中文古籍數字化成果輔助人文學術研究功能的調查
2019-06-25 01:57:02盧彤李明杰
圖書與情報 2019年1期
盧彤 李明杰


摘? ?要:文章通過網絡訪問、親身體驗與文獻調研,考察了中文古籍數字化成果輔助人文學術研究的功能。根據數據庫形態,將調查對象分為典藏檢索型數據庫、量化分析型數據庫與數字人文平臺,以表格形式展示了各類型古籍數字化成果,從系統功能角度分析歸納各類型數據庫的研究輔助功能,并指出在文史專家與信息科學家的協作下,結合文獻整理學術傳統與現代信息技術,以專業問題為導向的數字人文研究平臺的開發模式是未來古籍數字化的發展方向。
關鍵詞:古籍數字化;研究輔助功能;數字人文
中圖分類號:G255.1;C3? ?文獻標識碼:A? ?DOI:10.11968/tsyqb.1003-6938.2019010
Abstract By network access, hands-on experience and literature research, the authors investigates on functions of digital productions of Chinese ancient books in assisting humanities research. Target databases are classified into 3 categories: collection retrieval database, quantitative analysis database and digital humanity platform. Tabulations are used to help illustrate characteristics of different types of digitization products. The paper analyzes functions of assisting research of different databases from the perspective of system function and looks into the future. The development direction of ancient book digitalization is a research-oriented digital humanities platform that combines academic tradition of literature sorting and modern information technology, which calls for cooperation between humanists and information scientists.
Key words ancient book digitalization; function of assisting research; digital humanities
隨著數字人文的興起,人文學者開始接觸與使用各種數字技術來處理人文科學數據。古籍數字化產品慢慢由資源庫向研究平臺轉變,以滿足人文學者不斷提出的輔助其研究的新需求。而傳統的人文研究方法在全文數據庫強大的檢索功能輔助下,雖在技術上提升了檢索效率,但如何獲取和有效組織文獻數據,則依舊仰賴于人文學者在各自領域中經年累月的訓練所培養的基本功。古籍數字化成果究竟能在多大程度上輔助傳統的人文學術研究,目前尚存疑問。鑒于此,本文通過網絡訪問、親身體驗、文獻調研等方式,對我國現有古籍數字化產品功能進行調查,分析其滿足人文學者專業研究需求的程度,以探討古籍數字化產品功能的研發方向。借鑒申斌和楊培娜[1]對輔助歷史研究的功能層次的劃分,本文從典藏檢索型數據庫、量化分析型數據庫、數字人文研究平臺三個方面展開調查(僅揭示圖書館館藏的書目型、圖像型數據庫不在此次調查范圍之內)。
