基于SOM神經網絡的二階變異體約簡方法?
2019-06-11 07:40:04宋利,劉靖
軟件學報 2019年5期
宋 利,劉 靖
(內蒙古大學 計算機學院,內蒙古 呼和浩特 010021)
變異測試[1]是一種通過向源程序中人工注入缺陷來模擬軟件中實際缺陷的技術,被注入缺陷的程序稱為變異體.傳統的變異測試是指一階變異測試,即通過向源程序中人工注入一個缺陷來模擬軟件中的一個缺陷[2].但程序中的實際缺陷往往是由兩個或者更多個缺陷一起造成的[3,4],所以高階變異測試被提出來用以解決程序中復雜缺陷的問題,在模擬程序的復雜缺陷方面有著重要意義[5].
由一階變異體組合形成的高階變異體數量會大量增加,大大增加了執行開銷[6,7].因此,減少高階變異體數量和發現隱藏高階變異體(subtle higher-order mutant)已經成為當前高階變異測試的研究熱點[8].
啟發式算法被應用于高階變異測試中解決高階變異體數量[9-11]的問題,有效減少了高階變異體的數量,降低了程序的執行開銷,但卻會存在未被發現錯誤組合的缺點,這將降低測試組件質量.啟發式算法也被應用于解決發現隱藏高階變異體的問題[12,13],雖克服了未被發現錯誤組合的缺點,但卻增加了時間開銷.與此同時,聚類法被證明在變異體約簡上有很好的效果[14,15].Ma等人[14]使用聚類法在不影響變異充分度的前提下減少了變異體數量,降低了程序的執行開銷,但在運用到高階變異測試時卻因缺乏傳值而受限.針對該問題,本文著重研究二階變異測試.本文分析了影響二階變異體執行過程中中間值相似性的因素,并將該中間值相似性描述為條件下二階等價變異體,使用基于SOM神經網絡模型[16,17]的方法進行變異體聚類以達到充分考慮二階變異體組合時減少二階變異體執行開銷和發現隱藏二階變異體(subtle second-order mutant,本文定義為二階變異體中單獨的一階變異體均被測試例殺死,但兩者結合后的二階變異體不能被現有測試例殺死的二階變異體)的效果.
本文第1節介紹相關工作.第2節是本文方法中用到的基礎概念.第3節對所提方法進行具體的介紹.第4節對所提方法進行理論分析.第5節給出實驗結果及分析.第6節是本文的結論.
1 相關工作
在變異測試中,如果在同一測試例下,變異體的結果和原始程序的結果不同,則稱該變異體被殺死,否則它是存活的.被殺死的變異體個數與所有的非等價變異體個數的比值稱為變異充分度[2].傳統的變異體是指通過在原始程序中注入一個缺陷而產生的一階變異體.實際上,Purushothaman和Perry已經證明,程序中存在的許多缺陷都是復雜的,這類缺陷無法使用一階變異體進行模擬.為了解決該問題,高階變異體則通過在原始程序中注入兩個或更多個故障來模擬程序中的復雜缺陷.然而高階變異測試的成本卻很高,因此,降低高階變異測試的成本是非常重要的.
關于降低高階變異測試成本方法的研究已經有很多學者在探索,綜述文獻[8]對相關研究進行了很好的總結分析.其中,減少高階變異體數量的方法主要有3種不同類型:第1種是選擇有價值的高階變異體,如基于搜索的軟件工程的遺傳算法[5];第2種是減少變異算子的數量,例如last-to first的變異算子選擇算法和互不同的變異算子選擇算法[9,10];第3種是減少變異位置的個數,如數據流技術[11,18].關于發現隱藏高階變異體的方法[8]則更多的關注于使用基于搜索的軟件工程中的貪婪和遺傳算法的方法來解決[6,12,13].
與此同時,聚類法已經在變異測試中得到了很好的應用[14].該方法綜合考慮了動態變異體和變異體篩選的優點.研究表明,該方法在減少變異體數量方面具有很好的效果.雖然聚類法已經在變異測試領域取得了很大進展[14,15,19,20],但是該方法更注重減少一階變異體的數量并且缺乏中間結果的保存.因此,我們在二階變異測試中嘗試采用一種新的方法,即應用SOM(self-organizing map)神經網絡方法進行聚類.
SOM 神經網絡[16]是通過模擬大腦神經系統自組織特征映射功能進行的一種無監督競爭式學習前饋網絡,經過神經網絡學習提取數據中的重要特征或某種內在規律,對數據進行聚類.而SOM神經網絡的學習算法則是通過模擬生物神經元之間的興奮、協調與抑制、競爭作用的信息處理的動力學原理來指導網絡的學習與工作.所以該網絡具有很強的聚類能力,并且在各領域得到了廣泛的應用[17].
本文分析了影響二階變異體執行中間值相似性的因素.基于因素分析,提出了一種使用SOM神經網絡聚類模型進行變異體約簡及發現隱藏二階變異體的方法.具體而言,首先對不同變異點處的變異體組合成二階變異體,在此基礎上進行基于 SOM 神經網絡聚類模型的變異體約簡,根據不同變異點組合中間結果是否一樣為一類,然后從每一簇中選擇一組變異體進行繼續執行,達到對二階變異體進行聚類和發現隱藏二階變異體的效果.
2 條件下二階等價變異體
二階變異體的約簡原理,主要是根據二階變異體執行過程中的中間值相似性,即條件下二階等價變異體進行的,所以本節就條件下二階等價變異體的概念給出相關定義和示例.
2.1 概念定義
a)等價變異體:指對于任何測試數據,執行源程序和變異體后,輸出結果相同的變異體[20];
b)變異體被殺死:指對于相同的測試數據,分行執行變異體和源程序,若變異體和源程序的執行結果不同,則稱該變異體被殺死[20];
c)條件下等價變異體(conditionally overlapped mutants):指對于相同的測試用例,一組一階變異體的中間結果相同,但是有可能會被該測試用例殺死的一組變異體[14];
d)二階變異體的中間結果:本文定義為僅運行至二階變異體中兩個變異點后得到的結果,而非運行完整個程序后得到的結果,記為intermediate results of second-order mutants,簡單記為Irs;
e)條件下二階等價變異體:本文定義為對于相同的測試用例,一組二階變異體的中間結果相同,但可能會被該測試用例殺死的一組二階變異體,記為second-order conditionally overlapped mutants,簡單記為Second_CoM.
2.2 條件下二階等價變異體示例
為易于理解本文所提出的”條件下二階等價變異體”概念,以圖1(a)所示 Java片段為例進行說明.先使用關系運算符ROR和算術運算符AOR分別作用于程序中的第3行、第7行,生成各自的一個一階變異體如圖1(b)、圖1(c)所示;再同時作用于第3行和第7行生成一個二階變異體如圖1(d)所示.

