一種結(jié)合模型集成的輿情管理模型的研究
2019-06-17 09:28:08唐存琛王極可
計算機應(yīng)用與軟件 2019年6期
唐存琛 王極可
(武漢大學(xué)計算機學(xué)院 湖北 武漢 430070)
0 引 言
隨著互聯(lián)網(wǎng)技術(shù)的發(fā)展,由新浪微博所代表的社交平臺在網(wǎng)絡(luò)輿情傳播中起到關(guān)鍵性的作用。針對網(wǎng)絡(luò)輿情的快速傳播性導(dǎo)致網(wǎng)絡(luò)輿情難以監(jiān)控的問題,本文提出了一種結(jié)合模型集成的網(wǎng)絡(luò)輿情管理模型,使得有需求的研究人員和有關(guān)部門能參照此模型更好地實現(xiàn)對輿情信息的監(jiān)控和社交平臺的分析與管理。本文所設(shè)計的模型分為兩個子模型:輿情信息采集子模型與輿情信息分析子模型。傳統(tǒng)的網(wǎng)絡(luò)輿情管理模型大都注重其分析采集后的輿情信息,而忽略了對數(shù)據(jù)采集模塊的構(gòu)建。該模型相較于傳統(tǒng)模型,增加了采集輿情信息模塊化,針對現(xiàn)時主流的公共社交平臺,設(shè)計出了一個采集模型,使得在輿情采集上,能夠以較快的速度獲取質(zhì)量高、數(shù)據(jù)量大的輿情信息,為下面的輿情分析模型奠定了良好的基礎(chǔ)。而在輿情信息分析子模型當(dāng)中改進了現(xiàn)有的輿情分析算法設(shè)計,與傳統(tǒng)的輿情分析模型對比,本文提出的新模型在輿情信息采集以及輿情分析方面有了一定的提升。
1 模型總體架構(gòu)
模型由輿情信息分析模型與輿情信息采集模型兩個子模型組成,總體架構(gòu)如圖1所示。整個模型放置兩個接口,一個用來連接輿情信息采集子模型與數(shù)據(jù)預(yù)處理模塊,另一個用來連接數(shù)據(jù)庫與輿情信息分析子模型。在確定所需要的輿情信息后,通過輿情信息采集模型采集到相關(guān)輿情信息數(shù)據(jù),然后進行數(shù)據(jù)預(yù)處理存入數(shù)據(jù)庫,數(shù)據(jù)庫里面的數(shù)據(jù)通過輿情信息分析模型分析后得到輿情報告。
