融合領域多詞特征的英文武器裝備名識別研究
2019-06-17 10:01:58雷樹杰邢富坤王聞慧
計算機應用與軟件 2019年6期
雷樹杰 邢富坤 王聞慧
1(戰略支援部隊信息工程大學洛陽校區 河南 洛陽 471003)2(青島大學外語學院 山東 青島 266000)
0 引 言
命名實體識別(Named Entity Recognition,NER)是自然語言處理任務中一項基礎性的工作,可以為自動文摘(Automatic Summarization)、自動問答(Question and Answering)和機器翻譯(Machine translation)等更復雜的自然語言處理任務提供支持。對于軍事領域的信息處理而言,軍事類命名實體的識別同樣起著基礎性的作用,而武器裝備名就是一類非常重要的軍事類命名實體。
1 英文武器裝備名識別概述
武器裝備是武裝力量用于實施和保障戰斗行動的武器、武器系統和軍事技術器材的統稱,通常分為戰斗裝備和保障裝備。戰斗裝備是指在軍事行動中直接殺傷敵人有生力量和破壞敵方各種設施的技術手段,如槍械、作戰飛機、導彈等。保障裝備是為了有效使用戰斗裝備所必需的軍事技術器材,如雷達、軍用測繪器材、野戰工程機械等。武器裝備名可分為類名與具體名,類名是某類武器裝備名的統稱,如槍(gun)、戰斗機(fighter)等。具體名則專指某一款武器裝備的名稱,如“M1”、“J-20”都屬于具體名。從軍事領域自然語言處理任務需求看,武器裝備的類名與具體名都是重要的軍事領域專有信息,都應作為武器裝備名稱予以分析研究。
對命名實體的識別研究主要受到了如CoNLL(Conference on Computational Natural Language Learning)等評測會議的影響,其研究也主要集中在對人名、地名、組織機構名、時間和數字表達式的識別上[1],對武器裝備名的識別研究還較少。這一方面是由于其領域特殊性,另一方面也源于該領域語言資源的稀缺。
早期的命名實體識別方法大都是基于規則的,20世紀90年代之后,基于大規模語料庫的統計方法逐漸成為主流。在這方面的代表工作主要有文獻[2]采用人工標注語料訓練最大熵模型(Maximum Entropy Model),對英文與德文中的人名、地名、機構名以及其他實體名進行識別,取得不錯的效果;文獻[3]采用自助取樣方法(Bootstrapping Method)對統計模型識別出的時間表達式進行迭代、拓展和篩選,在識別準確率和召回率上都取得很大的提升;文獻[4]利用支持向量機(Support Vector Machine)對命名實體進行了識別,獲得了很好的效果;文獻[5]利用Hellinger PCA獲取詞向量并用Structural SVM-HMM作為學習模型對波斯語當中的命名實體進行了識別,取得了較好效果。
綜合來看,現階段對命名實體的識別研究從方法和效果上都取得了很大進步,但仍存在需要改進的地方。首先,對特定領域實體關注不夠,而特定領域實體具有區別于一般命名實體的領域特征,需要給予專門研究;其次,識別模型使用的語言特征較為單一,基本限定在詞形、詞性等普通語言特征,缺少對專門領域知識特征的研究與應用;最后,在以CRF為代表的序列標注模型中,標注單位限定為詞,而由于很大一部分實體特征是由多個詞組合而成,因此單獨以詞為標注單元對有效提取和利用語言特征具有消極影響。
