關(guān)于命名實(shí)體識別的生成式對抗網(wǎng)絡(luò)的研究
2019-06-06 05:46:34馮建周馬祥聰劉亞坤宋沙沙
小型微型計算機(jī)系統(tǒng) 2019年6期
關(guān)鍵詞:模型
馮建周,馬祥聰,劉亞坤,宋沙沙
(燕山大學(xué) 信息科學(xué)與工程學(xué)院,河北 秦皇島 066004) (燕山大學(xué) 河北省軟件工程重點(diǎn)實(shí)驗(yàn)室,河北 秦皇島 066004)
1 引 言
互聯(lián)網(wǎng)的快速發(fā)展使網(wǎng)絡(luò)信息呈爆發(fā)式增長,同時網(wǎng)絡(luò)信息的形式也變得越來越多樣化,這給用戶有效利用網(wǎng)絡(luò)信息資源帶來了很大的不便.面對網(wǎng)絡(luò)信息爆發(fā)式增長帶來的挑戰(zhàn),信息抽取技術(shù)逐漸發(fā)展起來.信息抽取是指從大規(guī)模的無結(jié)構(gòu)文本中提取出用戶真正感興趣的信息,并以結(jié)構(gòu)化或半結(jié)構(gòu)化的形式存儲或輸出[1].
信息抽取技術(shù)起源于20世紀(jì)70年代早期對自然語言處理(Natural Language Processing,NLP)的研究,而后從20世紀(jì)80年代中期開始蓬勃發(fā)展起來,這得益于消息理解會議(Message Understanding Conference,MUC)1的推動.繼MUC之后,自動內(nèi)容抽取(Automatic Content Extraction,ACE)2評測會議也對信息抽取技術(shù)的發(fā)展起著關(guān)鍵性的作用.
根據(jù)ACE的劃分,信息抽取主要包括4個方面的研究:命名實(shí)體識別、指代消解、實(shí)體關(guān)系抽取和事件抽取.其中,命名實(shí)體識別(Named Entity Recognition,NER)是這些任務(wù)中最關(guān)鍵的部分.這是因?yàn)槊麑?shí)體識別是NLP領(lǐng)域中一些復(fù)雜任務(wù)(如機(jī)器翻譯、問答系統(tǒng)、信息檢索等)的基礎(chǔ).同時命名實(shí)體識別又是實(shí)體關(guān)系抽取的基礎(chǔ).例如,在機(jī)器翻譯中,3Stanford Open Information Extraction.https://nlp.stanford.edu/software/openie.html.
4http://blog.heuritech.com/2016/01/20/attention-mechanism/
只有將目標(biāo)句子中的實(shí)體準(zhǔn)確地識別出來并知道實(shí)體之間的語義關(guān)系才能夠準(zhǔn)確的翻譯目標(biāo)句子.在問答系統(tǒng)中,系統(tǒng)只有從用戶的提問中準(zhǔn)確地識別出實(shí)體類型以及實(shí)體之間的關(guān)系才能更好地為用戶解答.
命名實(shí)體識別任務(wù)最初是在MUC-6上被提出的,它的主要任務(wù)是識別出自然語言文本中的各種短語并加以歸類.它有兩個關(guān)鍵的任務(wù):一是要識別出文本中是否有命名實(shí)體,二是要判斷出命名實(shí)體具體所指的目標(biāo)類型.命名實(shí)體的領(lǐng)域相關(guān)性很強(qiáng);數(shù)量巨大,收錄非常困難,沒有通用化的字典可供查詢;表達(dá)形式多樣,可能采用縮寫等其他變化的方式,影響判別準(zhǔn)確率等等,這些都給命名實(shí)體識別任務(wù)增加了難度.
2 相關(guān)工作
命名實(shí)體識別是NLP領(lǐng)域中一些復(fù)雜任務(wù)的基礎(chǔ),因此一直以來都是NLP領(lǐng)域中的研究熱點(diǎn).現(xiàn)有的命名實(shí)體識別研究方法有基于規(guī)則的方法,基于傳統(tǒng)機(jī)器學(xué)習(xí)的方法(又叫統(tǒng)計的方法),以及近年來流行的基于深度學(xué)習(xí)的方法.