2 輿情信息采集子模型
2.1 模型設(shè)計思想
數(shù)據(jù)是分析的先決條件,只有存在大量有效數(shù)據(jù)時才能進行分析。因此輿情信息采集是整個網(wǎng)絡(luò)輿情管理模型的基礎(chǔ),是該網(wǎng)絡(luò)輿情管理模型的重要組成部分。國外的科研人員在很早之前就針對Twitter、Facebook等大型社交平臺開展了一系列的分析[1-2],此外Facebook等知名社交平臺都會提供較大量的數(shù)據(jù)給研究人員,使其研究能順利開展。而國內(nèi)的社交平臺所提供的API[3]的種類有限,接口對爬取數(shù)據(jù)也有嚴(yán)格限制,這就導(dǎo)致國內(nèi)研究人員想通過官方提供的接口獲取研究所需的數(shù)據(jù)難度加大。現(xiàn)在市面上雖然有很多抓取軟件,如“Easy Web Extract”、“Data Scraping Studio”、“八爪魚”等,但經(jīng)過調(diào)研,這些軟件都有著一定的缺陷,采集的數(shù)據(jù)不能完全滿足研究和管理人員的需求。因此一些研究和管理人員在實驗中為了追求合適的數(shù)據(jù),還是需要去實現(xiàn)自己的一套爬蟲代碼,給輿情的獲取增加了時間成本與人力成本。特別是一些實時熱點輿情,更需要研究和管理人員能夠以最快的速度,分析出輿情走向,得到輿情報告。該子模型對國內(nèi)各大社交網(wǎng)站進行調(diào)研后,為不同的平臺設(shè)計其特定的采集器模塊,能夠滿足不同場景下的需求。
2.2 社交平臺頁面分析
本小節(jié)對國內(nèi)各大社交平臺網(wǎng)站頁面進行分析,根據(jù)現(xiàn)時情況將此模型分為三部分。
2.2.1輿情信息采集需求