基于以上問題,本研究對CRF標注模型做了兩點改進:一是在模型使用中融合了武器裝備名自身獨有的構造特征,豐富模型使用特征的范圍;二是將模型標注單元由詞擴展到多詞單元,以便模型能更好地利用領域特征。
2 構造模式與特征
英文武器裝備名涉及面廣,命名種類多樣。本文通過維基百科等渠道收集整理6 402條武器裝備名稱,并基于名稱實例及命名特點,對英文武器裝備名的構造模式與特征進行了研究。
2.1 構成成分及分類
針對英文武器裝備名的總體命名特點,本文用兩層分類體系對武器裝備名進行描述:第一層是對武器裝備名的總體性描述;第二層是對描述性要素的具體劃分。任何一個武器裝備名都可以用該分類體系進行描述。
第一層分類將武器裝備名內部構成成分分為型號(A)、別稱(N)、描述(P)、縮寫(R)四類。第二層分類將第一層分類中的型號(A)做進一步區分,區分為系列E和具體型號V;對第一層分類中的描述(P)也做了具體區分。描述類(P)的第二層分類信息如表1所示。

表1 描述類要素及舉例

續表1
2.2 構造模式
基于該分類體系,本文對收集整理的6 402條英文武器裝備名進行人工標注,分析了每一條名稱的構造模式與特征,并對標注后的結果進行了統計分析。表2是對武器裝備名構造模式的統計結果。

表2 武器裝備名構成模式統計結果
統計結果顯示,英文武器裝備名具有明顯的構造規律:其構成成分類型相對有限,其構造模式相對集中穩定。具體來講,英文武器裝備名的構成成分類型在本文的分類體系下只有19種,而64.41%的武器裝備名的構造模式集中在10個主要構造模式上。該結果表明本文針對英文武器裝備名構建的兩層分類體系具有很強的描述能力,也反映出英文武器裝備名具有明顯的領域特征,且該領域特征是自動識別的重要依據。
此外,在調查所得的詞條數為6 402的領域詞典中,有1 205條詞條由兩個或兩個詞以上組成,占比為18.82%。這說明多詞單元在英文武器裝備名的構成成分中占了相當一部分比例。這也要求對這些多詞單元進行組合,以充分利用武器裝備名的領域特征。
3 基于改進CRF的識別模型
英文武器裝備名識別的任務是在文本中識別出武器裝備名的邊界并將其正確歸類,該任務與一般的命名實體識別任務類似,都可以歸為序列標注任務。基于此,本文使用序列標注模型CRF開展相關實驗工作,并結合武器裝備名識別任務對CRF模型進行改進。
3.1 CRF簡介
條件隨機場(conditional random fields,CRFs)是由J. Lafferty于2001年提出,并迅速在自然語言處理領域得到廣泛應用[7]。自誕生以來,CRF模型被廣泛應用于序列標注問題當中,其定義了如下條件概率:
(1)
式中:X為觀測序列,Y為輸出標識序列,λj是特征函數Fj(Y,X)的權重,需要從訓練樣本中估計出來,1/Z(X)是歸一化因子,特征函數Fj(Y,X)包含了轉移函數和狀態函數兩個部分。 CRF選擇了指數函數作為其模型,這是由于指數函數能夠在符合所有邊緣分布的前提下使得熵值最大,符合最大熵原則。相對于隱馬爾科夫模型(hidden Markov models, HMM)而言,CRF消除了獨立性假設,因此能對整個序列內部的信息和外部觀測信息進行有效利用。而相對于最大熵馬爾科夫模型(maximum-entropy Markov model, MEMM)對每一個狀態都有不同的指數模型而言,CRF采用了單個指數模型,因此能有效避免標記偏置問題。