Fig.1 A Java example for related concepts圖1 相關概念的Java示例
以(A=4,B=2)作為測試數據分別執行源程序和二階變異體,得到的測試數據信息見表1所列.
由表1可知,一共生成了28個二階變異體,其中最后一列分別為28個二階變異體的中間結果.根據條件下二階等價變異體Second_CoM的概念可知,運行全部程序只需6個二階變異體即可.理由如下:由變異算子組合ID為1,5,17,21的二階變異體的中間結果為-8;變異算子組合ID為2,6,18,22的二階變異體的中間結果為-6;變異算子組合ID為3,7,19,23的二階變異體的中間結果為-2;變異算子組合ID為4,8,12,16,20,24,28的二階變異體的中間結果為0;變異算子組合ID為9,13,25的二階變異體的中間結果為8;變異算子組合ID為10,11,14,15,26,27的二階變異體的中間結果為2.即該測試例下,共有6組條件下二階等價變異體,每組條件下二階等價變異體具有相同的被殺死可能性.所以只需從每一組中選擇一個二階變異體繼續運行即可,因此,運行整個程序只需6個二階變異體.
從示例可以看出,對于條件下二階等價變異體,因為條件下二階等價變異體中的二階變異體中間結果的相似性,所以繼續執行程序至最終結果時也一樣.因此只需從每一簇中選擇一個二階變異體繼續運行即可,這與執行全部的二階變異體相比會節省很多時間.所以本文提出使用SOM神經網絡對條件下二階等價變異體進行聚類,以減少執行二階變異體的時間.

Table 1 Intermediate results of second-order mutants for the example表1 示例中二階變異體的中間結果
3 基于SOM神經網絡的二階變異體約簡方法
基于SOM神經網絡的二階變異體約簡方法的總體框架如圖2所示.

Fig.2 Framework of second-order mutant reduction based on SOM neural network圖2 基于SOM神經網絡的二階變異體約簡的框架
該方法主要包括3個步驟,本節接下來將詳細闡述這3個步驟.
3.1 二階變異體的產生
如圖2所示,本文中二階變異體的生成部分主要由以下3步組成.
(1) 一階變異體生成:使用變異測試工具muJava進行一階變異體的產生.
(2) 組合策略:提出使用更為全面的缺陷組合策略對一階變異體組合形成二階變異體.即對任意兩個不同位置處的任意兩個一階變異體進行組合,以充分模擬程序中的復雜缺陷.以第 2.2節例子進行說明,第3行的7個變異體與第7行的4個變異體進行充分組合,產生28個二階變異體,能夠將這兩個變異點處的全部錯誤組合表示出來.
(3) 二階變異體生成:首先對兩個一階變異體逐行讀取,然后根據一階變異體中變異點行數和變異算子組合等信息替換掉對應的語句形成二階變異體.為了二階變異體在執行測試示例時能夠及時獲取二階變異體中間結果,本文對muJava工具的源碼進行了修改,算法1描述了以變異算子AOR為例的修改.
算法1.含中間結果輸出的變異體生成.
輸入:源程序語句,原始表達式,AOR算子作用于變異點以后的表達式.
輸出:含中間結果顯示的變異體的.java文件.

以上即為二階變異體的生成過程,接下來將分析影響條件下二階等價變異體的因素,從而確定SOM神經網絡中的特征屬性.
3.2 特征屬性的分析和確定
本文在運用SOM神經網絡對二階變異體進行聚類時,首先分析了影響條件下二階等價變異體的可能性因素,并將其作為輸入層特征屬性.主要從以下3個方面進行分析.
(1) 影響二階變異體被殺死的原因
當二階變異體的中間結果與源程序不同時,二階變異體也會被殺死,所以本文根據二階變異體的中間結果進行分析,以確定二階變異體被殺死的原因.二階變異體中按照兩個變異點的先后順序,分別記為第 1變異點和第2變異點.圖3所示為根據兩個變異點組合的變異體的執行結果進行的分類分析.

