循環神經網絡模型在腹膜透析臨床預后預測中的初步應用
2019-06-18 10:25:40高峻逸馬辛宇張超賀馬連韜王亞沙
北京大學學報(醫學版) 2019年3期
關鍵詞:模型
唐 雯, 高峻逸, 馬辛宇,3, 張超賀, 馬連韜,3, 王亞沙,4△
(1. 北京大學第三醫院腎內科, 北京 100191; 2. 北京大學高可信軟件技術教育部重點實驗室, 北京 100871; 3. 北京大學信息科學技術學院, 北京 100871; 4. 北京大學軟件工程國家工程研究中心, 北京 100871)
腹膜透析是終末期腎病的重要替代治療手段,作為居家治療的替代治療方式,具有較好的成本效益比,在國內外得到了廣泛應用[1]。但進行腹膜透析治療的終末期腎病患者病情復雜,常合并多種合并癥和并發癥,需要專業醫護人員長期持續的照顧。在治療和管理腹膜透析患者的過程中,需要根據患者隨訪過程中的各種變化因素,全面合理地進行病情評估,并據此給予具有針對性的個體化治療方案。
隨著醫療信息化程度的不斷深入,各個醫院已經積累了與患者健康相關的大量數據。基于這些數據進行分析和挖掘,建立患者預后預測模型成為近年來醫學與信息學交叉研究的熱點方向[2]。目前對于腹膜透析患者的預后預測研究多為基于基線數據的統計學回歸分析模型,該模型由于難以描述患者隊列數據中的徑向關系,且難以捕捉數據之間復雜的非線性關系,而使其性能受限。
近年來,數據挖掘與機器學習技術蓬勃發展,特別是深度學習模型因其在計算機視覺、語音識別、自然語言處理、人機博弈等領域取得的顯著應用效果而獲得了廣泛關注[3]。一些學者嘗試將深度學習應用于醫療數據分析中,并在疾病自動診斷[4-5]、相似病人檢索、醫學影像數據分析[6]等方面獲得了長足的進展。循環神經網絡(recurrent neural network,RNN)及其變體門控循環單元(gated recurrent unit,GRU)作為典型的深度學習模型,可以靈活地處理變長時序數據,挖掘數據中深層的非線性關系,抽取數據中隱藏的模式,很適合腹膜透析患者的隊列數據分析場景,較之回歸分析模型可能會產生更加優越的預后預測性能。目前,尚未見基于循環神經網絡的腹膜透析臨床預后預測研究,因此,本研究基于北京大學第三醫院腹膜透析門診的常規診療數據,構建死亡風險預測模型,并與傳統邏輯回歸(Logistic regression,LR)模型進行性能比較,初步探討人工智能預后模型的相關發現。
