自動實現字段權重分配的科技項目查重方法研究
2019-06-03 02:51:54
探索科學(學術版) 2019年10期
關鍵詞:文本
廣西壯族自治區科學技術情報研究所 廣西 南寧 530023
1 研究背景
目前,項目的重復檢測主要是采用萬方、知網、維普等檢測系統,通過字符串匹配算法來計算待檢測的文件相對于文件庫中的目標文件的相似比[1]。字符串匹配算法是以一段文字一致作為衡量內容重復的標準[2],然而,由于中文語言的復雜性和表達方式的多樣性,對于實質內容相同的兩段文字,往往會因為中間出現一些無意義的“停詞”或虛詞或者主謂賓順序不一致等情況,而將其錯誤地判斷為不屬于重復內容,因此,采用現有技術中的字符串匹配算法可能會導致查全率和查準率不高。而且,字符串匹配算法對字符串的選取要求嚴格,算法本身復雜度較高,需要相對大的資源開銷和較長的計算時間,因此,查重的效率也不高。此外,近年來,隨著科技項目申報、學術論文和學位論文等的數量大幅增長,迫切需要查重結果準確、高效的文本數據查重的方法[3]。
2 科技項目查重方法
本文基于科技項目查重的需求背景,開展了自動實現字段權重分配的科技項目查重方法研究。基于深度學習算法自動實現字段權重分配的科技項目查重方法包括如下步驟:
步驟1:在目標文件的指定字段中提取目標文本,將所述目標文本切分為關鍵詞;例如,選取目標文件,指定字段設置為“技術內容”,在目標文件的“技術內容”字段中提取了“應用游戲引擎UDK技術將提取的特色元素虛擬化、數字化,利用三維建模Blender技術將虛擬化信息應用于移動游戲端”的目標文本,將目標文本切分為“應用/游戲/引擎/UDK/技術/將/提取/的/特色/元素/虛擬化/數字化/利用/三維/建模/Blender/技術/將/虛擬化/信息/應用于/移動/游戲端/”多個關鍵詞;實施例中,指定字段還可以包括“標題”、“負責人”、“承擔機構”、“合作機構”、“摘要”以及“正文”;在實施例中,將目標文本切分為關鍵詞時,可以按照動詞、名詞、形容詞、副詞、介詞切分為關鍵詞,省略其他類型的關鍵詞;
步驟2:在數據庫中檢索含有單個關鍵詞的項目文件,設定關鍵詞的權重值;例如,在12564個項目文件的數據庫中檢索后,含“應用”關鍵詞的項目文件9472個,含“游戲”關鍵詞的項目文件2761個,含“引擎”關鍵詞的項目文件958個,含“UDK”關鍵詞的項目文件8個,對項目文件個數進行歸一化處理y=x-8/(9472-8),結果得出:“應用”為“1”,“游戲”為“0.29089”,“引擎”為“0.10038”,“UDK”為“0.00085”;
步驟3:利用神經網絡組建權重評估器對含有關鍵詞的待查文件進行評估,權重評估器輸出待查文件的相關度,根據權重評估器的輸出結果進行排序;如:權重評估器的輸出結果為:待查文件1的相關度為0.913,待查文件2的相關度為0.762,待查文件3的相關度為0.913,待查文件4的相關度為0.206,待查文件5的相關度為0.050,待查文件6的相關度為0;因此,排序為待查文件1>待查文件3>待查文件2>待查文件4>待查文件5>待查文件6。
3 利用神經網絡組建權重評估器
獲取關鍵詞的權重值,選取六篇待查文件作為訓練樣本,其中三篇待查文件與目標文件相關,其他三篇待查文件與目標文件不相關,將相關的待查文件賦值為1,不相關的待查文件賦值為0;
獲取六篇待查文件含有的關鍵詞,根據相關性輸入神經網絡進行訓練,如表1所示;
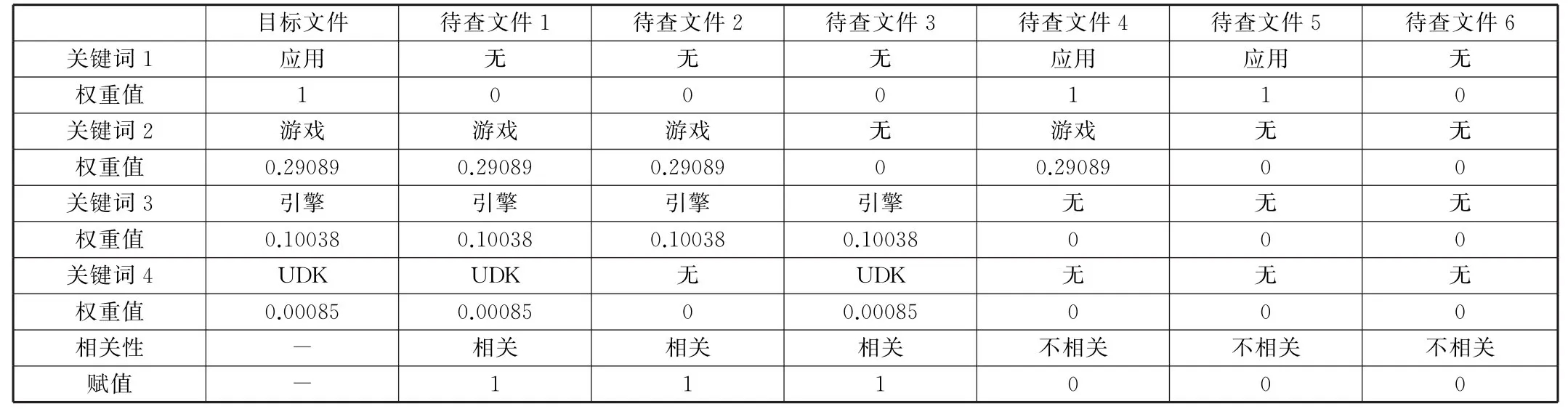
表1 神經網絡樣本訓練表
從表1可以獲得神經網絡的訓練集,輸入為關鍵詞權重值P=[0,0.29089,0.10038,0.00085;0,0.29089,0.10038,0;0,0,0.10038,0.00085;1,0.29089,0,0;0,0,0,0],輸出為相關性S0=[1,1,1,0,0,0];將以上樣本集代入式(1)的徑向基神經網絡進行擬合訓練,擬合訓練可獲得具有關鍵詞特性的權重評估器,如式(1)所示;
