新聞App用戶行為分析的實現
2019-04-29 06:06:20趙強彭瑋
中國傳媒科技 2019年3期
文/趙強 彭瑋
1.用戶行為分析意義
用戶行為,簡單來說就是用戶在網站或App上進行操作而產生的一系列行為。
在獲取網站或者App等平臺用戶訪問基本數據后,對相關數據進行統計分析,從中發現用戶的行為習慣和潛在需求,有針對地解決業務相關問題、提高用戶體驗,并為決策提供依據的過程我們稱之為用戶行為分析。
那么,為什么要進行用戶行為分析?截至2018年12月底,我國網站數量為523萬個,App在架數量為449萬款,每個領域都擁有成百上千的網站和移動App產品,競爭異常激烈。在這種環境下,如果企業能做好精細化的用戶行為分析、找準問題所在,并有效提出改進方向,既能避免資源浪費,又有助于優化產品質量,提升公司競爭力。
用戶行為分析通常應用于以下場景:
(1)運營分析,用戶來源渠道統計,有助于判斷哪個渠道有利于拉攏新用戶。
(2)產品改版分析,通過AB測試或其他方法來分析不同App版本下的用戶行為,以此來判斷哪個版本會受用戶喜愛,最終上線哪個版本。
(3)預測分析,合理構建算法模型,通過訓練模型、驗證模型,最終使用模型對用戶關鍵行為進行預測,提前洞察可能出現流失的環節,提早干預,從而降低流失率。
(4)采用基于用戶的協同過濾算法進行產品或內容推薦,即為A用戶推薦相似用戶B用戶感興趣的產品或者內容。用戶畫像構建是前提,用戶行為越多,推薦越精準,用戶的使用率和使用時長也會優化。
2.新聞App用戶行為分析
據2018年2月底發布的《第43次中國互聯網絡發展狀況統計報告》顯示,網絡新聞占據中國網民各類手機應用的前三位,截至2018年12月底,手機網絡新聞用戶達到6.53億,占手機網民的79.9%。由此可見,通過移動設備獲取新聞資訊已經成為非常重要的渠道。