1 資料與方法
1.1 資料來源
本研究納入2006年1月至2018年1月在北京大學第三醫院腎內科腹膜透析門診長期隨訪的腹膜透析患者共計1 118人(數據處理篩選后656人),所有患者隨訪截止至2018年10月31日。所有研究資料來自北京大學第三醫院腹膜透析門診的常規診療數據,數據包括患者在開始透析時的基線數據、隨訪數據和預后數據。
基線數據包括患者的人口學資料、腎臟病原發病、在透析開始時的合并癥狀況(糖尿病、心力衰竭、肺部感染、冠心病、心肌梗死、腦出血、腦梗塞、截肢病史等),以及透析開始時的血壓、化驗檢查(血肌酐、血尿素、血紅蛋白、血白蛋白、血鈣、血磷、甲狀旁腺激素等)信息。
隨訪數據包括在治療過程中患者隨訪檢查的化驗數據(血常規、腎功能、血白蛋白、電解質、血鈣、血磷、血甲狀旁腺激素、血糖、肝功能、血尿酸)、體重、血壓等指標,以及患者在隨訪過程中所出現的各種急、慢性合并癥。
預后數據指患者在隨訪結束時的狀態及時間,包括死亡及死亡原因(排除非正常死亡,即經濟原因放棄治療或自殺患者)、轉血液透析及其原因、腎移植、存活、轉其他腹膜透析中心或失訪。
按照醫學指標(下稱特征)所衡量的患者的不同身體情況,對所有用于本次研究的數據特征進行分類,詳情如表1所示。
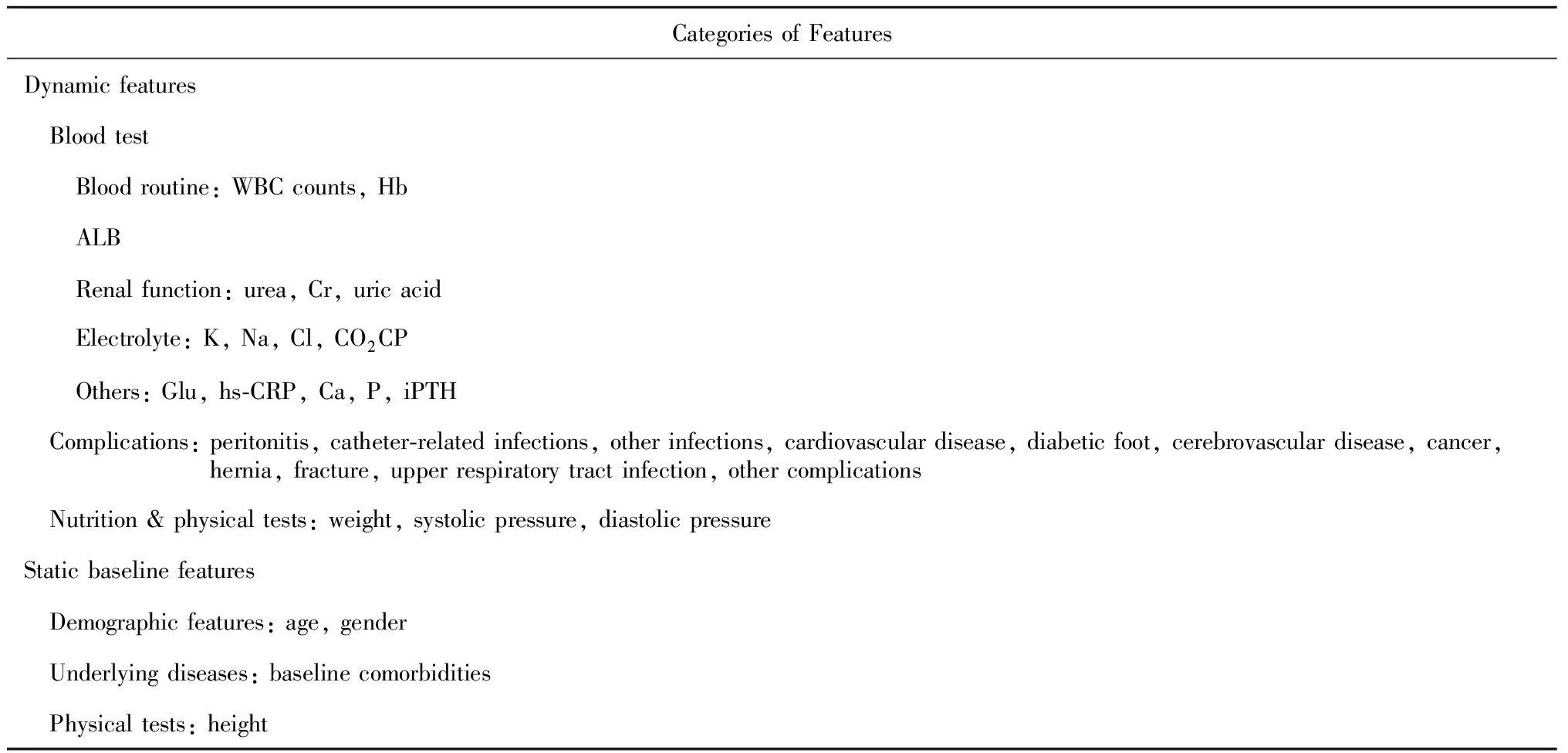
表1 腹膜透析相關醫療特征Table 1 Clinical features of peritoneal dialysis
