基于DCNN和遷移學習的食物圖像識別
2019-07-02 12:12:52張石清
實驗室研究與探索 2019年6期
張 鋼, 張石清
(1.廣州質(zhì)量監(jiān)督檢測研究院, 廣州 511447; 2.臺州學院 電子與信息工程學院, 浙江 臺州 318000)
0 引 言
近年來,隨著人工智能的發(fā)展,以及無人自動售貨機等智能設備的普及,自助餐廳中對飯菜種類的自動識別技術開始備受研究者的關注。目前,自助餐廳對顧客所選的食物價格進行結算時,大多是通過收銀員人工計價的方式實現(xiàn),如掃描食物包裝的條形碼或用識別托盤底部的射頻芯片方式來計算出價格。這種人工計價方式,效率低下,在就餐人員數(shù)量多的時候會給收銀員工作帶來諸多不便。
為了克服上述不便,近年來有研究者開始從計算機視覺方法[1-10]的角度來實現(xiàn)食物圖像的自動識別。例如,Joutou等[3]提出采用多核學習(Multiple Kernel Learning,MKL)方法融合顏色、紋理以及尺度不變特征變換(Scale Invariant Feature Transform,SIFT)等特征用于食物圖像識別。Yang等[4]提出采用多維度的直方圖統(tǒng)計參數(shù)作為局部特征用于食物圖像識別。Herranz等[5]提出一種基于局部約束線性編碼(Locality-constrained Linear Coding,LLC)特征的概率圖模型用于實現(xiàn)食物圖像的分類。Matsuda等[6]采用融合梯度方向直方圖 (Histogram of Oriented Gradient,HOG)和Gabor小波變換特征用于食物圖像的邊緣檢測和識別。郭禮華等[10]對SIFT特征、顏色直方圖特征、梯度方向直方圖、Gabor特征等在食物圖像識別方面的性能進行了分析與比較。然而,這些方法都是采用手工設計的特征用于食物圖像識別,而手工特征是一種低層次的特征,用于食物圖像識別的判別力還不夠。
為了解決上述問題,近年來發(fā)展起來的一種深度學習方法,如深度卷積神經(jīng)網(wǎng)絡(Deep Convolutional Neural Networks, DCNN)[11]可能提供了線索。DCNN利用多層次的卷積和池化操作來自動學習出圖像數(shù)據(jù)的高層次屬性特征,捕獲數(shù)據(jù)本身的豐富內(nèi)涵信息,同時也避免了復雜的手工特征的設計過程。目前,DCNN已經(jīng)被廣泛用于圖像檢測與分割[12]、人臉識別[13]、醫(yī)學圖像診斷和識別[14]等領域,但在食物圖像識別領域中的應用還很少見。
