基于增強二部圖網絡結構的推薦算法①
2019-04-29 08:58:50張岐山
計算機系統應用 2019年4期
張岐山,文 闖
(福州大學 經濟與管理學院,福州 350108)
引言
人工智能時代背景下產生了許多信息過載[1]問題,協同過濾算法是當今電子商務以及各種個性化推薦中應用最廣泛的推薦技術,協同過濾算法存在冷啟動問題,同時算法存在需要獲取大量用戶歷史數據,存在稀疏性等問題.為解決以上問題,國內外許多專家學者提出并完善了基于信任的推薦系統[2],
Guo[3]根據信任的來源將信任分為顯性信任(Explicit Trust 和隱性信任(Implicit Trust),顯性信任是指用戶網絡之中主體之間的直接交互,主動表達的信任關系,隱性信任是指根據用戶網絡中主體之間的直接交互關系挖掘出信任關系,根據用戶的某些行為(如評分)來推測用戶之間的信任關系,顯性信任具有很強可靠性和準確性,而隱性信任更好的區分信任度,能顯著提高覆蓋率,緩解冷啟動問題.Massa 等人[4,5]提出一種使用顯示信任的推薦系統,用信任權重代替傳統推薦系統的相似度進行推薦,相比傳統算法,提高了精度,增加了覆蓋范圍,可預測的評分總數,同時也能規避惡意用戶虛假評分降低推薦質量的隱患.Jamali[6]也考慮了信任問題,采取隨機游走的方法利用顯性信息,在用戶網絡中隨機選取信任鄰居,把用戶看成網絡中的節點,連接的邊即為信任關系,其強度代表了兩個用戶間信任度.文獻[7]引入了全局變量,融合用戶間局部信任度和全局信任度,從海量用戶歷史數據中,挖掘出用戶潛在的信任關系,緩解了數據的稀疏性問題,提高了推薦的準確性.Ray 等[8]設定了相似性閾值,提出了當用戶間相似度低于設定閾值則舍去,重構信任網絡之后再預測評分,此法提高了算法精確度,但是犧牲了數據的覆蓋率,也無從緩解冷啟動問題.Moradi 等[9]提出了RTCE 模型,該模型首先基于顯性信任機制為目標項目進行打分,同時設定信任閾值,對于評分可靠性低于閾值的用戶,通過綜合考慮積極因子,消極因子重構信任度.文獻[10]創建了用戶間信任繁殖算法以此拓寬信任網絡,通過信任繁殖得到了更多有效鄰居用戶,提高了算法的覆蓋率,緩解了推薦算法中的數據稀疏性和冷啟動問題.Zhou 等[11]利用動力學傳播原理構建用戶-項目二部圖網絡結構,用戶將自己的資源均衡分配給關注的項目,從而計算用戶與用戶的資源相關信任值,該算法提高了推薦預測精度,減少了算法的復雜度.
針對推薦算法的相關問題,本文在已有的研究成果上聚焦于用戶顯性信任關系以及通過設定閾值衍生繁殖隱性信任關系,充分考慮了信任關系的主觀性,非對稱性,傳播性,弱傳遞性,以及適應性,同時融合用戶偏好,依據評分相似性選擇目標用戶的最優近鄰集合,從而進行預測.本文的主要創新點主要體現在以下方面:
1)在基于加權用戶項目二部圖[12]的信任繁殖[13]模型過程中加入對直接信任的閾值篩選控制,降低了推薦系統的噪聲,同時構建用戶信任與用戶偏好關系融合的強化模型,具有一定現實合理性,最后設計與不融合用戶偏好的算法模型進行自身對比,對比結果證明了融合用戶偏好信任的優越性.
2)計算得到的信任度最后融合實驗下表現更加優異的基于MSD 和Jaccard 相似性的JMSD 相似系數[14],在Movielens 數據集和Last.FM 數據集下的實驗表明與基準算法相比較,本文提出基于二部圖的增強繁殖信任推薦算法模型以下簡稱BTUCF 算法模型,緩解了了推薦算法的數據稀疏性和冷啟動問題,提高了算法結果召回率,降低了算法的平均絕對誤差.
下一節本文對傳統協同過濾以及傳統加權二部圖推薦算法性能特點及局限性進行分析,第二節對本文提出增強的自適應繁殖信任模型進行描述,第三節討論分析了本文得到實驗模型結果.
