從去專業化到再專業化:數據新聞對數據科學的應用與趨勢*
2019-05-24 09:25:40閃雪萌
中國出版 2019年9期
關鍵詞:數據庫
□文│張 超 閃雪萌 劉 娟
長久以來新聞業不被視為理想類型的專業,因為記者技能的專業化程度有所欠缺。但由于新聞業對公共服務的承諾和對自主性的要求,又被認為是一個專業。[1]新媒體時代專業新聞生產者的內容生產特權被打破,采編技能被大規模“業余化”了,[2]新聞業面臨“去專業化”的危機,直接蠶食自身合法性。今天公眾對媒體專業性的要求并未降低,而在提高。[3]數據新聞的誕生為提升新聞專業性提供了契機。
數據新聞以數據作為認識現實的“原材料”、以數據科學作為求真的方法論、以數據可視化作為表征現實的手段。數據科學方法論將數據新聞與計算機輔助報道、精確新聞、圖解新聞區分開來。數據科學是在大數據背景下誕生的新興學科,是計算機科學、數學和統計學以及專業知識的交集。[4]
數據新聞正在建構自身專業話語,還未完成專業塑造,如何評價數據新聞的專業性成為新問題。全球數據新聞獎自2012年設立以來代表全球數據新聞實踐的最高水平,國內外對該獎項作品的研究還未深入觸及數據科學方法論。本研究以2013~2018年的獲獎作品為研究對象,管窺當前數據新聞在數據科學上的專業水準和發展趨勢。
一、全球數據新聞獎作品對數據科學的應用
如何從數據科學角度評價全球數據新聞獎作品?本文從數據采集方式、數據體量、數據類型、數據分析方法和數據處理難度五個維度進行分析。[5]
1.數據采集
作為專業的職業應擁有充分的自主性,保證其實現公共利益,形成特定的聲譽。[6]記者在數據采集時對數據科學方法的使用,讓一些重要數據采集的控制權轉移到記者手中,一定程度上提升了新聞生產的專業性和自主性,但這種提升有限。
在可識別的樣本(n=36)中,利用數據科學方法采集數據的樣本有6個,僅占16.7%。如“醫藥幻覺”網站(Medicamentalia.org)用編程語言抓取發展中國家藥品價格數據庫中的數據;美國國家公共電臺的《特朗普和克林頓第一次辯論的事實核查》(Fact Check: Trump and Clinton Debate for the First Time)利用語音實時轉錄文字的技術,用編程方法獲得辯論的原始數據。記者利用數據科學方法獨立采集數據的比例較低,一方面因為大量數據掌握在政府和企業手中,記者可通過多種途徑獲取到;另一方面,一些媒體并未掌握專業的數據采集方法,只能依賴現成數據集。
2.數據體量
大數據時代已經來臨,對數據新聞而言,多大體量的數據才能稱得上“大數據”?路透新聞研究所《媒體大數據》(Big Data for Media)報告認為,大數據是用太字節(TB)及以上的單位衡量的。國際調查記者聯盟的《巴拿馬文件》(The Panama Papers)包含2.6太字節數據、1150萬份資料,可以稱得上大數據新聞。
