企業級海量代碼的檢索與管理技術?
2019-06-11 07:40:08劉志偉邢永旭張曉東
軟件學報 2019年5期
劉志偉,邢永旭,于 澔,李 濤,張曉東
1(百度(中國)有限公司,上海 201210)
2(百度在線網絡技術(北京)有限公司,北京 100193)
3(西安交通大學 計算機科學與技術系,陜西 西安 710049)
軟件開發過程中所涉及到的活動非常廣泛,比如需求編寫、代碼開發、編譯、部署等等.研究發現,代碼搜索是軟件開發活動中最為頻繁的活動之一[1].比如,Google工程師每工作日使用代碼搜索多達12次[2].為了避免重復造輪子的過程,尤其在企業開發實踐中代碼搜索更為普遍,因為在企業里構建軟件幾乎都不是從零開始,而是通過復用大量代碼完成構建.因此,尋找程序員感興趣的代碼片段或者 API使用方式等代碼搜索活動變得非常重要[3].
然而,構建企業級的代碼搜索系統是非常困難的.
· 首先,代碼量巨大,Google代碼庫超過20億行[4],百度使用Git(https://git-scm.com/)進行代碼管理,Git存儲代碼規模空間就多達TB級.更為關鍵的是,代碼量時刻在急速增長中,百度平均每天新增代碼153萬行,刪除代碼 63萬行.因此,企業級的代碼搜索工具必須能處理海量的代碼數據,并且能保證代碼更新的時效性,這是極為困難的.
· 其次,大規模的企業里所使用的開發語言往往較為繁雜,在百度,包括各種腳本語言、數據庫語言等在內,使用了多達30種以上的編程語言.由于不同語言的語法分析不同,并且不能限制在單語言內進行搜索,使得在企業里提供針對語法代碼檢索變得非常困難.
· 再次,不同企業對代碼的管理方式不同,比如,百度利用多分支與多 tag的方式進行代碼管理.雖然 Git會優化多分支與多 tag的存儲,但是如果不加以對于重復的處理,將會造成代碼索引的迅速膨脹,使得搜索引擎工具很難容納如此海量的索引數據.
· 然后,企業內對如何提升海量代碼搜索質量的研究仍不足,比如在百度,通過用戶輸入一個單詞或幾個單詞組成的query(query是用戶進行搜索的關鍵詞,比如方法名或者類名),在數十億行的代碼文件進行查找,返回給用戶想要的結果是非常難的.因此,必需要利用豐富的特征信息,對大量代碼搜索結果進行排序.此方面的研究尚比較缺乏.
· 最后,如何保證檢索效率,能夠在百度TB級的索引數據中ms級內完成檢索,并且呈獻給用戶,也極具挑戰性.
互聯網搜索引擎比如百度、Google等也有檢索代碼的功能,但是還沒有考慮代碼本身特征進行索引排序等策略,效果還不理想.Google內部有強大的代碼搜索引擎,兼顧易用性以及準確性,當前對外可以通過 chromium(https://cs.chromium.org/chromium/)體驗.商業的代碼搜索軟件,比如 Krugle(http://www.krugle.com/)以及insight.io等,通過關鍵詞進行搜索,以及代碼托管網站,比如 Github(https://github.com/)、Bitbucket(https://bitbucket.org/)等也提供了通過關鍵字進行代碼搜索功能,這類工具的搜索準確性還有待提升.同時,已有大量代碼搜索的研究工作[5-11],有的工作對用戶查詢的輸入形式進行約束,比如 Kashyap等人[6]開發的 Source Forage引擎以 C/C++函數的形式作為輸入,以便更好地利用語法與語義,更精確地對相似代碼進行查找.有的工作是定義規約化的語言,讓用戶描述自己想要搜索的需求,從而能更容易地找到用戶需要的結果.然而,這種約束用戶輸入復雜的查詢條件的方法在企業里往往不現實.與自然語言的搜索引擎一樣,復雜的輸入將會限制用戶的使用.在企業的實際開發過程中,用戶只是會輸入簡單的一個或幾個單詞組成的查詢語句,比如搜索函數 sort,期望找到大家普遍使用、功能為排序的函數;如果用戶輸入code search,那么可能搜索code search這個系統的代碼庫,或者出現在文件路徑上的這個單詞,其次才可能是包括這個詞的文件.另外,比如近期的研究中,Gu等人[5]是以自然語言作為query,利用神經網絡學習的方法搜索到與自然語言語義上所匹配的代碼片段,達到利用自然語言檢索到實現相關功能代碼段的目的.