新聞媒體,從紙媒到門戶再到移動端。傳統媒體多是以文字和圖片呈現,而新媒體不僅可以通過文字、圖片,還可以通過圖集、視頻等多元化方式展現新聞內容,對用戶的沖擊力更大、更直觀。在新聞內容傳播的同時,用戶還可以進行評論、點贊、轉發,增加了互動社交性也擴大了傳播性。新媒體的時效性、傳播迅速也是傳統媒體遠遠比不上的。當用戶不僅僅是看新聞而是使用一個新聞資訊產品時,我們要在考慮滿足用戶對新聞內容需求的同時也要考慮到用戶的體驗。為了更好地了解我們新聞App產品的使用情況和不足,本文將就新聞類App的用戶行為分析技術做些分析和總結。
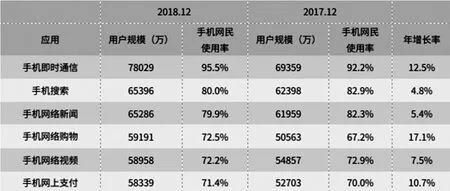
圖1 手機網民各類手機互聯網應用使用率圖
3.用戶行為數據采集
用戶行為數據的采集方式直接決定了數據源的質量,是用戶行為數據分析的基礎。數據的采集通常采用“埋點”方式。埋點又可分為客戶端埋點(前端埋點)和服務器埋點(后端埋點)。
3.1 客戶端埋點
客戶端埋點還可分為代碼埋點和可視化埋點。
3.1.1 代碼埋點
前端的代碼埋點,顧名思義是在產品開發階段,依據PM要求的數據需求文檔,前端開發人員在每個需要采集的數據點寫入代碼。在用戶每次前端操作時能夠觸發埋點上傳數據。
3.1.2 可視化埋點
開發加入“無埋點”的采集代碼,能夠對網頁或者App上所有的可交互事件元素進行解析并監測,當有用戶操作行為(交互事件)發生時,即對此事件進行采集、上報。無埋點并不是不用寫入任何代碼,而是通過代碼將所有事件元素解析后,以可視化的方式呈現,讓PM、運營經理等可以根據需要自行手動選取、標定。為了與開發逐一進行代碼寫入的方式進行區分,被稱作可視化埋點。可視化埋點通常通過第三方工具實現。
3.2 服務器端埋點
服務器端埋點也成為后端埋點,指的是開發在服務器端寫入代碼,采集了前后端的交互事件數據以及存儲與業務服務器中的業務數據。
三種方式對比如下表1所示:
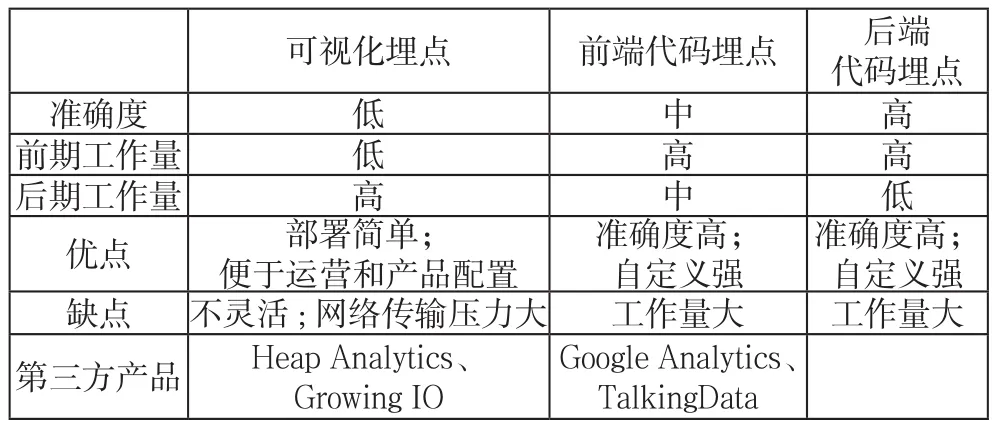
表1 三種埋點方式對比表
4.分析數據
4.1 分析指標
行為數據分析,通常要靠指標分析結果,選取合適的指標,才能有效判斷用戶的使用情況和App的問題所在。下面介紹幾種常用的指標。