此外,深度學習方法性能的發(fā)揮依賴于海量的數(shù)據(jù)支持。由于獲取大量有標簽的數(shù)據(jù)樣本較為困難,現(xiàn)有的食物圖像數(shù)據(jù)庫的規(guī)模往往不是很大,屬于小樣本數(shù)據(jù)集。在這種數(shù)據(jù)量不足的情況下,訓練出的深度學習網(wǎng)絡模型容易出現(xiàn)“過擬合”,無法發(fā)揮出深度學習方法的優(yōu)勢,即對于深度學習方法存在所謂的“數(shù)據(jù)瓶頸”問題。
近年來,遷移學習(Transfer Learning)[15]作為一種新興發(fā)展起來的機器學習理論,備受學術界和工業(yè)界的關注。在當前大數(shù)據(jù)時代背景下,有些領域已存在大規(guī)模的標注過的數(shù)據(jù)樣本可用來訓練和建立學習模型,而在一些其他一些領域難以得到所需要的大量標注過的數(shù)據(jù)樣本。可見,遷移學習可以從現(xiàn)有的數(shù)據(jù)中遷移知識,用來幫助將來的學習。近年來,遷移學習理論已被成功用于跨域(cross-domain)的文本分類[16]、圖像分類[17]、生物醫(yī)學[18]等領域。
考慮到深度學習與遷移學習方法各有優(yōu)勢的特點,本文提出一種基于深度卷積神經(jīng)網(wǎng)絡(DCNN)和遷移學習的食物圖像識別方法。該方法首先采用ImageNet圖像數(shù)據(jù)(集100萬張圖片,1 000種類別)上預訓練好的AlexNet[11]深度模型初始化所采用的網(wǎng)絡參數(shù),然后利用微調(diào)(Fine-tuning)的訓練方式在自建的小規(guī)模食物圖像數(shù)據(jù)庫集上進行遷移學習。這樣不僅可以減輕食物圖像數(shù)據(jù)不足的壓力,也可以充分利用DCNN強大的特征學習能力,使得DCNN能夠從原始的食物圖像中學習得到高層次的屬性特征。最后,采用線性支持向量機(Support Vector Machines, SVM)實現(xiàn)食物圖像的分類。在自建的食物圖像數(shù)據(jù)集上的實驗測試結果,表明了該方法的有效性。
1 基于DCNN和遷移學習的食物圖像識別模型
圖1給出了本文提出的基于DCNN和遷移學習的食物圖像識別模型。該模型選取AlexNet深度模型作為基礎網(wǎng)絡架構,用于獲取食物圖像的高層次屬性特征,從而實現(xiàn)食物圖像的識別。該方法包括3個步驟:① 食物圖像的預處理;② AlexNet的訓練和遷移學習;③ 基于SVM的食物圖像分類。
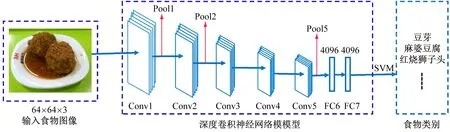
圖1 基于DCNN和遷移學習的食物圖像模型
