改進的k-means聚類算法在公交IC卡數據分析中的應用研究
2019-07-03 02:31:14楊健兵
軟件工程 2019年5期
楊健兵

摘? 要:針對傳統k-means算法中初始聚類中心隨機確定的問題,提出k-means改進算法。首先,定義變量權值,權值的大小等于樣本密度乘以簇間距離除以簇內樣本平均距離,通過最大權值來確定聚類中心,克服了隨機確定聚類中心的不穩定性。然后在Hadoop平臺上用Map-Reduce框架下實現算法的并行化。最后以南通公交IC刷卡記錄為例,通過改進的k-means聚類算法進行IC卡刷卡記錄的分析。實驗表明,在Hadoop平臺下改進k-means算法運行穩定、可靠,具有很好的聚類效果。
關鍵詞:MapReduce;改進k-means算法;k-means;聚類
中圖分類號:TP301? ? ?文獻標識碼:A
Abstract:Aiming at the problem of random determination of initial clustering centers in traditional k-means algorithm,an improved k-means algorithm is proposed in this paper.First,the weight value of the variable is defined.The weight value is equal to the sample density multiplied by the distance between clusters and then divided by the average distance within the cluster.The clustering center is determined by the maximum weight,and the instability of the cluster center is determined randomly.Then the parallelization of the algorithm is implemented under the Map-Reduce framework on the Hadoop platform.Finally,taking the Nantong bus IC card record as an example,an improved k-means clustering algorithm is used to analyze the IC card record.Experiments show that the improved k-means algorithm is stable and reliable under the Hadoop platform,with a good clustering effect.
Keywords:MapReduce;improved k-means algorithm;k-means;clustering
1? ?引言(Introduction)
傳統的公交客流調查大多數通過問卷調查獲得,這種調查方法原始、相對落后,耗費大量的人力、物理和財力,并且最終獲得的數據也不精確,往往為最終決策帶來一定誤差。而伴隨著智能公共交通系統的發展和普及,公交IC卡收費系統、GPS監控系統、車輛監控系統中積累了大量原始的公交數據,特別是公交IC卡收費系統,里面保存在每位乘客的上車刷卡信息,這些海量的刷卡信息內部蘊含著真實、全面的公交客流信息[1,2],如何利用數據挖掘技術從這些海量的公交IC卡數據中快速獲取真實全面的公交客流信息,也是研究的熱點問題。