1 相關工作
1.1 傳統協同過濾
基于用戶的協同過濾算法基礎流程如下:
1)基于用戶的協同過濾算法,輸入數據集為用戶-項目的評分矩陣,記為Rum,用戶u對項目m的評分記為rum,未評分項目即rum=0,用戶-項目評分矩陣共有m行n列,每一行都分別代表用戶u依次對各項目的評分,每一列都分別代表某個項目受到各用戶的評分數據,形式如下:

協同過濾算法主要通過構建相似度矩陣來預測目標用戶對該項目的喜好程度,相似度計算方法是協同過濾算法推薦的關鍵因素,相似度的度量方法主要分為四種:修正的Pearson 相關系數,均方偏差(MSD),Jaccard 相似度和斯皮爾曼等級相關(Spearman’s rank correlation).
顯式用戶評分矩陣非常稀疏,相比其它相似度量本文采用的Jaccard 相似度能一定程度的從全局角度利用用戶間的交互關系,但是缺少了用戶與用戶之間的直接信任交互與間接信任用戶間的交互信息,只考慮傳統協同過濾缺少了對這些必要信息的有效補充.
1.2 傳統加權二部圖推薦算法
二部圖中定義用戶集合U={u1,u2,u3,···,ui} 定義項目集合為O={m1,m2,m3,···,mj}將i個用戶節點和j個項目的關系轉化為一種選擇關系,當用戶Ui評價過項目mj就連接此用戶與項目,對每一條用戶與項目的連接線都賦予權重Wi,特別的當用戶對項目的評分大于等于3 時Wi=1;當用戶對項目的評分小于3 時Wi=β通過實驗證明當β=0.5 時推薦結果最優[13],本文中亦使用該最優值.
1)用戶-項目關系圖構造如圖1所示.
圖中用戶對項目的關注度如式(4)所示:
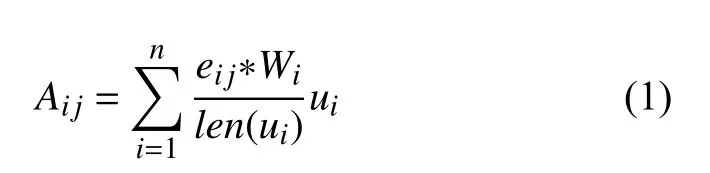
其中,Aij為項目mj受到用戶Ui關注項目總數,len(ui)為用戶ui評價過的項目權重總和,eij為用戶ui是否對項目mj有評價的布爾類型,有即為1 沒有即取0.
2)項目-用戶有向圖類似于用戶-項目有向網絡圖構建,將項目得到的用戶關注度重新反饋給用戶如圖2所示.
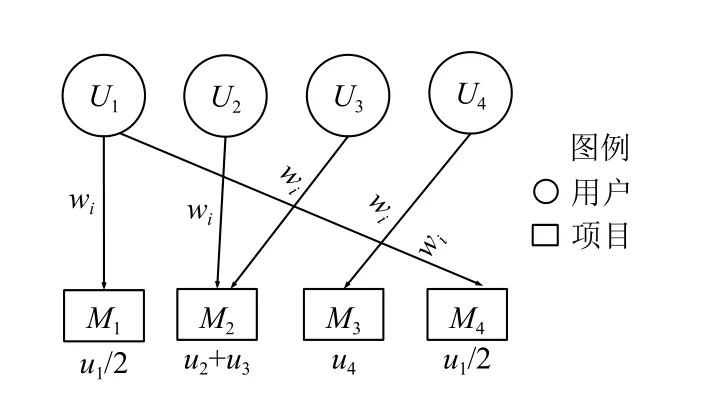
圖1 用戶—項目模型
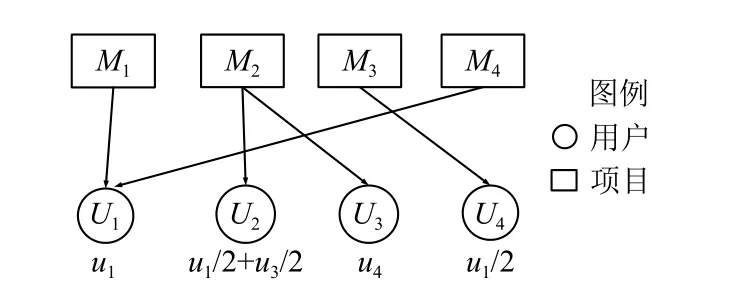
圖2 用戶—項目模型
圖中項目對用戶的反饋表達式如式(3)所示:
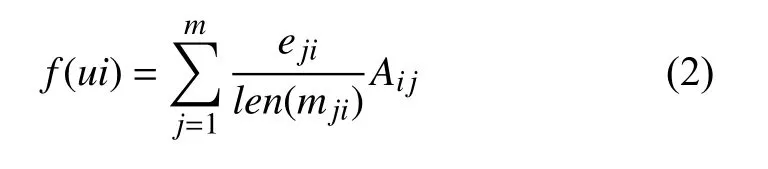
其中,f(ui)為項目反饋給用戶ui的關注度,len(mji)為用戶ui評價過項目mj的項目權重總和,eji為項目mj是否對用戶ui有評價的布爾類型,有即為1 沒有即取0,Aij為項目mj受到用戶ui關注項目總數.