(1) 食物圖像的預處理。在建立食物圖像數(shù)據(jù)集的時候,對每一張相機拍攝采集到的食物圖像進行人工裁剪處理,保留包含碗碟部分的食物圖像作為圖像樣本。然后對每一張圖像樣本統(tǒng)一采樣到像素為64×64×3的大小。由于AlexNet模型的輸入圖像像素大小是227×227×3,因此還需將每一張像素為64×64×3的圖像縮放到227×227×3的大小,作為DCNN的輸入。
(2) AlexNet網(wǎng)絡的訓練和遷移學習。AlexNet網(wǎng)絡主要由5個卷積層(Conv1~Conv5)、3個池化層(Pool1、Pool2、Pool5)以及兩個全連接層(FC6、FC7)構成。假如輸入數(shù)據(jù)為X,網(wǎng)絡對應的輸出為Z,該網(wǎng)絡通過訓練學習得到一個參數(shù)為Θ的非線性映射函數(shù)F(·|Θ),即
Z=>F(X|Θ)=
fl(…f2(f1(X|θ1)|θ2)|θl)
(1)
式中,fl(·|θl)表示網(wǎng)絡中第l層。
卷積層的作用是特征提取,由一些經(jīng)數(shù)據(jù)驅(qū)動進行自主學習的卷積核所組成。卷積層提取特征的計算過程表示如下:
Zl=fl(Xl|θl)=h(W?Xl+b)
(2)
式中:參數(shù)θl=[W,b];W為卷積核;b為矢量偏差;h(·)為激活函數(shù);?為二維卷積運算。
池化層通常用于卷積層之后,對卷積特征圖進行下采樣后構成池化特征圖。常用的兩種池化方法是平均池化(Average-pooling)和最大池化(Max-pooling),即計算出卷積核的激活函數(shù)在某一區(qū)域范圍內(nèi)輸出的平均值或最大值。本文采用最大池化方法。
全連接層實際上就是傳統(tǒng)神經(jīng)網(wǎng)絡層的隱藏層部分,它的每個神經(jīng)元結點都與上一層的每個神經(jīng)元結點相連接,同一層的神經(jīng)元結點互不相連。全連接層的激活函數(shù)一般采用sigmoid或tanh函數(shù),其輸出可表示為:
Zl=fl(Xl|θl)=h(WXl+b)
(3)
式中,W和Xl之間為矩陣乘積,而不是卷積運算。對于AlexNet的訓練過程如下:① 將ImageNet數(shù)據(jù)上預訓練好的AlexNet模型參數(shù)拷貝到本文采用的網(wǎng)絡,從而實現(xiàn)網(wǎng)絡參數(shù)初始化任務。② 將AlexNet中的softmax輸出層的類別數(shù),改成目標食物圖像數(shù)據(jù)的類別數(shù)。③ 采用后向傳播(Back Propagation, BP)算法在目標食物圖像數(shù)據(jù)集上進行遷移學習,實現(xiàn)網(wǎng)絡參數(shù)的更新。
