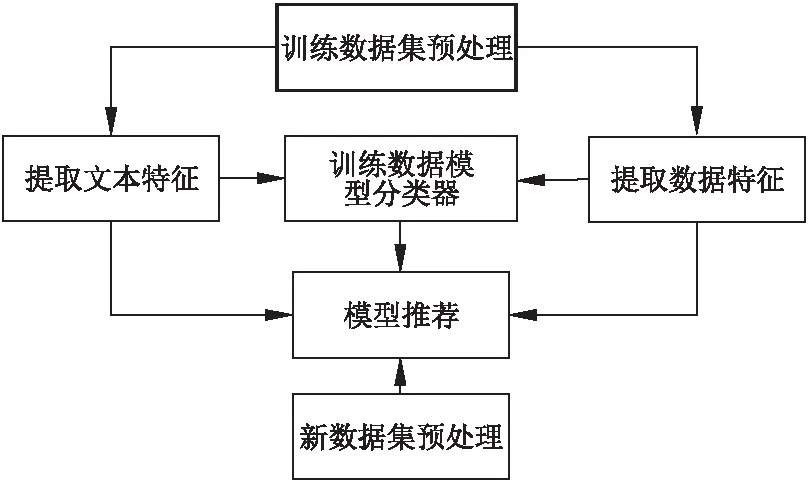
圖3 模型推薦具體步驟Fig.3 Model recommended specific steps
5.1 數據預處理
實驗基于數據集基于OpenML,主要包括數據集數據,數據集文本描述信息,各個數據集上模型運行信息等.
首先過濾數據集信息,對于在上面運行模型次數少于100次的數據集,因為其信息不足,進行排除.
然后標注各個數據集上的“最佳模型”,并得到此模型的模型類型.在此考慮最佳模型主要有兩方面影響因子:模型在此數據集上運行得到的準確率accuracy,模型被用戶運行次數runTime.可以根據如下公式進行歸一化處理,并得到評分最高的模型.
(6)
其中,A為準確率,R為單個模型運行次數,R′為數據集上所有模型總運行次數,α和β為歸一化因子.
當然定義模型運行好壞與否不一定只取決于運行得到的準確率,還有模型的ROC曲線等,其也可以類比帶入公式,并將其擴展.
一般為取最佳運行效果或最多運行次數,故根據各個模型取出此兩種評價因子,然后計算評分,即可得到各個數據集對應的最佳模型.
5.2 數據集特征信息挖掘
對于數據集特征,可以對數據集進行統計分析,參考OpenML可得到119個特征.利用這些特性可以得知數據集的一些特性,如數據集實例數目,數據集屬性數目,數字屬性數目,文本屬性數目等.同時,這些特征本身也都屬于數字特征,故可以很直接的用于后面的協同過濾推薦中.
5.3 文本描述信息挖掘
對于同類數據集的文本描述信息,其往往隱藏著相似的信息,如數據集來源、用戶偏好等等.對于文本信息挖掘,其第一步便是進行分詞.對于英文,其天然有空格隔開,可以按照空格分詞.而對于中文則需要使用相應的算法來進行分詞,可以使用現成的分詞工具jieba等.由于本實驗采用基于OpenML的數據集,其文本描述信息英文直接分詞便可,但需要處理無用的介詞,如on等,將其篩選掉,減少無用信息.
第二步便是特征工程.在這一步,將分詞后的文本數據轉換為特征向量.為了從文本數據中選出重要的特征,有以下幾種方式:計數向量作為特征,TF-IDF向量作為特征,詞嵌入作為特征,基于文本NLP的特征,主題模型作為特征等等.
本文推薦采用TF-IDF向量[13]或NLP[14].TF-IDF(Term Frequency-Inverse Document Frequency,詞頻-逆文件頻率)是一種常用于資訊檢索與資訊探勘的加權技術.TF-IDF采用統計方法,用以表示字詞在文件集中的一份文件的重要程度,當該字詞在本文件出現頻率越高,同時在整個文件集中出現頻率越低,該字詞就越加重要,越能代表該文件.即TF-IDF與一個詞語在一篇文章中出現次數成正相關,與在所有文章中出現次數成負相關.