最后結合用戶-項目,項目-用戶的有向網絡圖,從而可以得到用戶-用戶的有向網絡圖,結合式(4)和(5)推導出用戶與用戶之間的推導信任,推導信任取值范圍為0 與1 之間.0 表示無評價歷史,無信任交互,信任值越大信任程度越高,如式(7)所示:
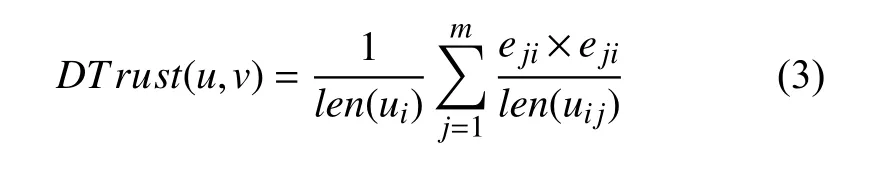
Guo[3]闡述的衡量主體與主體之間的信任關系5 個重要特性:主觀性:不同的主體有不同的興趣偏好,判斷標準,所以主體對于其他主體可能會有不同的信任值;非對稱性:主體對主體的信任都是單方面的,一般是不對稱的,在實際中A 對B 的信任度一般不等于B 對A 的信任值;弱傳遞性:信任是具有傳遞性的,在A 信任B,B 信任C 的前提下,trustAB和trustBC足夠大時,A 對C 的信任值是有顯著意義的;傳播性:主體之間的直接信任關系以及其變化會影響其他主體之間的信任關系,特別是當一個主體的興趣或者發生不誠信行為時,與其有信任關系的其余主體評估水平就會發生變化,這樣通過該主體獲得推薦的信任關系也會發生相應變化;適應性:主體之間的信任關系會隨著時間函數的變化,上下文環境的變化而變化,由于信任的動態性,推薦系統中的信任建立之后,要根據系統內各種要素的變化不斷調整調和參數.對比五種特性,傳統加權二部圖法在主觀性上一分為二的權重考慮沒有充分考慮用戶偏好,沒有在用戶之間建立不對稱的可適應性傳遞信任,沒有充分挖掘非直接交互的用戶間的潛在信任信息,同時沒有設定閾值的廣泛信任關系加入了不存在的信任關系,降低了系統的抵抗惡意攻擊能力,增加了系統噪聲.