Fig.3 Analysis of the causes of second-order mutants being killed圖3 二階變異體被殺死的原因分析
具體分析如下.
當某二階變異體被殺死時,可能的原因是二階組合中的兩個一階單獨或者共同造成二階變異體被殺死的,現分為兩種情況進行分析討論.
a.假設第1變異點變異后的結果(記VM(1,Y)為)造成二階變異體被殺死,則又可分如下3種情況分析.
· 若VM(1,Y)與第 1變異點的預期結果(兩者不發生變異時,由第1個變異點運行至第2變異點時的結果,記為VM(1,po)o)相同,則該假設“VM(1,Y)造成二階變異體被殺死”不成立.又因二階變異體被殺死,所以在VM(1,Y)=VM(1,po)o條件下,造成二階變異體被殺死的原因是第2變異點變異后的結果(記為VM(X,2))造成的.即VM(1,Y)未被殺死,VM(X,2)被殺死時導致了二階變異體被殺死.
· 若VM(1,Y)與二階變異體的中間值(兩個變異點同時變異時,運行至第 2變異點時的結果,記為VM(1,2)I)相同,所以VM(1,Y)與源程序結果不同,導致VM(1,Y)=VM(1,2)I.又因VM(1,2)I的結果與源程序不同,所以VM(1,Y)造成了二階變異體被殺死.即VM(1,Y)被殺死,VM(X,2)未被殺死時導致了二階變異體被殺死.
· 若VM(1,Y)≠VM(1,po)o,VM(1,Y)≠VM(1,2)I說明VM(1,Y)與源程序的第 1變異點的預期結果不同,所以導致VM(1,Y)≠VM(1,po)o;但是VM(1,Y)≠VM(1,2)I,說明VM(X,2)在VM(1,Y)上再次改變了二階變異體的中間值,導致VM(1,Y)≠VM(1,2)I.即VM(1,Y)被殺死,VM(X,2)被殺死時導致了二階變異體被殺死.即VM(1,Y)被殺死,VM(X,2)被殺死時導致了二階變異體被殺死.
b.假設第2變異點變異后的結果(VM(X,2))時造成的,則又可分如下3種情況分析.
· 若VM(X,2)與第2變異點的預期結果(兩者不發生變異時,運行至第2變異點時的結果,記為VM(po,2)o)相同,則該假設“VM(X,2)造成二階變異體被殺死”不成立.又因為二階變異體被殺死,所以在VM(X,2)=VM(po,2)o條件下,造成二階變異體被殺死的原因是VM(1,Y)造成的.即VM(1,Y)被殺死,VM(X,2)未被殺死時導致了二階變異體被殺死.
· 若VM(X,2)=VM(1,2)I,所以VM(X,2)與源程序結果不同,導致VM(X,2)=VM(1,2)I.又因VM(1,2)I的結果與源程序不同,所以VM(X,2)造成二階變異體被殺死.即VM(1,Y)未被殺死,VM(X,2)被殺死時導致了二階變異體被殺死.
· 若VM(X,2)≠VM(po,2)o,VM(X,2)≠VM(1,2)I,說明VM(X,2)與源程序的第 2變異點的預期結果不同,故導致VM(X,2)≠VM(po,2)o;但VM(X,2)≠VM(1,2)I,說明VM(1,Y)在VM(X,2)上再次改變了二階變異體的中間值,導致VM(X,2)≠VM(1,2)I.即VM(1,Y)被殺死,VM(X,2)被殺死時導致了二階變異體被殺死.
分析了二階變異體的中間結果被殺死的原因后,可知影響二階變異體的中間結果相似性,即影響條件下二階等價變異體的因素含
(2) 分析直觀的影響因素
眾所周知:當二階變異體被殺死時,與兩個變異體在程序中的位置以及變異算子等有關.現在以經典的三角形程序中的部分代碼為例進行說明,如圖4所示.

Fig.4 Analysis of intuitive factors圖4 直觀影響因素的分析
對程序的第1行、第5行語句分別施加ROR變異算子和AOR變異算子,可以得到:如果第1變異體為真時,則第2變異體的結果對程序的最終結果無影響;當第1行語句為真時,則第3行~第16行任意變異點的結果均對最終結果無影響.所以,影響二階變異體中間結果的因素含測試用例、變異點位置、變異算子、兩個變異體的距離.
(3) 影響隱藏二階變異體的因素
根據隱藏二階變異體的定義,即二階變異體中單獨的第 1變異體和第 2變異體均被殺死,但兩者組合后的二階變異體沒有被殺死的二階變異體.因此,因素中必含兩個變異點分別變異前運行至對應變異點時的預期結果(記為VP(1,po)o和VP(po,2)o)、兩個變異點分別變化后運行至對應變異點時的結果(記為VM(1,po)I和VM(po,2)I)、兩個變異點同時發生變異后的結果(即VM(1,2)I).注意,VM(1,po)o和VP(1,po)o的區別是:VM(1,po)o表示只有第1個變異點發生變異、第2個變異點未發生變異時的預期結果;VP(1,po)o表示源程序中任意兩個變異點均未發生變異時,第1個變異點的預期結果.同理,VM(po,2)o和VP(po,2)o的區別也是如此.
綜上所述,本文使用SOM神經網絡聚類時的特征屬性為:測試用例、變異點位置、變異算子、兩個變異體的距離、.
3.3 SOM神經網絡的設計
通過第2.2節的分析,確定了影響二階變異體中間結果的因素.接下來建立適用于二階變異體的SOM神經網絡.
(2)鑄造缺陷的修復 鑄造廠家對發現的鑄造缺陷進行補焊,由于補焊時未預熱,焊后未及時進行正火,導致補焊處在中頻感應淬火時出現淬火裂紋。由于鑄造毛坯經補焊后進行粗加工,導致補焊位置不易識別,在淬火過程中由于應力作用而出現裂紋問題,因而鑄造廠家調整補焊工藝,增加焊前預熱和焊后正火,以細化晶粒。
根據第2.1節中的方法獲取到一階變異體和二階變異體的中間結果的信息,將這些信息作為輸入層初始數據.對其中的非數值信息,進行ASCII編碼轉換.本文中的SOM神經網絡是在PyCharm中實現,算法的主要步驟和實現如圖5所示.

