面向圖計算系統的異步計算-加載模型
2019-06-06 05:46:36周曉麗
小型微型計算機系統 2019年6期
周曉麗,陳 榕
(上海交通大學 軟件學院 并行與分布式系統研究所,上海 200240)
1 引 言
目前,針對大規模數據的圖計算系統被漸漸關注起來,許多現實問題都可以被抽象成圖模型,并用圖計算系統得到解決,例如社交網絡、商品推薦等.分布式框架常被用于圖計算系統中,例如PowerGraph[1],PowerLyra[2],Giraph[3]文獻[4]都是近些年提出的分布式圖計算系統.通過集群強大的計算資源,它們可以處理規模龐大的圖數據,但機器數量的增多也會為管理、協調帶來難度,例如會有負載不平衡和通信代價的問題.
基于外存的核外(Out-of-core)技術為大規模圖數據計算提供了另一種解決方案,通過高效訪問外存(如,硬盤)和內存,該類系統使得在單個服務器上執行大規模圖數據的計算成為可能,例如有GraphChi[5],X-Stream[6],GridGraph[7]等.GraphChi將邊劃分成不同區間并存儲在外存中,它使用“并行滑動窗口”的方法載入這些邊進入內存,通過順序訪問來保證合理的I/O性能.X-Stream采用了“邊中心”式的計算模型,通過邊在頂點間傳遞數據,它的性能提升主要在于只允許隨機訪問發生在內存內,而保證對速度較慢的外存訪問是順序的.GridGraph首先提出了二維劃分邊的方法“網格劃分法”,它將邊按照起始和結束頂點劃分到不同的網格區間中,劃分目的是讓數據布局更有利于CPU訪問.為了減少I/O數量,它在邏輯上將多個網格中的邊合并成一個大的I/O數據塊,一同載入內存執行.GridGraph的性能要優于GraphChi和X-Stream,這主要是因為它能有效減少I/O數量并且較合理的利用I/O帶寬.
目前的out-of-core圖計算系統大都側重于優化I/O性能,例如確保順序訪問,減少I/O數量,充分利用帶寬等,卻沒有意識到隨著硬盤帶寬的不斷提升,計算時間逐漸凸顯,尤其對于一些計算密集型的圖算法,它們需要更多的計算時間,這些計算時間可能成為系統性能的瓶頸.GridGraph是三個代表性系統中性能最優的,但同樣存在上述問題.由于使用了同步計算-加載模型,計算過程和I/O加載過程缺乏并行性,工作線程既要負責I/O任務也要負責計算任務,且計算任務阻塞于I/O任務,這主要因為它使用的同步I/O引擎使得線程在發送I/O請求后,不得不等待I/O操作的完成,浪費了大量的計算資源.
1http://law.di.unimi.it/webdata/clueweb12/
2http://lse.sourceforge.net/io/aio.html
3http://wufei.org/2016/09/16/linux-io-data-flow/
本文通過實驗數據說明,當硬盤帶寬逐漸增加時,I/O讀寫的時間會進一步減少,計算時間會越來越突出甚至成為瓶頸.如圖1所示,在GridGraph上運行圖算法PageRank[8],輸入數據為ClueWeb1,當SSD數量從1增加到6時,I/O的帶寬能力也呈線性增長,但計算時間與I/O時間的比例也隨之增加,當SSD數量為6時,計算時間幾乎和I/O時間齊平,可以預見當SSD數量繼續增加時,計算時間就會成為整個系統性能的瓶頸.