研究和管理人員在研究一些輿情信息的時候,會對信息的來源等條件有一定的要求,故此模型根據(jù)所需數(shù)據(jù)的要求將數(shù)據(jù)采集分為兩個模塊:一是通用采集,即全站采集,對數(shù)據(jù)不進行篩選,將頁面上所有信息進行采集,數(shù)據(jù)清理后,存入數(shù)據(jù)庫;二是聚焦采集,對特定的信息進行采集,例如關(guān)鍵字采集等[4-5]。
(1) 通用采集 在通用采集中,一般有深度優(yōu)先和廣度優(yōu)先兩種策略[6],即采用廣度優(yōu)先與深度優(yōu)先不斷獲取URL,進而爬取到所有所需的頁面數(shù)據(jù)。算法1是通用采集深度優(yōu)先的策略的偽代碼。
算法1深度優(yōu)先偽代碼
Begin
def depth_crawler(main_page):
get main_page.data
get main_page URLS
for url in URLS:
get url.data
depth_crawler(url)
End
(2) 聚焦采集 聚焦采集是采集模塊中的重點和難點。例如對于較為常用的關(guān)鍵字、特定發(fā)布時間、特定發(fā)布地點信息的采集,算法2是聚焦采集的偽代碼。
算法2聚焦采集偽代碼
Begin
Get key_words, key_time, key_location
def key_word_crawler(data.url):
If match(key_words, key_time, key_location):
Get page_data
def key_word_crawler(data.url)
End
2.2.2頁面信息獲取
現(xiàn)階段各大社交平臺都有動態(tài)頁面,這些頁面利用JavaScript動態(tài)加載頁面數(shù)據(jù),這種頁面用普通爬蟲是爬取不到頁面內(nèi)的關(guān)鍵數(shù)據(jù)的,因此該模型設(shè)計了兩個采集模塊:獲取靜態(tài)頁面數(shù)據(jù)的靜態(tài)頁面采集器和獲取動態(tài)頁面數(shù)據(jù)的動態(tài)頁面采集器。