4.1.1 新增用戶
新增用戶指的是App被下載安裝后第一次啟動App的用戶,用于衡量推廣的效果。通常按照時間和渠道來源分類。
4.1.2 活躍用戶
活躍用戶指的是在一定統計周期內打開App的用戶數,一般用來衡量App的運營現狀。
4.1.3 用戶留存率
用戶留存率是指在某一個統計時段的新增用戶數中經過了一段時間后仍打開這個App的用戶比例,包括次日留存、7日留存(如今天新增用戶數在第7日再次打開App的比例,14日和30日留存以此類推)、14日留存、30日留存。這個指標是驗證你的App對用戶是否具有吸引力。
4.1.4 啟動次數
統計某一時段用戶打開App的次數。
4.1.5 使用時長
使用時長是指在統計周期內所有用戶從打開App到關閉App的總時長。這個指標考核的是你的App用戶粘性高不高,也反映了App的產品質量高低,使用時長一般會結合啟動次數一起分析。
4.1.6 用戶畫像分析
有了用戶數據,再做用戶畫像分析會更加容易。用戶畫像是對人口屬性的特征分析、用興趣分析、用戶行為分析等。用戶畫像可以幫助App逐漸實現精準化營銷,直接進行App與指定用戶之間的點對點交互。
4.2 分析工具使用
用戶行為數據分析工具通常有以下幾種:
4.2.1 腳本統計
Python、R語言是常用的數據分析語言,優點是成本不會太高,缺點是開發周期長、學習成本高,而且運行效率可能不高。
4.2.2 第三方統計
Talking Data、Growing IO、Google Analytics等工具,都可以用于數據分析,優點是方便快捷,缺點是成本會比較高。
4.2.3 日志分析工具
日志分析工具,如splunk、ELK,可以分析各種數據,而且有統計功能,優點是可以更靈活地運用于自身的業務。
5.實現方法
本文實現了新聞App的用戶行為分析,通過前端埋點方式采集客戶端用戶行為數據,將數據傳入后端,后端將行為數據放入隊列,splunk通過應用接收隊列數據后定時進行分析,并將統計結果放回隊列中,程序取出隊列數據放入MongoDB數據庫,最終頁面展示在業務系統中,供業務人員使用。流程如下圖2所示:
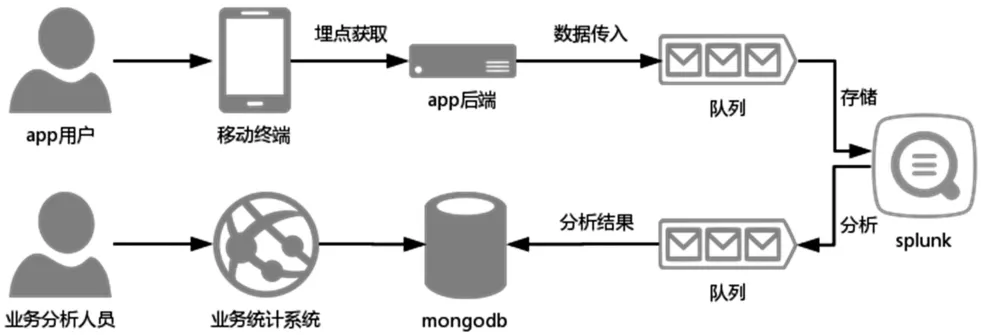
圖2 App用戶行為分析流程
5.1 前端埋點
獲取用戶行為數據采用前端埋點的方式,根據分析需求,規劃埋點位置,定義埋點字段,可獲取真實的用戶行為數據,埋點上傳字段如下表2所示:
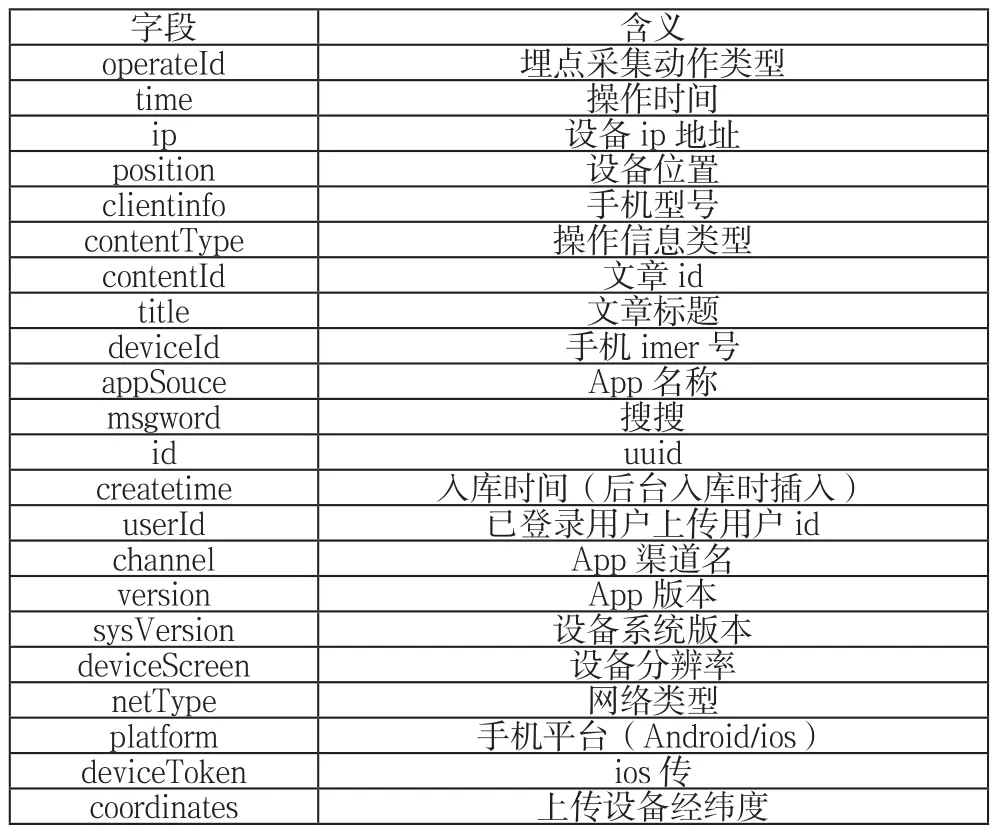
表2 前端埋點字段
表3為埋點采集動作類型(字段:operateId)。
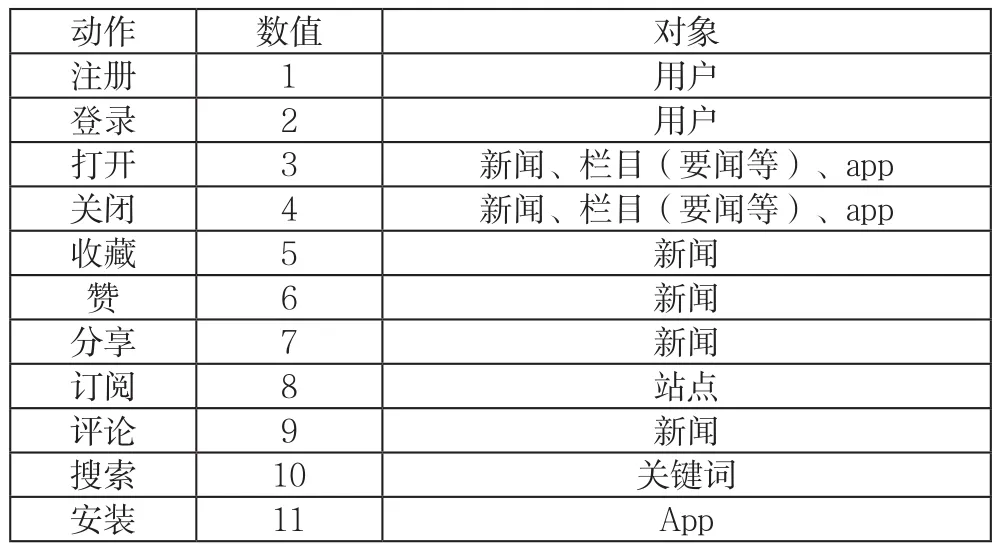
表3 埋點采集動作類型
表4為操作信息類型(字段:contentType)。

表4 操作信息類型
5.2 數據可靠傳輸機制
由于用戶行為數據并發量大且頻率高,因此,我們需要采取合適的方式保證數據的可靠傳輸并且減少對后端的壓力。這里我們采用消息隊列方式進行數據傳輸,消息隊列指的是在消息傳輸過程中保存消息的容器,埋點獲取的用戶行為信息,通過App后端傳入隊列rabbitmq中,采用消息隊列臨時存儲數據,有以下好處:
5.2.1 異步處理,減少請求響應時間
一次用戶行為, App前端獲取埋點數據后會向后端進行請求,后端接收數據后將其存入預先規定好的存儲設備中。然而,這樣App后端就會承受較大壓力,一是前端頻繁的請求,二是存儲數據請求響應的過程。使用隊列方式,可以減少請求響應時間,將數據直接放入隊列中,然后讓消費者再去存儲數據,異步處理,減輕了后端壓力。
5.2.2 應用解耦,不影響App的正常運行
當App后端要去存儲用戶行為數據時,如果存儲設備出現無法訪問等問題,那么App的正常運行可能就會受到影響。這時如果中間加入隊列方式,App后端將數據傳入隊列,就不會影響到App,數據只會堆積到隊列中,但也能確保用戶行為數據的完整性。
