基于Bi-RNN 中文語音識別的實驗設計
2019-05-17 07:42:36黃睿
現代計算機 2019年10期
黃睿
(廣東第二師范學院計算機科學系,廣州 510303)
0 引言
如今,人工智能、教育大數據的應用,推動著計算機等學科朝著智能化的方向發展。以深度學習、機器學習為代表的人工智能模型,已獲國內外學者的廣泛關注[1]。而深度學習等軟件平臺的開源,將促進學生對人工智能課程實踐開發興趣,進一步推動實驗教學水平的提高。目前,深度學習等課程的實驗開發,在本科教學中涉及較少,為促使學生對該類課程有更深入的理解,本文基于谷歌TensorFlow 人工智能開源平臺,結合Bi-RNN 和CTC 學習模型,最終完成中文語音識別的實驗設計。
1 TensorFlow
1.1 平臺介紹
Google 于2015 年開源了人工智能平臺TensorFlow[2],該平臺包含開源的軟件庫。其中,Tensor 表示為數據的張量,Flow 表示為數據的流圖。通過提供常用的深度學習框架進行人工智能的開發,以及跨平臺系統的應用。同時,該平臺也支持基于分布式的部署和應用。
1.2 架構
TensorFlow 是基于數據流圖運算的開發平臺,包含多種支持數值運算的軟件開源庫,以及短期記憶網絡、循環神經網絡和卷積神經網絡等網絡模型[3-5]。該模型常運用于機器學習和深度學習的開發,是較為核心的人工智能算法,同時也推動著人工智能領域的新發展,其基本架構如圖1 所示。

圖1 TensorFlow系統架構
前端:支持基于C、C++、Python 等高級編程語言,通過API 函數進行模型調用。
后端:主要用于提供支持前端的運行環境。
2 MFCC
梅爾頻率倒譜系數是基于人耳聽覺特性,將音頻數據由時域向頻域轉變的一種方法,它與頻率成非線性對應關系,廣泛應用于語音識別領域。
2.1 梅爾頻率
一段連續的音頻數據可以分解成幀,而每一幀數據通過快速傅里葉變換(FFT)可以計算出對應的頻譜,該頻譜反映的是信號頻率與能量的關系,如線性振幅譜、對數振幅譜等。其中,對數振幅譜是對各譜線的振幅進行對數運算,主要用于分析低振幅噪聲中的周期信號,任意頻率f 到梅爾頻率尺度的轉換由式(1)表示。

式中,頻率f 的單位為Hz。其中,臨界頻率帶寬增長與Mel 頻率一致。當Mel 頻率刻度為均勻分布時,赫茲之間的距離將隨頻率的增加而增大。將語音頻率劃分為一系列的三角濾波序列,即Mel 濾波器,如圖2所示。
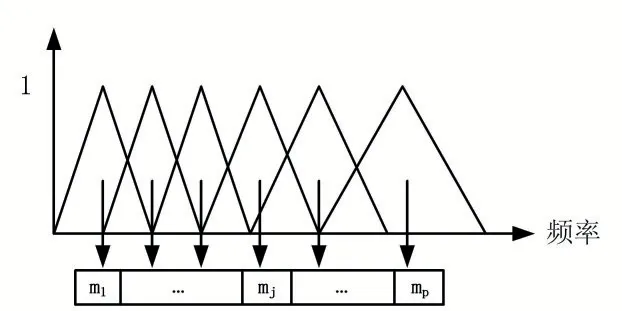
圖2 Mel濾波器
如圖2 可知,Mel 濾波器在低頻段分辨率高,類似于人耳的聽覺特性。因此,梅爾頻率首先通過對時域信號進行快速傅里葉變換成頻域,其次,利用梅爾頻率刻度的濾波器進行頻域信號切分,最后計算出每個頻率段對應的數值。
2.2 倒譜分析
一段連續的音頻數據可以分解成幀,而每一幀數據通過快速傅里葉變換(FFT)可以計算出對應的頻譜,該頻譜倒譜分析主要進行信號的疊加和分解,如信號的卷積轉化為信號的疊加。設頻率譜X(k),時域信號x(n),滿足式(2)。