然而,從企業級軟件開發的角度看,絕大部分是邏輯較為復雜的業務代碼,而不是可以用自然語言具名描述的算法或者過程;同時,企業開發中,往往由于業務進度壓力,代碼缺乏豐富的注釋,文檔也經常落后代碼迭代的速度,這也使得無法訓練出解釋代碼語義的模型.根據 Google的研究[2],在實際研發過程中,工程師搜索代碼的需求主要包括如何使用一個API、API如何實現、API定義在哪里等,由此可見,企業級軟件開發過程中代碼搜索這一環節,工程師搜索出發點是已經有關鍵詞.此外,每個Google工程師每次搜索平均使用1.85個關鍵詞(中位數是 1個關鍵詞).因此,針對企業級的海量代碼,與自然語言的搜索引擎一樣,利用簡單關鍵詞進行檢索匹配代碼的方案更為實用與迫切.
針對百度的實際需求以及企業開發中的現狀,本文提出了一套企業級的代碼搜索的實現方案,包括離線建庫部分和在線端用戶搜索部分.離線部分負責將不同的代碼相關的源數據,比如 Git代碼庫,以批量或實時增量等方式進行獲取,然后經過數據分析,比如進行語法識別、語法解析等,持久化到分布式海量數據庫(Elasticsearch集群)中.在線端負責完成用戶的實時代碼搜索,主要包括:首先是針對用戶的請求進行鑒權,保證權限安全;其次,在確定搜索請求安全后,對用戶的query關鍵詞進行變換處理,以搜索更多的相關的代碼;再次,向分布式數據庫進行請求,并獲得檢索到的結果;最后,對檢索結果進行排序,利用高級定制化的排序算法返回給用戶更合理的結果.另外,本系統使用緩存管理以提高搜索的性能,利用摘要生成模塊以為每條結果提供描述.
此代碼搜索系統自推出上線以來,索引了百度TB級的Git庫,并能在分鐘級準確索引變更代碼,支撐平均每天新增代碼153萬行、平均每日刪除代碼63萬行的索引,能夠針對文件、代碼庫、代碼提交時間等進行搜索.該系統在百度內部使用過程中,每周平均為數千名工程師提供代碼搜索服務,每周平均完成數萬次的搜索,平均每次檢索時間為1s以內.
根據調研,本工作是首次站在企業海量的代碼數據上,提出以及應用包括針對代碼的query變換、提出了更多代碼相關的特征并應用其進行排序的方法、針對代碼搜索結果的排序評估方法、摘要生成等創新性的技術,形成一套實用的代碼搜索方案.本文的主要工作貢獻如下.
· 在工業級的海量代碼上,提出了代碼的 query變換,應用新的代碼相關特征進行排序,且提出代碼排序的評估方法;同時,結合摘要生成,使得根據用戶簡單的輸入即可給出用戶想要的搜索結果.
· 并且針對此方案,實現了一套實用效果極佳的企業級系統,索引了百度 TB級的代碼,且能在分鐘級處理每日百萬級代碼行的變更.
本文第1節概述系統框架并簡介應用到的技術.第2節介紹代碼搜索系統的工作流程.第3節對系統進行實際應用的評估.第4節列舉系統當前不足之處.第5節是相關的研究工作.第6節進行總結與未來工作的展望.
1 方案框架概述以及應用到的技術簡介
本文提出的企業級代碼搜索系統主要由離線端和在線端兩部分組成.離線端采用Elasticsearch作為持久化存儲,Elasticsearch是一個基于Apache Lucene(TM)的開源搜索引擎,它提供了一個分布式多用戶能力的全文搜索引擎,是當前流行的企業級搜索引擎.離線端主要目標是將不同的代碼源數據以批量或實時增量等方式獲取,同時導入代碼等相關數據,然后經過數據分析,持久化儲存到Elasticsearch集群中.為了實現此目標,離線端分為3層:數據導入、數據分析、索引管理.