3.2 CRF標注模型的改進
本文對CRF標注模型的改進主要有以下兩點:
一是將武器裝備名的構造特征加入識別模型,從而豐富CRF模型所使用的特征。目前,利用CRF進行命名實體識別一般都是基于詞形、詞性等語言特征[8],這些特征具有提取容易,準確性較高的優點,被廣泛應用在語言序列標注問題中,具有較強的通用性。但是由于詞形、詞性都屬于淺層語言學特征,雖然對命名實體的識別具有一定的指示作用,但難以表征出特定領域的專業特征,因此難以滿足面向特定領域實體的識別需求。針對武器裝備名的識別任務,本研究引入武器裝備名的構造特征,將構造特征與一般語言特征融合使用,從而豐富識別模型所依賴的特征,希望能夠對實體識別起到支持作用。在實際識別中,本文將表1中構成武器裝備名的18個構造特征補充進特征模板。在對文本進行分詞處理后,會對每一個詞判斷其是否屬于這18個構造特征中的一類,如果屬于其中某一類,就將該類的類別特征作為這個詞的一個特征標簽,如果不屬于其中任何一類,則將其特征標簽設為“O”。這樣,識別模型就有了可以依賴的領域特征。如在對“F-18 Super Hornet jets”這個武器裝備名的識別中,識別模型就多了“F”的領域特征“系列E”,“-18”的領域特征“具體型號V”,“Super Hornet”的領域特征“別稱N”,以及“jets”的領域特征“基本類型K”這些領域信息來對該武器裝備名進行識別。
二是將多詞組合作為標注單元。傳統的CRF模型一般都是基于詞進行序列標注,如圖1所示。其中X={x1,x2,…,xn}是觀測序列,Y={y1,y2,…,yn}是狀態序列。

圖1 傳統的CRF模型
但對于英文武器裝備名而言,有很多構成成分是由兩個詞甚至兩個詞以上構成,如在“USS Ronald Reagan(美國海軍軍艦羅納德·里根號)”這個武器裝備名當中,其構成成分分為“USS”與“Ronald Reagan”兩個部分,而“Ronald Reagan”對應特征“具體型號V”,但如果將其分為兩個詞 “Ronald”和“Reagan”后,這兩個獨立的詞不對應任何一個武器裝備名專有的特征,造成特征缺失,其直接影響就是模型可依賴的識別特征缺失,造成識別效果降低。這樣的例子還有很多,如“F-18 Super Hornet jets”中的“Super Hornet(超級大黃蜂)”,“UH-60L Black Hawk helicopters”中的“Black Hawk(黑鷹)”等。為解決此問題,本研究在利用CRF進行實體識別時,將特征提取工作分為兩步,第一步進行多詞單元的識別,第二步進行特征提取。這樣就使得由多個詞構成的特征能夠被有效提取出來,為識別模型提供支持。多詞單元識別基于前期調查總結的英文武器裝備名特征詞表,利用最長匹配方法進行識別。改進后的CRF模型如圖2所示。相較于圖1中傳統的CRF模型而言,改進后的模型觀測序列X={x1_x2,x3,x4_x5,…,xn}。其中,x1與x2、x4與x5被組合為一個多詞單元。狀態序列Y={y1,y2,…,yn}。

圖2 基于多詞單元的CRF模型
3.3 武器裝備名識別框架
在前期對武器裝備名構成模式特征分析的基礎上,本文提取出可以支持CRF模型的武器裝備名構造特征集。在此特征集的支持下,本文對人工標注的訓練文本進行多詞組合與特征標注,并以此訓練CRF模型,得到針對英文武器裝備名的識別模型,并利用該識別模型對測試文本中的武器裝備名進行了識別,具體流程如圖3所示。