基于規(guī)則的方法[2]由于手工構(gòu)造規(guī)則,系統(tǒng)能夠達(dá)到較好的性能,但構(gòu)造規(guī)則時太依賴于專業(yè)領(lǐng)域知識,費(fèi)時費(fèi)力且系統(tǒng)的可移植性較差.
基于機(jī)器學(xué)習(xí)的方法中,命名實(shí)體識別被看作是序列標(biāo)注問題,傳統(tǒng)的機(jī)器學(xué)習(xí)方法有許多適用于序列標(biāo)注問題的模型.Borthwick等人[3]利用最大熵馬爾科夫模型和額外知識集提高了NER的準(zhǔn)確性.Lafferty等人[4]提出條件隨機(jī)場用于模式識別任務(wù).Zhou等人[5]提出使用四種不同特征來提高隱馬爾可夫模型在NER任務(wù)上的性能.McCallum A[6]提出使用更豐富,更高階的馬爾科夫模型的特征感應(yīng)法和維特比法用于NER任務(wù).除了基于有監(jiān)督的機(jī)器學(xué)習(xí)方法,機(jī)器學(xué)習(xí)的半監(jiān)督和無監(jiān)督的學(xué)習(xí)方法也可以用于NER任務(wù).在NER方面,主要的半監(jiān)督學(xué)習(xí)方法是“bootstrapping”方法[7,8].李麗雙[9]利用半監(jiān)督SVM模型與CRF模型進(jìn)行組合的方法,實(shí)現(xiàn)了將多分類器組合與字典匹配運(yùn)用到命名實(shí)體識別中,提高了試驗(yàn)效果.此外,還有一些無監(jiān)督的開放信息抽取系統(tǒng),如華盛頓大學(xué)的TxtRunner[10]、 ReVerb[11]等系統(tǒng),斯坦福大學(xué)的Stanford OpenIE3等是開放信息抽取中的典型工作.
近年來,隨著深度學(xué)習(xí)算法的普及,很多學(xué)者開始將深度學(xué)習(xí)算法應(yīng)用在NER領(lǐng)域,而且已經(jīng)取得了卓越的效果.Athavale V[12]提出的BiLSTM模型采用了雙向長短時記憶(Bi-Long-Short-Term Memory,BiLSTM)網(wǎng)絡(luò),通過BiLSTM網(wǎng)絡(luò)將上下文結(jié)合起來,進(jìn)行NER的訓(xùn)練,取得了良好的效果.Huang Z[13]和Lample G[14]采用BiLSTM與CRF(Conditional random field algorithm)結(jié)合的方法,進(jìn)行命名實(shí)體識別的實(shí)驗(yàn),不但能充分利用上下文的信息,又能考慮到句子的語義規(guī)則信息,從而取得了比單純BiLSTM更好的效果.Chiu等人[15]使用BiLSTM+CNN模型來獲取更多的特征,在輸入層,將詞向量和詞特征進(jìn)行結(jié)合,然后利用CNN進(jìn)行特征抽取,最后,通過BiLSTM進(jìn)行訓(xùn)練,從而提高了效果.Rei等人[16]在RNN-CRF模型結(jié)構(gòu)基礎(chǔ)上,重點(diǎn)改進(jìn)了詞向量與字符向量的拼接,采用CRF作為輸出層,并以預(yù)測的標(biāo)簽作為條件,使用注意力機(jī)制(Attention)4將原始的字符向量和詞向量拼接改進(jìn)成權(quán)重求和,使用兩層傳統(tǒng)神經(jīng)網(wǎng)絡(luò)隱層來學(xué)習(xí)Attention的權(quán)值,這樣就使得模型可以動態(tài)地利用詞向量和字符向量信息.深度學(xué)習(xí)的方法在NER領(lǐng)域雖然取得了很好的效果,但是仍然存在很大的改進(jìn)空間,比如超參數(shù)的選擇仍然依賴經(jīng)驗(yàn),優(yōu)化過程過早收斂等情況.