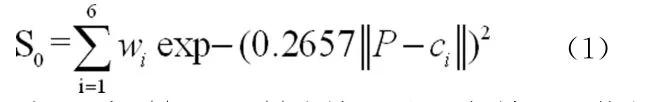
式(1)中,||P-c i||為輸入量P與神經網絡權量c i的歐式距離,w i為神經網絡隱層到輸出層之間的權量,w i=[w1w2w3w4w5w6]T=[0.050 0.315 0.465 0.585 0.835 0.975],c i=[c1c2c3c4c5c6]T=[0.3050 0.4528 0.6238 0.8029 0.9763]。
待訓練完成后,神經網絡組建的權重評估器可以根據關鍵詞的權重值P輸出該待查文件的相關度S0的值,如表2所示;

表2 待查文件的相關度
根據S0進行待查文件的相關度排序,如表2所示。
步驟4:選取相關度最高的待查文件,在待查文件的指定字段中提取比對文本;如:選取待查文件1,提取比對文本如下:“利用UDK虛幻引擎畫刷制作游戲四面墻,然后利用UDK虛幻引擎進行初始游戲的基礎添加,通過四面墻的添加以及貼圖的附加,場景的初步搭建。在其中添加一些隔斷墻,并適當的添加一些燈光,給其符合場景的顏色,給一些比較暗的地方添加Sport Light,場景中只有墻體閉塞,可以適當的創建天窗,并附上材質”;
步驟5:將所述目標文本與所述比對文本進行字母化,建立比對矩陣,在比對矩陣中查找滿足相似字符串條件的子矩陣;
步驟6:根據子矩陣的規模計算所述目標文本與所述比對文本的相似度,
計算比對文本的相似度的公式如下:
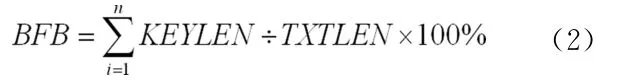
其中,BFB表示章節相似比,TXTLEN表示比對文本長度,n是比對文本中關鍵字的個數,KEYLEN表示關鍵字的長度(即查找出的相似片度的長度)。該方法利用神經網絡對相關樣本進行學習訓練,訓練完成后能夠高效、快速地完成文件相似性比對(查重)的任務。
5 結論
本研究提供了一種基于深度學習算法自動實現字段權重分配的科技項目查重方法,包括:在目標文件的指定字段中提取目標文本,將所述目標文本切分為關鍵詞;在數據庫中檢索含有單個關鍵詞的待查文件,設定關鍵詞的權重值;利用神經網絡組建權重評估器對含有關鍵詞的待查文件進行評估和排序;選取相關度最高的待查文件,在待查文件的指定字段中提取比對文本;建立比對矩陣,根據子矩陣的規模計算所述目標文本與所述比對文本的相似度;該方法利用神經網絡對相關樣本進行學習訓練,訓練完成后能夠高效、快速地完成文件相似性比對(查重)的任務。
科技項目重復立項問題會造成國家資助科技項目的資金浪費,同時損害科研精神,對科技創新造成較大的危害。本研究對大數據環境下的科技項目查重技術進行了研究,提出了自動實現字段權重分配的科技項目查重方法,此類科技項目查重技術的研究,將使大數據技術在科技項目查重中得到更好的利用,輔助科技項目查的重高質高效完成。
猜你喜歡
云南教育·小學教師(2022年4期)2022-05-17 14:46:24
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
甘肅教育(2020年8期)2020-06-11 06:10:02
藝術評論(2020年3期)2020-02-06 06:29:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
新世紀智能(語文備考)(2018年11期)2018-12-29 12:30:58
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2015年11期)2015-02-28 22:01:59