靜態(tài)頁面采集器可直接獲取頁面當(dāng)中所有的信息數(shù)據(jù),而動態(tài)頁面采集器又分成兩個子模塊:請求分析采集模塊與模擬瀏覽器模塊。請求分析采集模塊需要根據(jù)動態(tài)頁面數(shù)據(jù)加載情況采用特定的獲取方式,以獲取后臺傳輸?shù)臄?shù)據(jù);模擬瀏覽器則相對簡單,此模塊模擬人為操作瀏覽器的方式,使頁面動態(tài)數(shù)據(jù)傳輸?shù)角岸巳缓蟾鶕?jù)靜態(tài)頁面采集器的采集方式采集信息數(shù)據(jù)。
2.3 模型基本架構(gòu)
通過對社交平臺網(wǎng)站分析,設(shè)計出了如圖2所示的輿情信息采集子模型框架,該子模型包括4個大模塊分別是:聚焦采集接口、通用采集接口、靜態(tài)頁面采集器與動態(tài)加載采集器。請求分析采集與模擬瀏覽器是屬于動態(tài)頁面采集下的子模塊。圖3是整個輿情信息采集子模型的流程圖,輿情信息采集通過通用采集與聚焦采集后,根據(jù)采集頁面加載數(shù)據(jù)的形式,采用不同的采集器,在完成獲取之后,執(zhí)行數(shù)據(jù)處理并將其存儲在數(shù)據(jù)庫中。
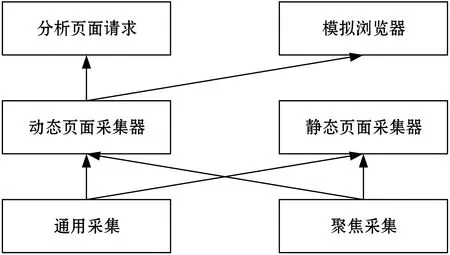
圖2 輿情信息采集子模型架構(gòu)
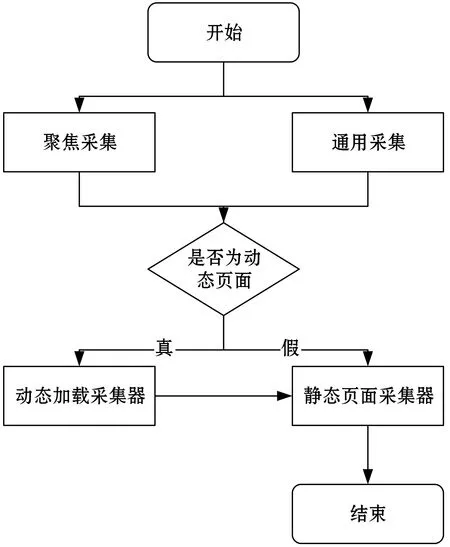
圖3 輿情信息采集子模型流程圖
2.4 模塊化采集器
通過上小節(jié)對各大社交平臺網(wǎng)站的分析,本模型提出了數(shù)據(jù)采集模塊化的概念。即是針對各種不同的場景將靜態(tài)頁面采集器劃分為不同的采集模塊如圖4所示,例如新浪微博采集模塊與知乎采集模塊,使其能方便快捷應(yīng)對各類需求與場景。研究人員與管理人員可以根據(jù)不同的場景調(diào)用不同的模塊,對不同的平臺網(wǎng)站信息進行采集。
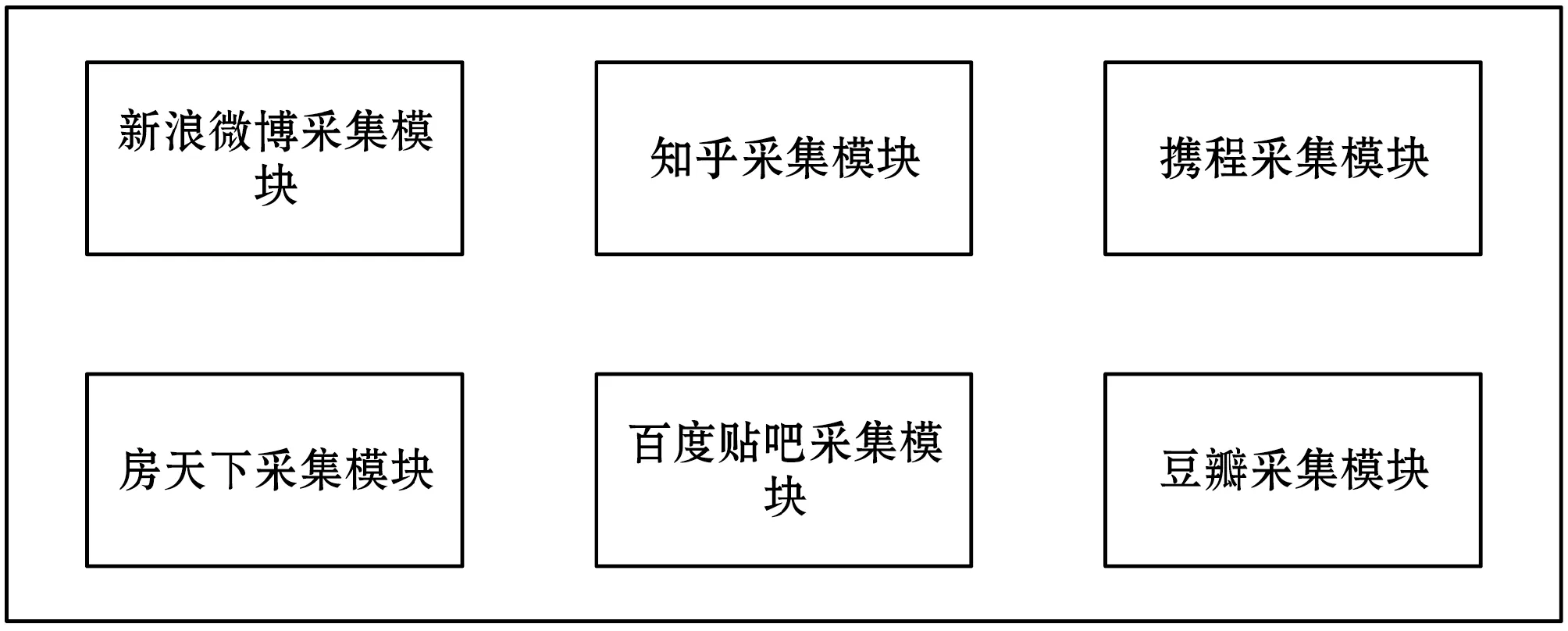
圖4 模塊化采集器
3 輿情信息分析子模型