最近幾年,國內外學者在公交IC卡數據分析中做了大量的研究工作。在國外,Jinhua結合AFC及AVC數據獲取上車站點,然而國外的城市公交系統與國內的相差很大。在國內,戴宵等[3]提出了對公交卡乘客的刷卡時間進行聚類分析判斷乘客上車站點的方法,于勇等[4]結合公交運營調度時刻表所提供的車輛及其發車信息,推算各車次到達各站點的時間,提高了上車站點推算精度。周銳[5]提出了基于IC卡數據的公交站點客流推算方法。趙鵬[6]基于成都公交IC卡數據的乘客上下車站點推算方法研究。徐文遠[7]等基于公交IC卡數據的公交客流統計方法。以上的研究存在數據不完整、準確率偏低等問題,所以研究的正確性很難得到保證。
本文針對公交IC卡中海量的刷卡數據,提出了基于hadoop平臺的改進k-means算法,在底層HDFS文件系統的支持下,通過k-means算法對公交IC卡刷卡數據進行分析。利用MapReduce算法進行并行計算,通過MapReduce算法極大地聚類算法的效率,為公交公司制定合理的調度方案提供了重要的依據。
2? ?數據預處理(Data preprocessing)
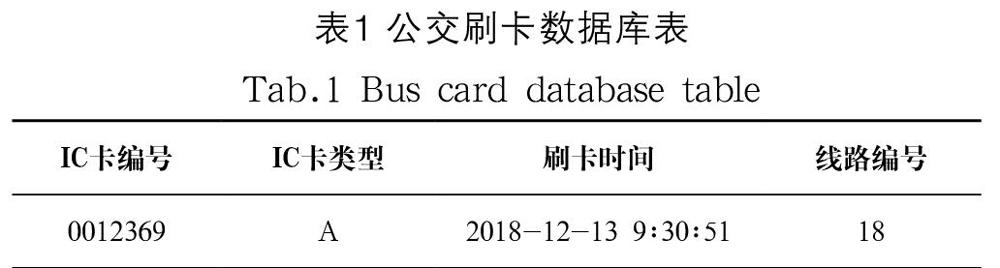
本文需要進行計算的數據是南通市公共交通IC卡刷卡數據。公交IC卡刷卡數據字段包括運營公司、IC卡編號、刷卡時間、刷卡金額、卡類型、線路編號、IC卡設備編號和公交車輛編號等字段。在本文的研究過程中,選取IC卡數據的IC卡編號、IC卡類型、刷卡時間、線路編號四個字段屬性。數據庫表的格式如表1所示。
由于公交車在行駛過程中依次停靠公交各個站點,在停靠的過程中乘客依次上車刷卡,又由于公交IC卡刷卡消費數據所記錄乘客刷卡時間具有一定的次序性,早上車的乘客刷卡時間早于后上車的乘客,其上車的站點順序只有兩種狀況。
①第一,乘車站點相同。在這種情況下,該站點所有的乘客刷卡時間相差不大,相鄰兩位乘客間的刷卡間隔非常短,大概在幾秒之間。該站點第一個上車乘客和該站點最有一個上車乘客刷卡時間差也不是很大,可以歸屬為同一類。
②第二,刷卡時間早的乘客上車時所在的站點位于刷卡時間晚的之前。在這種情況下,由于公交車從一個站點行駛到另外一個站點,所以相鄰兩個刷卡間隔比較長。
通過分析乘客刷卡記錄,我們可以得出結論,相同站點乘車乘客,刷卡時間間隔較短,乘客在不同站點乘車,其刷卡時間間隔較長,這樣可以通過對乘客刷卡記錄進行聚類,使得相同站點的刷卡記錄歸于一類,不同站點的刷卡記錄不在一類。
3? ?聚類算法(Clustering algorithm)
3.1? ?聚類算法和k-means聚類算法
聚類算法[8]是一種非監督機器學習算法,其實質就是對數據對象劃分成子集的過程。聚類分析的算法有多種,可以分為劃分法、層次法、基于密度的方法、基于網格的方法、基于模型的方法。k-means算法是屬于劃分方法中的一種,采用距離作為相似性的評價指標,該算法認為簇是由距離靠近的對象組成的,因此把得到緊湊且獨立的簇作為最終目標。
k-means算法把對象組織成多個互斥的組或簇,采用距離作為相似性的評價指標。假設數據集D包含n個歐式空間中的對象。聚類的目的是把D的對象分配到k個簇C1,…,Ck中,使得對于1≤i,j≤k,Ci∈D且Ci∩Cj=¢。聚類的劃分的目的使得簇內高相似性和簇間低相似性為目標。
3.2? ?改進的k-means算法
改進的k-means算法在選取初始中心點的時候不采用隨機選擇的方式,而是通過計算數據集的密度來考慮初始中心點。與傳統k-means算法隨機選取聚類中心點的方法比,減少了選取數據中心點的隨機性和盲目性。步驟如下:
兩個樣本之間的歐式距離d(xi,xj)按照(1)式來計算。
3.3? ?Hadoop平臺下的改進的k-means算法實現過程
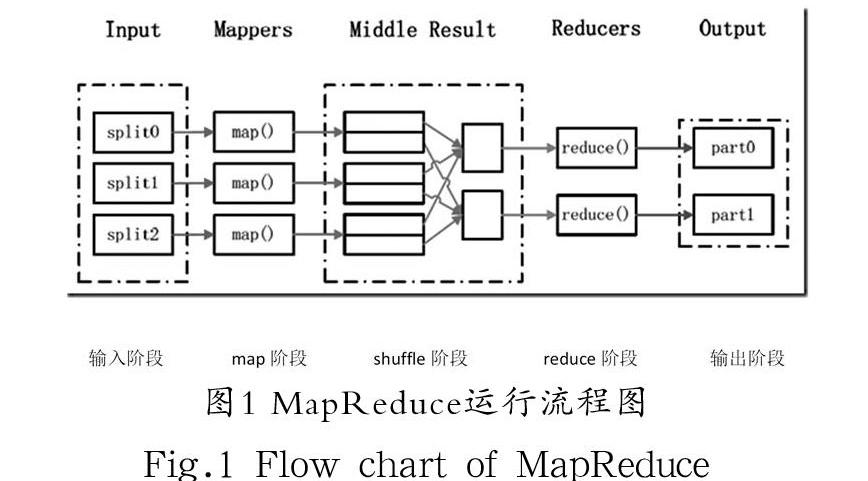