其中,TF(term frequency,詞頻)指的是某一個給定的詞語在給定的該文件中出現的頻率.IDF(inverse document frequency,逆向文件頻率)指的是如果包含詞條t的文件總數越少,IDF越大,說明詞條具有很好的類別區分能力.其公式可表示如下:
(7)
(8)
TF-IDF=TF*IDF
(9)
并且,由于一般分詞后詞語數量較多,如果取所有詞語進行TF-IDF向量計算,則一是特征值過多,后面協同過濾計算也較慢;二是特征過于稀疏,故一般取TF-IDF值前M個詞語進行代表該文本的TF-IDF值.
5.4 訓練模型類型分類器
利用之前創建的數據集數據和文本特征可以訓練一個分類器,用來判斷數據集屬于哪種類型的問題.常用的方法有SVM[15-18],KNN,LLSF,NNet等.其中,參考復旦大學自然語言處理實驗室使用不同分類算法對基準語料進行測試的結果.這一基準預料共有9804篇訓練文檔,9833篇測試文檔,并分為20類.在經過預處理之后,各個分類方法的性能指標如表1所示.
其中F1測度是綜合了召回率與準確率的指標,當兩個值都比較大的時候,對應的F1測度才會比較大,因此F1測度比單一的召回率或準確率更加具有代表性,更能體現性能的好壞.由比較結果不難看出,用SVM算法來進行分類器的訓練能取得較好的結果.
表1 復旦大學分類算法性能
Table 1 Fudan University classification algorithm performance
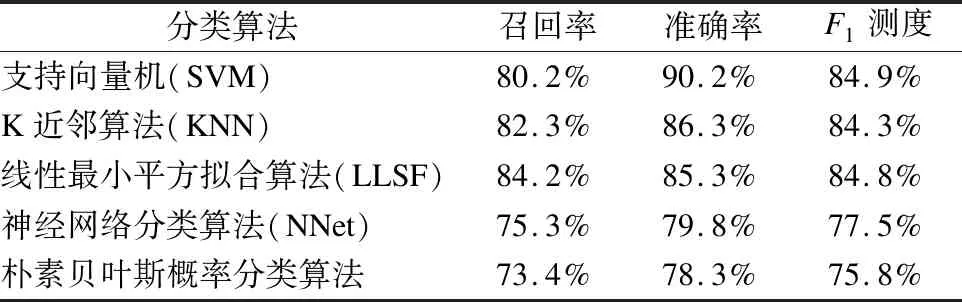
分類算法召回率準確率F1測度支持向量機(SVM)80.2%90.2%84.9%K近鄰算法(KNN)82.3%86.3%84.3%線性最小平方擬合算法(LLSF)84.2%85.3%84.8%神經網絡分類算法(NNet)75.3%79.8%77.5%樸素貝葉斯概率分類算法73.4%78.3%75.8%
SVM 算法有很堅實的理論基礎,SVM 算法的本質是解決一個二次規劃問題(Quadruple Programming),用其進行文本分類效果很好,是最好的分類器之一.同時SVM算法可以使用核函數將原始的樣本空間向高維空間進行變換,進而能夠解決原始樣本線性不可分的問題.
通過SVM訓練特征為TF-IDF向量的文本,預測數據集所屬的模型類型,一般有分類、回歸、聚類、子集劃分等幾種模型類型.
5.5 協同過濾模型推薦
通過利用以上的文本分析所得的數據集所屬模型類型,TF-IDF文本特征向量,數據集特征值進行協同過濾得到推薦模型.即先利用TF-IDF向量和數據集特征值進行協同過濾[19-22],然后得到數據集集合中與該數據集的相似矩陣,然后判斷其數據集的最佳模型是否屬于由SVM所得的模型類型,然后得到相似性最高的Top k個數據集的最佳模型.
5.6 算法實例
對OpenML上數據集anneal(id=2)進行驗證并進行模型推薦.對其數據集數據特征提取,可得到如表2所示.
表2 數據集數據特征
Table 2 Feature of data set

數據集名稱Credit-g實例數目 898屬性數目 39數字屬性數目6文本屬性數目33… …
對其文本描述信息進行特征提取,轉化為TF-IDF向量,如表3所示.
表3 文本TF-IDF向量
Table 3 Text TF-IDF vector
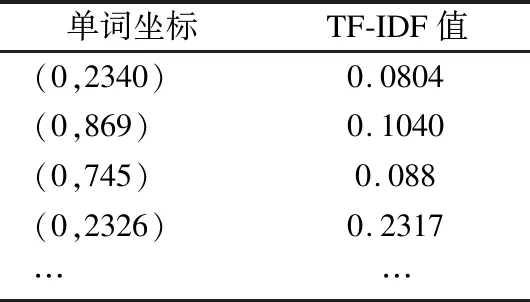
單詞坐標TF-IDF值(0,2340)0.0804(0,869)0.1040(0,745)0.088(0,2326)0.2317……
然后通過代入SVM分類器,得到模型類型為有監督分類(Supervised Classification).