輿情信息子模型的作用是將數(shù)據(jù)庫中的輿情信息進行分析,產(chǎn)生分析結(jié)果。對比現(xiàn)在各種單一的分類器模型,為使得到的分析數(shù)據(jù)更加精準(zhǔn),模型在原有的單個分類器模型基礎(chǔ)上進行調(diào)整,設(shè)計了如圖5所示的集成模型框架。新的分析模型主要由一個聚類器和一個分類集成器組成。輿情信息首先通過聚類器得到聚類分析結(jié)果,然后通過一個分類集成器得到分類分析結(jié)果。該模型可確保不同組的基分類器之間的差異性,使得最終的結(jié)果更加精確。
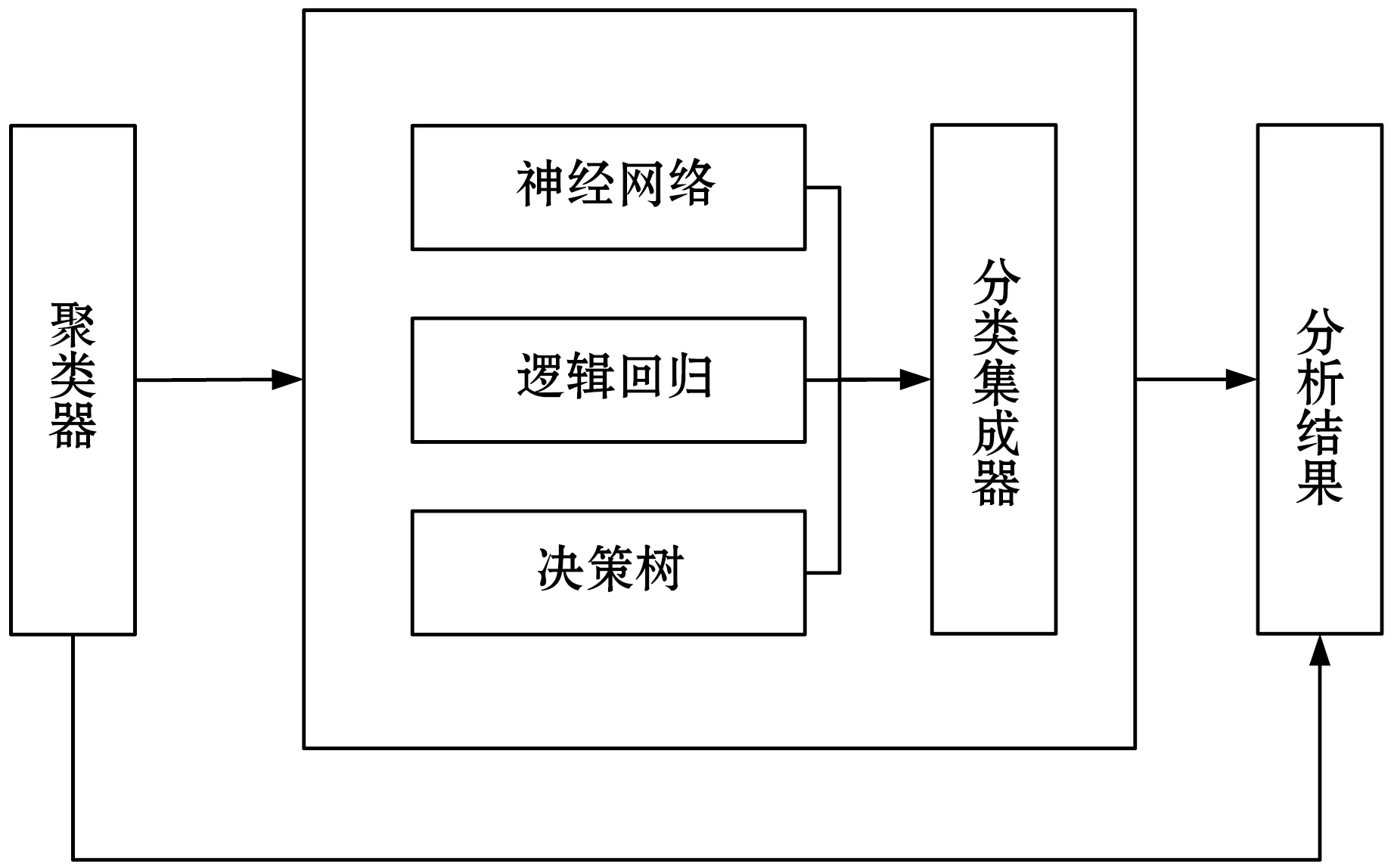
圖5 輿情信息分析子模型架構(gòu)
3.1 聚類器
聚類自從其誕生已來就已經(jīng)被用在了各大領(lǐng)域中,其作用是把具有相似特征的個體劃分到一個簇當(dāng)中,本文中聚類器起到了將所有具有相似含義、情感的輿情劃分到一起的作用。到目前為止,聚類算法大體上可以分為基于劃分的方法、基于層次的方法、基于密度的方法、基于模型的方法[7]。基于劃分的方法的核心步驟是將數(shù)據(jù)劃分為多個簇,而K-Means算法則是該聚類方法中最為簡單有效的一種。
3.2 分類集成器[8]
我們以3.1節(jié)提到的聚類器生成的聚類結(jié)果為輸入數(shù)據(jù),在此基礎(chǔ)之上在每個簇團上進行分類操作,將具有相似特征的輿情數(shù)據(jù)進行更加詳細(xì)的分類。分類常用的分類集成模型有串行的Boosting[9],并行的Bagging[10]以及隨機森林[9]。集成模型由兩部分組成:一是作為基本分類器的弱分類器;二是分類器的結(jié)合策略。本模型根據(jù)實際情況,調(diào)研各種集成模型,最終設(shè)計采用以下三種弱分類器作為基本分類器:決策樹、邏輯回歸、神經(jīng)網(wǎng)絡(luò)。
決策樹:決策樹跟數(shù)據(jù)結(jié)構(gòu)當(dāng)中的樹相似,通過每一次的分枝來一次次分類,最終解決分類問題。