1? ?典藏檢索型數據庫及其輔助人文學術研究功能
典藏檢索型數據庫從藏與用的目的出發,在對傳統紙質古籍進行校勘整理的基礎上,利用計算機技術將其編碼轉換,再根據文獻特性進行組織與元數據標引,從而實現古籍內容的數字化保存與傳播,同時借助計算機技術與數據庫環境發揮索引功能的優勢,實現分類瀏覽與字段檢索、全文檢索甚至語義關聯檢索的功能,因而是一種具備檢索功能的數字化文本存儲環境。本次調查的結果:典藏檢索型數據庫共79種,其中以圖書館、學術機構、數字出版商為主要開發者的分別有13種、16種和50種。
1.1? ? 圖書館開發的典藏檢索型數據庫
從古籍數字化三大主體的成果總量來看,圖書館雖是最多的,但其所建的古籍數字化系統大多只能進行一般的書目檢索或書影瀏覽,尚停留在揭示館藏的層面[2]。筆者對這些成果進行定期跟蹤,發現它們大多在資源更新與維護上并不及時,且未能跟進新的數字化技術,導致這類產品無法同時具備典藏與檢索的功能。根據跟蹤調研的結果,筆者選取內容經全文轉碼且具有檢索功能的產品,按其來源、成果名稱、分類瀏覽、檢索與顯示功能、嵌入工具及知識增值功能等情況統計出概況(見表1)。
調查結果顯示,在選題上,圖書館開發的典藏檢索型數據庫主要以館藏古籍和地方特色文獻為主,其中方志、家譜較為常見;在功能上,根據文獻內容本身的特色進行分類瀏覽,借助標引實現字段檢索功能。然而,無論是分類瀏覽或全文檢索,其原理都是通過著錄文獻外部特征以達到檢索文獻的目的,僅有少數數據庫具有初級的研究輔助功能,如“中華再造善本數據庫”可據不同底本進行版本對照。
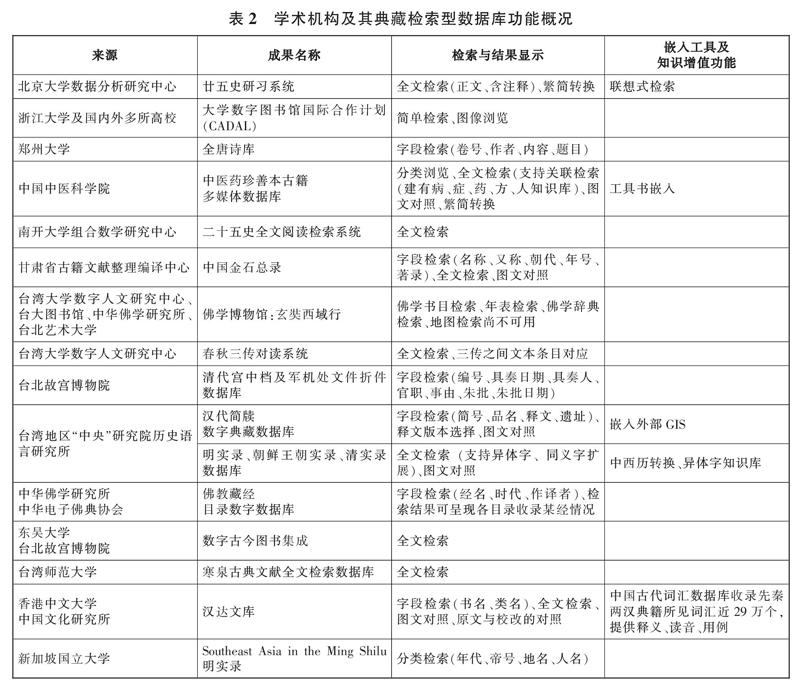
1.2? ? 學術機構開發的典藏檢索型數據庫
通過調研匯總了學術機構開發的典藏檢索型數據庫的概況(見表2)。首先,在選題上,由于學術機構不受館藏與地域的限制,因而所建的典藏檢索型數據庫更具專題性與實用性,也更符合專業研究者的需求。但此類數據庫多是課題研究的結果,新的數字化技術的應用都帶有一定的試驗性,且存在重復選題的現象;其次,在研究功能上,學術機構開發的此類古籍數字化產品在當時都具有一定的前瞻性。相較于只提供基礎性檢索功能的圖書館數據庫,這些系統又開發出新的輔助研究功能。
(1)檢索結果顯示與對比。初級的結果顯示功能是藉由計算機技術將影像或文字經過一定處理,在顯示界面為讀者提供文本及圖像的對比環境,常見且已趨成熟的功能有圖文對照、繁簡轉換,兩者都是保留底本原貌的一種手段;進階的結果顯示功能是根據文獻本身內容與形式之間的聯系所設計,更能發揮數字化環境的優勢,如臺灣大學數字人文研究中心“春秋三傳對讀系統”,能將《左傳》《公羊傳》《谷梁傳》根據《春秋》的編年時序進行文本條目的對應,并將一傳的檢索結果與其他二傳結果并列顯示,以便比較研究。