· 數據導入模塊主要負責適配各種代碼數據源.在百度的實際應用中,主要以 Git倉庫為主,除了批量獲取數據,還對數據源進行監聽以實時導入變更代碼庫.
· 數據分析模塊主要由多個流水線解析器組成,解析器主要完成編碼檢測、代碼提交信息萃取等工作.通過對代碼以及其衍生數據(比如編碼信息、作者提交信息、文本屬性等)的解析,獲得抽象語法樹(abstract syntax tree,簡稱AST)和代碼相關數據,其中,AST解析由Eclipse CDT/JDT完成,Eclipse CDT/JDT是基于Eclipse平臺并提供C/C++(CDT),Java(JDT)集成開發環境的插件.
· 索引管理模塊主要負責海量數據在分布式情況下的持久化存儲與管理,主要采用Elasticsearch作為數據索引存儲.索引化數據除了支持代碼檢索,也應用在了代碼跳轉上.由于代碼跳轉是另外的話題,本文不詳細展開.
在線端主要負責實時響應用戶關鍵詞搜索,實現包括接口管理、搜索管理、隊列管理.
· 接口管理模塊主要包括請求鑒權和數據收集,其中,請求包括兩類:一是單個用戶的關鍵詞搜索,二是來自各個產品線的API調用(比如代碼重復度查詢).百度產品線眾多,不同的產品代碼有著嚴格的保密等級,因此,標識用戶身份、防止機密代碼泄露,做到代碼安全是搜索系統所必須的.因安全相關與本文關聯不大,這里暫略過.
· 搜索管理主要包括查詢變換、Ranker、緩存管理、摘要生成模塊.此外,搜索管理模塊還通過分析用戶搜索行為數據,反饋給Ranker,提高了搜索質量和相關性.
· 隊列管理主要負責對Elasticsearch分布式數據庫的并行訪問與參數優化.
如圖1所示,當用戶在前端發生一次代碼提交后,系統監聽到代碼變更消息,通過增量的方式完成整個流水線,以達到實時性的目標.當用戶在檢索端嘗試搜索時,系統適當調整query關鍵詞后,根據不同用戶權限,通過在緩存、全文索引、語法索引等不同index中搜索,在原始召回的結果中應用ranker中的排序策略,并在最終的結果中提煉最相關的摘要片段返回給用戶,以完成整個檢索過程.
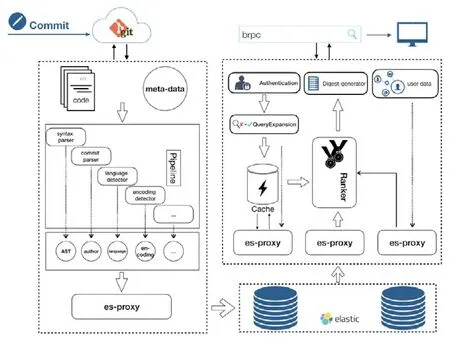
Fig.1 Interactive process chart of Baidu code search圖1 百度代碼搜索用戶交互流程圖
2 方案實現
2.1 代碼數據爬蟲與代碼索引
爬蟲是搜索引擎系統中不可缺少的組成部分,代碼檢索系統的爬蟲同互聯網爬蟲一樣[12-14],從遠端系統獲取數據.代碼數據爬蟲負責是從各種代碼管理系統獲取海量的代碼數據,比如 SVN(https://subversion.apache.org/)、Git,然后進行代碼索引.除此之外,在企業中數據安全也是數據爬蟲端遇到的重要問題,尤其是代碼數據,是企業的核心資產,代碼數據數據的爬蟲與索引同樣需要極高的安全保障,不能使得爬下來的代碼發生泄漏的可能.由于安全是另外非常重要的話題,且并不是本文的重點,因此這里并不會展開闡述.