綜上,我們采用了隊列方式存放及管理埋點數據,以降低前端數據采集與后端數據處理系統之間的耦合性,提升系統運行效率。
5.3 splunk應用接收mq數據
隊列中的用戶行為數據需要由消費者取走,通常可以用程序方式,消費隊列數據將其放入數據庫中,再用腳本對數據進行分析。然而,我們會面臨如下問題:首先原始的用戶行為數據數據量非常龐大,普通數據庫不適宜存儲大數據,二是如果用腳本操作數據庫,數據庫會承受較大壓力,分析數據的速度也會受到影響。這里我們選擇采用splunk來接收存儲數據。
Splunk是一個典型的大數據處理工具,面向機器數據的全文搜索引擎,是一個一體化的平臺:數據采集-存儲-分析-可視化。Splunk的應用AMQP Messaging經過配置可直接接收隊列數據,存于splunk中,splunk的專用搜索語言SPL(searchprocessinglanguage)語法簡單,類似sql,可以直接進行分析,效率高速度快。與splunk類似的工具還有ELK,ELK是ElasticSearch,Logstash,Kibana的縮寫,分別提供搜索,數據接入和可視化功能,ElasticSearch是一個基于Lucene的開源搜索服務。使用splunk有如下優勢:
(1)數據導入簡單,splunk提供各種應用可以直接接收不同數據,適配性強,而ELK需要filebeats或者logstash接收,接收后再傳入ES,配置過程較為繁瑣。如圖3所示,splunk可以通過應用接收MySQL數據、Citrixnetscaler數據等等,經過配置即可導入。其中amqp_ta即為接收隊列數據的應用,部分配置如圖4所示。圖5為導入的用戶行為數據。
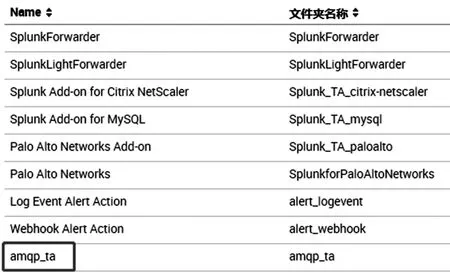
圖3 splunk安裝應用圖

圖4 splunk配置隊列數據導入
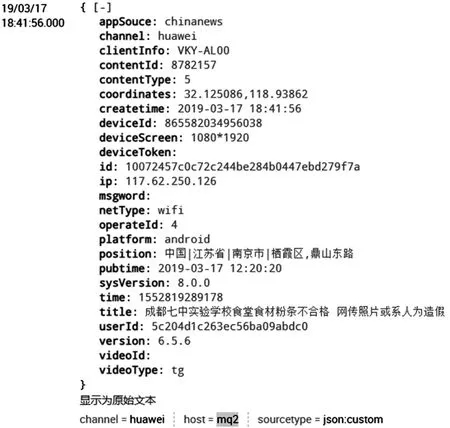
圖5 用戶行為數據事件