WBC, white blood cell; Hb, hemoglobin; ALB, albumin; Cr, creatinine; K, blood potassium; Na, blood sodium; Cl, blood chlorine; CO2CP, carbon-dioxide combining power; Glu, blood glucose; hs-CRP, high-sensitivity C-reactive protein; Ca, blood calcium; P, blood phosphorus; iPTH, intact parathyroid hormone.
1.2 研究結局與預測變量
本研究的結局變量為腹膜透析患者在數據記錄時刻的死亡風險狀態(riskt),模型的預測結果為患者在相應時刻的死亡風險(概率)。利用在第1.1小節中提到的患者所有歷次的數據記錄對死亡風險進行預測。具體而言,將歷次隨訪數據合并為數條時間記錄序列(record1,record2,…,recordt),而預后數據主要用于提供患者的身體狀況信息,用于計算結局變量。
對預后信息的處理如圖1,對觀察窗口內死亡患者,取死亡時間之前一年內時間段就診為高死亡風險狀態,記結局變量riskt=1;兩年之前為低死亡風險狀態,記結局變量riskt=0;中間為死亡風險不確定狀態,記結局變量riskt=uncertain。對觀察窗口內存活患者,將觀察窗口截止處一年內設為不確定狀態,一年以前記錄全部設為低風險狀態。
綜上,本研究綜合考慮了base,record1,record2, …,recordt的信息并對riskt給出了一個概率性的預測。
1.3 數據納入、排除與補全標準
本研究排除了在某項特征或指標下沒有數據記錄的所有患者,且只選取出現于至少60%患者中的特征納入預測模型。對記錄中的缺失值,用該特征缺失時間點之前最近的數據進行補全。
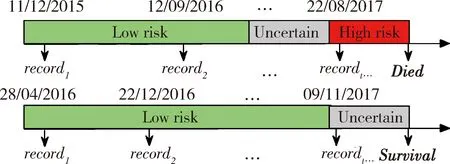
圖1 健康風險狀態標簽的定義Figure 1 Definition of health risk labels
1.4 預測模型
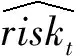
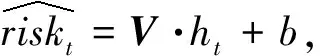