圖3 武器裝備名識別框架
4 實 驗
4.1 實驗語料的選擇與加工
本文收集了110篇美國國防部官網2017年度的新聞報道作為待標注語料,并對其中的英文武器裝備名進行了人工標注。本文選取了其中80篇作為訓練語料,另外30篇作為測試語料。
在對110篇新聞報道完成標注后,本文抽取出其中所包含的英文武器裝備名,并利用上文所述的兩層分類體系對所有武器裝備名進行了人工標注。標注完成后,本文統計總結了這些武器裝備名的構成成分和構成模式,并做成了包含(構成成分—構成成分類型對)的領域詞典作為構造特征集。該特征集作為包含了英文武器裝備名構造規律特征的語言資源參與到了對武器裝備名的識別當中。領域特征集如表3所示,表中第一列是武器裝備名構成成分,第二列是該成分所屬構成類型。
本文采用了三元素標注集,三個元素為{B-MILEQP,I-MILIQP,O}。其中,“B-MILEQP”表示一個英文武器裝備名的起始部分,“I-MILIQP”表示英文武器裝備名的非起始部分,“O”表示非英文武器裝備名成分。
4.2 評測標準
只有對文本當中一個完整武器裝備名的各個部分全部標注正確并且對該武器裝備名的后一個其他成分沒有標注為“I-MILIQP”,本文才視為對該武器裝備名識別成功,部分標注正確或標注超出了該武器裝備名的界限則視為標注失敗。
為了更加全面地描述實驗效果,本文設置了六個評價指標,各個指標定義如表4所示。

表4 評價指標
其中,整體標注的正確率Pw用來評價模型對整體文本的標注情況;武器裝備名識別的準確率Pm與召回率Rm用來評價模型對武器裝備名的識別情況;F值則用來綜合評價模型對武器裝備名的識別情況;為了排除模型對某一特定武器裝備名多次識別成功或失敗所造成的對總體評價指標的影響,本文設置了武器裝備名type識別的召回率Rtype這一指標,在這一指標下,對同一武器裝備名的多次識別成功只計算一次;而未登錄詞識別的召回率Ruk則用來評價模型對未登錄詞的泛化能力。
4.3 CRF特征模板
為了驗證英文武器裝備名的構造規律對武器裝備名識別的有效性,本文設計了三個特征模板,如表5所示。
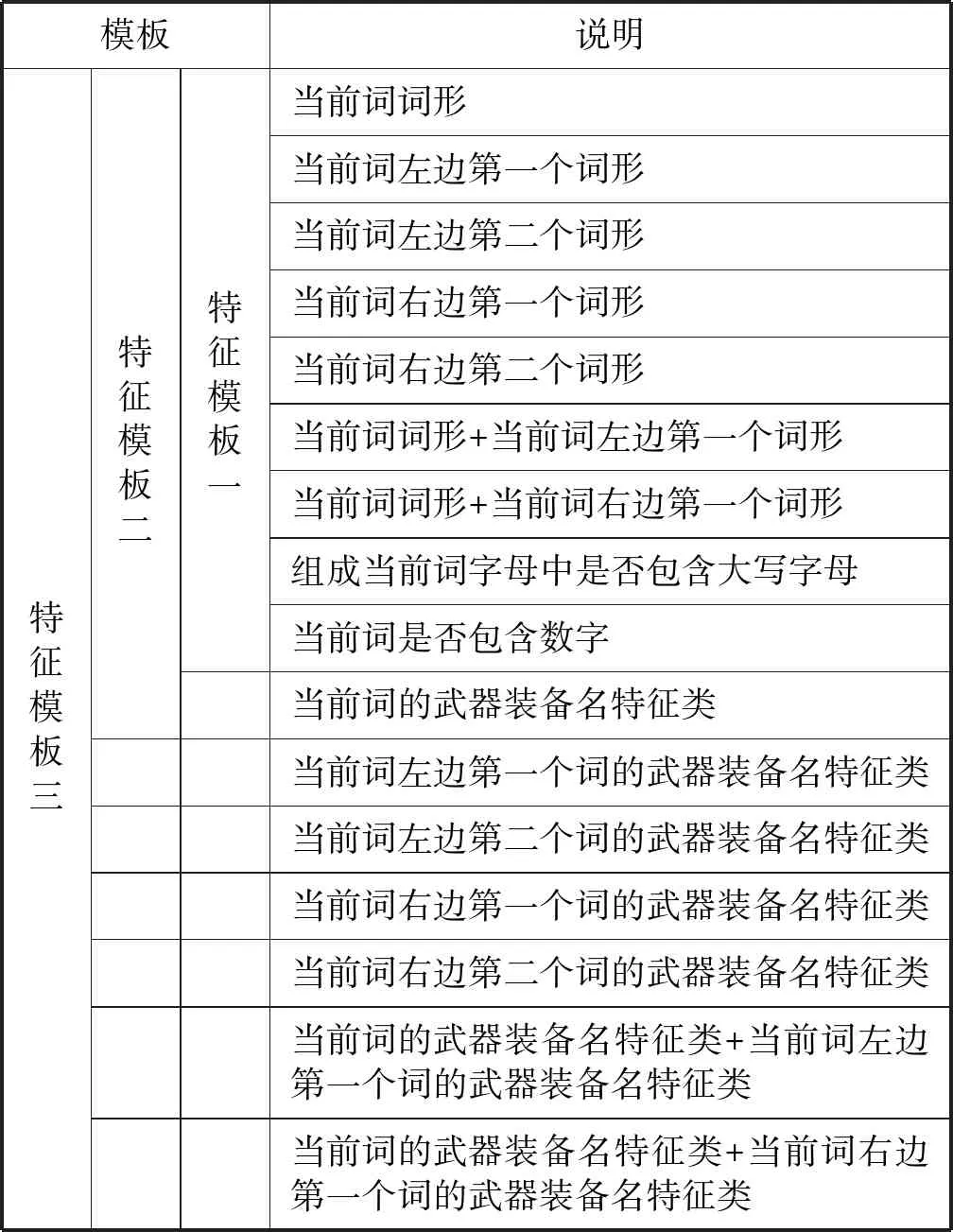
表5 特征模板
在特征模板一中,選取了當前詞詞形本身、當前詞前后各兩個詞形、當前詞與前一個詞的組合、當前詞與后一個詞的組合、是否包含數字、是否包含大寫字母共九個特征作為特征模板,該特征模板主要包含了詞形特征。特征模板二除了包含特征模板一中的所有特征外,還包含了表1中18個英文武器裝備名的構造特征作為語言學特征來支持對命名實體的識別。特征模板三包含了特征模板二中的所有特征,區別在于:在該特征模板中,所有非詞形特征被歸并為一列,對于一個詞可能擁有多個非詞形特征的情況,本文將其所擁有的多個非詞形特征連寫。如Missile這個詞就擁有“包含大寫字母”H、基本類型K與附屬C三個非詞形特征,其特征連寫為“HKC”。在此基礎上,特征模板三還包含了當前詞前后兩個詞的非詞形特征、當前詞的非詞形特征與前一個詞的非詞形特征的組合、當前詞的非詞形特征與后一個詞的非詞形特征的組合共六個特征。