導入elasticsearch的數據要通過logstash處理為符合要求的數據格式,通過配置logstash/config/logstash.conf文件中input、filter、output模塊,如下圖6配置input模塊和圖7配置output模塊,最終導入elasticsearch,圖8即為kibana查看導入es的json格式數據。
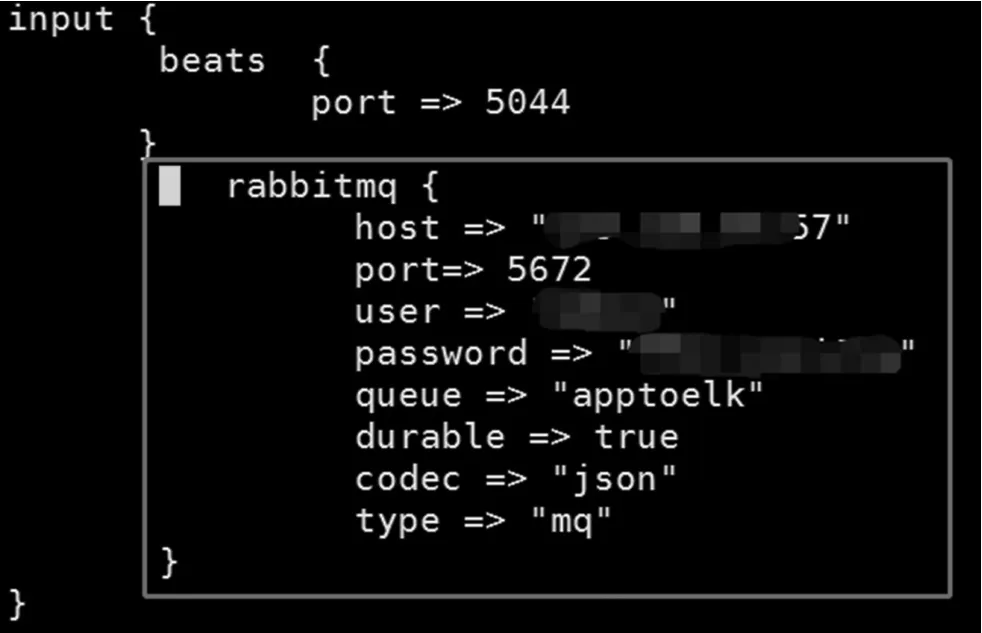
圖6 logstash配置input模塊

圖7 logstash配置output模塊

圖8 導入elasticsearch后kibana可視化圖
(2)字段識別容易,splunk支持自動抽取字段,搜索時也會動態抽取新的字段,而這是elastic不支持的。
(3)數據分析和處理上,ElasticSearch使用Search API來實現,而splunk提供較強大的SPL,語法簡潔,非常易用,以查看某天的新聞閱讀量排行為例,splunk的SPL語句如下:
host=mq2
| search appSouce=chinanews operateId=3 contentType=3
| stats count as pv by contentId | sort -pv
Python調用ES的腳本如下圖9所示,比SPL略復雜,如果需要更復雜的計算,更會凸顯SPL的優勢。

圖9 Python調用ES
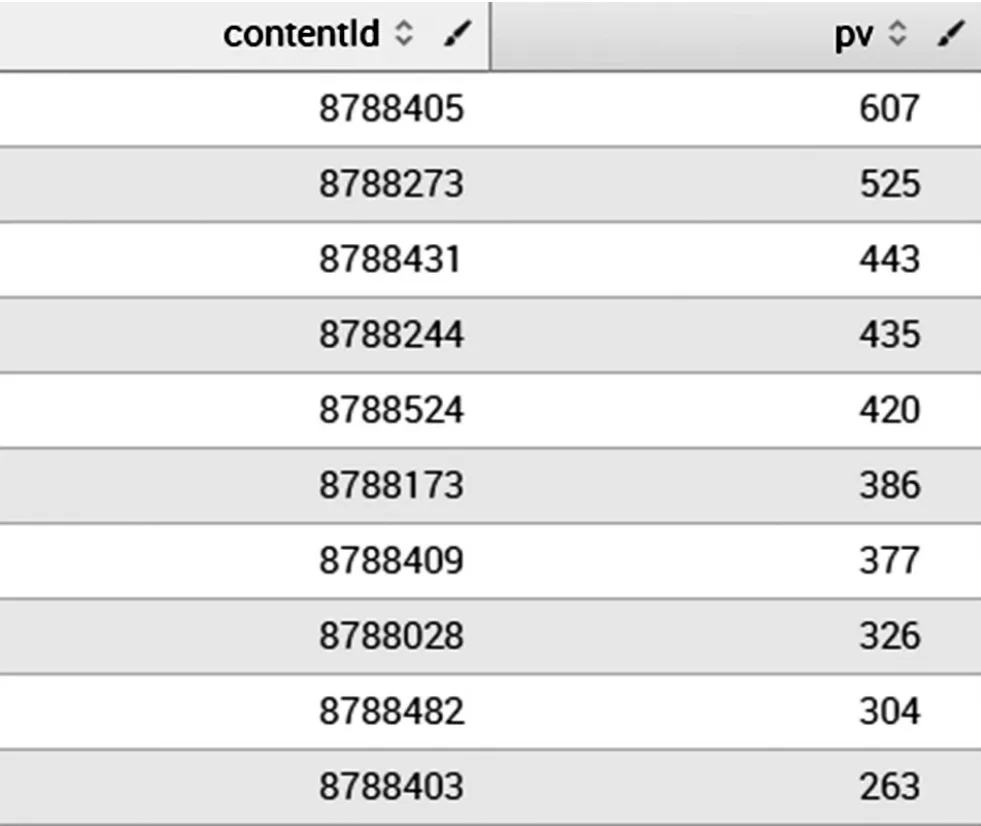
圖10 splunk分析結果圖
通過圖10splunk結果和圖11python調用ES結果前十名對比,可以看出,分析結果稍有偏差,從kibana查看訪問量最高的contentId8788405如圖12所示,可以看出結果應該和splunk統計的相同均為607才對,但是聚合運算過后,結果就不準確了。查看ES官方文檔可以了解到api提供的聚合運算確實存在一定誤差。因此語法簡單易懂,計算準確的splunk就更有優勢了。