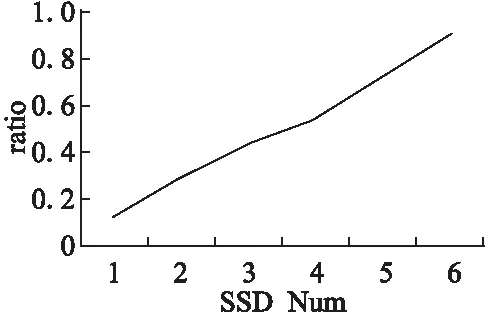
圖1 計算時間與I/O時間比Fig.1 Ratio of computation time to I/O time
此外,同步計算-加載模型沒有區分計算線程和I/O線程,線程數量往往由服務器的核數決定,這樣的線程創建數量的確有利于計算任務的并發性,卻不利于I/O訪問.一方面,操作系統對外存的訪問方式缺乏并行性;另一方面,I/O有限的帶寬并不需要服務器核數數量的線程就能填滿.這些原因決定了下層I/O無法很好的支持用戶程序大量的并發請求,因此在使用同步計算-加載模型的這類系統中,例如GridGraph,它們往往由于不合理的I/O線程數量而無法充分利用硬盤帶寬.
針對上述問題,本文提出了異步計算-加載模型,該模型使得圖計算系統中計算過程和I/O過程能夠并行起來,較長的I/O時間可以很好地“隱藏”計算時間,據此,本文也稱這種模型為IOC(I/O Overlapping Computation).該模型將線程按照所執行任務的類型區分為計算線程和I/O線程,并根據不同的訪問需求創建不同的線程數量.對于計算線程而言,線程數量應該由服務器的計算能力決定,它們擁有獨立的子任務數據,互不干擾,IOC創建與服務器核數一致的線程數量來盡可能提高計算的并發性;對于I/O線程而言,線程數量應該由下層I/O的處理能力決定,IOC的策略是創建能夠填滿硬盤帶寬的最小線程數量,避免造成額外開銷.為了進一步提高I/O性能,IOC拋棄了其他系統使用的PSYNC I/O引擎,這類引擎接口簡單,但這主要是由于下層操作系統向上屏蔽了很多實現細節,不利于上層用戶程序的優化.IOC使用了異步的I/O引擎LIBAIO2,I/O線程使用該類型的接口向操作系統發出I/O請求后,無需等待I/O操作完成就立即返回,繼續處理下個請求,通過這種方式,單個線程單位時間內可以處理更多的I/O請求.此外,LIBAIO的batch機制在保證硬盤帶寬被填滿的前提下,還能接收粒度更細的I/O請求數據,這同樣有助于線程間的負載平衡.
本文的主要貢獻在于:1)提出了異步計算-加載模型IOC,使得I/O時間能夠“隱藏”計算時間,避免了硬盤帶寬不斷提升后,計算時間逐漸凸顯成為瓶頸的問題.2)IOC區分計算線程和I/O線程,并能夠結合硬件資源的限制,合理分配計算線程和I/O線程數量,以滿足不同執行任務的訪問需求.3)IOC使用的異步I/O引擎LIBAIO,在保證充分利用硬盤帶寬的前提下,允許上層用戶提交粒度更細的I/O數據塊,優化了負載的平衡性.4)本文在最后通過實驗結果表明IOC模型無論是在運行時間,I/O帶寬,還是負載平衡方面都能明顯優于同步計算-加載模型.
2 背景介紹
2.1 同步計算-加載模型
比較常用的一類計算模型是同步計算-加載模型.該模型沒有區分計算線程和I/O加載線程.在將任務劃分之后,每個線程都有一份獨自的子任務,每個線程首先從外存中載入子任務所需數據,在I/O加載過程中,各個線程一直處于等待狀態,直到該數據被加載進內存,線程才能重新被CPU調度并執行計算過程.在線程等待I/O的過程中,CPU一直處于閑置狀態,浪費計算資源.
該模型的問題還不僅僅在于浪費計算資源,不區分計算線程和I/O線程還會影響I/O性能.在使用該模型的系統中,線程數量通常由服務器的核數決定,一般會創建20-40個線程,這些線程并行的向操作系統發出I/O請求,而目前Linux系統對外存的訪問方式還缺乏并行性[9],例如Linux內核順序的對I/O任務排序以及輪詢地向底層發送I/O任務.也就是說,下層的操作系統無法滿足上層用戶程序大量的并行I/O請求.