邏輯回歸:邏輯回歸模型是現(xiàn)在用來處理分類問題的比較常用的模型,它是在線性回歸的基礎(chǔ)之上加上了一個邏輯函數(shù),使其能夠較好地處理分類問題。
神經(jīng)網(wǎng)絡(luò):神經(jīng)網(wǎng)絡(luò)是近年來較為火熱的領(lǐng)域之一,其主要分為循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)、深層神經(jīng)網(wǎng)絡(luò)(DNN)以及卷積神經(jīng)網(wǎng)絡(luò)(CNN)。而在文本分類上,循環(huán)神經(jīng)網(wǎng)絡(luò)有著較好的效果,故該模型采用此神經(jīng)網(wǎng)絡(luò),能夠更好地處理文本分類的問題。
利用單獨模型對微博信息進行情感分析,然后通過集成的方式,對所有單獨模型的分類結(jié)果進行集成,最后利用“簡單投票法”的集成策略將多個分類模型集成在一起,得到最終分類結(jié)果。
設(shè)計好聚類器與分類集成器之后,將這兩部分連接起來組成完整的輿情信息分析子模型。訓(xùn)練時,先將訓(xùn)練樣本的輿情信息數(shù)據(jù)經(jīng)過K-Means聚類器,從而形成多個簇,然后在每個簇上利用由神經(jīng)網(wǎng)絡(luò)、邏輯回歸、決策樹三種弱分類器組成的分類集成器進行訓(xùn)練,最終得到訓(xùn)練好的模型。
4 模型實現(xiàn)與測試
4.1 模型實現(xiàn)
為了測試本模型的應(yīng)用性,本節(jié)中就以此模型為基礎(chǔ),采用標(biāo)準(zhǔn)的Django架構(gòu),前端使用AngularJS框架。通過以上兩個主要的框架,使得輿情管理系統(tǒng)能夠在短時間內(nèi)完成搭建。Diango是基于Model-Template-View(MTV)的一個Python框架。將Control層改為了Template層,將之前的Control層植入框架自動完成。