代碼數據爬蟲需要解決的主要問題是數據的時效性和數據的準確性:時效性指在海量的代碼數據情況下,比如百度數TB以上的Git代碼庫基礎上,還能實時處理平均每日新增與刪除的數百萬代碼數據,能夠確保新變更的代碼數據能夠被快速索引到,以便用戶把代碼合入代碼庫后,即可進行搜索;數據的準確性是指在如此大規模的數據變更索取下,索引的數據不能和真實的數據有所偏差,否則會造成用戶的使用障礙.因此,本文系統所設計的代碼數據爬蟲分為3個服務:批量爬蟲服務、定時爬蟲服務、實時爬蟲服務.
批量數據爬蟲負責遍歷全代碼庫進行索引,主要的用途是第 1次構建代碼搜索,或者由于代碼索引技術的升級,需要再次進行全庫重新索引,比如在第 1次索引代碼的時候沒有進行代碼變更時間的索引,所以需要再次
全庫重新索引,這時都需要利用批量數據爬蟲服務.實時索引是代碼庫合入事件觸發的,每次只會索引變更的代碼文件,因此能保證在分鐘級甚至更少的時間索引完成.定時索引的任務是為了確保數據的準確性,因為在整個系統中并不能保證服務是 100%可用的,我們必須進行容錯處理,比如事件觸發可能沒有通知到爬蟲系統,或者爬蟲系統所在的機器異常等情況.基于系統是可能出錯的前提下,需要保證代碼索引數據的準確性,就需要一個額外的定時索引任務,它會對比索引的數據與真實代碼數據之間的差異,處理可能由于錯誤引發的數據異常.為了提高代碼數據爬蟲索引代碼的效率,數據爬蟲系統被設計為是多個進程、多個線程在多物理機上執行,能夠很好地使得機器的負載均衡.
代碼數據爬蟲系統除了關鍵的 3個服務以外,還有一個特殊的代碼去重的服務.因為正如在第 1節簡介中所描述的,在百度是通過分支、tag對代碼進行管理,如果針對分支、tag進行代碼索引,就需要跟默認開發分支或者稱為主干代碼進行去重,因為分支、tag的代碼跟主干代碼會非常大量的重復代碼.對大量的重復代碼進行索引,不僅造成存儲空間的浪費,同時降低了搜索性能,并且如果用戶搜索出大量的重復代碼,并沒有什么意義,這降低了用戶的體驗,所以必須要對索引代碼進行去重.對索引代碼去重有多種方式,首先推薦的是在代碼索引之前,利用Git命令查找出,不同分支、tag與主干代碼的區別,然后只對這些有區別的代碼進行索引.這種方法往往意味著再次遍歷全代碼庫,并且效率也很低.另外一個方法是,利用 Elasticsearch的索引庫進行去重,因為在Elasticsearch進行信息檢索非常高效.判斷文件內容的重復,可以利用一個文件內容的md5或者直接使用一個文件的Git blob(https://git-scm.com/book/en/v2/Git-Internals-Git-Objects)信息,md5或者Git blob可以唯一標識一個文件,如果在索引庫里一個md5或者Git blob值出現了多個文件,那么就需要對這些文件進行去重.
利用上述方案,在代碼數據爬蟲解決了數據的時效性和準確性后,就可以進行真正的代碼索引了.因為在企業實際應用中,用戶不僅可以對代碼進行搜索,也希望對代碼庫進行搜索,所以也需要索引代碼庫本身的屬性信息.但是代碼庫本身的屬性信息和代碼文件是完全不同的索引,需要對他們進行分別索引.
對于代碼庫的搜索而言,圖2中代碼庫的屬性信息是非常重要的,比如代碼庫的類型,它是一個公開的還是一個私有的代碼庫,這個屬性在企業里控制代碼庫是否開放給其他人進行訪問查看.再比如代碼庫編程語言,如果一個進行搜索的開發者,他本身是長期開發PHP的,那么這個開發者在搜索字符串的時候,比如sort,他有很大的概率是在尋找PHP下的sort函數,而不是C++或其他編程語言的,因此,索引了代碼庫的下編程語言有哪些這樣的數據,代碼搜索系統就可以進行更為精確的查找.