2014年,Ian Goodfellow[17]提出了生成式對抗網(wǎng)絡(luò),即GAN(Generative Adversarial Networks)模型.最初,GAN模型是用于生成圖像這樣的連續(xù)數(shù)據(jù)的,并不能直接用來生成離散數(shù)據(jù).而當(dāng)離散數(shù)據(jù)做微小改變時,在映射空間中也許根本就沒有對應(yīng)意義的序列,所以當(dāng)GAN處理NLP這種離散數(shù)據(jù)的任務(wù)時,容易出現(xiàn)梯度消失的問題.此外,GAN無法判斷目前生成的某一部分序列的質(zhì)量,因?yàn)樗荒芙o生成的完整序列打分.
但是,這些問題近兩年已經(jīng)有所突破.于瀾濤等人[18]提出的SeqGAN(Sequence Generative Adversarial Nets)模型,通過執(zhí)行強(qiáng)化學(xué)習(xí)中的策略梯度解決了原始GAN在序列標(biāo)注問題中無法為生成器提供梯度的問題.SeqGAN中的獎勵信號仍來自判別器對完整序列的判斷,只不過它使用蒙特卡洛搜索返回中間狀態(tài)的動作步驟來實(shí)現(xiàn)為部分序列打分.Arjovsky M[19]提出了WGAN模型來解決NLP領(lǐng)域的梯度消失問題.該論文給出了GAN訓(xùn)練效果不穩(wěn)定的原因,并利用wassertein距離進(jìn)行了解決,同時解決了GAN的模式崩潰的問題.Mirza M[20]提出的CGAN模型針對NLP領(lǐng)域以往的GAN不能生成特定屬性的問題,進(jìn)行了相關(guān)改進(jìn),它將特定屬性融入到生成器和判別器當(dāng)中,從而解決了GAN不能生成特定屬性的缺點(diǎn).Gulrajani I[21]在WGAN的基礎(chǔ)之上提出了WGAN-GP,通過采用lipschitz連續(xù)性限制的方法,解決了訓(xùn)練梯度消失或者梯度爆炸的問題,同時,提高了收斂速度.
相關(guān)研究工作表明,GAN可以在NLP任務(wù)上有杰出表現(xiàn).但在NER方面,GAN還沒有相應(yīng)的研究.因此,本文將CGAN和WGAN-GP兩者的優(yōu)點(diǎn)結(jié)合,提出一個適合于命名實(shí)體識別任務(wù)的條件Wasserstein生成式對抗網(wǎng)絡(luò)(Conditional Wasserstein Generative Adversarial Nets,CWGAN).
3 基于CWGAN的命名實(shí)體識別
命名實(shí)體識別任務(wù)一般被看做序列標(biāo)注問題.因此,本文將未標(biāo)注的句子作為條件,構(gòu)建CWGAN模型,完成命名實(shí)體識別任務(wù).在對抗學(xué)習(xí)中本文將命名實(shí)體識別任務(wù)描述如下:給定一個未標(biāo)注的由一系列單詞組成的句子X={x1,x2,…,xn},并以此作為CWGAN模型的條件,生成器模型通過條件生成句子的標(biāo)注序列,判別器模型給生成的標(biāo)注序列打分,并為生成器模型提供反饋指導(dǎo)生成器模型訓(xùn)練,最終訓(xùn)練好的生成器模型能夠生成質(zhì)量較高的命名實(shí)體標(biāo)簽Y={y1,y2,…,yn},其中xi代表單詞,yi代表其對應(yīng)的生成標(biāo)簽.
3.1 用于命名實(shí)體識別的CWGAN模型的設(shè)計思路
本小節(jié)介紹用于命名實(shí)體識別的CWGAN模型的設(shè)計思路.如圖1所示,模型分為兩部分:生成器模型(G)和判別器模型(D).
