基于MFCC及其一階差分特征的語音情感識別研究
2019-05-27 01:18:46羅相林秦雪佩賈年
現代計算機 2019年11期
羅相林,秦雪佩,賈年
(西華大學計算機與軟件工程學院,成都610039)
0 引言
隨著計算機科學的發展,計算機的計算能力逐年顯著提升,語音情感識別充分利用現代計算機強大的計算能力,通過計算機識別語音情感信息,是人機交互的重要領域,在醫療、教育都有廣泛的應用,目前很多國家都在進行這方面的研究。語音情感識別主要包括預處理、特征參數提取和情感分類三部分,預處理包括采樣、量化、分幀加窗等操作,特征提取包括著名的MFCC特征提取、基頻、共振峰、短時能量、短時過零率等。對于情感的分類,目前國內外學者普遍采用基本情感、情感二維空間、情感輪三種分類方式[1]。識別方法方面,目前國內外學者和研究機構采用SVM、DNN、HMM、RNN等分類方法。
本文通過提取語音信號的MFCC和其一階特征,對特征進行歸一化和降維后,采用SVM模型對進行訓練,識別語音情感,提升了語音情感的識別率。MFCC特征反映了語音信號的靜態特征,一階差分MFCC特征則反映了語音信號的動態特征,兩種特征結合是本文的一個特色;PCA降維降低了特征的維度,提升了模型的訓練效率;用網格搜索法[2]對模型進行調參,求出最優解,方便實用;十折交叉驗證法選用模型降低了由數據分割帶來的模型評估的誤差,利于模型擇優。
1 語音信號的特征提取
1. 1 MFCC特征提取
研究表明,由于人耳的特殊構造,人耳的濾波作用在1000Hz一下為線性尺度,在1000Hz以上為對數尺度,這使得人耳對于低頻的信號更加靈敏[3];人耳并不能區分所有頻率分量,只有兩個頻率分量相差一定帶寬時,人類才能區分,否則人就會把兩個音調聽成同一個,這稱為屏蔽效應,帶寬稱為臨界帶寬。MFCC在一定程度上模仿了人耳的這一特性,MFCC濾波器組就相當于人耳的濾波器,提取過程如圖1。
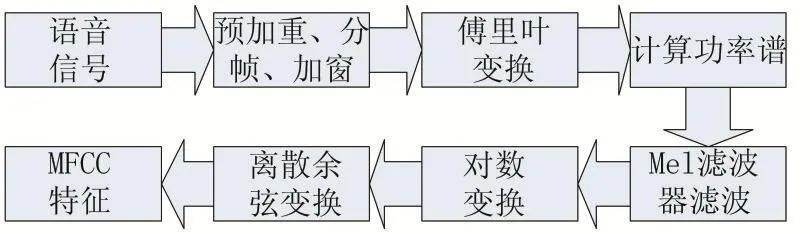
圖1
預加重的作用是放大高頻,平衡頻譜,因為通常高頻與低頻相比具有較小的幅度,也可以改善信噪比,本文使用一階預加重濾波器對信號進行預加重,公式如下:
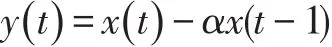