其中,函數σ為激活函數。已知當前時間戳下的真實死亡風險為riskt,則定義交叉熵損失函數為:
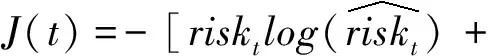
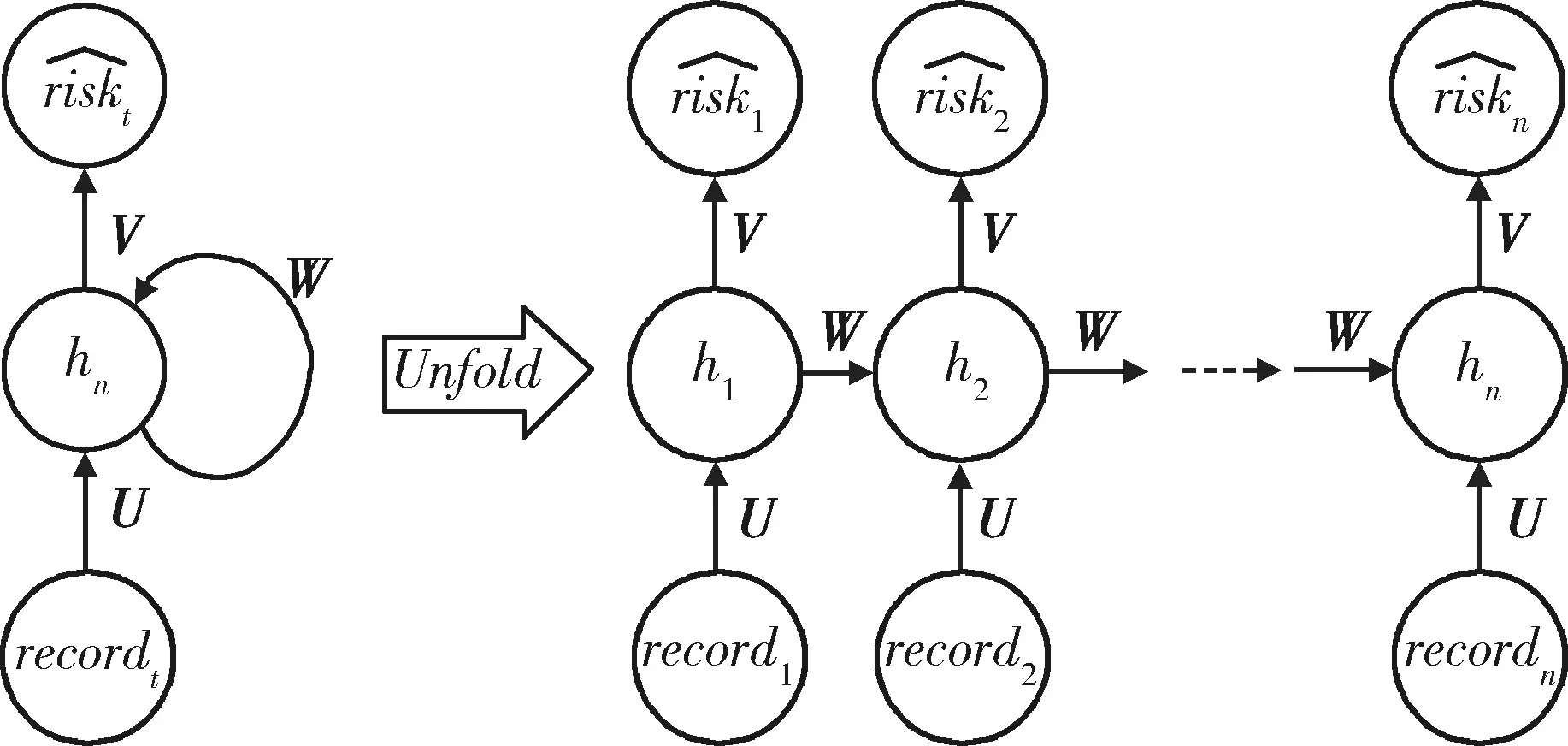
圖2 循環神經網絡模型Figure 2 Recurrent neural network
1.4.2門控循環單元 門控循環單元(gated recurrent unit,GRU)是RNN的一種變體[8],其大體時序信息傳播結構與RNN模型相似(圖3)。σ和tanh分別為神經網絡中sigmoid和tanh非線性激活函數,符號“×”和“+”指代矩陣的元素積和矩陣加法。GRU模型和RNN模型的區別在于其每個時間節點t下的處理更為復雜,對上一時間戳的狀態ht-1,GRU會選擇性地通過“更新門”和“重置門”機制對其保留和遺忘,即分別對應圖中的zt和rt。而在醫療時序數據分析預測中,數據的長時間依賴對當前時間預測很重要,而傳統RNN在處理時序數據時,無法很好地抽取長時間間距之間信息的相關信息,GRU的“更新門”和“重置門”機制很好地解決了這一問題。具體而言,GRU對于每一個時間戳下的輸入向量recordt,結合節點狀態向量ht-1,計算更新門與重置門,更新門的值越大則模型將會利用更多新時刻的信息,重置門的值越大則保留更多歷史信息:
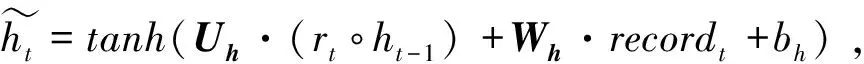
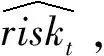
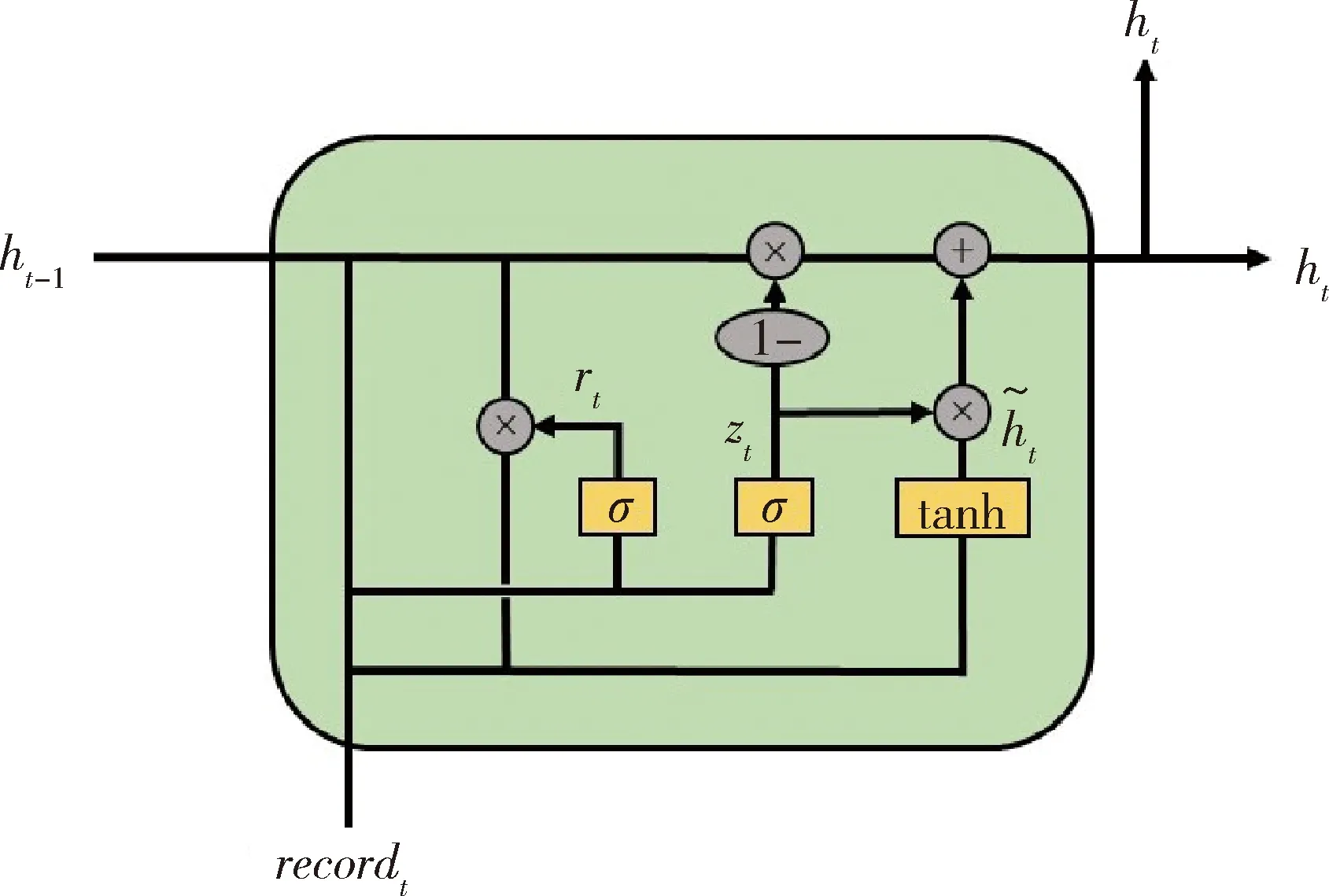
圖3 基于時序數據進行分類的門控循環單元Figure 3 Gated recurrent unit, which is used to perform classification based on time series data
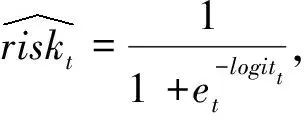