(2)知識庫構建與檢索擴展。古籍數字化產品常見的知識庫有人名、地名、職官、異體字等內容,是由專家對本領域知識以一定的規則進行組織整序,形成一種內部知識相互關聯的網絡結構,一方面擴大檢索入口,提高檢全率;另一方面為用戶提供知識鏈接的環境。如北京大學數據分析研究中心的“廿五史研習系統”,其聯想式檢索是一種在全局環境下(包括自建知識庫與文獻庫中的全文、注釋)的一鍵式檢索功能,用戶可在閱讀環境下選擇文本中的任意字詞進行知識鏈接;臺灣地區“中央研究院”歷史語言研究所的“明實錄、朝鮮王朝實錄、清實錄數據庫”則是鏈接該所與臺北故宮博物院共同研發的“明清檔案人名權威資料”,用戶可在閱讀時隨時了解文中出現人物的生平與履歷信息。
(3)嵌入外部知識工具。常見的外部知識工具有古漢語字典、人名與地名詞典、生僻字輸入工具、時間換算法(古今紀年、干支公元換算)等。本次調研發現,由臺灣地區“中央研究院”歷史語言研究所開發的“漢代簡牘數字典藏數據庫”嵌入了“史語所藏居延漢簡遺址查詢系統”,可借助GIS呈現遺址及簡牘發現位置。不過,此類功能在學術機構研發的典藏檢索型數據庫中仍較少見。
1.3? ? 數字出版商開發的典藏檢索型數據庫
數字出版商依托圖書館的古籍善本資源,或吸納文史專業研究人員參與研發,或與高校學術機構聯合成立電子文獻研究所,大規模、成系統地將常用基本古籍數字化,其規模和總量在三類主體中居首位(見表3)。在本次調研中,所有數字出版商所開發的古籍數字化產品皆屬于典藏檢索型數據庫,但新技術的應用尚不充分,其各具特色的內容資源尚未得到充分挖掘。
數字出版商開發的古籍數字化產品以大型綜合性數據庫和叢書數據庫為特色,涵蓋史學、文學、宗教、醫學等領域常見古籍,很大程度上滿足了專業研究人員的需要,但各開發主體間缺乏協作,因此選題重復率較高。在輔助研究功能上,它們開發的古籍數字化產品有以下特點:
(1)基本檢索功能成熟。多數產品具有分類瀏覽功能,用戶可根據各系統的分類組織方式掌握資源概況以類求書,其功能更偏重于資源的組織與展示;字段檢索通過對古籍外部特征進行數據描述得以實現,常見字段見表3,但大多不支持檢索擴展或智能檢索。這就要求用戶對各數據庫的元數據著錄規范有充分的掌握,對用戶的檢索能力要求較高。同時由于標引的深度不夠,無法發現古籍內容中潛在的知識;全文檢索功能雖在一定程度上彌補了字段檢索在內容檢索上的缺陷,但因對知識組織與關聯技術的引入不夠,目前的全文檢索功能實際上仍停留在字詞索引階段,導致用戶在檢索專題資料時仍需耗費大量精力來設計全面的檢索式,以獲得更高的檢全率。
(2)嵌入的知識工具同質性高。調查顯示,嵌入的知識工具仍在字詞典、紀年換算的范圍,其中愛如生與書同文公司所開發的產品大多配備統一的嵌入工具,一些有專門需求的數據庫則未根據文獻特色開發出相應的輔助工具。值得一提的是,書同文公司開發的三維助檢系統及關聯漢字檢索較具特色,前者可在書同文公司自建的知識庫中查詢歷史地名、人名與職官信息,也可在閱讀環境中通過超鏈接直接獲取相關知識信息;后者根據內建字體知識庫,幫助用戶將檢索詞擴展至異體字、簡繁體等變體,其效果類似截詞檢索,在技術上利用知識庫與布爾邏輯規則彌補了單純全文檢索在變體字檢索上的缺陷。
(3)知識增值功能少且單一。調查顯示,此類型數據庫的知識增值功能主要以版本對照與查詢為主,但僅限于古籍數字化底本與文本的對照,而其他版本只能查詢其館藏出處,仍無法做到傳統文獻整理所要求的“廣羅異本”,更無法滿足將一切有校勘價值的文獻資料提供給專業研究者的需求。加上未能有效結合前人的版本考訂成果,讀者對開發商選用底本的依據無從知曉。個別數據庫能提供多個版本的圖像對照,但限于顯示環境,對比翻檢困難。另外,相關研究整合與國學寶典嵌入的知網結節功能藉由人工與引文分析的方法,可幫助研究者快速獲得相關課題的研究成果。