其中α的值一般取0.95或0.97,本文取0.97。
信號預加重之后,需要將信號分成短時幀。這一步驟的基本原理是信號中的頻率隨時間變化,因此大多數情況下,對整個信號進行傅里葉變換是沒有意義的,因為我們會隨著時間的推移而丟失信號的頻率輪廓。為了避免這種情況,我們可以假設在短時間內信號的頻率是靜止的。因此,我們通過在該短時幀上進行傅里葉變換,再通過相鄰幀的連接來獲得信號輪廓的良好近似。語音處理中典型幀大小范圍為20ms至40ms,連續幀之間具有50%(+/-10%)的重疊,本文采用通常語音處理中的設置,幀大小為25ms,幀重疊為15ms。
分幀之后,需要對每一幀信號進行加窗處理。加窗的目的主要有兩個:一是信號使全局更加連續,避免出現吉布斯效應;二是使原本沒有周期的語音信號呈現出周期函數的部分特征。本文采用漢明窗進行加窗,漢明窗的公式如下:
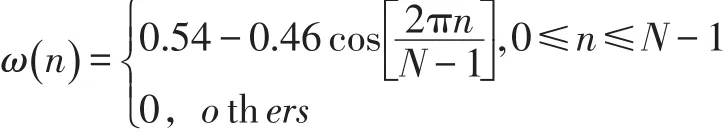
傅里葉變換將信號從時域變換到頻域,得到信號的頻譜特征,傅里葉變換的公式如下:

計算功率譜,即每幀譜線能量,公式如下:

將每幀譜線能量譜通過Mel濾波器組,得到濾波后的能量譜,Mel濾波器公式:
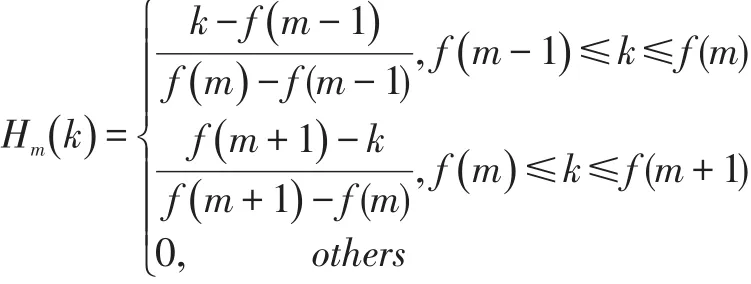
將通過Mel濾波器組的能量取對數,然后進行離散余弦變換就得到MFCC特征。
1. 2 一階MFCC特征提取
MFCC為語音信號的靜態特征,不符合語音動態變化的特征,如果能提取語音的動態特征就更能反映語音的實際特性[4]。對MFCC進行差分運算就得到語音信號的動態特征,即一階MFCC特征。差分運算公式:

其中d(n)表示第n個一階差分,c(n+i)表示第n+i個倒譜系數的階數,k表示差分幀的區間。
2 數據預處理和模型尋優
2. 1 數據歸一化和PCA降維
由于提取到的初始特征在數量級方面相差很大,單位不統一,根據機器學習的相關理論,應該對數據進行歸一化處理,提高機器學習的效果。本文采用數據縮放的形式,經過實驗,將特征縮放到指定的區間,以提升語音情感識別效果。