正因為如此,模型搭建維護更加簡單方便,更易于二次開發(fā)。其中數(shù)據(jù)存取層(Model)用于處理與數(shù)據(jù)相關(guān)的所有事務(wù);業(yè)務(wù)邏輯層(Template)用于處理與表現(xiàn)相關(guān)的決定;表現(xiàn)層(View)用于存取模型及調(diào)取恰當(dāng)模板的相關(guān)邏輯[11]。模型實現(xiàn)后的系統(tǒng)架構(gòu)如圖6所示。
根據(jù)上述系統(tǒng)架構(gòu),設(shè)計了如圖7所示的網(wǎng)絡(luò)輿情管理系統(tǒng)流程圖,首先用戶需要登錄模型,如未注冊用戶,需經(jīng)注冊才能使用本模型。登錄后根據(jù)用戶其需求采集相關(guān)的輿情信息;采集完畢后,選擇所采集的數(shù)據(jù)集進行分析,最后選擇所需要的圖表生成輿情報告。
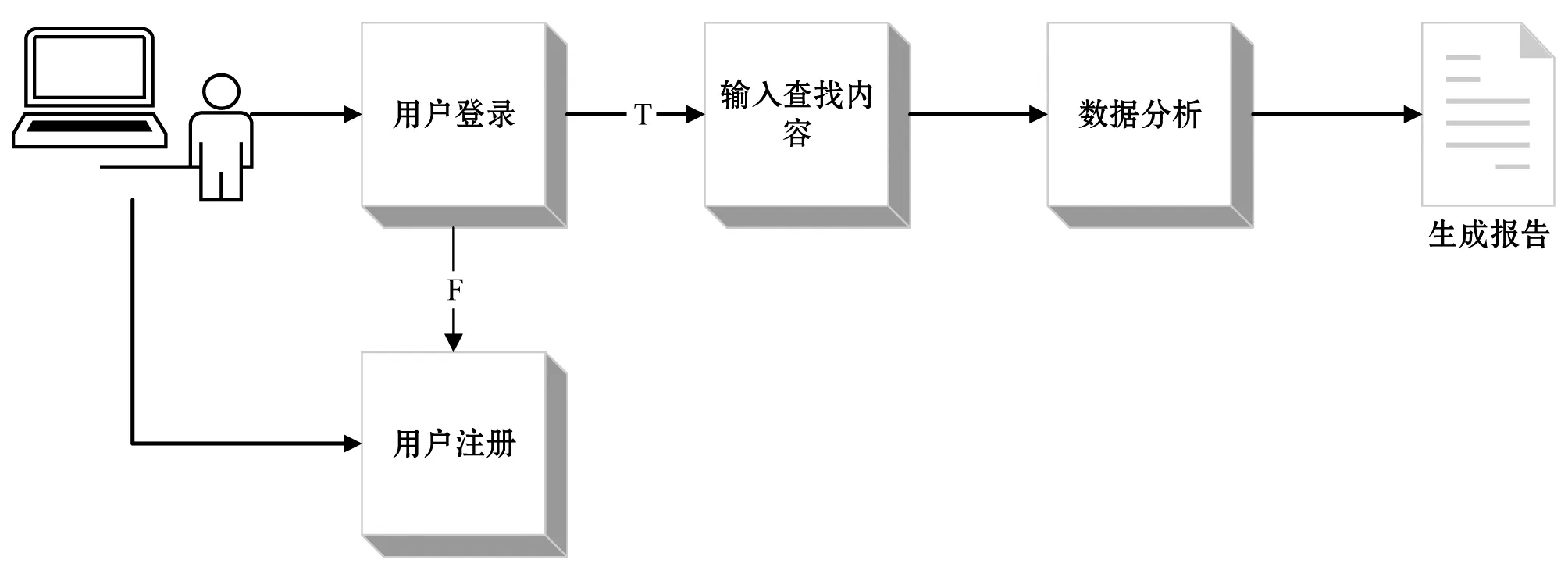
圖7 網(wǎng)絡(luò)輿情管理系統(tǒng)流程圖
4.2 輿情采集子模型效率測試
基于上小節(jié)所實現(xiàn)的系統(tǒng),本節(jié)對模型的性能進行測試。在眾多數(shù)據(jù)的采集過程中,新浪微博信息的采集是比較困難的,現(xiàn)以新浪微博中關(guān)鍵字?jǐn)?shù)據(jù)采集為例,將“邪典視頻”與“直播答題”作為關(guān)鍵詞進行輿情信息采集。圖8是本模型的信息采集子模型與“八爪魚采集器”采集信息數(shù)據(jù)量的對比。從圖中可明顯觀察出,本文所采用的模型在新浪微博的關(guān)鍵字采集量上大約是“八爪魚采集器”的十倍,在采集量上有明顯的優(yōu)勢。
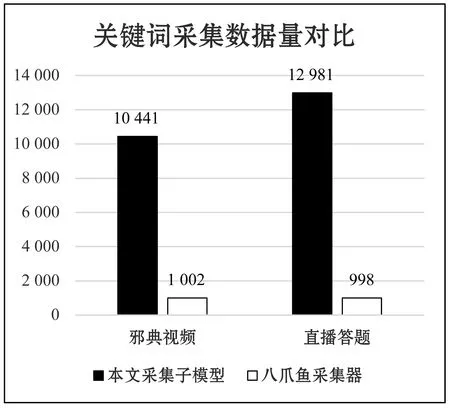
圖8 關(guān)鍵詞采集數(shù)據(jù)量對比
4.3 輿情分析子模型準(zhǔn)確率測試