更糟糕的是過多的線程同時訪問I/O會降低I/O帶寬.在收到用戶的I/O請求后,Linux內核會執行4個操作3:plug,unplug,dispatch,completion.為了優化I/O性能,內核會在unplug階段對當前所有I/O請求排序,從而盡可能順序的訪問硬盤.內核的這種機制在保證底層硬盤訪問性能時,卻可能造成對不同線程的I/O請求的響應時間不均衡,這種不均衡在順序讀文件時最為明顯,圖4 (a)說明了這一點.
目前大部分out-of-core圖計算系統都使用同步的計算-加載模型,一方面計算線程阻塞于I/O,大大浪費計算資源;另一方面,這類模型簡單的將計算線程用于I/O訪問,不僅加重I/O負載、造成額外開銷,而且有背于內核的優化原則,影響I/O性能.
2.2 PSYNC和LIBAIO
PSYNC和LIBAIO是Linux系統向上提供的兩種I/O引擎接口.PSYNC為同步I/O類型,主要包括pread/pwrite調用,pread根據指定的文件描述符、文件偏移量讀取指定長度的數據到內存,pwrite根據文件描述符、偏移量寫入指定長度的數據到外存.LIBAIO是Linux的原生異步I/O,用戶程序可以通過io_submit系統調用以batch的方式向Linux內核發送I/O請求,通過io_getevents調用來獲取一組完成的I/O數據.
2.2.1 阻塞與非阻塞
PSYNC為阻塞式的I/O.用戶程序在發起阻塞I/O調用后,會一直處于等待狀態,直到內核將完成的I/O數據拷貝到用戶程序空間后,才從相關系統調用中返回,用戶進程阻塞于整個pread過程.而LIBAIO卻是一種非阻塞型的I/O機制.用戶進程發起io_submit系統調用后,無需等待I/O完成就可返回,內核負責向底層設備傳遞I/O請求并將返回的I/O數據先載入到內核緩沖區中,整個過程期間用戶進程可以執行其他操作.當用戶進程需要I/O數據時,主動發起io_getevents進行數據“收割”,內核負責將數據拷貝至用戶進程的內存空間.

圖2 非batch和batch的比較 Fig.2 Comparison of non-batch and batch
不難發現,阻塞型I/O會造成用戶進程大量的等待時間,但目前的很多圖計算系統都采取這種方式.它們通常開辟服務器核數的線程,并行發起pread/pwrite調用,這些線程阻塞于整個I/O調用過程,無法進行計算,導致大量計算資源的浪費.
2.2.2 非batch和batch
LIBAIO可以batch提交I/O請求,通過參數BLOCKSIZE、IODEPTH可以分別指定單個IO請求塊的大小和批量處理的塊數量.相比PSYNC,LIBAIO的batch機制可以用來支持更細粒度的I/O請求.上文提到了Linux系統處理I/O請求的四個階段plug,unplug,dispatch,completion,在plug階段,內核會將每個I/O task對應的I/O請求塊合并到plug-list中,當plug-list中的數量達到一定閾值之后才會進入unplug階段,之后才會向底層硬盤發出傳輸請求.為了最大效率的利用硬盤帶寬,上層用戶程序需要盡可能快的提交一定數量的I/O請求數據來填滿plug-list,如圖2所示,沒有batch機制的PSYNC只能增大每次請求數據的BLOCKSIZE,而支持batch機制的LIBAIO可以通過增大batch的數量IODEPTH,從而支持更細粒度的BLOCKSIZE.
在同步計算-加載模型中,每個線程的計算數據的粒度和I/O請求數據的粒度相同,如果該模型使用PSYNC,I/O請求數據的粗粒度也直接決定了計算數據的粗粒度,在動態分配任務的計算模型中,將會導致各個線程工作負載的不平衡,從而影響整體系統的性能.