語音情感識別的結果受特征參數的影響比較大[5],為了提高識別率,一般會提取更多特征,但是維數過多會造成維數災難,導致識別率降低。因此,本文選擇常用的一種降維方法,PCA降維方法對特征進行降維[6]。PCA是一個線性變換,將數據集變換到新的坐標系統中,使得任何數據投影的第一大方差在第一個坐標(稱為第一主成分)上,第二大方差在第二個坐標(第二主成分)上,依次類推。PCA的目標是尋找r(r小于特征向量維數)個新變量,使它們反映事物的主要特征,壓縮原有數據矩陣的規模,將特征向量的維數降低,挑選出最少的維數來概括最重要特征。尋找到的r個新變量是互不相關、正交的,它很大程度上體現了原始特征。
2. 2 支持向量機
本文選擇SVM分類器進行語音情感識別。SVM是一種應用廣泛的機器學習方法,具有如下特點:①非線性映射是SVM方法的理論基礎,SVM利用內積核函數代替向高維空間的非線性映射;②對特征空間劃分的最優超平面是SVM的目標,最大化分類邊際的思想是SVM方法的核心;③支持向量是SVM的訓練結果,在SVM分類決策中起決定作用的是支持向量;④SVM是一種有堅實理論基礎的新穎的小樣本學習方法。它基本上不涉及概率測度及大數定律等,因此不同于現有的統計方法。從本質上看,它避開了從歸納到演繹的傳統過程,實現了高效的從訓練樣本到預報樣本的“轉導推理”,大大簡化了通常的分類和回歸等問題;⑤SVM的最終決策函數只由少數的支持向量所確定,計算的復雜性取決于支持向量的數目,而不是樣本空間的維數,這在某種意義上避免了“維數災難”;⑥少數支持向量決定了最終結果,這不但可以幫助我們抓住關鍵樣本、剔除大量冗余樣本,而且注定了該方法不但算法簡單,而且具有較好的魯棒性。
SVM用于處理多分類問題時,常用的有一對多(one-to-rest)和一對一(one-to-one)兩種策略[7]。根據前期的分析研究,一對一的分類策略更有效,本文采用該策略。核函數是支持向量機的關鍵,目前常用的核函數有線性核函數、多項式核函數、高斯核函數等。根據前期的實驗數據,文中采用效果最好的高斯核函數。如何選擇合適的懲罰因子C和核函數參數g是訓練一個SVM分類器的關鍵問題,本文采取網格搜索法[8]進行參數搜索,用K折交叉驗證法進行評估,選擇出最優模型。
2. 3 K折交叉驗證