本測試使用了兩個數(shù)據(jù)集,分別是Reuters數(shù)據(jù)集和斯坦福德的IMDB電影評論情感二分類數(shù)據(jù)集。而作為對比的是集成模型隨機森林,隨機森林是由多個決策樹組成的強分類器。圖9是分類正確率的測試結(jié)果。通過圖9可以觀察出,本文所提出的輿情分析集成模型較隨機森林算法在正確率上有一定地提升。
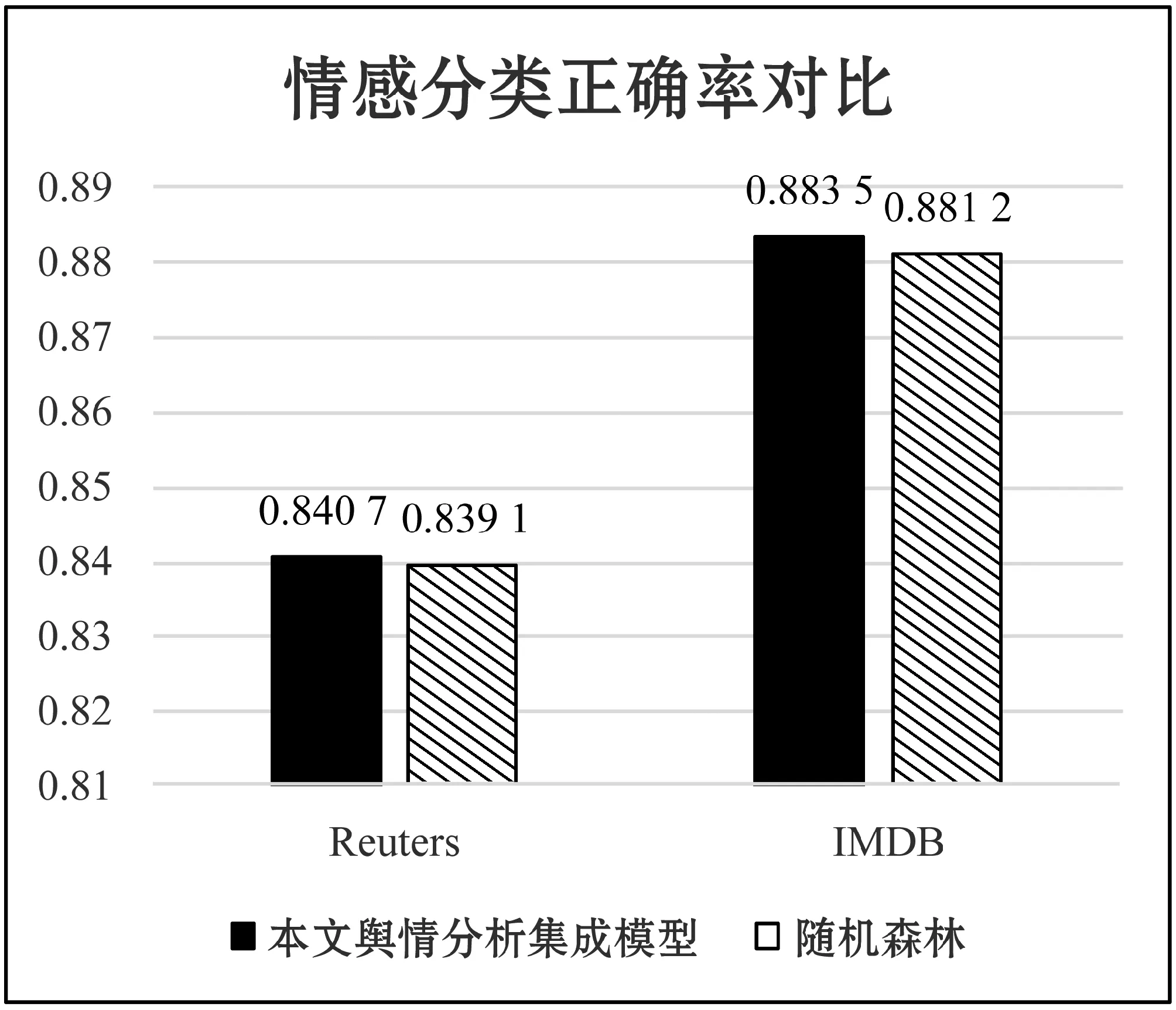
圖9 情感分類正確率對比
5 結(jié) 語
針對網(wǎng)絡(luò)輿情的快速傳播性導(dǎo)致網(wǎng)絡(luò)輿情難以監(jiān)控的問題,設(shè)計出一種結(jié)合模型集成的網(wǎng)絡(luò)輿情管理模型。該模型提出了新型的模塊化采集信息子模型,在與現(xiàn)時一些爬蟲軟件的對比中有較強優(yōu)勢;同時根據(jù)一種新的集成學(xué)習(xí)算法思想設(shè)計出輿情信息分析子模型,相較于單個分類器分析模型在精度上有一定的提高。本文所提出的輿情管理模型有較強的應(yīng)用性,為網(wǎng)絡(luò)輿情分析與管理提供了新的途徑。同時此模型也有一些需要改進的地方,特別是在輿情分析子模型上還存在很大的提升空間,以后的工作將圍繞提升集成模型的正確率展開。
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫(yī)苑(2022年1期)2022-08-30 08:39:14
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
民用飛機設(shè)計與研究(2020年4期)2021-01-21 09:15:02
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:24
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
山東工業(yè)技術(shù)(2016年15期)2016-12-01 05:31:22
電腦愛好者(2011年11期)2011-06-22 08:20:18