模型中的sigmoid函數即體現了最終輸出概率與輸入之間的非線性關系。同樣采用交叉熵損失函數來衡量損失,并采用隨機梯度下降的方式最小化損失,從而計算得到模型所需的最優參數W和b。值得一提的是,LR模型無法考慮時間這一因素帶來的影響,而是單純從每個數據本身挖掘其背后的特征和意義。因為LR模型無法處理時間序列,本研究將患者就診記錄序列中的每次就診數據獨立地輸入LR模型中,每次就診記錄中包含的數據類型與RNN和GRU模型相同。某種程度上講,前文提及的RNN和GRU模型納入的信息相較于LR而言是更全面的。
1.5 統計分析
本研究采用十折交叉驗證的方式對模型的超參數進行調整,并使用獨立驗證集進行性能測試。其中,測試集在全部患者集合中隨機選取50位。在訓練集中利用GRU建立預測模型,在測試集中主要采用了受試者工作特征(receiver operation characteristic,ROC)曲線下面積(area under the ROC curve,AUROC)、召回率(recall)、F1分數(F1-score)三個指標來衡量模型對患者死亡風險的預測情況。其中,召回率在統計學上指所有預測為正樣本中預測正確的比率,F1分數則指預測精確率和召回率的調和平均值。通過對比這三個指標,可以很容易地對不同模型的預測能力進行評估。
2 結果
2.1 腹膜透析患者數據集基本統計特征
經過數據清洗、補全等預處理,本研究使用的數據集共有656例患者,包括死亡患者261例,所有患者共計13 091條記錄。患者平均年齡(58.55±15.81)歲,平均每位患者擁有(19.95±13.53)條記錄,女性患者占比49%。患者的各項化驗指標的統計見表2,合并癥記錄統計見表3,患者基本信息統計見表4及圖4。
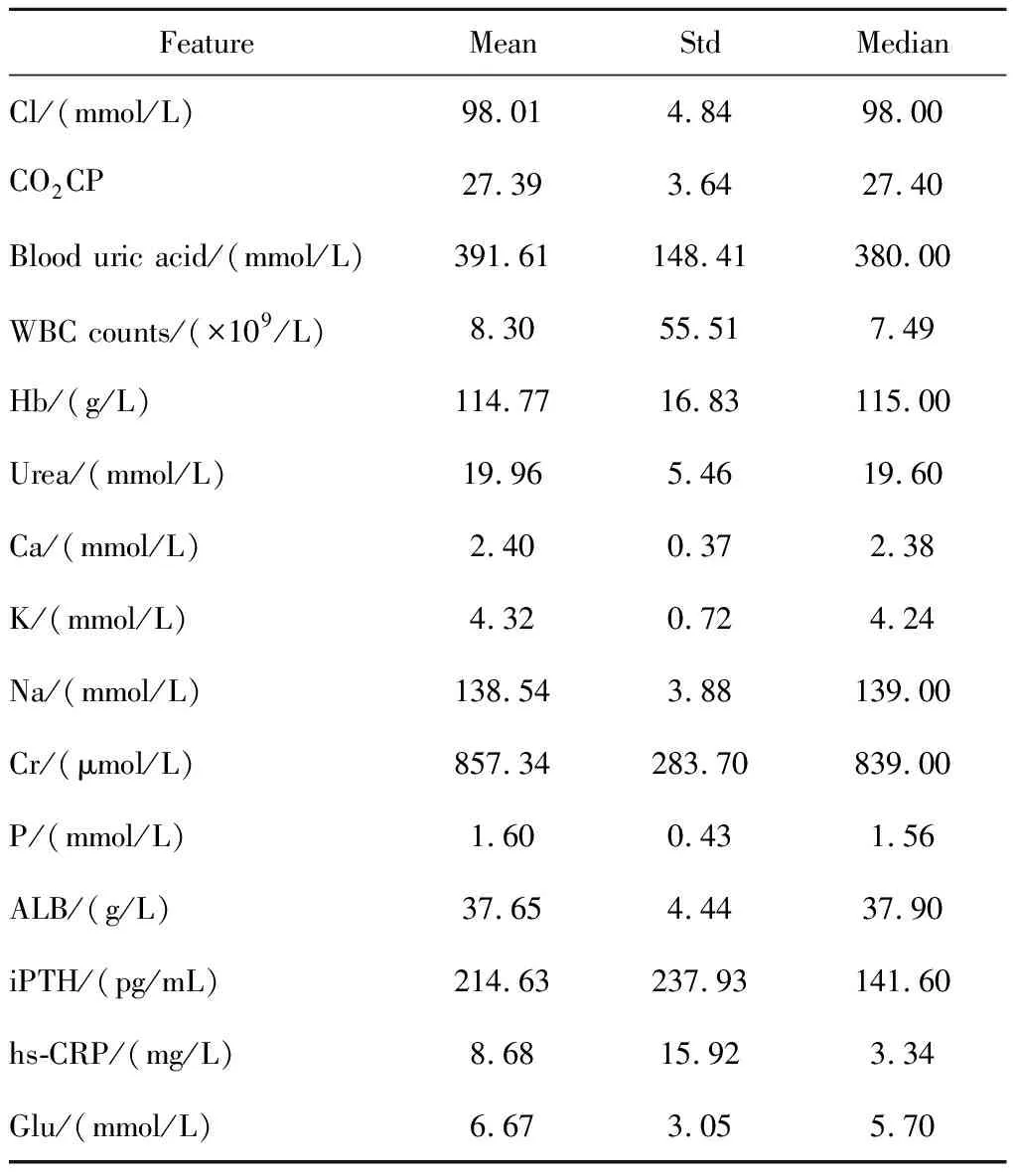
表2 數據集中腹膜透析相關醫療特征統計Table 2 Statistics of peritoneal dialysis clinical features in the dataset
Std, standard devation. Other abbreviations as in Table 1.