將頻域 X(k)進行拆分,如式(3)所示。

此時,對應的時域信號分別為 h(n)和 e(n),則如式(4)所示。

分別對頻域進行對數運算和反傅里葉變換可得(5-6)式,進行時域疊加為式(7)。

式中,x′(n)為倒譜,h′(n)為倒譜系數。通過上式,將卷積時域信號轉換成線性疊加關系。
3 Bi-RNN
如果能結合上下文的信息關系,進行未知信息的判斷,將極大提升在多序列標注方法中的準確率。雙向循環神經網絡主要運用于連續數據的處理,該模型分別進行正向規律和反向規律的學習,從而達到比傳統模型更優的擬合效果。
3.1 模型介紹
RNN 模型容易忽略對未知信息的上下文關系,而Bi-RNN 模型的輸入層可以結合已知的上下文關系進行未知的預測,其結構圖如圖3 所示。
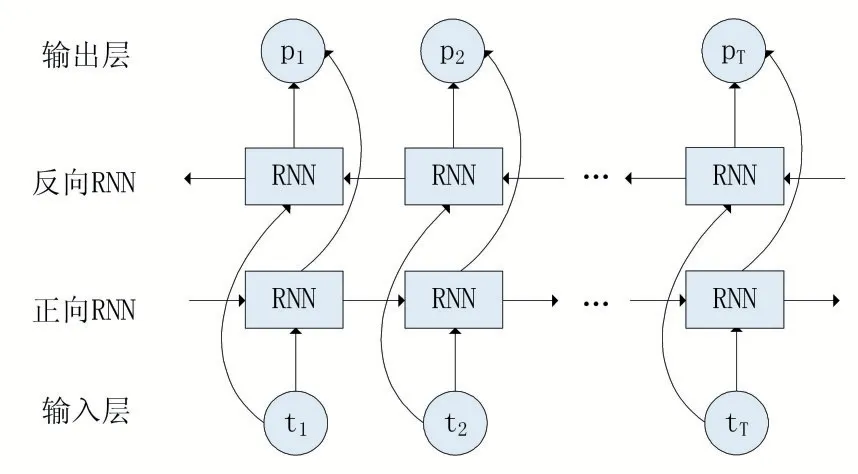
圖3 Bi-RNN模型
由圖3 可知,該模型由輸入層、正向循環神經網絡、反向循環神經網絡和輸出層組成。
3.2 模型實現
雙向循環神經網絡的正向推算和單循環神經網絡模型一樣,需要完成全部的輸入序列計算時,模型的輸出才被更新。而反向推算則需要先完成輸出層計算后,再計算后的權值返回給兩個隱含層。實驗偽代碼如圖4 所示。

圖4 Bi-RNN模型實現
4 實驗步驟
基于TensorFlow 平臺,使用Thchs-30 中文語音數據集,結合公式(7)的梅爾頻率倒譜系數,進行Bi-RNN、CTC 模型的搭建,并最終完成中文語音的識別。
4.1 Thhcchhss--3300數據集
該數據集是由清華大學建立的語音樣本,包含訓練數據集、開發數據集和測試數據集。音頻是通過16KHz 的采樣頻率和16bit 的量化位數進錄制,具體內容如表1 所示。
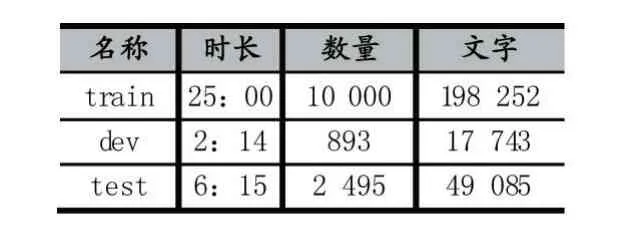
表1 Thchs-30 數據集
如表1 可知,訓練數據集總時長25 小時,包含10000 條句子。開發數據集總時長2:14,包含893 條句子。測試數據集總時長6:15,包含2495 條句子。
4.2 CCTTCC
聯結主義時間分類用于Bi-RNN 的頂層連接,使通過每一幀的輸入序列都能夠輸出對應的標簽(含空白標簽)。在語音識別過程中,該方法可以將音頻停頓、噪點等內容歸納空白標簽,最后使預測輸出的標簽值完成時間序列上的對齊。
為了方便計算出模型的識別率,需要將預測輸出的空標簽進行剔除,形成類似于原始標簽的輸入格式。CTC decoder 函數用于預測結果的加工,完成與標準標簽的損失loss 計算,參數如表2 所示。

表2 CTC decoder 函數
4.3 實驗驗證
(1)模型庫導入。分別導入 numpy、mfcc、wav、os、time、tensorflow、ctc 等庫文件。
(2)導入數據集。獲取數據集內的所有音頻文件和對應的翻譯內容。
(3)模型初始化。完成參數的初始化和Session 的建立。
(4)模型建立。完成 MFCC、Bi-RNN、CTC 等模型架構。
(5)模型保存。對節點權重、偏置等參數進行存儲。
(6)模型驗證。對訓練的模型完成語音識別驗證,部分音頻識別效果如圖5 所示。

圖5 部分音頻識別效果
由圖5 可知,基于Bi-RNN 的中文語音識別模型建立了2666 個漢字表,完成了對單音節詞、雙音節詞和上下文關系的語音識別。
5 結語
該文基于TensorFlow 開發平臺,建立中文語音MFCC 模型,結合Bi-RNN 和CTC 網絡模型,對Thchs-30 中文語音數據集進行深度學習,并結合訓練模型進行語音識別的驗證,最終完成了中文語音識別的實驗設計。該模型的實現對人工智能中文語音識別,在本科實驗教學中具體重要的參考意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
西安航空學院學報(2022年2期)2022-07-04 07:45:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
光學精密工程(2016年6期)2016-11-07 09:07:19
南風窗(2016年19期)2016-09-21 16:51:29
南風窗(2016年19期)2016-09-21 04:56:22