更多的樣本未提供數據體量的說明,本文借用記錄數評價這一指標。記錄數是一個數據集的行數,達到“萬級”可評價為數據體量較大,達到“百萬級”的可歸為大數據。在可識別的樣本(n=30)中,記錄數達到“千級”的有14個樣本,“萬級”的有8個,“百萬級”的有3個。
如果將記錄數轉換成數據體量,大部分樣本是小數據。置身大數據時代,為何小數據是“主角”?一方面是數據新聞制作周期的制約。基于大數據的數據新聞生產勢必占用更多的新聞采編資源和更長的生產周期,是否值得為大數據新聞投入更多資源需要媒體權衡。另一方面是處理大數據的能力問題。一些媒體“有心”,卻“無力”處理大數據。
3.數據類型
數據類型可分為結構化數據和非結構化數據。結構化數據是存儲在數據庫中具有一定邏輯結構和物理結構的數據,日常新聞處理的數據基本上是結構化數據;非結構化數據是結構化數據以外的數據,它不存儲在數據庫中,而是以各種類型的文本形式存放,[7]如文本、視頻、音頻、網絡日志等數據。
在可識別的樣本(n=33)中,完全使用結構化數據的樣本有16個,完全使用非結構化數據的有9個,結構化數據和非結構化數據結合的樣本有8個(見表1)。
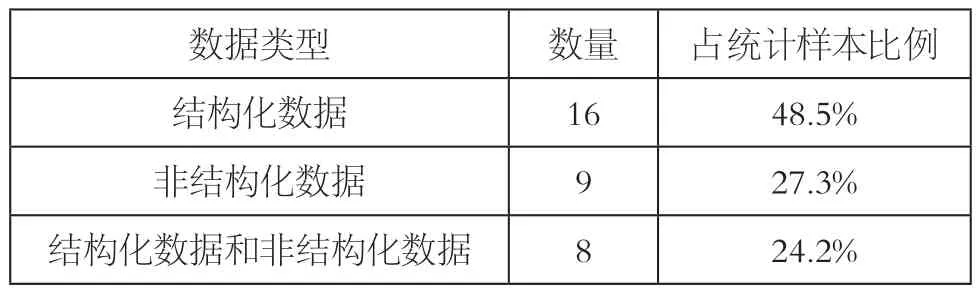
表1 2013~2018年全球數據新聞獎作品數據類型統計
17個樣本包含了非結構化數據,說明數據新聞在處理數據類型上有了很大進步,這是數據新聞業者在數據科學專業技能上的關鍵突破。
4.數據分析方法
數據分析方法有很多種,數據新聞常用的數據分析方法有描述性數據分析、探索性數據分析、數據庫/數據倉庫、機器學習和信息檢索等。
在可識別的樣本(n=31)中,20個樣本包含描述性和探索性數據分析,9個樣本僅有描述性數據分析。個別樣本結合了數據庫與數據倉庫(3個)、機器學習(2個)等數據分析方法(見表2)。
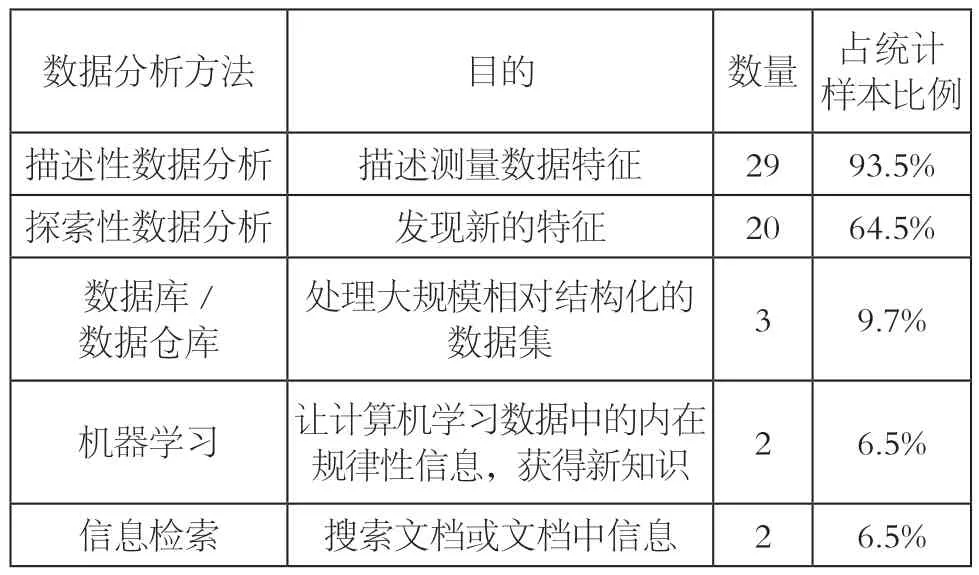
表2 2013~2018年全球數據新聞獎作品數據分析方法統計
現實是復雜的,映射現實的數據也是復雜的,這要求記者在解釋復雜問題時運用多種數據分析方法。加拿大《環球郵報》的《無據可依》(Unfounded)運用“無根據”結案率的均值、極值、分布情況進行了描述性數據分析,還利用相關性檢驗探索了女性警察和“無根據”結案率的相關性。
國際調查記者聯盟的《瑞士泄密》(Swiss Leaks)的原始文件十分龐大,賬戶信息散布在看似毫無關聯的數萬個文件中,傳統的人工挖掘方式已無法分析這些龐雜的非結構化數據,作品用圖形數據庫(Neo4j)處理高度聯系的數據和復雜的問詢,并將這種聯系轉化為圖形節點,探索節點之間的聯系,這是將數據庫與信息檢索相結合的技術。
5.數據處理難度
本文將數據處理難度分為低、中、較高、高四個等級:①直接呈現原數據的評定為“低”;②描述了一維數據的數字特征和分布特征,如均值、中位數、眾數、方差、分布函數等,評定為“中”;③描述了數據的特征,還運用了多元統計分析的研究方法,如相關分析、回歸分析、降維分析、聚類分析或簡單編程,評定為“較高”;④建立了數學模型,進行大數據挖掘或算法創新與改進,評定為“高”。后三個等級可評價為“專業”。