綜上所述,不同主體開發的典藏檢索型古籍數據庫在選題上各有不同,但在研究功能上都以檢索功能為主,字段檢索與全文檢索相互輔助能有效地獲取原始文獻內容,但文本內的知識組織與利用較為欠缺。
2? ?量化分析型數據庫及其輔助人文學術研究功能
量化分析型數據庫是將古籍內容或整理成果轉化為可制表分析的量化形式,不僅包含類似人口、產量、價格等數字信息,“其他描述性的信息,也應通過某種形式轉換為可量化分析的數據,這是歷史文獻數據化的理想狀態”[3]。與典藏檢索型數據庫相比,量化分析型數據庫打破了古籍原有的內容結構,經過重組的文獻內容以新的文本形態或數據結構呈現,在不同研究者、不同研究工具與研究視角下可能觸發新的研究靈感。本次調研涉及量化分析型數據庫16種,依其數據來源可分為單純將紙質古籍整理成果進行轉化的數字化索引、具備研究輔助功能的分析平臺兩種類型。
2.1? ? 數字化索引型的量化分析數據庫
具有量化分析功能的索引是由專家根據不同文獻的特點對其內容進行提取并重新整序,形成高度結構化與規范化的組織形式,有利于計算機進行大規模的統計分析。而將既有古籍整理成果轉化為可制表的量化形式,則是對傳統文獻整理成果在數字環境下的增值利用。數字化索引多是先有紙本古籍整理成果,然后形成數據庫(見表4),因此在內容組織與索引對象上大致不脫離原書范圍,但以其強大的檢索功能大大縮短了翻檢時間。在研究功能上,這類數據庫在開發時因元數據方案受制于原書體例,檢索功能較為單一,未能充分發揮計算機數據處理與結果呈現方面的優勢,因此輔助研究的功能不強。另外,經過數字化轉換后的原始數據被存儲在數據庫中,用戶只能通過特定的接口才能訪問,無法獲得原始數據,從而限制了這類數據庫的使用效率。
2.2? ? 分析平臺型的量化分析數據庫
與數字化索引不同,分析平臺在數據來源上并不局限于特定的古籍整理成果,而是更多的來自未經整理的民間文書、地契、檔案與相關歷史文獻。因文獻整理與數據庫構建同時進行,開發人員與文史專家得以帶著研究課題與特定假設開展工作,這使得文史專家能根據特定要求制定相應的元數據方案與文獻整理規范。經整理的文獻多能按照規范的數據結構嚴格著錄,或以人名權威檔的形式將傳主的基本數據與履歷信息制表呈現出來,較傳統的文獻整理成果更利于計算機進行大規模數據處理和做相關性的分析。因此,這類將研究問題、文獻整理方式與數據庫設計三者有機結合的數據庫因其量化數據與二次信息的特性,降低了不同學科研究者在閱讀與理解跨學科文獻過程中所耗費的精力,促進了跨學科研究的發展。在研究功能上,該類數據庫有以下特點:
(1)檢索過程簡化,檢索字段更符合研究需要。因文獻整理方式與數據表結構充分發揮數據庫的優勢,目前此類數據庫在檢索接口多采用下拉列表的字段檢索方式,可輕易實現多維檢索。由于文獻整理過程中充分結合研究問題,使得可供檢索的字段彼此之間具有強關聯性的內容特征,而非僅是傳統文獻著錄的外部特征,研究者可對不同的檢索結果列表以原始的數據表形式導出,再以各自的研究視角與研究工具進行分析解讀。此外,相較于典藏檢索型數據庫,下拉列表檢索簡化了檢索過程,也降低了數據庫對用戶檢索技巧與文獻特征理解的要求。
(2)知識增值功能發揮量化數據在統計與可視化上的優勢。如上海交通大學歷史系與圖書館開發的《中國地方歷史文獻數據庫》[4],其檢索結果統計功能可對檢得文獻的地域分布、年代排序、類型分布及事主進行統計,而關聯文獻聚合功能可根據標引內容,將與檢得文獻同屬同一批次、地域、歸戶或同一事主的文獻一并呈現;又如臺灣“中研院”《清代糧價數據庫》[5],用戶輸入起訖年月、省府別、糧別后可獲得糧價數據,查詢結果會以表格、點狀圖及柱狀圖呈現。表格內每月糧價有最高價和最低價兩種,點狀圖以不同顏色代表最高糧價及最低糧價,柱狀圖則顯示價差。