3 異步計算-加載模型IOC
異步計算-加載模型IOC區分了計算線程和I/O線程,計算線程無需管理I/O的讀寫,僅僅負責數據的計算,只要有待處理的數據就會不斷地被CPU調度執行.I/O的讀寫操作由專門的I/O線程管理,這些線程無需關心上層計算,只負責發送I/O請求和“收割”I/O數據,只要有足夠的內存空間就會不斷地將數據從硬盤中載入進來.計算線程和I/O線程并行執行各自的任務,這樣一來較長的I/O時間便可以“隱藏”計算時間,從用戶程序的角度,整個系統的運行時間就只有I/O時間.
3.1 挑戰
但實現IOC模型并不容易,關鍵難點就在于如何在內存容量限制的前提下,協同I/O線程和計算線程:I/O線程將從硬盤中載入的I/O數據塊緩存在內存緩沖區中,計算線程從緩沖區中獲取待處理的數據塊,那么如何在內存緩沖區剩余空間不足時,同步I/O線程放慢(或停止)I/O操作,當沒有新載入的I/O數據塊時又如何通知計算線程.這看起來像一個生產者-消費者問題,但卻復雜的多.
傳統的生產者-消費者算法存在兩個明顯弊端:
1)生產者和消費者都是按序連續的使用內存緩沖區,不夠靈活.
2)生產和消費過程都涉及到數據的拷貝,并且拷貝時相應線程獨占整個緩沖區資源,其他線程只能等待,缺乏并行性.在IOC中,計算線程相當于消費者,I/O線程相當于生產者,但如果直接使用上述算法,還是會有不少問題:
1)按序連續使用內存的方式不夠靈活,只能支持同步I/O引擎PSYNC,而支持不了異步I/O引擎LIBAIO,這主要因為當I/O線程主動調用io_getevents請求“收割”I/O數據時,操作系統將I/O數據從內核緩沖區拷貝至用戶的內存緩沖區中,但并不能保證按照用戶內存的地址順序來進行拷貝,也就無法保證內存緩沖區被連續使用.
2)如果每次計算線程和I/O線程“生產”和“消費”時都需要進行數據拷貝,首先會增加內存負擔,其次拷貝過程需要消耗一部分計算資源,這些都將影響IOC的性能.所以,實現IOC并不能簡單的套用傳統的“生產者-消費者”模型,具有一定挑戰性.
3.2 關鍵設計
為了解決上面的問題,圖計算系統需要更加靈活的異步計算-加載模型IOC,靈活體現在允許離散的使用內存緩沖區空間以支持LIBAIO引擎;此外,還需減少計算、加載過程中數據的拷貝.為了解決這些問題,本文提出了基于地址管理的IOC模型.
首先將內存緩沖區按照I/O數據塊的大小進行劃分,假設內存緩沖區的總空間為BUFSIZ,I/O數據塊的大小為BLKSIZ,那么就將緩沖區劃分成BUFSIZ/BLKSIZ塊,第i塊的地址為i*BLKSIZ.IOC將這些塊區分為數據塊和空閑塊,并使用隊列來記錄它們的地址,隊列中相鄰的塊地址可能指向離散的物理內存空間.
如圖3所示,隊列computing記錄著等待計算線程處理的數據塊地址,I/O loading隊列記錄著等待I/O線程載入數據的空閑塊地址.兩組線程分別查找各自隊列以獲取所要的塊地址,避免了競爭,同時也通過彼此隊列實現同步.圖3描述了具體的同步過程:
1)計算線程訪問computing queue,請求獲取可計算的數據塊地址,如果隊列為空,則進入等待狀態,否則成功返回;
2)計算線程通過地址訪問到該數據塊并執行計算,計算結束后就釋放該數據塊以用于載入新的I/O數據,將該數據塊的地址插入到I/O loading queue中,該數據塊變為空閑塊.
4http://law.di.unimi.it/webdata/uk-union-2006-06-2007-05/
3)I/O線程訪問I/O loading隊列,請求獲取一個可用空閑塊的地址用來載入I/O數據,如果該隊列為空則等待,否則執行I/O操作.