2.2 模型的性能比較結果
對GRU、RNN和LR模型的性能進行十折交叉驗證、調整超參數,并在測試集測試,結果見表5,各模型的ROC曲線見圖5。可以看出RNN模型和GRU模型在AUROC、召回率、F1分數三項指標上都明顯優于傳統的LR模型。雖然LR模型已經達到了一定的預測水平,但其未考慮生存時間變量因素,很難隨著患者的不同隨訪時間變化,做出更加準確的預測。RNN和GRU模型與LR模型相比,不僅能夠處理當前狀態數據,還能夠處理時序數據,通過納入患者之前的狀態來對當前狀態進行預測,所以其結果優于LR模型。但RNN模型在處理時序數據時,無法很好地抽取長距離信息依賴,GRU的“更新門”和“重置門”機制很好地解決了這一問題,同時從結果中也可以看出GRU模型的性能有了進一步的提升,說明GRU模型可以更深刻地理解當前數據背后的臨床意義,并且能更好地擬合數據。

表3 數據集中腹膜透析相關合并癥統計Table 3 Statistics of peritoneal dialysis complications in the dataset

表4 數據集基本統計特征Table 4 Statistics information of patients
Std, standard deviation.
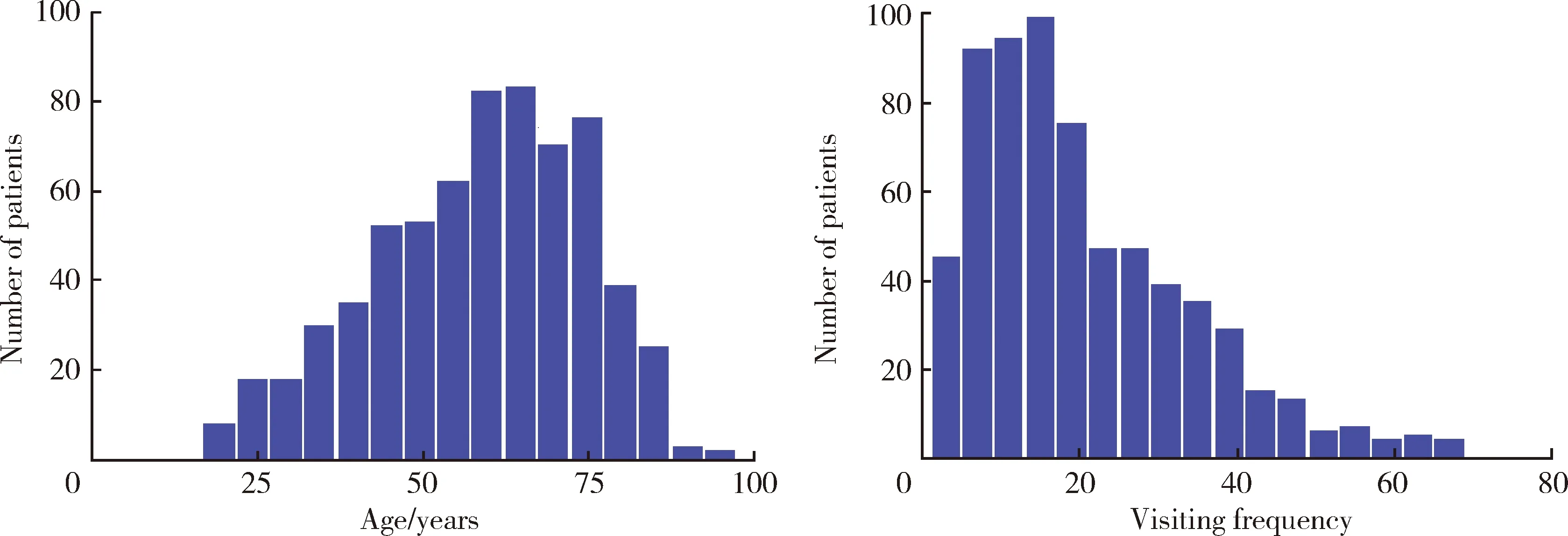
圖4 數據集中年齡與就診頻次的分布Figure 4 Data distribution of age and visiting frequency in the dataset
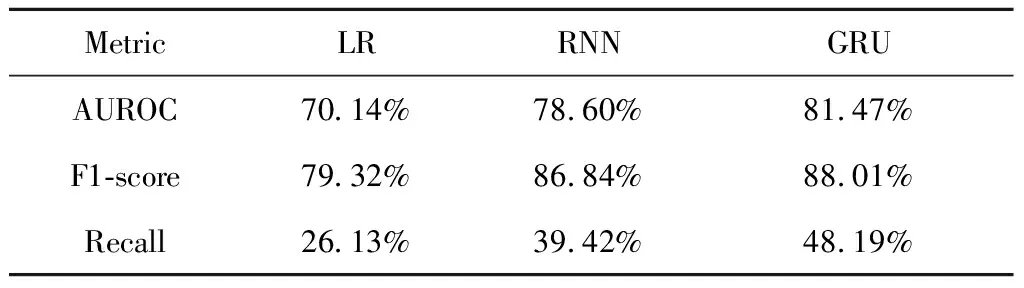
表5 測試集各預測模型性能的平均值Table 5 Average performance of each prediction model in testset
LR, logistic regression; RNN, recurrent neural network; GRU, gated recurrent unit; AUROC, area under the receiver operation charac-teristic curve.