在可識別的樣本(n=34)中,在數據處理方面評價為“低”和達到“專業”水平的各有17個樣本(見表3)。一半多的作品直接呈現了原始數據,進行了簡單的數量、百分比統計。
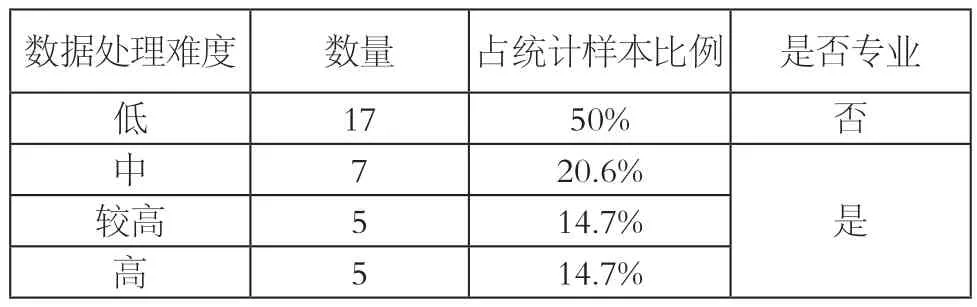
表3 2013~2018年全球數據新聞獎作品數據處理難度統計
也有一些作品在數據處理難度上體現了較高的水準。“嗡嗡喂”(BuzzFeed)的《隱藏的空中偵察機》(Hidden Spyplanes)利用飛行網站的大量飛行跟蹤數據,通過機器學習算法找出疑似聯邦調查局或國土安全部飛機的飛行軌跡。算法先定義了一些飛行特征指標,如轉彎速度、飛行高度和速度等,然后訓練隨機森林算法區分、標記好的普通飛機和偵察機數據,算法自己決定區分指標,用訓練好的隨機森林算法來區分未標記的飛行數據。
《環球郵報》的《快錢》(Easy Money)定義了一個全新的統計指標:國家證券犯罪累犯率。記者通過反復計算、實地調研驗證了該指標的準確性,揭示了該國治理金融市場的問題。
如果給每個等級賦分,評定為“低”得0分,評定為“中”得1分,評定為“較高”得2分,評定為“高”得3分,樣本平均得分僅為0.94分。可見即便是全球數據新聞獎,相當比例的作品在數據處理難度上很低,許多作品的主要精力仍放在了數據結果的呈現上。
二、數據新聞在數據科學領域的應用趨勢
在樣本中,數據新聞作品在數據科學專業性的各個指標上高低不均,總體上看,相當多的作品在數據科學上還有很大的提升空間。隨著智媒時代的到來,數據新聞在數據科學應用方面將呈現以下趨勢。
1.自建數據庫:提供個性化服務,創新盈利模式
在開放數據運動的推動下,記者接觸的免費數據集越來越多,一些媒體具備了自行采集各類數據的能力。無論是作為一種產品形態,還是一種數據科學分析方法,數據庫日益受到媒體重視。全球數據新聞獎也設置了“開放數據獎”鼓勵媒體公開與公共利益密切相關的數據庫。自建數據庫主要有以下兩種方式。
現有數據集的質量提升。媒體將開放數據集整理、清洗后變成數據質量更高的開放數據庫。在各國政府的開放數據集中,很多存在數據質量和格式問題,公眾想獲得高質量的數據并不容易。媒體借助既有的開放數據集進行二次加工,不需要額外付費,既可以節省成本,又有助于提升數據庫的利用率,樹立媒體為公眾服務的品牌形象。
創建“利基”數據庫,即面向特定細分市場的數據庫。媒體依據調查研究的問題,將開放數據、信息公開數據、“泄露”數據、自行采集的數據進行系統整合,創建更具個性特點和用戶體驗的數據庫,可瞄準利基市場,為特定用戶開展深度服務。自建數據庫還有助于媒體積累數據資源,提升數據新聞生產效率。2016年半島電視臺獲“年度最佳突發新聞數據使用獎”的作品《脫軌美鐵列車:死亡曲線上的飛馳》(Derailed Amtrak Train Sped into Deadly Crash Curve)之所以能在短時間內完成,在于記者一年前就積累了相關數據。