本文用十折交叉驗證評估SVM的超參(C和g),進而選擇模型[9]。模型評估的方法是將數據分為訓練集、驗證集、測試集,訓練集用于訓練模型,驗證集用于模型的參數選擇配置,測試集用于評估模型的泛化能力。傳統的模型評估方法只需按比例將原始數據劃分成三部分,不過如果只做一次分割,評估結果對訓練集、驗證集和測試集的樣本數比例,還有分割后數據的分布是否和原始數據集的分布相同等因素比較敏感,不同的劃分會得到不同的最優模型,而且分成三個集合后,用于訓練的數據更少了。
K折交叉驗證是對傳統的模型評估方法的改進。以K取十為例,先將原始數據劃分為訓練集和測試集,再將訓練集劃分為十份互斥的數據,設定模型參數后,每次選取其中九份數據做訓練集訓練模型,另一份數據集作為驗證集評估模型,總共進行十次,求出平均得分,得到模型最終得分。具體過程如圖2所示。
K折交叉驗證減少了原始數據分割后數據的分布對模型評估的影響,增強了模型的泛化能力。
3 實驗與結果分析
3. 1 實驗設計
本文選取德國柏林技術大學錄制的柏林德語情感語料庫作為實驗數據,它共535句語音,由5男5女錄制,它包含生氣(anger)、害怕(fear)、高興(happy)、厭煩(boredom)、悲傷(sad)、平靜(neutral)、厭惡(disgust)7種情感。由于提取特征的單位和數量級不統一,經過實驗,用[-10,10]將特征歸一化效果最好,然后用PCA選擇60個特征向量。
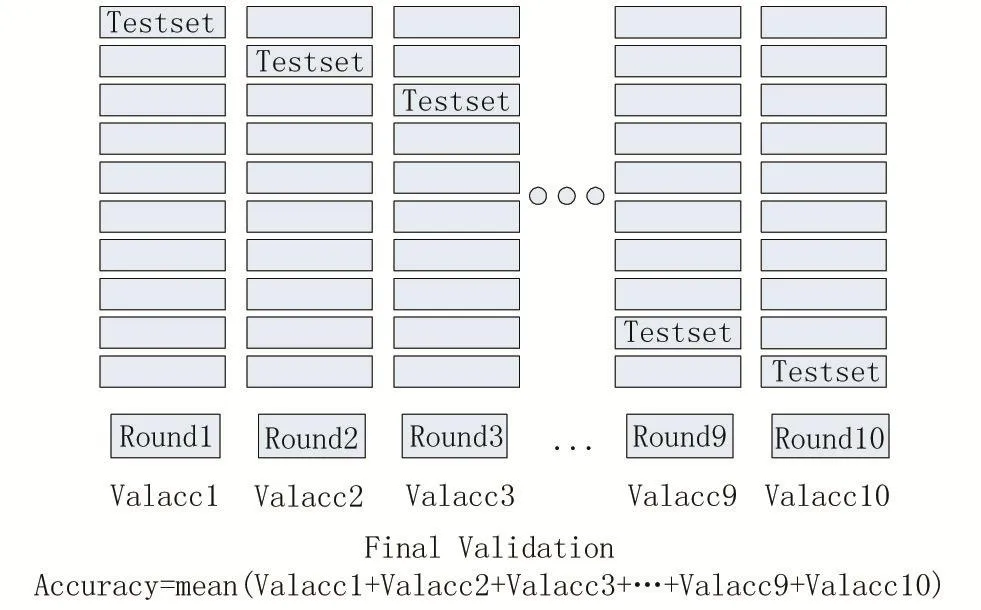
圖2
首先將7類語音情感數據中的每一類隨機抽取80%作為訓練集,余下20%作為測試集,分別提取訓練集和測試集的特征;其次將訓練集隨機劃分成10份用于十折交叉驗證訓練和評估模型,選出最優模型;最后用測試集評估最優模型的性能,得出情感識別結果。本文提取MFCC和MFCC一階差分特征的均值、方差、最大值、最小值共104維特征向量,用數據歸一化和PCA對特征進行預處理,通過網格參數提供SVM的C和gamma值,并用十折交叉驗證法對評估模型,最終選出最優模型,并用測試集測試模型的泛化能力,得出語音情感識別的結果。具體流程如圖3。
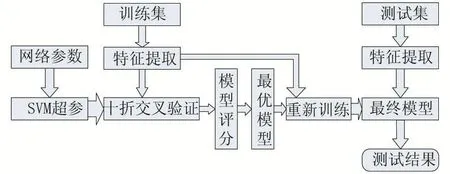
圖3
3. 2 結果分析
運用上述實驗設計流程進行實驗,得到識別的混淆矩陣,結果如表1。
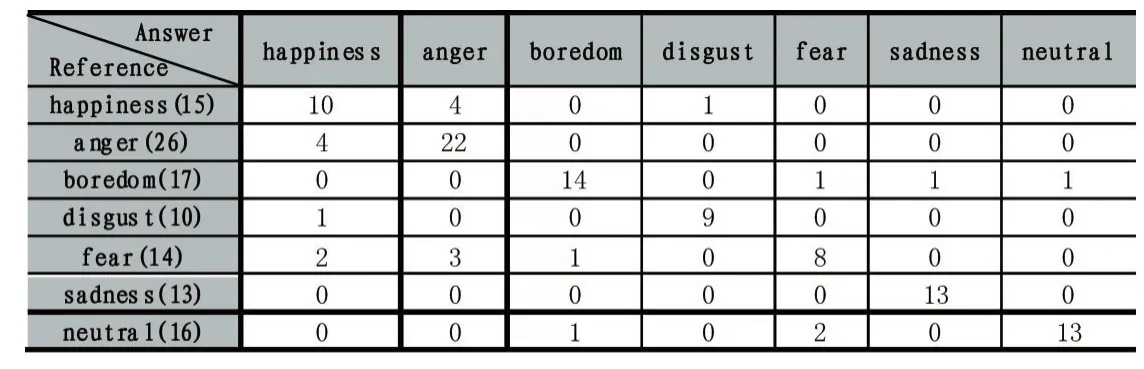