為了確定模型對于不同死亡原因的預測表現,本研究計算了測試集上不同死亡原因的平均召回率。此外,還分析了預測窗口設置為3個月時模型的性能(圖6)。相比于RNN和LR模型,GRU模型具有更好的預測效果,所以下文的結果和討論均使用GRU模型。
3 討論
本研究發現,與傳統的LR模型相比,RNN及其變體GRU模型都具有更優的擬合和預測效果,展現了循環神經網絡模型在臨床預測模型中的潛在應用價值,在此基礎上的數據挖掘可能為臨床提供更為有意義的發現。
此外,根據圖6中模型的表現,我們發現幾種死亡原因(如感染、胃腸道出血、營養不良和癌癥等)具有相當高的召回率,提示模型對于這幾種原因導致的死亡的預測效果較好,但同時,一些死亡原因(如心血管疾病、腦血管疾病)的召回率相對較低,提示模型對急性發病的心腦血管疾病預測效果不佳,進一步提示需要在模型中納入更多可能的危險因素,或在臨床上需要進一步尋找可能的預測因子來提高模型的預測效果。
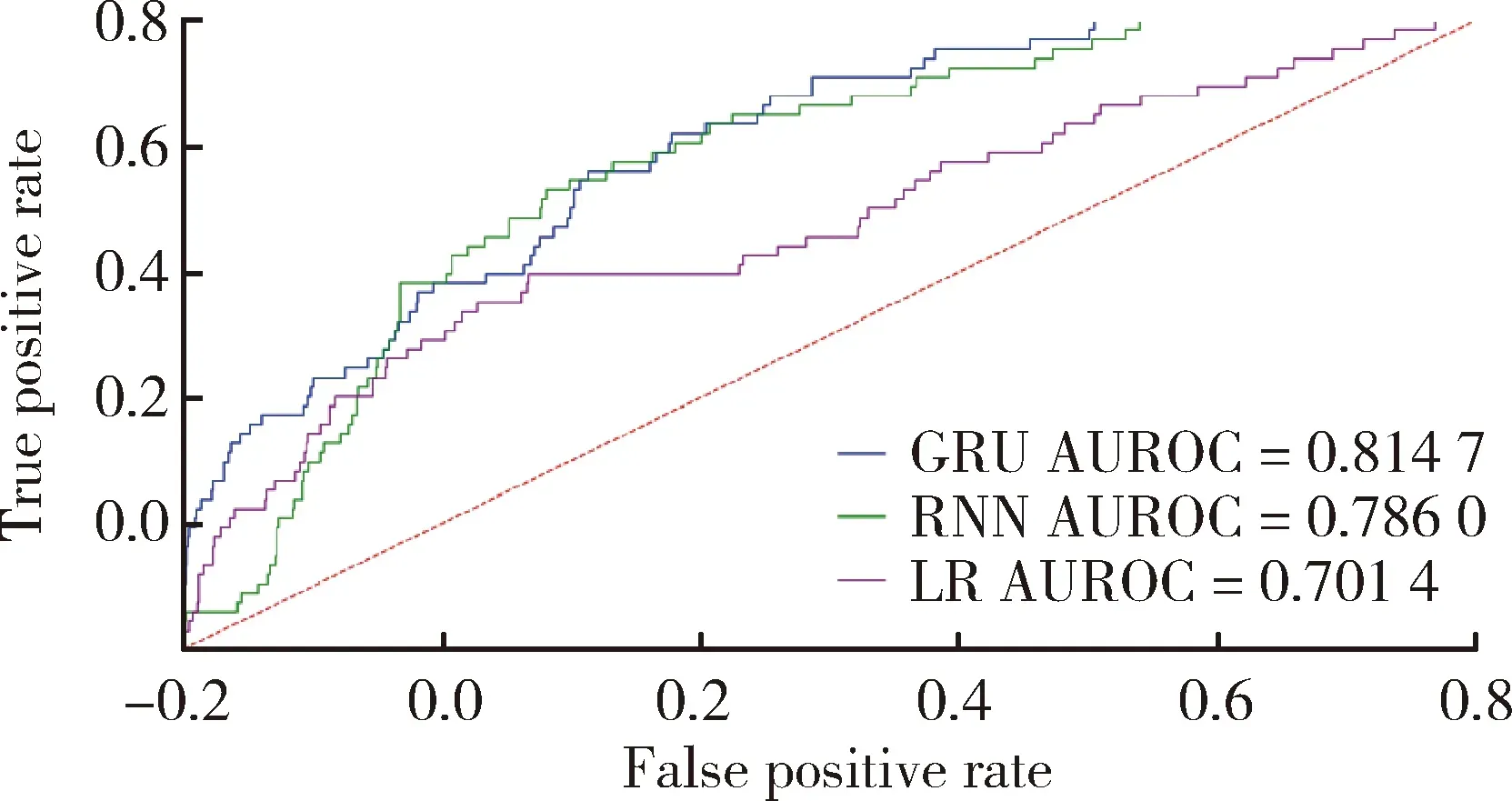
AUROC, area under the receiver operation characteristic curve.圖5 預測模型的ROC曲線Figure 5 ROC of prediction models
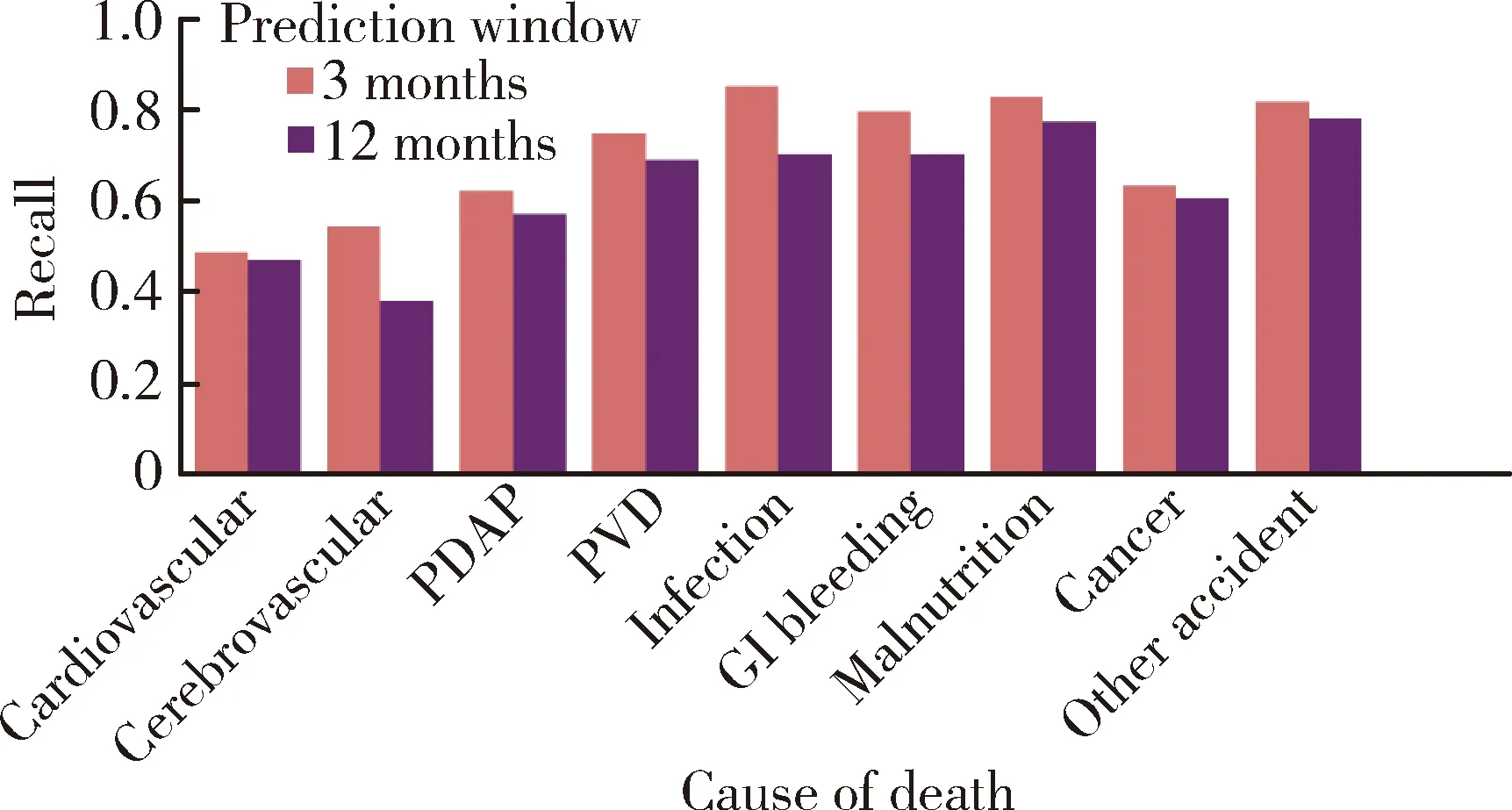