Fig.5 Implementation of SOM neural network algorithm圖5 SOM神經網絡算法的實現
其核心學習算法每一步的具體實現如下.
(1) 初始化
令獲取到的信息為輸入數據集dataSet,從訓練集中隨機取一輸入模式并進行歸一化處理;競爭層中,各神經元對應的內星權向量為com_weightj(j=1,2,...,m),m為輸出層神經元數目,對其進行歸一化處理.歸一化的方式如公式(1)和公式(2),建立初始優勝鄰域和學習率初值設為0.9.
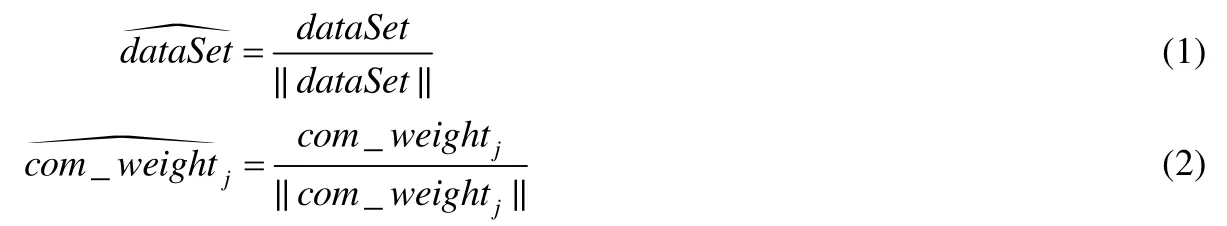
(2) 尋找獲勝神經元
根據影響二階變異體的中間結果的因素,本文中,獲勝神經元的計算方式為計算輸入樣本與權值向量的歐幾里得距離(記為dj).即計算輸入數據集dataSet歸一化后的數據與競爭層中所有神經元對應的內星權向量com_weightj(j=1,2,...,m)的歐幾里得距離,如公式(3):

距離最小的神經元贏得競爭,即距離越小的神經元相似度越大,更容易聚為一類.
(4) 調整權值

(5) 重新歸一化處理
權向量經過調整后,得到的新向量不再是單位向量,因此要對學習調整后的向量進行重新歸一化,循環運算,當eta(t,N)≤etamin時結束訓練.不滿足時重新進行步驟(1),直到學習率為0.
最后,使用聚類后的約簡過的二階變異體進行程序的完整執行,即強變異測試.
以上 3小節即為本文所提方法的 3個步驟,能充分模擬程序中的復雜缺陷,并且減少程序執行開銷的預期效果.接下來,從理論上進行分析和證明所提方法的正確性和有效性.
4 理論分析
為了更加清晰和唯一確定地理解所提出的方法,該節采用Shin等人[21]提出的變異測試的數學理論框架,對本文所提方法的核心理論進行分析和證明.該框架是以程序與程序的差異性為基礎展開的,而非程序的正確性.即該框架具有能夠說明兩個變異體是否能夠產生相同結果的功能,而非僅限于說明某個(些)變異體的結果與源程序之間是否相同.同時,所提方法也是基于二階變異體的中間結果的比較進行的,所以可以使用該框架進行理論分析和證明.本節將從兩方面進行數學分析和證明,即變異體約簡和發現隱藏二階變異體.
4.1 變異體約簡理論分析
為方便分析和證明,從基于SOM神經網絡的聚類結果中的每簇中任選一個二階變異體用以構成最小二階變異體集時,以選取每簇中的第1個二階變異體為例進行分析(實際上,從每簇二階變異體中選取的需要完全執行的二階變異體是隨機的).給定全部的二階變異體和測試用例集.假設產生的全部二階變異體一共有Mall個,聚類后有N個簇,分別編號為M1,M2,...,MN,也就是S_Coms={M1,M2,...,MN};假設簇M1中現有變異體m個,分別簡單編號為M1x1,M1x2,...,M1xm;假設N個簇中的任意簇中的二階變異體的個數為y,例如選取M1中的二階變異體的個數為y.現選取簇M1中的任意一個變異體作為原點,例如以M1x1作為原點,則簇M1中的所有變異體的中間結果之間相似性可以用數學表示為

其中,d表示測試差分(簡稱差分).測試差分表示了程序之間的差異性[21],可用公式(6)[21]表示.

在理論框架中,原點對于公式所表示的內容具有重要意義,而公式(5)中選取M1x1作為原點,則表示M1xi與M1x1的差異性.
公式(6)顯示了在相同測試用例下,如果兩個程序的運行結果不同,差分d記為1;否則記為0.類似的,采用該框架表示本文中變異體之間的差異性時,可用如下公式表示.
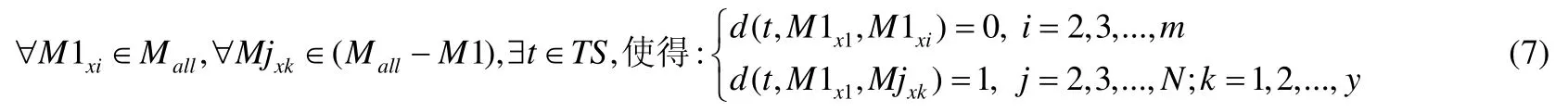
其中,Mjxk表示某一簇中的任意一個二階變異體.該公式顯示了同一簇中的二階變異體具有相同的二階變異體的中間結果(即Irs).由于同一簇中的二階變異體具有相同的Irs,因此測試差分的值為0.不同簇中的二階變異體具有不同的Irs,所以測試差分d的值為1.
結合公式(5)和公式(7),本文中的二階變異體的約簡原理可作如下推導.