2 一種增強的自適應繁殖信任模型
2.1 增強的二部圖網絡信任機制
(1)傳統加權二部圖基礎上的信任繁殖.利用傳統加權二部圖得到直接信任,但是直接信任只反映了有相互交互的用戶之間的關注度程度,實際數據中許多用戶之間并沒有直接互動,根據信任的可傳遞性與傳播性,用戶A 信任B,用戶B 信任用戶C,則存在用戶A 信任用戶C,挖掘潛在的間接信任可以拓寬信任關系,信任繁殖可以極大的提高算法的覆蓋率與算法精度.根據文獻[13]創建的信任進行了拓展,同時設定閾值d,本文只對直接信任大于0.01 才計算ITrust間接信任計算公式如下:
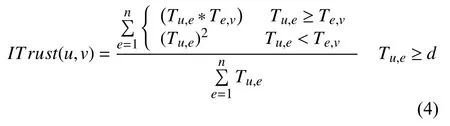
(2)綜合信任度.結合用戶間直接信任DTrust與間接信任ITrust,可計算用戶間綜合信任度,計算公式如下:
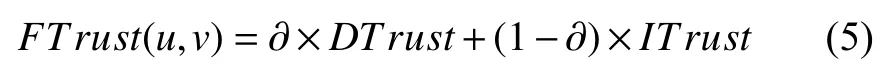
自適應性因子? 表達式如下:
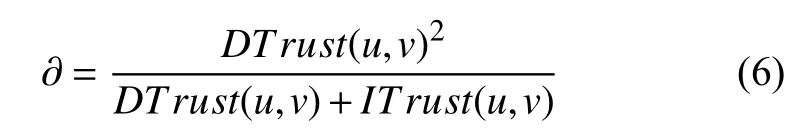
(3)結合用戶偏好的信任增強機制.增強的信任加權的二部圖在用戶-項目關系連接線上考慮了權重Wi當評分大于3 時Wi=1,當評分小于3 時Wi=0.5,加入權重后的二部圖模型具有較為明顯的優勢,但仍存在一個問題,加入權重的推薦系統降低了系統抵抗惡意攻擊的能力,沒有考慮用戶的評分偏好問題,樂觀用戶偏向于打高分,消極用戶偏向于打低分,傳統加權二部圖中假設三個用戶對四個項目的評分值分別為(1,1,1,1),(2,2,2,2)和(1,2,2,3),計算得到的信任關系u1與u2,u3與u4是相同的,這顯然不符合不符合實際情況,根據信任特性u1與u2用戶的信任度應該大于u1與u3,用戶針對此問題,本文提出了一種偏好的調整信任度,其公式為:
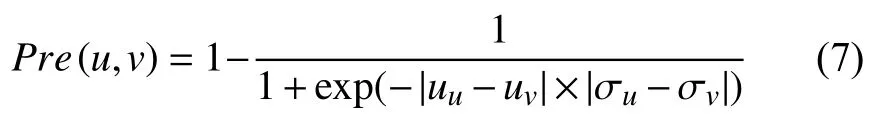
基于以上,本文在第一種模型上提出一種新的偏好調整用戶信任度度量方法構建第二種模型,增強信任公式表現如下:
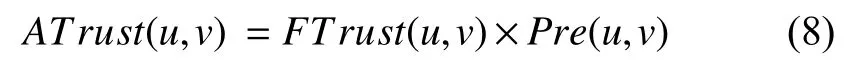
2.2 結合JMSD 相關系數推薦
本文采用的是實驗下性能更加優異的基于MSD和JMSD相似性的JMSD系數,基于用戶共同評分項的個數來度量的JMSD系數中作為一種補充的全局信任信息結合二部圖網絡信任機制全面的挖掘了用戶之間信任關系.均方偏差MSD公式為:
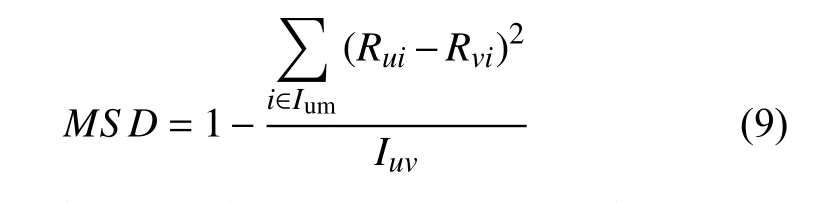
MSD無法處理用戶共同評分項過少這個問題,而Jaccard相似度是基于用戶共同評分項的個數來度量,其公式如下:
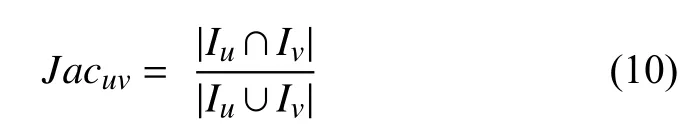
JMSDuv其公式如下:
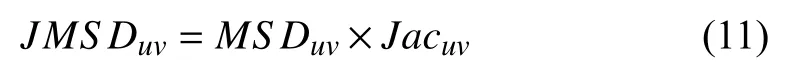
基于相似度與偏好調整信任度的研究,對于目標用戶ui的未知評分預測,給出綜合相似系數Sim如公式:
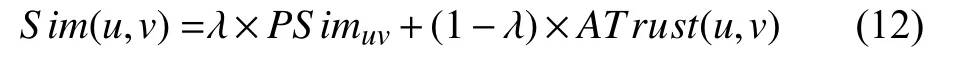
(12)根據計算的相似系數Sim,對于用戶未進行評分的項目,可采用如下預測公式預測:
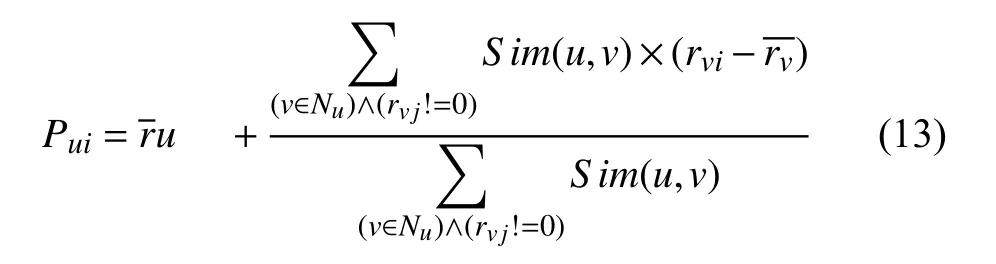
3 實驗結果和分析
3.1 實驗數據集
為檢驗算法的合理性,本文使用Grouplens 提供組供的Movielens 數據集和在線音樂系統Last.FM 提供的Last.FM 數據集對算法模型進行驗證,Movielens 由美國Minnesota 大學計算機科學與工程學院的Grouplens項目組創辦,本文選擇其中的Ml100k 數據集,數據集包括了943 個用戶的100 000 條評價數據,評分范圍1-5,每個用戶至少對20 部電影項目作出評價,分值越大喜好越大;Last.FM 數據集包含了1892 個用戶對17 632 張音樂專輯的收聽信息,實驗中與基準對比算法一致將收聽數量轉化成收聽評分用于對比.兩個數據集均按照4:1 劃分訓練集和測試集,Movielens 數據集和Last.FM 數據集根據數據稀疏性定義計算分別為:
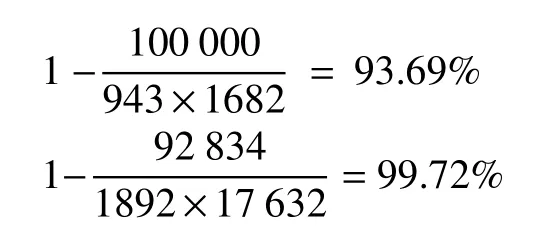
3.2 度量標準
本文采用推薦系統的度量標準是廣泛應用于評價協同過濾推薦算法的平均絕對誤差(MAE),以及召回率(Recall)定義如下:
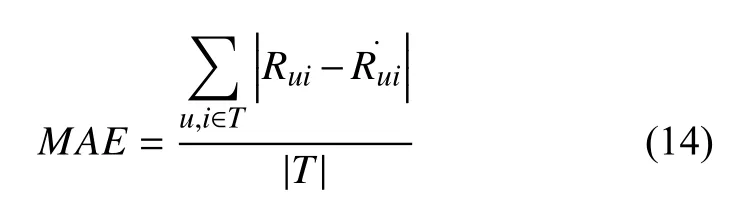
1)平均絕對誤差和均方根誤差通過訓練集計算用戶的預測評分和測試集的實際真實評分之間的偏差來度量算法的推薦準確性,所以MAE和RMSE越小,推薦的結果越準確.

2)召回率(Recall)又叫查全率,主要指通過算法可以預測出來的評分數與所有待測分數之間的比值.其中m表示通過算法模型得到的測試集預測評分數,n表示測試集中待測評分數.
3.3 算法推薦性能比較
本文提出JMSDuv相關系數與增強信任繁殖模型構建BTUCF 算法模型,在Python3.6 環境下,為了評價推薦算法的精度,對提出的模型算法進行試驗驗證,在相同的實驗環境下,對不同數據集首先對算法模型進行敏感性分析,然后與三種基準算法進行實驗對比和分析,參照的基準算法包括了主流的基于用戶的協同過濾推薦TraCF 算法[15],基于信任模型的協同過濾推薦Tru_1CF 算法[16]以及一種改進的基于信任的改進算法Tru_2CF[17].第一種基準對比算法是基于用戶推薦的經典推薦算法,第二種基準對比算法是經典的采用構建信任網絡上的局部和全局信任構建信任矩陣引入信任模塊和相似度模塊不同權重推薦算法,第三種基準改進算法設置了通信信任,相似信任,和傳遞信任三個信任度構建信任矩陣.最后為了證實本文引入用戶偏好的合理性,設置了JMSDuv相關系數與信任繁殖模型構建算法模型,即沒有融合用戶偏好的算法模型(以下簡稱BTCF 算法模型)作為另外一組對比算法進行自身對照.