同樣,對于代碼搜索而言,圖2中的代碼文件的屬性也是對于搜索來說非常重要的,比如編程語言的識別,同上面講的代碼庫的編程語言識別作用一樣.再比如最近提交作者與時間,則對豐富代碼搜索系統的功能很重要,使得用戶可以檢索一段時間內的代碼,或者針對開發者進行搜索.其中,對代碼搜索而言,非常重要的一個屬性就是語法.代碼不同于自然語言,更加結構化.語法的信息能夠幫助系統更容易給出用戶想要的結果,比如用戶在搜索代碼時,經常會使用函數名、類名、變量名等作為query,因此需要對所有語言進行語法解析,獲取到代碼的語言元素,從而提高搜索質量和相關性.雖然語法解析的工具已經很成熟,但是實際上在企業里解析海量代碼的時候,依然困難重重,比如,C++是百度的主流編程語言之一,雖然使用了 CDT這樣非常成熟的工具,但它的解析還是很困難,因為除了語法本身比較復雜(https://en.wikipedia.org/wiki/Most_vexing_parse),每個編譯單元(單個 cpp文件)還需要準確的給定頭文件輸入和預處理宏定義才可能進行正確的語法處理,本系統通過解析百度內部編譯工具Bcloud(開源版本broc(https://github.com/baidu/broc))的中間產出,收集了所有頭文件和宏定義,再通過項目依賴關系進行二次推測來降低CDT解析符號的錯誤率完成索引.

Fig.2 Index data of code圖2 代碼索引數據
2.2 query變換
代碼搜索是基于文本搜索匹配的技術,而用戶給出的 query和真正的代碼片段可能不盡相同[15],為了提高檢索效率和相關性,適當地對用戶的輸入詞進行糾錯或調整,是每個搜索引擎所必須的.
近年來,不少用于代碼搜索的query變換方法被相繼提出,比如:Wang等人[16]將用戶的意見納入代碼搜索引擎返回的反饋代碼片段,以優化結果列表;Roldan-Vega等人[17]通過計算同一個詞與查詢中的詞的頻率來建議替代查詢詞;Lu等人[18]通過利用查詢和 WordNet[19]中每個單詞的詞性(POS)來擴展查詢,并提出了一種表示為PWordNet的查詢擴展方法;Lemos等人[20]基于WordNet和與代碼相關的同義詞庫自動擴展測試用例.
本系統通過分析大量用戶行為,發現大部分錯誤均為諸如下劃線(_)和短橫線(-)混淆等誤寫 1~2個字符的情況,借鑒文獻[17],本系統保存最常引用、最常搜索點擊的詞為候選集合,并基于編輯距離的貝葉斯模型獲得最可能的輸入調整.算法詳細如下.
對于給定的query關鍵詞w,期望從候選集合中找到用戶實際最可能搜索的詞c,即求解條件概率最大的c:
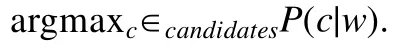
根據貝葉斯公式(https://en.wikipedia.org/wiki/Bayes’_theorem),上式等價于
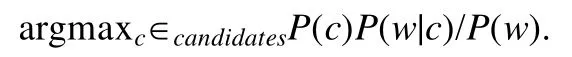
不妨假設P(w)為常數,即用戶搜索任意關鍵詞概率相等,得出:

問題轉變為求出c的概率和w與c的某種概率關系.
· 首先構造候選詞c集合,通過分析已索引中的數據和用戶行為統計,將最常引用、最常搜索點擊的詞存為候選集,即{word:〈ref_count,click_count〉},那么P(c)=〈ref_count,click_count〉,因total_count對于所有c相等,遵循避免除法原則,P(c)=〈ref_count,click_count〉.
· 其次,w與c的概率關系,如上所述,用戶多數情況下為手寫錯誤或混淆某個字符,因此,系統通過編輯距離來模擬,即,編輯距離越近,則概率越大.此外,除了用戶最多誤寫 1個~2個字符,加之對系統實時性能的約束,系統最終采用了編輯距離小于2的概率計算.
2.3 搜索策略
2.3.1 Elasticsearch原生排序的問題
Elasticsearch的原始結果是根據文本匹配程度排序的(https://www.elastic.co/guide/en/elasticsearch/guide/current/scoring-theory.html),每個結果會計算 query出現的次數(TF)和 query在倒排索引中出現的次數(IDF),TF/IDF作為此結果的得分,并用來排序.但對于代碼搜索,Elasticsearch的打分能夠提供一定的參考,但文本匹配程度并不是最理想的排序方式,因為它忽略了代碼的結構、語義等[8].比如,當搜索函數名的時候,用戶更希望獲得它的函數聲明、定義和針對該函數的單元測試等.