需要說明的是,由于能力有限,本文未能精確地將武器裝備名的每個部分標為該部分在當前實體中所屬的構造特征,而是將其所有可能的構造特征全部賦予該部分。如在“Brimstons Missile”這個詞條中,“Missile(導彈)” 的構造特征是基本類型K。在“Alleigh Burke-class Missile Destroyer”中,“Missile”表示該驅逐艦攜帶有導彈,其構造特征屬于附屬C。本文并未進行這樣的區分,而是把基本類型K與附屬C這兩個構造特征都賦給了文本中的“Missile”作為其構造特征,再加上該詞本身擁有大寫字母特征,使得文本中所有的“Missile”都擁有H、K、C三個特征標注。由此也引出了上文提到的特征模板三中的特征連寫。
4.4 實驗設計及結果分析
為了驗證本文對CRF改進的有效性,本文對基于詞進行序列標注與基于多詞單元進行序列標注在三個特征模板下都做了實驗。三個特征模板所包含特征的層層遞進性能驗證英文武器裝備名的構造特征對識別效果的有效性。此外,本文在以下兩種情況下都做了上述實驗:一種情況是未將測試語料中的未登錄詞的構成成分包含在領域詞典中,另一種情況是將測試語料中的未登錄詞的構成成分包含在領域詞典中。在第一種情況下,由于領域詞典的不完備性,包含了多個詞的未登錄詞并沒有被合并為多詞單元,因此難以驗證多詞單元對識別效果提升的有效性。在第二種情況下,測試語料當中的多詞單元都能得到合并,因此能驗證基于多詞單元進行序列標注對識別效果的提升作用。
4.4.1包含未登錄詞影響的實驗
該實驗沒有將測試語料當中的未登錄詞構成成分包含在領域詞典中,以此來驗證基于改進CRF的識別模型在開放測試集上的識別效果,實驗結果如表6、表7所示。

表6 包含未登錄詞影響的實驗結果1

表7 包含未登錄詞影響的實驗結果2
4.4.2去除未登錄詞影響的實驗
該實驗將測試語料當中的未登錄詞的構成成分包含在領域詞典中,以此來驗證多詞單元對CRF模型識別效果的提升作用,實驗結果如表8、表9所示。

表8 去除未登錄詞的影響的實驗結果1
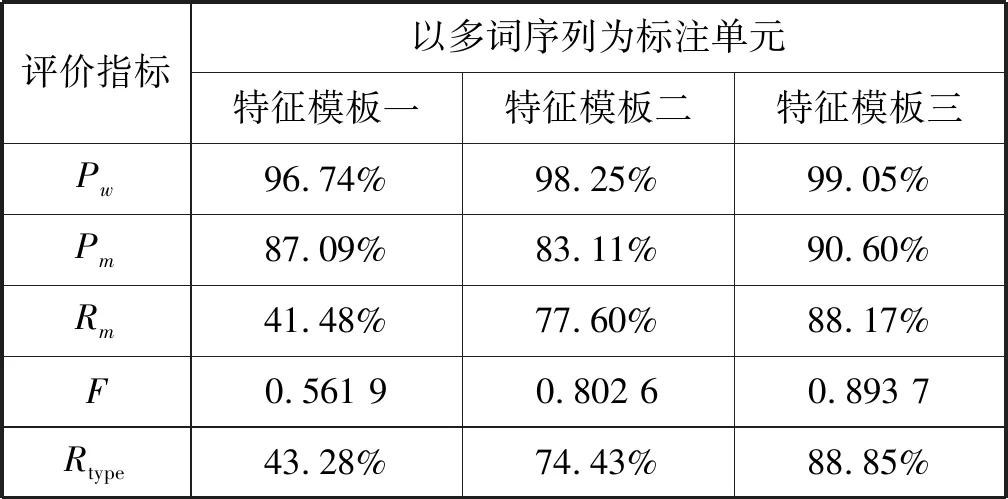
表9 去除未登錄詞的影響的實驗結果2
4.4.3結果分析
本文從四個方面對實驗結果進行分析:
(1) 武器裝備名的構造特征對于識別效果的影響 從實驗結果可以看到,無論是否將未登錄詞的構成成分包含在領域詞典當中,隨著英文武器裝備名構造特征和其上下文構造特征的加入,CRF對英文武器裝備名識別的準確率、召回率和F值都獲得了極大的提升,其中召回率更是得到一倍左右的提升,整體標注正確率也提升近三個百分點,最高達到99%以上。這顯示了英文武器裝備名構造特征對于識別效果的顯著提升作用,并證明武器裝備名構造特征在提升識別效果方面有著相較于其他淺層語言學特征不可比擬的優越性。如在特征模板一,“F-35”這個詞條未被識別出來。而在特征模板二與特征模板三,由于加入“F”的構造特征“系列E”與“-35”的構造特征“具體型號V”,該詞條就被成功識別出。
(2) 多詞組合特征對識別效果的影響 在4.4.2節的實驗中,隨著序列標注從基于詞變為基于多詞單元,識別的各個評價指標都有了極大的提升。這是因為當標注序列變為多詞單元后,更多的構造特征可以加入到識別當中,這樣就帶來了識別準確率和召回率的雙重提升。從另一個意義上講,多詞單元的組合也是將本文前期調查的語言學規則加入模型當中,一定程度上實現了“規則+統計”的識別模式。
