Spark Streaming中參數與資源協同調整策略
2019-06-07 15:08:13梁毅劉飛常仕祿
軟件導刊 2019年1期
梁毅 劉飛 常仕祿

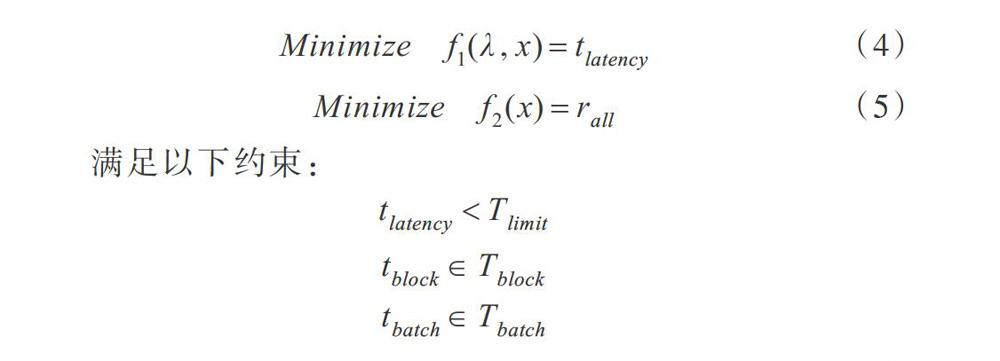
摘 要:Spark Streaming是一種典型的批量流式計算平臺,可用于處理持續到達的數據流。流式數據最重要的兩個特征是波動性和時效性。利用動態調整系統參數和動態調整資源滿足不同數據到達速率的響應延遲,但調整參數的方式具有局限性,其用戶成本較大。因此提出一種參數和資源協同調整策略,采用動態鄰域粒子群算法找到一種滿足SLO目標且使用資源最少的系統方案。實驗表明,AdaStreaming與DyBBS相比,延遲性降低了70.1%,在資源使用量上比DRA降低了42.1%。
關鍵詞:Spark Streaming; 動態鄰域粒子群;參數配置;資源分配
DOI:10. 11907/rjdk. 181652
中圖分類號:TP301文獻標識碼:A文章編號:1672-7800(2019)001-0045-03
Abstract:Spark Streaming is a typical batched streaming processing system that can be used to process continuously arriving data streams. The two most important characteristics of streaming data are its volatility and timeliness. The method of dynamical parameter configuration and dynamical resource allocation are proposed to guarantee the end to end latency with different data arrival rates. However, the method of dynamical parameter configuration has limitation on scope of application, and the method of dynamical resource allocation will bring greater cost to users. Therefore, this paper proposes a parameter and resource coordination adjustment strategy, using dynamic neighborhood particle swarm algorithm to find a solution that can achieve resource minimization on the premise of meeting the SLO goal. Experiments show that AdaStreaming reduced latency by 59% against DyBBS, and reduced the amount of resources by 34% against DRA.
0 引言
隨著大數據應用場景的多樣化,各種行業產生了海量流式數據[1-3]。流式數據最重要的兩個特征是波動性和時效性,不同時刻流式數據到達的速率是波動的,且需在一定時間內完成處理[4]。Spark Streaming[5]是一種典型的批量流式計算平臺,被工業界和學術界廣泛采用。
隨著云計算的發展,許多流式計算平臺被部署到云上,為用戶提供靈活的服務[6]。對于這類部署在云上的Spark Streaming平臺,滿足用戶SLO和最小化資源使用以降低用戶成本成為最重要的兩個目標[7-8]。現有研究主要從3方面進行優化:①數據丟棄[9-11]。但該方法不適用具有“至少執行一次”語義保證的應用;②動態調整參數配置[12-13]。然而,當數據速率激增時,當前資源分配情況下可能出現調整參數無法使延遲滿足需求的情況;③動態調整資源。當數據處理落后于數據流入時,會增加分配的資源數量以提升數據處理速率[14]。考慮到云環境按需付費的服務模式,該方法會給用戶帶來巨大的成本開銷。
本文通過分析影響Spark Streaming平臺性能的一些因素,提出一種參數和資源協同調整策略AdaStreaming。該策略采用一種動態鄰域粒子群算法,在滿足SLO的前提下,選擇一種資源使用量最少的參數和資源調整方案,并以此為依據進行系統調整。實驗表明,與動態調整參數的DyBBS方法相比,本文提出的AdaStreaming在延遲上降低了59%,與動態調整資源的DRA方法相比,AdaStreaming在資源使用量上降低了34%。
1 Spark Streaming
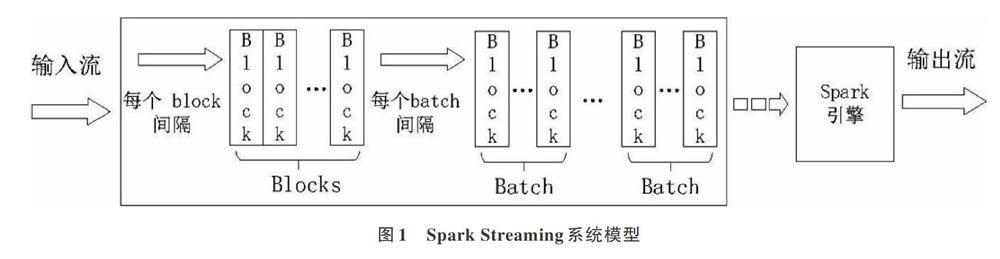
Spark Streaming構建于Spark[15]之上,其處理流程如圖1所示。流入系統的數據以一定的劃分間隔分割成分開的數據塊,然后以一定批次的劃分間隔劃分為獨立的批次任務,并按順序提交到Spark引擎中執行。根據上述處理過程,可以看出數據塊劃分間隔和批次劃分間隔是影響系統性能的兩個重要參數。
2 SparkStreaming中參數與資源協同調整策略
2.1 動態鄰域粒子群算法
粒子群優化算法(Particle Swarm Optimization,PSO)是一種基于迭代的優化算法,易于實現且無較多參數需要調整[16-18]。動態鄰域粒子群(DNPSO)算法可在不同階段考慮不同目標,用于多目標約束優化問題的求解[19-20]。對于兩個目標的問題,第一個目標[f1]可確定粒子鄰域,第二個目標[f2]作為度量粒子質量的適應度函數。因此鄰域函數[f1]找到粒子i的鄰域[Ni]后,粒子i在t+1時刻的個體最優位置可由式(1)計算。