其中,公式(8)中,Mall為全部二階變異體;公式(9)中,Mi是第i簇二階變異體;公式(10)中,Mix1表示第i簇中的一個二階變異體.結合本文選取和確定的特征屬性決定了每簇中的二階變異體具有相似的功能,若該集合具有某種功能,則該集合中的任意一個二階變異體均具有相似的功能.每簇中選取的二階變異體構成的新的集合具有全部二階變異體的功能.
綜上所述,理論上,采用本文方法聚類后的二階變異體個數會減少很多,且不影響原來二階變異體的測試總結果(例如錯誤組合的表示情況).
4.2 隱藏二階變異體理論分析
所提方法發現隱藏二階變異體的方法和執行步驟為:使用SOM神經網絡聚類后,找到某一測試例下的隱藏二階變異體;找出所有測試例下的隱藏二階變異體,提取出不同測試例下相同的隱藏二階變異體,即為找到的隱藏二階變異體.這些隱藏二階變異體不能被現有的測試用例殺死.其中,對于某一測試用例下隱藏二階變異體的數學模型為
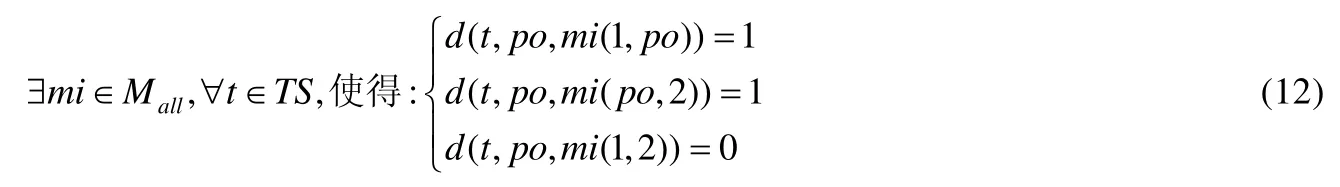
其中,po為源程序;mi(1,po)表示第1個變異點處變異體結果被殺死,第2個變異點未發生變異的變異體.由公式(6)可知,測試差分的值表示該簇中任意一個二階變異體與測試用例的運行結果情況,所以公式(12)可用于表示某測試例下的隱藏二階變異體.
但是,使用本文方法時需要找出所有測試例下的隱藏二階變異體,即需找到滿足公式(13)的二階變異體.
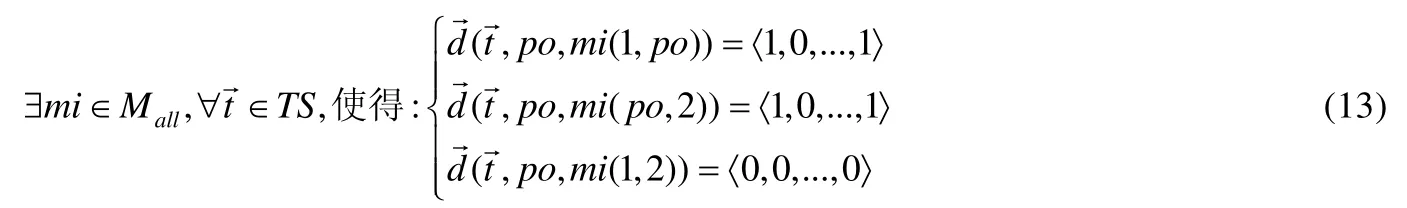
其中,此處的測試用例和差分均使用了矢量,指多個測試用例下的隱藏二階變異體[21].差分矢量結果中若有混合的1和0,則它們的順序是任意的(因為變異體可能是被任意測試用例殺死,而不局限于被第1個和最后一個測試用例殺死),此處均記為〈1,0,...,1〉;若只有 0,則沒有測試用例可以殺死該變異體.針對多個測試用例下找到隱藏二階變異體的過程可使用程序空間[21]進行分析,對程序空間改進后,發現隱藏二階變異體的過程如圖6.其中,深黑色圓圈指變異體被測試用例殺死,淺灰色圓圈指未被殺死.圖6(1)~圖6(3)表示了某二階變異體在只有一個變異點被殺死時,該二階變異體能夠被3個測試例t1~t3中任意一個測試例殺死;但是如果兩個變異點均發生變異后,該二階變異體反而不能被 3個測試用例殺死,即圖6(4)所示.此時需添加新的測試用例來殺死該隱藏二階變異體,即如圖6(5)所示;圖6(6)表示推廣到二階變異體中有多個隱藏二階變異體,然后針對不同隱藏二階變異體設計新的測試用例(如圖6(7)所示),使得該隱藏二階變異體被殺死,用以提高測試組件的質量.
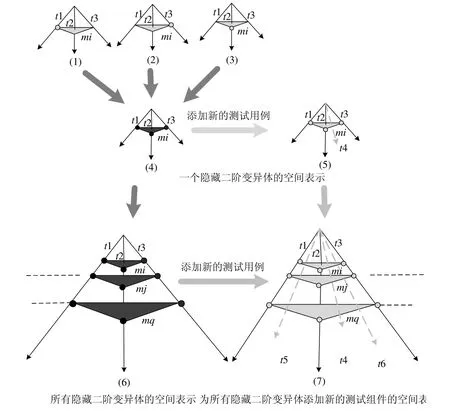
Fig.6 Mathematical model of finding subtle second-order mutants圖6 發現隱藏二階變異體的數學模型
針對多個測試用例下的多個隱藏二階變異體添加新的測試例前后的變化,使用差分矢量可表示為