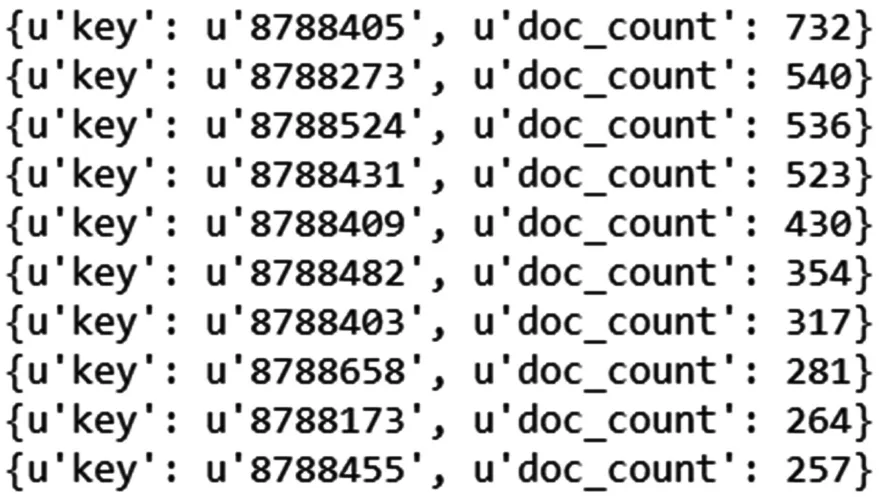
圖11 Python調用ES分析結果圖

圖12 kibana查看contentId8788405訪問量
(4)可視化方面,ELK用的是kibana,splunk直接在平臺上集成了非常方便的數據可視化和儀表盤功能,通過簡單配置就可以進行可視化分析。
5.4 splunk定時統計輸出
Splunk的告警功能能夠滿足對數據進行定時統計分析的需求。如下圖13所示,每天0點執行SPL語句,語句實現了統計昨日訪問量前100名的正文稿件,結果數量大于0時,觸發執行Python腳本mq.py,Python腳本實現將統計結果處理后放到隊列。

圖13 splunk定時統計分析
5.5 頁面展示
Java程序取上一步隊列里的結果,放入mongodb數據庫中。業務統計系統將結果展示在頁面中,某天的正文訪問量排行部分內容統計如下圖14所示。
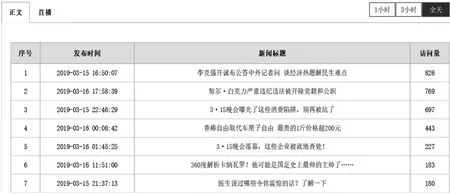
圖14 業務統計系統部分統計結果
結語
綜上,splunk為用戶提供了一個存儲和處理數據的平臺,以最簡單的方式將數據接入平臺,最快的速度計算數據,讓業務人員根據自身需求,利用平臺上的數據解決自己實際業務中的問題。這樣的方式可以在更多的行業和領域進行復制。將splunk應用于新聞App用戶行為分析的實現,幫助我們很好地貼合實際業務進行分析,更深層次認識產品現狀,對App的運營開發、改善優化具有指導意義。
猜你喜歡
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
電子制作(2018年18期)2018-11-14 01:48:24
商用汽車(2016年11期)2016-12-19 01:20:16
山東工業技術(2016年15期)2016-12-01 05:31:22
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