生成器模型(G)定義了在給定句子的情況下生成該句子對應(yīng)的命名實(shí)體標(biāo)簽序列的策略.本文的生成器模型使用的是一個BiLSTM網(wǎng)絡(luò).將句子序列X輸入到生成器中(句子序列是未標(biāo)注的),將未標(biāo)注的句子作為條件信息,用于生成標(biāo)注,通過BiLSTM網(wǎng)絡(luò)得到每個單詞的上下文信息表示,通過全連接層以及softmax層得到每個單詞在各個命名實(shí)體標(biāo)簽上的概率.判別器模型(D)使用的是一個BiLSTM網(wǎng)絡(luò).將句子序列X及其對應(yīng)標(biāo)注標(biāo)簽序列L(專家預(yù)先標(biāo)注的標(biāo)簽)連接作為正實(shí)例輸入到D,同時,將句子序列X與G生成的標(biāo)簽序列連接起來作為負(fù)實(shí)例輸入到BiLSTM網(wǎng)絡(luò),以專家標(biāo)注的標(biāo)簽為參照,為生成的標(biāo)簽序列的打分,將每個詞的生成標(biāo)簽得分進(jìn)行求和,返回句子中每個詞的標(biāo)簽的總得分,最后句子的得分是句子中每個詞的得分的均值.由于得分均值是通過每個詞和標(biāo)注組合的得分加和而來,所以在反向傳導(dǎo)過程中,D能針對G每一步的輸出進(jìn)行反饋.D給G的反饋是針對于句子中每個詞的,這樣做相對于直接對整個標(biāo)簽序列和句子序列進(jìn)行判別,返回的信息更多,更有助于G的優(yōu)化.
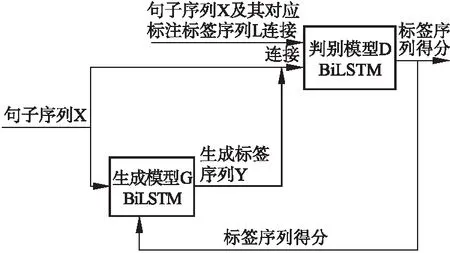
圖1 CWGAN整體框架Fig.1 Whole frame diagram CWGAN
3.2 輸入表示
NLP任務(wù)中通常要把文本轉(zhuǎn)換成分布式表示,本文采用詞向量的方式來表示文本中的單詞,使用詞向量的目的是將句子中的每個單詞映射成K維實(shí)值向量.例如,給定一個句子X={x1,x2,…,xn},通過映射詞向量矩陣E∈R|V|×dw將每個單詞xi表示為dw維實(shí)值向量,V是詞表的大小(詞向量訓(xùn)練語料中的詞的數(shù)目).
3.3 生成器模型

如圖2所示,得到單詞的上下文表示后,通過一個全連接層并將結(jié)果傳送給softmax層得到每個單詞在各類標(biāo)簽上的條件概率,計算方法如下:
(1)
公式(1)表示在參數(shù)θ下,單詞xi的標(biāo)簽歸為y的概率,其中,nm是標(biāo)簽種類個數(shù),o是全連接層后的輸出,其計算方法如下:
(2)
其中,W′代表全連接層的權(quán)重矩陣,hi代表單詞xi的上下文信息,b′為偏置向量.
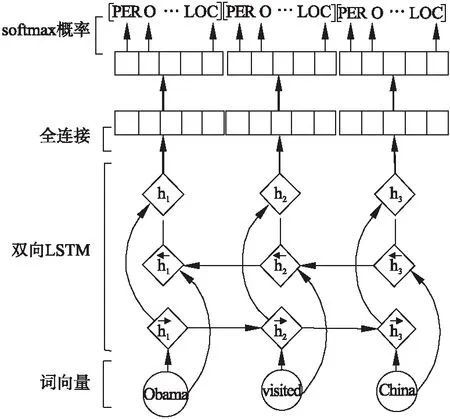
圖2 生成器的BiLSTM處理過程Fig.2 Bidirectional LSTM processing of generator
3.4 判別器模型
本文提出的CWGAN模型中的判別器模型也是BiLSTM網(wǎng)絡(luò).使用BiLSTM,可以為每個單詞的標(biāo)簽單獨(dú)打分.由于句子的長度是不固定的,通過填充將句子轉(zhuǎn)換為具有固定長度T的序列,該長度是生成器模型的輸出設(shè)置的最大長度.