通過使用數學理論框架對本文所提方法進行的分析和理論證明,使得本文所提方法的核心思想更加地容易理解.更重要的是,使用框架中的元素對本文中的方法進行了推導證明,證明了方法的正確性和有效性.接下來,將從實驗上驗證所提方法的實際效果.
5 實驗及結果分析
5.1 實驗準備
(1) 程序和實驗環境
本文首先選取兩個經典的基準程序,即三角形(Triangle)[7,11,14]和找中間數(Mid)[7,11,14]來進行驗證,然后使用規模較大的實用性開源項目 Snake和小組團隊開發程序 Shopping來驗證方法的可應用性和有效性.實驗運行環境為Eclipse集成開發環境,實驗中的一階變異體由修改后的muJava工具產生,聚類后變異體由SOM神經網絡聚類后產生,基準程序中的測試用例來源于文獻[11],實用性項目因為現有文獻中沒有相同的項目資料,所以使用自己團隊編寫的測試用例用來驗證.因每次對同一數據聚類的結果有細微偏差,所以本文選擇其平均值.
(2) 變異算子
本文選取研究中經常使用的變異算子[7,11,14]來進行實驗.在符合優秀程序員準則后的程序中,算術運算符、關系運算符和條件運算符等出錯的概率比較高,所以這 7個變異算子覆蓋了多數程序語言中缺陷常出現的情況,所以這些變異算子具有一定的代表性.其信息見表2.