2.3.2 ranker模塊整體方案
如圖3所示,從Elasticsearch獲取的結果,首先根據庫歸類為多個群組;接下來,根據庫本身的屬性調整分數;最后,在每個庫群組的結果中,根據語法策略判斷結果的語法屬性,最后對所有結果重新排序分頁.
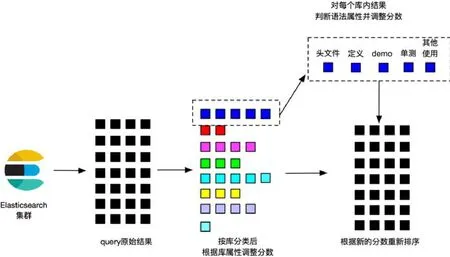
Fig.3 Rough sketch of search strategy圖3 搜索策略示意圖
2.3.3 根據代碼庫權重調整
結果會按照下面公式根據代碼庫權重調整:
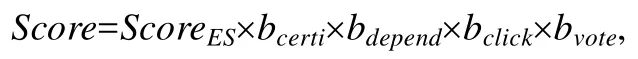
其中,
·ScoreES為Elasticsearch的原始得分,代表結果的文本匹配程度;
·bcerti為認證的公共基礎模塊(包括開源三方庫)的權重調整系數,該認證列表由公司的各編程語言技術委員會提供;
·bdepend為離線計算的庫之間依賴關系的權重調整系數;
·bclick為用戶在搜索中點擊數據生成的權重調整系數;
·bvote為用戶對搜索結果投票數據生成的權重調整系數.
其中,bclick和bvote會在線定時根據新的數據更新權重.
2.3.4 語法策略
經過代碼庫權重的調整,每組結果會根據離線生成的語法數據庫判斷屬性,如果能夠判斷為函數或類的聲明、定義、單元測試等,則標記為對應的語法元素.以 C++為例,同一個函數的聲明所在頭文件會優先于對應的源代碼文件.
2.3.5 摘要生成
為了提高用戶體驗,絕大多數搜索引擎都會為用戶提供摘要預覽,代碼搜索也不例外,通過展現與搜索詞最相關的代碼片段(摘要),以減少用戶尋找相關結果的時間,提高點擊的精準率.
3 實際應用評估
3.1 實施場景
本系統索引了百度所有的Git代碼庫,總數據量為TB級,平均每天新增代碼153萬行,刪除代碼63萬行.
系統功能強大,同時支持代碼搜索、代碼庫搜索和文件搜索.搜索結果可以根據編程語言歸類,支持全部主流編程語言.提供包括庫名、編程語言等的篩選.
搜索響應時間在1s以內.搜索結果會對代碼更改保持接近實時的更新,代碼從提交到可被搜索到,間隔時間為分鐘級.
本系統的用戶包括了大部分的百度開發人員,每周的使用用戶數千人,每周總搜索次數達數萬次,工作日提交代碼的開發者平均進行7次搜索.
3.2 搜索結果精度
3.2.1 評估指標
信息檢索的常用評估指標為精確率和召回率(https://en.wikipedia.org/wiki/Precision_and_recall).
· 這兩個評估指標在某種程度上是互相矛盾的.對于搜索引擎,由于召回率相對容易滿足,一般更常用精確率作為主要評估指標.
· 評估單個搜索關鍵詞的精確率,本系統采用Precision@N(以下簡稱P@N).即,對每個關鍵詞預設N個最佳結果,和實際搜索結果的前N項進行比較,匹配數量/N作為此關鍵詞的精確率.根據定義,P@N結果在0~1之間,實際選取的N值為5.
· 評估代碼搜索的整體精確率,本系統采用 Mean Average Precision(https://en.wikipedia.org/wiki/Evaluation_measures_(information_retrieval)#Mean_average_precision)(以下簡稱 MAP),即,對所有預設的關鍵詞得到的P@N結果,再取平均值.MAP的得分在0~1之間.
