基于Spark平臺ALS模型推薦算法的研究與優化
2019-07-08 02:23:41李珍吳青洋
電腦知識與技術 2019年13期
李珍 吳青洋


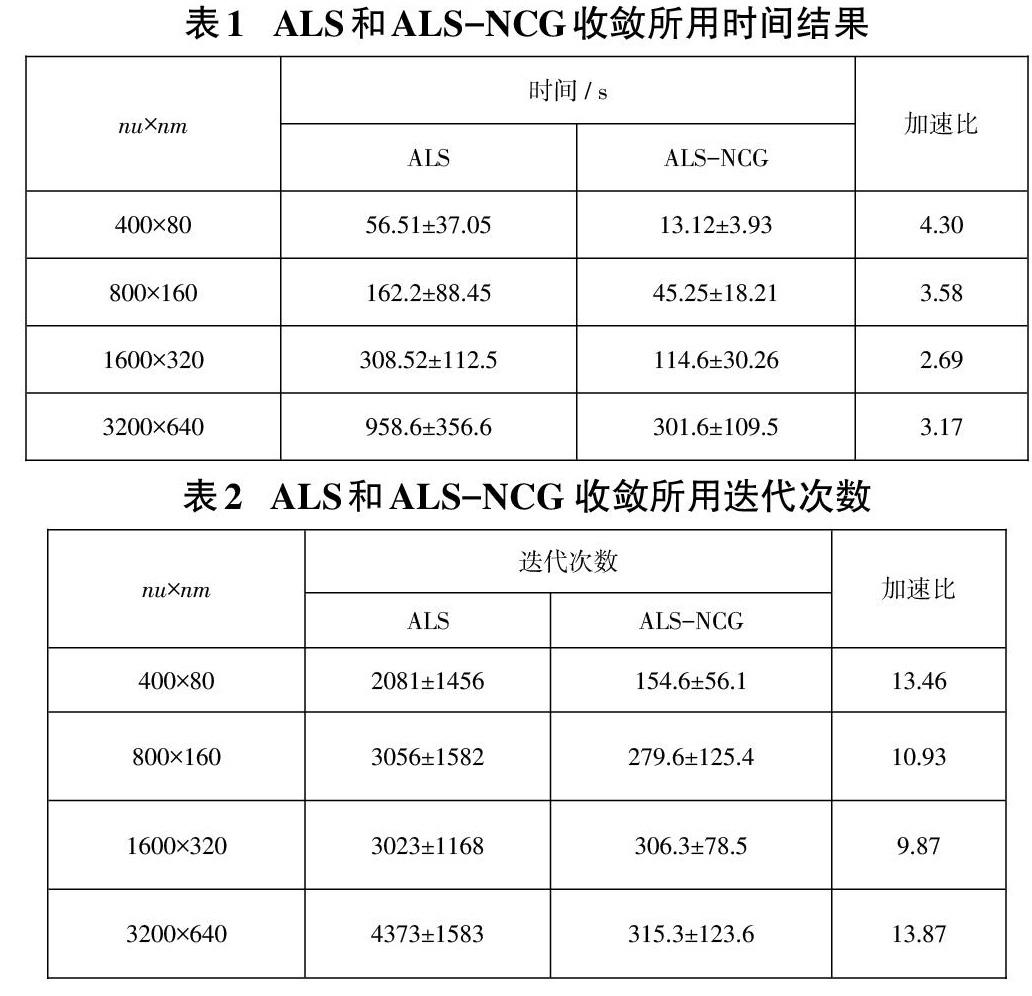
摘要:推薦算法是推薦系統的重要組成部分,交替最小二乘算法ALS(Alternating Least Squares)在許多大規模數據處理過程中,經常用于計算潛在的因子矩陣分解。對于ALS算法迭代次數多、收斂時間長的問題,該文提出了一種采用非線性共軛梯度算法NCG(nonlinear conjugate gradient )對ALS算法進行改進,來加快ALS算法的收斂速度,并對該方法進行了實驗研究,通過在MovieLens 10M數據集上的實驗結果表明,ALS-NCG模型推薦算法在收斂過程中,比ALS模型推薦算法迭代次數少,時間消耗少。
關鍵詞:Spark;最小二乘法;矩陣分解;推薦系統;協同過濾
中圖分類號 ?TP311.52 ? ? ? ?文獻標志碼 ?A
文章編號:1009-3044(2019)13-0019-04
Abstract: Recommendation algorithm is an important part of the recommendation system. Many large-scale data processing environments include collaborative filtering models for which the Alternating Least Squares(ALS) algorithm is used to compare latent factor matrix decompositions. To solve the problem that ALS algorithm has too many iterations and too long convergence time, in this paper, we propose an approach to accelerate the convergence of parallel ALS-based optimization methods for collaborative filtering using a nonlinear conjugate gradient(NCG) algorithm wrapper around the ALS iterations. Experimental results on the Movie Lens 10M dataset show that ALS-NCG model recommendation algorithm has less iteration times and less time consuming than ALS model recommendation algorithm in convergence process.