判別器的BiLSTM的輸入有兩種,一種是句子序列x1,…,xT和對應(yīng)的標(biāo)注標(biāo)簽序列l(wèi)1,…,lT的連接[X;L],另一種句子序列x1,…,xT和生成器生成的標(biāo)簽序列y1,…,yT的連接[X;Y](兩個句子序列相同,標(biāo)簽不同).其中X,L,Y分別為句子序列矩陣X1:T和生成標(biāo)簽矩陣Y1:T以及標(biāo)注標(biāo)簽矩陣序列L1:T,它們分別建立為:
X1:T=x1;x2;…;xT
Y1:T=y1;y2;…;yT
L1:T=l1;l2;…;lT
其中,xt,yt,lt是k維詞向量表示,分號是連接運(yùn)算符,且在[X;L]和[X;Y]中為行連接,在X1:T、Y1:T以及L1:T中為列連接,即,若標(biāo)簽序列維度為n1,則連接后的[X;L]和[X;Y]的維度為T×(dw+n1).
(3)
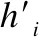

圖3 判別器的BiLSTM處理過程Fig.3 Bidirectional LSTM processing of discriminator
3.5 優(yōu)化目標(biāo)函數(shù)
本文提出的CWGAN模型使用WGAN-GP模型的梯度更新方式,即通過拉近真實(shí)樣本分布和生成樣本分布之間的Wasserstein距離(又叫Earth-Mover,EM距離)來優(yōu)化目標(biāo)函數(shù).Wasserstein距離的公式定義如下所示:
(4)
其中,Pr代表真實(shí)樣本的分布,Pg代表生成器生成樣本的分布,∏(Pr,Pg)代表真實(shí)樣本分布Pr和生成樣本分布Pg組合起來的所有可能的聯(lián)合分布的集合.從每一個可能的聯(lián)合分布γ中采樣得到一個真實(shí)樣本x和一個生成樣本y,即(x,y)~γ,算出這對樣本的距離‖x-y‖,然后就可以計算該聯(lián)合分布γ下樣本對距離的期望E(x,y)~γ[‖x-y‖].在所有可能的聯(lián)合分布中能夠?qū)@個期望值取到的下界(公式(5)等號右邊),即定義為Wasserstein距離.通過拉近真實(shí)樣本和生成樣本的Wasserstein距離來拉近兩個樣本的分布,其好處是在兩個樣本分布無重疊或重疊部分可忽略的情況下,Wasserstein距離仍然可以提供有意義的梯度.
在對抗訓(xùn)練的過程中,判別器的作用是為生成器生成的數(shù)據(jù)(分布)打分,生成器則根據(jù)判別器給出的分?jǐn)?shù)做出微小的調(diào)整,然后再將新生成的數(shù)據(jù)交給判別器打分.所以當(dāng)輸入判別器的樣本稍微改變,判別器不能給出與上次樣本差距太大的分?jǐn)?shù),即需要限制判別器打分的變動幅度.對于判別器的這種限制可以通過施加Lipschitz限制實(shí)現(xiàn),如下:
‖f(x1)-f(x2)‖≤K|x1-x2|
(5)
其中K是一個大于等于0的常數(shù),x1和x2是樣本空間內(nèi)的元素.本文的CWGAN模型利用梯度懲罰來實(shí)現(xiàn)Lipschitz限制,即額外設(shè)置一個損失項(xiàng):
[‖xD(x)‖p-K]2
(6)
為了使損失項(xiàng)的期望能夠進(jìn)行采樣,只在生成樣本集區(qū)域、真實(shí)樣本集中區(qū)域以及夾在它們中間的區(qū)域進(jìn)行采樣.加上以上損失項(xiàng)后判別器損失函數(shù)定義如下:
L(D)=-Ex~Pr[D(x)]+Ex~Pg[D(x)]+

(7)

(8)
判別器期望拉大兩個分布之間的Wasserstein距離,生成器希望拉近兩個分布之間的Wasserstein距離.
生成器的損失函數(shù)定義如下:
L(G)=Ex~Pg[D(x)]+cost
(9)
其中,cost代表真實(shí)樣本與生成樣本的交叉熵,計算公式如下:
cost=-[D((l′)log(D(y′))+(1-D(l′))log(1-D(y′))]
(10)
其中,l′代表句子序列和對應(yīng)的標(biāo)注標(biāo)簽序列的連接[X;L],y′代表句子序列和生成器生成的標(biāo)簽序列的連接[X;Y].