最后,利用歐氏距離處理TF-IDF向量,利用余弦相似度處理數據集數據特征,協同過濾得到推薦模型Top1為:weka.J48(1).Top5為:weka.J48(1),weka.SMO_RBFKernel,weka.ZeroR(1),weka.RandomForest(1),weka.weka.NaiveBayes(1).而通過分析任務運行信息得出的定義最佳模型為:weka.J48(1),故通過模型推薦結果符合實際情況.
6 實驗結果
6.1 實驗數據平臺介紹
OpenML是一個開放,協作,自動化的數據分析、機器學習平臺.其主要由數據集、任務、模型、運行情況構成.
數據集,即用戶所需進行數據分析工作上傳的數據集合,它們是由許多實例構成,通常以表格形式呈現.
任務由一個數據集和一個數據分析任務組成,如分類或聚類以及評估方法.對于監督任務,這也指數據中的目標所代表的列.
模型指從特定的庫或框架(如Weka,mlr或scikit-learn)中識別特定的機器學習算法構成的工作流流程.
運行是特定的流程,即模型和具有特定的參數設置,適用于特定的任務.
用戶在OpenML上面上傳數據集,對數據集創建任務,構建模型,挑選模型在任務上運行.在OpenML上共有2萬左右用戶上傳的數據集,對于這些數據集用戶創建了6萬8千左右的數據分析任務,構建了約6千個左右模型,在這些任務(數據集)上共運行了9百萬次模型.實驗通過API接口獲取這些數據,對模型和運行信息分析,得到對應數據集的最佳模型,并將全部數據集分為訓練數據集和測試數據集.接著對數據集數據信息和數據集文本描述信息進行特征提取,模型分類,模型推薦.
6.2 文本特征提取方法比較
首先,過濾運行次數不足100的數據集,然后對于公式(1)中α,β各取0.5,然后對于1814個數據集進行上述實驗,對比實驗各種不同的文本特征提取方法,得到結果為表4.
表4 文本特征提取方法比較
Table 4 Comparison of text feature extraction methods
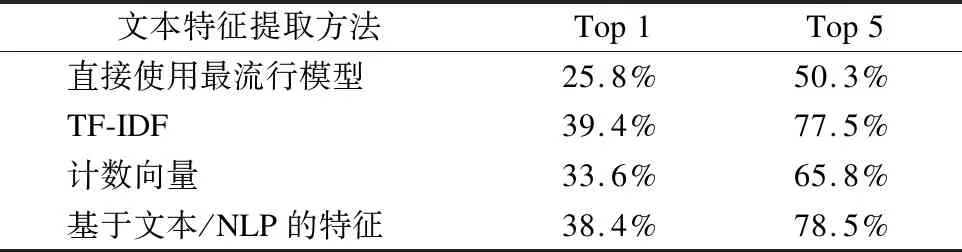
文本特征提取方法Top1Top5直接使用最流行模型25.8%50.3%TF-IDF39.4%77.5%計數向量33.6%65.8%基于文本/NLP的特征38.4%78.5%
由上述表格可以看到,在利用數據集特征和文本描述信息計算數據集相似性以推薦模型時,不同文本特征提取方法對結果的影響.
對比直接使用最流行模型,即使用人數最多的模型進行推薦,可以看到還是能取得不錯的效果.對于使用最流行的一個模型進行推薦,其準確率可以達到25.8%,使用最流行的5個模型進行推薦,其準確率可以達到50%左右.當然,隨著數據集和模型數量的增長,該準確率也會降低.
而當使用上述算法進行構建、推薦時,可以看到使用TF-IDF和NLP進行文本特征表示效果最好,同時也能較為明顯的提升了模型推薦的準確率.對比計數向量,TF-IDF向量考慮到了逆文檔頻率,更加能夠體現出不同文本信息之間的區別.而NLP也通過構建語言模型,提取特征更加豐富準確.而從效率方便性來看,TF-IDF特征向量要更加簡便.
6.3 相似性距離計算方法對比
其次,當令α,β各取0.5,文本特征提取方法使用TF-IDF特征向量時,對比不同相似性距離計算方法如表5所示.