自建數據庫通過交互設計、權威數據、與公共利益相關,建立起與用戶的“強關系”,實現社會效益和經濟效益的雙贏。作為數據產品,數據庫有多種盈利模式:①利用數據庫帶來的流量,進行廣告的二次售賣。②提供數據集下載收費服務。③基于數據庫提供面向用戶的針對性服務。
2.擁抱非結構化數據:展現更廣闊的社會現實
全世界數據中80%是非結構化數據,擁抱非結構化數據是大數據時代新聞生產的必然選擇。樣本中包含非結構化數據的作品占50%,未來非結構數據在數據新聞生產中的比重將進一步加大。
數據新聞對非結構化數據的接納有以下原因。
開放數據的局限阻礙數據新聞生產。2016年萬維網基金會發布的《開放數據晴雨表》顯示,在抽查的政府數據集中,只有10%是完全開放的,很多數據集還存在質量問題。非結構化數據比結構化數據更遍在、易得,能為媒體提供更多的數據題材,更好地實現監測社會的功能。
非結構化數據比結構化數據更“誠實”。結構化數據的處理依賴統計學方法,統計學方法注重假設、抽樣,不追求全樣本,在現實表征中存在一定程度的偏差。非結構化數據則包含完整、連續的信息和關鍵細節,在現實表征中更可靠、可信。
媒體數據科學應用能力的提升。現在國內外一些主流媒體或雇傭程序員、或通過合作方式,提升自身對非結構化數據的處理能力。非結構化數據挖掘與處理能力將是未來衡量媒體數據新聞生產能力的重要標準,帶來的是數據新聞生產的“破壞式創新”。誰有能力處理非結構化數據,誰就能夠在大數據時代占據主動權。
3.配置機器學習:提升大數據處理與洞察能力
數據新聞生產智能化也是未來重要的發展趨勢,機器學習有望在未來幾年內成為記者處理大規模數據集的“標配”技術。
機器學習主要有三類:監督學習、無監督學習和強化學習。監督學習又稱有導師學習,指在訓練期間有一個外部“老師”告訴網絡每個輸入向量的正確的輸出向量,讓程序“照章辦事”。無監督學習又稱無導師學習,指網絡只面向外界,在沒有任何指導的情形下構建其內部表征,[8]讓程序“自我發現”,如尋找聚類和異常檢測。強化學習是以環境反饋(獎/懲信號)作為輸入,以統計和動態規劃(Dynamic Programming)技術為指導的一種學習方法。[9]通俗地說就是基于環境采取何種行動以獲取最大預期收益。
基于以上分類,機器學習在數據新聞的應用有三個方面。
分類和預測。監督學習能幫助記者快速識別和獲取所需的數據。這種方法特別適用于處理批量、有規律的數據。記者還可利用監督學習中的回歸分析對數據進行預測。《亞特蘭大憲法報》的《醫生與性侵》(Doctors & Sex Abuse)在數據采集環節先由記者用50個爬蟲程序從美國醫療系統中爬取10萬多份醫生紀律處分文件,用機器學習清理分析文件,檢索涉及性侵行為的關鍵詞。[10]監督學習的優劣很大程度上取決于算法設計和“訓練”數據的可靠性,否則數據結果會出錯。