本模型采用Adam優(yōu)化算法來優(yōu)化判別器和生成器的損失函數(shù).為了防止生成器訓(xùn)練時發(fā)生梯度爆炸,使用裁剪(clip)的方法限制每次更新后梯度的范圍,一旦生成器的梯度超過了設(shè)定閾值就對其進(jìn)行“裁剪”,使其保持在設(shè)定閾值范圍內(nèi).
4 實(shí)驗(yàn)結(jié)果及分析
為了證明本文提出的CWGAN模型的優(yōu)越性,本節(jié)設(shè)置了幾組對比實(shí)驗(yàn),通過比較CWGAN模型和BiLSTM模型在不同數(shù)據(jù)集上實(shí)現(xiàn)NER任務(wù)時的性能,以及不同設(shè)置下CWGAN模型在NER任務(wù)中的性能來說明CWGAN模型的效果.另外需要說明的是,本文的CWGAN算法只與基礎(chǔ)的BiLSTM模型進(jìn)行了比較,因?yàn)樯瞎?jié)提到的BiLSTM+CRF模型、CNN+BiLSTM模型,以及CNN+Attention+BiLSTM模型都是在BiLSTM基礎(chǔ)模型上增加新的模塊從而改善了性能,本文算法同樣可以在輸入端和輸出端增加相應(yīng)的模塊來改善性能,這里就不再一一進(jìn)行比較.
4.1 數(shù)據(jù)集及評估標(biāo)準(zhǔn)
本節(jié)實(shí)驗(yàn)使用的數(shù)據(jù)集是CoNLL-2002中的西班牙文數(shù)據(jù)集和CoNLL-2003中的英文數(shù)據(jù)集.
CoNLL-2002中NER任務(wù)數(shù)據(jù)集包含了西班牙文數(shù)據(jù)集和荷蘭文數(shù)據(jù)集.西班牙文數(shù)據(jù)集是由西班牙的EFE通訊社提供的新聞組成.該數(shù)據(jù)集標(biāo)記有四種不同的命名實(shí)體類型,分別為:人名(PERSON),地名(LOCATION),組織機(jī)構(gòu)名(ORGANIZATION)以及其他命名實(shí)體(MISC),即不屬于以上三種實(shí)體中的任何一種.該數(shù)據(jù)集包含了標(biāo)準(zhǔn)的訓(xùn)練集,驗(yàn)證集和測試集.如表1所示.
5https://en.wikipedia.org/wiki/Word2vec
6https://nlp.stanford.edu/projects/glove/
表1 CoNLL-2002 NER任務(wù)西班牙文數(shù)據(jù)集規(guī)模表
Table 1 CoNLL-2002 NER Task Spanish dataset scale table

人名地名組織機(jī)構(gòu)名其他單詞數(shù)量訓(xùn)練集82246804123825385273037驗(yàn)證集208113213066109954837測試集13691409250489653049
CoNLL-2003 NER任務(wù)數(shù)據(jù)集由路透社RCV1語料庫的新聞專線組成.它標(biāo)有四種不同類別的命名實(shí)體類型:人名(PERSON),地名(LOCATION),組織機(jī)構(gòu)名(ORGANIZATION)以及其他命名實(shí)體(MISC).該數(shù)據(jù)集包括標(biāo)準(zhǔn)的訓(xùn)練集,驗(yàn)證集和測試集.如表2所示.
表2 CoNLL-2003 NER任務(wù)英文數(shù)據(jù)集規(guī)模表
Table 2 CoNLL-2003 NER Task English dataset scale table

人名地名組織機(jī)構(gòu)名其他單詞數(shù)量訓(xùn)練集111358297100274593204568驗(yàn)證集315020942092126851597測試集27771925249691846667
采用NLP任務(wù)中常用的評測指標(biāo)F-1測度值對實(shí)驗(yàn)結(jié)果進(jìn)行評價分析,F-1測度值是對準(zhǔn)確率和召回率的一種平均加權(quán),它能夠體現(xiàn)整體測試效果.它的計算方法為:
(11)
其中,P代表準(zhǔn)確率,P=正確識別的命名實(shí)體個數(shù)/識別的命名實(shí)體總數(shù)×100%,R代表召回率,R=正確識別的命名實(shí)體個數(shù)/數(shù)據(jù)集中命名實(shí)體總數(shù)×100%.