4)I/O操作完成后,該地址指向的空閑塊中填充了I/O數據,下一步就是交給計算線程計算,I/O線程將該空閑塊的地址插入到computing queue中,空閑塊又變為數據塊.從靜態角度看,在某個時刻,緩沖區內的某個內存塊為數據塊或空閑塊,它們對應的地址只可能出現在兩個隊列中的其中一個.從動態角度看,這些內存塊的地址在兩個隊列之間不停流轉,構成了整個IOC的同步過程.

圖3 異步計算-加載模型IOCFig.3 Model of asynchronous computation-I/O (IOC)
計算和I/O線程并行執行各自任務,并通過隊列同步、協作,共同完成圖計算系統的任務,算法1也表示了這一過程.最開始,computing隊列為空表示當前無可計算的數據塊,所有內存塊都是空閑狀態,它們的地址都被插入到 loading隊列中.隊列通過鎖機制保證了多線程訪問時數據的正確性,front_pop()為同步操作,只有當隊列不為空時,當前線程才能成功獲取地址,否則進入等待狀態.計算線程可以通過返回地址p_data_blk訪問到數據塊data_blk,并進入處理數據階段.傳統的“生產者-消費者”算法先將數據塊內容拷貝至計算線程自己的內存空間中,釋放鎖之后再計算,但拷貝操作無疑會增加內存和計算資源的負擔.考慮到大部分圖算法的計算過程都比較簡單、時間較短,IOC中計算線程會直接對內存緩沖區中的數據data_blk進行計算,而不是預先拷貝副本,直到處理完data_blk中的數據后,才會通過間接操作地址的方法釋放該數據塊.它將data_blk的地址p_data_blk插入到loading隊列中,等待I/O線程主動獲取并重新利用.I/O線程成功獲取空閑塊地址p_free_blk后,開始執行do_io操作,并準備向操作系統發送I/O請求,IOC靈活使用內存的方式可以用來支持異步發送I/O請求.當I/O線程通過LIBAIO提供的io_submit發送請求時,會向操作系統傳遞兩大基本參數:需要讀取的數據塊地址范圍、讀到內存的地址p_free_blk,傳遞完畢后就返回.之后,操作系統將該范圍的數據塊從外存載入到內核緩沖區中,在“收割”數據階段,再直接將數據從內核緩沖區拷貝至p_free_blk指向的空閑塊中.完成“收割”后,該空閑塊轉化為數據塊,I/O線程隨即將該塊地址插入到computing queue中.
算法1.異步計算-加載模型(IOC)
// completed or not
Boolean done = 0;
Queue computing { 0 };
Queue loading { BUFSIZ/BLKSIZ };
1 procedurecompute() {
2 while (!done) {
3 Addr p_data_blk = computing.front_pop();
4 do_compute(p_data_blk);
5 loading.append(p_data_blk);
6 }
7 }
8 procedureio() {
9 while (!done) {
10 Addr p_free_blk = loading.front_pop();
11 do_io(p_free_blk);
12 computing.append(p_free_blk);
13 }
14 }
基于地址管理的IOC算法更加靈活.當某個空閑塊地址中的內存被填充好I/O數據后,它就立刻被I/O線程處理,并被插入到computing queue中,而無需等待那些地址在它之前但還未完成I/O操作的空閑塊,這點可以用來支持異步的I/O發送接收方式(LIBAIO引擎).當某個數據塊被處理完畢后,計算線程隨即將它插入到loading queue中,而無需因為內存連續使用的限制而等待.此外,兩組線程都是通過內存地址直接對緩沖區中的數據進行操作,有效避免了數據的拷貝,從而節省了一部分內存和計算資源.
3.3 使用LIBAIO支持更細粒度的I/O數據塊
IOC使用LIBAIO作為I/O引擎.一方面,I/O線程可以非阻塞的發送I/O請求,而無需等待I/O操作的完成,這樣可以增強系統發送I/O請求的能力,盡快地填滿硬盤帶寬.另一方面,LIBAIO的batch機制可以支持更細粒度的I/O數據塊,這些I/O數據塊被填滿I/O數據后,地址被插入到computing queue中,等待計算線程的處理,這就相當于通過“動態分配”的方式讓所有計算線程來“競爭”這些數據塊.粒度更小,各個工作線程的負載就越平衡,4.3通過實驗說明了這點.