Key words: Spark; alternating least square (ALS); matrix decomposition; recommended system; collaborative filtering
1 背景
推薦系統通過分析用戶行為數據,為其推薦如電影、音樂、或其他商品,并已成為在線服務中的重要組成部分。協同過濾是構建推薦系統的一種策略,即通過收集許多用戶的喜好信息來進行推薦。協同過濾方法已用于在線業務,如亞馬遜[1],Netflix[2]。
基于隱語義模型推薦算法的實質是將稀疏的用戶評分矩陣分解為若干個組成部分,用戶物品評分矩陣R中每一項表示用戶對物品的評分,快速求解低維用戶矩陣U和物品矩陣M是十分必要的,并滿足[R≈UTM]。
矩陣分解與奇異值分解(SVD)聯系緊密,但是SVD不能處理含有缺失值的矩陣。由于[R≈UTM],使R中預測評分和實際評分之間的平方差最小,是獲取用戶矩陣和物品矩陣的方法之一。通常采用隨機梯度下降(SGD)或交替最小二乘(ALS)來最小化這種差異[3]。其中,ALS可以處理含有隱式數據模型,而且也容易并行化。
盡管ALS推薦算法相對其他推薦算法而言有一定的優勢,然而ALS推薦算法收斂過程中迭代次數多、收斂時間長,很難適用于實時推薦的場景。于是本文提出一種用來計算用戶、物品的矩陣的優化后的ALS算法。本文使用非線性共軛梯度算法(NCG)[4]來融合 ALS算法,從而大大加快ALS算法的收斂,本文將這種組合算法稱為ALS-NCG。
本文將在Spark平臺上并行實現優化后的ALS算法,其中Spark是一個大型的分布式數據處理環境。在商業環境中,Spark已經廣泛應用于大數據分析中。本文在文獻[5-6]提出在Spark平臺上并行實現ALS模型推薦算法的基礎上對ALS模型算法進行優化。
表3顯示了ALS算法改進前后的RMSE對比結果, 當正則化參數設置為10時,迭代次數為10、20、30、40,屬性數為8、10、12,進行比較。圖1是對應于表3的統計柱狀圖。由圖1可知ALS-NCG算法對應RESE的數值要比ALS算法對應的RMSE的數值低得多,當迭代次數為40并且屬性個數為10時,RMSE值降低到0.870414,RMSE值越小,表明預測的精度越高,可以看出,利用非線性共軛梯度算法融合ALS算法,不但可以加快ALS算法的收斂速度,還能使模型的評價指標更好。
7 總結
本文介紹了ALS模型推薦算法和Spark平臺的概況,對于ALS模型推薦算法在收斂過程中,收斂時間長、迭代次數多的問題,本文采用非線性共軛梯度算法融合ALS算法,并在Spark平臺上將優化后的ALS-NCG算法并行化實現了。實驗結果表明ALS-NCG算法效果顯著,有效地加快了ALS算法的收斂,提高了ALS模型推薦算法在海量數據下的執行效率,并降低了評測指標RMSE值。但是也存在不足之處,本文提出的ALS-NCG 推薦算法是在離線環境下進行的,使用GroupLens提供的電影相關的數據,本文進一步的工作應該包括:在線上環境進行實驗和研究其他類型的數據。
參考文獻:
[1] Linden G, Smith B, York J. Amazon. com recommendations: Item-to-item collaborative filtering[J]. 2003, 7(1): 76-80.
[2] Bell M R, Koren Y. Lessons from the Netflix prize challenge[J]. SIGKDD Explor. Newsl, 2007, 9(2): 75-79.
[3] Koren Y, Bell R, Volinsky C. Matrix factorization techniques for recommender systems[J]. Computer, 2009, 42(8): 30-37.
[4] Liu Z, Wang Y, Yang S, et al. Differential evolution with a two-stage optimization mechanism for numerical optimization[C]// IEEE Congress on Evolutionary Computation. IEEE, 2016.
[5] Zhou Y, Wilkinson D, Schreiber R, et al. Large-scale parallel collaborative filtering for the netflix prize[C]// Algorithmic Aspects in Information and Management, International Conference, Aaim 2008, Shanghai, China, 2008(6): 23-25, Proceedings. DBLP, 2008: 337-348.
[6] Koren Y, Bell R, Volinsky C. Matrix factorization techniques for recommender systems[J]. Computer, 2009, 42(8): 30-37.
[7] PILASZY I, ZIBRICZKY D. Fast als-based matrix factorization for explicit, implicit feedback datasets[C]//Proceedings of the Fourth ACM Conference on Cecommender Systems. New York: ACM Press, 2010: 71-78.
[8] Dena D, Bucicoiu M, Bardac M. A managed distributed processing pipeline with Storm and Mesos[C]. Networking in Education and Research, 2013 RoEduNet International Conference 12th Edition, Iasi, 2013: 1-6.
[9] 夏俊鴛. Spark大數據處理技術[M]. 北京: 電子工業出版社, 2015.
[10] Polak E, Ribière G. Note sur la convergence de méthodes de directions conjuguées[J]. Rev. franaise Informat. recherche Opérationnelle, 1968, 16(16): 35-43.
【通聯編輯:謝媛媛】