3.2.2 關鍵詞選取和設置預設最佳結果
關鍵詞從用戶實際搜索的熱門關鍵詞中選取,經過人工選擇.
預設最佳結果同樣要避免過多的人為因素,采用用戶數據分析加人工優化選擇方式.用戶數據包括用戶實際搜索的點擊數據、用戶都搜索結果的投票統計等.人工選擇部分,針對不同的用戶搜索模式設置不同的評估原則,見表1.

Table 1 Measurement principle of different types of query words表1 不同關鍵詞類別的評估原則
以上評估原則綜合參考了多種方法[2,21,22]并進行了用戶調研,調研覆蓋了百度內部多個部門的各種主流編程語言開發人員,超過80%的受訪者認可上述原則.系統上線后的統計信息也表明,表1中的關鍵詞類別覆蓋了超過90%的搜索.
3.2.3 一個例子
正如前文概述中所述,工程師常用的搜索大多是一個 API或者類名,從線上環境取一個用戶實際 query baidu::rpc::Controller作為本次評估用例,這是baidu-rpc庫(一個C++的網絡服務基礎庫,即百度對外開源的brpc(https://github.com/brpc/brpc)的內部版本)的一個類名,根據前述原則和代碼實際結構,設置5個期待結果及說明見表2.

Table 2 Expected results of baidu::rpc::Controller表2 baidu::rpc::Controller的期待結果
實際搜索結果共計2 700余個,其中前5個均為本庫內結果,可見表3.

Table 3 Actual results of baidu::rpc::Controller表3 baidu::rpc::Controller的實際結果
和前述期待結果對照,共計3個匹配,此搜索詞P@N得分為0.6.
作為對比,在GitHub上進行對應的搜索,注意:開源版本的brpc和公司內baidu-rpc在namespace和代碼結構有所區別,但基本可以對應.比如,搜索關鍵詞相應的變更為brpc::Controller,它的聲明頭文件在brpc庫的src/brpc/controller.h
對全 GitHub代碼的搜索中(https://github.com/search?q=brpc%3A%3AController&type=Code),搜索結果的前2頁沒有任何來自brpc庫的結果.第1個來自brpc的結果出現在第27條.
對brpc庫內搜索(https://github.com/brpc/brpc/search?q=brpc%3A%3AController),其前5條結果見表4.

Table 4 Actual results of brpc::Controller on GitHub code search表4 brpc::Controller在GitHub代碼搜索的實際結果
和前述期待結果對照,只有第3條匹配,GitHub在此搜索詞的P@N得分為0.2.
3.2.4 搜索精度得分
如表5所示,作為對比,同時列出Elasticsearch原始結果的MAP得分.

Table 5 MAP score表5 MAP得分
4 不足之處
當前實現的系統還有幾個不足之處.
· 首先是還沒有更好地利用代碼相關的各種屬性使得搜索結果更好.代碼相對于自然語言有著明確的語法約束以及語義,現在僅能對語法元素在搜索結果的排序上進行處理,但是尚未通過分析或者挖掘代碼語義進行優化搜索結果的排序.
· 其次,尚未充分利用代碼之間的調用關系.在傳統的信息檢索中,PageRank算法使得相關度較高的網頁獲得更靠前的排序[23].與之類似,代碼中的函數與函數之間、類與類之間、文件與文件之間、代碼庫與代碼庫之間,皆存在著清晰明確的調用關系.目前還沒有充分挖掘調用關系以及和代碼相關聯的數據特征,在未來可以利用知識圖譜[24]、PageRank等技術優化代碼搜索的排序結果.
· 再次,尚未利用開發者的自身信息.代碼不是孤立存在的,編寫代碼的開發者也具有獨特的特征,比如在企業里,每個開發者的代碼權限是不一樣的,每個開發者的技能水平也是不一樣的.
· 最后,尚未挖掘用戶行為信息.代碼搜索系統推出以后,大量用戶開始使用,已經累積大量的用戶行為數據,比如在什么時間進行了哪些搜索、在哪頁第幾個結果上進行了點擊、用戶瀏覽搜索結果的停留時間、用戶查看結果并且更新了搜索詞進行了二次搜索、用戶對結果條目進行了滿意度評價等等.這些行為數據可以用來進行點擊率預估[25],使得系統給出的搜索結果更加符合用戶預期.