(3) 基于SVM的食物圖像分類。當完成AlexNet的訓練之后,提取其最后一層全連接層(FC7)產(chǎn)生的4096-D 屬性特征作為DCNN最終學習到的高層次屬性特征,然后輸入到線性支持向量機(SVM)分類器,用于實現(xiàn)食物圖像的識別任務。
2 實驗結果及分析
為了測試本文提出方法的有效性,我們建立了一個小規(guī)模的食物圖像數(shù)據(jù)集。該數(shù)據(jù)集包含6種飯菜:豆芽(2 135個)、紅燒獅子頭(2 012個)、黃豆豬腳(2 343個)、雞蛋羹(2 007個)、麻婆豆腐(2 105個)、萵苣炒肉(2 214),共計12 816個食物圖像樣本。圖2列出了這6種飯菜的食物圖像樣例。

(a) 豆芽

(d) 雞蛋羹
此外,為了與其他手工提取的特征性能進行比較,本文也測試了梯度方向直方圖(HOG)和Gabor小波兩種手工類特征輸入到線性支持向量機所取得的食物圖像識別性能。對于HOG和Gabor小波特征的提取,按照文獻[6]中的參數(shù)設置,最終提取2 916維度的HOG特征和1 536維度的Gabor小波變換特征。表1列出了不同方法所取得的食物圖像識別的性能。由表1可見,本文方法取得的正確識別率為94.20%,而HOG和Gabor小波兩種手工特征取得的正確識別率分別為87.29%和89.80%。這表明了DCNN學習到的食物圖像特征比手工特征具有更好的判別力。主要原因是DCNN利用多層次的卷積和池化操作,能夠有效提取食物圖像的高層次屬性特征用于食物圖像的分類。

表1 不同方法所取得的食物圖像識別性能的比較
為進一步獲取每種食物圖像的正確識別率,圖3所示給出了本文方法所取得的食物圖像識別結果的模糊矩陣。
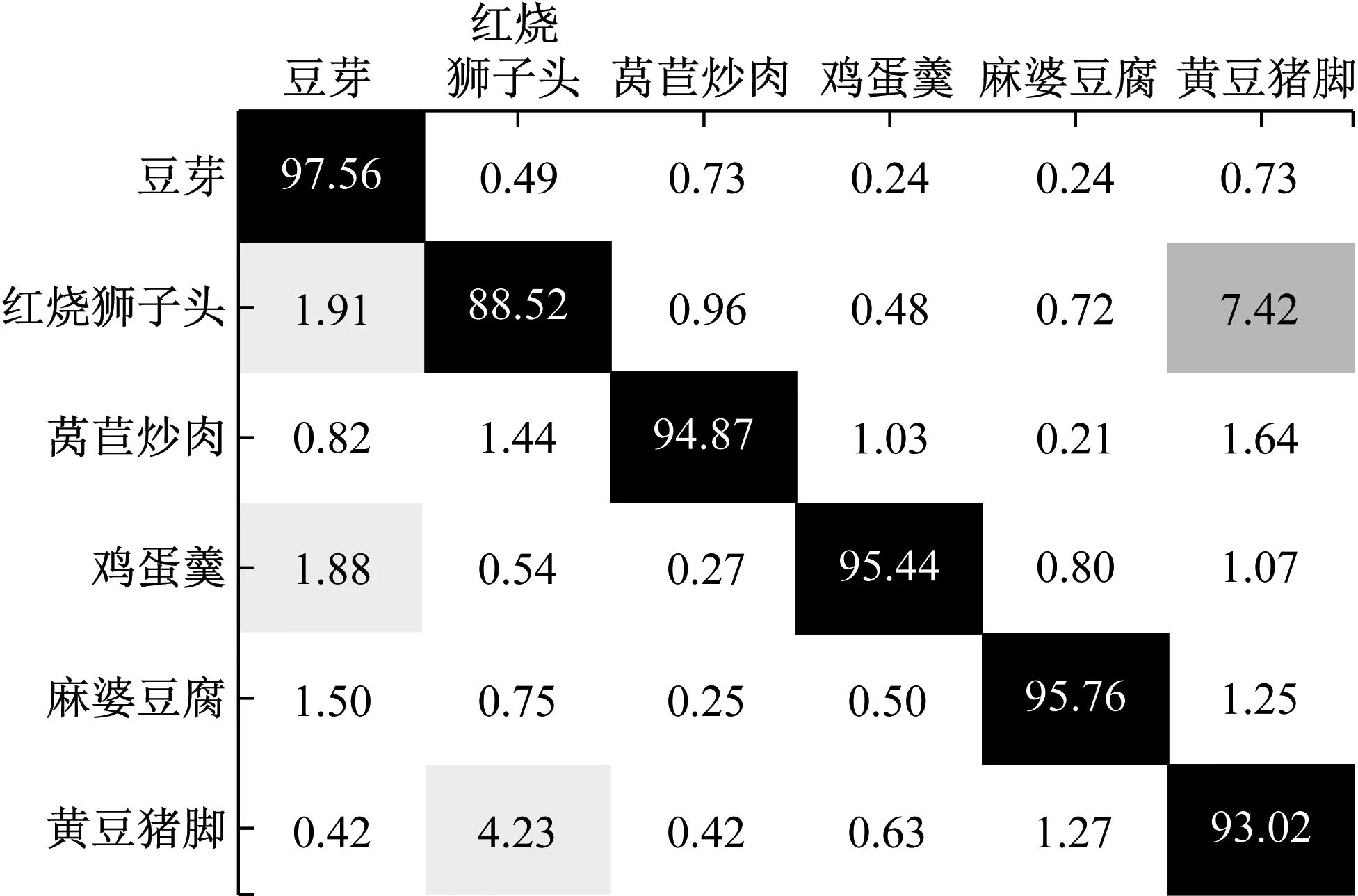
圖3 本方法取得的識別結果的模糊矩陣
由圖3可見,本文方法對這6種食物圖像的識別都取得了較高的性能,大部分食物圖像的正確識別率都達到了93%以上。這表明了該方法的有效性。不過,識別率最低的是“紅燒獅子頭”,只有88.52%。主要原因是它與“黃豆豬腳”視覺上比較相似,導致這兩者容易相互混淆。
3 結 語
本文設計了一個基于DCNN和遷移學習的食物圖像識別方法。在自建的小規(guī)模的食物圖像數(shù)據(jù)集上的測試實驗中,本文方法取得的食物圖像識別率達到了94.20%,優(yōu)于其他兩種手工類特征,如梯度方向直方圖(HOG)和Gabor小波。這表明本文采用深度卷積神經(jīng)網(wǎng)絡和遷移學習用于實現(xiàn)食物圖像的分類,能夠取得較好的識別性能。
猜你喜歡
中學生數(shù)理化·七年級數(shù)學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