3.4 合理的I/O線程數
為了適應內核的I/O訪問機制,合理的做法是分配能夠填滿I/O帶寬的最小線程數量,IOC也遵從這一原則.例如對于1個SSD(最大帶寬為450MBps),單個線程就可以填滿,IOC僅分配1個I/O線程.在順序讀取文件時,單個線程按照文件順序發出I/O請求,文件偏移量低的數據塊會優先到達,內核也會按照這樣的順序向I/O通道傳遞請求,這樣一來,到達的數據塊都會被及時處理,I/O請求的完成時間比較均衡.
為了更有說服力,本文通過實驗比較了對文件順序讀時,使用40個線程和1個線程的I/O請求時間.實驗在GridGraph上運行PageRank算法,輸入數據為UK圖4,使用1個SSD.結果如圖4所示,橫軸為按照文件偏移順序排列的各個I/O請求,縱軸為請求的完成時間.圖4(a)為40個線程順序讀時各個I/O請求的時間,抖動很大;圖4(b)為使用單個線程的結果,各個I/O請求的完成時間比較均衡且遠遠低于40個線程的數值.這也就說明了過多的I/O線程不僅會加大I/O負載,還會造成I/O請求完成時間的不均衡,增大延遲,從而影響整個圖計算系統的I/O性能.
5http://law.di.unimi.it/webdata/gsh-2015/
6http://law.di.unimi.it/webdata/eu-2015/

圖4 I/O完成時間比較Fig.4 Comparison of I/O completion time
4 性能評測
GridGraph是目前性能比較出色的out-of-core圖計算系統,它的性能要優于X-Stream和GraphChi,這也是本文選取它為參照的原因.GridGraph使用同步計算-加載模型,并通過PSYNC提供的I/O接口來處理I/O請求.本文的實驗直接修改了GridGraph代碼,使它支持使用LIBAIO引擎的異步計算-加載模型,并著重探究兩種模型對圖計算系統性能的影響,主要從以下三個方面探究:運行時間,計算負載的平衡性,I/O帶寬.

表1 實驗數據集Table 1 Experimental data sets
4.1 實驗環境
本文的所有實驗均在單個多核服務器上完成,服務器配置為:40個超線程vCPU cores,25MB LLC Cache,116GB memory,1-6 800GB SSDs,6個SSD順序讀的最大吞吐量均可達到450MB/s-500MB/s.
4.2 運行時間
下面實驗分別在使用不同計算-加載模型的GridGraph中運行PageRank和SPMV[10]算法,使用6個SSDs (RAID0),輸入數據如表1所示,這些圖數據(UK,GSH5,ClueWeb,EU6)描述了從不同域名爬取的網頁信息.PageRank和SPMV均為計算密集型算法,計算時間所占比重較大,使用IOC模型之后,它們的計算時間被I/O時間“隱藏”,因此整體系統性能的提升比較明顯.圖5(a)為PageRank算法下兩種模型的時間比較,左邊為GridGraph的運行結果,包括下面的I/O時間和上面的計算時間,緊挨著的右邊為基于IOC模型的GridGraph (IOC-Grid)的運行總時間.兩個模型的運行時間都隨著輸入圖規模的增加而上升,但IOC-Grid的運行時間要始終少于GridGraph,這主要歸功于計算時間被I/O加載時間“隱藏”;此外,IOC能更好的利用硬盤帶寬,I/O加載時間少于GridGraph,這主要歸功于IOC模型靈活的區分I/O線程和計算線程,并創建合理的I/O線程數,既能填滿硬盤帶寬又不會造成額外開銷,從而提高了I/O性能.圖5(b)為SPMV算法的運行結果,IOC-Grid性能依然保持領先.SPMV算法中的邊是帶權重的,與PageRank相比,需要多載入邊的權值數據,因此也就需要更多的運行總時間.