3.3.1 敏感性分析
敏感性實驗主要分析在Movielens 數據集和Last.FM 數據集下參數λ對本文提出的BTCF 和BYUCF 推薦精度MAE的影響,實驗結果分別如圖3和圖4.
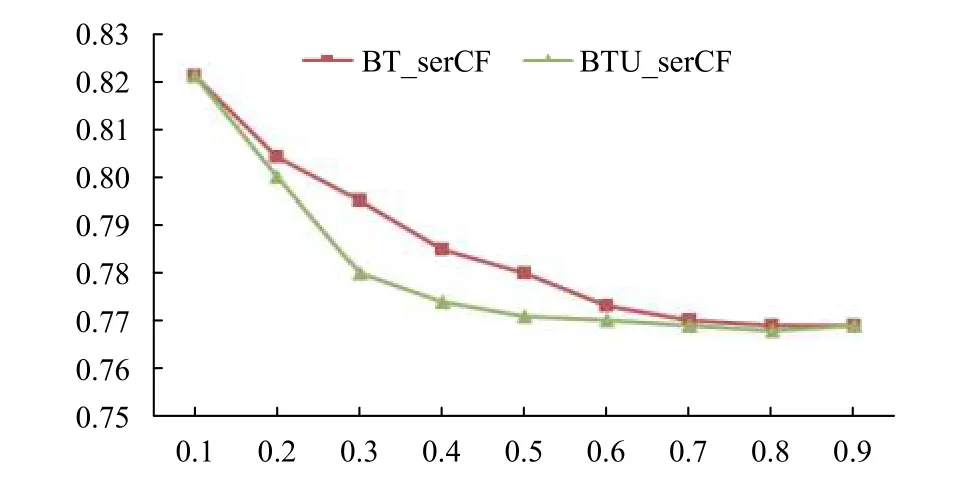
圖3 Movielens 數據集下MAE 分析
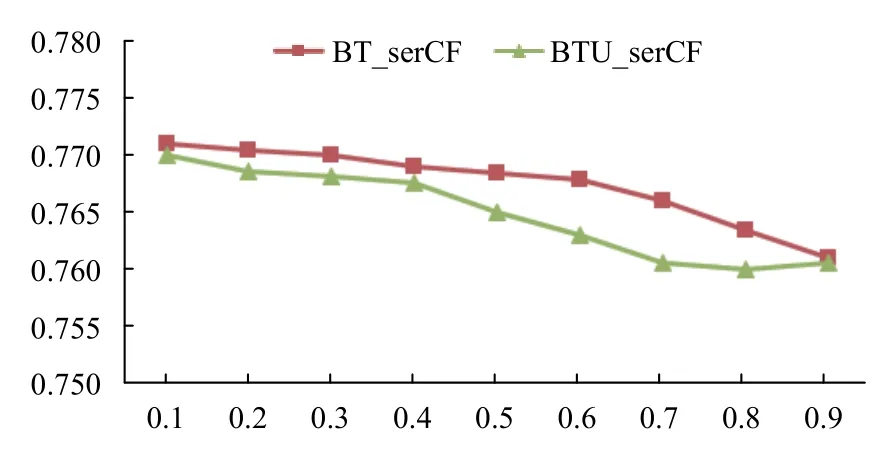
圖4 Last.FM 數據集下MAE 分析
從圖3圖4中中我們可以看到JMSD系數和融合用戶偏好的信任在推薦結果中的影響力是不一樣的,Movielens 數據集下λ=0.8 時取得了最好的結果.Last.FM 數據集下中λ=0.8 時取得最優結果.
基于二部圖的自適應性繁殖信任推薦算法其評分預測結果主要來源于兩個部分:評分相似系數和偏好信任系數,當λ=0.0 時表示在算法模型中融合用戶偏好的信任對最后的推薦結果起唯一作用,當λ=1.0 時表示在算法模型中JMSD系數對最后的推薦結果起唯一作用,相比于傳統信任算法推薦,比較從λ=0.0 和λ=1.0的變化,采用用戶之間的評分數據其推薦質量高于采用用戶之間的融合用戶偏好的信任,這表明在推薦模型中,信任必須來源于用戶的評分,這符合信任的定義和特點,同時也表明了本文基于融合用戶偏好的信任挖掘了用戶之間的潛在信任聯系,提高了推薦質量.