表5 相似性距離計算方法對比
Table 5 Comparison of similarity distance calculation methods

數據集特征 文本描述 準確率(Top5)歐式距離歐式距離66.1%歐式距離余弦相似度67.0%余弦相似度余弦相似度76.8%余弦相似度歐式距離77.5%
因為皮爾遜相關系數和余弦相似度效果類似,同時皮爾遜相關系數值區間為[-1,1]要將其轉換,并和歐氏距離等進行合并比較麻煩,故此處不將皮爾遜相關系數進行比較.
結果如表5所示,分析可得,對于數據集特征,使用余弦相似性進行計算明顯要比歐氏距離要好.分析其原因應該是因為數據集數字特征之間量級相差可能較大,用歐式距離進行計算較難以準確算出相似性,而余弦相似性在處理量級相差較大的特征時明顯比歐式距離好.對于文本描述信息,其使用余弦相似度和歐式距離進行計算差別不大,因為在使用TF-IDF特征向量進行文本特征表示后,其值都為[0,1]之間,故兩者并無太大區別.
6.4 模型分類影響
在處理文本描述信息中,我們先將其利用SVM多進行文本多分類,得到數據集所屬的模型類型,然后利用此信息對協同過濾得到的模型進行過濾.對于模型分類,其準確率為89.7%.
而當令α,β各取0.5,文本特征提取方法使用TF-IDF特征向量,數據集特征距離計算方法使用余弦相似度,文本描述使用歐式距離計算時,其對比結果如表6所示.
表6 模型分類準確率影響
Table 6 Model classification accuracy rate impact

是否分類準確率(Top5)SVM分類得到模型類型77.5%無分類68.9%
由表6可以看出,利用SVM算法先對文本描述信息進行分類,得到數據集所屬模型類型,對得到準確的模型有較為明顯的提升.
6.5 最佳模型計算方法對比
最后,當文本特征提取方法使用TF-IDF特征向量,數據集特征距離計算方法使用余弦相似度,文本描述使用歐式距離計算,并使用SVM分類得到模型類型,α,β取不同值對模型推薦的準確率影響如表7所示.
由表7可以看出,當取最佳模型只考慮模型運行時準確率時,取得的最佳模型在算法模型推薦時效果最差.當取最佳模型只考慮流行度或者說模型運行次數時,取得的最佳模型在算法模型推薦時效果最好.
其原因是因為當只考慮模型運行準確率時,各個數據集的模型運行的準確率可能有偶然性,同時最佳模型的種類也會更多,各個數據集上最佳模型相似性也會更低.反之,當只考慮流行程度時,最佳模型的種類將會大大減少,模型推薦的準確率相對而言會更高,但這并不代表模型推薦的效果會更好.因為對于用戶而言,不僅僅考慮模型的流行度,模型的準確率也是重要的考慮因素,故需對其取一個平衡,均衡考慮.
表7 最佳模型計算方法對比
Table 7 Comparison of the best model calculation methods

模型準確率運行次數準確率(Top5)α=1.0β=063.6%α=0β=1.081.7%α=0.5β=0.577.5%
7 結論與展望
本文針對當前流行的數據分析服務流程提出了基于數據集的模型推薦方法,通過對數據集數據和文本描述信息特征的提取,使用SVM分類對其進行模型類型的預測,再綜合協同過濾算法對其進行模型推薦.
本文針對數據集數據特征和文本描述信息,實驗了多種方法,在其之上定義了最佳模型的計算方法,實驗了三種文本特征表示方法:計數向量,TF-IDF,NLP方法,并在其上驗證了多種距離計算方法對模型推薦效果的影響.
實驗結果可以發現,通過數據集數據特征和文本描述信息能較好進行模型推薦,可以大大節省用戶建模時間,讓模型可以充分被重復利用.
當然,實驗也存在一些不足之處,和接下來進一步優化目標:
1)可將用戶的偏好從文本描述信息中抽取出來,或者通過標注訓練的方法從文本描述信息中得到用戶偏好.
2)可以進一步分析數據集規模和模型推薦準確性的關系.
3)利用TF-IDF向量進行計算文本描述信息相似性,對于每個新的數據集每次都要重新開頭計算.可以考慮使用其他文本特征表示方法在不失準確率的情況下提高效率.
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
創業家(2015年5期)2015-02-27 07:53:25