(3) 武器裝備名type的識別效果分析 武器裝備名type的召回率體現的是識別模型對不同武器裝備名type的識別能力,排除了模型對同一武器裝備名type的多次識別而導致的識別評價指標虛高的情況。從表6、表7、表8與表9可以看出,當加入武器裝備名構造特征后,武器裝備名type的召回率Rtype有了大幅提升,提升效果在25%以上,尤其是當排除未登錄詞的影響且標注序列變為多詞單元后,Rtype更是提升了45%以上。這一指標變化也印證武器裝備名領域特征與多詞單元對于CRF模型的有效支持作用。
(4) 未登錄武器裝備名的識別效果分析 對于未登錄詞的識別是命名實體識別模型效果的一個重要評價指標,該指標反映的是模型的泛化能力。表6與表7中的Ruk就是識別模型對于測試語料中未登錄詞的召回率。從表中可以看到,在武器裝備名構造特征對識別模型的支持下,未登錄詞的召回率提升了25%以上。這體現了在武器裝備名構造特征支持下的CRF模型具有更強的泛化能力。
但本文的方法也存在一定程度的局限性,本文統計了改進的識別模型識別出錯的原因類型,主要有兩點:
(1) 模型的泛化能力雖有提高,但依然存在能力不足的問題,主要體現在對未登錄詞的識別方面。這主要是由于領域特征詞典的覆蓋度不足。如在4.4.1節實驗當中,隨著標注序列變為多詞單元,識別的各個指標都存在一定程度的下降。這是因為實驗中有大量未登錄詞構成成分未包含在領域特征詞典中,這導致大量多詞單元不能組合到一起,其構造特征也相應不能支持模型對該武器裝備名的識別,因此導致了指標的下降。
(2) 武器裝備名構成特征過強的泛化能力導致模型將不是武器裝備名的詞條識別為武器裝備名。如“CTF-70”本意是美國太平洋艦隊第七艦隊的戰斗指揮部——第70特遣隊。但由于該詞條包含了本文特征模板中的“大寫字母”、“數字”、“具體型號”(“-70”也是一個具體型號),這使得識別模型將其誤判為武器裝備名。
而這兩點不足也是下一步研究要解決的主要問題。
5 結 語
本文抽取了美國國防部官網的110篇新聞報道,對其中的武器裝備名進行了標注,并依據筆者前期的研究成果對這些武器裝備名的構成成分進行了分析,得到了包含了對(構成成分,構成成分類型)的領域詞典。在調查結果的支持下,針對已有CRF應用在命名實體識別領域的缺點,本文對CRF做了兩方面的改進:一是將英文武器裝備名的構造特征加入到了CRF中;二是依據英文武器裝備名的構造特征將CRF從基于詞進行序列標注拓展為基于多詞單元進行序列標注。實驗結果顯示,英文武器裝備名的構造特征和多詞單元都能夠很好地提升CRF對英文武器裝備名的識別效果。在接下來更深一步的研究中,可以將深度神經網絡模型應用到對武器裝備名的識別中,以期達到更好的效果。
本文的研究思路、方法和成果不僅能夠支持軍事領域相關的英文信息處理工作,也能夠對其他語種和其他相關領域的研究提供重要借鑒意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
鄱陽湖學刊(2016年6期)2017-01-16 13:05:41
中國遠程教育(2016年6期)2016-12-07 10:07:02
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年19期)2016-08-11 08:17:03