綜上所述,量化分析型數據庫與典藏檢索型數據庫在構建理念與文獻整理方法上存在諸多差異,其中最大的不同在于它打破了文獻內容原有的組織方式,以數據表的形式呈現經過提取的二次信息。此法雖利于計算機處理數據與呈現結果,但由于用戶直接使用的是結構化的文獻內容,因此在利用這些數據時仍須將其重新放回到所在文本乃至當時的社會背景下進行綜合考慮,以免得出武斷的結論。
3? ?數字人文平臺及其輔助人文學術研究功能
數字人文平臺是一種基于典藏檢索型數據庫與量化分析型數據庫發展而來的學術研究環境,既具備前者的全文檢索與典藏功能及透過深度的元數據標引實現多維度檢索與檢索后的分類功能,又兼具后者的數據化特性,即文獻整理時依據文獻特性與研究者需求將所提取文獻信息以結構化方式呈現,發揮計算機數據統計的優勢。一方面,作為一種研究環境,數字人文平臺的目的是除檢索功能外,能提供研究者“觀察”史料的工具,即借由信息技術幫助已有自身問題意識的研究者輕易地從史料中找到論證對象;另一方面,幫助研究者挖掘一些意料之外的學術問題,開拓出新的研究視野[6]。
本次調研共發現15個可稱之為數字人文平臺的中文古籍數據庫,為便于分析其功能,筆者將以文本處理與字頻統計功能為主的文本分析工具歸為一類(見表6),而將整合了多種功能并能呈現可視化的研究平臺歸為一類(見表7)。
3.1? ? 文本分析工具的研究輔助功能
文本分析工具由典藏檢索型數據庫發展而來,在檢索功能上延續了其基于外部特征的字段檢索與分類瀏覽功能,此外在全文數據庫的基礎上借助N-gram模型解決了古代漢語的分詞問題,借由計算機自動處理全文,實現字頻統計與文本分析的功能。從文本分析工具成果表可發現,目前常見的文本分析是相似度對比,它一般直接忽略文本內容的語義,采用自然語言處理(NPL)模型(如N-gram模型、向量空間模型)對文句建模并進行相似度比較。此類功能根據不同的研究需求有不同的應用場景,如文學領域可用于語言風格分析,以定量方法判定作者歸屬和文學流派;文獻學領域可用于分析文獻之間的引用關系或文獻校勘。對文風和遣詞造句習慣的分析,還可為文獻辨偽提供參考。
另一類常見的文本分析功能是字詞頻分析。調查顯示,《全唐詩分析系統》《全宋詩分析系統》的用戶只需要根據所選格律、聲調、體裁輸入檢索詞,系統便可統計檢索詞在全庫中各作者詩作中的使用頻次;《近代史料全文數據庫》可同時支持5個詞匯的檢索,以折線圖形式呈現檢索詞在文獻集中的出現次數;《中國哲學書電子化計劃》嵌入的Text Tools插件,可將檢索詞的出現頻次與共現關系以圖表、詞云或網絡圖形式呈現。此外,詩詞格律是文學領域中特有的研究內容,利用前人對詩作整理與格律標引成果,并借助計算機的幫助,可實現對大量詩作的格律分析,如《全唐詩分析系統》《全宋詩分析系統》可根據每首詩的數據化格律信息找出相似格律的詩作。相反,也可找出《全唐詩》與《全宋詩》中的重出詩與誤收詩。
然而,不論是詞頻統計或是相似性分析,其結果并不能也不該直接得出任何結論[7]。因為這類從文本中提取出的數據終究無法涵蓋文獻本身的所有信息,而文獻本身又是基于特定時空背景下所產生的,文本分析工具雖可幫助研究者發現文獻中事件、人物、時間等因素之間在傳統文本條件下難以發現的關聯性,但這些關聯性背后深層次的原因仍需要文史研究者以其經過專業訓練所形成的史才、史學與史識加以闡述與論證。