圖5 GridGraph與IOC-Grid的運行時間Fig.5 Runtime of GridGraph and IOC-Grid
IOC-Grid在不同的輸入數據集上有不同的性能提升,其中ClueWeb圖的提升最為明顯,這主要因為該圖的計算時間最突出,幾乎與I/O時間齊平.GridGraph的計算性能受數據布局的影響較大,好的數據布局有助于頂點數據的順序訪問,提高cache命中率,從而減少計算時間.但ClueWeb的數據布局不及其他三個數據集,這點從表2所示的LLC 未命中率就可以看出,這就導致它的計算時間最為突出,幾乎與I/O時間齊平.IOC將這最明顯的計算時間“隱藏”,使得整體性能能夠提升到一半.

表2 不同數據集的LLC 未命中率Table 2 LLC cache miss rate of different data sets
4.3 計算線程負載的平衡性
為了比較兩種模型下計算線程負載的平衡性,下面實驗在原先和修改后的GridGraph上分別運行PageRank算法,創建了40個計算線程,輸入的圖數據為UK,使用1個SSD.圖6(a)為GridGraph的運行結果,使用了PSYNC引擎的同步計算-加載模型;圖6(b)是支持LIBAIO的IOC模型的運行結果.可以明顯看出IOC中計算線程的負載要更加平衡,這主要歸功于LIBAIO可以支持更細粒度的I/O數據塊.Grid-Graph使用的PSYNC引擎為了填滿硬盤帶寬,I/O數據塊小被設定在24MB,而IOC為128KB.兩者的I/O數據塊大小都決定了計算數據塊的大小,128KB和24MB相比明顯粒度更細,這也使得IOC中負載的分配能夠更加公平,各個計算線程的負載更加均衡.
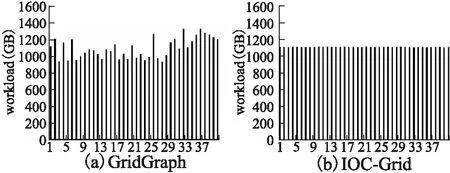
圖6 GridGraph與IOC-Grid的負載平衡性Fig.6 Load balance of GridGraph and IOC-Grid
4.4 不同SSD數量下的帶寬比較
表3為不同SSD數量下,IOC-Grid和GridGraph的帶寬比較結果.可以發現,IOC-Grid始終能保持更高的帶寬利用率,在1個SSD下最為明顯.這主要歸功于IOC能夠根據下層I/O的處理能力合理的分配I/O線程數量,而GridGraph中 I/O線程數量取決于服務器核數,大量的I/O線程數量會增加資源競爭和額外開銷.隨著SSD數量增多,下層I/O的處理能力增強,能夠稍微緩解上層大量I/O并發請求的競爭,GridGraph受益于此,I/O帶寬有所提升,但依然不及IOC-Grid.

表3 不同SSD數量下的帶寬,單位MBpsTable 3 I/O bandwidth under different SSD number,MBps
5 結 論
核外(Out-of-core)圖計算系統使得在單點服務器上執行大規模圖數據成為可能,已有的該類型系統都是通過優化I/O訪問來提高性能,卻忽略了隨著硬盤訪問能力的提升,計算時間越來越突出的問題.對此,本文提出了異步計算-加載模型IOC,在該模型中計算過程不再阻塞于I/O加載過程,較長的I/O時間能夠“隱藏”計算時間.IOC根據硬件資源的訪問能力分配不同數量的線程數,既保證高效的計算能力又保證充分的帶寬利用.IOC摒棄了傳統同步計算-加載模型使用的PSYNC I/O引擎,改用LIBAIO,異步的處理方式提高了接受I/O請求的能力,LIBAIO提供的batch機制也使得各個線程的負載更加均衡.本文最后通過實驗結果說明,IOC能將out-of-core圖計算系統的性能提升高達1倍,并且有更好的帶寬利用率和負載平衡性.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
光學精密工程(2016年6期)2016-11-07 09:07:19