4.2 實(shí)驗(yàn)設(shè)置
1)預(yù)訓(xùn)練的詞向量.與隨機(jī)初始化的詞向量相比,使用預(yù)訓(xùn)練的詞向量可以取得更好的效果.
本實(shí)驗(yàn)使用了兩種預(yù)訓(xùn)練的詞向量:Word2vec5和GloVe6.GloVe與Word2vec都是基于詞共現(xiàn)結(jié)構(gòu)以無監(jiān)督的方式學(xué)習(xí)單詞的向量表示.不同的是,GloVe是對“詞-詞”矩陣進(jìn)行分解從而得到詞表示的方法,屬于基于矩陣的分布表示,它相比Word2vec充分考慮了詞的共現(xiàn)情況.
由于兩者都具有比較優(yōu)秀的準(zhǔn)確性,并且這兩種詞向量是當(dāng)前使用比較廣泛的兩種詞向量,所以,此次實(shí)驗(yàn)采用了這兩種方法生成的向量作為實(shí)驗(yàn)的輸入.本實(shí)驗(yàn)中使用300維的實(shí)值向量表示單詞的詞向量,word2vec和GloVe訓(xùn)練詞向量時使用的參數(shù)如表3所示.
表3 詞向量訓(xùn)練參數(shù)表
Table 3 Word vector training parameters table

詞向量工具詞向量維度窗口大小學(xué)習(xí)率采樣閾值Word2vec30030.011e-4GloVe30030.01—
2)參數(shù)設(shè)置.本文在訓(xùn)練時使用三折交叉驗(yàn)證法調(diào)整模型.用網(wǎng)格搜索法來確定最優(yōu)參數(shù),并指定參數(shù)空間子集為:窗口大小w∈{1,2,3…7},過濾器數(shù)量n∈{64,128,256,512},生成器梯度裁剪閾值∈{8,9,10,11,12},隨機(jī)梯度下降學(xué)習(xí)率λ∈{0.1,0.01,0.001,0.0001},使用 Adam優(yōu)化器更新參數(shù).本文實(shí)驗(yàn)使用的參數(shù)如表4所示.
表4 實(shí)驗(yàn)參數(shù)表
Table 4 Table of experimental parameters

詞嵌入維度隱藏層神經(jīng)元個數(shù)窗口大小批大小丟棄率學(xué)習(xí)率梯度閾值dw=300n=256w=3B=16p=0.5λ=0.000110
4.3 實(shí)驗(yàn)對比及分析
本文提出的CWGAN模型與BiLSTM模型[12]的性能進(jìn)行了對比.表5是BiLSTM與CWGAN的基于西班牙文數(shù)據(jù)集的對比實(shí)驗(yàn)的結(jié)果.表6是BiLSTM、CWGAN的基于英文數(shù)據(jù)集的對比實(shí)驗(yàn)結(jié)果.CWGAN代表生成器和判別器都使用BiLSTM.由于西班牙用于預(yù)訓(xùn)練的數(shù)據(jù)不充足,導(dǎo)致實(shí)驗(yàn)效果不是很好,但是,實(shí)驗(yàn)的對比效果并沒有因此受到影響.
表5 基于CoNLL-2002的CWGAN模型效果表
Table 5 CWGAN Model base CoNLL-2002 effect table
從表5中可以看出,在對于基于CoNLL-2002的實(shí)驗(yàn)上,無論是在驗(yàn)證集Test_a上還是測試集Test_b上,CWGAN模型的F1值都比BiLSTM模型的F1值有所提高.在驗(yàn)證集Test_a上,CWGAN模型比BiLSTM模型提高0.49%;在測試集Test_b上,CWGAN模型比BiLSTM模型提高1.20%.這說明CWGAN模型將生成對抗式網(wǎng)絡(luò)用于命名實(shí)體識別任務(wù)是成功的,判別器能夠指導(dǎo)生成器學(xué)習(xí).