Table 2 List of mutation operators表2 變異算子列表
其中,
· AOIS表示算術運算符插入,包含有兩個操作符,分別為“++,--”.變異點的變異例如“a?a--”;
· AOIU表示一元算術運算符插入,包含一個操作符,即“-”.變異點的變異例如“a?-a”;
· LOI表示邏輯運算符插入,包含一個操作符,即“~”.變異點的變異如“if (b==a)?if (b==~a)”;
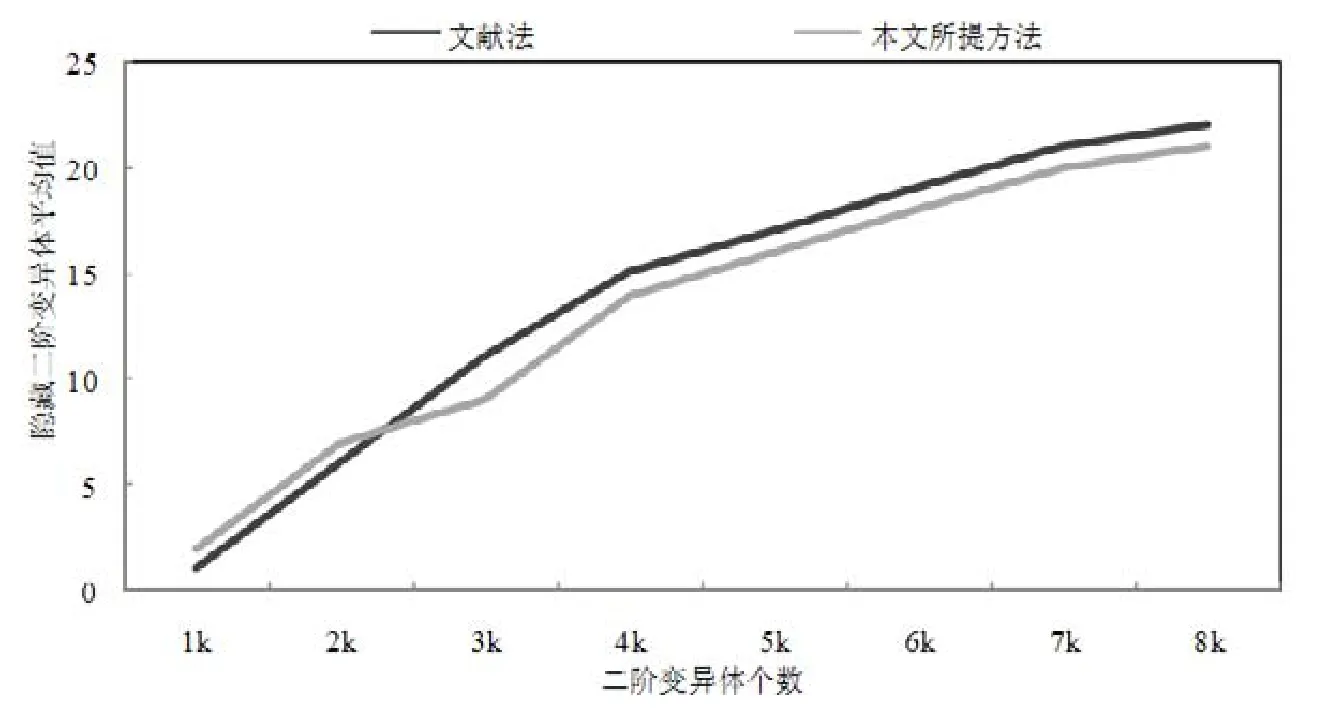
· ROR 表示關系運算符替換,包含 6 個操作符,分別為“<,≤,>,≥,==,≠”.變異點的變異例如“a>b?a · COI表示條件運算符插入,包含一個操作符,即“!”.變異點的變異例如“a≤0?!(a≤0)”; · COR 表示條件運算符替換,包含兩個操作符,分別為“&&,||”.變異點的變異例如“(a&&b)?(a||b)”; · AOR表示算術運算符替換,包含5個操作符,分別為“*,/,%,+,-”.變異點的變異例如“(a+b)?(a-b). 本文的實驗將從以下幾個方面開展:所提方法能否減少二階變異體個數;所提方法對變異充分度是否影響;所提方法能否降低變異測試時間開銷;所提方法能否發現隱藏二階變異體.針對以上幾個方面進行如下實驗. (1) 二階變異體個數的實驗 為了驗證本文方法能夠減少運行的二階變異體個數.首先用本文方法生成一階和二階變異體,通過對一階和二階變異體個數的比較,以顯示二階變異體個數的龐大,并和文獻[11]方法(記為已有方法)比較.選擇該文獻的原因如下. · 首先,該文獻中解決的問題和本文所要解決的問題是一致的,即考慮文章中出現的錯誤組合,然后對二階變異體個數進行約簡;而其他文獻中關于高階變異體的約簡則是通過對一階變異體折半組合以達到減少變異體數量的目的,與本文研究的問題有稍許偏差. · 其次,該文獻作者所在研究組一直跟蹤研究高階變異測試,且該篇文章是該研究組近期發表的一篇非綜述類研究高階變異體約簡的文章,該文獻的工作具有較好的代表性,所以選其作為對比對象. 實驗對比的具體信息見表3. Table 3 Number of first-order and second-order mutants generated for benchmark programs表3 基準程序生成的一階和二階變異體個數 其中,已有方法生成二階變異體的方法使用的是 Last To First Different Operators策略,該策略忽略了某一個錯誤組合后再同其他錯誤組合的情況,造成程序中某些錯誤組合被遺漏;本文充分考慮程序中可能出現的錯誤組合,采用較為全面的組合策略對一階變異體進行組合生成二階變異體;接著進行聚類前后二階變異體個數比較的實驗,使用二階變異體減少率的形式展示,具體見表4和表5. Table 4 Number of second-order mutants after filtering for Mid表4 Mid篩選后的二階變異體數量 Table 5 Number of second-order mutants after filtering for Triangle表5 Triangle篩選后的二階變異體數量 如表3所示,為兩個程序在本文方法和文獻[11]方法下生成的二階變異體(未篩選)個數.由最后一列可知,與已有方法比,本文方法生成了更多的二階變異體.如就 Triangle程序而言,已有方法產生的總的二階變異體的個數為47 557,而本文方法則生成了62 369個二階變異體,這將有利于充分表示程序中的復雜缺陷.由表4和表5可知,一方面,二階變異體聚類后個數極少,與聚類前相比減少了很多;另一方面,與已有方法相比,本文方法執行了更少的二階變異體,如以Triangle為例,已有方法減少了99.86%,而本文方法的減少率至少為99.92%.這表明,基于SOM神經網絡的二階變異體聚類能夠有效減少二階變異體個數. 為了驗證結論是否有效,本文對表4和表5中本文方法和已有方法篩選后的減少率做了差異顯著性分析(使用的是無重復雙因素分析,其中a=0.05),結果見表6. Table 6 Result of the significance difference analysis of reduction rate of second-order mutants for benchmark programs表6 基準程序中二階變異體減少率的顯著性差異分析的結果 表6從統計學上的顯著性差異進行分析,從表格中可以看出,基準程序 Mid和 Triangle的P-value均小于0.01,說明兩組數據具備顯著性差異的可能性大于 99%,表明本文方法與已有方法的減少率差異極為顯著,具有統計學意義上的差異顯著性.說明基于SOM神經網絡的二階變異體聚類能夠有效減少二階變異體個數. (2) 變異充分度的實驗 為驗證本文方法對變異充分度的影響,首先進行一階和二階變異充分度比較的實驗,來反映聚類后二階變異體對變異充分度的影響;然后和文獻[11]方法進行變異充分度比較,來反映本文方法的優劣性.實驗時使用的一階變異體和二階變異體個數的具體信息見表7,變異測試中變異體被殺死的具體信息見表8和表9,變異充分度的比較信息見表10,其中,二階變異測試充分度計算方法為:假設100個非等價二階變異體,聚類后有20個簇.若10個簇的代表性二階變異體被殺死,而10個簇中共含有60個二階變異體,則變異充分度為60%. Table 7 Number of mutants under test cases for benchmark programs表7 基準程序的測試例執行的變異體個數 Table 8 Information on the number of first-order mutants killed by executing test cases for benchmark programs表8 基準程序執行測試用例時被殺死的一階變異體個數的信息 Table 9 Information on the number of second-order mutants killed by executing test cases for benchmark programs表9 基準程序執行測試用例時被殺死的二階變異體個數的信息 Table 10 Mutation score of first-order and second-order mutation testing for benchmark programs表10 基準程序的一階和二階變異測試的變異充分度 表8和表9展示了變異測試中變異體被殺死的具體信息,根據這兩個表可得到表10的變異充分度比較信息.其中,本文方法的某個二階變異體被殺死指該二階變異體所在簇中的二階變異體被殺死.以表9中三角形基準程序為例,本文所提方法中被殺死的二階變異體為12個,則指的是有12個簇的二階變異體被殺死. 由表10可知, · 一方面,本文所提方法的二階變異充分度和一階變異充分度很接近.以三角形為例,本文方法中二階變異體的變異充分度為92.5%,較已有文獻中的91.7%,更加的接近一階變異充分度.