洞察。面對海量數據,記者的認知和經驗是有限的,單純依靠記者設計的監督學習算法可能會“撿了芝麻丟了西瓜”。無監督學習能自主尋找海量數據間的關聯,識別數據中“隱藏的結構”。美聯社記者運用無監督學習從14萬條人工輸入的案件記錄中找到槍支濫用的典型案件,推算出如果案件涉及孩子或警察,犯罪嫌疑人故意開槍的概率等。[11]
決策。強化學習可幫助記者在具體環境下決策,這一學習方法在新聞生產中還較為少見。著名的“阿爾法狗”使用的就是強化學習。《紐約時報》推出的“石頭、剪刀、布”(Rock-Paper-Scissors)互動頁面,系統利用一個人出手勢的傾向和模式來獲得優于對手的優勢。[12]在新聞推送中,一些媒體會利用強化學習確定最有效的頭條新聞和內容推送方案。
三、結語
在大數據遍在、人工智能高速發展的當下,數據新聞業需要繼續提升數據科學專業水準,增強自身的專業性和不可替代性,才能實現專業塑造,鞏固新聞業的合法地位,滿足公眾對新聞業的期待。
注釋:
[1][6]李艷紅.重塑專業還是遠離專業?——從認知維度解析網絡新聞業的職業模式[J].新聞記者,2012(12)
[2]周紅豐,吳曉平.重思新聞業危機:文化的力量——杰弗里·亞歷山大教授的文化社會學反思[J].新聞記者,2015(3)
[3]彭蘭.更好的新聞業,還是更壞的新聞業?——人工智能時代傳媒業的新挑戰[J].中國出版,2017(24)
[4]葉鷹,馬費成.數據科學興起及其與信息科學的關聯[J].情報學報,2015(6)
[5]本研究對樣本的選取方式是在剔除鏈接失效的獲獎作品后,依據前期設計的分析類目辨識剩余樣本。由于不是所有的樣本提供原始數據下載或制作方法介紹,有些類目無法辨識,所以不同類目的可識別樣本數不同。
[7]張枝令.結構化數據及非結構化數據的分類方法[J].寧德師專學報(自然科學版),2017(4)
[8]楊盛春,賈林祥.神經網絡內監督學習和無監督學習之比較[J].徐州建筑職業技術學院學報,2006(3)
[9]王雪松,程玉虎.機器學習理論、方法及應用[M].北京:科學出版社,2009:5
[10]調查記者編輯協會.2016美國數據新聞獎揭曉,深度報道再添范例[EB/OL].https://cn.gijn.org/2017/01/25/2016
[11]余婷,陳實.人工智能在美國新聞業的應用及影響[J].新聞記者,2018(4)
[12]Bradshaw.Data journalism’s AI opportunity:the 3 different types of machine learning & how they have already been used[EB/OL].https://onlinejournalismblog.com/2017/12/14/data-journalisms-ai-opportunity-the-3-different-types-of-machine-learning-how-they-havealready-been-used
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