3.2? ? 數字人文平臺的研究輔助功能
數字人文平臺構建的文獻來源十分豐富,包括文集、方志、書目、民間文書、檔案數據與人物傳記數據等。這些文史數據經過適當的整理與標引后,再結合平臺的系統功能,可為研究者建立一個虛擬的歷史環境,幫助研究者發現文獻各部分內容、各歷史人物、各歷史事件之間通過人工難以發現的內在關聯;在功能上,平臺集成不同類型的功能于一體,如GIS系統、文本分析功能、可視化功能、嵌入知識庫與社會網絡分析等功能。
“中國歷代人物傳記數據庫(CBDB)”是由哈佛大學、臺灣地區“中央研究院”與北京大學合作開發的一個關系型數據庫,旨在收錄公元7-19世紀中國歷史上所有重要的人物傳記資料。通過大范圍收集數據,CBDB提供許多檢視過去個人或群體生平的方法,即群體傳記學(Prosopography)[8],同時基于數據的完備與規模,為研究者提供了人際網絡分析(Social Network Analysis)與地理信息學(Geo-information Science)的研究環境。其中,群體傳記學的目的是想找出某一群體所共享的身份,如教育背景、出生地、任官履歷等,并藉此分析背后的社會原因;人際網絡分析注重的是人物之間一對一關系組構而成的復雜網絡。以上兩種研究方法一直是文史學者所關心的問題,如今結合計算機與地理信息系統的幫助,使得以往局限于人工環境而難以發現的隱藏關系或不確定的模糊概念,都可借助數字人文的研究方法獲得新的研究空間。
“中國歷代典籍總目分析系統(HBCC)”是一款由北京大學數據分析研究中心開發的基于FRBR理念與知識本體構建的綜合性古籍文獻知識庫,內容涵蓋我國經典書目,采用自然語言處理技術,完成目錄原數據的自動標注、切分、信息抽取工作和數據語義規范,以人工審校確保數據質量,由此完成將書目信息轉化為品種、版本、印次、藏本、分類信息與責任者等模塊的數據化處理[9]。該系統囊括古今各類書目,并綜合分析存世文獻和歷史文獻的著錄數據,在一定意義上與鄭樵所提出的“會通觀”“編次必記亡書”等文獻整理理念暗合。HBCC具有以下功能:(1)成書年代分布。系統按書目層次描述古籍文獻本體,自動統計分析古籍文獻成書年代,并以可視化圖表呈現,借由大規模書目信息形成不同類目文獻的成書年代分布圖,從定量分析的角度為研究學術發展史提供佐證;(2)責任者相關性多維分析。在對責任行為分類的基礎上,分析責任人或責任機構基于同一作品因責任行為所產生的聯系;(3)層次聚類分析。參照國際圖聯FRBR標準,將品種、版本、印次、藏本四種實體層級根據書名、書目范圍、分類、書目層級、版本類型、版本時代、責任等屬性進行聚類,有助于研究者快速掌握某一作品的所有衍生型式。
臺灣大學數字人文研究中心開發的“臺灣歷史數字圖書館(THDL)”是一個以“明清時期的臺灣歷史”為主題的研究平臺。由于開發人員在平臺構建之初便預設系統收錄的檔案之間蘊藏著一種既開放、又具有各種不同連結的多元脈絡,因此開發了一系列基于“群體”概念的研究輔助工具,主動為研究者分析檢索結果“整體”呈現的特征。系統主要功能有[10]:(1)檢索結果分類。以年代、出處、作者、性質四種方式對檢索結果分類,借此表現檢索結果的組成成分,并可對年代后分類的結果可視化呈現;(2)集中關聯文獻。相關文書、奏折與地契都具有往復、流轉的特性,因此若能將同一事件的往返奏折,或同一塊土地的不同交易行為的契約進行關聯,則有助于了解整體事件的歷史,目前已建成“上下手契”“原契與契尾”“鬮分契多份”“契書內容”的關聯關系;(3)檢出相似文獻。古契書可能因鬮分契一式多份、契書重復抄寫或格式雷同等造成契書的相似,THDL可針對兩兩文件全文計算相似度,將同種文獻的不同文本一并檢出。