3.3.2 性能對比分析
不同數據及下本文提出的BTUCF 算法模型與基于用戶的協同過濾推薦TraCF 模型,基于信任模型的協同過濾推薦Tru_1CF 算法,一種改進的基于信任的改進算法Tru_2CF 以及本文提出的沒有融合用戶偏好BTCF 算法對比如下:

表1 Movielens 數據集最佳點推薦精度比較
表1可知Movielens 數據集下BTUCF 算法模型有較大改進,對比試驗結果,在參數K=7,λ=7 時(算法最佳點)具有更低的MAE值和更高的召回率.

表2 Last.FM 數據集最佳點推薦精度比較
由表2可知Last.FM 數據集下BTUCF 算法模型在MAE指標表現上優于傳統協同過濾算法和經典信任算法,但是與對比算法一種改進的基于信任的改進算法處于相同水平,召回率表現還是更加優異,MAE在Movielens 數據下系統更加優秀是因為推薦系統采用的是在較小鄰居域表現更好的JMSD相似系數,Last.FM 數據集相比Movielens 數據集更加稀疏推薦系統的優勢被相對稀釋,進一步說明了本模型對數據稀疏性的反應程度.
圖5、圖6給出了五種算法在不同數據集和不同鄰居數量下的MAE和Recall值,我們可以直觀的發現,結合JMSD系數的推薦模型算法與結合皮爾遜以及改進的皮爾遜算法模型有較大差異,在K 較小的區間內結合JMSD系數的推薦模型算法具有更好的表現.這也驗證了文獻[17]的結論和本文引入JMSD系數的合理性,在算法結果對比下本文提出的BTUCF 算法模型在召回率的變現上更好,同時具由較低的平均絕對誤差.
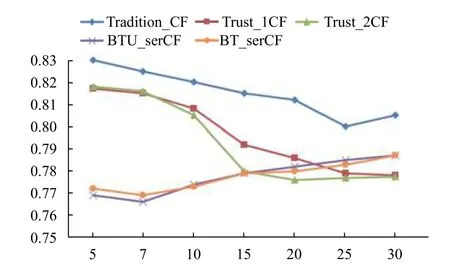
圖5 Movielens 數據集下的MAE 對比圖
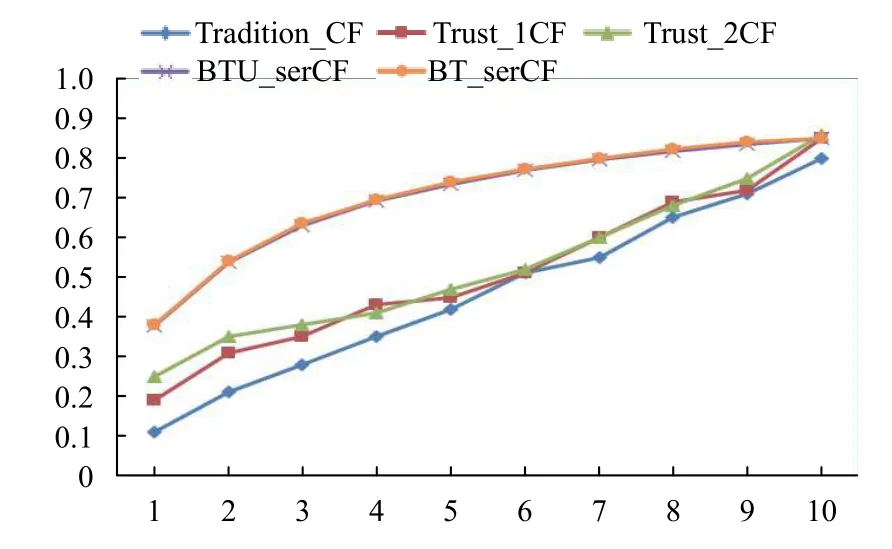
圖6 Movielens 數據集下的Recall 對比圖
同時對比BTCF 算法模型和TUCF 算法模型,前者因為算法模型引入了繁殖信任融合JMSD系數,改進算法的同時也增加了數據噪聲對推薦系統的影響,引入用戶偏好的BTUCF 算法模型可以緩解噪聲數據的影響,使得系統在K較小值范圍能更取得更低的MAE,但是作為引入用戶偏好的模型也降低了系統的召回率.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