PDAP, peritoneal dialysis associated peritonitis; PVD, peripheral vascular disease; GI, gastrointestinal.圖6 不同預測窗口下對不同死因的召回率Figure 6 Recall of different death reasons at different prediction windows
需要注意的是,心腦血管疾病雖然具有相對較低的召回率,但隨著預測窗口從一年減少到3個月,腦血管疾病的召回率增加,心血管疾病召回率增加不明顯,表明對于患有腦血管疾病的患者,如果醫生可以更加密切隨訪患者,則可以使用現有類型的臨床數據進行預警。而對于患有心血管疾病的患者,當前的臨床信息不足以更準確地對死亡做出預警,因此,臨床上對于心血管疾病的預測,可能需要進行更詳細的測試(如心電圖、心肌酶、冠狀動脈CT血管造影、超聲心動圖等心臟檢查),進一步探索納入這些心臟測試后的模型預測效果。
本研究也存在不足之處,比如數據缺失率較高[2],對風險預測有明顯的負面影響。RNN模型中的機制旨在分析患者健康狀況的變化特征,因此對缺失率較高的數據補全策略引起的異常變化非常敏感。在未來的工作中,將不同來源的數據更合理地結合或進行遷移學習和數據補全可能會解決這一問題。
綜上所述,相比于傳統醫學研究所使用的LR模型,RNN模型,尤其RNN的變體GRU模型的性能更優,更適合預測終末期腎病腹膜透析患者的死亡風險。使用基于循環神經網絡模型的死亡風險預測系統來輔助醫生進行臨床決策和干預,可能有助于臨床醫生更好地隨訪和檢測患者,提高醫療質量。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