4? ?結語
本次對中文古籍數字化成果輔助人文學術研究功能的調研顯示,典藏檢索型數據庫的輔助研究功能仍以檢索為主,大多數系統只能從古籍外部特征獲取文獻線索,其內在知識內容仍難以為研究者所用;量化分析型數據庫利用前人的古籍整理成果作為基礎,或以基于研究需要的文獻整理方式對古籍內容進行再組織,有效地將計算機的統計分析優勢應用于人文學術研究,但因為受文獻本身特性和標引深度的限制,使得根據數據化文本得出的結果仍需文史學者的介入與考證;數字人文研究已然成為新趨勢,在此背景下,人文學者對研究工具的功能提出了新的要求,即盡可能以“辨章學術、考鏡源流”“會通觀”等文獻整理學術傳統為參照,因為這些傳統早已被證明是與人文學術研究相適應的。這就要求數字人文研究平臺的開發必須依靠文史專家與信息工程師的全程協作,從古籍數字化之初就共同參與到系統的開發之中,以專業問題為導向,以符合人文學科研究的需求為出發點。這種將學術傳統與信息技術融合在一起的開發模式,將是未來古籍數字化的發展方向。
參考文獻:
[1]? 申斌,楊培娜.數字技術與史學觀念——中國歷史數據庫與史學理念方法關系探析[J].史學理論研究,2017(2):87-95,159.
[2]? 李明杰,俞優優.中文古籍數字化的主體構成及協作機制初探[J].圖書與情報,2010(1):40-50.
[3]? 趙思淵.地方歷史文獻的數字化、數據化與文本挖掘:以《中國地方歷史文獻數據庫》為例[J].清史研究,2016(4):26-35.
[4]? 上海交通大學圖書館.中國地方歷史文獻數據庫[DB/OL].[2018-10-29].http://dfwx.datahistory.cn/pc.
[5]? 臺灣地區“中央研究院”近代史研究所.清代糧價數據庫[DB/OL].[2018-10-29].http://mhdb.mh.sinica.edu.tw/foodprice/index.php.
[6]? 項潔,翁稷安.關于數位人文的思考:理論與方法[A].項潔.數位人文研究的新視野:基礎與想象[M].臺北:臺灣大學出版中心,2011:9-18.
[7]? 項潔,涂豐恩.什么是數字人文[A].項潔.從保存到創造:開啟數位人文研究[M].臺北:臺灣大學出版中心,2011:9-28.
[8]? 傅君勱.中國歷代人物傳記數據庫用戶指南[EB/OL].[2018-11-07].http://projects.iq.harvard.edu/files/chinesecbdb/files/cbdb_users_guide_ch_170126.pdf.
[9]? 北京大學數據分析研究中心.中國歷代典籍總目分析系統(HBCC v1.0)產品說明[EB/OL].[2018-11-07].https://wenku.baidu.com/view/1f6739a2f524ccbff1218486.html.
[10]? 臺灣大學數字人文研究中心,杜協昌,項潔.臺灣歷史數字圖書館[DB/OL].[2018-11-07].http://doi.airiti.com/LandingPage/NTURCDH/10.6681/NTURCDH.DB_THDL/Text.
作者簡介:盧彤,男,武漢大學信息管理學院碩士研究生,研究方向:古籍數字化;李明杰,男,武漢大學信息管理學院、武漢大學數字圖書館研究所教授,博士生導師,研究方向:古典文獻學、中國圖書文化史。