表1
分類結果報告如表2。
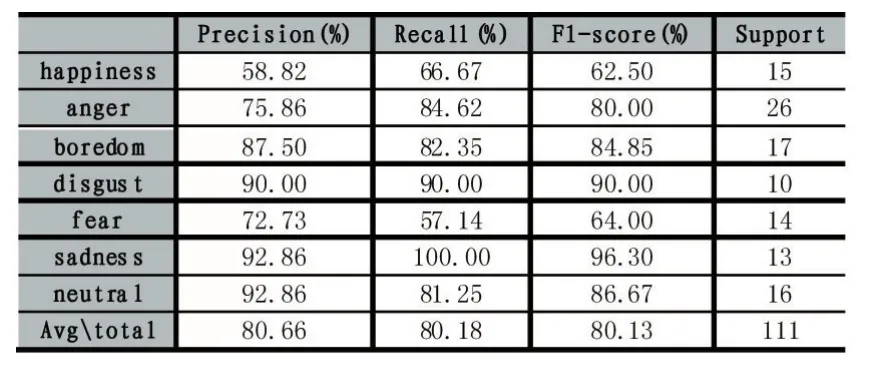
表2
從以上兩張表可以看出:①采用7種情感的平均識別率為80.66%,每種情感的識別率都處于合理范圍;②happiness情感容易被識別成anger情感,導致識別率較低,fear情感容易被識別成anger和happiness情感;③boredom、disgust、sadness、neutral識別率超過80%,其中 disgust、sadness、neutral識別率超過 90%。可見,本文的語音情感識別率較高。
在柏林語音數據集下,將本文實驗結果與相關研究結果進行對比,如表3。
可見,除了文獻[10]之外,其余的識別率均低于本文的語音情感識別率,說明本文的語音識別方法是有效的。文獻[11]提取了語音信號的MEDC特征,本文并沒有提取這種特征,識別率比本文高,也在情理之中;文獻[11]采用DNN的識別率與本文識別率相近;文獻[12]采用DNN+HMM的識別方法識別率比本文低2.74%。綜上,本文的提出語音識別方法具有有效的識別率,且達到該領域的識別水平。
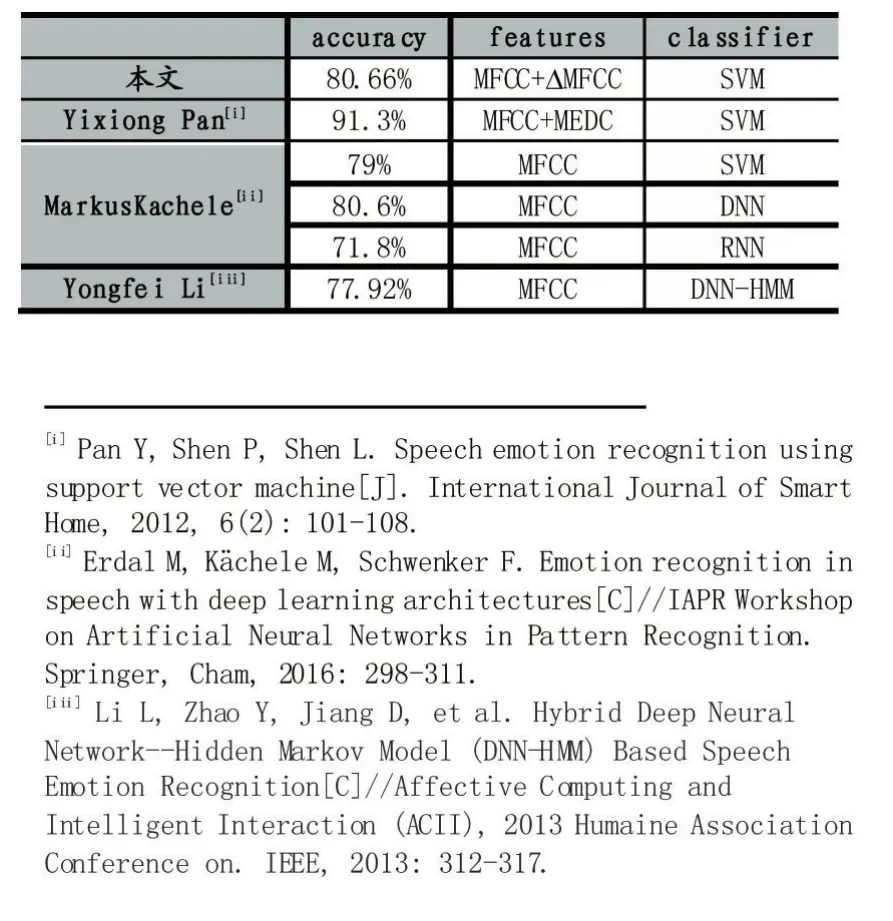
表3
4 結語
針對語音情感識別中特征維數高、識別率低的問題,本文采用PCA降低特征維數,用網格參數搜索結合十折交叉驗證選擇SVM模型。在柏林情感語料庫的實驗結果表明,本文采用的語音情感識別方法是有效的。但是happiness、fear和anger的識別率不高,希望以后進行相關研究,提高語音情感的識別率。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
中國生殖健康(2020年5期)2021-01-18 02:59:48
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
當代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2018年5期)2018-11-06 07:15:40
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