根據文獻[7,11]所述,當二階變異充分度和一階變異充分度越接近時,表明二階變異體選取的越好,即本文選取聚類后的二階變異體具有很好的效果. · 另一方面,也表明了本文所提方法取得的二階變異充分度較文獻[11]更接近一階變異充分度,表明本文所提方法與已有方法相比,能夠運行更有效的少量二階變異體,取得更好的二階變異充分度. 為了驗證該方法的可應用性和有效性,本文使用一個規模較大的開源項目和小組團隊開發程序.程序的信息見表11. Table 11 Information list for practical projects表11 實用項目的信息列表 其中,Snake是一個開源的貪吃蛇游戲,通過鍵盤上的方向鍵控制蛇前進的方向,游戲實時記錄自己當前的長度及可以計時;Shopping是一個自己小組使用SSH框架開發的電子商城,主要功能有訂單管理、用戶管理、商品管理. 使用本文提出的組合策略將Snake項目和Shopping項目的一階變異體組合生成二階變異體,其中的具體信息見表12. Table 12 Information of mutants generation for practical projects表12 實用項目的變異體生成的具體信息 由表12中可知,雖然項目代碼行較多,但是由于其中多數為不易出錯的代碼,如Snake中GUI代碼,該類代碼相似的重復性操作較多(由熟練程序員假設可知,此部分屬于不易出錯范疇),含操作符代碼不多,所以一階變異體并不多,如Snake一階變異體數為146個. 因為項目的主要功能分布在某些類中,我們重點對核心類進行分析,實驗中,非核心類多數不產生變異體;為驗證其可應用性,使用自己團隊編寫的測試用例進行實驗,其中,測試用例并不能保證殺死全部的變異體,選擇在全部測試用例下進行分析,而沒有再分析單個測試例的變異測試充分度.將聚類前的一階變異測試充分度和聚類后的二階變異測試充分度做對比,用以驗證本文方法的可應用性.具體信息見表13. Table 13 Mutation score for practical projects表13 實用項目的變異充分度 由表13可知,兩個項目在使用本文方法約簡后,二階變異體測試充分度較一階變異測試充分度較為接近,如Snake的一階變異測試充分度為13.68%,其篩選后二階變異體測試充分度為13.73%.由文獻[7,11]可知,當二階變異充分度和一階變異充分度接近時,表明二階變異體約簡的效果越好.為驗證該結果是否具有統計學上的差異顯著性,對實驗中的一階變異測試充分度和篩選后二階變異測試充分度的數據做差異顯著性分析,分析結果見表14. Table 14 Result of the significant difference analysis of mutation score before and after filtering for practical projects表14 篩選前后的實用項目的變異充分度的顯著性差異分析的結果 從表14中可以看出,顯著性差異分析結果的P-value為0.894 863,大于0.05,說明兩組數據具備顯著性差異的可能性小于95%,表明本文方法的篩選后二階變異充分度較一階變異測試充分度較為接近. (3) 時間開銷和發現隱藏二階變異體的實驗 因為發現隱藏二階變異體的實驗需知道全部二階變異體執行過測試例的信息,所以可從聚類后根據符合該特征的簇中獲取隱藏二階變異體.基于該特征,可將發現隱藏二階變異體和變異體約簡的時間開銷同時分析. 為了驗證本文方法能夠降低時間開銷,同時便于發現隱藏二階變異體實驗的比較,所以實驗中的程序使用基準程序 Coordinate[7],測試例為非充分測試例(即測試組件不能殺死全部二階變異體),并將本文方法使用的時間和文獻[7]中的時間進行比較. a) 時間開銷的實驗 本文通過和文獻[7]的方法(記為文獻法)比較平均時間來反映時間消耗.實驗需執行全部的測試組件,而不是執行單獨的測試用例進行測試.Coordinate程序的平均時間信息見表15. Table 15 Average time cost of executing mutants for programs表15 程序執行變異體的平均時間消耗 由表15可知,一方面,雖然聚類花費時間較長,但是聚類后的二階變異體運行測試例的時間卻很短;另一方面,本文中所提方法在發現隱藏二階變異體功能上,比該文獻方法中的時間開銷減少了一些,如文獻法使用了39 685.000s,而本文方法則使用了38 847.892s.說明本文方法能夠減少程序執行開銷且用時較少. b) 發現隱藏二階變異體的實驗 為了驗證本文方法能夠發現隱藏二階變異體,實驗中每次使用不同個數的算子運用到程序中,生成不同個數的二階變異體.如圖7所示,為該文獻方法和本文方法獲取到的隱藏二階變異體的平均數.其中,本文隱藏二階變異體的獲取方法為:根據聚類后的二階變異體,提取出第一變異體被殺死、第二變異體被殺死,但是二者共同作用時未被殺死的二階變異體,進行比較,得到隱藏二階變異體. Fig.7 Average of finding subtle second-order mutants圖7 發現隱藏二階變異體平均值 由圖7可知: · 本文方法尋找的到隱藏二階變異體個數的平均數,在總數不是很大時優于該文獻. · 當數據量增大時,與該文獻方法幾乎一樣稍微偏低.原因為數量較大時,根據聚類后的二階變異體,提取出第一變異體被殺死、第二變異體被殺死,但是二者共同作用時未被殺死的二階變異體數有少許誤差. 綜合來說,表明本文方法能夠發現隱藏二階變異體,且數量相差不多. 二階變異測試中的二階變異體能夠模擬程序中的復雜缺陷,具有重要意義.但由一階變異體組合形成的二階變異體數量龐大,因此減少執行的二階變異體個數、降低程序的執行開銷是至關重要的.本文提出了一種基于SOM神經網絡的二階變異體約簡方法. · 首先,采用較為全面的二階變異體錯誤組合策略對一階變異體組合形成二階變異體; · 然后,根據二階變異體執行過程中的中間值相似性,進行基于SOM神經網絡模型的變異體聚類; · 最后,以基準程序和開源項目進行驗證.結果表明,組合策略充分模擬了軟件中的復雜錯誤,通過對二階變異體執行過程中的中間值進行基于 SOM神經網絡的聚類,保證了在二階變異測試充分度較為接近一階變異充分度的情況下減少了二階變異測試的執行開銷;與此同時,在較短的時間里能夠發現隱藏二階變異體. 另外,二階變異測試是高階變異測試的基礎,所以該方法可以推廣到高階變異測試中的其他階的測試.當推廣到不同的階數時,需要另外增加特征屬性以達到更好的聚類效果.如果不增加特征屬性,也會有一定的聚類效果,但是效果不如現有的方法好,所以需要額外增加特征屬性.5.2 實驗結果及分析













6 結 論
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
Coco薇(2016年2期)2016-03-22 02:42:52
中國衛生(2015年3期)2015-11-19 02:53:32
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