表6 基于CoNLL-2003的CWGAN模型效果表
Table 6 CWGAN Model effect base CoNLL-2003 table

模型Test_a_F1Test_b_F1收斂所需的迭代次數(shù)BiLSTM92.73%88.01%60CWGAN(BiLSTM-BiLSTM)93.02%88.32%40
從表6中可以看出,對于基于CoNLL-2003數(shù)據(jù)集的實(shí)驗(yàn)上,無論是在驗(yàn)證集Test_a上還是測試集Test_b上,CWGAN模型的F1值比BiLSTM模型的F1值有所提高.在驗(yàn)證集Test_a上,CWGAN模型比BiLSTM模型提高0.29%;在測試集Test_b上,CWGAN模型比BiLSTM模型提高0.21%.這說明CWGAN模型將生成對抗式網(wǎng)絡(luò)用于命名實(shí)體識別任務(wù)是成功的,判別器能夠指導(dǎo)生成器學(xué)習(xí).
從收斂迭代次數(shù)方面比較,CWGAN模型的效果也優(yōu)于BiLSTM模型,CWGAN模型在迭代40次上下時達(dá)到收斂,而BiLSTM模型則需要迭代60次上下.
4.4 預(yù)訓(xùn)練詞向量和dropout的影響
為了驗(yàn)證預(yù)訓(xùn)練的詞向量以及dropout對于命名實(shí)體識別模型的影響,本小節(jié)做了以下對比實(shí)驗(yàn).“dropout”是指在訓(xùn)練的時候,按一定的概率p來對權(quán)重層的參數(shù)進(jìn)行隨機(jī)采樣.
表7 基于CoNLL-2003數(shù)據(jù)集的不同設(shè)置下的CWGAN
模型效果對比表
Table 7 CWGAN model effect comparison table under different
Settings base CoNLL-2003 database

模型Test_a_F1Test_b_F1CWGAN84.17%80.45%CWGAN+dropout85.81%81.38%CWGAN+pretrain(word2vec)91.85%86.99%CWGAN+pretrain(GloVe)73.60%69.44%CWGAN+pretrain(word2vec)+dropout93.02%88.32%CWGAN+pretrain(GloVe)+dropout74.62%70.67%
表7顯示了使用預(yù)訓(xùn)練的詞向量和使用隨機(jī)初始化的詞向量的結(jié)果對比,表中“dropout”代表訓(xùn)練時設(shè)置丟棄率,“pretrain(word2vec)”代表使用word2vec工具預(yù)訓(xùn)練的詞向量,“pretrain(GloVe)”代表使用GloVe工具預(yù)訓(xùn)練的詞向量,CWGAN和CWGAN+dropout代表使用隨機(jī)初始化的詞向量.結(jié)果顯示,使用預(yù)訓(xùn)練的word2vec詞向量比使用隨機(jī)初始化的詞向量F1值提高了6.99%到7.16%,說明與隨機(jī)初始化的詞向量相比,使用預(yù)訓(xùn)練的word2vec詞向量可以獲得更好的效果.而使用GloVe詞向量F1值反而比隨機(jī)初始化的詞向量效果更差了,因此建議預(yù)訓(xùn)練詞向量時使用word2vec詞向量.表7中可以看出,在訓(xùn)練時使用“dropout”比不使用F1值提高了1.17%到1.02%,說明在訓(xùn)練時使用“dropout”可以提高模型的性能,這是因?yàn)椤癲ropout”在訓(xùn)練階段可以阻止神經(jīng)元的共適應(yīng).
5 結(jié) 論
本文提出了一個生成式對抗網(wǎng)絡(luò)模型(CWGAN)用于命名實(shí)體識別任務(wù).該網(wǎng)絡(luò)模型借鑒CGAN以文本描述為條件的圖像概率分布的思想,來完成命名實(shí)體識別以句子序列為條件獲得標(biāo)注序列概率分布的任務(wù).另外,該模型采用WGAN-GP中的梯度懲罰來保證梯度在后向傳播的過程中保持平穩(wěn).實(shí)驗(yàn)證明,本文提出的CWGAN模型在命名實(shí)體識別任務(wù)中是有效的,在對抗學(xué)習(xí)的過程中判別器可以指導(dǎo)生成器進(jìn)一步提高自己的性能.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