5 相關研究工作
近年來,代碼搜索領域的研究者提出了許多不同的搜索方法,絕大多數通過自然語言或者自定義的規格對用戶輸入約束,返回抽象調用序列、函數片段等不同粒度的代碼.簡要介紹如下.
· Yahav[26]以部分代碼作為輸入,基于對象類型查找語義相關的代碼片段.
· DEEPAPI[5]使用深度學習循環神經網絡的方法,對于給定的查詢語句,生成API用法序列.
· Sourcerer[27]在代碼實體完全限定名上使用TF-IDF技術,結合right-most handside boosting技術和圖排序算法來查找功能的實現代碼、現有代碼片段的使用及包含特定屬性及模式的代碼.
· Xsnippet[10]給對象實例化任務提供示例代碼,靈活設定查詢范圍,并根據代碼片段長度、出現頻率等進行啟發式排序.
· Portfolio[28]利用函數調用圖建立模型,模擬編程者瀏覽及關聯其他函數行為,檢索到能夠解決查詢語句中描述的多項任務的具體函數.
· Mica[29]為用戶提供更多API使用的相關信息,返回相關的API方法類和域,并根據頻率相關性排序.
· PARSEWeb[30]與Google Code Search Engine交互,通過對代碼分析,將代碼片段抽象表示成方法調用序列的形式,然后對方法調用序列進行聚類和排序.
· Exemplar[31]結合信息檢索和程序分析技術,使用方法關鍵字匹配查詢應用的描述、源代碼以及幫助文檔.
· RACS[32]聚焦JavaScript框架代碼特征,支持自由形式的查詢語句,使用方法調用關系圖來描述API調用之間的復雜關系;同時,從自然語言查詢語句中也捕捉相對應的關系,提高了 JavaScript框架代碼示例搜索的準確率.
· SP[8]基于用戶提供的規格描述(包括關鍵字、類或方法簽名、測試用例、約束、安全限制),檢索出滿足要求的函數及類.
· Prospector[33]工具為程序員編寫API客戶端代碼提供幫助.用戶描述輸入/輸出類型,自動使用API方法簽名及從大量示例客戶端代碼中挖掘到的jungloids來合成便于復用的查詢結果.
· DERECS[34]方法基于方法調用及代碼片段的結構特征對代碼進行描述增強的方法,減小了被搜索的代碼與自然語言查詢語句之間的差異,提高了搜索的準確性.
本文針對企業級的海量代碼,提出了和自然語言搜索引擎一樣,利用簡單關鍵詞進行檢索匹配代碼的方法.
6 總結與未來工作
本文提出了企業級海量代碼下的代碼檢索與管理方案以及系統實現,整個系統分為離線建庫端和在線搜索端:離線建庫使得代碼數據通過批量和實時的方式進行獲取、語法解析、索引建庫;在線搜索端接收用戶的輸入請求,對用戶的請求進行變換,然后在Elasticsearch上進行數據檢索,拿到Elasticsearch基于詞頻等特征給出搜索結果,利用多個排序策略再次進行排序,最后呈現搜索結果.系統在百度上線以后,廣受百度工程師用戶的好評.
然而正如在第 4節所描述的,未來還有大量的優化工作需要進行:首先,需要進一步挖掘代碼本身語法與語義信息,更好地匹配用戶的搜索意圖;其次,需要挖掘代碼、文件、代碼庫、開發者等之間的關系,利用知識圖譜、PageRank等算法優化搜索結果;最后,用戶的行為數據是真實地指明系統現狀以及用戶想要的結果是什么,所以接下來會挖掘用戶的行為數據,進行點擊率預估,進一步優化系統給出的結果.
同時,根據百度內部的調查,用戶在使用后,反饋的需求和改進包括:根據提交信息搜索、支持搜索注釋、能夠識別和過濾敏感信息(如誤遞交的帳號密碼等)等.接下來也會在這些功能上進行完善.經過這些措施完善后的代碼搜索工具,借助于百度研發效率云對外開放.