在hadoop程序開發中最重要的就是MapReduce程序的實現,MapReduce程序的開發分為map程序開發和reduce程序開發兩個過程。MapReduce的程序設計與實現如圖1所示。
首先,將公交IC卡刷卡數據存儲在Hadoop分布式文件系統中,然后通過MapReduce并行處理模型計算出K-means算法的輸入參數,輸入參數是初始聚類中心和k值,然后將計算任務再分配給Map任務節點,完成數據的并行聚類計算。具體步驟如下。
①對存儲在HDFS中的IC卡刷卡數據進行初始化操作,產生
②Map任務節點計算數據塊中樣本密度,并根據式(1)—式(7),計算出最大權值w,并得到一些聚集,計算出每個聚類均值,并把該均值作為該簇的鍵值Key,Reduce算法根據鍵值key將具有相同Key值的簇集進行數據合并。
③重新計算出每個簇集的均值,并把計算的結果設置為Value的值,同時對key進行編號,key的號即為簇號。
④通過Map函數計算特征向量與k個初始聚類中心的歐氏距離,根據距離最小原則,找出其距離最小對應簇的簇號,從而得到更新的鍵值對〈Key,Value1〉。
⑤Reduce函數將每個分區中具有相同Key值的信息進行最后的合并。
⑥重復步驟④和步驟⑤,直到最終聚類結果的誤差平方和達到穩定狀態,并輸出最終k個簇的相應信息。
4? ?實驗結果(Experiment results)
4.1? ?實驗環境
在本實驗中,使用兩臺服務器搭建hadoop集群,每臺機器CPU為Intel Xeon處理器,內存128GB。操作系統采用Centos7,搭建ambari大數據管理平臺,包括一個master節點和一個slaver節點,來運行k-means和改進的k-means算法。
4.2? ?實驗數據
實驗數據來自南通公交2018年8月份南通公交某線路的刷卡數據,刷卡數據包括IC卡編號、IC卡類型、刷卡時間、線路編號等四個字段。
4.3? ?實驗結果
本實驗使用精度作為評價聚類性能的評價標準。通過對公交IC卡使用傳統的k-means方法和改進的k-means方法進行分析,并計算其精確度,為了更好評價聚類性能,本實驗共進行聚類五次。具體的分析如表2所示。
5? ?結論(Conclusion)
本文以海量公交IC刷卡數據為基礎,提出了一種在hadoop平臺下改進的k-means算法,針對傳統的k-means聚類算法中存在的問題,提出了采用一種采用密度參數的改進方法,在選取聚類中心的時候,充分考慮樣本數據密度,同時定義了權值,權值的大小有樣本密度乘以簇間距離然后除以簇內樣本距離而得,通過最大權值來確定聚類初始中心和k值,提高了聚類的準確性和精確性。
參考文獻(References)
[1] 孫慈嘉,李嘉偉,凌興宏.基于云計算的公交OD矩陣構建方法[J].江蘇大學學報(自然科學版),2016,37(4):456-461.
[2] 陳鋒,劉劍鋒.基于IC卡數據的公交客流特征分析——以北京市為例[J].城市交通,2016,14(1):51-58;64.
[3] 戴霄,陳學武,李文勇.公交IC卡信息處理的數據挖掘技術研究[J].交通與計算機,2006,24(01):40-42.
[4] 于勇,鄧天民,肖裕民.一種新的公交乘客上車站點確定方法[J].重慶交通大學學報,2009,28(1):121-125.
[5] 周銳.基于IC卡數據的公交站點客流推算方法[D].北京交通大學,2012:27-38.
[6] 趙鵬基于成都公交IC卡數據的乘客上下車站點推算方法研究[D].西南交通大學,2012:16-31.
[7] 徐文遠,鄧春瑤,劉寶義.基于公交IC卡數據的公交客流統計方法[J].中國公路學報,2013,26(5):158-163.
[8] Jiawei Han,MichelineKamber,JianPei.數據挖掘概念與技術[M].北京:機械工業出版社,2012:4-5.
